
基于Stacking模型的土壤综合肥力评价
——以富川瑶族自治县植烟区为例
2023-09-12 00:57:32邹天祥梁志鹏龚佳林沈文杰张介棠范东升卢燕回
西南农业学报 2023年7期
邹天祥,梁志鹏,龚佳林,周 萌,沈文杰,2,3,张介棠,范东升,卢燕回
(1.中山大学地球科学与工程学院,广东 珠海 519000;2.广东省地质过程与矿产资源探查重点实验室,广东 珠海 519000;3.广东省地球动力作用与地质灾害重点实验室,广东 珠海 519000;4.广东微碳检测科技有限公司,广东 清远 511500;5.中国烟草总公司广西壮族自治区公司,南宁 530022)
【研究意义】土壤是植物生长的基础,其营养元素和理化性质决定了作物对养分的吸收和转化效率;气候为农业发展提供了光、热、水等物质条件,并在很大程度上决定当地作物种植制度;地形地貌通过影响环境中的温湿度、养分含量等,对作物种植和生长产生制约。因此,准确评价土壤肥力及其影响因素至关重要,以便针对不同地区制定适宜的作物利用方案,实现作物优质生长和土地资源可持续发展。【前人研究进展】土壤肥力是农作物种植研究的重要课题,但研究者多侧重于土壤营养物质和矿质成分的储量和有效性研究,对土壤综合肥力的探索不足,相关标准尚未统一。传统综合肥力评价方法(包括主成分分析法[1]、指数法、最小数据集法、内梅罗指数法[2]、模糊综合评价法[3]等)存在过程繁琐、评价指标多样、主观影响大和标准难以统一的缺点。近年来,随着信息技术的快速发展和大数据行业的兴起,机器学习在多个领域得到广泛应用。例如赖红松等[4]采用遗传算法-模拟退火(GASA)优化支持向量机(SVM)参数算法实现对农田地力的等级评价;李小刚等[5]运用BP神经网络结合模糊综合评价实现对耕地土壤肥力的等级划分。尽管已有关于土地肥力评价的机器学习和大数据案例和尝试,但针对不同地区、不同作物土壤肥力的划分标准无法通用,需要针对具体地区作物进行相应的土壤肥力评价。【本研究切入点】烟草是我国重要经济作物,可塑性强、环境适应性广。富川瑶族自治县是贺州市烟草的重要产区,烟草产业是当地实施精准扶贫的重要窗口。然而当地针对植烟区土壤综合肥力方面的研究相对薄弱,尚未进行系统的土壤肥力评价调查。【拟解决的关键问题】为优化富川县植烟区烤烟的种植布局,合理利用植烟区生态资源,本文以富川植烟区为例,采用Stacking堆叠算法构建植烟区的土壤综合肥力评价模型,实现对土壤综合肥力评价的标准化和快捷化。
1 材料与方法
1.1 研究区概况
广西省贺州市富川瑶族自治县位于广西东北部,总面积157 200 hm2,下辖9镇3乡。县域地势呈北高南低,四周是丘陵山脉和岩溶峰林,中部是宽阔的溶蚀平原[6]。研究区属亚热带季风气候,阳光资源丰富,昼夜温差明显,年降雨量达1700 mm,多年平均气温19.1 ℃,历年总积温7008 ℃,全年≥10 ℃的活动积温为6099 ℃,平均日照时数为1573.6 h,区内以轻壤土、中壤土为主要土壤类型,部分地区为砂土、黏土和重壤土,具备生产优质烟叶的生长环境和气候条件。
1.2 评价因子选取
土壤肥力受众多因素影响,可归纳为土壤条件、气候环境和地形地貌3大类。仅土壤条件就包含土壤物理指标、化学指标、生物指标和养分指标等多种纬度, 涉及指标繁多且部分指标的测定和应用存在困难[5]。本研究在同类研究[7-11]的基础上,筛选出15种易于测定且重现性好的指标作为影响因子,指标的选取和简要解释见表1[12-13]。

表1 肥力评价指标体系

图1 采样点空间分布

表2 土壤养分的测定指标及测定方法
1.3 数据来源
1.3.1 土壤样品采集和测试 根据植烟土壤类型、耕作模式等具体状况,将采样区域划分为若干单元,尽量保证每个单元的土壤性状均匀一致。具体采样方法如下:对于连片的烟田,每3.33 hm2作为一个单元,采用“S”形布点采样;不连片或狭小的烟田,则单独作为一个采样单元,采用“梅花”形布点采样。土样采集为耕作层0~20 cm表层土壤,采用多点混合采样法,在每个采样单元采集5~8个点混合而成混合样。在本研究中,共采集1360个样点,其中广西省河池市、百色市和贺州市钟山县地区总计1038个样点用作训练和测试数据,富川县322个样点用于研究区数据,研究区采样点空间分布见图1。样品经自然风干、去杂、研磨、过筛后,进行养分指标的测定分析(表2)。
1.3.2 气候环境 气候数据来源于中国地面气候资料日值数据集(V3.0)。本研究选择3—6月大田期数据,统计广西全域及周围共计42个气象站站点2010—2019年日值数据,计算出各站点旺长期降雨量、大田期日均气温、大田期日均相对湿度、大田期活动积温和大田期日照时数,采用合适的插值方法[14]获取不同影响因子的气候信息数据。

表3 各影响因子隶属函数、阈值及其权重
1.3.3 地形地貌 DEM数据来源于BIGMAP(http://www.bigemap.com),空间分辨率17.5 m。使用ArcGIS表面分析工具获取海拔和坡度数据。
1.4 模糊数学模型
训练集数据的建立使用模糊数学模型法[15],通过隶属函数将无规则分布的定量或定性描述数据转换为0~1的隶属值,其隶属函数公式包括抛物线型、S型和反S型[16],公式如下:
(1)
(2)
(3)
式中,x1、x2、x3、x4分别表示隶属函数的下限、下优、上优和上限。参评指标的因子权重采用AHP层次分析法[8]计算,且判断矩阵均通过一致性检验。具体影响因子的隶属函数阈值[8, 17-19]和权重如表3所示。其中,pH、有机质、全氮、容重、孔隙度、旺长期降雨量、大田期日均气温、大田期相对湿度、大田期日照时数、海拔为抛物线形隶属函数,有效磷、速效钾、大田期活动积温为S形隶属函数,坡度为反S形隶属函数。土壤质地采用直接赋值法,砂壤土、轻壤土、中壤土、黏土、砂土和重壤土分别赋值1.0、1.0、0.9、0.8、0.8和0.8。
得到对应样点的综合肥力指数IFI(Integrated fertility index),计算公式如下:
(4)
式中,n为影响因子总数,Pj为第j个影响因子权重,Xij表示第i个样本第j个影响因子的隶属度。IFI的取值范围为0.1~1.0,IFI值越高表明该样点的综合肥力评价越好。
1.5 Stacking模型
Stacking 是一种混合学习方法[20-21],其核心思想在于通过整合多个差异性较大的模型,从而实现相较单一模型更佳的预测表现。通常将各独立模型称为初级学习器,而负责整合各初级学习器的模型被称作次级学习器或者元学习器[22]。Stacking模型首先针对初始数据集进行初级学习器的训练,并生成用于元学习器训练的次级训练集数据,在此基础上得到最终预测结果(图2)。
由于数据存在噪声,各模型在不同特征方面的表现存在差异。在理想情况下,采用Stacking训练方法可以提炼各模型在特征提取优秀的部分,同时摒弃其在某些方面不佳的表现。然而,直接使用初级学习器的训练集来产生次级训练集存在过拟合风险,需要采用交叉验证方法来形成次级训练集[23]。如图3所示,以5折交叉验证为例,在训练初级学习器时,将训练数据随机划分5份,每次用其中4份训练并预测剩下的1份数据,重复5次即可获得完整训练集的预测结果。同时,每个初级学习器都需要对测试数据集进行预测,从而得到5个测试集预测结果的平均值,作为次级学习器的一个特征纬度。
1.6 模型搭建
为了增强Stacking模型的泛化性能,需要考虑以下两个方面:其一,选择具有不同特征的学习器作为初级学习器以提高模型的多样性,减少过拟合现象;其二,对每个选定的学习器进行参数优化,以提高模型的精度和泛化性能。通过模型的优化组合和调参,最终选择随机森林[24](rf)、极端树[25](et)、梯度提升树(GBDT)、XGBoost[26]和Catboost作为初级学习器,选择线性回归(lr)作为元学习器,所有模型基于python搭建,建立过程如下:① 通过模糊数学模型获取初始训练数据集,采取8∶2划分,80%数据用作训练集,20%数据作为测试集。② 选择随机森林(rf)、极端树(et)、梯度提升树(GBDT)、XGBoost和Catboost作为初级学习器,使用网格交叉搜索确定模型参数[27]。③ 构建一个1×830、1×208和5×208的矩阵;使用5折交叉训练,每一折训练166个训练集样本,同时预测每一折的208个测试样本。每一折预测产生166个预测值,堆叠成1×830的次级训练集数据矩阵;每一折预测形成1×208测试集预测值,填充后形成5×208的预测值矩阵,取平均得到次级数据集的预测数据。④ 基于线性回归的元学习器对次级数据集进行训练,从而构建融合5种初级学习器的Stacking模型。

图2 Stacking模型简要流程

图3 k折交叉训练流程

表4 Stacking01模型中各学习器性能指标
2 结果与分析
2.1 模型性能度量
为有效度量模型性能,选取平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R2)为性能度量指标。
(5)
(6)
(7)
Stacking01模型的泛化性能显著优于所有初级学习器,R2系数达0.9858,相较于初级学习器Rf01、Et01、GBDT01、Xgboost01和Catboost01模型有0.2066、0.2168、0.0432、0.0322和0.0063的提升,平均提升幅度为0.1010,表现出显著优势。调用特征重要性指令表明,各学习器特征重要度前6的特征均为有机质、全氮、稳定积温、速效钾、pH和有效磷。为简化分析,将模型特征精简为重要度前6的关键因子并构建Stacking02模型,在表5中展示各初级学习器和Stacking02模型的超参数集及性能度量。
Stacking02模型的MAE、RMSE和R2分别为0.0066、0.0084和0.9529。图4-a展示了模型的线性拟合结果,拟合斜率为0.9438,呈现出优秀的拟合结果。图4-b和4-c分别描述了常规残差分布及其区间占比,所有测试样点的残差均分布在-0.025~0.025,且集中于-0.01~0.01,占总数的77.88%。
2.2 富川县植烟区肥力综合评价预测
使用训练完成的Stacking02模型对研究区肥力进行综合评价预测,其预测结果见表6,研究区IFI的最小值、平均值、25%位点、50%位点和75%位点均高于广西其它植烟区。图5展示了预测结果的空间分布,根据四分位点把IFI划分为4个等级,分别为Ⅳ级(0.720~0.821)、Ⅲ级(0.821~0.851)、Ⅱ级(0.851~0.875)、Ⅰ级(0.875~0.930)。研究区北部综合肥力水平优于南部,位于北部的石家乡、富阳镇、葛坡镇和朝东镇Ⅰ级和Ⅱ级产区占比分别达66.67%、66.67%、61.29%和59.26%,而位于研究区南部的新华乡、莲山镇、柳家乡的Ⅰ级和Ⅱ级产区占比较低,分别为15.79%、11.11%和0。由表7可知,相较于IFI后25%的样点,IFI前25%的样点平均土壤pH低0.36,平均全氮含量高0.30 g/kg,平均速效钾含量高139.01 g/kg,低IFI区域存在土壤pH偏高而全氮和速效钾含量偏低的问题[28-29]。

表5 Satcking02模型中各学习器性能度量和超参数集
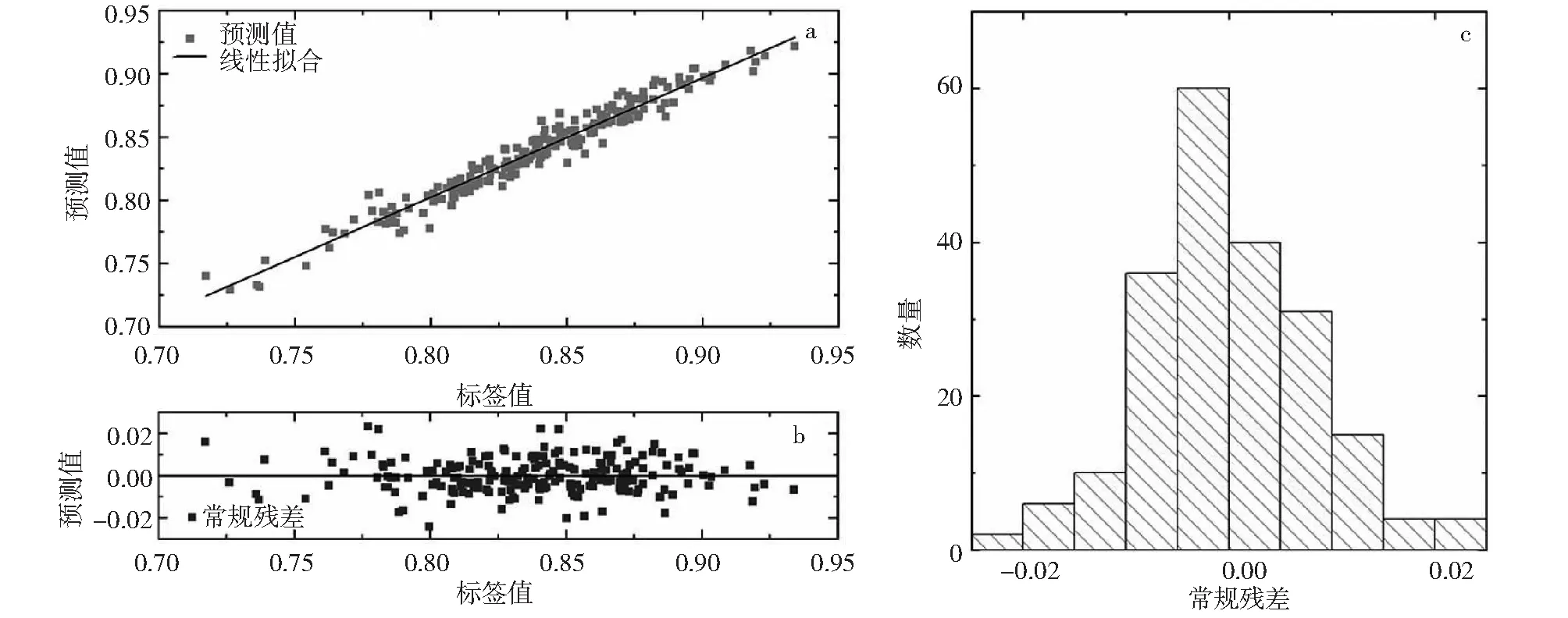
图4 Stacking02模型测试集预测结果可视化

图5 富川县植烟区肥力综合评价空间分布

表6 富川植烟区预测结果与广西其它地区对比
3 讨 论
Stacking算法是通过组合多个模型以生成新模型的集成方法,其第一层学习器的目标是对原始数据进行特征抽取,并利用异质性来表示不同特征。该模型的有效性取决于第一层学习器特征抽取的质量,而第二层是基于对第一层数据的学习,使得模型存在过拟合风险。因此,在训练初级学习器时需要使用交叉验证,并选择简单的模型用于结合初级学习器。
基于6种关键因子构建的Stacking02模型对研究区的预测结果表明,研究区综合肥力水平较好,但低IFI区域存在土壤pH偏高,且全氮和速效钾含量偏低。研究表明土壤pH在5.5~6.5的烤烟质量较好[30],而氮肥和有机肥的施用可致土壤pH下降[31-33],因此需要因地制宜地补充氮肥、有机肥和钾肥。此外,研究区西南红壤分布广泛,其抗蚀能力差且长期连作使土壤全氮、全钾、有效磷和有机质降低,进而导致土壤理化性质恶化和烟叶品质降低[34],建议在扩大南部烟区种植面积的同时,采用稻烟轮作、增加复种指数等管理措施。
4 结 论
相较于各初级学习器,Stacking模型在MAE、RMSE和R2性能度量上均有提升。通过对关键特征因子的优选,Stacking02模型在强大的泛化性能和计算效率上取得了平衡,其R2决定系数达0.9529,表明该模型可扩展至其它地区及作物的土壤综合肥力评价,进而制定针对性的作物利用方案;采用Stacking02模型对研究区进行肥力综合评价,结果表明研究区北部综合肥力水平优于南部。低IFI区域普遍存在pH偏高而全氮速效钾含量偏低的问题,建议合理施用肥料、采用稻烟轮作等管理措施,在增加氮素钾素的同时降低土壤pH。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
杭州师范大学学报(社会科学版)(2021年2期)2021-04-06 03:57:40
中国-东盟博览(旅游版)(2021年2期)2021-03-15 02:25:14
中国化肥信息(2018年7期)2018-08-23 09:12:42
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
安全生产与监督(2016年10期)2016-08-15 00:55:16
西南农业学报(2016年5期)2016-05-17 05:42:37
江西煤炭科技(2015年1期)2015-11-07 03:06:32
