
基于低场核磁共振技术的植物油种类快速识别
2023-09-13 02:53史翠熠陈名扬杨国龙
食品科学 2023年16期
彭 丹,史翠熠,陈名扬,周 琪,杨国龙
(河南工业大学粮油食品学院,河南 郑州 450001)
植物油是我国食用油脂的主要来源,其消费量居全球首位[1]。食用植物油的种类繁多,不同植物油的产量、脂肪酸组成及营养物质互有不同,价格差异较大,以至于调和油市场上存在随意冠名、以次充好等问题[2]。对此,GB 2716—2018《植物油》中明确规定了调和油命名和标识,要求标明食用植物调和油的原料比例。然而,目前缺少对植物油掺伪,特别是植物油种类鉴别的有效方法,这不利于遏制市场上假冒伪劣的调和油,也给部门监管带来一定难度。因此,亟需开发一种准确、快速的植物油种类鉴别方法,以确保调和油的质量。
现有植物油种类鉴别方法主要有两大类:一类是根据植物油内部组成或特征性物质进行鉴别,如脂肪酸组成和含量[3]、甘三酯(triacylglycerol,TAG)结构[4]及芝麻酚、棉酚等特征标志物[5-6]。Li Xinhui等[7]采用气相色谱-质谱测定植物油的脂肪酸组成,结合化学计量学方法建立食用植物油的分类模型。Tang Fenfen等[8]基于脂肪酸和TAG组成信息对橄榄油品种进行分类。然而,油脂的种类差异及同种油脂的成分会受产地、加工工艺等因素影响而发生变化,单纯通过植物油某一特征指标很难得到整个油脂体系的准确信息,并且该法难以实现快速在线检测。另一类是利用光、电等间接方式采集信息进行鉴别,研究中多采用光谱法如紫外光谱、近红外光谱、中红外光谱、拉曼光谱和荧光光谱等[9-12]。近红外、中红外光谱法快速、无损,但易受到外界因素(如仪器、样品状态等)及测量条件的影响;拉曼光谱法研究目前还不够成熟,信号弱且仪器昂贵难以推广应用;紫外光谱法和荧光光谱法快速、检测成本低,但模型稳健性较差,有待进一步提升。低场核磁共振(low-field nuclear magnetic resonance,LF-NMR)技术作为新型无损检测技术,具有快速、简便、绿色等优点,在化学、食品、高分子材料等领域有越来越广泛的应用[13-18]。Romanel等[19]基于LF-NMR技术开发了一种汽油掺假检测的新方法。Miao Xuepei等[20]通过LF-NMR技术监测环氧涂料的性能变化。Wang Chen等[21]利用LF-NMR技术检测煎炸棕榈油中极性组分含量。然而,LF-NMR技术在油脂掺伪检测领域上的研究尚处于起步阶段。近年来,相关研究主要分为两方面:一方面通过检测固体脂肪含量(solid fat content,SFC)鉴别餐饮业废油的掺假问题[22],GB/T 31743—2015《动植物油脂 脉冲核磁共振法测定固体脂肪含量 直接法》也将LF-NMR技术作为SFC检测手段;另一方面利用横向弛豫时间T2的相关信息检测植物油掺假问题,现有的研究主要是基于弛豫时间变化规律分析植物油掺伪情况[23-25],对于检测基础理论研究较少。植物油是一种复杂体系,不同种类油脂的组成十分接近,仅用简单的规律分析或数学方法建立模型,无法对植物油掺伪鉴别起到理论指导作用。基于此,本实验系统研究植物油内部组成与低场核磁弛豫特性间的关系,采用LF-NMR技术结合化学计量方法对5 种植物油进行鉴别研究,旨为保障食用油的质量安全、有效维护食用油市场秩序提供技术支持。
1 材料与方法
1.1 材料与试剂
样品来源:河南郑州各大超市购买的不同产地、不同品牌、不同种类的植物油共5 类,分为菜籽油(11 种)、大豆油(15 种)、花生油(17 种)、葵花籽油(13 种)及玉米油(12 种)。对建模68 个样本按照3∶1比例,随机选择51 个样本作为训练集,其余为预测集。
正己烷(色谱纯)、甲醇钠、无水硫酸钠等,除特殊标记外,其余均为分析纯。
1.2 仪器与设备
8860气相色谱仪 美国Agilent公司;Mq 20 LF-NMR分析仪 德国Bruker公司;80-2型离心机 江苏科析仪器有限公司。
1.3 方法
1.3.1 脂肪酸组成分析
油样甲酯化具体方法参照GB 5009.168—2016《食品中脂肪酸的测定》。气相色谱条件:氢火焰离子化检测器;BPX-70色谱柱(30.0 m×250 μm,25.0 μm);进样口温度:250 ℃;柱温:170 ℃;检测器温度:300 ℃;分流比:20∶1;N2流速:1 mL/min;H2流速:30 mL/min;空气流速:400 mL/min;进样量:1 μL。
1.3.2 甘油酯含量测定
取35 mg油样溶于6 mL正己烷,加入无水硫酸钠去除水分,过滤膜后进入气相色谱仪进行测定。气相色谱条件:氢火焰离子化检测器;DB-1ht色谱柱(30.0 m×250 μm,0.1 μm);进样口温度350 ℃;柱箱初始温度100 ℃;升温程序:100 ℃保持1 min,50 ℃/min升至220 ℃保持2 min,15 ℃/min升至290 ℃保持2 min,40 ℃/min升至320 ℃保持6 min,20 ℃/min升至360 ℃保持8 min;检测器温度:350 ℃;分流比:10∶1;N2流速:4 mL/min;H2流速:40 mL/min;空气流速:300 mL/min;进样量:1 μL。
1.3.3 低场核磁回波衰减曲线测定及反演
准确量取3 mL样品于低场核磁专用试管内,经水浴恒温45 ℃后置于LF-NMR样品槽中,利用CPMG(Car-Purcell-Meiboom-Gill)脉冲序列测定样品的横向弛豫时间T2。
仪器参数设置:采样频率:200 kHz;扫描次数:8 次;循环延时:2 s;增益:50 dB;半回波时间:0.5 ms;回波个数:3000 个。每个样品重复测定3 次,取平均值作为样品的测定结果。
通过Matlab软件对低场核磁CPMG回波衰减数据进行反演拟合,得到样品的多组分弛豫图谱,包括弛豫时间T2i、峰面积S2i(i=1,2,…,n)及总峰面积S总。当样品作为一个整体进行反演时可得到样品的单组份弛豫时间T2W。
1.4 数据处理
利用SPSS软件对不同植物油的低场核磁弛豫特性进行差异显著性分析,对油样弛豫特性指标与其脂肪酸、甘油酯含量进行Pearson相关性分析。采用The Unscrambler X 10.4软件的主成分分析(principal component analysis,PCA)、线性判别分析(linear discriminant analysis,LDA)对低场核磁回波衰减曲线数据进行处理,并建立植物油种类鉴别模型。
PCA是一种有效的数据压缩和信息提取方法,通过线性变换,将高维数据空间投影到低维PC空间,用较少的变量代替原来的变量,且彼此之间互不相关[26]。
LDA是一种有监督的模式识别方法,将高维样本数据投影到最佳鉴别矢量空间上,投影后使同类别样本尽可能接近,而不同类别样本中心之间的距离尽可能大,从而达到分类目的[27]。样本在新空间中的类内离散度SW和类间离散度SB为:
式中:D为样品类别数;N为样本总数;Ni为第i类样本数;为样本总均值;xij为第i类样本的第j个样品;为第i类样本均值。常用的判别函数有线性判别函数(Linear)、二次判别函数(Quadratic)和马氏距离(Mahalanobis)。
2 结果与分析
2.1 不同种类植物油组成成分分析
由表1可知,5 种不同植物油的甘油酯组成及含量存在一定的差异,其中TAG含量均占90%以上,而甘二酯(diglyceride,DAG)、甘一酯(monoglyceride,MAG)含量相对较少,均低于5%。此外,植物油中还具有含量极少的磷脂、色素、甾醇等物质[28]。植物油作为一个复杂混合物体系,构成甘油酯的脂肪酸种类、碳链长度、不饱和度等对油脂的性质起着重要作用,仅通过植物油的甘油酯组成,很难全面反映不同种类油脂的特点,因此可以借助脂肪酸组成提高油脂种类的分辨率。从表2可以看出,5 种植物油的脂肪酸组成均符合国家标准(GB/T 1536—2021《菜籽油》、GB/T 1535—2017《大豆油》、GB/T 1534—2017《花生油》、GB/T 10464—2017《葵花籽油》及GB/T 19111—2017《玉米油》),不同种类植物油的主要脂肪酸组成基本一致,且油酸(C18:1)和亚油酸(C18:2)含量占总含量的72%以上。然而,受品种、气候等因素影响,不同植物油的脂肪酸含量存在一定的差异。其中,菜籽油和花生油的油酸含量相对较高,属于油酸型油脂;而大豆油、葵花籽油和玉米油的亚油酸含量均大于50%,属于亚油酸型油脂。相比于其他植物油,菜籽油中不仅含有芥酸(C22:1),还含有与大豆油中含量相当的亚麻酸(C18:3);花生油中花生酸(C20:0)、山嵛酸(C22:0)、木焦油酸(C24:0)等长碳链脂肪酸含量明显高于其他植物油。大豆油、葵花籽油和玉米油的多不饱和脂肪酸(polyunsaturated fatty acid,PUFA)含量远大于菜籽油和花生油。Prestes等[29]研究发现脂肪酸不饱和度越高,油脂黏度越小,相应弛豫时间越长。Lu Rongsheng[30]、夏义苗[31]等也研究表明LF-NMR弛豫图谱中弛豫时间与植物油的饱和脂肪酸(saturated fatty acid,SFA)含量有关。可见,5 种植物油(菜籽油、大豆油、花生油、葵花籽油及玉米油)的脂肪酸饱和度差异会引起弛豫特性的不同,这也为LF-NMR技术鉴别植物油种类提供了理论基础。
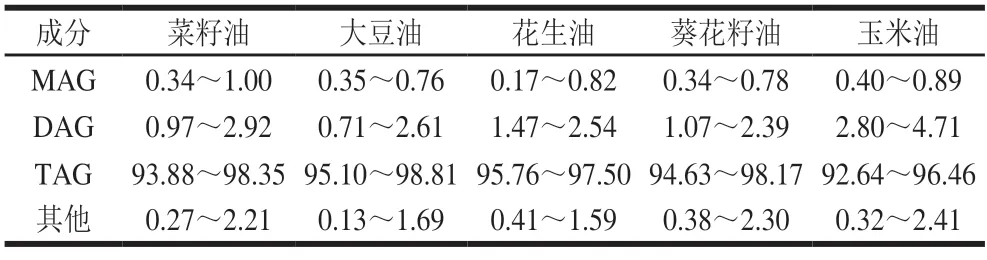
表1 不同种类植物油的主要成分及含量Table 1 Contents of major components in different vegetable oils%
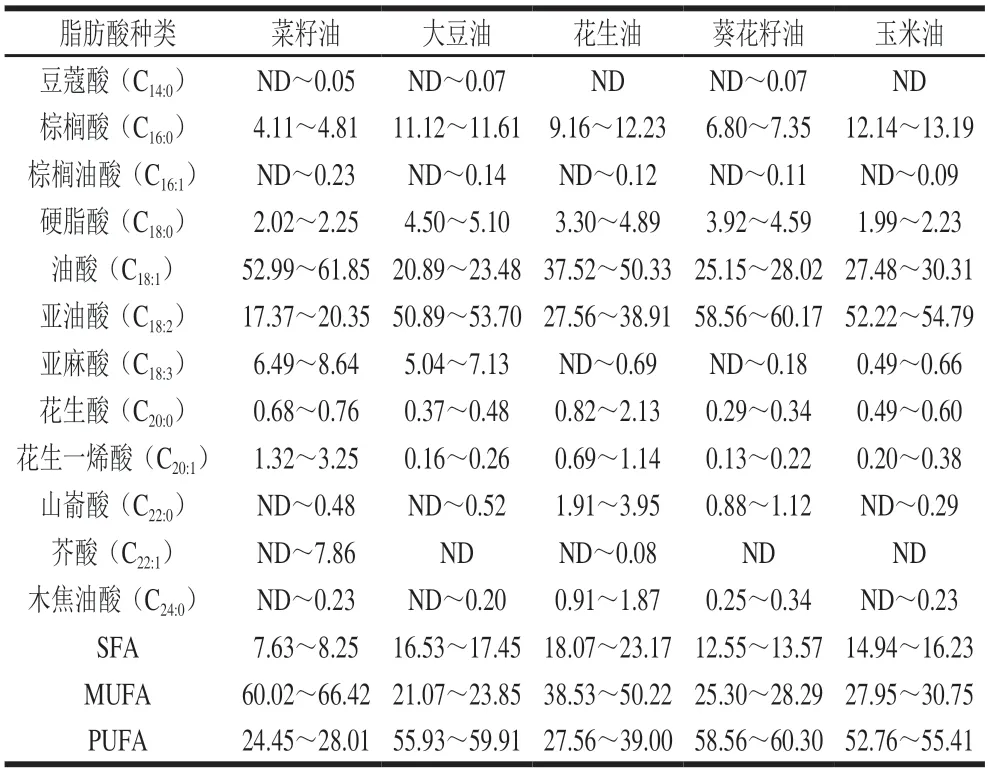
表2 不同种类植物油的脂肪酸组成分布Table 2 Fatty acid composition in different vegetable oils%
2.2 不同种类植物油弛豫图谱分析
对5 种植物油的低场核磁回波衰减曲线进行测定,其结果如图1所示。不同种类植物油的低场核磁回波曲线的整体衰减趋势一致,但其曲线衰减速率存在一定的差异,即花生油>菜籽油>玉米油>大豆油>葵花籽油。这可能与5 种植物油中脂肪酸碳链长度及不饱和度差异有关[32]。
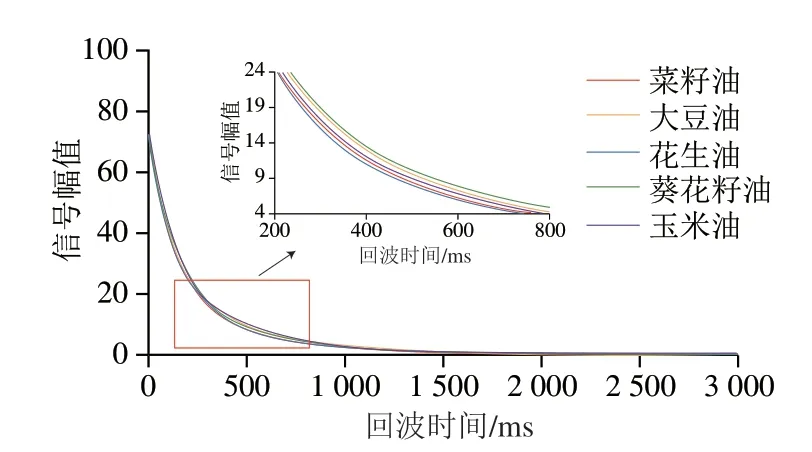
图1 不同种类植物油的低场核磁回波衰减曲线Fig.1 LF-NMR echo attenuation curves of different vegetable oils
为进一步研究植物油种类对回波衰减曲线的影响,通过反演拟合数据分析植物油种类与LF-NMR弛豫特性间的关系,结果如图2、3和表3所示。由图2可知,5 种植物油的多组分弛豫谱图中均存在T21、T22、T23三个响应峰,表明其均含有3 种不同状态的氢质子,T21所对应的峰面积S21最小,而峰面积S22、S23较大。5 种植物油以峰面积S23为评价指标,按峰面积由小到大排列依次为:花生油<菜籽油<玉米油<大豆油<葵花籽油;当以弛豫时间T2W为标准时,5 种植物油的弛豫时间顺序为:花生油<菜籽油<玉米油<大豆油<葵花籽油,与峰面积S23排列顺序相同。Berman等[33]研究发现,油酸和油酸甲酯形成不同的液晶状态会引起其弛豫时间和峰面积发生变化,表明脂质弛豫特性与内部结构和外部环境相关。对于菜籽油、大豆油、花生油、葵花籽油和玉米油5 种植物油来说,其内部甘油酯、脂肪酸组成及含量存在差异(表1、2),所以植物油种类改变会引起多组分弛豫谱图中弛豫时间和峰面积发生不同的变化。
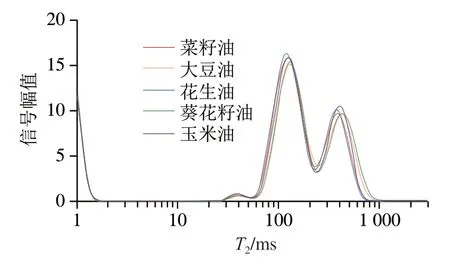
图2 不同种类植物油的横向弛豫图谱Fig.2 Transverse relaxation spectra s of different vegetable oils
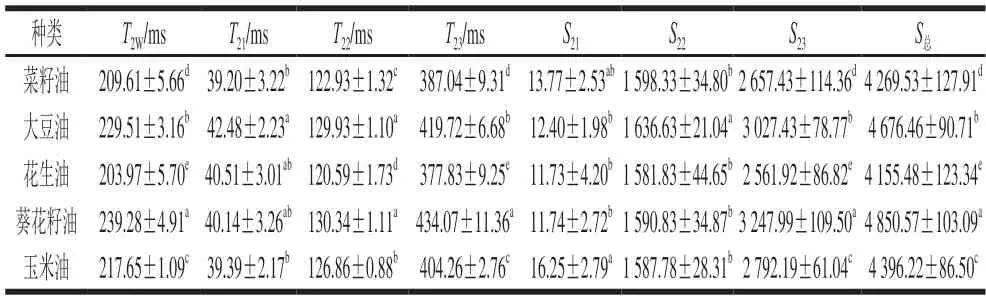
表3 不同种类植物油的LF-NMR弛豫特性指标结果Table 3 LF-NMR relaxation properties of different vegetable oils
通过SPSS软件对5 种不同植物油的弛豫特性指标进行显著性差异分析,从表3可以看出,5 种植物油的弛豫特性指标T2W、T23、S23和S总存在显著差异(P<0.05);相比之下,T21、S21和S22的差异较小。由图3可知,弛豫特性指标T2W、T22、T23、S23、S总与C18:1、C18:2、C20:0、单不饱和脂肪酸(monounsaturated fatty acid,MUFA)、PUFA含量存在极显著相关性(P<0.01),同时C18:0、C20:1、C22:0、C24:0、DAG和TAG也对弛豫特性有显著影响(P<0.05)。其中,C18:2、PUFA与弛豫特性指标显著正相关,而C18:1、C20:0、MUFA呈极显著负相关。可见,油脂内部的脂肪酸、甘油酯组成及含量差异是引起5 种植物油的多组分弛豫谱图存在差异的主要因素。因此,利用LF-NMR技术鉴别植物油品种有可行性。
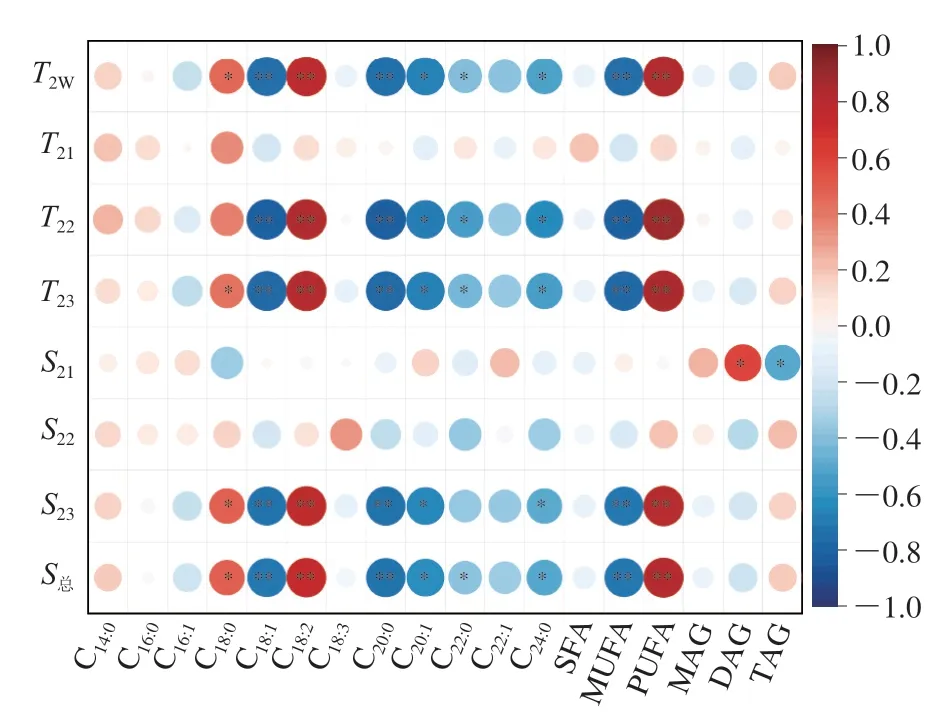
图3 植物油低场核磁弛豫特性与脂肪酸和甘油酯含量的相关性Fig.3 Correlation between LF-NMR relaxation properties and contents of fatty acids and glyceride in vegetable oils
2.3 PCA结果
采用PCA对5 种不同植物油的低场核磁回波衰减数据进行分析,结果如图4所示。前4 个PC的累计贡献率超过99%,保留了回波衰减曲线原始数据大部分信息。结合表2可以看出,5 种植物油在得分图中分布与其脂肪酸组成有着密切关系。大豆油和葵花籽油在PC1-PC2得分图上的分布较为接近,而玉米油、菜籽油和花生油的分布十分接近,甚至相互重叠;在PC3-PC4得分图上玉米油与菜籽油、花生油的分布距离相对较远,而菜籽油、葵花籽油和花生油的分布交错在一起,不存在明显边界。上述现象表明,PCA仅能鉴别出油酸型油脂(菜籽油和花生油)和亚油酸型油脂(大豆油、葵花籽油和玉米油),但对于5 种植物油的区分效果并不理想。
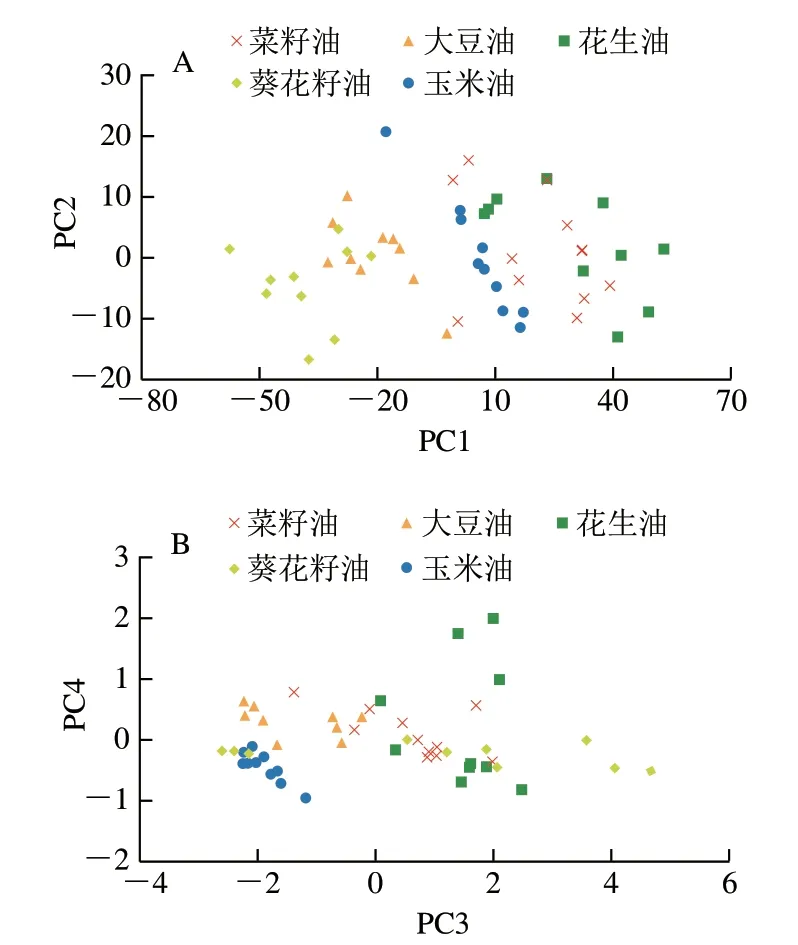
图4 不同种类植物油的PCAFig.4 PCA plots of different vegetable oils
2.4 PCA-LDA结果
建模数据会直接影响模型的预测能力和稳健性。建模数据筛选既可以简化模型,又可以剔除不相关或干扰信息,提高模型的泛化能力。本研究将油样回波衰减曲线的3000 个数据点,从弛豫时间上设定6 个不同数据段:1~500(500数据点)、1~1000(1000数据点)、1~1500(1500数据点)、1~2000(2000数据点)、1~2500(2500数据点)和1~3000(3000数据点),以Linear为判别函数,利用各数据段分别建立植物油种类鉴别模型,其结果如图5所示。以2000 个数据点为例(图5A),大豆油与葵花籽油较为接近,分布于图的左上方区域,菜籽油集中于图的右侧区域,玉米油位于图的中心区域,而花生油则分布于图的中下方区域。当数据点小于1500时,LDA模型的预测准确度均小于70%;而数据点超过2000以后,模型预测正确率不低于80%,且预测性能变化不大,因此选取样本数据点个数为2000 个。

图5 不同建模数据量对LDA模型性能的影响Fig.5 Effect of the number of input data on the performance of LDA model
为提高计算的简便性,采用PCA结合LDA法建立植物油种类的鉴别模型,通过交叉验证比较PC数和判别函数对模型性能的影响,如图6和表4所示。随着PC数的增加,3 种判别函数下LDA模型的分类准确率先增加后趋于平缓,PC数对3 种判别函数的模型性能影响程度依次为:Linear>Mahalanobis>Quadratic。以PC=4为例(表4),当判别函数为Linear时,花生油误判为菜籽油、葵花籽油误判为大豆油的样本比例较高,误判率分别为25%、20%;相比之下,当判别函数为Quadratic时,5 种植物油的正确识别率可达100%;若判别函数选择Mahalanobis时,仅有菜籽油被误判为花生油,其他4种植物油均能准确识别。综合考虑模型的稳定性和识别能力(图6),选择判别函数Linear、Quadratic和Mahalanobis的模型最佳PC数分别为10、4和7。
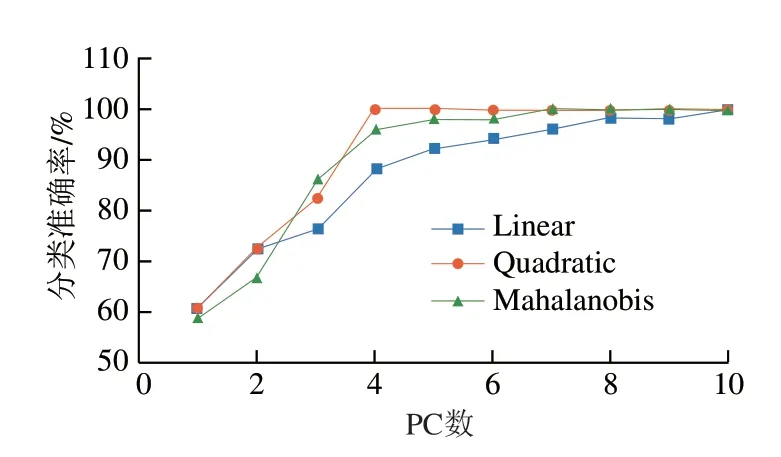
图6 PC数对LDA模型性能的影响Fig.6 Effect of the number of PCs on the performance of LDA model

表4 不同判别函数对LDA模型性能的影响(PC=4)Table 4 Effect of different discriminant functions on the performance of LDA model (PC=4)
选取17 个未知样品,对不同判别函数的PCA-LDA模型进行外部验证,以确定最佳判别函数及所建模型的预测能力,其结果见表5。判别函数为Linear和Quadratic时,PCA-LDA模型对植物油种类的鉴别效果要明显好于判别函数Mahalanobis的模型。当判别函数为Linear时,除葵花籽油外,其他4 种油脂种类均能准确识别,模型预测正确率为88.2%;而当判别函数为Quadratic时,虽然模型的识别率也为88.2%,但是葵花籽油、玉米油分别被错误分入大豆油、花生油中。综上,LF-NMR技术结合PCA-LDA快速识别植物油种类可行。然而,植物油因受产地、气候、加工工艺等因素影响而复杂多变,考虑到实际应用,为此还需要不断补充新样品对模型进行更新,从而提高模型的鉴别能力。
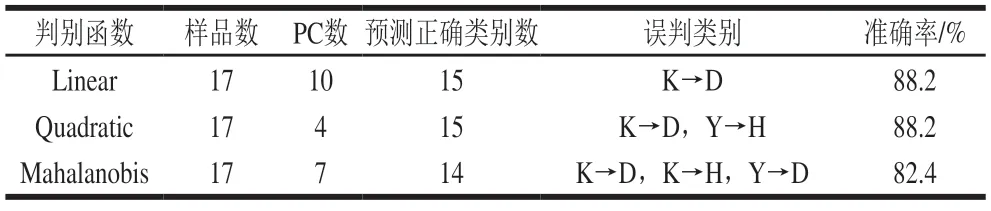
表5 植物油种类LDA模型预测结果Table 5 Prediction results of LDA model for vegetable oils
3 结论
LF-NMR技术作为一种快速无损检测方法,在油脂品质分析中具有广阔的应用前景。本研究对5 种植物油的弛豫图谱进行了系统分析,采用LF-NMR回波衰减曲线信息结合PCA-LDA,建立了植物油种类的鉴别模型。结果表明,5 种植物油的弛豫特性指标T2W、T23、S23和S总存在显著差异;PCA回波衰减曲线数据,有效降低数据维数和提取有用信息;PCA-LDA最佳建模条件为判别函数Linear、PC数10,其对未知油样种类的预测正确率达88%以上,因此采用LF-NMR技术鉴别植物油种类可行。然而,在实际应用中,植物油的种类多、类别杂,加之油料作物的改良,还需进一步增加建模样品的种类及数量,以提高模型的稳健性和预测能力。此外,LF-NMR技术起步较晚,信号处理方法仍待进一步完善。
猜你喜欢
商品与质量(2021年30期)2021-11-23
中国食品(2021年11期)2021-06-23
中国市场(2020年19期)2020-08-13
动漫界·幼教365(大班)(2019年10期)2019-10-28
中国特种设备安全(2019年5期)2019-07-16
中国科技纵横(2018年3期)2018-03-15
现代食品(2016年14期)2016-04-28
中国粮油学报(2016年1期)2016-02-06
海南热带海洋学院学报(2014年2期)2014-08-08
大众健康(2014年5期)2014-05-28
