
顾及多分辨率特征的复合字典城中村识别方法
2023-09-05 06:27邢若芸冉树浩高贤君杨元维
测绘通报 2023年4期
邢若芸,冉树浩,高贤君,,杨元维,2,4,方 军
(1. 长江大学地球科学学院,湖北 武汉 430100; 2. 湖南科技大学测绘遥感信息工程湖南省重点实验室,湖南 湘潭 411201; 3. 湖南科技大学地理空间信息技术国家地方联合工程实验室,湖南 湘潭 411201; 4. 城市空间信息工程北京市重点实验室,北京 100045)
城中村是指由于城市迅速扩张、耕地征用,而保留的宅基地等集体建设用地区域[1-2]。城中村区域的精确检测识别在统筹城乡发展和改善民生方面具有重要意义。城中村内部建筑物混杂密集,缺乏合理规划和有效管理,传统人工走访调查方式费时费力,难以满足大区域监控、周期性更新的现实需求,亟需一种面向场景的城中村快速识别和监控方法。
目前基于高分辨率遥感影像的场景识别方法主要包括特征分类法、语义分类法、学习分类法[3]。特征分类法主要是提取颜色纹理等特征,对图像进行描述,如文献[4]利用随机森林分类器对基于纹理、形态剖面、偏振特征的空间图像描述符进行城中村提取。该方法对于简单的分类任务有较好的效果,但受限于特征算子的提取能力,在复杂场景下分类精度较低。文献[5—7]提出了基于隐狄利克雷分配(latent Dirichlet allocation,LDA)模型的无监督语义框架,进行目标建筑物的识别,将语义分类法应用于复杂场景分类。词袋模型(bag of word,BOW)是指将每篇文档视为一个词频向量,将文本信息转化为易于建模的数字信息,应用于视觉处理领域,形成了视觉词袋模型(bag of visual word,BOVW)[8],它包含丰富多样的语义信息,并在图像分类和场景识别[9]等领域获得广泛应用。文献[10]设计了基于BOVW的高分辨率影像土地利用分类方法,并在土地利用数据集上取得了较好的分类效果。文献[11]提出了一种针对高分影像的局部-全局特征视觉词袋场景分类器,词典中包含更丰富的特征。随着计算机算力的提升,学习分类法被用于场景识别,通过自学习方式,利用联想反馈机制学习图像特征信息从而实现识别。文献[12]采用视觉词袋模型,将卷积神经网络(convolutional neural network,CNN)[13-14]作为特征提取器,能够从地理场景图像中学习到更丰富的视觉词。文献[15]利用迁移学习的全卷积网络(fully convolutional networks,FCN)提取城中村,取得了较高精度。识别精度与训练样本数据量呈正相关,在训练样本充足的情况下可获得较高的精度,但城中村样本获取难度大,难以实现大范围的普及应用。BOVW不过度依赖训练数据,在小数据集分类任务中,仍然能取得较好的分类精度,且对硬件资源要求不高。但现有的BOVW关注全局特征,而非局部突出区域。本文提出将尺度不变特征转换(scale invariant feature transform,SIFT)滑动格网密集采集(GridSIFT)与多分辨率颜色矢量角特征进行融合的方法,对细节特征与颜色特征进行提取,进而实现城中村的精确识别。
1 顾及多分辨率特征复合字典
传统词袋模型聚焦于局部纹理与结构特征的提取,缺乏对多分辨率特征与光谱信息的挖掘。而在城中村提取过程中,光谱特征作为区分地物类别的有效依据,具有重要的提取价值。因此,本文设计顾及多分辨率特征的复合字典,包含GridSIFT特征提取、多尺度空间矢量角特征提取、字典编码、多特征融合及分类等步骤。
1.1 多分辨率特征复合字典
如图1所示,复合字典的实现过程为:通过提取图像中的特征区域,将相似的区域聚类为一个视觉单词,统计视觉单词出现的频率,以直方图的形式表示,图像被抽象成直方图后进行分类,由分类器完成分类。

图1 多分辨率特征复合字典流程
利用多分辨率特征复合字典模型表示图像的步骤为:首先将每幅影像Ii划分为均匀格网,然后通过滑动窗口G(x,y)在每个窗口提取一个SIFT特征,最后将影像Ii的3层进行Haar小波分解,计算每层的小波系数。
在每个小波分解尺度上提取特征点后,将每层的特征点映射至原图尺度上,得到特征点后计算每个点与周围3×3窗口的颜色矢量角。颜色矢量角θ的取值范围为[0°,90°]。以0.5°为一个区间统计直方图,形成180个一维颜色特征。
假设训练集中有N幅影像,共检测到若干局部特征fij,i=1,2,…,N,j=1,2,…,Si,其中Si为图像i中特征的总数。量化特征形成视觉单词为
(1)
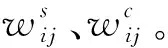
(2)

(3)
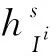
(4)
式中,ws为从训练图像集提取的SIFT特征构建的词汇表。计算完成图像的直方图后,通过直方图融合将其连接形成联合直方图hIi,将式(3)、式(4)合并可得
(5)
图像特征直方图提取后,由分类器完成直方图匹配,对图像进行分类。分类完成后依据空间关系进行识别结果的后处理,对于识别为城中村的影像单元且周围均为非城中村的影像单元,修正为非城中村单元。
1.2 SIFT滑动格网密集采样
SIFT常被用于提取图像的结构特征[16],其所提取的特征点具有良好的稳定性,通常不受尺度、角度、光照化、噪声等信息的干扰。传统SIFT是一种基于全局的特征提取方式,能有效避免特征点冗余,但同时也易造成一些具有代表性的局部特征点被忽略。相较于随机采样,密集格网采样更有效[17]。
1.2.1 SIFT提取原理
传统SIFT特征的提取步骤主要为:①构建尺度空间;②确定关键点;③构建关键点描述符。构建尺度空间时,通过高斯核函数进行构建,完成尺度空间构造后,确定关键点并构建描述符。对比每个点及其周围所有点的大小,即同尺度的相邻8个点和上下尺度的9个点,共26个点,将极值点作为特征点。计算关键点描述符时,为了保证描述符的旋转不变性,需要利用图像局部特征为关键点分配方向,即确定主方向。以关键点为中心选择16×16的区域,利用梯度和方向分布特点可以得到梯度模值和方向。
统计8个方向出现的频率并绘制直方图,直方图的峰值为该点的主方向。将坐标轴旋转至主方向,把关键点的周围区域划分为4×4个子区域,对每个子区域内的所有像素进行梯度方向θ′和梯度模值m′的计算,方法与确定主方向类似。最终得到每个子区域8个方向上高斯加权的梯度幅值之和,即每个关键点得到一个16×8维的描述向量。
1.2.2 特征提取
针对局部关键点被忽略的问题,GridSIFT法通过滑动窗口对场景影像进行SIFT特征提取。首先将场景影像分割为多个像素,即重叠度为4像素、大小为8×8像素的子图像块;然后在每个子图像块中提取一个SIFT特征向量;最后得到225个SIFT特征向量。影像分割过程中,像素重叠值越小,则子图像的重叠度越高,采样率越高。通过选择合适的图像块大小和重叠值,可在保证采样量的同时避免冗余。GridSIFT特征与全局SIFT特征提取步骤基本一致,区别在于选择最大值时,前者中一个窗口只取一个最大值计算SIFT特征向量。采用格网采样而非关键点采样计算SIFT描述子的原因在于,稠密采样能够提取到包含更多图像细节的全局信息[18],且可为每幅图像生成数量恒定的特征。
1.3 多分辨率颜色矢量角直方图(CVAH)
1.3.1 多分辨率特征点提取
在高分辨率遥感影像中,不同大小的建筑物同时存在,尺度差异明显。为实现对不同大小建筑物的准确判别,同时关注城中村等小型建筑局部特征,需进行多分辨率特征点的提取。多分辨率特征点的提取过程如图2所示,其主要原理为,通过小波分解的方法得到多分辨率特征,可以由粗到细提取代表性点作为多分辨率关键点。具体步骤可描述为:

图2 多分辨率特征点提取流程
(1)将影像I转为灰度图像,并进行一次双倍上采样,得到upsampling_I。
(2)对上采样图像进行小波分解,分解为分辨率不同的3层。
(3)将第i层的高频分量{CDi,CVi,CHi}标准化,若同一层像素的3个高频分量均大于0.6,将该点作为备选点。
(4)求3个高频分量之和形成一个分量,在该分量上以备选点为中心的5×5窗口内,若备选点最大则为特征点,反之则删除该点。
(5)分别求3层中的特征点,将3层特征点映射在原图上,映射坐标公式为
(6)
式中,L为小波分解的层数;(x,y)为在小波分解层的坐标;(X,Y)为原图坐标。
1.3.2 基于颜色矢量角的直方图(CVAH)
为提取更丰富的细节与颜色特征,并增强特征字典的稳健性,以构建的颜色矢量角直方图作为颜色特征,并将颜色特征与其他特征融合。在RGB颜色空间中,度量两个像素值间的色差最简单的方式为欧式距离法。欧式距离计算方法简单,具有旋转不变性。然而,RGB颜色模型不是均匀空间,欧式距离对图像的亮度变化非常敏感,而对色调和饱和度的变化不敏感,因此欧式距离很难反映两种颜色的视觉差异。假设在RGB颜色空间中有c1、c2、c3、c44点,两个颜色对(c1,c2)和(c3,c4)的欧式距离相等但视觉差异很大。因此,角度衡量颜色差异优于欧式距离法。
在RGB空间中,颜色矢量角(CVA)表示两个相邻像素的RGB颜色向量之间的夹角,公式为
(7)
式中,(r1,b1,g1)为RGB颜色空间某个像素的颜色向量值;(r2,b2,g2)为与(r1,b1,g1)相邻像素的颜色向量值;θ为两个像素之间的颜色矢量角。
以多尺度关键点为中心,选取周围3×3的窗口,求关键点与局部区域8个像素的颜色矢量角,颜色矢量角反映了关键点和周围点的视觉色差,范围为[0°,90°]。均匀量化颜色矢量角,量化阶距为0.5°,计算每个角度区间的像素数,形成颜色矢量角直方图,形成180个一维的颜色特征。
1.4 字典编码和特征融合
量化特征词时,由于场景尺度、角度及光照的变化,同一特征可能对应多个视觉词[11],不同特征的视觉词之间指代的特征有很大差别,因此在生成视觉词典时需要进行字典编码和特征融合。将SIFT特征通过K-means聚类量化,具有相似特征值的影像单元被聚类为一个视觉词。假设一个n幅影像组成的影像集A={a1,a2,…,an},一幅影像被分为P个子影像单元,提取量化特征描述符X={x1,x2,…,xp},随机聚类得到K个聚类中心C,公式为
(8)
式中,Sj表示聚类中心Cj的特征向量集合。通过计算特征向量xi与聚类中心Cj的最小值,确定代表子影像单元的视觉词,将图像分别按照不同特征视觉词编码后,统计每个视觉词出现的频率,生成具有H1个视觉词柱的特征直方图。与SIFT特征量化相似,颜色特征量化得到具有H2视觉词柱的颜色矢量角特征直方图。最后将两个特征直方图横向拼接,即具有N幅影像经直方图融合后形成(H1+H2)×N维的语义表达。
1.5 图像分类与后处理
特征直方图融合后,利用分类器将特征进行分类。常用的分类器包括支持向量机、随机森林等,本文采用随机森林分类器对影像进行分类。
由于城中村具有大范围聚集出现的特点,因此对识别结果中明显错分的影像单元进行后处理,搜寻空间上无相邻关系的城中村影像单元,改为非城中村。即检索每一个城中村单元,以城中村单元为中心的3×3窗口内若除了中心影像单元外无其他影像单元为城中村,则将该城中村单元修正为非城中村单元。
2 试验结果与分析
2.1 试验设计
为了对本文方法的有效性进行评估,设计对比试验:与经典深度学习方法对比,将本文方法与迁移学习VGG16和ResNet50方法对比;不同特征描述符对比,将SIFT、加速稳定特征(speeded up robust features,SURF)与本文的GridSIFT方法对比;分析多分辨率颜色特征对精度的影响,对比融合多分辨率颜色特征后识别精度。选取总体精度(OA)、回归系数(Kappa)两个评价指标对试验结果进行定量评价分析。
数据源为高分二号遥感可见光影像,空间分辨率为1 m,图像大小为15 960×7980像素。参考城中村实地大小,选取64×64像素大小的无重叠区域,共采集2780幅影像,其中城中村1333幅,非城中村1447幅,按照2∶1的比例划分训练集和测试集。
2.2 与经典深度学习网络对比
为与当前计算机视觉领域常用的深度学习图像分类方法进行对比分析,选取在ImageNet数据上的预训练VGG16[19]与ResNet50[20]模型进行迁移学习[21-22]。神经网络训练次数均为100,学习率为0.001,优化器选择RMSProp,训练集和测试集与本文方法保持一致,试验结果见表1(列最佳值已用粗体突出显示)。

表1 与经典深度学习网络精度对比 (%)
由表1可知,VGG16的分类精度为85.3%,ResNet50的精度为88.1%,ResNet网络在VGG网络的基础上增加了长度,加入Resblock残差模块避免了梯度消失;本文方法的最优精度为90.08%,明显优于VGG16和ResNet50分类方法。
为了评估本文方法的识别结果,与迁移学习的ResNet50识别结果进行可视化结果对比,并选择8个典型区域的识别结果进行详细分析。
如图3所示,与ResNet50相比,本文方法的城中村识别结果与人工目视解译遥感影像结果吻合度更高。在如图4所示的局部放大图中,区域1—4城中村附近建有大量的廉租房或厂房等易混淆建筑,由于密集采样法提取场景全局特征,注重全图特征的提取,因此本文方法在识别时有较高的准确度,ResNet50则易将周围混淆区域与灌木丛错分为城中村。区域5—8城中村边界明显较空旷,ResNet50在识别时将城中村识别为非城中村,存在大量的识别错误。由于本文方法引入了多分辨率颜色特征,对城中村这种小建筑物颜色细节更加敏感,可以将城中村正确识别。

图3 研究区城中村识别结果

图4 典型区域城中村识别结果对比及原始影像
2.3 不同特征描述符对比
试验选择SURF[23]、SIFT及GridSIFT提取特征作为特征描述符,分类器使用随机森林分类器,分类器参数采用交叉验证法确定。复合字典的规模大小取决于词袋中的词数,本文试验中词数为K={90,100,110,120,150,200,300},通过调整K-means聚类数实现。对每个词数大小场景生成的特征向量,重复分类5次,以分类平均值作为最终分类结果。K在90~150范围时,词数与分类精度无显著关系;在150~300范围时,词数与分类精度成反比,词数变大时精度降低,多次试验分类精度的最大最小值之间的差值变大。与SIFT和SURF相比,GridSIFT方法的总体精度和Kappa系数都有明显优势。由表2可知(列最佳值已用粗体突出显示),GridSIFT方法的Kappa值均在75%以上,说明该方法预测结果和实际分类结果有较好的一致性。使用SURF描述符在K为120左右时精度最佳,达80.78%。使用SIFT描述符在K为200左右时精度最佳,达86.57%。使用GridSIFT描述符最佳精度与SIFT最佳精度相比提升2.72%,Kappa系数提升5.48%。

表2 特征描述符精度评价 (%)
2.4 多分辨率颜色特征提取对精度的影响
为了验证多尺度颜色特征提取(CVAH)方法的有效性,分别将SURF、SIFT、GridSIFT特征提取方法与其进行融合,并与单一特征方法作对比。由图5中的对比结果可知,融合CVAH特征后,几种特征提取方式的精度均有所提升,SURF特征与CVAH特征融合后显著提高了精度,但对于CVAH特征,敏感性弱于SIFT和SURF;均匀格网的提取方法相较于极值特征提取方法,特征提取更加均匀丰富,对于其他特征的敏感性低于其他两种方法。SIFT特征与CVAH特征融合后,提升精度的同时,精度与词数之间的相关性变得更弱;在K为90~300范围时,总体精度均大于88%。GridSIFT特征与CVAH特征融合后,也明显提高了分类精度均值。CVAH特征与SURF、SIFT、GridSIFT特征融合后,最佳总体精度分别提升了2.28%、2.10%、0.79%,验证了CVAH特征对提升分类精度的有效性;与SIFT特征相比,GridSIFT+CVAH特征融合后精度提升了4.51%。

图5 融合多尺度颜色特征平均精度对比
3 结 语
本文提出了一种顾及多分辨率特征复合字典高分辨率遥感影像城中村提取方法,通过将GridSIFT与多尺度颜色矢量角融合,可以有效区分色彩显著差异的错分图像。引入多分辨率颜色特征对建筑物细节颜色特征进行提取,精度得到提升。与经典深度学习方法相比,总体精度较VGG16和ResNet50分别高出4.78%和2.28%。与不同特征描述符对比,本文的GridSIFT方法精度均高于SIFT、SURF特征提取方法。
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
建材发展导向(2022年2期)2022-03-08
今日农业(2021年8期)2021-07-28
数学物理学报(2019年3期)2019-07-23
摄影之友(影像视觉)(2018年12期)2019-01-28
家庭影院技术(2018年9期)2018-11-02
现代园艺(2018年2期)2018-03-15
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
市场周刊(2017年1期)2017-02-28
