
基于注意力机制和一致性损失的深度伪造人脸检测方法
2023-09-13 03:57范智贤程晴晴杨高明
湖北民族大学学报(自然科学版) 2023年3期
范智贤,程晴晴,杨高明*
(1.安徽理工大学 人工智能学院,安徽 淮南 232001;2.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
受益于生成技术的巨大成功,人脸伪造已经成为近年来新兴的热门研究课题。深度伪造(deepfake)技术能够生成高质量的假视频,合成人眼无法区分的逼真面部。由于使用门槛低,导致这些伪造技术很可能被恶意滥用,产生严重的安全和道德问题,损害个人声誉和国家政治安全。因此,开发更通用和实用的人脸伪造检测方法至关重要。当前大多数深度伪造人脸检测方法都是二分类模型,专注于如何构建复杂的特征提取器,以使用二分法区分出真假人脸,但是无法实现对于伪造区域的定位。
针对此问题,Nguyen等[1]提出了多任务学习检测伪造人脸方法,可以同时进行伪造人脸的分类以及伪造区域的定位,在多个任务中共享相关信息,促进学习。Dang等[2]提出用注意力机制来处理和改进分类任务的特征图,学习到的注意力图突出信息区域,通过可视化使被操纵的面部区域实现定位功能。这些方法可使网络更好、更全面地学到关于篡改区域的内在表示并取得了不错效果,但是过分关注训练数据集的伪造痕迹,很容易产生过拟合问题,导致在跨数据集的实验中准确率大大下降。对此,一些学者越来越关注网络模型在跨数据集中的实验效果,目的是提升模型的泛化性能。Masi等[3]提出基于两分支网络结构的深度伪造检测方法,一个分支用于传播原始人脸信息,另一个分支用于抑制人脸信息内容;并将时域、空域、频域信息进行融合,综合判断是否为伪造人脸,在虚假人脸检测的跨数据集方面有了一定的性能提升。Qian等[4]提出F3-Net检测方法,利用频率感知的分解图像向量和局部频率统计信息二者互补但不同频率感知的线索,提高了对特定压缩率视频的检测效果。Liu等[5]提出了基于相位谱信息提取的空域浅学习方法,结合空间图像和相位谱来捕获人脸伪造的上采样伪影,从相位谱中捕捉频域伪造痕迹,通过浅化网络来减少感受野,以抑制高级特征并专注于局部区域,实现了更为优越的迁移能力。
这些伪造人脸检测方法都取得了不错的效果,但仍存在不足之处,如模型容易对训练数据集中的图片产生过拟合,导致在新数据集上的检测效果降低,泛化性能不足;另外,大多数检测方法关注人脸图片的整体特征,缺少对伪造区域的细粒度特征提取。因此,提出基于注意力机制和一致性损失相结合的深度伪造人脸检测方法(method based on attention mechanism and consistency loss,MAMCL)。该模型使用注意力机制关注人脸的细粒度特征,提取人脸的细节区域;并使用基于注意力的擦除模块,对数据进行扩增,提升模型的精确度;再使用余弦相似度函数约束不同表示的一致性,提升模型的泛化性能。通过对比实验和消融实验,可以证明MAMCL模型的有效性。
1 MAMCL模型
基于注意力机制和一致性损失的深度伪造人脸检测模型架构如图1所示。由图1可知,MAMCL模型包括多注意力模块、双线性注意力池化(bilinear attention pooling,BAP)模块、基于注意力的擦除模块和一致性损失模块。

图1 基于注意力机制和一致性损失的深度伪造人脸检测方法的模型架构Fig.1 Model architecture of deepfake face detection method based on attention mechanism and consistency loss
1.1 多注意力模块
目前大多数伪造人脸检测方法都将伪造人脸检测视作二分类问题,首先使用主干网络提取全局特征,然后将特征输入分类器,判断真假。由于生成伪造人脸的技术在不断升级,真假人脸之间的差异通常在局部区域很难被单一注意结构网络捕捉到。因此,借鉴细粒度分类的思想,为在多个目标部位提取更具辨别性的局部特征,将注意力分解为多个区域,生成多张注意力图,能更有效地为深度伪造检测任务收集局部特征,迫使网络关注不同的局部信息。基于单注意力结构的网络可以将视频级标签作为训练的标准;与之不同,基于多注意力结构的网络由于缺乏区域级标签,只能以无监督或弱监督的方式进行训练。
首先通过卷积神经网络提取人脸I的特征,并将F(F∈RH×W×N)表示为特征图,其中H、W和N分别代表特征层的高度、宽度和通道数。人脸各部分的分布用注意力图A(A∈RH×W×M)表示,该注意力图由F得到。
(1)
其中,f(·)是卷积函数;AK(AK∈RH×W×M)代表第K个注意力图,对应某个特定的判别区域,如眼睛、嘴巴等;M是注意力图的数量。
MAMCL模型所使用的注意力模块如图2所示。由图2可知,它是轻量模型,由1个3×3卷积层(convolutional layer,Conv)、1个批归一化层(batch normalization layer,BN)、1个线性整流函数层(rectified linear unit layer,ReLU)组成。

图2 注意力模块Fig.2 Attention module
1.2 双线性注意力池化模块
用注意力图A表示人脸图像的各个部分之后,受到双线性池化的启发,采用BAP模块提取特征,该模块如图3所示。由图3可知,将特征图F与注意力图AK逐元素相乘,生成M个部分特征图FK。如果特征图和注意力图不匹配,需先使用双线性插值将注意力图调整到与特征图匹配的尺度。

图3 双线性注意力池化模块Fig.3 Bilinear attention pooling module
FK=AK⊙F(K=1,2,…,M),
(2)
其中,⊙表示逐元素相乘。
通过附加的特征提取函数g(·),即全局平均池化,进一步提取有区别的局部特征,以获得第K个注意特征,即
fK=g(FK),fK∈R1×N。
(3)
人脸的特征由部分特征矩阵组成,用Z(Z∈RM×N)表示,该矩阵由部分特征fK堆叠而成,采用Γ(F,A)表示特征图F和注意力图A之间的双线性注意力池化,可用式(4)表示:
(4)
1.3 基于注意力的擦除模块
为了缓解神经网络的过拟合问题,可引入一些基于擦除的方法进行数据增强操作,例如随机擦除、对抗擦除等,而MAMCL模型采用的是基于注意力的擦除。
随机擦除使用单个随机大小的矩形掩模在随机位置部分遮挡图像,使网络对单个遮挡具有鲁棒性。然而,由于缺乏有效监督,随机擦除不能有选择地删除伪迹,因而会导致过拟合,且随机擦除固有算法的缺陷是更倾向于擦除图像的中心区域。对抗擦除是有监督的方法,可以渐进地擦除有区别的对象区域。然而,对抗擦除中用于定位擦除区域的类激活映射是在网络最后的卷积层上计算所得,这可能会导致实际擦除区域与应该擦除区域不同。MAMCL模型使用基于注意力的擦除方法,如图4所示。由图4可知,将经过双线性注意力池化后的伪造人脸图片进行可视化,由此可以确定该模型侧重于哪块区域,然后遮挡敏感区域(即有可能发生篡改的部分),进行有目的擦除,将擦除过后的伪造人脸重新送入网络进行训练,鼓励模型深入挖掘之前忽略的区域。

图4 基于注意力的擦除模块Fig.4 Attention-based erasing module
1.4 一致性损失模块
虽然目前的卷积神经网络已经具备了可接受的性能,但是仍然存在过拟合问题。为了缓解此问题,引入一些数据增强方式。由于缺乏显式正则化,不同表示之间的一致性不太令人满意。为此,MAMCL模型明确限制了不同表示之间的一致性:首先捕获具有不同增强的不同表示,然后对表示的余弦距离进行正则化以增强一致性,迫使模型能够处理更多内在的伪造证据。
MAMCL模型重构了损失函数,同时使用交叉熵损失函数Lce和一致性损失函数Lcos作为模型的损失函数,总体损失函数为L=Lce+αLcos,其中,α是2种损失的平衡权重。
该模型使用标准交叉熵函数作为分类损失,即Lce=-[ylog2P+(1-y)log2(1-P)],其中,y是真实标签,真实人脸设为1,伪造人脸设为0;P表示真实人脸的预测概率;(1-P)表示伪造人脸的预测概率。
对于N对输入图像,分类损失可以写为
(5)
一致性损失用于惩罚从同一原始图像的不同视图中提取的表示向量的距离。MAMCL模型采用余弦相似度损失Lcos来惩罚2个表示向量之间的距离:
(6)
余弦相似度损失只是将向量的角度拉近,忽略了向量的范数。选择使用余弦相似性的原因是,它不会强迫不同视图的表示结果完全相同。例如,随机擦除在人脸上遮挡某个区域,使得2个视图中的信息不相同,在这种情况下,强制表示相同可能会损害学习的表示,因此,使用余弦相似度损失而不是L1或L2损失,能使2个向量的范数相同。
2 实验部分
2.1 相关数据集
主要用到了3个数据集,分别是面部取证++数据集(FaceForensics++,FF++)[6]、用于深度伪造取证的大规模具有挑战性数据集(a large-scale challenging dataset for deepfake forensics,Celeb-DF)[7]、深度伪造检测挑战数据集(deepfake detection challenge,DFDC)[8]。
FF++数据集于2019年发布,其中1000个真实视频来源于YouTube,而伪造数据是由4种伪造方法组成,即有4个子集,分别是:深度伪造(deep fakes,DF)、换表情伪造(face2face,F2F)、换脸伪造(face swap,FS)、神经纹理(neural textures,NT)。该数据集数据量大、伪造类型多,但合成的痕迹较为明显。FF++数据集有3个版本,分别是c0(无压缩)、c23(轻压缩)、c40(重压缩)。
Celeb-DF数据集于2019年发布,其中的590个真实视频来源于59位性别、年龄、种族各异的采访者,而伪造数据只采用了deepfake这一伪造技术,有5639个虚假伪造视频。该数据集将人脸的分辨率提升至256像素×256像素,人脸轮廓融合更好,边缘处的伪影更细微,在视觉上效果良好。
DFDC数据集于2020年发布,其中19154个真实视频是由全真实演员在全真实场景中所拍摄,99992个伪造视频是由多种伪造技术生成。该数据集的伪造方法高达8种,干扰手段高达19种,视觉效果好,检测较难。
2.2 实验设置
2.2.1 实验预处理 在预处理阶段使用开源计算机视觉库(open source computer vision library,OpenCV)将视频抽帧保存为图片,对训练集中的每个视频使用dlib工具包将人脸定位,按照1∶1.3的比例裁剪人脸。为了保证正负样本平衡,在FF++数据集中,每个真实人脸视频提取80帧,伪造人脸视频提取20帧。模型训练之前,先对人脸图片做预处理操作,将尺寸调整到299像素×299像素,使用水平翻转、高斯模糊等数据增强操作来扩充数据集。
2.2.2 数据划分和参数设置 根据FF++数据集的原始划分,按照72∶14∶14的设置依次划分为训练集、验证集、测试集。使用的模型是Xception网络,在ImageNet上加载预训练权值优化网络,使用Adam优化器,学习率设为0.0002,批量大小设为16,网络结构模型采用Pytorch框架实现。
2.3 评估指标
使用的评估指标为准确率和受试者工作特征曲线(receiver operating characteristic curve,ROC)的曲线下面积。准确率的计算公式如下所示:
(7)
其中,V表示模型对深度伪造人脸检测的准确率;STP表示真实人脸被预测成真实的数据;STN表示伪造人脸被预测成虚假的数据;SFP表示伪造人脸被预测成真实的数据;SFN表示真实人脸被预测成虚假的数据。用Q值表示ROC曲线下面积的大小,最小为0.5,最大为1,值越大表示效果越好。
3 结果与分析
3.1 与不同算法比较
首先在FF++数据集(c23版本)训练,并在此数据集上进行测试,再与目前几个比较经典的算法进行比较,评估指标为V和Q,结果如表1所示。由表1可知,MAMCL模型的准确率达到了96.38%,虽然尚未超越F3-Net的准确率,但Q值相比于F3-Net有所提升,综合来看,MAMCL模型具有一定优越性。

表1 不同算法下V、Q的性能评估Tab.1 Performance evaluation of V and Q under different algorithms
3.2 FF++数据集内检测
将MAMCL模型在FF++数据集(c23版本)的4个子集(DF、F2F、FS、NT)上分别进行对比实验,即在每个数据集上进行训练,并在训练的数据集上进行测试,得到各个模型的准确率,结果如表2所示。

表2 在4种不同伪造方法数据集上的V值评估Tab.2 V value evaluation on four different tampering method datasets
由表2可知,MAMCL模型在DF、F2F和FS子集上都达到了98%以上的准确率,在NT子集上准确率也达到了95%以上。该模型在FF++数据集(c23版本)的4个子集上都取得了最优的检测结果,具有良好的库内检测精度。
3.3 跨数据集检测
为了评估MAMCL模型的泛化性能,在FF++数据集上进行20轮训练,并在Celeb-DF数据集和DFDC数据集上进行测试。采取指标Q衡量不同模型在不同数据集上的泛化能力,实验结果如表3所示。由表3可知,MAMCL模型与一些最近的人脸伪造检测方法的Q值比较,在Celeb-DF数据集上获得了较先进的Q值,在DFDC数据集上虽然没有取得最优秀的Q值,但仍然具有良好的性能。在跨数据集检测中,不同的数据集使用的生成算法和种类并不完全一致,而且视频质量良莠不齐,导致检测模型的某些跨数据集检测效果不佳。
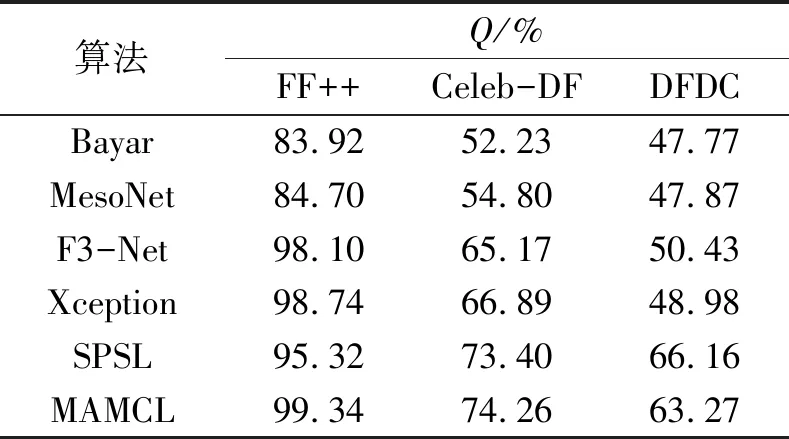
表3 在3种数据集上的跨域Q值评估Tab.3 Cross-domain Q value evaluation on three datasets
3.4 消融实验
为了测试MAMCL模型中各模块(多注意力模块、基于注意力的擦除模块、一致性损失模块)的有效性,在FF++数据集上进行消融实验,结果如表4所示。
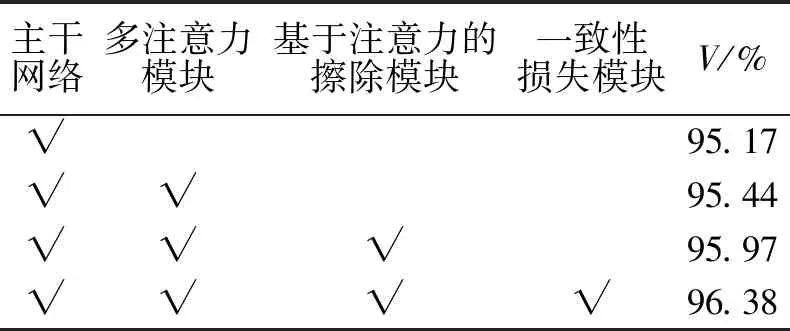
表4 在FF++数据集上的消融实验Tab.4 Ablation experimental results on FF++ datasets
由表4可知,未添加任何模块时,MAMCL模型所用的主干网络准确率为95.17%。仅使用多注意力模块时,准确率提高到95.44%,表明该模块能够使网络关注更多的细节部分,达到更好的检测效果。在同时使用多注意力模块和基于注意力的擦除模块时,相对于只使用多注意力模块,准确率提高到95.97%,表明基于注意力的擦除模块能使该模型关注到之前忽略的区域,检测效果得以提高。3个模块同时使用,相对于不使用一致性损失模块,准确率提高到96.38%。由此可知,MAMCL模型可以充分挖掘伪造信息,使模型关注到更细微的局部信息,处理更多的内在伪造证据,从而提高检测精度和泛化性能。
3.5 实验效果的可视化
为了直观地观测MAMCL模型效果,随机选取FF++数据集中的1张真实人脸,以及4张由不同伪造方法(DF、F2F、FS、NT)生成的伪造人脸,进行基于梯度的类激活图(gradient-weightedclassactivationmapping,Grad-CAM)[12]可视化处理,效果如图5所示;其中,图5(a)为原图,(b)(c)(d)(e)依次为4种伪造方式(DF、F2F、FS、NT)生成的伪造人脸。图5能直观地展现出MAMCL模型的网络架构侧重于哪块区域,即能对伪造区域实现定位功能,图中的高亮区域即为所检测出的伪造区域。由图5可知,原图为真实人脸,热力图中无高亮区域;而经过伪造方法生成的虚假人脸,其热力图中有明显的高亮区域,即MAMCL模型所检测出的经过篡改的伪造区域。

(a) 原图 (b) DF (c) F2F (d) FS (e)NT图5 4种换脸方法的热力图Fig.5 Heat map for four face-changing methods
4 结论
针对目前深度伪造人脸检测方法泛化性能不足的问题,提出基于注意力机制和一致性损失的深度伪造人脸(MAMCL)模型,该模型主要包括以下3个方面:1) 采用多注意力机制,生成多张注意力图,迫使网络捕捉到更细微的局部异常信息;2) 设计基于注意力的擦除模块,进行有目的擦除,可使模型深入挖掘之前忽略的区域;3) 设计一致性损失模块,约束不同表示的一致性,引导模型更加关注伪造细节,提高模型的泛化性能。结果表明,MAMCL模型在FF++数据集上获得了优秀的检测精度,在Celeb-DF和DFDC数据集上展现了良好的泛化性能。但是该方法仍然存在不足之处,例如针对不同分辨率的图片或视频,将其缩放到统一大小来处理时会丧失部分特征,导致模型的检测精度和泛化性能下降。因此,下一步研究将会从这一方面对模型进行改进。
猜你喜欢
公民与法治(2022年5期)2022-07-29
教学考试(高考物理)(2021年5期)2021-11-08
少儿美术·书法版(2021年9期)2021-10-20
中医眼耳鼻喉杂志(2021年1期)2021-07-22
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
动漫星空(2018年9期)2018-10-26
数学物理学报(2017年5期)2017-11-23
燕山大学学报(2015年4期)2015-12-25
发明与创新(2015年33期)2015-02-27
