
基于Apriori 算法的高职院校图书精准推荐系统
2023-09-21 07:04王丽兰
河北软件职业技术学院学报 2023年3期
王丽兰
(泉州经贸职业技术学院,福建 泉州 362000)
0 引言
目前高校使用的图书推荐方式主要包括两种,一种是基于图书相似度的推荐,根据图书的借阅历史记录,为学生推荐其感兴趣的相似的图书;一种是根据学生的基本信息和行为,挖掘出具有相同特征信息的学生,从而推荐互相感兴趣的书目。[1]相对本科高校,一般高职院校学生数量少,学生阅读兴趣不高,因此借阅记录也较少。现有的图书推荐系统一般针对学校的纸质图书借阅记录进行分析并推荐,但部分高职院校根据学生需求上线了电子图书阅读平台,电子图书阅读平台的图书相比纸质图书更新速度快,体量也更大,已经成为当代大学生阅读的主要方式之一,因此电子图书平台拥有更多更准确的学生借阅记录。如何利用纸质图书借阅记录和电子图书借阅记录,结合高职院校学生的阅读特点,对学生进行图书精准推荐,激发学生阅读兴趣,提高学生阅读和专业能力水平是各个高职院校图书馆都需要考虑的问题。
对高职院校学生的借阅记录进行分析,发现借阅记录存在以下两个特征:一是专业书籍借阅记录较少,借阅频率较多的是文学类书籍;二是大多数学生的阅读习惯较差,缺乏合理有效的阅读计划,阅读过程存在随意性和盲目性问题,多数学生在规定时间未阅读完所借图书。[2]为此,高职院校图书馆需要从杂乱无章的阅读记录中利用Apriori 算法为学生进行图书精准推送。
1 Apriori 算法介绍
Apriori 算法是一种经典的数据挖掘算法,利用数据间的关联度获得数据之间的强关联规则。关联分析中的基本概念包括频繁项集、支持度和置信度。
满足最小支持度阈值的事件集为频繁项集。如果事件里有K 个元素,就是频繁K 项集。可以说频繁项集是出现频率较高的元素集合。事务集D 中包含的几个有关联的数据所占D 的百分比,称为支持度。支持度公式为:
事务集D 中包含A 的事务同时也包含B 的百分比,称为置信度。置信度公式为:
在Apriori 算法中,需要设置最小支持度阈值和最小置信度阈值。Apriori 算法实现流程如图1所示。

图1 算法实现流程
2 高职院校图书精准推荐需求分析
高职院校图书馆在图书推荐过程中需要考虑所推荐图书的专业性和参考性。所谓的专业性是指对学生进行图书推荐过程中,需要结合其专业进行相关推送,而不仅限于本身的阅读习惯;参考性是指所推荐的图书需要对学生具有辅助作用,对于娱乐性强、参考性不大的图书需要进行过滤。只有兼顾专业性和参考性原则才能为学生精准推送有价值的图书。实验证明,带有过滤机制的Apriori 算法在较小数据量下可以通过分析更少的数据来获取到相同的强关联规则结果,算法效率会大幅提高。[3]高职院校学生层次区别较大,以专业排名为序对学生的阅读进行分析可以发现,排名靠前的学生,其阅读的记录较多,且其阅读具有一定的规划性,除了文学读物外,阅读轨迹一般与其专业需求保持一致;而排名靠后的学生,其阅读记录相对较少且零散,该数据直接影响到算法的效率和精准度。为提高算法效率,选取教务系统中成绩排名在前60%的学生的借阅记录作为分析数据。通过教务系统获取排名前60%的学生数据,所需要字段包括XM(姓名)、YXDM(院系代码)、NJ(年级)、ZYDM(专业代码)、ZYPM(专业排名)。将获取的数据与电子资源库的阅读记录以及纸质图书借阅记录相结合,对借阅记录进行过滤,获取分析对象。
通过Apriori 算法对待分析借阅记录进行挖掘并推荐。Apriori 将待分析阅读记录作为挖掘项集,设定最小支持度阈值和最小置信度阈值。通过挖掘支持度大于最小支持度阈值以及置信度大于最小置信度阈值的强关联规则,形成关联规则库,再将关联规则数据库同借阅者所选图书进行关联匹配,根据推荐策略得到推荐图书。结合本文的图书算法内容,Apriori 算法在图书精准推荐中的实现步骤为:(1)读取读者数据集,包括纸质图书借阅记录和电子图书借阅记录;(2)提取经筛选的数据集,通过关联教务系统学生成绩数据选择专业排名前60%学生的借阅记录作为数据集;(3)针对数据集计算出不同频繁项集的集合;(4)形成图书推荐系统的关联规则库,要求支持度大于最小支持度阈值和置信度大于最小置信度阈值;(5)根据搜索读者的借阅记录和浏览记录,将满足关联规则的图书推荐给学生。
3 Apriori 算法在高职院校图书推荐系统中的实施
图书精准推荐系统是基于J2EE 技术开发的,数据库使用SQL Server 2008,利用JDBC 建立应用程序与数据库之间的连接。[4]图书推荐系统的数据流向如图2 所示。
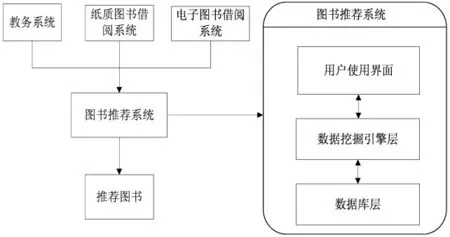
图2 图书推荐系统数据流向图
图书推荐系统的数据流向是从纸质图书借阅系统和电子图书借阅系统获取借阅数据,借阅数据包括学生学号、专业及已借阅图书记录,利用教务系统对已获取的数据进行筛选,获得专业排名前60%学生的借阅数据。筛选后的数据即为图书推荐系统的事务集TD。
导出读者借阅数据,通过对比发现,排名前60%的学生借阅书籍所占比例较大,且所借书籍中专业书籍占比相对较大;排名后40%的学生借阅量相对较少,且所借书籍中文学类及其他课外读物占比相对较大。通过寻找频繁项集,获取强关联规则,再对读者进行图书精准推荐。下文将以会计系专业学生的借阅记录为例,在纸质图书系统和电子图书借阅系统中,会计系学生在2022 年1月-11 月期间的借阅记录总共有3454 条(同一读者在不同时间借阅的数据为不同记录),将该借阅记录与教务系统的专业排名相关联筛选出专业排名前60%学生的借阅数据,共计2637 条。在Apriori 算法下选取数据的执行过程如下所述。
(1)初始设置支持度为40%,根据推荐结果对支持度进行优化,读者借阅事务集如表1 所示。

表1 读者借阅事务集
(2)通过枝剪过滤掉不满足最小支持度的项集,得到K 项集,如表2 所示。

表2 简化后的借阅记录事务集
第一次迭代:k=1,满足支持度大于40%的频繁项集如表3 所示。

表3 频繁1 项集
第二次迭代:k=2,满足支持度大于40%的频繁项集如表4 所示。

表4 频繁2 项集
第三次迭代:k=3,满足支持度大于40%的频繁项集如表5 所示。

表5 频繁3 项集
第四次迭代:k=4,满足支持度大于40%的频繁项集如表6 所示。

表6 频繁4 项集
第五次迭代无满足支持度大于40%的频繁项集,设置并计算置信度,将满足置信度规则的结果作为强关联规则。
(3)对该输出结果进行判断,确定是否调整支持度和置信度。如结果不符合预期则继续调整,确定最终的支持度和置信度。运行该算法并将最后运行结果存入关联规则表中,根据读者的借阅记录对读者进行图书精准推荐。
通过使用Apriori 对高职院校学生图书借阅记录进行深度挖掘,从而达到精准推荐的目的。本系统与传统的图书推荐系统相比更加优化,主要体现在下述两点。第一,推荐结果更符合学生阅读需求。根据学生阅读习惯的转变,系统将分析对象进行扩充,在纸质图书借阅记录基础上增加了电子图书借阅记录。图书借阅记录数据量的增加可以有效提高图书推荐的精准度。第二,系统运行效率更高。传统的图书推荐系统根据读者借阅记录进行分析,运行速度慢,效率低。通过分析发现高职院校学生之间的阅读习惯相差较大,学习成绩较好的学生其借阅数据相对较多,且借阅书籍紧跟专业课程需求;而学习成绩较差的学生借阅数据相对较少,且借阅数据与专业课程相关度较低,书籍类别较杂。本系统通过关联教务系统,将专业排名前60%学生的借阅记录提取出来,利用Apriori 算法进一步分析,既避免了杂散数据的干扰,提高了运行速度,又提高了推荐结果的精准度。
4 结语
为提高服务能力和服务质量,高职院校图书馆需要根据学生的阅读情况有针对性地进行阅读推荐。在图书精准推荐系统中,结合高职院校学生的阅读特点,通过关联教务系统对借阅记录进行过滤,以提高Apriori 算法的运行速度和推荐结果的精准度,同时由于算法执行结果的精准度与算法设置的置信度和支持度有重要关系,因此在系统运行前期需要根据产出结果的精准度进行不断调整,确定最适合的置信度和支持度,最终使系统的运行结果达到理想状态,实现图书精准推荐。
猜你喜欢
核科学与工程(2021年4期)2022-01-12
南风(2020年22期)2020-09-15
小学生优秀作文(低年级)(2019年5期)2019-04-25
计算机应用(2018年5期)2018-07-25
小学阅读指南·低年级版(2017年12期)2017-12-26
轴承(2015年2期)2015-07-25
卷宗(2014年5期)2014-07-15
计算机工程(2014年6期)2014-02-28
电讯技术(2011年11期)2011-04-02
网络安全与数据管理(2010年1期)2010-05-18
