
监控视角下密集人群口罩佩戴检测算法
2023-09-18 04:36张荣芬刘宇红饶庭漓
计算机工程 2023年9期
孙 龙,张荣芬,刘宇红,饶庭漓
(贵州大学 大数据与信息工程学院,贵阳 550025)
0 概述
正确佩戴口罩可以有效阻绝新型冠状病毒在人群中的传播[1]。然而,疫情常态化的趋势使得民众逐渐放松了警惕,公共场所等高风险区域不戴口罩或不规范佩戴口罩等现象频发,例如,据“深圳发布”2022 年10 月11 日消息,深圳新一轮疫情中一部分新增病例因不规范佩戴口罩而发生隔空感染。因此,在高风险场所内如何结合安防摄像头对密集人群进行口罩佩戴检测,成为一个值得研究的问题。与此同时,随着深度学习及计算机视觉的快速发展,目标检测这一计算机视觉下的子分支在安防监控、自动驾驶、无人机场景分析等领域中得到广泛应用。目标检测是语义分割、实例分割等高级视觉任务的基础,可简单定义为:给定输入图像,通过目标检测算法,在输入图像中检测出指定物体类别及其对应坐标位置信息,并通过矩形框可视化标注。
现有目标检测算法可根据阶段数分为单阶段与双阶段两类。常见单阶段目标检测算法包括YOLO[2]、SSD[3]、Retina-Net[4]等,常见双 阶段算 法包括Fast R-CNN[5]、Faster R-CNN[6]、Cascade R-CNN[7]等。单阶段目标检测算法往往以检测精度为代价从而具有较快的推理速度,而双阶段算法则与之相反。
本文研究的口罩佩戴情况包括正确佩戴、不规范佩戴、未佩戴等3 个类别。目前已有许多研究者将目标检测算法运用于口罩佩戴检测这一任务中。春雨童等[8]提出新冠肺炎疫情背景下聚集性传染风险智能监测模型,基于Cascade-Attention R-CNN目标检测算法,利用两阶段网络精度高的优点实现对聚集区域、行人和口罩佩戴情况的自动检测,但仍然不可避免两阶段检测网络检测效率的难题。HE 等[9]提出基于HSV+HOG 特征和SVM 的人脸口罩检测算法,利用人脸关键点检测人脸口罩佩戴情况。该算法虽然达到了一定的检测精度,但时间复杂度较高,鲁棒性较差。李雨阳等[10]提出基于改进SSD 的口罩佩戴检测算法,同时通过引入协调注意力机制、使用Quality Focal Loss 实现更优的正负样本分配策略。曹城硕等[11]提出利用YOLO-v3 算法进行口罩佩戴检测,但所构建数据集样本过少,且未针对特定场景做出优化。白梅娟等[12]提出利用可见光与红外图像进行联合口罩佩戴检测研究。此种方式虽然能提升模型算法的准确率与召回率,但应对复杂多变的外部环境时不具备普适性。
上述研究都一定程度上实现了性能优异的口罩佩戴检测算法,但作为目标检测子任务之一的口罩佩戴检测同样会遭遇目标检测中的几大难题,如目标样本密集分布、遮挡、图像畸变、小目标检测等,而在监控视角下针对密集人群的口罩佩戴检测也同样会面临以上问题。为此,本文提出基于YOLO-v5 改进的针对监控视角下密集人群的口罩佩戴检测算法MDDC-YOLO,主要工作如下:改进YOLO-v5 特征融合策略,选择对小目标检测更为友好的C2 特征图输入特征路径聚合网络FPN+PANet中;受Trident-Net 启发,利用空洞卷积构建用于增强感受野的多分支空洞卷积模块MRF-C3,替换YOLO-v5 中用于构建骨干网络的C3 模块,提高模型小目标检测能力;引入Repulsion Loss,采用基于样本边界框排斥吸引的原则,提高模型应对目标遮挡的鲁棒性;引入ECA(Efficient Channel Attention)注意力机制,赋予模型进行自适应关注通道特征的能力;提出基于透视变化结合缩放拼接的离线数据扩充方法,增加监控视角下小目标、目标不同透视角度的样本数量,并使用能生成更多小目标样本的 Mosaic-9 数据增强结合随机擦除的在线数据增强方法。
1 MDDC-YOLO 算法
MDDC-YOLO 监控视角密集人群口罩佩戴检测算法改进于通用目标检测算法YOLO-v5,为使其适用于本文所针对的应用场景,相对YOLO-v5 做出以下改进:利用空洞卷积构造多分支感受野模块MRF-C3替换YOLO-v5 中常规C3模块,解决密 集人群中小目标占比大、普遍存在遮挡的现象;使用Repulsion Loss 基于样本边界框排斥吸引的原则,提高模型抗遮挡能力;引入ECA 注意力机制,赋予模型进行特征通道最优化选择的能力。MDDC-YOLO网络结构如图1 所示(彩色效果见《计算机工程》官网HTML 版,下同)。

图1 MDDC-YOLO 网络结构Fig.1 Structure of MDDC-YOLO network
1.1 MRF-C3 模块
为提高网络对多尺度目标检测的鲁棒性,受Trident-Net[13]研究启发,本文在原三叉戟块(Trident blocks)的基础上,设计用于增强模型不同层次感受野的多分支感受野模块MRF-C3,如图2 所示,其中,图2(a)为YOLO-v5 中原始C3模块,图2(b)为MRF-C3 模块。

图2 C3 与MRF-C3 模块Fig.2 C3 and MRF-C3 modules
MRF-C3 模块采用膨胀率分别为(1,2,3)的3 组空洞卷积与1 条来自于上层输入的残差连接构成,并最终形成四分支并行的特征图输出模块。值得注意的是,Trident-Net 的提出者认为应使模型学习到目标不同尺寸的特征,而不是将被缩放至不同尺寸的同一物体视为毫无关联的多个不同物体[13],因此,在3 条由空洞卷积构成的分支中,将不同分支的空洞卷积设置为参数共享。本文将这样的多分支感受野聚合模块MRF-C3 嵌入YOLO-v5 骨干网络CSPDarkNet53 中,以提升模型对目标尺度变化的敏感性。
1.2 Repulsion Loss
针对密集人群的口罩佩戴检测常常会遇到目标之间相互遮挡的问题,如图3 所示。在训练阶段,目标间遮挡会导致本属于目标B 的预测框被与之重叠的目标A 的真实框吸引,从而导致训练过程中正样本丢失,影响训练精度;在预测阶段,由于目标检测器预测时后处理中通常使用非极大值抑制(Non-Maximum Suppression,NMS)来抑制针对同一目标产生的多个冗余框,而目标间遮挡时会出现前文中所提及的交叉物体干扰的现象,导致经NMS 后处理后出现交叉物体漏检现象。

图3 目标遮挡示意图Fig.3 Schematic diagram of target occlusion
为解决以上问题,本文采用WANG 等[14]基于预测框与真实框排斥吸引的Repulsion Loss 来解决密集人群口罩佩戴检测中的目标遮挡问题。Repulsion Loss 可定义为式(1):
其中:LAttr为吸引项,作用为使预测框与相匹配的真实框尽可能接近,具体可定义为式(2),式中,P+为图像中正样本集合,BP为预测框,GP,Attr为与该预测框对应的真实框;LRepGT及LRepBox为排斥项,前者作用为排斥该预测框周围的其余真实框,后者作用为排斥其余分别归属于不同真实框的预测框,两者分别定义为式(3)、式(4),在式(3)中,IIoG(BP,GP,Attr)为该预测框与其对应真实框之间重叠部分在真实框中的占比,在式(4)中,Ι[]为标识函数,ε为功能常数,用于避免出现分母为0 的情况,SmoothLn具体定义如式(5)所示,平滑因子σ∊)[0,1 ;α与β为平衡两者损失的补偿项。
1.3 ECA 注意力机制
注意力机制意在空间层面及通道层面对各组成部分进行权重分配从而使得网络性能获得提升。近年来,大量与视觉相关的注意力研究相继被提出,如关注通道间关系的SE[15]、同时关注空间与通道间特征关系的CBAM[16]以及对通道间关系关注更为高效的ECA[17],本文选择ECA 注意力机制作为提升各层级特征表达的模块,并将其插入FPN[18]与PANet[19]连接处,如图4 中蓝色虚线框中蓝色箭头所示。

图4 ECA 注意力插入位置示意图Fig.4 Schematic diagram of ECA attention insertion position
在ECA 注意力模块中,首先将输入特征进行全局平均池化,并将其输入至核大小为k的一维卷积中,然后通过Sigmoid 激活函数获得各通道权重,最后对各通道特征进行权重分配,从而获得输出特征。ECA 注意力模块具体结构如图5所示。

图5 ECA 注意力模块结构Fig.5 Structure of ECA module
1.4 数据增强策略
考虑到真实监控视角下口罩人脸存在透视畸变的问题,在离线数据增强中,本文引入透视变换进行数据扩充从而获得口罩人脸多角度样本。为增强模型抗遮挡的鲁棒性,在训练过程中引入图像区域随机擦除方法[20],为进一步解决监控视角下口罩人脸目标小的问题,使用Mosaic-9 替代常规Mosaic[21]数据增强方法。
透视变换具有将图像从一个视平面投影至新的视平面,使得一个平面图像产生透视效果的能力,透视变换可表示如下:
其中:x、y、w为原始图像坐标,对应得到经投影变换后的图像坐标x′、y′、w′;矩阵A为投影变换矩阵。
本文将透视变换结合缩放拼接的方式应用于目标数为1 图像中,以此进行数据集扩充,即通过设置不同的透视变换矩阵,获得原始图像不同透视角度的图像,并结合原图进行缩放拼接。离线数据增强示意图如图6 所示。
Mosaic-9 与Mosaic 数据增强总体思路相同,都是使用多张图像进行缩放拼接处理,从而使样本在训练过程中得到多尺度表达,有助于增加数据集多尺度样本、丰富检测物体的背景以及在批归一化计算时同时计算多张图像数据。在原始YOLO-v5 中,随机从数据集中选取4 张图像进行Mosaic 处理,但在本文所针对的应用场景下,为尽可能多地提供小目标样本,采用9 张图像作为Mosaic 数据增强的最小组合,如图7 所示,处理流程如下:1)随机抽取9 张图像,保持原始图像高宽比进行整体随机缩放;2)将9 张图像分别放置于尺寸相同的初始图像的9 个区域中;3)对每一张初始图像按照图中所示橙色分割线进行分割,并将9 个分属于不同图像的分割结果拼接为一张图像,原始图像缩放比例及分割线位置都为随机选取。在上述处理流程的基础上,使用随机擦除数据增强方法,并采用图像均值进行擦除区域填充。将上述针对数据处理策略统称为DAFS。

图7 Mosaic-9 数据增强示意图Fig.7 Schematic diagram of Mosaic-9 data augmentation
2 实验结果与分析
2.1 实验平台
硬件配置:CPU 为Intel®酷睿™i7-12700KF,GPU为GeForce RTX™3090,操作系统为Ubuntu 18.04 LTS。深度学习环境配置:深度学习框架PyTorch 版本为1.8.2 LTS,CUDA 版本为11.1,Python 版本为3.8。
2.2 实验数据集
本文利 用公开 数据集MaskedFace-Net[22]与PWMFD[23]组建实 验数据 集。PWMFD 数据集中包含3 个类别的口罩佩戴类型,共计9 205 张图像,但不规范佩戴口罩这一类别目标数仅为366 个,类别极度不均衡,而MaskedFace-Net 提出名为MTFDM(Mask-to-Face Deformable Model)的模型,用于根据已有人脸数据集生成佩戴口罩人脸图像,并基于FFHQ(Flickr-Faces-HQ)[24]构建包 含3 个类别共计133 783 张图像的人脸口罩数据集。
本文算法通过人脸关键点与口罩关键点匹配,从而获得包括正确佩戴口罩、未完全遮挡下巴、露出鼻子、露出嘴和鼻子等类别的数据,各类别关键点匹配示意如图8 所示。

图8 各类别关键点匹配示意图Fig.8 Schematic diagrams of matching each class of landmarks
为解决不规范佩戴口罩这一类别样本严重缺乏的问题,选取8 585 张类别为不规范佩戴的图像作为实验数据补充,并采用本文提出的DAFS 方法进行数据扩充,得到如表1 所示数据集。
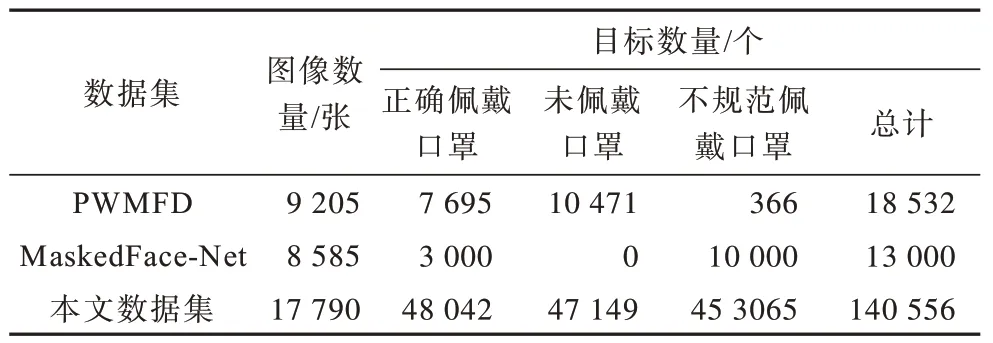
表1 实验数据集 Table 1 Experimental dataset
实验中并未以图片数量作为数据集划分的最小单位,而是以样本数量即图像中的目标数量作为依据,按照8∶1∶1 的比例将数据集划分为训练集、测试集、验证集,具体如表2 所示。

表2 数据集划分 Table 2 The partition of dataset
2.3 实验结果
为验证本文中所采用的各改进策略的有效性,设计消融实验进行验证研究,训练过程总共迭代300 个epoch,batch size 设置为32,使用SGD 优化器,在开始的3 个epoch 中使用warm up 调整学习率,初始学习率设置为0.001,momentum 设为0.937,MDDC-YOLO 训练结果如图9 所示,消融实验结果如表3 所示。
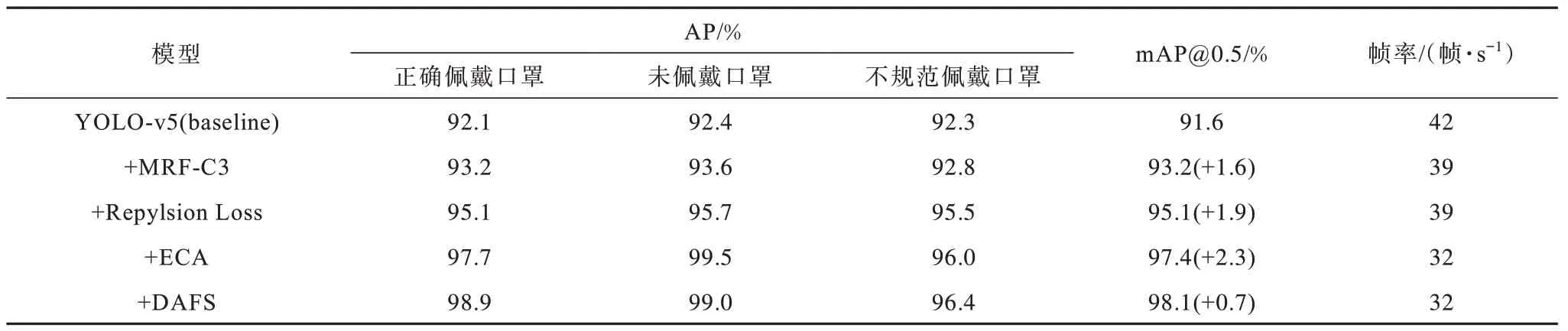
表3 消融实验结果 Table 3 The result of ablation experiment
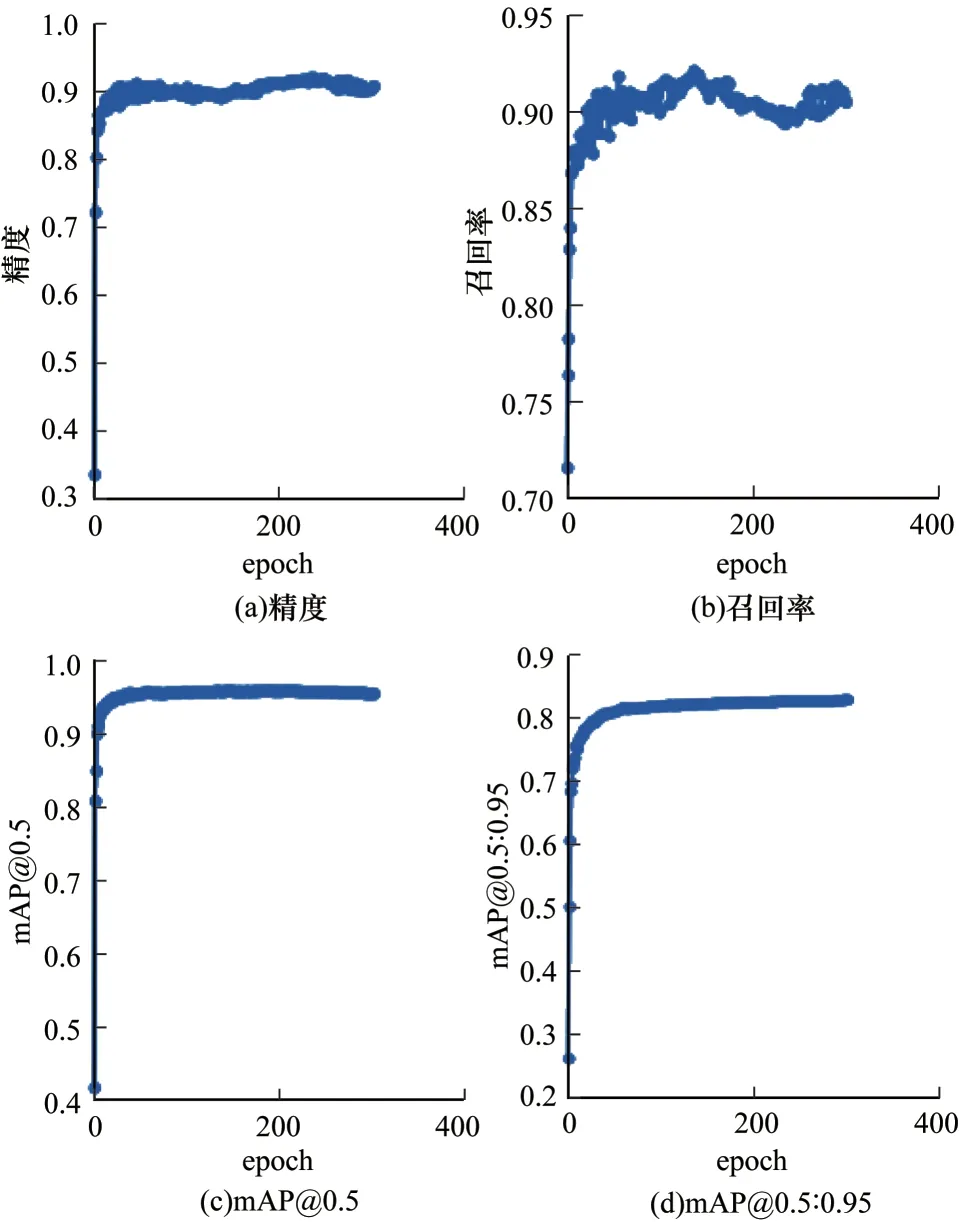
图9 训练结果Fig.9 Train results
与YOLO-v5(baseline)相比,在骨干网络CSPDark Net53中嵌入多分支感受野模块MRF-C3 后,模型以牺牲帧率为代价获得1.6 个百分点mAP 的提升,通过替换边界框损失函数为Repulsion Loss 后模型获得1.9 个百分点mAP 的提升,这来源于目标密集分布场景下,该损失函数使得训练过程中遮挡正样本得到充分利用。引入ECA 注意力机制后可使特征通道权重化,模型能够快速准确提取不同重要性的特征信息,最后使用透视变换、随机擦除等离线数据增强策略,增加了目标多角度样本,并在Mosaic-9 及随机擦除的增强下,获得0.7 个百分点mAP 的提升,并最终将帧率保持在32 帧/s,从而满足算法实时性应用的需求。
为比较MDDC-YOLO 算法与目标检测领域常见算法在监控视角下密集人群口罩佩戴检测这一任务上的优劣,本文进一步设计对比实验进行研究,实验结果如表4和表5所示,其中加粗数据为最优数据。

表4 对比实验结果 Table 4 The result of comparative experiment

表5 与其他YOLO-v5 改进模型对比实验结果 Table 5 The result of comparative experiment with others model improved base YOLO-v5
表4 数据表明,本文提出的MDDC-YOLO 算法达到了98.1%的mAP,相比本文所选择的基础算法YOLO-v5,mAP 获得6.5 个百分点的提升,同时仅使帧率由42 帧/s 下降至32 帧/s,而目标检测领域中将检测器检测帧率是否大于30 帧/s 作为判断检测器实时与否的标准,故本文所提出算法仍属于实时检测器的范畴;表5 对比中以YOLO-v5 为基础改进的几个模型,虽能够在通用目标检测上取得优异的性能表现,但面对本文所针对监控视角下人群密集分布场景时,均出现一定程度的精度丢失,无法满足密集人群高风险公共场所视频监控这一应用场景的要求。
为直观展示检测效果,实验最后给出可视化检测效果,如图10、图11 所示,其中边界框颜色蓝、黄、红分别对应正确佩戴口罩、不规范佩戴口罩、未佩戴 口罩等3 个类别,图10(a)、图10(c)和图11(a)为监控视角下密集人群图像原始图像。可以看出,针对正确佩戴口罩、不正确佩戴口罩、未佩戴口罩这3 个类别,面对透视畸变、侧脸、遮挡以及模糊等监控视角下的诸多问题,本文算法均能得到较好的检测效果。

图10 MDDC-YOLO 检测效果1Fig.10 Detection effect 1 of MDDC-YOLO

图11 MDDC-YOLO 检测效果2Fig.11 Detection effect 2 of MDDC-YOLO
3 结束语
基于改进YOLO-v5[29]通用目标检测算法,本文提出一种监控视角下密集人群口罩佩戴检测算法MDDC-YOLO。为应对监控视角下小目标检测的难点,提出基于空洞卷积的多分支感受野模块MRF-C3,并将其嵌入YOLO-v5 骨干网络中,然后采用Repulsion Loss 提升目标密集分布情况下模型的抗遮挡能力。在此基础上,在YOLO-v5 特征聚合部分插入ECA 注意力模块,使得各通道间特征得到最优化选择,以提升模型检测精度。最后,提出采用透视变换及Mosaic-9 等数据增强策略,提升适用于监控视角密集人群口罩佩戴检测的样本数量。在一系列改进策略的支撑下,MDDC-YOLO 相较于YOLO-v5取得6.5 个百分点mAP 的提升,并最终使模型帧率保持在32 帧/s,相较于其他通用目标检测模型,体现出推理速度更快、检测精度更高的性能优势。本文在解决透视畸变时除采用离线数据增强之外,并未进行更多处理,所以透视角度过大时,存在口罩佩戴检测失准的情况。后续可进一步考虑引入小微型神经网络嵌入主模块中,针对透视变换矩阵进行学习,从而进行自适应的透视畸变矫正,以对抗真实应用场景中复杂的外部条件。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
中学生数理化·高一版(2021年2期)2021-03-19
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
作文大王·笑话大王(2019年3期)2019-04-22
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
汽车与新动力(2012年1期)2012-03-25
