
双模态融合特征下的说话人识别
2023-09-13 03:07谢娅利庞炜千薛珮芸赵建星师晨康
计算机工程与设计 2023年8期
谢娅利,庞炜千,白 静,薛珮芸,赵建星,师晨康
(太原理工大学 信息与计算机学院,山西 晋中 030600)
0 引 言
说话人识别是一种根据说话人的特征来确定身份的模式识别技术。说话人识别技术广泛应用于各个领域[1,2],因此对说话人识别技术进行研究具有重要现实意义。
特征提取在说话人识别系统中扮演举足轻重的角色。Huang JJ等[3]利用人耳的听觉特性将小波包分解为五级,提取语音中包含的动态特征进行说话人识别。然而在信噪比较低的情况下,提取的特征参数会导致识别率显著下降。Yang HY等[4]提出双阈值函数去噪的特征方法进行说话人识别,该方法在低信噪比环境下具有更好的性能。然而该算法较复杂,训练时间较长。周萍等[5]将伽玛通滤波倒谱系数和梅尔频率倒谱系数融合,并结合它们的动态特性构成混合参数,用高斯混合模型进行分类,实验结果表明该参数具有更好的抗噪性和识别性。Zhang Yan等[6]从发音器官中提取发音动作参数,使用动态时间规整进行说话人识别,研究发现发音动作特征对噪声环境下的说话人识别率有明显提高。
通过上述研究发现,发音动作特征与声学特征一样具有识别性。目前说话人识别主要选用单模态特征,然而仅使用单模态特征进行说话人识别很难提高其识别率。于是本文对传统发音动作特征进行改进得到参考点发音动作特征,并将其与声学特征进行融合,采用基于惩罚项的嵌入式特征选择去除冗余特征,得到双模态融合特征,然后使用TORGO数据库和自建库进行实验,验证本文所提参考点发音动作特征和双模态融合特征的有效性。
1 特征提取
1.1 声学特征
声学特征可分为语言学特征和超语言学特征,语言学特征包括词汇、句法、语法和语境等,超语言学特征有音质特征、韵律特征和频谱特征。由于语言学特征提取和分析比较困难,本文选择韵律特征和伽玛通滤波倒谱系数进行说话人识别。
韵律特征主要体现语音信号语调和强度的特点,不同说话人的声音强度和语调流畅度是不同的,由于韵律特征对信道环境噪声不敏感,因此被广泛应用于文本无关的说话人识别[7]。常见的韵律特征有振幅、共振峰、基频、过零率、短时能量等。
信号的振幅表示振动的强度,幅值越大,信号的强度越高。共振峰是元音激励产生的一组共振频率,反映了声道的共振特性。
基频是浊音中声带振动的频率。在发音过程中,声门瞬间闭合,声道受到强烈刺激,此时振幅急剧增加,导致突变,则该处基频为两个相邻声门闭合时间的倒数[8]。使用短时自相关函数进行基音检测,则语音信号x(m)的基频为
Rn(k)=∑N-km=nxn(m)xn(m+k)
(1)
语音信号在一帧内越过零电平的次数为过零率。它能在一定程度上反映信号的频谱特性,从而对语音信号进行粗略估计,则函数表示为
Zn=0.5∑N-1m=0|sgn[xn(m)]-sgn[xn(m-1)]|
(2)
语音的短时能量可以通过它的响度来衡量。设各帧语音信号xn(m)的帧长为N,则能量公式为
En=∑N-1m=0x2n(m)
(3)
伽玛通滤波倒谱系数(Gammatone filter cepstral coef-ficient,GFCC)是根据人耳的听觉特性构造的语音特征参数,反映了说话人之间的差异,并且在一定程度上减小了噪声对特征提取的影响,具有良好的识别性能。语音信号通过快速傅里叶变换后,使用伽玛通滤波器组进行滤波,伽玛通滤波器组可模拟人耳耳蜗基底膜的分频特性[9],其滤波器的带宽与人耳的临界频带关系为
ERB(f)=24.7×(4.37f/1000+1)
(4)
对滤波器的输出采用对数压缩和离散余弦变换,得到听觉特征参数GFCC
GFCC(i)=2π∑Mj=1αjcos[πiM(j-0.5)],i=1,2,…,N
(5)
其中,α1,α2,…,αj是一组对数能量谱,N是GFCC参数的维数,M表示滤波器的个数。
1.2 参考点发音动作特征提取算法的提出
发音动作参数由三维电磁发音仪(3D electromagnetic articulography,EMA)采集,由发音部位产生的发音动作参数位移和速度值作为发音动作特征(articulatory movement features,AMF)[10,11]。EMA采集的发音动作参数都是原始数值,由于每个说话人发音部位的特性容易受到其它发音部位的相对位置变化的影响,在说话人识别系统中直接用初值进行分类效果并不太好,因此要对原始数据进行处理。于是本文对传统发音动作特征进行改进,提出参考点发音动作特征(reference point articulatory movement features,RPAMF)提取算法,用来突破单独发音部位提取的发音动作参数不足、识别率低的限制。
参考点发音动作特征提取算法的主要思路是由于说话人在发音时鼻梁始终与身体保持相对静止,因此选择以鼻梁为参考点,舌部(舌尖、舌中、舌后)、唇部(上唇、下唇)和下颌与参考点相对位移和相对速度作为发音动作参数,RPAMF参数公式如下
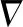
(6)
(7)
1.3 双模态融合特征
特征融合可同时提取多个特征,以实现特征互补并减少单个特征固有缺陷的影响[12]。声学特征和发音动作特征能从不同角度反映说话人信息,由于不同特征之间具有互补性,有效的融合能更全面的表征出说话人特性。
本文提出的双模态融合特征主要思路如下,首先提取语音的韵律特征如过零率、振幅、基频、短时能量以及第1和第2共振峰,并计算韵律特征和GFCC的统计参数;其次选择舌尖、舌中、舌后,上唇、下唇和下颌各单独发音部位相对于鼻梁运动产生的平均位移、位移的方差、平均速度和速度的方差,组成72维RPAMF;然后将韵律特征和GFCC的统计函数与72维RPAMF特征融合,采用基于惩罚项的嵌入式特征选择方法去除不相关和冗余的特征,组成最终的双模态融合特征。
双模态融合特征集合表示为
F={Fr,Fg,Frp}
(8)
其中,Fr表示韵律特征集合,Fg表示GFCC特征集合,Frp表示72维RPAMF特征集合。
韵律特征集合表示为
Fr={z,A,P,E,F1,F2}
(9)
其中,z为过零率;A为振幅的统计参数构成的向量,即
A=(maxA,minA,,maxA′,minA′,′)
(10)
各量依次为振幅的最大值、最小值、平均值,振幅变化率的最大值、最小值、平均值;P由基频的统计参数构成,即
P=(maxP,minP,,maxP′,minP′,′)
(11)
各量依次为基频的最大值、最小值、平均值,基频变化率的最大值、最小值、平均值;E表示短时能量及其变换率的统计值,即
E=(maxE,minE,,maxE′,minE′,′)
(12)
各量依次为能量最大值、最小值、平均值和能量变化率的最大值、最小值、平均值;F1,F2分别表示由第1和第2共振峰的统计参数构成的向量,即
F1=(1,σ2F1,Δ1,σ2ΔF1)
(13)
F2=(2,σ2F2,Δ2,σ2ΔF2)
(14)
其各量依次为均值、方差及一阶差分的均值和方差。
GFCC特征集合表示为
Fg={G1,G2…,Gk}
(15)
Gk= (k,σ2Gk,Δk,σ2ΔGk)
(16)
k取12,其各量依次为均值、方差及一阶差分的均值和方差。
72维RPAMF特征集合表示为
Frp={Sx,Sy,Sz,Vx,Vy,Vz}
(17)
其中,Sx,Sy,Sz分别表示由舌尖、舌中、舌后,上唇、下唇和下颌相对于鼻梁X轴、Y轴、Z轴平均位移和位移的方差构成,即
Sx=(x,σ2Sx)
(18)
Sy=(y,σ2Sy)
(19)
Sz=(z,σ2Sz)
(20)
Vx,Vy,Vz分别表示舌尖、舌中、舌后,上唇、下唇、下颌相对于鼻梁X轴、Y轴、Z轴平均速度和速度的方差构成的特征向量,即
Vx=(x,σ2Vx)
(21)
Vy=(y,σ2Vy)
(22)
Vz=(z,σ2Vz)
(23)
为了去除冗余特征,采用基于惩罚项的嵌入式特征选择方法,引入L1、L2范数正则化,L1正则项来选择特征,L2正则交叉检验。其目标函数公式如下
minw∑ni=1(yi-wTxi)2+λ1w1+λ2w22
(24)
2 GMM-SVM分类器
对于同类语音数据具有相似性和不同类数据具有不同几何距离的特点,本文采用高斯混合模型-支持向量机(Gaussian mixture model-support vector machine,GMM-SVM)分类器创建说话人识别系统,GMM-SVM说话人识别系统结合了高斯混合模型(Gaussian mixture model,GMM)和支持向量机(support vector machine,SVM)的优点,与单独使用GMM或SVM的说话人识别系统相比,具有更好的鲁棒性和识别率,语音信号经过GMM模型参数化表示后的均值超向量可提高SVM模型对序列的分类能力,并且SVM在数据量较小时也能很好解决分类问题。GMM-SVM算法是通过GMM提取均值超矢量,利用SVM进行分类,从而达到说话人识别的目的[13]。GMM-SVM的说话人识别系统如图1所示。
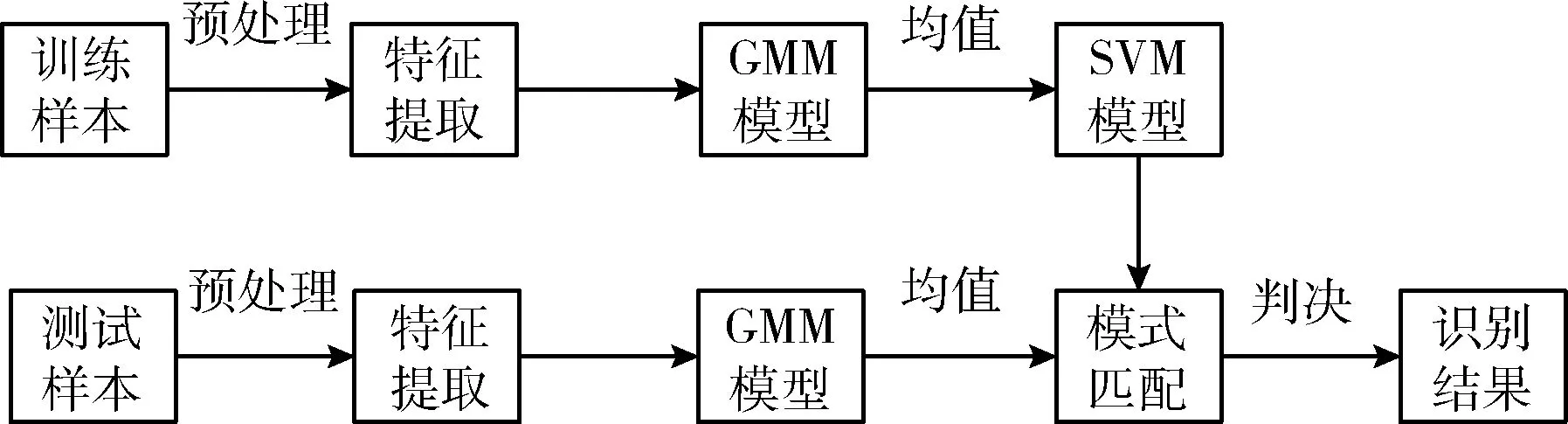
图1 基于GMM-SVM的说话人识别系统
2.1 GMM均值超向量
用KL距离表示不同说话人之间的差异性,其公式如下
D=∫Rnga(x)log(ga(x)gb(x))dx
(25)
其中,ga,gb是经过MAP自适应技术而得的,但KL距离不能直接用于SVM模型,需使用log-sum不等式来获得KL距离上限,MAP自适应时,保持其方差和权重不变,只更新GMM模型的均值。假设满足方差为对角矩阵,则公式如下
d=0.5∑Ni=1wi(μai-μbi)∑-1i(μai-μbi)
(26)
其中,μa,μb为MAP自适应后的均值超向量。从上述两式可得,0≤D≤d, 均值超向量间的差距越大,两个语音段的差异就越大,从而能更好区分说话人。由于上式具备良好的对称性,可以将上式转换为内积样式,让核函数满足SVM模型的KKT约束条件
K(utta,uttb)=∑Ni=1wi(μai)t∑-1iμbi=∑Ni=1(wi∑-0.5iμai)(wi∑-0.5iμbi)
(27)
从而得到基于GMM模型均值超向量的线性核函数。
2.2 支持向量机
在SVM模型中,将多分类问题分解为多个二值分类问题,采用一对多的方法。一对多方法要求将每个类别分别训练成相应的分类器,对于n个类别,需要分别训练n个相应的分类器。对于非线性SVM分割超平面表示为
f(x)=∑mi=1αiyiκ(xi,xj)+b
(28)
其中,κ(xi,xj) 就是核函数,核函数将原始样本空间映射到高维空间,找到最优分类超平面,从而将非线性分类问题转化为线性分类问题。
3 数据库
为验证本文所提方法的优越性,采用多伦多大学和语音病理学系联合开发的TORGO数据库和实验室自建库进行实验。TORGO数据库包含约23 h的英语语音数据和发音动作数据,构音障碍的类型是脑瘫或肌萎缩性脊髓侧索硬化症[14],无其它身体损伤,能自主发音。实验室自建库包含健听学生和构音障碍患者的普通话语音数据和发音动作数据,健听学生为在校大学生,构音障碍患者为听力障碍,佩戴助听器有5年以上,并拥有一年以上语言康复训练经历,无其它身体损伤,能自主发音。数据库基本构成情况见表1和表2。

表1 TORGO数据库概况

表2 自建数据库概况
在实际应用中,语音内容大多与文本无关,可供识别的语音数据也往往较少,随着语音持续时间的缩短,准确率将显著降低。针对上述问题,本文随机选取每人60个不同短文本,为了避免数据质量对实验结果造成不良影响,在开始实验之前需要对原始数据进行多次筛选,用Praat软件筛选声学数据,Visartico软件筛选运动学数据,经过双重筛选后,每人提取40条语音数据,40条发音动作参数数据。
4 实验结果与分析
本文用TORGO数据库和自建库进行实验,使用SVM、GMM-SVM对说话人进行识别,GMM模型选择混合度为32,采用K-Means实现模型参数初始化。核函数采用径向基核函数,根据粒子群算法优化参数[15]。采用10折交叉验证方法对说话人进行分类实验。
4.1 AMF和RPAMF的识别结果与分析
为测试所提RPAMF特征对正常人和构音障碍患者不同发音部位的识别性能,把构音障碍患者设为对照组,对传统发音动作特征和参考点发音动作特征进行对比实验,测试改进RPAMF特征的识别率。然后去除病理因素对所有人进行实验,验证改进RPAMF特征的有效性。测试结果见表3和表4。
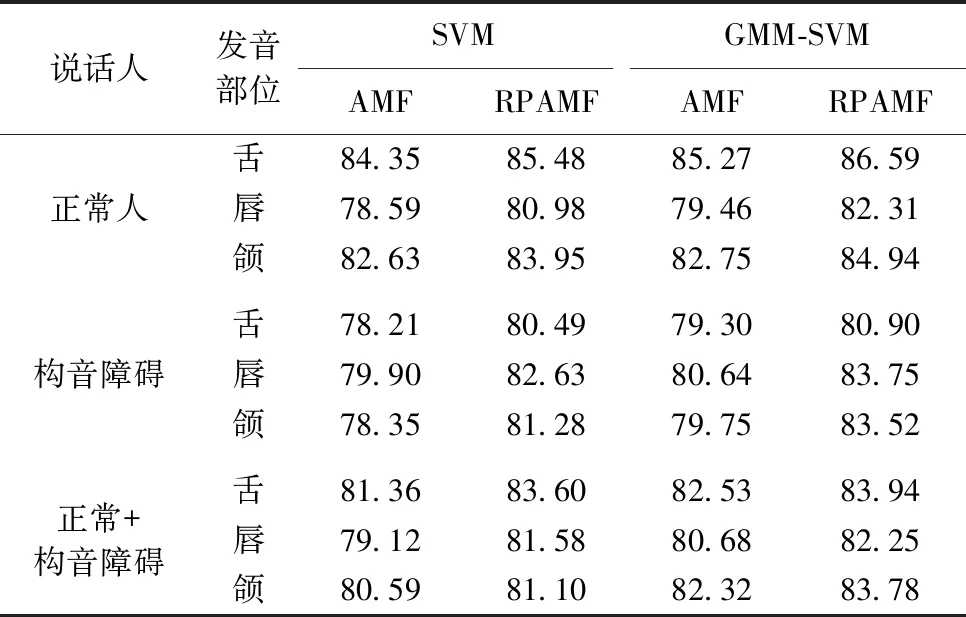
表3 TORGO数据库不同发音部位AMF和RPAMF识别率/%
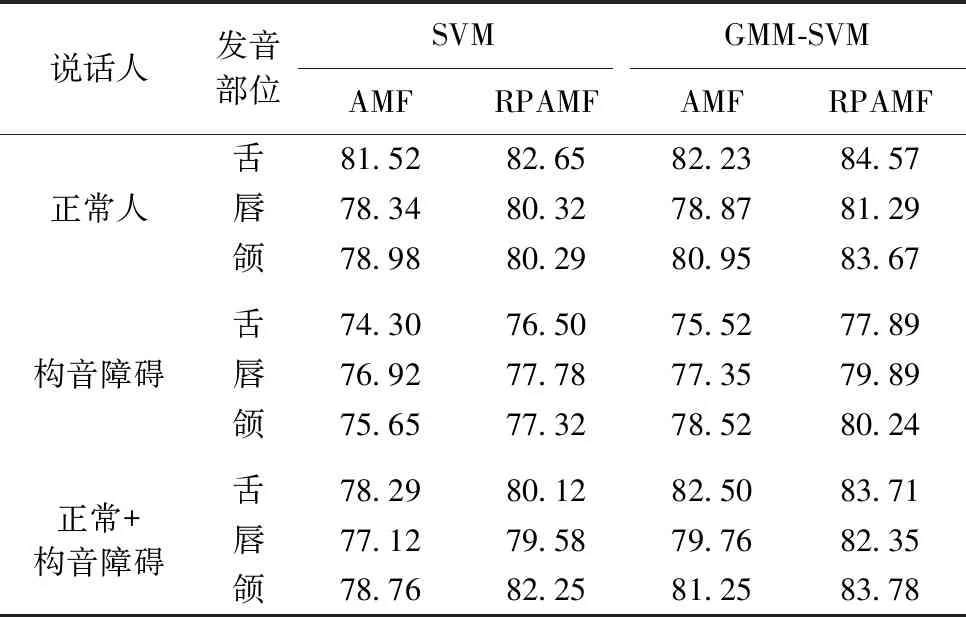
表4 自建库不同发音部位AMF和RPAMF识别率/%
从表3和表4的实验结果得出,无论正常人还是构音障碍患者,无论使用何种分类器,提出的RPAMF的识别准确率都比AMF的识别准确率高,使用GMM-SVM分类器后优化效果更为明显。将正常人和构音障碍患者作为整体实验对象进行实验,实验结论同样适用。验证了本文所提RPAMF的有效性。
4.2 融合特征的识别结果与分析
从上述实验结果得出,无论使用何种数据库,本文所提的RPAMF的识别性能都比AMF的识别性能好,因此将TORGO数据库和自建库作为整体实验对象,测试单模态特征的分类精度及所提双模态融合特征的识别性能。具体分类识别结果见表5。
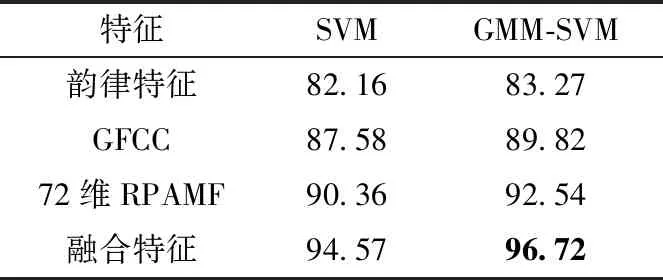
表5 说话人各类特征识别率/%
从表5可以看出,无论使用何种分类器,双模态融合特征相比于单模态特征识别准确率都有所提高。使用SVM分类器,双模态融合特征识别准确率达到了94.57%,相比于单模态特征识别准确率最少提高了4.21%,提升较为明显,使用双模态融合特征和GMM-SVM分类器的组合达到的识别准确率最高,识别准确率达到了96.72%,体现了本文所提双模态融合特征的优越性,双模态融合特征可以更好地表征说话人之间的差异,同时选用GMM-SVM分类器,可以取得更好的识别效果。
5 结束语
随着社会的发展,说话人识别越来越重要。虽然相关研究成果十分丰富,但单模态特征并不能很好的表现说话人之间的差异,于是本文将声学统计特征和参考点发音动作特征进行融合,采用基于惩罚项的嵌入式特征选择去除冗余特征,从而构成双模态融合特征下的说话人识别系统。在TORGO数据库和自建库上进行实验,实验结果验证了本文所提RPAMF的优越性。同时,将两数据库作为整体实验对象,测试不同特征的分类精度,从而发现双模态融合特征能实现更高的识别率。在今后的研究中,需要对特征融合做进一步的理论研究和技术改进,力求达到更高的识别率。
猜你喜欢
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中国交通信息化(2016年2期)2016-06-06
小学生时代·大嘴英语(2015年12期)2016-01-07
小学生时代·大嘴英语(2014年11期)2014-12-04
电测与仪表(2014年15期)2014-04-04
