
改进ResNet双目视觉算法在人脸活体检测中的应用研究
2023-09-21 03:53张文兴杨振凯刘文婧王建国
机械设计与制造 2023年9期
张文兴,杨振凯,刘文婧,王建国
(1.内蒙古科技大学机械工程学院,内蒙古 包头 014000;2.内蒙古自治区机电系统智能诊断与控制重点实验室,内蒙古 包头 014000)
1 引言
随着移动网络的迅速崛起,生活中随处可见的“刷脸”支付方式使得人脸支付在日常生活中受到了许多人喜爱[1]。人脸支付涉及到个人的财产安全,其决定了钱袋子的安全性。目前的攻击方法可以分为三种主要类型:打印照片,重放视频和人皮面具。由于较高的生产成本和需要十分详细的人脸3D数据,因此,采用面具的人脸攻击极少[2]。随着手机相机分辨率和高清打印机还原度的快速提升,加之社交平台的开放性很容易获得受害人的照片和视频,照片和视频的攻击已成为日常最常用的攻击手段。因此,人脸活体检测已经成为人脸面部识别认证系统必不可少的安全验证步骤。2012 年ImageNet 图像识别大赛冠军Alexnet 第一次将“Dropout”,和“LRN”等优化函数同时应用到了卷积神经网络之中,将验证错误率从25%以上降低到了15%,使得深度学习在图像识别算法领域迅速走热[3]。文献[4]首次将卷积神经网络(CNN)的深度学习方法直接应用到活体检测中,受限于公开数据集规模以及模型深度,性能始终无法超越传统方法。文献[5]提出了一种新颖的CNN-RNN架构用于端到端的学习深度图和rPPG信号的混合特征,使得深度学习算法在人脸活体检测领域第一次超越了传统机器学习算法。文献[6]提出利用红外和普通光学相机的双目测距方法获重建人脸的48个特征点的深度信息依靠支持向量机(SVM)进行二分类识别,然而受限于3D人脸建模精度的限制难以普及。文献[7]提出利用独立的RGB相机和深度相机深度融合方法,将两种相机获取的图像分别用相同的单路卷积神经网络进行特征提取,最后将两条卷积提取的特征在分类层直接相加融合后再进行分类。单目活体检测对角度和光线变化的干扰比较敏感,双目的活体检测越来越受到研究者的关注。
以往双目活体检测的方法不是利用双目测距原理重建人脸特征点处的深度信息,就是使用多路卷积将不同相机的画面分别送入多路卷积提取特征,然后直接将提取的特征向量相加送入分类层进行分类。这样利用双路卷积提取的特征信息只不过是各自的特征的直接叠加,而不是两幅图像的综合特征。
2 人脸活体检测算法
通过手工制作视差图,将独立的双目图片制作成具有联合特征的一张图片,使用单路卷积将双目图片的联合特征提取出来,这样就能很好的利用视差特征用于活体检测之中。
2.1 制作数据集
2.1.1 双目同步相机原理
视差指与被观察对象存在一定距离时,两个观察角度对目标产生的角度差异。受限于单目相机的自身结构无法获得同一时刻不同角度的视差,因此本实验需要使用同步双目相机。同步双目可见光相机的结构原理,如图1所示。目标物P的视差值计算等式由三角形定理可得:
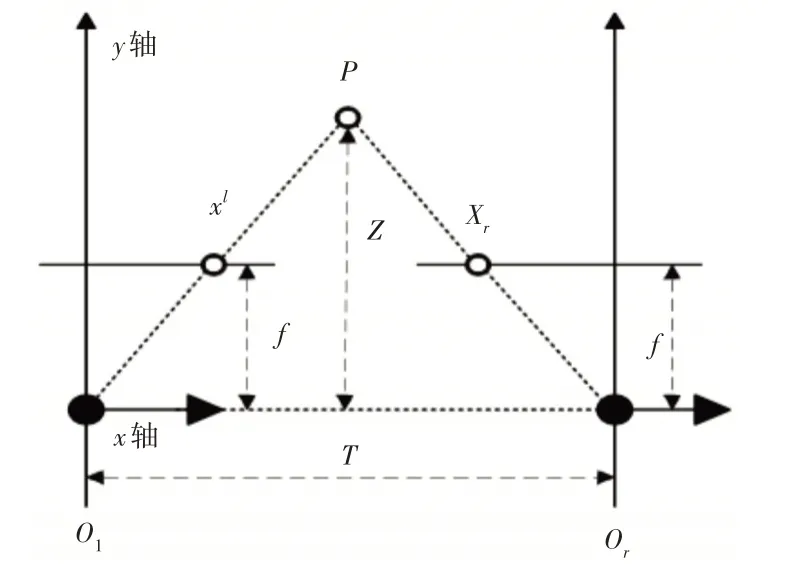
图1 平行光轴双目相机结构原理Fig.1 Structure Principle of Parallel Optical Axis Binocular Camera
故求得双目相机视差值为:
式中:Ol、Or—相机左右光心;
T—光心距;
f—焦距;
xl和xr—物体P在成相面上横坐标投影。
2.1.2 制作双目同步视差数据集
由于没有适合该实验研究的公开数据集,自建一个小型人脸双目视差数据库。实验中数据集制作使用HBV-1780-2普通可见光同质双目同步摄像头,如图2所示。

图2 HBV-1780-2可见光同质双目同步摄像头Fig.2 HBV-1780-2 Visible Light Homogenous Binocular Sync Camera
该摄像头是一种同步单通道RGB摄像头,能够有效解决画面非同步造成的差异。实验数据集采用基于Pycharm的OpenCV框架制作过程流程,如图3所示。

图3 实验数据制作流程Fig.3 Experimental Data Production Process
首先利用Haar 特征把人脸检测的级联分类器(Cascade -Classifier)载入,来获得双目图像左右区域中的人脸位置信息。然后将人脸位置信息进行个数判断,若获得到2张人脸的坐标信息时将局部人脸分割出来统一为(100×100)的尺寸大小;否则继续下一张图片提取。最后将提取的局部人脸使用Numpy库中的图像并联函数Concatenate()进行左右拼接。
本实验采集了10个人的人脸数据,包含日光,灯光,逆光和室内白天4种不同光照条件下的真脸。四种不同条件下的真实人脸样本,如图4所示。

图4 四种不同条件下的真实人脸样本Fig.4 Real Face Samples Under Four Different Conditions
将小米9 手机录制的1080p30 标准视频分别在手机、Think Vision显示器、惠普暗影精灵4笔记本电脑显示器播放。再将惠普M180n打印机打印的A3大小彩色照片统一录制制作成4种不同的假脸,如图5所示。

图5 四种不同条件下的攻击人脸样本Fig.5 Attack Face Samples Under Four Different Conditions
本实验一共采集到了真伪人脸各4000张,总计8000张。为了提高模型的泛化能力,采集过程中变换了人脸的不同角度,距离远近和是否戴眼镜等变量,以提高模型的泛化能力。
2.2 残差神经网络模型
残差神经网络[8](ResNet)网络是深度学习图像分类领域应用较广的新型卷积神经网络。ResNet神经网络是由多个残差块堆叠而成,标准残差块,如图6所示。

图6 残差块结构Fig.6 Residual Block Structure
当通道尺寸相同时,残差块输出的计算公式为:
式中:xi—输入;xi+1—输出值;
F(xi,Wi)—卷积运算;
Ws—卷积核。
当卷积网络中xi+1与xi的通道数目不相同时,采用卷积核大小1×1,步长为2的卷积运算Ws进行维度匹配,得到输出值xi+1。公式如下:
式中:Ws—卷积运算。
通过以上数据变换,当前残差块的输出即可以得到经过残差块卷积过后的特征,这种结构避免了特征矩阵经过多卷积层时,导致梯度值过小使得模型不收敛问题。
2.3 改进的残差网络模型
在残差神经网络(ResNet34)的残差块中的结构,如图7(a)所示。文献[9]提出第二个卷积只对第一个卷积的结果进行了特征提取,而没有充分利用上一级残差块的输入特征矩阵的关系,为此加入跳跃连接使得第二个卷积可以直接复用上一层卷积的输入。结构如图7(b)图所示。

图7 改进前后的残差块结构示意图Fig.7 Schematic Diagram of the Residual Block Structure Before and After the Improvement
人脸作为一种类间差异性较小的样本模型,需要大量样本训练减少过拟合,而“shortcut”可以实现特征复用,提高数据的利用率降低过拟合。文献[10]中提出对于残差神经网络内部残差块中的BN层排布在卷积层之前,导致了输入卷积计算时的数据并未起到归一化运算。因此调整残差块的结构将“BN”层移动到卷积层之前。结构如图7(b)图所示。
2.4 引入SENet注意力模块
注意力机制(Attention Mechanism)的SENet 模块是最后一届ImageNet大赛的冠军模型[11]。该模型弥补了以往模型只提取了空间和维度特征,而忽略了通道之间的相关性。SENet模块主要运算过程的步骤,如图8所示。

图8 SE模块结构图Fig.8 SE Module Structure Diagram
(1)Squeeze将某个channel上的空间特征进行压缩,提取为一个具有全局感受野的实数。公式如下:
式中:zc—输出向量;Fex(uc)—全局平均池化;h、w—输入特征的高和宽;uc(i,j)—输入矩阵。
(2)Excitation分为两步,首先将借助参数w来为每个特征通道生成权重,学习通道之间互不相关的非线性特征关系,σ()表示非线性激活函数sigmoid,用来处理非线性变化。
式中:σ()—激活函数sigmoid;g(z,W)—输入向量;sc—每个通道的权重。
其次,将经过非线性变换后的向量从一维向量恢复到原始输入数据的形状。
式中:uc—输入矩阵的原始形状参数。
文献[12]通过实验探究了以标准的SEResNet 块为基础的新SE-ResNet结构获得更高的识准确率,如图9(a)的结构关系。后来本实验将9(a)结构中“Relu”激活函数进行的再次调整,避免残差块结构对SENet网络模块的影响。再将图7(b)中第一个卷积层之前的“BN”层,放置到图9(b)所示的SE-ResNet块之后,使其对两条路径都可以起到归一化作用,从而进一步提高了模型的性能。最终网络模块,如图9(b)所示。
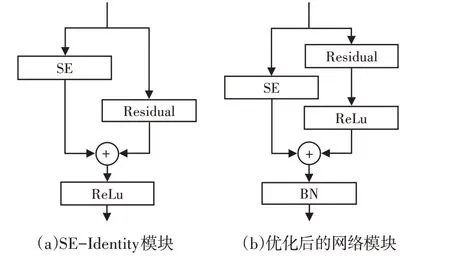
图9 加入SE模块的残差块结构Fig.9 Add the Residual Block Structure of the SE Module
通过对以上改进模型实验结果的分析对比,得出平均准确率,如表1所示。优化1指将ResNet34模型中加入“Shortcut”结构后的新结构,如图7(b)所示。平均准确率97.78%;而这里方法将SE-ResNet34模型改进了SENet在残差块中的结构,如图9(b)所示的结构平均准确率98.62%。

表1 不同改进方法的消融实验结果Tab.1 Results of Ablation Experiments with Different Improved Methods
改进后的模型有4种残差块结构,具体结构参数,如表2所示。

表2 改进后的网络结构参数Tab.2 Improved Network Structure Parameters
除第1类残差块以外,其余3类残差块中第一个残差块的首个卷积运算的步长均为stride=2,余下步长都为1;SENet网络模块中的压缩率为经验值16。残差块“ResBlock”中前两行分别代表第一个卷积层参数,第二个卷积层参数以及SENet 网络的参数,具体参数结构,如表2所示。
3 实验结果与分析
实验平台采用Windows 10 基于Pycharm3.7 的TensorFlow 2.1 和OpenCV 3.4.3 框架。硬件配置为Intel(R)8th Gen i5 8300H,16 GB运存,NVIDIA 1050ti显卡。
3.1 搭建调试网络摸型
在改进的SE-ResNet34网络模型中设置迭代次数为50;学习率0.0001;采用随机梯度下降(Adam)算法;并采用了Categorial-Crossentropy()损失函数。将制作好的真假人脸取8000张图片制作one-hot编码,设置图片输入尺寸为(128,64,3)图片格式HSV。将数据按照8:1:1进行划分,5600张训练,1200张验证,1200张测试。
3.2 实验结果对比分析
实验验证了多种经典模型对于实验数据的有效性,测试集准确率均取后10 次测试集准确率的平均值结果,如表3所示。这里的实验方法对比经典模型LeNet5测试集准确率提升了7.04%、对比ResNet34 网络模型测试集平均准确率提升了2.07%、对比SE-Resnet34 网络模型测试集平均准确率提高了0.83%。

表3 自制数据集在经典模型上的平均准确率对比Tab.3 Comparison of the Average Accuracy of Self-Made Data Sets on Classic Models
文献[11]对SENet 网络又进一步研究了,通过ResNet 网络与SENet 网络模块不同的排列方式提出多种方案。当ResNet 与SENet内部残差块结构排序如图9(a)所示时,获得的平均准确率超过了文献[12]最早提出的结构。然而该模型最后结果出现了一定的过拟合现象,平均准确率为96.97%。而本实验调整后的结构如图9(b),具有一定的抗过拟合作用,相比调整前的模型平均准确率提高了1.65%。
4 结论
为了能够有效的抵抗图片和视频攻击,本实验提出的一种基于改进ResNet 双目视觉算法及其在人脸活体检测中的应用研究。实验在残差块中引入“Short”结构,调整了ResNet神经网络的和SENet模块的相对位置。实验结果证明了本实验能够在自制小样本数据集上有效解决角度和光线变化对人脸活体检测结果的影响。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
肝博士(2021年1期)2021-03-29
华人时刊(2020年21期)2021-01-14
保健医苑(2020年1期)2020-07-27
电子制作(2019年20期)2019-12-04
动漫星空(2018年9期)2018-10-26
现代计算机(2016年11期)2016-02-28
百科探秘·航空航天(2015年10期)2015-11-07
发明与创新(2015年33期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
