
基于多尺度残差注意力网络的全色锐化方法
2023-09-13 12:53吴燕燕王亚杰谢延延
重庆理工大学学报(自然科学) 2023年8期
吴燕燕,王亚杰,谢延延
(沈阳航空航天大学 工程训练中心, 沈阳 110136)
0 引言
遥感图像全色锐化(pan-sharpening)是指将高空间分辨率的全色(panchromatic,PAN)图像与低空间分辨率的多光谱(low-resolution multi-spectral,LRMS)图像进行融合[1-2],以合理利用和整合星载全色多光谱图像信息,获得高空间分辨率多光谱图像(high spatial resolution multispectral images,HRMS),便于目标探测、土地覆盖分类及检测[3-4]。全色图像具有较高的空间分辨率,包含较多地理位置信息、纹理和边缘;多光谱图像具有丰富的光谱信息,能很好地对各种地物进行解译、分类,利用两者信息的互补性可以有效提高监测效率和改善视觉效果[5-6]。
遥感图像融合方法主要包括成分替换法(component substitution,CS)[7-9]、多分辨率分析法(multi-resolution analysis,MRA)[10-11]、模型优化法[12-14]、深度学习方法[15-16]。其中,基于深度学习的遥感图像融合算法是近年研究的热点。2016年,Masi等[17]开创性地提出了一种应用在遥感图像融合中的卷积神经网络方法(pansharpening by convolutional neural networks,PNN),该方法采用三层卷积神经网络(convolutional neural network,CNN)和一些辅助的非线性指数,将遥感图像融合当成一个端到端的问题,在不增加网络复杂性的同时提高了算法性能。之后,大量使用卷积神经网络的全色锐化方法被提出。2017年,Rao等[18]在CNN网络中加入了残差网络,改善了融合图像的光谱失真问题。2018年,Scarpa等[19]为了改进网络的性能,使得到的融合图像包含更多的信息,在CNN网络中加入了目标自适应函数。2020年,Liu等[20]提出了一种两流融合遥感图像融合方法,使用2个子网络分别提取LRMS和PAN图像的信息,并且在重建HRMS部分中加入了残差网络,既保留了大量光谱信息也提高了图像的清晰度。
然而,基于CNN的遥感图像融合方法大多使用相同的网络结构提取源图像的特征,或者是将源图像叠加后经过浅层卷积提取图像的特征,会导致融合后的图像存在光谱或空间信息丢失,因此多尺度卷积神经网络被提出[21]。此外,CNN网络中的所有通道被平等对待,不能灵活地判别通道之间不同频度的信息,而注意力机制网络被证实能够学习通道之间更深的相互依赖性[22-23]。
综上所述,提出了一种基于多尺度残差注意力网络的遥感图像全色锐化方法。先将LRMS图像经过双三次插值上采样,与PAN图像进行级联作为输入;设计3个不同的子网络并行提取源图像的高频和低频特征,每个网络中包含多个含有残差注意力机制的多尺度块,一方面,可以使用不同的卷积核提取多尺度特征,另一方面,可以自适应地考虑通道信息特征,使融合图像在包含较多光谱信息的同时保留更多的空间信息,处理过程包含浅层特征提取、深层特征提取、特征融合和特征重建;最后将3个子网络的输出结果进行级联得到最终融合图像。同时,将平均绝对误差(mean absolute error,MAE)、光谱角映射(spectral angle mapper,SAM)和几何梯度(geometric gradient,GG)作为一种新的损失函数来进行训练,进一步改善融合效果。
1 多尺度残差注意力网络
多尺度残差注意力网络主要包含4个部分:浅层特征提取层、深层特征提取层、特征融合层和特征重建层,网络框架如图1所示。
1) 浅层特征提取层
浅层特征提取层以三层卷积神经网络[24]为基础,提取输入图像不同频度的浅层特征,得到原始图像不同角度的浅层特征图。
2) 深层特征提取层
根据原始图像结构特点,使用不同数量的多尺度残差注意力模块(multi-scale residual attention,MRA)进行深层特征提取,充分提取原始图像不同频度上的空间和光谱特征,准确地表示特征并全面重建HRMS,每个MRA包括2个部分:多尺度特征提取网络和残差通道-空间注意力网络,结构如图2所示。
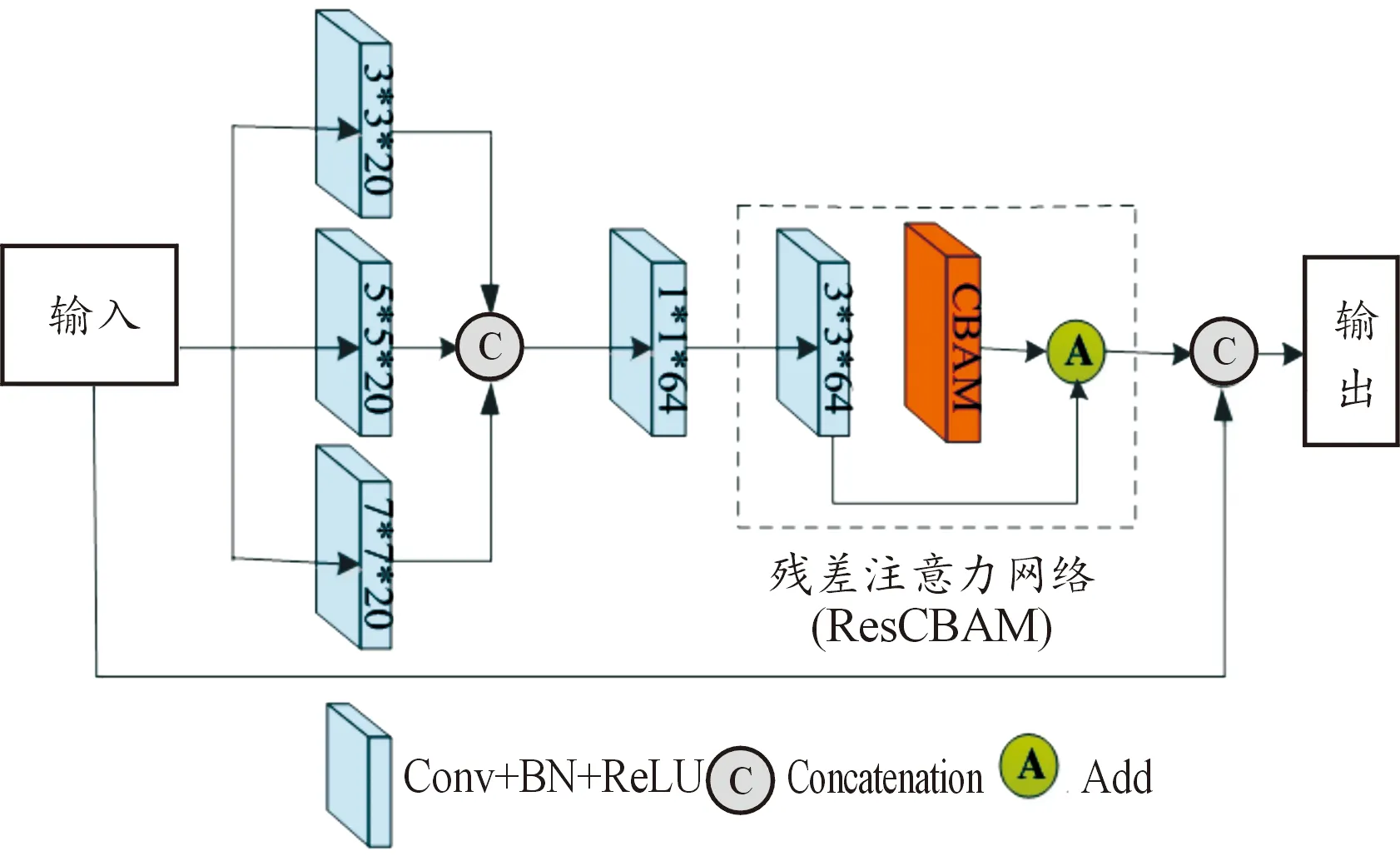
图2 MRA多尺度残差注意力模块
在多尺度特征提取网络部分,使用卷积核分别为3×3、5×5、7×7,步长为1,边界填充值为0的卷积神经网络提取输入的特征图中不同尺度的特征,每个尺度得到的特征数都是20。为了增强得到的特征,将多个尺度提取的特征进行级联,经过一个卷积核为1×1,步幅为1,边界填充值为0的卷积神经网络后,输出特征数为64。在残差注意力网络部分使用的注意力网络是一种通道-空间注意力联合的卷积锁注意力机制(convolutional block attention module,CBAM)网络[25],与其他的通道注意力网络和空间注意力网络相比,CBAM可以从通道和空间两方面学习和表示图像的特征。由于残差网络在计算机视觉和图像处理领域表现出了显著优越性,在使用CBAM注意力机制时,将CBAM和残差网络进行结合,用于保留更多重要的特征,如图2中虚框所示,并且为了防止过拟合和特征丢失,每个MRA网络中都使用了局部跳连接操作。
3) 特征融合层
特征融合层的任务是将多个MRA获得的特征数进行级联,并使用卷积神经网络将级联后的特征进行融合,减少参数量和保留更多重要的特征。
4) 特征重建层
在特征重建层,使用输出特征数为原始图像通道数的卷积神经网络获得包含不同频度特征的HRMS图像。
2 基于多尺度残差注意力网络的遥感图像融合
2.1 具体的融合过程
为了充分保留原始图像的空间信息和光谱信息,该算法使用了3个并行的多尺度残差注意力网络分别提取图像不同级别的特征,将这3个子网络分别表示为M1、M2、M3,其中M1提取输入图像的低频特征,M2和M3提取输入图像的高频特征,通过3个子网络输出结果的跳连接可以获得最终融合图像。基于多尺度残差注意力网络的遥感图像全色锐化过程如图3所示。

图3 基于多尺度残差注意力网络的遥感图像全色锐化
将LRMS图像经过双三次插值上采样后与PAN图像级联,得到一个5通道图像作为整个网络的输入,具体融合过程如下。
1)在浅层特征提取层,在M1、M2、M3中分别使用了卷积核为5×5、7×7、9×9,步长为1,边界填充值为0的卷积神经网络[26]实现浅层特征的提取,每个卷积神经网络提取的特征数都是64。
2)在深层特征提取层,考虑到参数爆炸的问题,在M1中使用了3个MRA,在M2中使用了2个MRA,在M3中使用了1个MRA。
3)在特征融合层,将多个MRA获得的特征数进行级联,在M1、M2、M3 3个子网络中分别使用卷积核为1×1,步长为1,边界填充值为0,输出特征数为32的卷积神经网络将级联后的特征进行融合,以减少参数量和保留更多重要特征。
4)在图像重建阶段,每个子网络中使用相同的卷积核为5×5,步长为1,边界填充值为0,输出特征数为4(原始LRMS上采样后的通道数)的卷积神经网络获得3个包含不同频度的融合图像。
5) 将每个子网络获得的不同频度的HRMS图像进行级联,获得最终的高空间分辨率多光谱图像。
为了防止训练过程中出现梯度爆炸和过拟合现象,整个网络除了最后一层5×5的卷积神经网络外,在每个卷积层的后面都加上了归一化层,并且每一个卷积层使用的激励函数都是Relu,由于残差学习的优越性,该算法使用了多个短跳过连接和长跳过连接,以减少空间和光谱损失。
2.2 多尺度残差注意力网络的损失函数
损失函数是为了衡量目标图像与生成图像之间的误差,为了更进一步改善图像融合的效果,减少目标图像与融合图像之间的差异,选择MAE、 SAM和GG作为损失函数来训练网络参数,与均方差(mean square error,MSE)相比,MAE收敛性能更好[26]。将参考图像表示为I、融合图像表示为F,所设计的损失函数如式(1)所示。
Lloss=αL1(I,F)+SAM(I,F)+βGG(I,F)
(1)
式中:L1表示MAE,其函数如式(2)所示,计算的是参考图像和融合图像之间的平均绝对误差值,在实际计算时,α和β的取值各为0.5。

(2)
式中:N表示图像的数量;|·|表示绝对值;In表示参考图像;Fn表示融合后的图像。
SAM是指目标图像与生成图像之间的光谱损失真度,计算的是在相同像素内融合图像和参考图像光谱向量之间的角度[27]。SAM的值与光谱失真度是正相关的关系,SAM越小,融合图像的光谱失真率越低,当SAM的值为0时,则表示融合图像没有出现光谱失真的问题,是最理想的融合结果。SAM的计算如式(3)所示,在损失函数中引入SAM函数能使融合的图像包含更多光谱信息。

(3)
几何梯度GG表示融合图像和参考图像的几何空间细节损失[28],用于改善融合图像的空间失真,如式(4)所示。
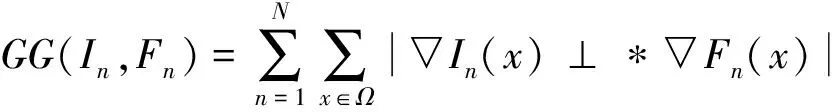
(4)
式中:N表示图像的数量;Ω表示图像的像素域;▽表示梯度计算。
3 实验结果与分析
3.1 数据集的制作与参数设置
为了验证该算法的有效性,采用WorldView-3和WorldView-2卫星数据进行实验,并与其他算法进行比较。选择WorldView-3数据中的3对LRMS图像和PAN图像,其中2对做训练和验证,1对做测试。同样从WorldView-2数据中选取3对LRMS图像和PAN图像,2对做训练和验证,1对做测试。首先依据Wald’s协议分别对原始的LRMS图像和PAN图像进行下采样[29],将原始的LRMS图像作为参考图像;其次将下采样后的LRMS图像进行双三次插值与PAN图像的分辨率保持一致;最后将获得的上采样后的LRMS图像、PAN图像、参考图像裁剪为128×128的尺寸,将裁剪得到的数据集的70%作为训练集,30%作为验证集,并取与训练图像不同的另一对图像数据,将其裁剪成400×400的小块作为测试集。
使用Keras搭建网络框架,在PyCharm上实现,并利用自适应矩估计(adaptive moment estimation,Adam)优化器对模型进行优化,学习率设置为0.000 1,beta1设置为0.9,beta2设置为0.99,Batchsize设置为8,超参数α=100,β=0.05。 实验环境的配置是AMD和RTX2080TI。为了验证所提算法的性能,将该算法与自适应施密特正交(gram-schmidt adapative,GSA)方法[30]、基于调制变换参数和高斯滤波的广义拉普拉斯变换(modulation transfer function (MTF) matched filter,MTFGLP)方法[31]、GFPCA[32]、PNN[17]、高通滤波和残差网络结合的PanNet算法[33]、FusionNet[34]、ResTFnet[20]7种方法进行对比,并使用有参考评价指标SAM、空间相关系数(Spatial CC,SCC)[35]、全局融合误差(ERGAS)[36]、峰值信噪比(PSNR)[37]和无参考评价指标Dλ、Ds与QNR[38]评价不同算法得到的融合图像质量。SCC越高,说明融合图像中包含的空间信息越多;ERGAS计算融合图像和参考图像之间的波段误差,ERGAS值越小,说明融合图像与参考图像的差异越小,融合结果越好;PSNR计算融合图像的最大峰值和2幅图像的均方误差的比值,PSNR值越大,融合图像的失真程度越小;空间失真指数Dλ评估融合图像和源全色图像的空间差异;光谱失真指数Ds评估融合图像和源多光谱图像之间的光谱差异,两者的值越小,融合图像质量越高;QNR用来评估融合图像总体的光谱和空间信息,数值越大,融合图像质量越好,最大值是1。
3.2 融合实验结果分析
图4和图5展示了不同的算法在低分辨率设置下得到的2种卫星图像融合结果,(a)和(b)分别为原始的LRMS图像与PAN图像;(c)为GFPCA算法得到的融合结果;(d)为GSA算法得到的融合结果;(e)为MTFGLP算法得到的融合结果;(f)为PNN 算法得到的融合结果;(g)为PanNet算法得到的融合结果;(h)为FusionNet 算法的融合结果;(i)为ResTFnet 算法的融合结果;(j)为本文融合结果。

图4 WorldView-2图像融合结果

图5 WorldView-3图像融合结果
从图4 WorldView-2数据集的融合结果看出,GFPCA的融合图像清晰度较低(如红色框所示),但包含的色彩信息较多;GSA和MTFGLP的融合图像包含的清晰度较高,但是产生了光谱失真的现象;PNN得到的图像包含的细节信息较多,但有颜色丢失的现象;PanNet得到的融合图像保留了大量的颜色信息,但存在某些空间细节表现不足的问题,如图中红框所示建筑物的边缘较本文的稍模糊;FusionNet的融合图像较为模糊,存在颜色过饱和;ResTFnet融合结果的颜色和清晰度均表现不错,但红框中所示的建筑物存在颜色失真的问题。相比而言,本文方法得到的融合图像包含了更多的空间细节和光谱信息。
图5为各种融合方法在WorldView-3数据集上的融合结果,可以看出GFPCA的融合图像较模糊(如图中红框所示);GSA和MTFGLP的融合图像的清晰度较GFPCA算法高,但是产生了光谱失真;PNN得到的融合结果包含的细节较多,颜色接近自然色;PanNet得到的融合图像颜色信息丰富,但依然存在局部空间细节保留不佳的问题,例如图中大红色框所示的建筑物和地表信息与本文相比,清晰度略显逊色;FusionNet的融合图像清晰度欠佳,但颜色信息较丰富;ResTFnet整体融合效果较好,但存在部分细节丢失。对比可见,本文方法得到的融合图像在空间细节和光谱信息保持方面具有一定的优势。
不同遥感图像融合算法在WorldView-2数据集上得到的评价结果如表1所示。

表1 WorldView-2数据集上的评价结果
由表1可知, 虽然PanNet在PSNR和ERGAS上获得的评价结果优于其他深度学习的遥感图像融合方法,但是本文方法在表征光谱信息和空间信息的评价指标SAM、SCC上表现最好,Dλ评价结果也优于其他深度学习方法,仅次于GSA。客观验证了本文方法在WorldView-2遥感图像融合方面能够保留较多源图像的光谱信息和空间信息。
为了进一步验证该方法的有效性,表2给出了不同遥感图像融合算法在WorldView-3数据集上的客观评价结果。

表2 WorldView-3数据集上的评价结果
从表2的评价结果可以看出,本文方法在ERGAS和SCC上获得的融合图像评价结果最好,说明本文方法在遥感图像融合过程中保留了更多源图像的空间特征。在无参考评价指标中,本文方法的Dλ和Ds值小于其他的深度学习算法,说明本文得到的融合图像包含的颜色信息和纹理信息多于其他对比的深度学习融合方法,本文的QNR值高于其他深度学习融合算法,说明融合质量高,客观地证明了该方法能够在WorldView-3全分辨率图像融合中保留更多光谱信息和空间信息。
3.3 损失函数及模型优越性分析
为了测试模型和损失函数的性能,在WorldView-3数据集上分别对不同的注意力机制模型和损失函数进行了实验分析,评估结果如表3所示。使用平均绝对误差MAE作为损失函数进行评估,记为L1;在MRA中使用通道注意力机制压缩-激励(squeeze-and-excitation,SE)网络[22]和CBAM[25],分别记为SE和CBAM,并与本文方法进行比较。

表3 不同损失函数和网络结构的融合结果
从表3中可以看出,使用本文的损失函数训练网络结构所得到的融合结果,除了Ds一项指标外,其他指标均优于L1、SE和CBAM,说明改进的损失函数提高了网络性能,获得了更好的融合效果,而且在遥感图像全色锐化时使用残差网络与CBAM结合比单独使用SE和CBAM获得的融合图像效果要好,证明了残差注意力网络可以提高图像的特征表达能力,使融合图像包含更多的光谱信息和空间信息,减少颜色畸变和空间细节丢失的现象。
4 结论
提出了一种基于多尺度残差注意力网络的全色图像和多光谱图像融合方法,有效改善了传统基于深度学习的全色锐化方法导致的空间信息丢失和光谱信息失真的问题。该网络由3个并行的多尺度残差注意力网络构成,分别提取源图像不同频度的特征信息;残差注意力多尺度模块的引入,保证了从空间和通道两方面提取更多源图像的特征,使融合图像包含较多光谱信息和空间信息。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
自动化学报(2019年6期)2019-07-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
河南科技(2015年8期)2015-03-11
时代英语·高三(2014年5期)2014-08-26
