
基于改进双向长短时记忆网络的自动驾驶车辆驾驶意图识别*
2023-09-11 07:40何东赵茂杰王梓楠
汽车工程师 2023年9期
何东 赵茂杰 王梓楠
(重庆交通大学,重庆 400074)
1 前言
高速混行环境下,自动驾驶车辆可以通过车联网技术实时共享彼此的驾驶意图,理解当前的行驶环境,但是人工驾驶汽车无法与车联网发生相关信息的交换,自动驾驶汽车只能通过人工驾驶汽车外在的行为特征对驾驶员的意图(直行、左换道、右换道等)进行推断。
目前,驾驶意图识别方法可以分为基于传统机器学习的驾驶意图识别方法和基于深度学习的驾驶意图识别方法。在基于深度学习的方法中,神经网络模型和长短时记忆(Long Short-Term Memory,LSTM)网络模型应用较为广泛[1]。Huang 等[2]将深度学习神经网络(Deep-Learning Neural Network,DNN)应用于换道行为辨识,对复杂的换道行为特征进行有效拟合,但DNN对时序特征的捕捉能力较弱,因此近年来该模型关注度较低。LSTM 网络因其具有强烈的时序捕捉能力,十分贴合驾驶意图识别的应用场景,是当前研究者关注的重点[3]。Phillips 等[4]通过对采集的十字路口交通数据使用LSTM 搭建意图识别模型,实现对左转、右转和直行意图的预测,验证了LSTM网络对真实采集时序数据特征的捕捉能力。黄玲等[5]提出了一种高速公路人机混行环境下基于LSTM神经网络的换道意图识别模型,该模型在人机混行环境下对车辆换道行为具有较高的识别精度,其改进在于引入均方根传播(Root Mean Square propagation,RMSpro)算法优化神经网络的超参数,以规避人工调参带来的影响。惠飞等[6]使用双向长短时记忆(Bidirectional Long Short-Term Memory,Bi LSTM)网络模型识别驾驶行为中的异常状态,将Bi LSTM 与全连接神经网络(Fully Connected Neural Network,FCNN)相结合,充分发挥了二者的优势。
从研究进程和相应的指标来看,深度学习模型总体表现优于传统机器学习模型。以LSTM 模型为代表的深度学习模型以强大的拟合能力与对时间序列特征的捕捉能力使其在驾驶意图识别上的表现整体强于传统机器学习模型。然而,部分研究还存在周围车辆交互特征考虑不足、忽视驾驶风格、人工调参困难等问题。
本文提出一种基于改进Bi LSTM 网络的驾驶意图识别模型,以目标车辆轨迹序列、驾驶风格、周围车辆的交互特征作为模型的输入,并使用鲸鱼优化算法对模型的超参数进行寻优来规避人工调参。最后对NGSIM数据集的数据进行处理、验证,证明该模型在车辆驾驶意图识别方面具有较高的准确性。
2 改进双向长短时记忆网络
2.1 双向长短时记忆网络
LSTM 神经网络是循环神经网络(Recurrent Neural Networks,RNN)的一类变种,相较于RNN,它通过引入“门”结构和细胞概念控制信息的流动,从而克服了困扰RNN 的梯度爆炸及梯度消失问题。该网络最基本的单元结构如图1 所示,它与RNN 的区别在于,该单元结构中存在遗忘门(Forget Gate)、更新门(Input Gate)、输出门(Output Gate)3 种特殊的“门”结构以及用于储存和传递之前时刻状态信息的细胞(Cell)结构,以实现信息的流通[7]。图1 中,xt为当前时刻t的输入,ht、Ct分别为t时刻的输出信息和存储在细胞中的状态信息为输入门对输入xt进行信息更新后产生的新的输入向量,σ为sigmoid 激活函数,ft、it、Ot分别为遗忘门、输入门、输出门,wf、wi、wo分别为遗忘门、输入门、输出门的权重系数,wc为(t-1)时刻与t时刻的连接权重系数。
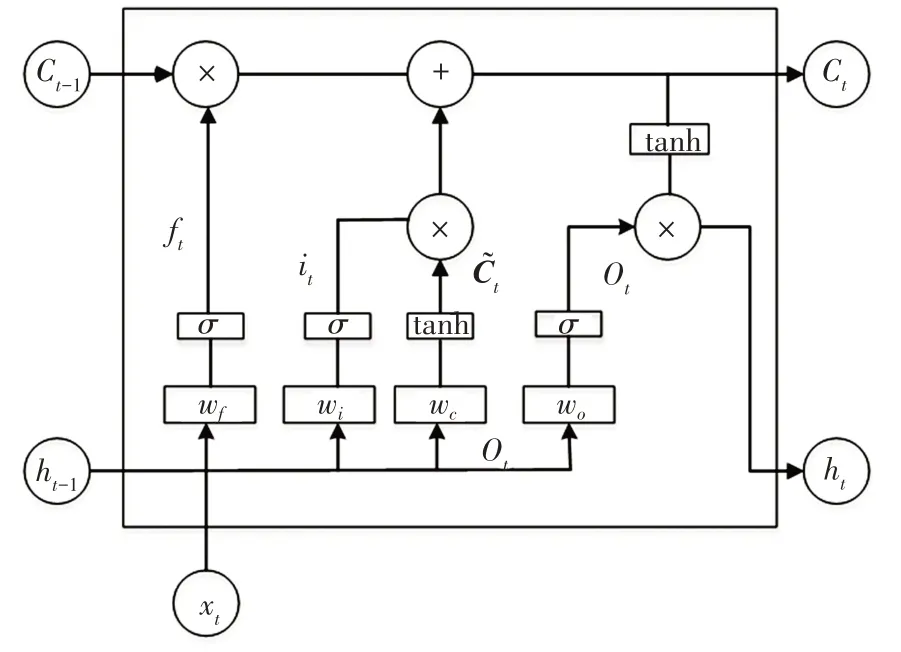
图1 LSTM基本单元结构
LSTM 虽然解决了RNN 存在的问题,但它自身只能利用过去的特征信息,而忽略了未来的信息,故在此基础上诞生了Bi LSTM 神经网络[8]。该模型包含2个独立的LSTM网络,模型所需的参数分别以正向和反向的形式输入到2个LSTM网络中,然后将2 个网络提取出的特征向量进行拼接获得模型最终特征向量,经过正向和反向的特征提取,最终的拼接向量同时拥有过去和未来的信息,其结构流程如图2 所示。为正向运算过程为反向运算过程:

图2 Bi LSTM结构流程
式中,f为激活函数为t时刻正向LSTM 网络的输出分别为正向偏置和权重为t时刻反向LSTM网络的输出分别为反向偏置和权重。
将正向LSTM 网络及反向LSTM 网络的输出向量拼接在一起,即为Bi LSTM网络的输出:
2.2 驾驶意图识别模型
本文基于Bi LSTM 网络搭建驾驶意图识别模型,模型架构如图3所示。
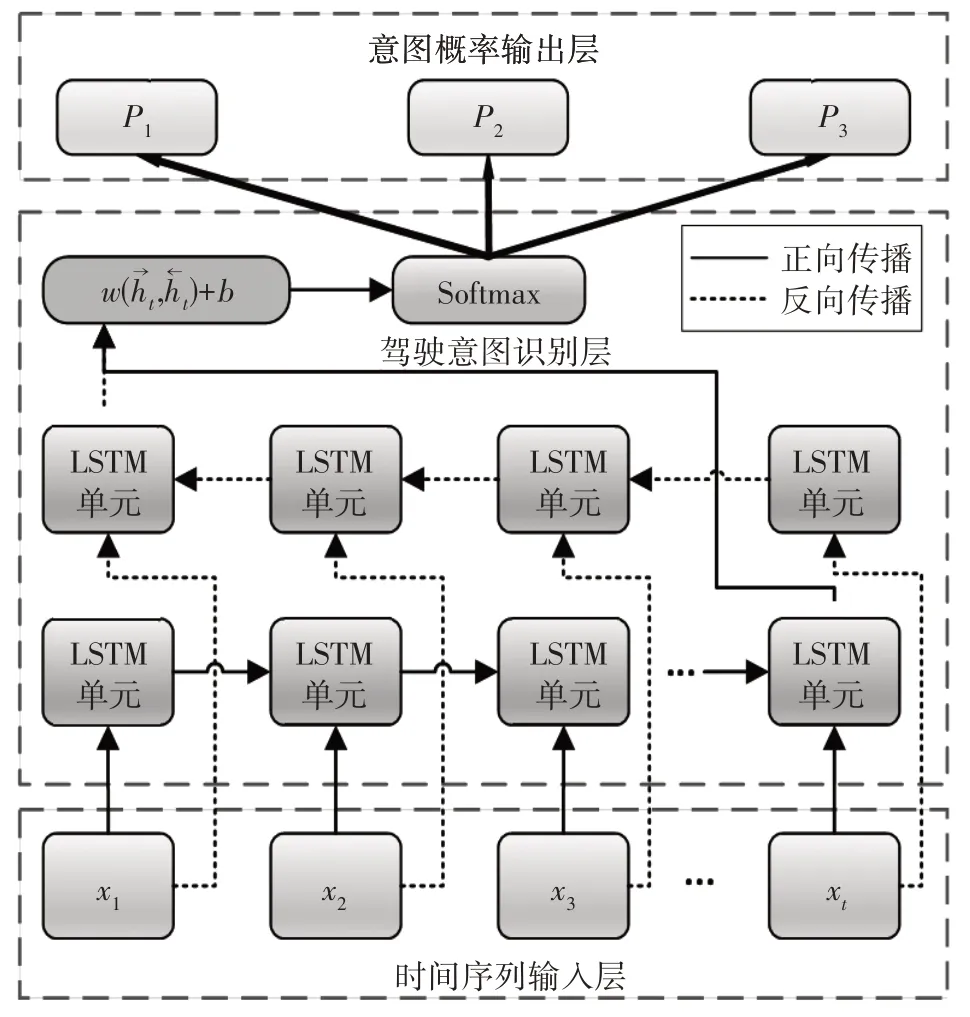
图3 Bi LSTM驾驶意图识别模型
图3中,时间序列输入层将Xt=(x1,x2,x3,…,xt)分别输入正向和反向LSTM 网络,序列中的每一个时刻t的输入xt在该模型中都会获得正向输出和反向输出再进行拼接获得向量将xt'输入到全连接层中获得输出yt=wxt'+b,其中w、b为全连接层的权重和偏置。将yt输入SoftMax 层,通过激活函数获得t时刻输入的左换道、右换道、直行3 种类别各自的概率,然后使用分类层将概率最大的类别输出,作为当前时刻的驾驶意图。
2.3 Bi LSTM 超参数优化
Bi LSTM 网络的超参数对模型的性能影响较大,隐含层节点数、学习率是其中重要的超参数指标。隐含层节点数越多,模型的性能越好,精度也会越高,但需要的计算资源会越大,也越耗时,且节点数超过一定阈值后反而会降低模型的性能,但节点数过小则可能不会收敛,准确率也会降低;学习率的选择决定模型能否收敛,学习率过大时模型难以收敛,学习率过小时模型训练耗时更长,且可能陷入“局部最优”陷阱。
正确选择隐含层节点数和学习率既可以提高训练速度,也能提高模型精度。因此,为获取这2个超参数的最优解,本文使用鲸鱼优化算法(Whale Optimization Algorithm,WOA)对Bi LSTM 的损失函数进行寻优,算法迭代曲线收敛且损失函数结果最小时对应的超参数即为最优解。WOA Bi-LSTM 的算法流程如图4所示。其中,p为行为选择概率,X(t)为t时刻鲸鱼所处的位置,X*(t)为最佳包围位置,Xrand(t)为当前随机鲸鱼个体的位置,D、D'、D"分别为当前鲸鱼个体与最佳个体、最佳包围位置、随机鲸鱼个体之间的距离,A、C分别为权重系数,b为常量系数,l为[-1,1]区间上的随机数。

图4 WOA-Bi LSTM 算法流程
鲸鱼优化算法通过模拟鲸鱼族群的捕猎行为来更新优化参数,该算法包括包围猎物、攻击猎物和随机搜寻猎物3 个环节[9]。每条鲸鱼的位置都代表一个可行解,对于N个待优化参数,可将鲸鱼的位置设定为X=(x1,x2,x3,…,xN)。
使用WOA 模型对Bi LSTM 网络的损失函数进行寻优。优化算法的迭代次数均设置为50次,优化器均使用Adam,损失函数设为交叉熵,WOA- Bi LSTM 模型中的鲸鱼种群数设为30 个,迭代次数设为20 次,Bi LSTM 网络的输入为目标车辆的运动状态特征方程构造的驾驶意图数据集;根据WOA 模型迭代收敛的输出结果,适应度曲线收敛时的适应度对应的鲸鱼位置向量即为最优解,对应的最优隐含层节点数为82个,最优学习率为0.001 6。
3 驾驶意图识别模型仿真分析
3.1 基于改进滑动窗口算法的数据预处理
交互场景中通常存在多个交通参与者,自动驾驶汽车会受到周围车辆间交互的影响,交互特征的选择对于准确识别人工驾驶车辆的意图至关重要。考虑到横向距离对车辆行驶安全的重要性[10],将横向距离作为交互特征之一引入驾驶意图识别任务,设li、di分别为第i辆目标车辆与自动驾驶汽车的横、纵向相对距离,周围车辆交互特征fsocial可表达为:
式中,xi为第i辆目标车与自动驾驶汽车的横、纵向相对距离构成的向量。
交互特征描述的是自动驾驶车辆与周围车辆的交互行为,识别驾驶意图还需选择目标车辆的运动状态特征ft=(v,a,x,y,vy,ay),其中v、a分别为目标车辆的速度、加速度,x、y分别为目标车辆的纵、横坐标,vy、ay分别为目标车辆的横向速度、横向加速度。
不同风格的驾驶员面临相同驾驶场景时产生的驾驶意图有所不同,因此,精准识别目标车辆的驾驶意图还需要引入其驾驶风格特征,其特征向量为:
综上所述,驾驶意图识别模型的输入iv由交互特征、目标车辆运动状态特征、驾驶风格特征构成:
完成特征参数选取后,需要对NGSIM 数据集中的数据进行筛选并提取相应的特征数据,同时,分类模型是有监督学习模型,需要对驾驶意图数据进行车辆行为标注。Deo 等[11]针对该问题提出了一种通过时间标定换道行为的方法,首先寻找车辆在换道点的时刻t,然后将车辆处于区间[t-4 s,t+4 s]的车辆行为标定为左、右换道,但Wang 等[12]通过对NGSIM 数据集的观察发现,许多车辆在t-4 s时刻并未产生换道意图,仍然处于车道保持状态,因此直接根据4 s 的时间标定换道行为存在一定误差。而李文礼等[13]使用横向位移达到车道宽作为换道完成的标定参数,提高了换道行为标定的准确率。受以上研究的启发,本文提出一种结合横向位移的滑动窗口算法对相应数据进行提取并赋予标签,如图5所示。

图5 改进滑动窗口数据提取算法
由图5可知,改进的数据提取方法定义为:找寻车辆换道点St对应的时刻t,然后提取车辆轨迹序列中t-4 s 和t+4 s 时刻对应的采样点并计算二者横向位移的差值。若该差值大于车道宽3.75 m,则将该条轨迹标定为换道成功。若该差值小于3.75 m,则以换道点所在的时刻为中心,在两端取相互对称的2 个采样点S1、S2并计算二者横向位移的差值,当该差值达到3.75 m 时,则将S1对应的时刻t1定义为换道起始时刻,将S2对应的时刻t2定义为换道结束时刻,落入区间[t1,t2]的采样点均为换道过程点。
用以上方法对NGSIM 数据集中的数据进行换道行为标定,并采用前文驾驶意图识别模型进行数据处理,提取时长为4 s的轨迹序列作为试验时模型的输入数据,最终共获取样本数据23 800 组,其中左换道标签数据4 977 组、右换道标签数据6 331组、直行标签数据12 492 组,按7∶1.5∶1.5 的比例将数据集划分成训练集、验证集和测试集。
3.2 仿真结果分析
选择使用不同超参数的Bi LSTM 网络作为试验对比,网络的迭代次数均设置为50 次,损失函数均为交叉熵损失函数,各模型参数设置及在训练集上的训练耗时和最后一次迭代的准确率如表1 所示。训练时各模型损失函数下降曲线及准确率上升曲线分别如图6、图7所示。

表1 不同超参数网络训练集表现

图6 损失函数下降曲线
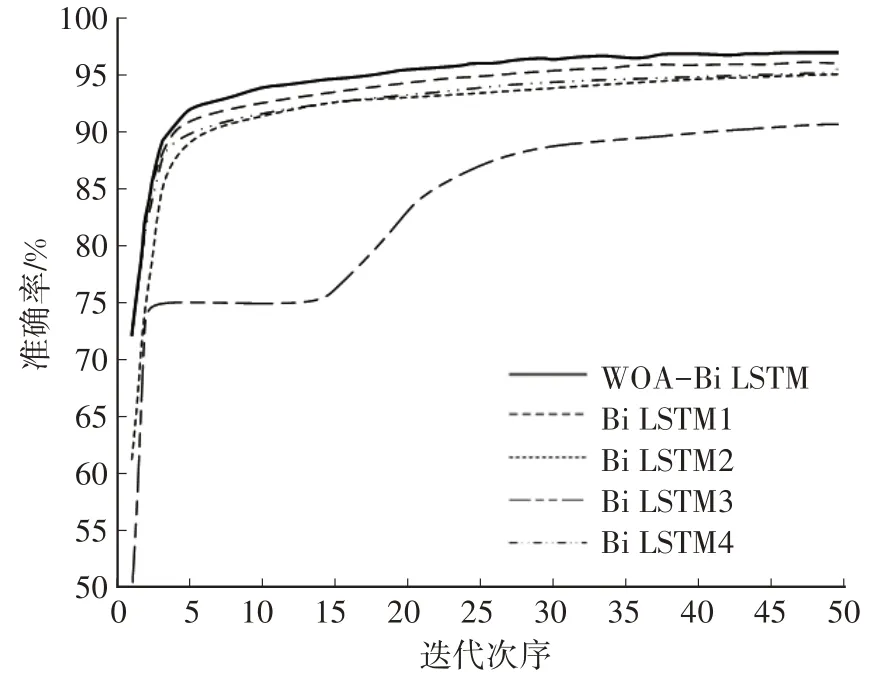
图7 准确率上升曲线
从表1、图6、图7中可以看出,WOA-Bi LSTM 在各模型中损失函数最低、收敛速度最快、性能最优。此外,从表1中可以看出,学习率及隐含层节点数对模型的准确率和训练耗时均有影响。在采用与WOA-Bi LSTM 相同的学习率的条件下,选择Bi LSTM1 和Bi LSTM2 这2 个不同隐含层节点数的网络进行训练时,隐含层节点数增加,模型的准确率提高,但是训练所需的时间和计算资源也会随之增加。此外,当隐含层节点数到达一定阈值后,增加隐含层节点数反而可能导致准确率下降,这在WOA-Bi LSTM 和Bi LSTM2 中均有所体现。当选择与WOA-Bi LSTM 节点数相同的网络Bi LSTM3、Bi LSTM4 进行训练时,相较于较小初始学习率的模型,较大初始学习率的模型训练所需的时间较短,但准确率相对较低。而学习率数值过小,会使网络陷入局部最优,同样降低模型的识别准确率,例如Bi LSTM3 网络。虽然该网络在损失函数上的表现较为优异,但其识别准确率却是所有模型中最低的。
综上所述,选择合理的隐含层节点数和初始学习率对模型的性能有较大影响。使用优化后的Bi LSTM 对测试集数据进行识别,结果如图8 所示。其中:前3 行白色方格给出了模型辨识正确的样本数量和该类驾驶意图辨识正确的样本数占测试集总样本数的比例;深灰色方格给出了模型辨识错误的样本数量和该类驾驶意图辨识错误的样本数占测试集总样本数的比例;第4 列浅灰色方格给出了模型对各类驾驶意图辨识正确的样本数占该类别驾驶意图总样本数的比例;第4 行浅灰色方格给出了该类别驾驶意图辨识准确率;第4 行白色方格给出了模型在测试集上的总体辨识准确率。
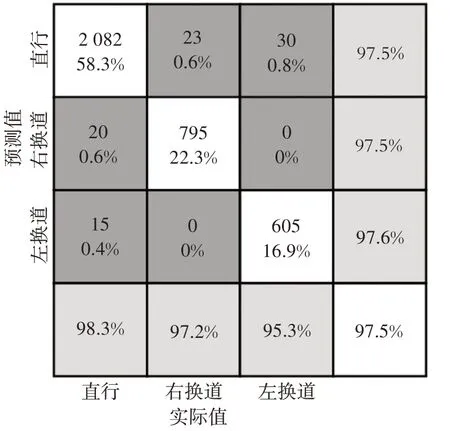
图8 测试集混淆矩阵
从图8 中可以看出,模型在测试集上的识别准确率较高,达到97.5%,且模型对右换道数据识别准确率(97.2%)大于左换道数据识别准确率(95.3%),这是因为左换道训练数据相对于右换道较少,模型在训练时,对于右换道特征的理解学习强于左换道,但二者的识别准确率均较高,说明模型对于左、右换道识别能力较强。
4 结束语
本文针对高速混行环境下周围车辆的驾驶意图识别问题,首先,提出一种结合横向位移的滑动窗口算法对NGSIM 数据集的数据进行处理、提取并构造驾驶意图特征数据集,然后基于该数据集提出一种改进双向长短时记忆网络驾驶意图识别模型,并使用鲸鱼优化算法对该模型中的学习率和隐含层节点数进行超参数优化,以规避人工调参对模型性能的负面影响。通过对比发现,鲸鱼优化算法获得的最优超参数可有效提高模型的识别准确率。在NGSIM 数据集测试集上,模型的识别准确率达到了97.5%,左、右换道和直行的识别准确率分别为95.3%、97.2%、98.3%,识别耗时为1.35 s,表明该模型能够实时精确识别驾驶意图,为周围车辆的轨迹预测提供帮助。
猜你喜欢
幼儿100(2022年41期)2022-11-24
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
法律方法(2021年3期)2021-03-16
数学大王·趣味逻辑(2020年9期)2020-09-06
小天使·二年级语数英综合(2019年4期)2019-10-06
动漫星空(2018年4期)2018-10-26
小学阅读指南·高年级版(2014年2期)2014-05-27
