
基于深度学习的电影数字修复系统研究
2023-09-07 05:27陈佳辉范正辉黄东晋丁友东
现代电影技术 2023年8期
于 冰 陈佳辉 范正辉 相 雪 黄东晋 丁友东
上海大学上海电影学院,上海 200072
1 引言
随着计算机技术和图像视频处理技术的进步与完善,电影的数字化修复取得长足发展,多家商业公司推出数字化修复解决方案,如Digital Vision Phoenix、DaVinci Revival、HS - ART Diamant、MTI Film DRSTMNOVA 等。中国电影资料馆、中央宣传部电影卫星频道节目制作中心、意大利博洛尼亚电影资料馆(Fondazione Cineteca di Bologna)及德国茂瑙基金会(Friedrich Wilhelm Murnau Stiftung)等国内外多家机构均修复了大量珍贵影像。
近几年,大数据、云计算、人工智能(AI)等技术的跨越式发展为电影行业注入了全新动力,人工智能在电影领域的应用颇多,诸如剧本创作、三维建模、电影剪辑及后期制作等。作为人工智能的分支,深度学习(DL)在图像和视频处理领域大放异彩,电影修复与增强的智能化系统也陆续被提出。国家中影数字制作基地研发的“中影·神思”人工智能图像处理系统[1],采用生成式对抗网络(GAN)、循环网络(LoopNet)等技术,实现影片画面质量提升、图像去场(Deinterlace)、图像修复及分辨率提升等效果;爱奇艺推出ZoomAI 技术[2],实现划痕修复、超分辨率增强、智能插帧、色彩增强等功能,完成多部影片的修复;此外,部分电影修复商业软件也同样加入了自动修复功能,借助计算机图形学(CG)及人工智能技术,有效提升影片修复效果。
本文面向损伤修复与画质增强任务,通过应用深度学习算法,研究电影修复的智能化处理方法,探索电影修复软件自主创新的途径。本文主要研究污损去除、缺失修复算法,进而研究基于深度学习的修复与增强系统。
Kim 等[3]提出一种深度盲视频去字幕网络(Blind Video Decaptioning Network,BVDNet),该网络采用混合编码器与解码器模型,编码器由一个三维卷积神经网络(CNN)与一个二维CNN组成,解码器是一个二维CNN;BVDNet 网络的编码器从目标帧的相邻帧以及已修复的前一帧中聚合时空上下文信息,而解码器则重建目标帧实现修复。Iizuka 等[4]提出一种端到端的老电影修复网络(Deep Remaster,DR),通过半自动的方式实现损伤去除、画质增强、黑白上色;该网络包括修复与上色两个子网络,修复网络由三维时间卷积组成,实现灰度视频的损伤去除与视频增强,上色网络在源参考注意力(Source-Reference Attention,SRA)层的引导下借助已上色的关键帧完成视频的彩色化。Zeng 等人[5]提出了联合时空Transformer 网络(STTN),首次将Transfomer 应用到视频修复任务中,网络模型分为3 部分:编码器、时空Transformer、解码器。时空Transformer 借助注意力机制沿着空间和时间维度寻找合适的内容并填充缺失区域,它可以同时填充所有输入帧中的缺失区域,解决了之前逐帧修复方法存在时序不一致的问题。Liu 等人[6]提出了解耦的时空Transformer(DSTT),包含时间解耦的Transformer和空间解耦的Transformer,使模型可以从时间和空间维度上寻找到更加合适的内容来填充缺失区域。Liu 等人[7]提出了一种可以融合更多信息的新型Transformer(Fuseformer)模型,使用常规的注意力在所有的特征图上进行全局查询,为缺失区域寻找填充内容。
2 基于深度学习的电影修复算法研究
为提升修复效率,本文提出两种基于深度学习的电影序列修复算法:(1)基于注意力循环时间聚合网络的污损去除算法;(2)基于Transformer 的大面积缺失补全算法。
2.1 基于注意力循环时间聚合网络的污损去除算法
2.1.1 算法介绍
为实现对电影划痕与斑块等损伤的去除,深度模型既要检测到画面中的这类损伤,又要用新的内容替代损伤区域,这实际上属于盲修复的研究范畴。本文引入循环时间聚合框架,提出一种注意力导向的堆叠生成式对抗网络(GAN),在保持时空一致性的前提下,采用由粗到细的两阶段方式,实现老电影画面损伤的自动去除。在此基础上,提出一种针对老电影损伤修复的时空参考注意力(Temporal-Spatial Reference Attention, TSRA)层,该层使得网络能在第一阶段的损伤预测结果引导下,更好地利用时域非局部相似信息,完成损伤的去除。
本节算法的生成网络由两个子网络构成,第一个子网络用G1表示,第二个子网络用G2表示,生成网络表示为表示通过第一阶段子网络G1模型修复后的序列,表示中的第t帧,表示中从第t-L帧开始到第t- 1 帧的连续L幅序列帧,表示中从第t-L帧开始到第t帧的连续L+ 1 幅序列帧。生成网络的整体架构如图1所示,描述如下。
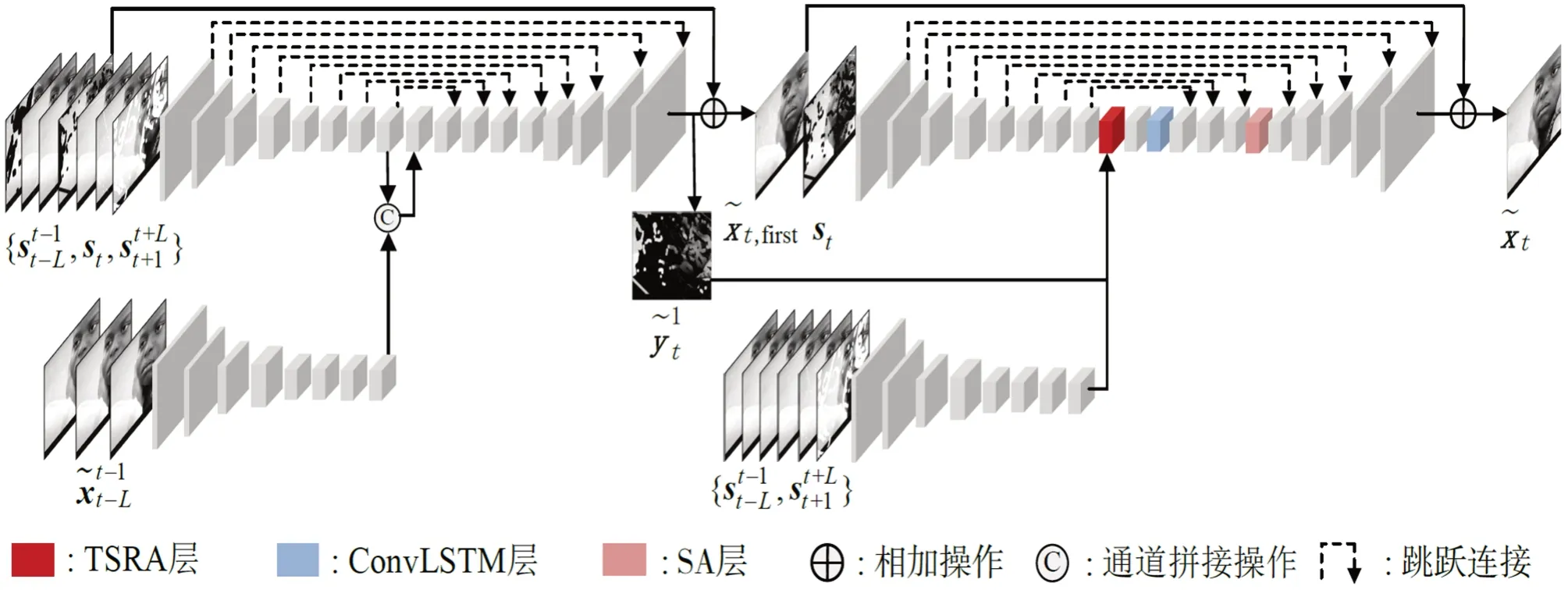
图1 基于注意力循环时间聚合网络的电影污损修复框架
第一阶段子网络G1有两个输入分支,对于当前帧st的修复,分别接收与,然后两个分支输出的特征经过通道拼接聚合后输入到后续的单一分支。最后,输出的结果与当前帧的输入st相加得到第一阶段网络的输出,运算过程如式(1)所示。
首先,第二阶段子网络G2有两个输入分支,分别接收与。其次,两个分支输出的特征与第一阶段的预测残差图像共同输入到本节提出的TSRA 层。再次,输出特征经过一个卷积后输入到ConvLSTM 层,经过三个卷积后输入到基于二维卷积的自注意力(Self-Attention,SA)层[9]。复次,经过一个卷积与四个反卷积以后输出预测残差图像。最后,输出的预测残差图像与第一阶段的输出x͂t,first相加得到最终的修复结果,运算过程如式(2)所示。其中,是模型G2(·,·)输出的预测残差图像。
在本节算法的生成网络中,有两点针对老电影损伤修复的重要设计:(1)预测残差图像与当前帧的相加操作,可以使网络将注意力集中在损伤的像素上,并防止帧的全局信息丢失,这点对老电影修复任务而言,有助于网络不改变除损伤外的其他像素值。(2)本节算法采用逐帧修复的方式,除在输入方面充分利用时域信息外,还引入了ConvLSTM层,通过逐帧依次相连的方式,进一步提升序列修复结果的时空连续性。
本节算法的判别网络有两项,分别用DI与DV表示,网络结构均采用多尺度PatchGAN 结构[10]。在第一阶段,DI接收一组帧输入:或,DV接收的输入为:或。在第二阶段,DI接收一组帧输入:或,DV接收的输入为:或。
本节网络的目标函数包括六项,分别是关于DI的GAN 损失、关于DV的GAN 损失、感知损失、风格损失、时域连续性损失、重建损失,六项损失项的加权取和,得到联合目标损失。本节网络分两个阶段,第一阶段网络与第二阶段网络的优化目标均为以上六项的加权和。网络训练阶段分为三个步骤:(1)采用联合目标损失对生成器G1与判别器DI、DV训练;(2)固定G1,采用联合目标损失对生成器G1、G2与判别器DI、DV训练;(3)采用联合目标损失对生成器G1、G2与判别器DI、DV训练。另外,本节网络使用Adam 算法[11]进行了优化,学习率为0.0002,网络的权重由均值0和标准偏差0.02的高斯分布初始化。
2.1.2 实验数据集
本节算法的数据集包括两个部分,分别是自建的老电影损伤数据集以及Youku-VESR视频[12]数据集。
(1)本节构建的损伤数据集包含989 段序列,每段序列包含100 帧图像,共98,900 幅图像,包括了各类划痕、斑块及污损。通过三种途径构建:第一种,在互联网上通过关键词进行搜索,并下载合适的污损序列;第二种,通过特效软件合成数据;第三种,选取文献[13]的随机损伤掩膜。在数据集划分方面,训练集选取889 段,验证集选取50 段,测试集选取50段。图2展示了自建的损伤数据集。

图2 本节构建的老电影损伤数据集示例
(2)Youku-VESR 数据集是为视频增强任务而设计,涵盖各种类别的影视内容,包括1000 段1080P 的视频片段,每段视频100 帧,包含降质集与原始集。本节算法仅选用Youku-VESR 的原始集,并调整为432×768 的灰度图像。在数据集划分方面,训练集选取900段,验证集选取50段,测试集选取50段。
自建损伤数据与Youku-VESR 视频数据两者随机结合为老电影损伤帧。合成方式为:第一,通过Youku-VESR 视频帧与损伤帧相加或相减来获取合成帧;第二,为尽可能模拟不同程度的损伤,在合成之前,需要为损伤数据乘以一个[0,1]之间的随机系数。另外,为提高训练模型的泛化能力,对Youku-VESR 视频数据进行扩展,扩展方式包括图像的水平翻转、尺寸调整、亮度调整、对比度调整以及添加噪声等。图3展示了合成的老电影损伤帧示例。

图3 合成的老电影损伤帧示例
本节将所提出算法与两种较为先进的同类视频修复方法进行比较。(1)DR 方法[3]:该方法是国际上较为有效的老电影修复神经网络模型。(2)BVDNet方法[4]:该方法是目前较为先进的用于盲视频修复的神经网络模型,可实现老电影的修复任务。为保证实验对比的有效性,以上所有网络模型都使用相同的数据进行重新训练。本节使用三种定量标准对测试数据集评估提出的方法和其他方法。在空域方面,采用峰值信噪比(PSNR)和结构相似性(SSIM)指数,用于反映结果在像素级别与真实图像的接近程度。在时域方面,采用稳定性误差(SE)[14],用于反映测试视频的视觉连贯性。如表1所示,可以看出本文方法相对其他方法,在定量指标上表现最优。
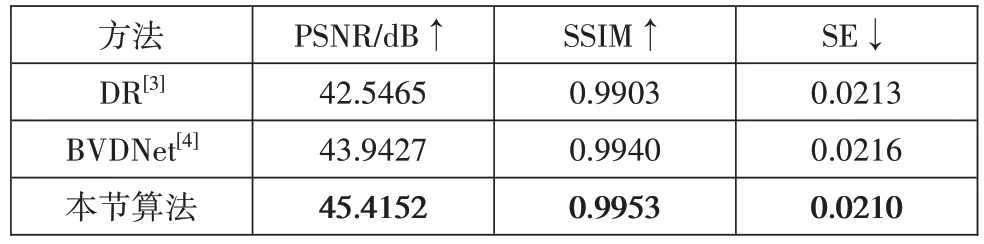
表1 本节算法在污损去除测试集上修复结果对比
2.1.3 实验结果分析
为了验证本节在自建数据集上训练的网络模型对于实际老电影数据的修复效果,笔者选取《骑士》(Knight)、《淘金记》(The Gold Rush)、《秋海棠》(1943)等三部电影的损伤片段。本节所选的三部电影片段,损伤涵盖了亮划痕、暗划痕、亮斑块、暗斑块等多种类型,且损伤大小与分布均有一定的代表性(图4、5、6),应用本节方法后能够较多地实现画面中损伤的修复,且修复后的区域很难被察觉曾有损伤痕迹,满足人眼视觉感知需求。本节算法对于损伤类型的鲁棒性较强,对不同大小及亮度的损伤均能够较好地检测与消除,从而实现老电影的自动修复。

图4 影片《骑士》(Knight)修复结果

图5 影片《淘金记》(The Gold Rush)修复结果

图6 影片《秋海棠》(1943)修复结果
2.2 基于Transformer 的大面积缺失补全算法
2.2.1 算法介绍
在解决修复问题时,一般需要用户手工标记或采用相关算法自动标记待补全的区域,这些区域往往是用户主观选择的修饰对象。一旦确定待补全区域,修复方法自动或半自动的执行剩下的工作,实现缺损的补全。修复是一种病态的逆问题,没有明确定义或唯一解决方案,在老电影修复等应用情境下,希望修复方法填充的内容尽可能接近缺失或损伤前的信息,而另一些应用情境修复目的是隐藏原始图像或视频的某些部分,如视频目标移除,其修复结果只需满足感知自然即可。
以往基于Transformer 的视频修复方法[15],没有足够重视视频帧之间的连续性,导致注意力查询范围不合理。如果查询范围过大,则需要较大的计算量,导致训练时间变长;如果查询范围过小,则有可能在这个范围内查询不到合适的填充内容,而注意力查询范围不合理最终会影响视频修复的质量。针对上述问题,本节提出基于Transformer 的大面积缺失补全算法,从加强视频帧之间的连续性出发,提出了时间Transformer,有效解决了注意力查询区域范围不合适的问题,给出了合理的查询区域,从而解决了计算量大时找不到合适填充内容的问题。模型由生成网络和判别网络组成,其中生成网络由五个部分组成,分别是编码器、重叠分割模块、8 个级联的时间Transformer、重叠合成模块、解码器。网络架构如图7所示。

图7 基于Transformer 的大面积缺失补全网络架构
在本节中,令X≡{x1,x2,…,xt}表示原始未破损的视频序列,其中x1,x2,…,xt表示单幅的视频帧,t表示原始视频序列的长度;令M≡{}m1,m2,…,mt表示掩膜序列,其中m1,m2,…,mt表示单幅的掩膜图,t表示掩膜序列的长度,与原始视频序列中的单幅视频帧一一对应,表示单幅视频帧的破损区域。
生成网络以原始视频序列X和掩膜序列M作为输入,原始视频序列X∈R(h,w,3),掩膜序列M∈R(h,w,1),此处h、w分别表示视频帧的高和宽,R表示实数集。原始视频序列中的每幅视频帧与掩膜序列中相对应的单幅掩膜图进行逐像素相乘,得到包含缺失区域的视频序列I∈R()h,w,3。包含缺失区域的视频序列I经过编码器得到潜在特征集合,其中c 是通道的长度;F经过重叠分割模块后得到潜在特征集合,其中d是通道的长度;E经过8 个级联的时间Transformer 后得到潜在特征集合͂经过重叠合成模块得到潜在特征集合͂经过解码器得到修复后的视频序列,其中y1,y2,…,yt表示修复的单幅视频帧,t表示视频序列的长度,Y∈R(h,w,3)。
时间Transformer 包含两个归一化层、时间注意力和融合前馈层,其作用是从潜在特征中查找合适的内容填充缺失区域。时间注意力是时间Transformer 的核心,它包含维度切分、上下时间注意力、左右时间注意力、维度拼接和线性层。时间Transformer 如图8(a)所示,时间注意力如图8(b)所示,左右时间注意力如图9(a)所示,上下时间注意力如图9(b)所示。
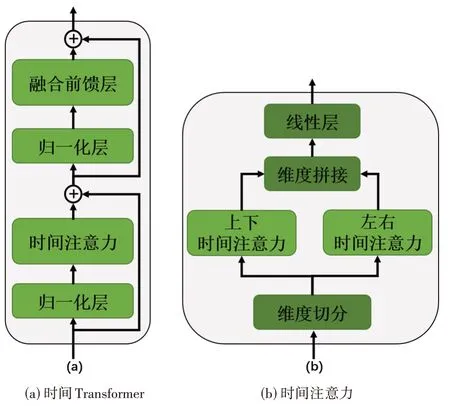
图8 时间Transformer 和时间注意力

图9 左右时间注意力和上下时间注意力
判别网络使用T-PatchGAN[16]判别器,其输入为修复后的视频序列Y和原始视频序列X。本节网络的目标函数由三个损失项组成,分别是破损区域重建损失、有效区域重建损失和GAN 损失,所述目标函数表达式如式(3)所示:
其中,L表示目标函数,Lhole表示视频帧中破损区域的平均绝对误差,Lvalid表示视频帧中未破损区域的平均绝对误差,Ladv表示关于判别器的GAN 损失;λhole、λvalid和λadv分别是Lhole、Lvalid和Ladv所对应的权重系数,Lhole取值为1,Lvalid取值为1,Ladv取值为0.01。
Lhole的表达式如式(4)所示:
Lvalid的表达式如式(5)所示:
其中,Y为修复后的视频帧集合,X为原始视频帧集合,M为掩膜图集合,⊙表示逐像素相乘;‖ ‖表示计算算术平均值。
2.2.2 实验结果分析
本节算法使用两个数据集:YouTube-VOS[17]和DAVIS[18]进行训练与测试;YouTube-VOS 的训练集包含3471 个视频,测试集包含541 个视频;DAVIS 包含150 个不同场景的视频,该数据集仅用于评估,没有用于训练。训练时,本模型仅在YouTube-VOS 的训练集上进行训练。评估时,在YouTube-VOS 测试集以及从DAVIS 中随机抽取50 个视频进行评估。本节将所提出算法与两种基于Transformer 的视频缺失补全方法进行比较。(1)DSTT[6]:该方法采用先进的Transformer 框架,包括时间解耦和空间解耦模块,实现时间域和空间域的联合补全。(2)Fuseformer[7]:该方法是目前较为先进的缺失补全方法,通过融合更多信息,提升修复结果质量。为保证实验对比的有效性,以上所有网络模型都使用相同的数据进行重新训练。采用PSNR、SSIM、VFID 等指标进行评估,定量对比结果如表2 所示。可以看出本文方法在定量指标上表现较优。为了验证本节算法的实际效果,选取越剧电影《孙悟空三打白骨精》中的片段(图10)和DAVIS 数据集中的一个随机视频序列(图11)。《孙悟空三打白骨精》片段中包含的破损情况不一、大小不等、形状各异的破损区域,真实地反映了老电影中的破损情况;DAVIS 数据集中的随机视频序列用来展示本算法用于目标移除的效果。本节算法能够修复大面积破损区域,修复结果在空间与时间维度上均符合要求。
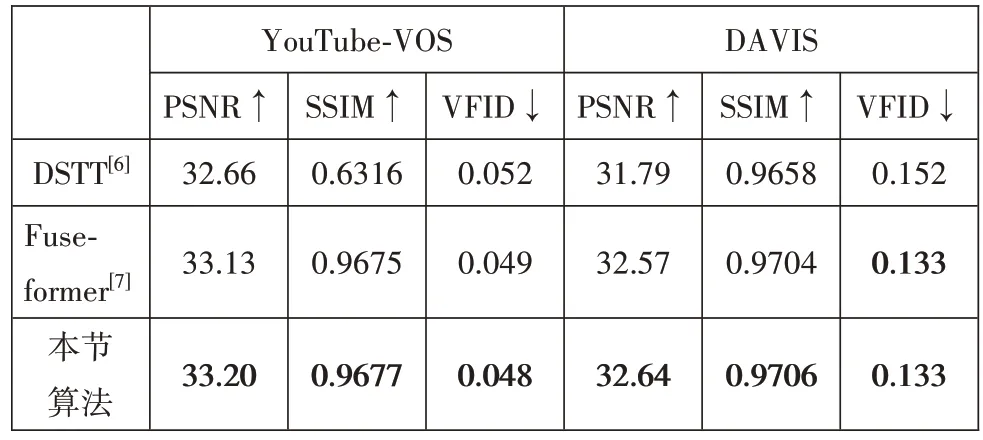
表2 本节算法在缺失补全测试集的修复结果对比

图10 越剧电影《孙悟空三打白骨精》修复结果

图11 DAVIS 中视频的目标移除结果
3 基于深度学习的电影修复系统研发
3.1 本文算法及系统的实验环境
本文提出的电影修复系统及算法,硬件环境为配备NVIDIA GeForce RTX 3090(24GB)显卡的图形工作站,软件环境包括Ubuntu 22.04 操作系统,结合PyTorch 深度学习工具,并采用Python 编程实现。
3.2 基于深度学习的电影修复系统流程
在电影修复方面,由于早期电影胶片材质的特殊、保存条件的恶劣以及拷贝播放的耗损等原因,大量珍贵电影胶片因物理或化学作用而遭受严重损坏,从而导致数字化后出现闪烁、抖动、划痕、斑块、噪声、污点以及大面积破损等问题。在此情况下,电影视觉效果大打折扣,亟需采用数字修复技术手段进行修复与保护,以期达到改善影像资料质量的目的。通过实验研究,本文把应用人工智能修复电影分为四个主要步骤:(1)污损去除:包括噪声、划痕及斑块等污损修复。(2)缺失补全:包括大面积破损补全、缺帧修复等。(3)画质增强:包括分辨率提升(如低分辨率到高清、2K、4K、8K分辨率的转换)、帧率提升(如16FPS 或24FPS 到48FPS、60FPS 的转换)等。(4)色彩增强:包括黑白影片的上色、褪色修复等。除此之外,还有预处理和后处理等两个步骤,主要涉及去闪烁与去抖动等操作。本文系统修复流程如图12所示。

图12 基于深度学习的电影修复系统流程
对于待修复的视频序列,根据损伤类型、选择性或全部依次经过预处理、污损去除、缺失补全、画质增强、色彩增强及后处理等步骤,经过视频鉴定后,输出修复后的视频序列。本文系统采用第2 节自研的污损去除和缺失补全功算法,以及基于像素流的视频上色算法[19]。除此之外,本文引入基于缺陷图谱的神经滤波盲视频去闪烁[20]、深度卷积网络去抖动[21]、深度盲去噪算法[22]、深度中间流估计插帧[23]、基于BasicVSR 的视频超分辨率[24]等算法,完善整个修复流程。需要说明的是,对于所采用的算法,均需在自建的电影修复数据中训练与调参,以期获得较优的修复结果。
3.3 基于深度学习的电影修复系统设计
根据上文实验总结的电影智能修复流程,笔者设计了基于深度学习的电影修复系统。如图13 所示,系统功能分为基础功能、修复增强功能和其他功能三个部分。基础功能包括打开、保存和视频播放等;修复增强功能包括视频去噪、视频去污损等多种修复方法;其他还包括掩膜生成和运动估计等辅助功能。

图13 基于深度学习的电影修复系统功能架构
该系统主要包含主界面、功能弹窗和掩膜生成弹窗等操作界面。主界面(图14)包含两个播放窗口:左窗口播放原视频,右窗口播放修复或者增强后的视频。通过逐帧播放,有利于对处理前后的视频进行对比。功能弹窗界面如图15 所示,选项卡的每项对应一类功能,并包含该项功能相应的设置选项。每项选项卡均分为两个部分:上半部分是对应人工智能模型的处理界面,下半部分是开始按钮和处理过程的显示窗口。设置完成“AI 模型”及参数后,点击“开始”按钮,人工智能模型启动推理处理运算,显示窗口即会输出设置信息与模型的处理过程。
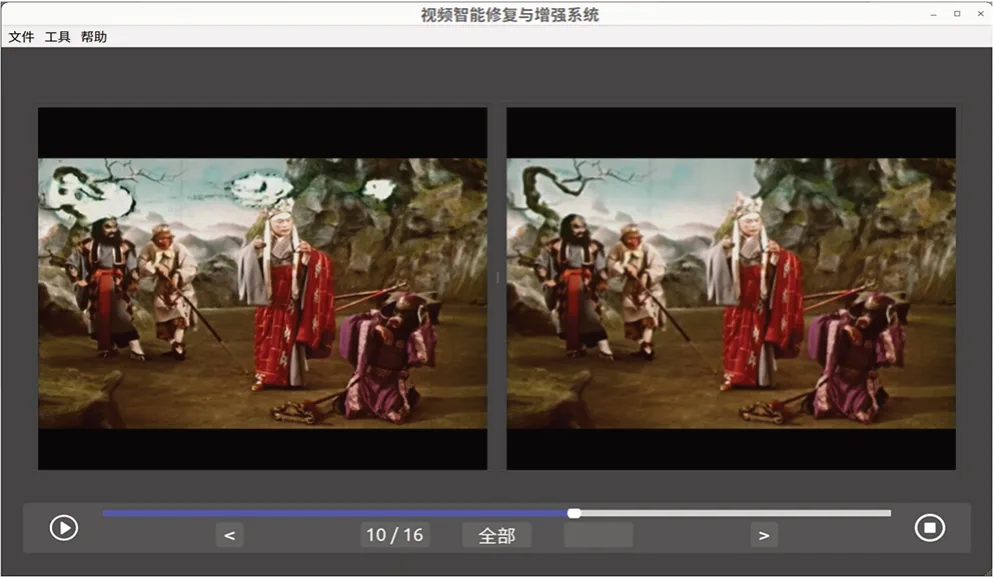
图14 基于深度学习的电影修复系统主界面
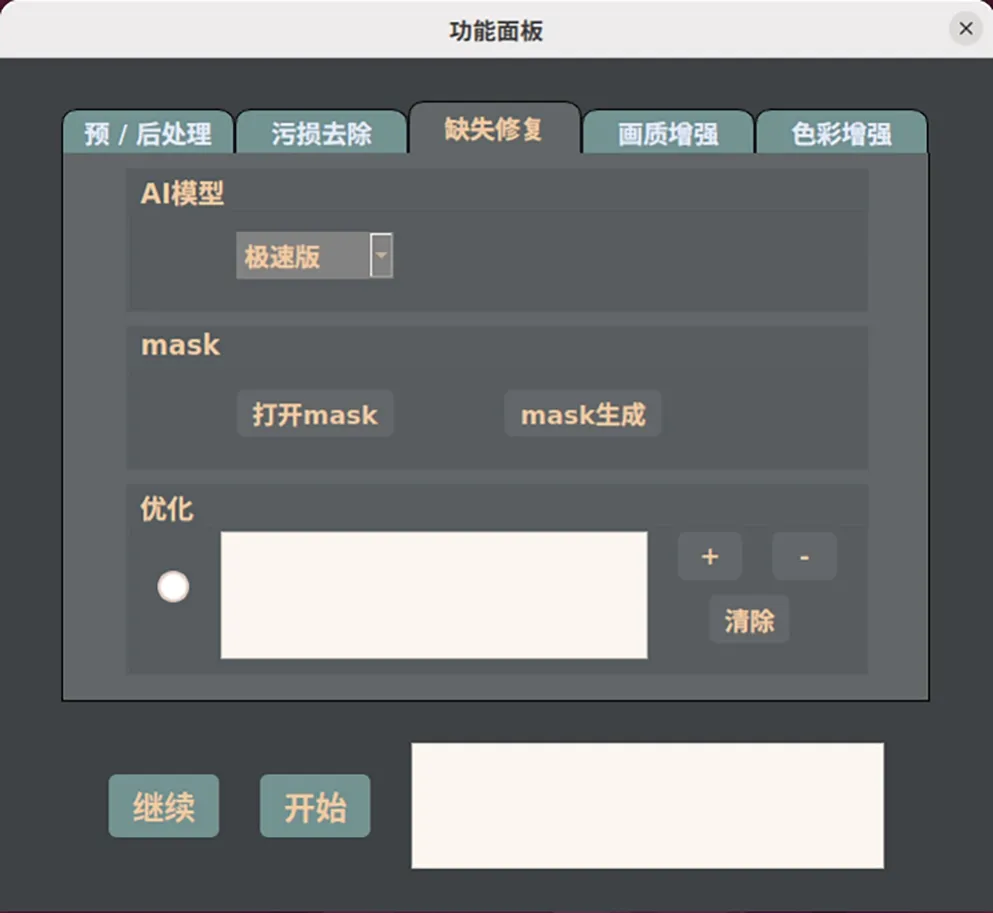
图15 功能弹窗界面
4 总结
修复是电影保护与编辑的重要手段,其理论与方法创新将对数字资源的高效利用产生深远影响。针对该问题,笔者设计了基于人工智能的修复系统,将深度学习技术应用到电影视频的处理中,提高了处理的速度与质量。该系统具备多种修复与增强功能,可以解决电影的综合修复问题。电影修护是一个综合处理过程,在未来的工作中,仍需进一步优化人工智能模型,以期实现电影画质的全面提升。
作者贡献声明:
于冰:算法设计与实验测试、论文撰写,全文文字贡献40%;
陈佳辉:算法、系统研究与测试、论文撰写,全文文字贡献30%;
范正辉:系统研发、论文撰写,全文文字贡献5%;
相雪:系统研发、论文撰写,全文文字贡献5%;
黄东晋:论文撰写与修订,全文文字贡献10%;
丁友东:论文撰写与修订,全文文字贡献10%。
猜你喜欢
计算机仿真(2022年9期)2022-10-25
导航定位学报(2022年5期)2022-10-13
中国体视学与图像分析(2021年3期)2021-11-24
数学小灵通·3-4年级(2021年6期)2021-07-16
女报(2020年7期)2020-08-17
英语文摘(2020年12期)2020-02-06
资源节约与环保(2019年11期)2019-01-21
环境保护与循环经济(2017年5期)2018-01-22
制造技术与机床(2017年10期)2017-11-28
科技资讯(2016年21期)2016-05-30
