
基于改进麻雀搜索算法的北疆春玉米产量预测方法
2023-09-13 03:07崔兴华
计算机工程与设计 2023年8期
崔兴华,靳 晟
(新疆农业大学 计算机与信息工程学院,新疆 乌鲁木齐 830052)
0 引 言
作物产量预测是农业科学的重要研究内容,性能可靠的作物产量预测模型可为农业工作者合理制定水肥施配方案提供理论指导,提高农业生产效率。传统的研究方法通常使用线性回归模型拟合作物生产规律,但由于线性方法存在局限,部分学者提出利用神经网络技术探寻作物生长与外界条件之间的非线性关系,并通过产量预测仿真实验证明神经网络模型的预测精度优于传统线性模型[3,4]。神经网络模型的性能表现在很大程度上依赖于超参数的选取,人为确定超参数往往费时费力且效果一般,基于此,部分学者尝试通过优化算法对超参数进行寻优,为解决超参数优化问题提供了新思路[5,6]。
本文提出一种基于改进的麻雀搜索算法的北疆春玉米产量预测方法。针对麻雀搜索算法(sparrow search algorithm,SSA)[7]存在的缺陷,改进算法使用遍历均匀性良好的Kent映射改善初始种群,引入改进反向学习机制及食物源机制引导算法跳出局部最优,增强算法的全局搜索能力。将改进算法与径向基神经网络(radial basis function neural network,RBFNN)结合构建模型,将模型用于新疆灌溉中心实验站的玉米产量预测仿真实验,实验结果表明,本文所提模型在玉米测产方面具备可行性。
1 改进的麻雀搜索算法
1.1 基于Kent映射的种群初始化
研究表明,Kent映射在遍历均匀性及迭代速度方面皆表现良好[8]。Kent映射的表达式[9]为
xt+1={xt0.5+ε,0≤xt≤12+ε,1-xt0.5-ε,12+ε≤xt≤1.
(1)
鉴于Kent映射的优良性质,利用Kent混沌序列对麻雀种群进行初始化,可以使初始种群更均匀的分布在搜索空间,提高算法的收敛速度及全局搜索能力。
1.2 结合反向学习的跟随者位置更新策略
反向学习(opposition-based learining,OBL)[10,11]常用于提升算法收敛速度,但OBL的搜索范围受限于搜索空间的上下边界,在迭代后期,反而可能拖累算法效率。
为改善OBL的搜索范围,本文将OBL与光的折射定律相结合,光线折射原理如图1所示。
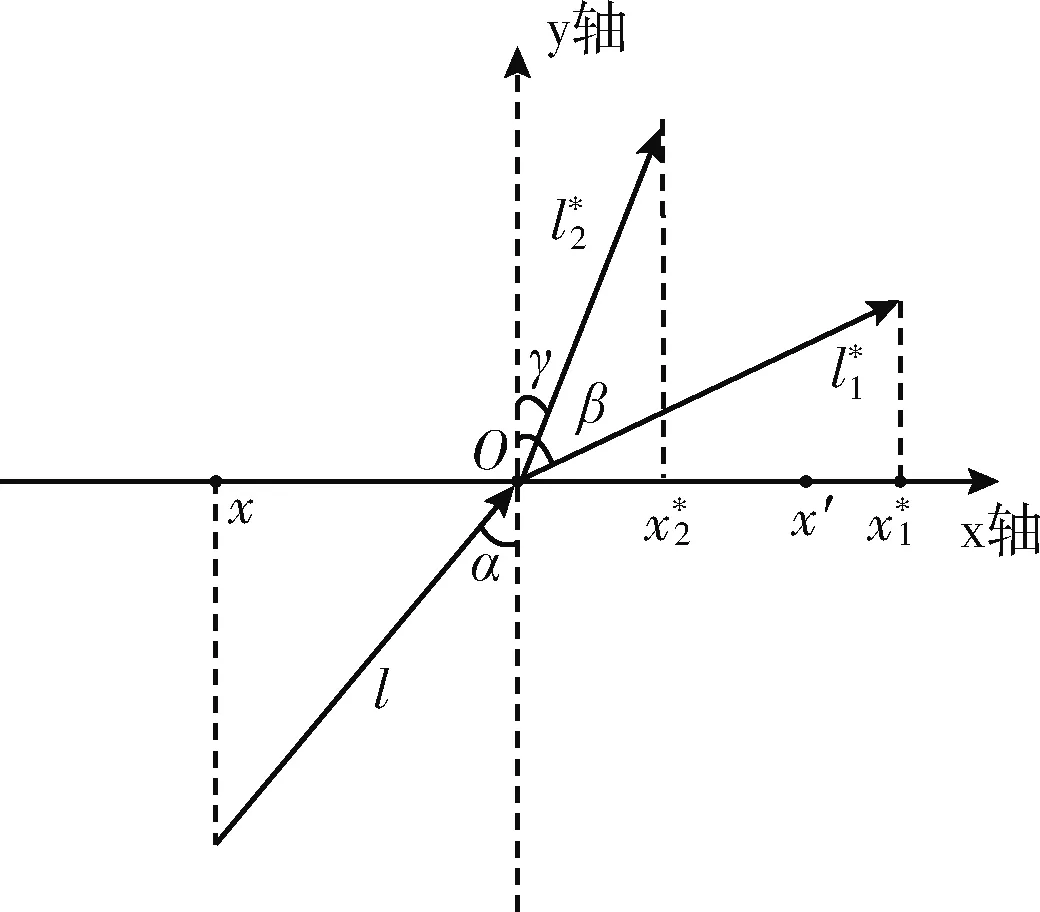
图1 光线折射原理
以维度为1的解x为例,当光线自光密介质射入光疏介质时,已知入射角α、出射角β、入射光线l、折射光线l*1,O为区间[x,x′]的中点,设l与l*1等长,则折射率可表示为
n=sinαsinβ=x+x′2-xx*1-x+x′2·l*1l=x′-x2x*1-x+x′2
(2)
变换可得
x*1=n+12n·x′+n-12n·x
(3)
式中:n∈(0,1) 为控制参数。式(3)所得折射解可跳出当前搜索空间获得更大的搜索范围,通过调整控制参数获得不同的折射解,可遍历区间[x,x′]外的整个搜索空间。
同理,当光线自光疏介质射入光密介质时,设其折射光线为l*2,且l与l*2等长,推理可得
x*2=n+12n·x′+n-12n·x
(4)
式中:n∈(1,+∞) 为控制参数,此时折射解落在区间[x,x′]内,倾向于向中点收敛。
在标准SSA算法中,跟随者的位置更新通过两个策略实现,其中,适应度值较差的跟随者会趋向于收敛到固定点,不利于算法的全局寻优。因此本文结合式(3)、式(4)对原跟随者位置更新策略进行调整,使最优位置作为不同介质的分界线,则新的表达式为
Xt+1i,j={α+1α·Xtp-1α·Xti,jifi>n3·e- ttmaxXtp+1d∑dj=1(1β·(Xtp-Xti,j))otherwise
(5)
式中:α为区间(0,1)内的随机数,d为麻雀个体的维度,β为区间 (1,1+5d∑dj=1|Xtp-Xti,j|) 内的随机数。由式(8)对追随者位置进行更新时,适应度值较差的麻雀不再收敛到固定点,而是趋向于逃离最优位置,适应度值较优的麻雀则将向最优位置靠拢,此处改动继承了原算法中的部分思想,使得适应度值较优的麻雀向最优位置靠拢时在各维度上保持一致,不会出现某一维过大或过小的情况。此外,本文在式中加入控制因子以控制全局搜索跟随者与局部搜索跟随者的比例,从而使得算法在前期执行广泛的全局搜索操作,在后期执行深入的局部寻优。
由于本文预设入射光线与折射光线长度一致,当入射角过小时,入射光线l可能会过长,从而导致折射光线超出寻优边界,如图2所示。
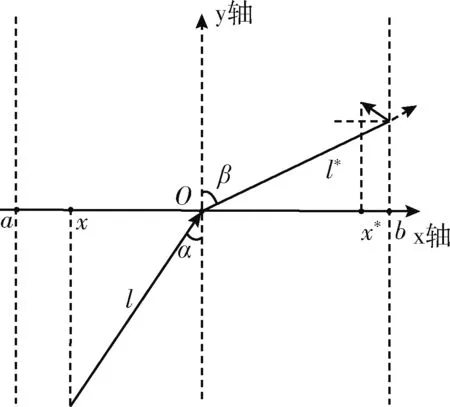
图2 折射光线越界
此时,应重新调整折射解的位置,本文设定遇到边界时,折射光线会发生反射,且令入射光线长度等于折射光线与反射光线长度之和,则新的折射解表达式为
Xt+1i,j={a+sinβ·((Xtp-Xti,jsinα-b-Xtpsinβ)%b-asinβ),if [(Xtp-Xti,jsinα-b-Xtpsinβ)b-asinβ]%2≠0b-sinβ·((Xtp-Xti,jsinα-b-Xtpsinβ)%b-asinβ).if[(Xtp-Xti,jsinα-b-Xtpsinβ)b-asinβ]%2=0={a+(n+1)·Xtp-Xti,j-n·bn%(b-a),if [(n+1)·Xtp-Xti,j-n·bn·(b-a)]%2≠0b-(n+1)·Xtp-Xti,j-n·bn%(b-a).if[(n+1)·Xtp-Xti,j-n·bn·(b-a)]%2=0
(6)
式中:α为入射角,β为出射角,n=sinα/sinβ为控制参数,%为取模运算,[]为取整运算。
此外,若最优位置距边界过近,也可能出现折射解越界的情况,如图3所示。
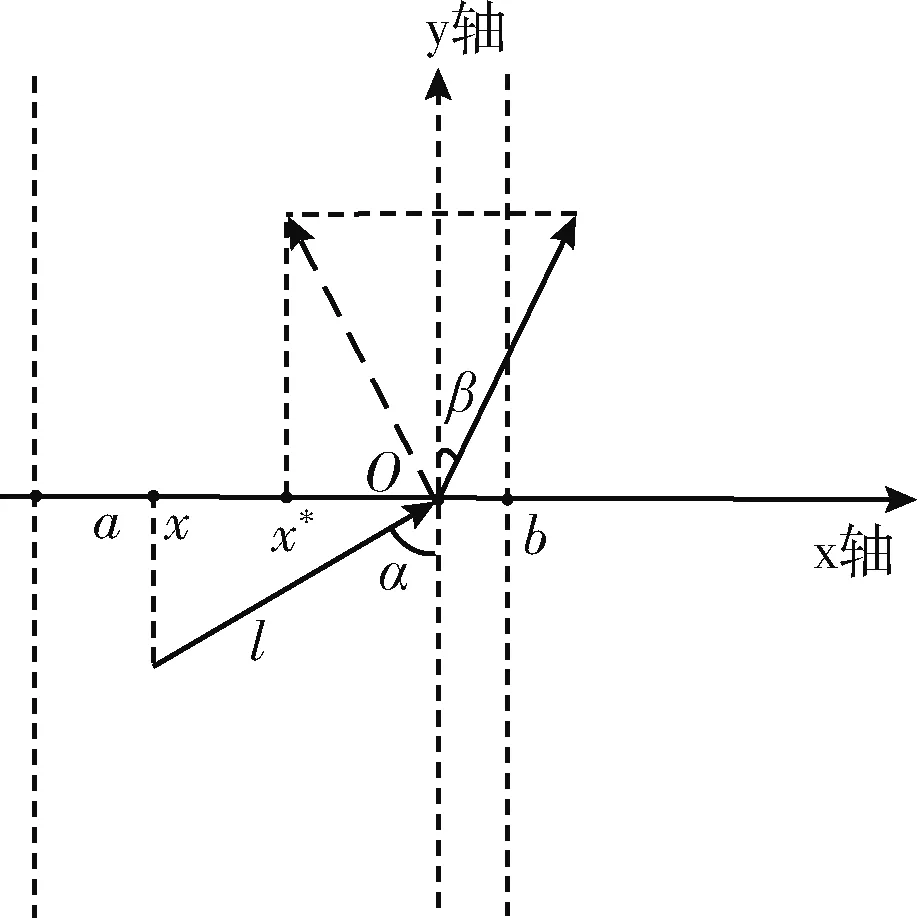
图3 折射解越界
此时,x与最优位置的距离大于x与边界距离的一半。本文设定以最优解为镜面,以折射解的镜像解作为真实折射解,则真实折射解的表达式为
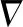
Xtp-1d∑dj=1(1β·(Xtp-Xti,j))otherwise
(7)
式中:α为区间(0,1)内的随机数,d为麻雀个体的维度,β为区间(1,1+5d∑dj=1|Xtp-Xti,j|) 内的随机数。
本文综合式(5)、式(6)、式(7)对跟随者位置进行更新。
1.3 融合柯西变异和高斯变异的食物源机制
受人工蜂群算法[12]的启发,本文引入食物源机制增强算法跳出局部最优的能力,具体规则为:
(1)记录麻雀种群迭代过程中找到的最优食物位置为食物源;
(2)在麻雀种群的迭代过程中,若食物源位置无变化则累计开采次数。食物源开采次数到达上限则对处于最优位置的麻雀进行扰动,并重置食物源位置;
(3)对于新发现的食物源,更新其开采次数上限,并按规则(2)继续迭代。
在上述规则中,对麻雀位置进行扰动的表达式为
xbest+xbest⊗gaussian(0,1)r1<1-exp(-i-1iter)1+r2
(8)
式中:cauchy(0,1) 是服从标准柯西分布的柯西算子,gaussian(0,1) 是服从标准正态分布的高斯算子,r1、r2为区间(0,1)内的均匀随机数,i代表当前迭代代数,iter为最大迭代代数。
相比于标准正态分布,标准柯西分布在原点附近分布更小,从峰值向0逼近的趋势更平缓,因此在算法中引入柯西算子有助于种群向更广的范围变异,从而增强算法的全局搜索能力,相对的,引入高斯算子则有助于种群在最优点附近更深入地搜索,从而增强算法的局部搜索能力。引入式(8)使算法在迭代前期以更高概率执行广泛的全局搜索,避免算法过早收敛,在迭代后期以更高概率对局部进行深入搜索,从而增强算法的寻优精度。
此外,食物源开采次数上限的初始值应按照种群大小和问题规模设置,在规则(3)中,更新食物源开采次数上限的表达式为
Lnew=fnewfp·Lp
(9)
式中:fnew、fp分别为新食物源和上一代食物源的适应度值,Lnew、Lp分别为新食物源和上一代食物源的开采次数上限。
1.4 算法描述
综合上述改进方法,改进的麻雀搜索算法(improved sparrow search algorithm,ISSA)实现步骤如下:
步骤1 初始化算法参数,包括麻雀种群规模N、发现者数量PD、侦察预警的麻雀个数SD、预警值R2、食物源开采上限L、问题维度D、搜索空间[lb,ub]、最大迭代次数itermax;
步骤2 应用式(1)生成初始麻雀种群X;
步骤3 计算种群中个体的适应度值,记录最优适应度值fb、最优位置xb、最差适应度值fw、最差位置xw,记录食物源位置xf=xb,食物源适应度值ff=fb;
步骤4 选取适应度值较优的P个麻雀作为发现者,据文献[7]中式(3)更新位置;
步骤5 剩余的N-P个麻雀作为跟随者,据式(5)~式(7)更新位置;
步骤6 在Xnew中随机挑选S个麻雀作为预警者,据文献[7]中式(5)更新位置;
步骤7 重新计算最优适应度值fbnew对应的最优位置最优位置xbnew,若fbnew不优于ff,对xf计一次开采次数;否则,更新食物源位置xf=xbnew,并据式(9)重置食物源开采次数上限;
步骤8 若食物源开采次数已达上限,据式(8)更新当前适应度值最优麻雀位置;
步骤9 若迭代次数达到最大值itermax,则结束迭代,输出结果;否则返回步骤3。
1.5 算法复时间杂度分析
假设麻雀种群规模为N,发现者数量为P,警戒者数量为S,问题维度为D,求解目标函数的时间为f(D)。
对标准SSA的时间复杂度进行分析[13],其参数初始化时间复杂度为O(1),初始化种群时间复杂度为O(ND), 计算个体适应度值的时间复杂度为O(Nf(D)), 对麻雀个体位置进行更新的时间复杂度为O(ND+SD), 则SSA整体时间复杂度为O(SSA)=O(D+f(D))。
据1.4节对ISSA时间复杂度分析如下:
步骤1进行参数初始化的时间复杂度为O(1),步骤2通过Kent映射初始化的时间复杂度为O(ND), 步骤3计算个体适应度值的时间复杂度为O(Nf(D)), 步骤4更新发现者位置的时间复杂度为O(PD), 步骤5更新跟随者位置的时间复杂度为O((N-P)D), 步骤步骤6更新警戒者位置的时间复杂度为O(SD), 步骤7重新计算个体适应度值的时间复杂度为O(Nf(D)), 步骤8重新更新最优位置的时间复杂度为O(D), 则整体时间复杂度为O(ISSA)=O(1)+O(ND)+O(Nf(D))+O(PD)+O((N-P)D)+O(SD)+O(Nf(D))+O(D)=O(D+f(D))。
综上所述,对比SSA,ISSA在修改部分算法策略后并未影响整体时间复杂度,降低算法效率。
2 基于改进的麻雀搜索算法的RBFNN预测模型
对于RBFNN模型,影响网络性能最重要的因素在于基函数中心的确定,本文将所提ISSA算法与RBFNN结合起来,提出ISSA-RBFNN模型用于玉米测产,模型建立流程如下:
步骤1 数据预处理。由于采集设备故障或采集人员操作不规范等原因,真实实验数据通常存在数据异常、数据缺失等问题,因此,建立模型首先需要对数据进行清洗、集成、无量纲化等操作以保证数据的可靠性。其中本文进行数据无量纲化所用表达式为
x*=x-min(x)max(x)-min(x)
(10)
步骤2 初始化模型参数。包括ISSA算法参数及网格搜索参数等。
步骤3 通过ISSA对RBFNN隐含层中激活函数的中心c、宽度σ进行寻优。其中,ISSA中麻雀个体的适应度函数表达式为
fitness=∑ni=1(yi-i)2n
(11)
式中:n为训练样本总数,yi、i分别表示真实值和预测值。
步骤4 使用梯度下降法更新连接权值ω。
步骤5 将 ISSA的寻优结果赋给RBFNN,完成模型构建。
3 仿真实验与分析
为了验证ISSA算法及ISSA-RBFNN模型在性能上的优越性,本文设置了两部分实验。第一部分实验验证ISSA算法的有效性,第二部分实验验证ISSA-RBFNN模型的有效性。
3.1 不同优化算法对比
本文选取了10个标准测试函数[14,15]对标准的麻雀搜索算法、遗传算法(genetic algorithm,GA)[16]、粒子群算法(particle swarm optimization,PSO)[17]、灰狼优化算法(grey wolf optimizer,GWO)[18]以及ISSA进行了优化仿真实验,以对比不同算法的寻优性能。
3.1.1 标准测试函数
实验所选标准测试函数详情见表1,其中F1~F5为单峰测试函数,只存在一个全局最优值,用来测试算法的收敛速度及精度,F6~F10为多峰测试函数,存在一个全局最优值及多个局部极值,用来测试算法跳出局部极值进行全局寻优的能力。

表1 标准测试函数
3.1.2 参数设置
公平起见,本文设定所有算法种群规模为100,最大迭代次数为1000次,各算法其余参数设置见表2。
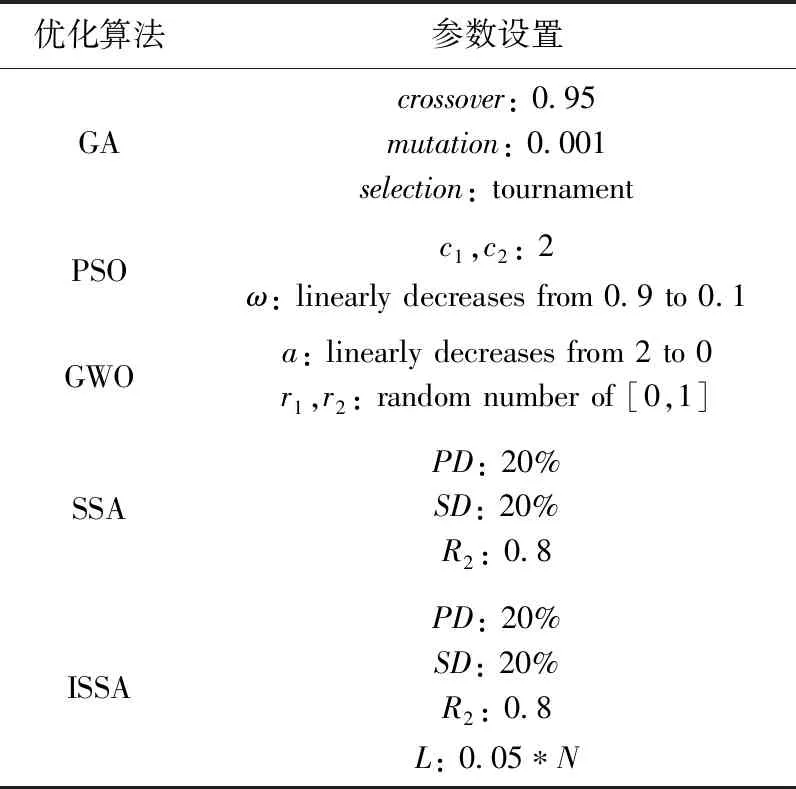
表2 算法参数设置
3.1.3 算法性能对比
为减小随机误差对实验结果的影响,本文将各算法在相同条件下各运行30次,得到实验结果如表3所列。表中best栏代表30次实验中得到的最优适应度值,mean栏代表30次实验的适应度值平均值,std栏代表30次实验的适应度值标准差。通过最优值和平均值可以反映算法的寻优精度,通过标准差则反映算法的稳定性。
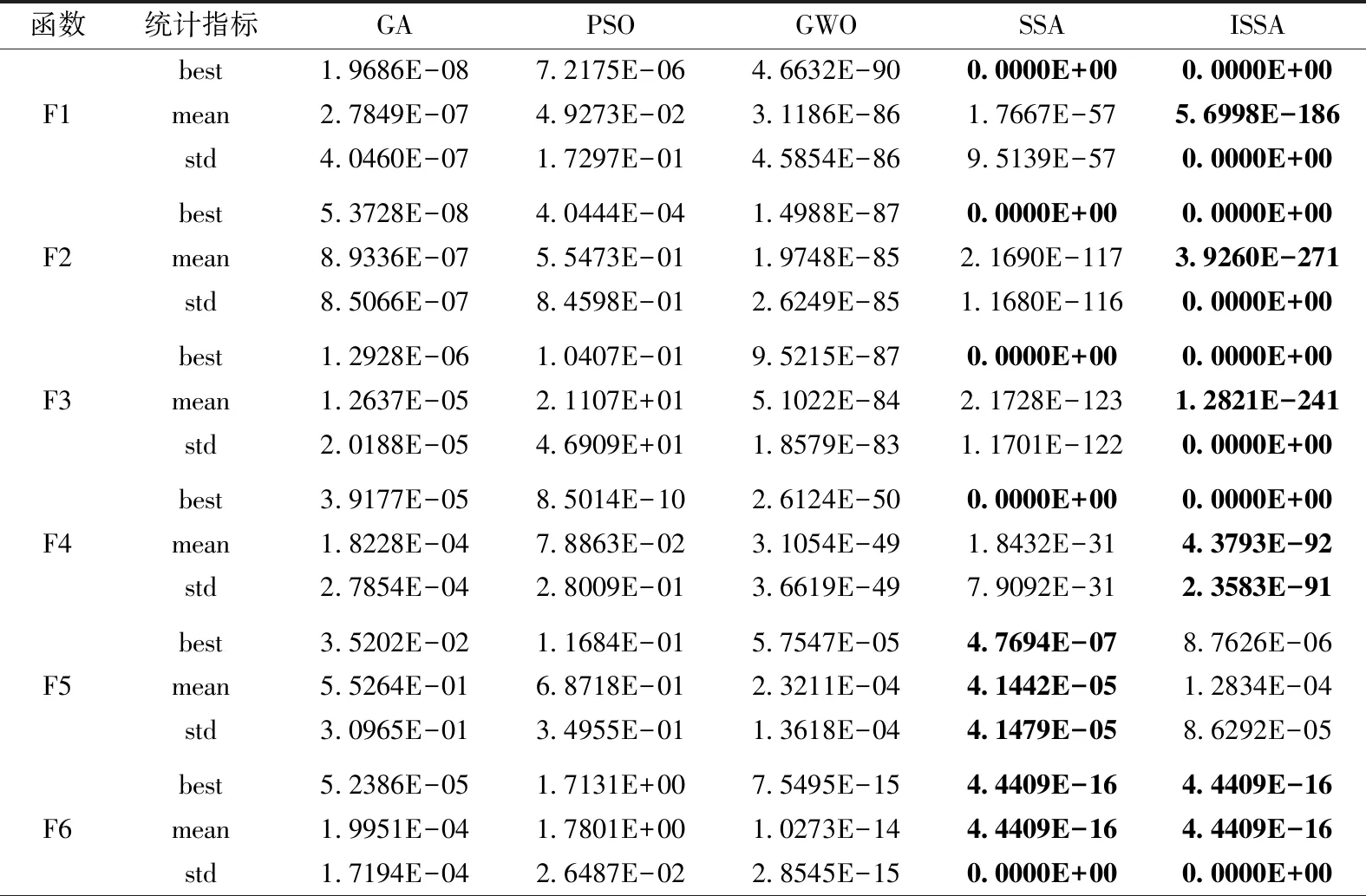
表3 标准测试函数寻优结果
首先对各类算法的寻优精度进行对比分析。从表3中可以看出,对于单峰测试函数,ISSA在函数F1~F4的最优适应度值及平均适应度值均为最优,且最优适应度值都得到了理论最优解,在函数F5上也获得了比GA、PSO、GWO更好的结果;对于多峰测试函数,ISSA在函数F6~F10上的最优适应度值及平均适应度值均优于其它4种算法,且在函数F7~F10上得到了理论最优解,总体来说,ISSA在寻优精度上优于其余4种算法。
其次对各类算法的稳定性进行对比分析。由表3中std栏的结果可以看出,ISSA算法在函数F1~F4、F6~F7、F9~F10上的标准差均优于其它4类算法,在函数F5上的标准差也优于GA、PSO、GWO这3种算法,在函数F8上,ISSA算法的稳定性比GA、PSO、GWO这3种算法差,但优于SSA算法。综合来看,ISSA算法在10个标准测试函数上具有较好的稳定性,同GA、PSO、GWO、SSA算法相比也具有一定竞争力。
最后对各类算法的收敛速度进行对比分析。为直观展示各算法的收敛速度,图4给出了各算法在标准测试函数上的收敛曲线。由图可看出,对于单峰函数,ISSA算法在函数F1~F5上皆率先收敛,且寻优精度高于其它算法;对于多峰函数,ISSA算法在函数F6、F8、F10上的收敛速度高于其余4类算法,在函数F7、F9上,其收敛速度与SSA相差不大,快于GWO、GA、PSO。
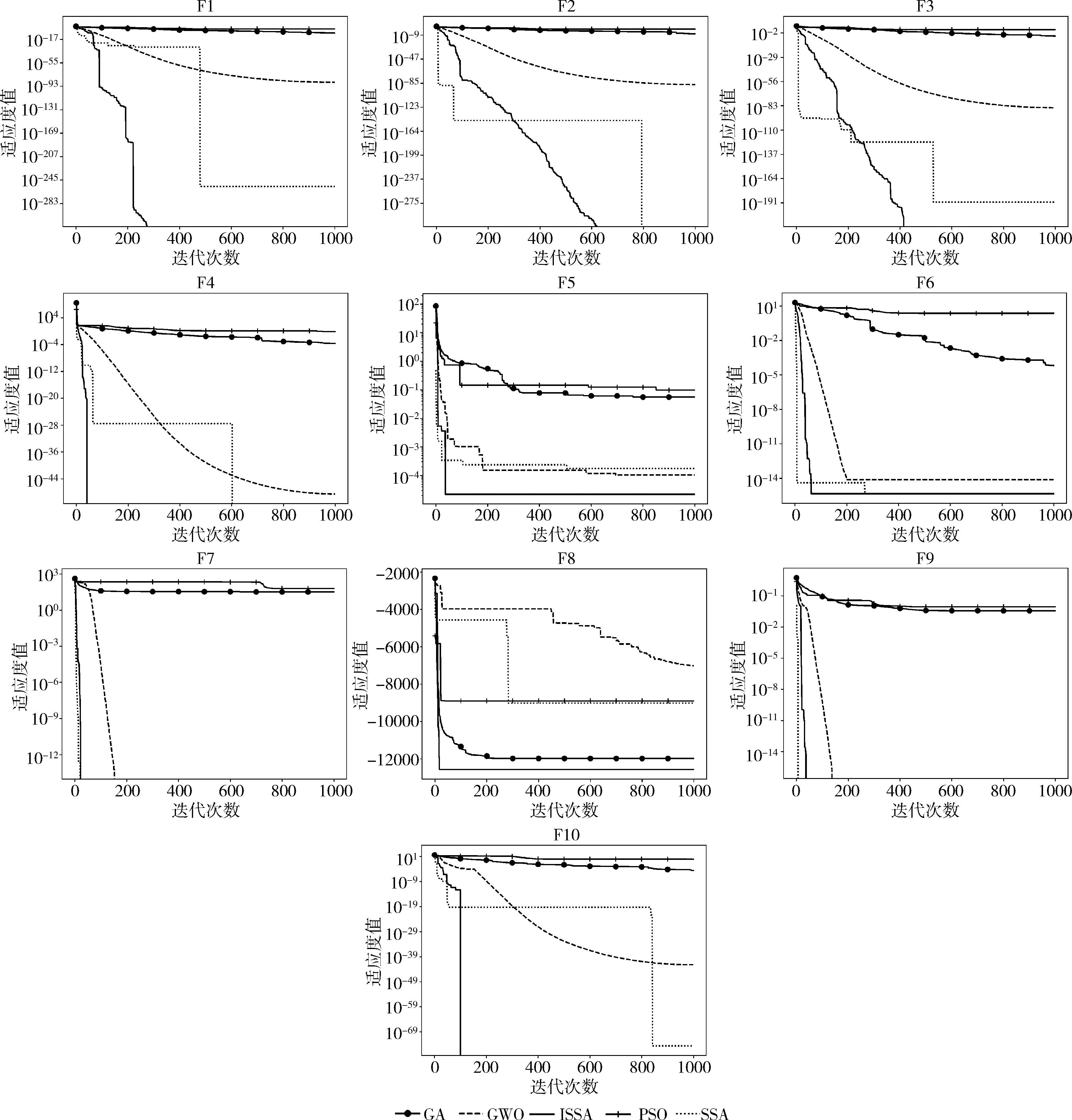
图4 各算法收敛曲线对比
综合上述分析,ISSA算法比GA、PSO、GWO、SSA算法具有更强的竞争力,在寻优精度、收敛速度及稳定性上皆表现良好。
3.1.4 与不同改进策略的SSA算法对比
为进一步验证本文所提ISSA算法的性能,选取文献[13]所提多策略融合的改进麻雀搜索算法(ISSA1)及文献[19]所提自适应变异的麻雀搜索算法(AMSSA)与本文所提算法进行对比分析。其中ISSA1利用混沌反射和反向学习策略丰富初始种群,并结合随机跟随策略调整了麻雀搜索算法中跟随者的位置更新公式,最后加入柯西变异和高斯变异对最优位置进行扰动;AMSSA同样在算法中加入了混沌映射以丰富麻雀种群,此外还利用柯西变异及混沌扰动增强了算法的局部搜索能力,最后加入自适应因子动态调整捕食者与跟随者比例,从而实现算法在全时期的寻优能力。
由于文献[13,19]在测试环境与实验参数设置上与本文基本一致,因此本文使用文献原文所列数据与本文测试结果进行对比,对比结果见表4。Null表示原文献未在此测试函数上进行测试。

表4 不同改进策略的SSA算法对比
表4分析可知,对于函数F2、F3、F4、F7、F9,ISSA的最优值、均值及标准差均为最优,其中在单峰函数F2~F4上,3种算法都能收敛到理论最优值,但ISSA1及AMSSA在30次迭代后的均值及标准差比ISSA多出了数十到百余个数量级,说明ISSA在单峰函数上具有较好的收敛精度,在多峰函数F5~F9上,3类算法在最优值、均值及标准差3项指标上仅相差1~2个数量级,因此,综合来看,ISSA的收敛精度略优于另外两类算法。此外,ISSA在8个存在有效值的函数上,有6个(F2~F7及F9)取得了最优标准差,反映出ISSA的稳定性总体上优于ISSA1及AMSSA算法。综合来看,对比ISSA1及AMSSA,ISSA在寻优精度及鲁棒性上皆有提升。
3.2 ISSA-RBFNN性能分析
3.2.1 数据获取
为获取训练模型所必要的样本数据,选取新疆灌溉中心实验站作为实验区进行了连续两年的玉米水肥耦合效应实验。为研究玉米水肥施用量与产量的关系,实验采集的数据主要包括:土壤氮、磷、钾含量,土壤含水率,玉米生长过程中的灌水量、施肥量及最终产量。实验最终采集样本数据72组,对样本数据进行清洗、集成后,统计其均值、标准差、极值、中位数及四分位数,结果见表5。
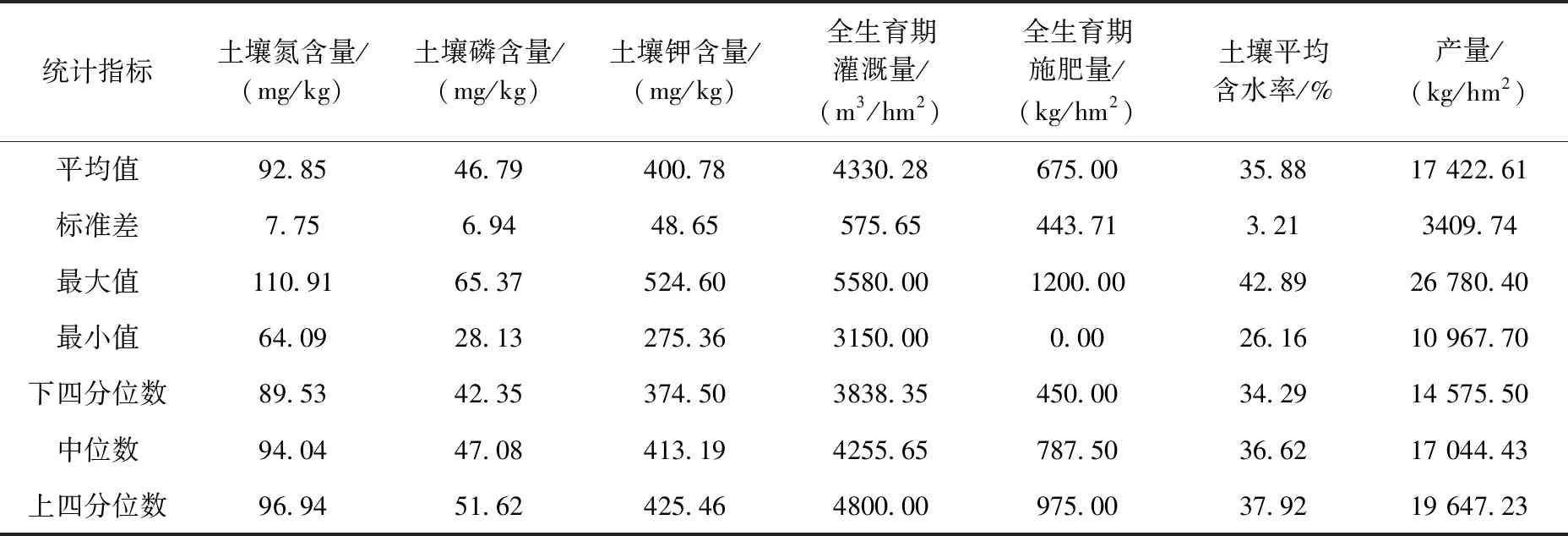
表5 样本数据统计结果
对所获数据集预处理后,以土壤氮含量、土壤磷含量、土壤钾含量、土壤含水率、灌水量、施肥量6个特征作为模型的输入,以玉米产量作为模型的输出,按施肥水平分层抽样,选取样本数据集的80%作为训练集,剩余20%作为测试集,进行模型的构建。
3.2.2 结果分析
为验证ISSA-RBFNN模型的有效性,本文选取以K-means方法确定中心的RBFNN模型(K-means-RBFNN)、SSA算法优化的RBFNN模型(SSA-RBFNN)、广义回归神经网络模型(general regression neural network,GRNN)[20]、支持向量机模型(support vector machine,SVM)[21]在相同实验条件下建模进行对比,其中,SSA、ISSA算法均设定麻雀种群规模为50,最大迭代次数为500,其余参数设置同表2所列。实验选择均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)、平均绝对百分比误差(mean absolute percentage error,MAPE)作为模型的评价指标。RMSE、MAE、MAPE的表达式依次为式中:n为样本总数,yi、i分别表示真实值和预测值。
为获得可靠的实验结果,实验采用五折交叉验证并通过各评价指标均值分析模型的预测效果。实验结果如图5所示,各模型性能评价见表6。
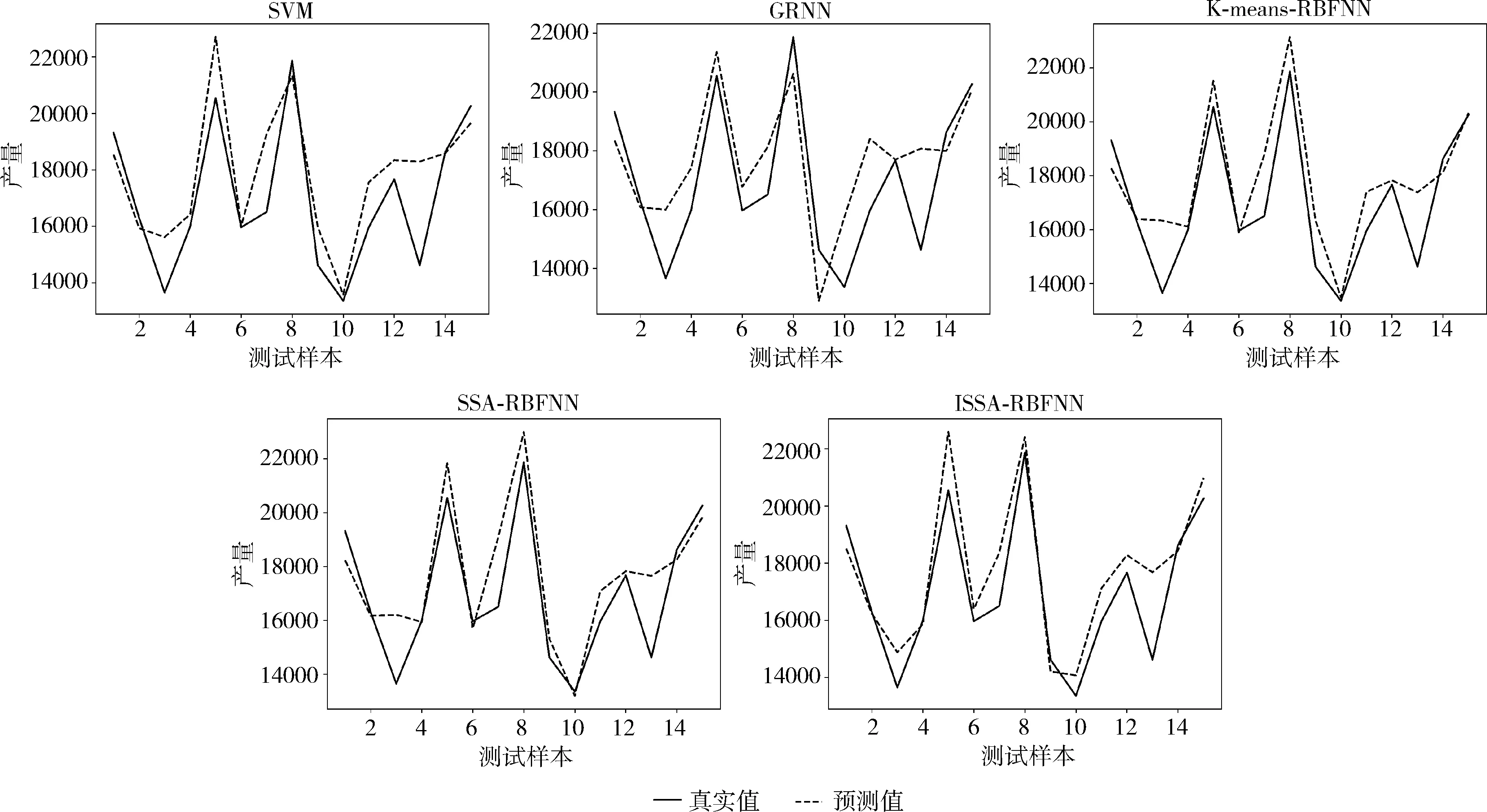
图5 模型预测结果
RMSE=∑ni=1(yi-i)2n
(12)
MAE=∑ni=1|yi-i|n
(13)
MAPE=100%n∑ni=1|yi-iyi|
(14)
可以看出,ISSA-RBFNN模型在3个性能指标上皆优于其它4种模型,GRNN模型表现最差。ISSA-RBFNN模型在RMSE、MAE、MAPE这3个指标上分别比SSA-RBFNN模型降低了11.07%、6.98%、8.15%,比K-means-RBFNN模型降低了11.79%、8.80%、11.08%,可见,ISSA有效降低了RBFNN模型的预测误差。与SVM模型相比,ISSA-RBFNN模型在RMSE、MAE、MAPE这3个指标上分别低20.85%、18.75%、19.92%;与GRNN模型相比,ISSA-RBFNN模型在RMSE、MAE、MAPE这3个指标上分别低25.62%、31.14%、34.46%,验证ISSA-RBFNN模型具有比SVM、GRNN具有更好的预测性能。综合来看,ISSA-RBFNN模型具有较为理想的预测精度。
4 结束语
(1)本文在麻雀搜索算法的基础上,提出一种改进的麻雀搜索算法,算法主要有3点改进:①使用Kent映射初始化种群;②引入改进反向学习机制替代原跟随者位置更新策略;③引入食物源机制。数值实验结果表明,改进策略提高了麻雀搜索算法的收敛速度和收敛精度。
(2)本文构建了ISSA-RBFNN北疆春玉米产量预测模型,并设计仿真实验验证模型的有效性,实验结果表明,对于新疆北疆地区春播玉米的产量预测,ISSA-RBFNN模型具备预测可行性,且在预测精度及鲁棒性上优于SVM模型、GRNN模型、K-means-RBFNN模型及SSA-RBFNN模型。
猜你喜欢
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
物联网技术(2017年5期)2017-06-03
上海理工大学学报(2016年2期)2016-06-02
火控雷达技术(2016年3期)2016-02-06
陕西理工大学学报(自然科学版)(2015年6期)2016-01-25
电测与仪表(2015年15期)2015-04-12
河北科技大学学报(2015年5期)2015-03-11
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
