
基于卷积神经网络的面料检索系统
2023-09-14 09:31王彪,毋涛
计算机技术与发展 2023年9期
王 彪,毋 涛
(西安工程大学 计算机科学学院,陕西 西安 710600)
0 引 言
近些年来,随着互联网经济的快速发展,电子商业也进入了蓬勃发展的阶段,消费者对于以纺织面料为原材料的商品,如服装、鞋等的需求量大大增加。面料生产企业为了能满足市场需求,不得不研究生产新的面料,这样也就导致市场上的面料种类越来越多,从而给面料生产企业带来了一个新的问题,即如何从种类繁杂的面料中快速、精准地检索到目标面料[1]。
传统的纺织企业在进行面料检索时,一般都是采取人工的方式进行。该方式不仅费时费力,检索结果还附带主观性的影响,不能达到用户对检索速度和准确度的要求[2]。市场上虽然存在成熟的图像检索方法和系统,但是由于面料图像的特殊性,并不适用于面料图像的检索需求,需要进行较大的改进。
在图像检索领域,主要存在两种技术:基于文本的图像检索(Text-Based Image Retrieval,TBIR)和基于内容的图像检索(Content-Based Image Retrieval,CBIR)[3-6]。TBIR,需要人为地对图像进行文本标注,具有效率低、查找不准的缺点。CBIR,提取图像的浅层视觉特征或深层语义特征,结合相似度度量方法,从数据库中检索出最为相似的top-k张图片,这是目前国内外研究的热点[7]。徐佳等人[8]提出一种基于全局和局部相位特征相融合的图像检索算法。王妙[9]提出基于深度学习的印花织物图像检索系统设计,采用哈希算法的粗检索和卷积神经网络的细致检索相结合的分级检索,在提高精度的基础上进一步提高了速度。Xia等人[10]提出的CNNH通过对相似度矩阵进行分解,得到样本的哈希码,再利用卷积神经网络对哈希码进行拟合。Lai等人[11]提出DNNH。该方法对网络结构做了针对性的设计:用部分连接取代全连接,引入分段量化函数。Zhang等人[12]提出的DRSCH用加权的汉明距离代替普通的汉明距离,这种方法可以提高计算距离的效率和精度,但是时间复杂度也会增加。Lin等人[13]在AlexNet的F7和F8之间加入一个全连接层,基于由粗到细的策略,利用学习到的类哈希二进制码和F7层特征,实现图片检索。该方法降低了特征匹配的计算量,加速了检索速度,但是不能保证哈希码相似的图像在语义上也相似,因此检索精度不高。何彬等人[1]提出了一种基于InceptionV3迁移学习的面料图像特征提取算法。该算法在Inception中加入哈希编码层,并优化了损失函数,将模型输出的哈希编码作为面料图像的特征向量,采用分级检索的策略进行检索。该方法虽然在精度和时间上优于一般的检索算法,但是由于采用的暴力检索策略,在速度上仍有较大的提升空间。刘瑞昊等[7]通过改进LresNet50E-IR网络结构,将其迁移学习到面料检索上,结合faiss进行面料图像检索可以取得很好的效果。但是算法采用的损失函数只能限制模型具有较好的分类效果,不能保证相似的面料图像的特征也相似。
该文主要针对目前面料图像检索领域存在的“找料慢”“找料难”等问题[14],通过结合深度学习和faiss向量检索解决以上问题,为纺织企业提供高效的面料管理策略。
1 面料检索系统框架
1.1 检索系统模块
面料图像的检索是以纺织企业的实际需求为依据,利用卷积神经网络对面料图像进行特征学习、表示和匹配,从面料数据库中检索出相似面料图像。系统分为模型训练、构建面料特征数据库和面料检索3个模块。模型训练是对VGG16[15]网络结构进行微调,同时优化损失函数,以企业提供的面料作为训练数据训练模型参数,以表达面料图像的特征;构建面料特征数据库是用训练好的模型提取面料特征,以向量的形式保存下来;面料检索是将待检索的面料和数据库中图像进行相似度匹配,排序输出检索结果。
1.2 检索整体流程
基于CNN的面料检索系统框架结构如图1所示。

图1 面料检索整体框架流程
该系统首先以企业提供的面料为训练集对模型进行训练,得到提取面料特征的模型,对所有的面料图形进行特征提取,将特征向量保存在本地作为特征向量库;然后将待检索的面料送到检索系统中,提取其特征,以余弦相似度作为特征向量之间相似度的度量,将相似度最高的top-k检索结果返回,完成一次检索过程。
2 相关工作
2.1 准备数据集
企业提供真实的面料样本,通过图像采集设备获得每一张面料的图像,一共有37 002张,部分面料图像见图2。根据不同纺织机机型,对面料进行批量的归类,一共分为10类,分别是12E、14E、16E、18E、20E、22E、24E、26E、28E、36E。按照8∶2的比例,将数据集划分为训练集和测试集,其大小分别是29 602和7 400。

图2 部分面料
在模型训练阶段,考虑到检索情景的多样性,提高模型的泛化能力,使检索系统具有较强的鲁棒性,对训练集进行随机水平翻转、随机颜色抖动等数据增强操作。
2.2 模型选择
面料特征的提取是整个面料检索系统最核心的环节。优秀的模型提取出的特征向量可以很好的表示图像,也是后续进行特征匹配的关键,所以模型选择至关重要[7]。
2.2.1 VGG16网络结构
VGG网络是2014年ImageNet大规模图像识别大赛的亚军,VGG16是其中的一类模型,常用于图像分类、目标检测和图像分割等任务,其结构如图3所示。VGG16一共有16层,包括卷积层、池化层和全连接层。
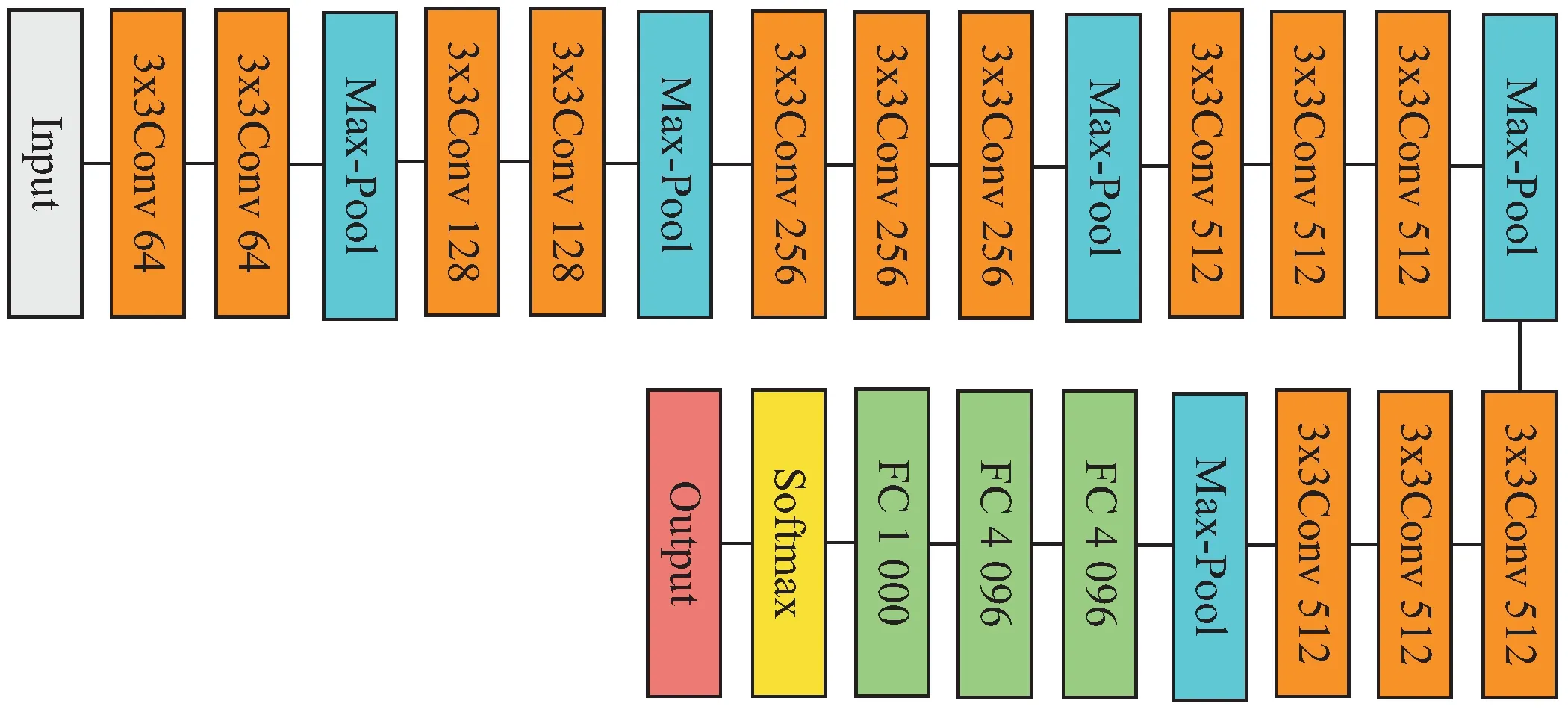
图3 VGG16网络结构
VGG16在卷积层采用3×3的小卷积核,减少了参数量,同时加快了模型的训练速度。在每个卷积层之后使用ReLU激活函数对特征图进行非线性映射以提高模型的表征能力。
池化层的池化窗口大小为2×2,步长为2,在不减少特征图数量的前提下,缩小了特征图的尺寸,压缩了参数量。
网络最后是3层全连接层,融合了卷积层提取的局部特征,表达了输入图像的全局特征。
2.2.2 改进VGG16
虽然使用3×3的卷积核减少了参数量,但是模型还是很复杂,有可能会出现过拟合的问题;在检索过程中计算两个面料的特征向量的相似度时,由于特征向量维度过高,带来较大的计算量;交叉熵损失函数是用来分类的损失函数,只能保证模型能够对图像进行正确的分类,不能让模型学习相似的面料图像的特征向量也相似。本面料检索系统以VGG16为基础网络,迁移学习其网络结构,对其做出以下改进:为了避免模型发生过拟合,提高模型的泛化能力,在卷积层之后,激活层之前加入BN层;为了减少检索过程中向量相似度计算的计算量,修改classifier部分的layer3的输出神经元数量为128个;为了使模型学习到相似面料图像的特征向量也相似,对损失函数进行优化:在原来分类损失函数的基础上加入相似度损失函数similarity。要计算相似度损失函数,首先要构建两个相似度矩阵A和B,然后再计算A和B对应位置元素差的平方和的均值。A和B,以及相似度损失函数的计算公式见式(1)、(3)、(4)。
(1)
式中,aij表示第i个特征向量xi和第j个特征向量xj的余弦相似度,计算公式见式(2)。
(2)

(3)
式中,bij仅有0和1两种取值。0表示向量xi和向量xj不属于同一种类别,即不相似;1表示两个特征向量属于同一种类别,即相似。
(4)
式中,n表示特征向量的数目。
2.3 模型训练
准备数据集、选择模型和构建损失函数这些前期工作做好后,下一步是训练模型。训练参数设置见表1。

表1 模型训练参数
在迭代80个epoch后,训练集和测试集的损失和准确率都已基本收敛,将此时的网络保存到本地作为构建特征数据库和检索时提取面料特征的模型。
2.4 基于faiss的图像检索
faiss是Meta(原Facebook)AI团队为了解决海量稠密向量的检索问题,结合高效相似度检索和聚类方法,提出的一种开源的相似度检索库[16]。例如,从给定的面料图像库中检索出与待检索的面料图像相似度最高的前K张图像,称为K近邻检索[17]。本研究借助faiss向量检索工具,为每一张面料图像的特征向量绑定一个唯一的索引,在损失极小的精度的情况下,大大提高了检索的速度。
3 对比实验
为证明文中方法的可行性,与多种图像检索算法进行对比。多特征融合方法结合了图像的形状、颜色和纹理3种特征,检索效果要优于单一的特征[18]。Inception_HashOP[1]通过在倒数第2层加入哈希编码层并优化损失函数,采取分级检索的策略进行图像检索。VGG19[15]相比于VGG16在结构上没有太大的区别,只是比VGG16多了三层卷积层。
3.1 评价指标
要比较这几种算法的性能,首先要确定统一的评价指标。该文采用图像检索领域常用的平均查准率(mAP)和检索一张面料平均消耗的时间T作为算法性能的评估指标。
查准率(Precision)是指一张面料图像经过检索,检索结果列表中与该图像相似的数量在检索结果列表中所占的比例[19]。Precision的计算公式见式(5)。
(5)
式中,TP是指检索到的相关面料,FP是指检索到的不相关面料。
平均查准率(Average Precision,AP)表示一张面料图像经过检索之后,检索结果列表中,每个召回率点上的查准率的均值。计算公式见式(6)。
(6)
式中,ri是指第i召回点,R表示检索结果中与检索面料相似的个数,P(ri)表示第i个召回点的查准率。
平均查准率均值(mAP)是多张查询面料的平均查准率的均值[20]。计算公式见式(7)。
(7)
式中,APi表示第i个查询面料的平均查准率,n表示查询面料的个数。
3.2 实验环境
模型训练是在服务器上进行。服务器CPU(E5-2678 v3)运行内存122 GB,GPU(RTX3090)显存为24 GB,使用Pytorch深度学习框架。
3.3 实验过程
从测试集中随机抽取100张面料图像,其余作为构建特征数据库的面料图像。当输入一张要查询面料图像,经过改进的vgg16模型提取查询面料图像128维的特征向量,计算其与特征数据库中的每一个面料的特征向量的余弦相似度,按相似度从高到低排序输出,然后根据输出结果计算平均查准率均值mAP。具体流程见图4。
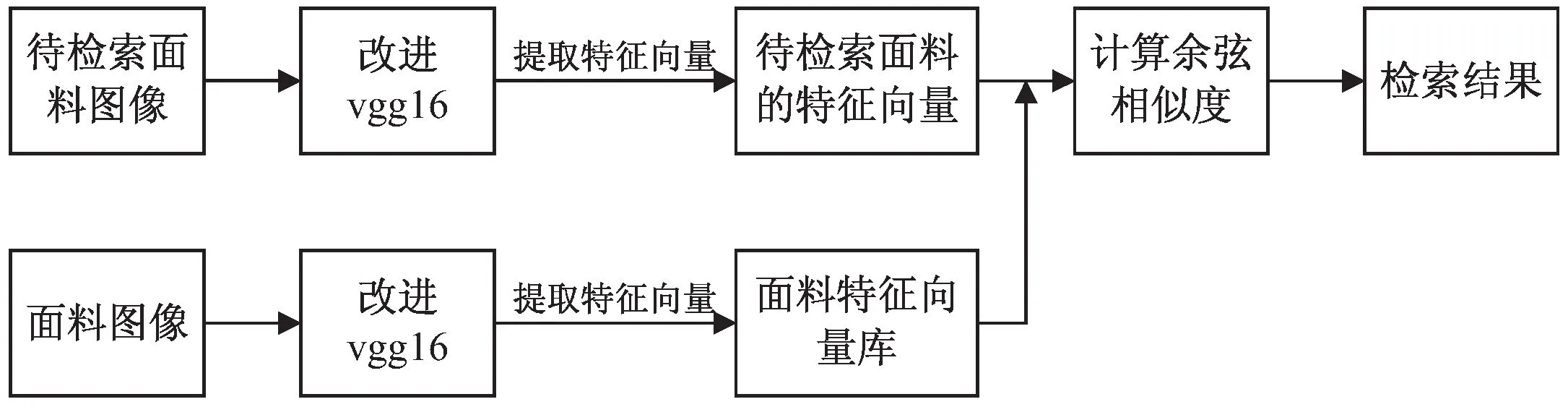
图4 实验流程
3.4 实验结果
表2展示了各种算法在mAP和检索时间上的对比。可以看出该文提出的方法无论是在平均查找率均值方面,还是在检索速度上都具有巨大的优势。其中,虽然Inception_HashOP和文中方法在mAP上相差不多,但是由于其在特征向量相似度计算时采取的是暴力遍历的方法,所以其检索速度远远低于文中方法;VGG19由于提取的特征向量维度较高,所以检索速度最低。
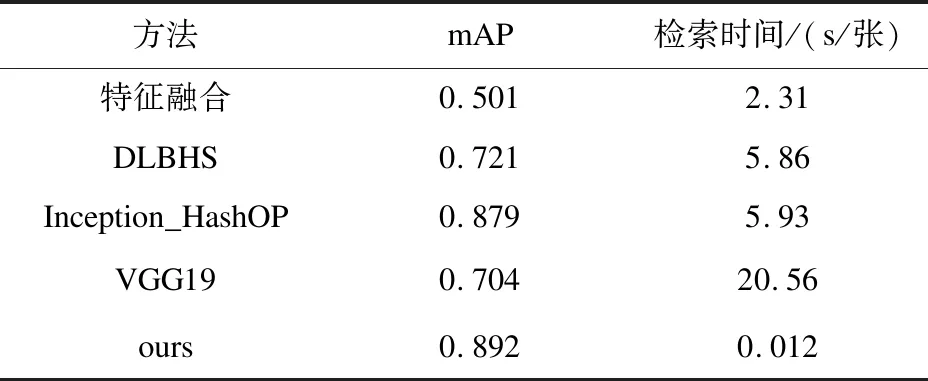
表2 不同算法对比
综上,提出的研究方法在企业面料数据集上同时具备检索速度快和检索精度高的特点,具有良好的检索性能。
4 检索系统
4.1 系统框架设计
面料图像检索系统基于web技术,主要由四个模块组成,分别是前端模块、后端模块、算法模块和数据库模块。如图5所示。其中前端模块主要负责面料图像的上传、接受/处理请求和展示面料图像检索的结果,后端模块主要负责整个面料图像检索系统的图像数据的输入与输出,算法模块主要负责对查询的面料图像的检索,面料图像特征数据库保存在MySql数据库中,数据库模块主要由Redis构成,主要负责存储面料图像及其相对应的id,便于前端模块的检索结果的展示。检索流程为:第1步,用户通过前端页面将待检索的面料图像上传至前端;第2步,前端将面料图像传输至后端;第3步,由后端对面料图像进行相关处理,将其输入至算法模块中;第4步,算法模块将检索结果的面料图像id返回至后端模块;第5步,后端将算法模块返回的检索结果id输入数据库模块;第6步,数据库将图片路由返回给后端;第7步,后端将图片路由和id返回给前端;第8步,前端模块接收后端模块返回的面料图像检索结果id和相对应的图片路由后,显示给用户。

图5 系统框架
4.2 系统实现
在面料检索的检索页面中,点击上传按钮上传要查询的面料图像,点击检索按钮,经过系统检索后,根据输入的检索数量N,系统的前端页面展示出N张最相似的面料的图像、id以及和查询面料的相似度。检索结果如图6所示。

图6 检索结果
5 结束语
该文提出一种基于卷积神经网络的面料检索系统,解决了企业面料检索速度慢、精度低的难题。通过微调VGG16网络结构,迁移学习到面料数据集上,利用CNN强大的表征能力,同时借助向量检索工具faiss进行特征向量检索,使得检索系统具有很好的性能。系统在面料图像上的mAP可达到0.892,检索时间仅为0.012秒,均优于以往的算法。该方法存在的缺点是,模型训练时间耗时长,当面料数据集更新时需要重新训练模型。因此,接下来可在现研究基础上进一步优化网络,降低模型训练的时间,提高检索系统的实用性。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
纺织服装流行趋势展望(2020年3期)2020-02-01
纺织服装流行趋势展望(2020年1期)2020-02-01
信号处理(2018年1期)2018-09-03
信号处理(2018年5期)2018-06-28
信号处理(2018年4期)2018-06-27
信号处理(2018年3期)2018-06-27
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
