
基于VDM-ISSA-LSSVM的云资源短期负载预测模型
2023-09-13 13:20:20杨哲兴谢晓兰李水旺
实验室研究与探索 2023年6期
杨哲兴, 谢晓兰,b, 李水旺,b
(桂林理工大学a.信息科学与工程学院;b.广西嵌入式技术与智能系统重点实验室,广西 桂林 541004)
0 引言
容器作为一种新型虚拟化技术,凭借其启动速度快、资源利用率高、可伸缩强等优点,极大地缓解了云计算中数据处理和运算压力,已经成为云计算应用和服务软件开发的轻量级解决方案。随着云计算平台的不断扩展,大量的请求被同步提交给云平台,资源需求量的增加会导致容器容易面临突发负载的压力[2],使得云平台变得不稳定。通过容器云资源负载的有效预测可促进应用的主动调度或容器负载平衡决策,对确保服务质量(QoS)与用户的服务水平协议(sla)至关重要。
短期云资源负载数据具有明显的非线性、随机性和不稳定性[2],有效地捕捉云资源负载的线性和非线性相关性,并准确预测未来的云资源负载变化,是一个极具挑战性的研究难题。
目前,关于云资源负载预测的研究还较少,在以往传统研究中常采用时间序列预测模型,如自回归、移动平均、自回归移动平均。考虑到短期云资源负载数据明显的非线性和非平稳特性,时间序列模型相对不具有较好的适用性。文献[3]中指出,机器学习模型比时间序列预测模型具有更好的泛化能力和映射能力,能更高效地处理非线性负载数据。文献[4]中针对传统时间序列预测模型在面对小样本、非线性云资源负载数据时预测精度不高,建立支持向量机(Support Vector Machine,SVM)的负载预测模型,验证SVM 预测模型在负载预测中的精度比传统时间序列方法高、均方误差更小等优点。但SVM 求解复杂且计算较为耗时。针对SVM的弱点,文献[5]中提出一种基于最小二乘支持向量机(Least Squares Support Vector Machine,LSSVM)的预测模型,通过二次规划法实现不等式约束与等式约束的转化,降低模型计算难度,有效提高预测的准确率。LSSVM 因其优越性,近年来已被广泛应于多个预测领域[6]。
机器学习模型参数对云资源负载的预测效果有很大影响。如何选择最优参数是机器学习模型的核心。文献[9]中采用灰狼优化算法(Grey Wolf Optimizer,GWO)对SVM参数进行寻优,针对标准GWO 算法易陷入局部最优解,引入种群动态进化算子增强其获得全局最优解的概率,提高了云资源短期负载预测的精确性。文献[10]中采用鲸鱼算法(Whale Optimization Algorithm,WOA)来优化LSSVM 参数,提出一种WOA-LSSVM负荷预测模型,提升模型收敛速度和预测精度。
上述学者的研究虽然都在提高预测精度取得了成果,但都没考虑原始云资源负载数据非线性、非平稳性等特点。就此,文献[11]中采用经验模态分解(Empirical Mode Decomposition,EMD)将负载数据分解为互不耦合的IMF分量,降低负载数据的非线性程度。文献[12]中采用小波变换把时间序列分解为不同时间频率的子序列,来降低原始云负载数据的复杂性。但EMD容易出现模态分量混叠[13]和小波变换存在分解层数难以确定等缺点,这些都会导致预测精度的下降。针对上述问题,文献[14]中采用变分模态分解(Variational Mode Decomposition,VDM),来替代EMD或小波变换等方法来处理原始数据,它克服了EMD方法中模态分量混叠,分解效果更优。
标准麻雀搜索算法(Sparrow Search Algorithm,SSA)新颖,性能较好,但存在迭代后期种群多样性降低、容易陷入局部最优等[15]。在上述背景基础上,本文提出一种基于VMD 算法与改进麻雀搜索算法(Improved Sparrow Search Algorithm,ISSA)优化的LSSVM云资源短期负载预测模型。该模型使用VMD算法将原始云资源负载数据分解成多个不同的模态分量,增强数据序列的平稳性;采用ISSA对LSSVM进行参数寻优;建立VMD-ISSA-LSSVM模型分别预测各模态分量,叠加得到最终的预测值并和其他5 个模型比较,验证该模型对云资源短期负载预测的准确性。
1 变分模态分解
VMD为一种自适应非递归时频信号分解算法,主要由变分问题的构造和求解两步组成。
1.1 变分问题的构造
设原始云资源负载序列为f(t),经过分解后得到K个模态分量
式中:φk(t)为非递减的相位函数;Ak(t)为包络函数,k=1,2,…,n。
步骤1采用希尔伯特变换获得各模态分量的单边频谱,同时设模态中心频率为ωk,加入指数项e-jωkt,将各模态的频谱转换到基带,得到移频后的频谱
步骤2利用高斯平滑度对宽度进行估算,并引入约束条件,求解各模态估计宽度之和的最小值,约束变分模型
1.2 变分问题求解
步骤1引入增广拉格朗日函数,将式(3)重构为非约束性变分问题,即:
式中:α为二次惩罚因子,可使信号重构时有较高精确度;λ为拉格朗日乘法算子。
步骤2用交替方向乘子方法,交替更新uk、ωk和λ,对式(4)中的鞍点进行求解,得模态分量uk和中心频率ωk的迭代求解公式:
2 最小二乘支持向量机
LSSVM模型的求解原理
式中:η为权重向量;φ(x)为非线性变换的映射函数;b为偏移量。
(2)利用结构风险最小化原理求解η、b。把函数拟合问题转化为优化
式中:ξi为误差变量;c为惩罚因子。
(3)建立拉格朗日方程对该优化问题进行求解
式中,αi为Lagrange乘子。
(4)根据KKT 条件和Mercer 条件,消去ω 和ξi后,可得LSSVM最终预测模型
式中,k(x,xi)为核函数,本文采用径向基函数作为核函数
式中,σ为核参数。
3 麻雀搜索算法及其改进
3.1 标准SSA算法
SSA算法是通过麻雀觅食行为提出的一种新的启发式种群优化算法,有较好的寻优性能。在寻优过程中,作为发现者的麻雀为种群提供搜索方向和区域,加入者麻雀根据发现者的指引进行搜索,侦查者麻雀则依靠反捕食策略避免种群陷入局部最优。
发现者的位置更新
式中:t、itermax分别为当前和最大迭代数;α∈Random(0,1];Q为在[0,1]正态分布的随机数;L为维度1 ×d的矩阵;R2为警戒值;ST为安全阈值。
加入者的位置更新
式中:Xp、XworstX分别为当前最优解和最差解;A为维度1 ×d的矩阵,且满足A+=AT(AAT)-1。
侦察者的位置更新
3.2 改进的SSA算法
3.2.1 Iterative映射初始化
传统SSA 算法,种群多样性较差。引入Iterative混沌映射初始化种群,降低随机化的初始种群对算法收敛的影响
式中:υ为控制参数,υ∈(0,1),本文设定υ =0.7;xn为第n次迭代后x的值。
取n=200 对Iterative 映射进行仿真,由图1 可知,经Iterative映射得到的种群分布相对均匀。
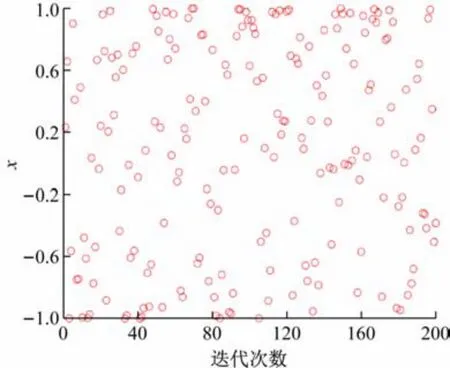
图1 Iterative分布
3.2.2 自适应权重因子
在标准SSA算法中,发现者会逐渐向全局最优解移动,易陷入局部最优解。权重因子对保持算法搜索能力的稳定起到重要作用。引入自适应权重因子
改进后的发现者位置更新
3.2.3 加入者位置改进策略
在迭代过程中,由式(14)可知,加入者和探索者会逐渐同化靠近最优解,使得种群的多样性快速下降,算法容易陷入局部最优。采用柯西分布对种群个体进行扰动,使算法能更好地脱离局部最优解。柯西分布概率密度
改进后加入者位置更新
3.2.4 侦查者非线性递减策略
侦查者的存在能够增强算法的寻优能力,其比例因子SD值会影响算法的寻优策略。SD 值越大越有利于算法前期的全局搜索,不利于算法后期的局部搜索。受文献[16]的启发,引入非线性递减策略来动态调整比例因子SD,使得SD 随着迭代次数动态下降。同时为保证算法的有效性,应避免出现SD为0。具体调整
式中:SDmax为最大比例因子;SDmin为最小比例因子。
3.3 ISSA算法性能分析
本文选取6 个基准测试函数来检验ISSA 算法的性能,测试函数的具体介绍见表1。

表1 基准测试函数具体介绍
在对比测试时,将本文所提ISSA 算法与SSA、WOA、GWO 3 种算法进行对比,为使测试结果更加客观,统一使用测试软件Matlab 2020b,4 种算法共有参数统一设置,种群数量设为30,最大迭代次数设为200。每个算法独立运行30 次,统计其最优值、平均值以及方差作为算法评价指标。各优化算法性能对比见表2。
分析表2 可知,对于高维单峰函数F1~F3,本文所提ISSA在寻优结果上明显优于其他3 种算法,虽然SSA在面对函数F1~F2也找到了最优值,但其平均值和方差均远低于ISSA。对于高维多峰函数F4~F6,SSA和ISSA都能稳定地寻找到最优值,并且性能都比GWO和WOA要出色。
为更直观对比算法的收敛精度和速度,图2(a)~(f)为各优化算法的收敛曲线对比。观察函数收敛曲线可知,ISSA 在收敛速度上均优于SSA、GWO 以及WOA。对于高维多峰函数F4~F6,ISSA 和SSA 均找到了全局最优解,但ISSA 的迭代速度远少于SSA 且曲线更光滑,说明ISSA 跳出局部最优解的能力更强,收敛速度更快。
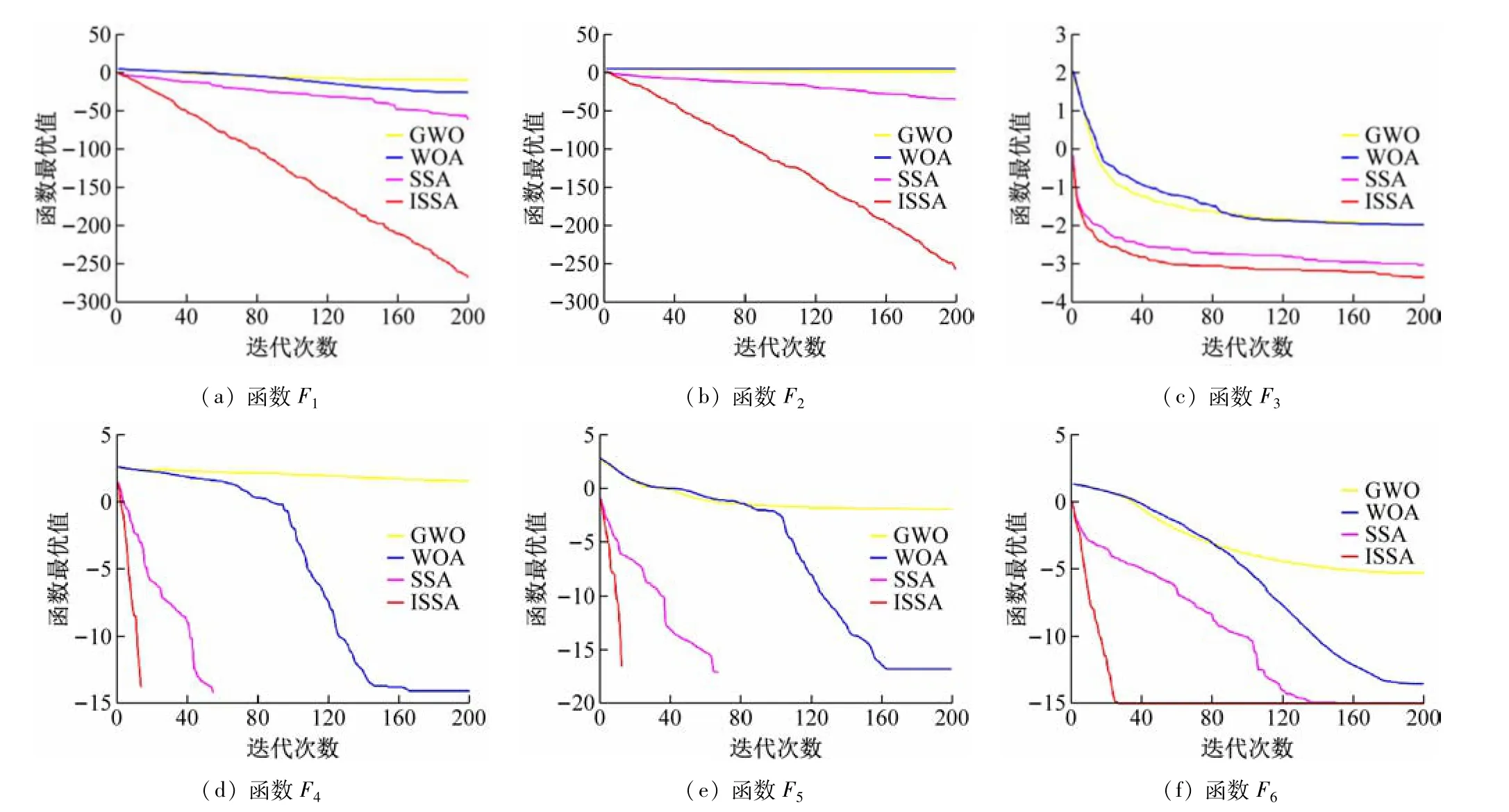
图2 各优化算法收敛曲线
4 VMD-ISSA-LSSVM预测模型
使用VMD 算法对云资源负载数据进行分解处理。采用ISSA算法对LSSVM的核函数宽度σ和惩罚因子c进行优化,提高预测精度。叠加各模态分量的预测值,获得云资源负载预测结果。建模流程如图3所示,具体步骤
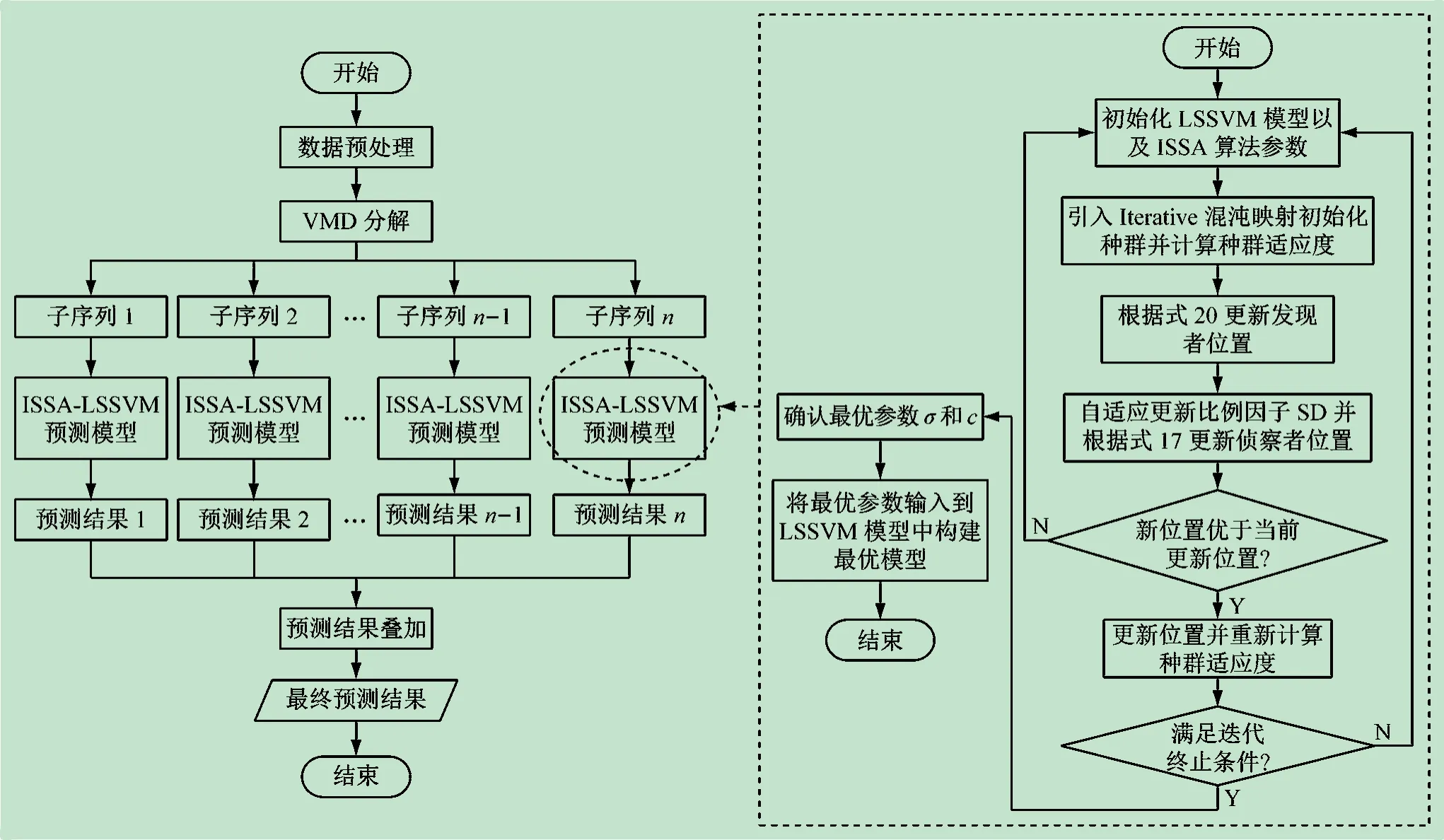
图3 VMD-ISSA-LSSVM建模流程图
步骤1对原始云资源负载数据线性化归算至[0,1]之间,归一化
步骤2利用VMD分解原始云资源负载数据。
步骤3对原始数据分解得到的每个分量,分别输入ISSA-LSSVM模型,采用改进麻雀搜索算法优化σ和c这两个重要参数,然后进行预测。
步骤4叠加各模态分量的预测结果,形成最终云资源负载预测结果。
ISSA算法优化LSSVM步骤如下:
步骤1对ISSA和LSSVM的参数进行初始化。
步骤2引入Iterative 混沌映射,利用式17 初始化种群,提高初始位置分布的均匀性。
步骤3计算麻雀适应度值,找出最优和最差适应度值,同时根据式(17)更新发现者位置。
步骤4根据式(19)对加入者的位置进行更新。
步骤5根据式(20)自适应更新侦察者比例因子SD,利用式(14)对侦察者位置进行更新。
步骤6重新计算各麻雀的适应度,判断新位置是否优于当前更新位置。
步骤7若新位置更优,则更新位置,反之重复步骤2。
步骤8判断迭代终止条件是否满足,若是,则确定最佳参数,将获得的最优参数输入到LSSVM中构建最优模型进行负载预测,反之重复步骤2。
5 实验与分析
5.1 数据来源
本文选取的数据集来自某网站2015-6-1 ~2015-6-30 每日24 h云计算资源负载数据[18],数据采样时间间隔为1 h,共720 个数据,云资源原始负载数据如图4 所示,选取前29 d 的数据为训练集,预测第30 d 的云资源负载数据。
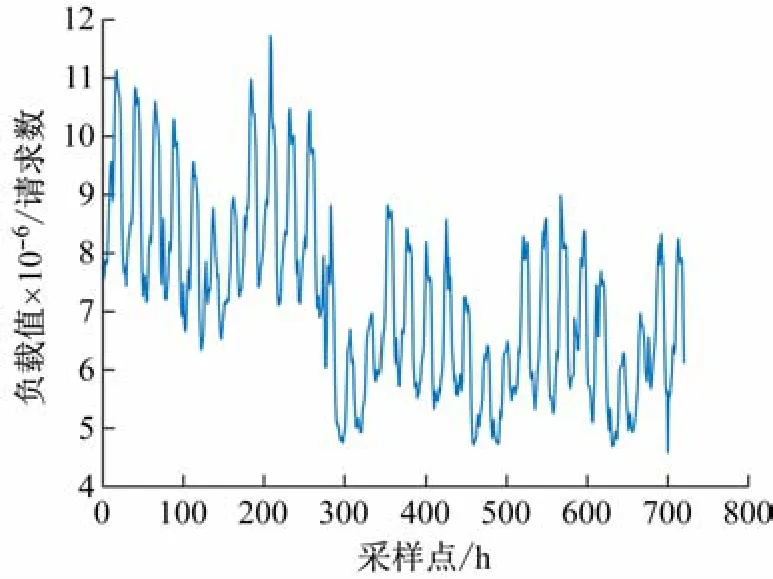
图4 云资源原始负载数据图
5.2 评价指标
本文设置均方根误差(Root Mean Squared Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)以及平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)作为客观评价预测精度的标准,三者的值越小,模型预测精度则越高
式中:n为预测样本容量;yi为云资源负载的实际值;y'i为云资源负载的预测值。
5.3 结果分析
由图4 可知,云资源负载数据有较强的非线性和非平稳性。首先对原始数据进行VMD分解,模态数K值的选取会对VMD 分解产生重要影响,当模态数K值过小或过大时,原始信号会出现模态异构或由于相邻模态分量的中心频率过于接近,导致模态重复,影响预测效果,需通过分析不同模态数下中心频率来选择合适的K值。各K值对应的中心频率见表3。
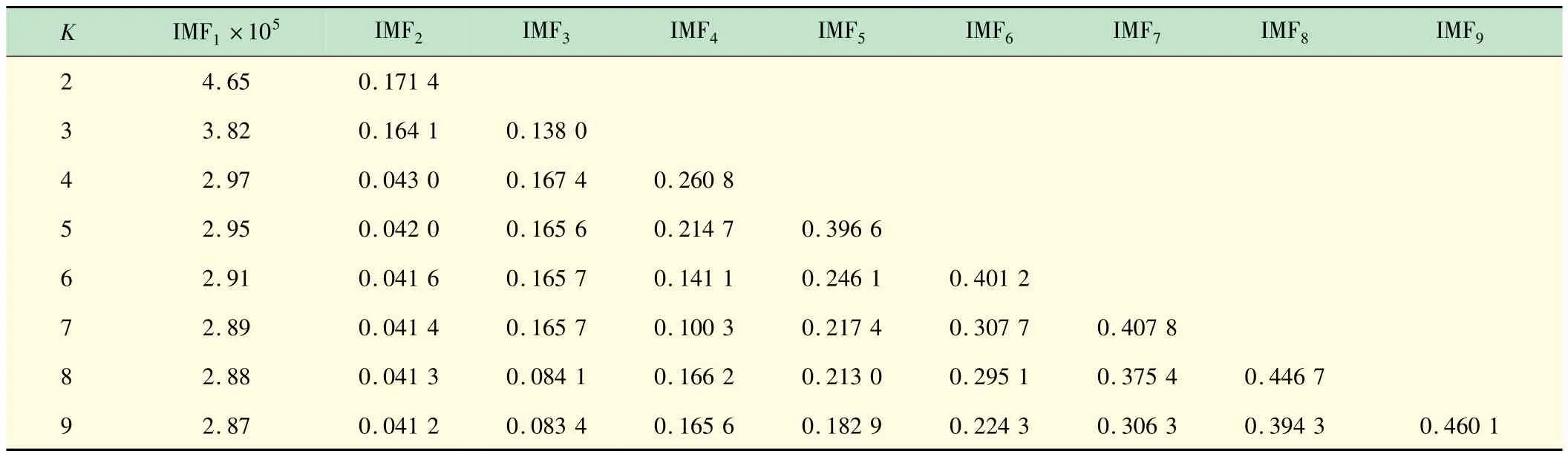
表3 K值对应的中心频率
分析表3 数据可得,随着分解模态个数的增加各模态分量的中心频率差值逐渐变小,当K>7 时相邻模态分量间的差值过于偏小,开始出现模态重叠现象,本文将K设为7;惩罚参数α =2000;噪声容忍t=0;初始中心频率init =1;收敛容差tol =10-7。VMD分解效果如图5 所示。
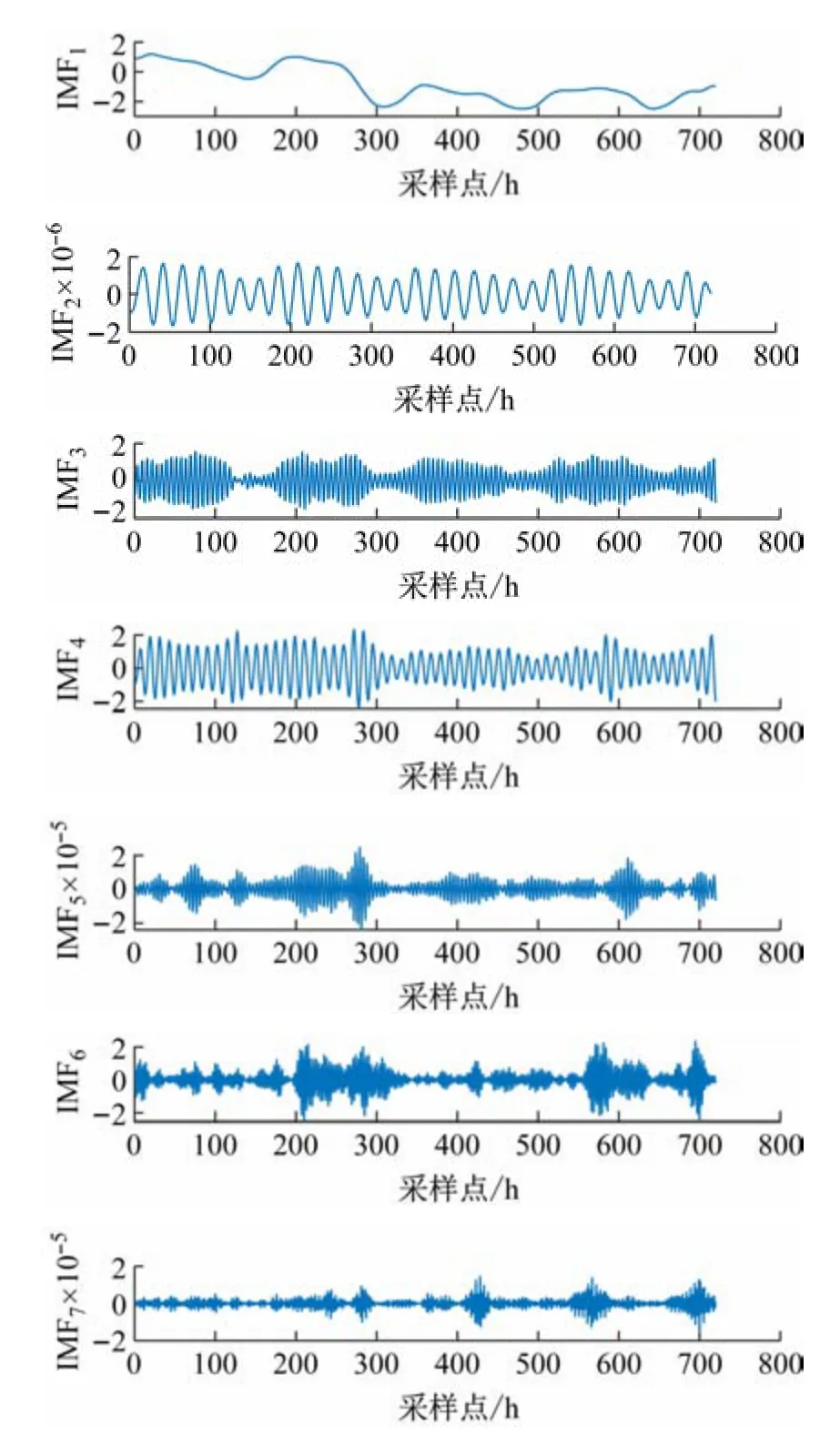
图5 VMD分解结果
将VMD 分解后获得的7 个模态分量分别输入ISSA-LSSVM预测模型,设定LSSVM 核函数宽度σ 和惩罚因子c的寻优范围为[0.1,1000],ISSA参数设置为:种群数量P=30,最大迭代次数M=50,预警值R2=0.8,发现者比例因子PD =0.2,跟随者比例因子SD为[0.2,0.1]非线性递减。采用ISSA算法优化LSSVM的核函数宽度σ 和惩罚因子c,优化后的参数为σ =2.2921,c=1.1604。
为进一步分析本文所提模型,选取2 种独立模型SVM、LSSVM 和3 种组合模型EMD-LSSVM、VMDLSSVM、ISSA-LSSVM进行对比实验。各模型可视化预测结果如图6 所示,各模型评价结果标准见表4。

表4 6 月各模型的评价结果

图6 6月各模型的可视化预测结果图
分析表4 数据可知,在单一模型中,SVM 和LSSVM均能大致预测云资源负载数据的变化趋势,且LSSVM的表现略优于SVM。与单一模型比,各组合模型的预测精度都得到了不同程度的提高。相较于EMD-LSSVM型、VMD-LSSVM模型的MAE、RMSE值和MAPE 值分别降低了57.64%、51.55%、59.89%,说明用VMD分解得到的云资源负载子序列更为平稳能更好地提高预测精度。对比LSSVM和ISSA-LSSVM模型,发现经过对模型关键参数进行寻优后,模型的MAE、RMSE 和MAPE 的值分别降低了43.97%、32.464%和48.51%,预测精度更高。在此基础上对原始数据进行VMD 分解后再分别输入ISSA-LSSVM模型进行预测,使预测精度得到了进一步的提升,其MAE、RMSE和MAPE的值均优于以上各个模型,预测效果表现最好。由以上分析可得,本文所提VMDISSA-LSSVM预测模型精度更高。
为检验本文所提模型的泛化性和稳定性,本文还选取了同年7 月云资源负载数据进行预测实验,实验结果如图7、表5 所示。

表5 7 月各模型的评价结果
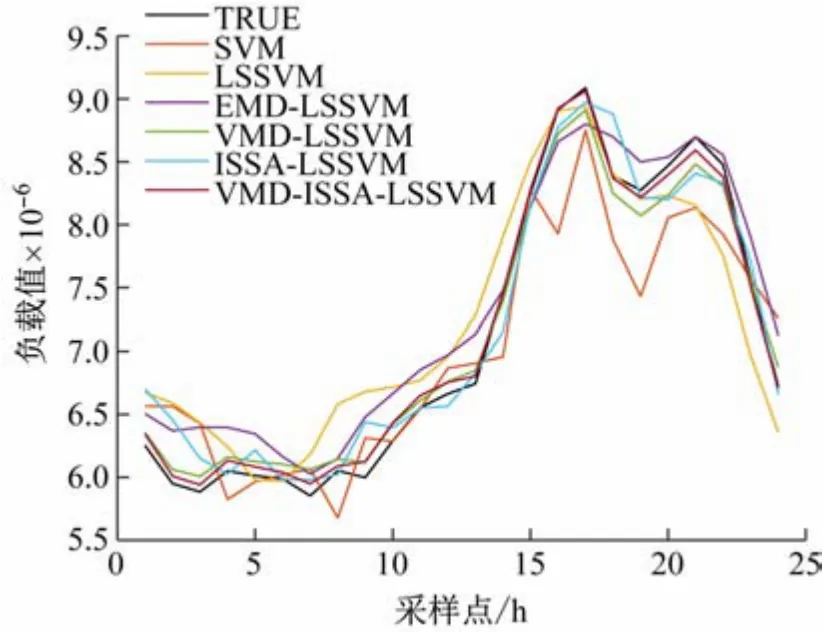
图7 7月各模型的可视化预测结果
分析表5 可知,VMD-ISSA-LSSVM 模型在MAE、RMSE以及MAPE 的值上均优于其他模型,预测精度最高。说明VMD-ISSA-LSSVM 模型针对非线性的云资源负载数据预测精度和稳定性较强。
6 结语
(1)针对云资源负载数据的非线性和非平稳性特点,提出VMD分解方法,将原始数据分解为平稳的模态分类,有效提高了预测精度。
(2)针对SSA种群多样性不足,容易陷入局部最优等缺陷,引入Iterative 映射初始化和自适应权重因子,并对加入者和侦查者的更新策略进行改进,进一步提高算法的收敛能力。通过仿真得出,ISSA能够减少迭代次数,加快算法收敛速度。采用ISSA 对LSSVM的关键参数进行优化后,模型的预测精度优于原始LSSVM模型。
(3)相对于参比模型,本文所提VMD-ISSALSSVM云资源负载预测模型在面对非线性和非平稳性云资源负载数据预测中精确度更高,对于提高云资源的优化效率,保障云服务质量有着积极意义。
猜你喜欢
学苑创造·A版(2025年2期)2025-01-14 00:00:00
今日农业(2022年15期)2022-09-20 06:54:16
电子制作(2018年11期)2018-08-04 03:25:38
测绘科学与工程(2016年5期)2016-04-17 06:51:15
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
电子设计工程(2015年3期)2015-02-27 12:03:45
计算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年14期)2014-02-27 14:11:53
当代畜禽养殖业(2014年10期)2014-02-27 07:59:49
