
基于注意力机制改进残差神经网络的轴承故障诊断方法
2023-09-05 01:19韩争杰牛荣军马子魁崔永存邓四二
振动与冲击 2023年16期
韩争杰, 牛荣军, 马子魁, 崔永存, 邓四二
(1. 河南科技大学 机电工程学院,河南 洛阳 471003;2. 舍弗勒(上海)贸易有限公司(研发中心),上海 201804)
机械故障是风力电设备、航空发动机、高档数控机床等大型机械装备安全可靠运行的“潜在杀手”[1]。故障诊断是用于保障设备安全、平稳运行的重要技术手段,在故障诊断技术的发展的早期阶段,相关研究和工程技术人员大多通过对设备生命周期中出现故障时的具体物理参数或损伤进行相应的记录和分析,从而依靠不断累积的经验知识对设备故障进行诊断[2]。近年来,随着计算机科学发展的进步,轴承故障诊断已由传统方法向智能化方向转变[3],尤其是深度学习方面,基于数据驱动的智能机械故障诊断方法取得了较大发展[4]。
传统的故障特征提取方法主要基于时域,频域和时频域,而时频域分析既包含时域信息也包含频域信息,在轴承故障诊断中得到广泛应用。时频分析方法中小波变换(wavelet transform,WT),短时傅里叶变换(short time Fourier transform,STFT)、希尔伯特黄变换(Hilbert-Huang transform,HHT)及其他改进算法[5-6]等通常将原始时域振动信号转换到时频域上,并提取出信号的统计特征[7],将这些构造出的特征作为故障分类算法的输入。传统的故障分类算法[8-10],属于浅层机器学习的方法,要与特征提取方法结合,使用人工特征提取方法,针对具体的任务,带来了人为因素的干扰,很难应用于所有情况的特征,具有较低的泛化性。
而深度学习是让计算机自动学习特征的方法,能够直接从原始的信号中学习到重要的特征,目前主要的深度学习的方法有卷积神经网络(convolutional neural network, CNN),循环神经网络(recurrent neural network,RNN),自编码网络(auto encoder, AE)[11-12]。随着深度学习在故障诊断中的应用,也随之暴露了一些缺点,比如说随着训练层数和参数的增加,从头开始训练一个大型的深度学习模型要有足够的样本、算力和时间[13],而故障诊断想获取大量数据比较困难。
针对深度学习上述不足,在机械故障诊断领域中引入了迁移学习的方法。在单源域迁移学习中,基于预训练的不同的网络模型,实现模型的迁移,并利用该数据微调预训练模型,实现了较高的故障诊断准确率和训练效率[14-15]。对于多源域迁移学习,Zhu等[16]通过搭建多源域适应网络,实现目标域数据的识别。Li等[17]提出一种适用于任何基于梯度学习规则训练模型的方法,在数字和动作识别试验中取得了较好的试验结果。无论是单源域还是多源域迁移学习,当在同一工况内进行模型迁移训练效果一般较好,但当迁移到不同工况时,尤其是不同工况内无训练样本时,其训练效果将会变得很不理想。
针对迁移学习不同工况训练中存在的不足,提出了一种基于注意力机制改进残差神经网络的轴承故障诊断方法,本算法的创新点在于:
(1) 通过迁移学习方法,利用残差神经网络在二维时频域图像上实现不同工况下样本的直接迁移,是在一定工况训练好模型,直接迁移到其他工况进行测试,相比较传统将不同工况的数据集划分为训练集和测试集的样本迁移,本文提出的网络具有更强的泛化性。
(2) 在注意力机制的基础上,提出了注意力模块中的挤压与激励网络(squeeze and excitation networks, SENet)和卷积模块的注意力模块(convolutional block attention module, CBAM)对残差神经网络进行优化,都达到了优化残差神经网络的目的。SENet模块是只关注通道的注意力机制,CBAM模块是即关注通道,也关注空间的注意力机制,两种模块可以嵌入到现在任何流行的网络。
1 理论基础
1.1 连续小波变换
小波变换包括连续小波变换(continue wavelet transform,CWT)和离散小波变换(discrete wavelet transform,DWT),本文主要对轴承的振动信号分析,采用CWT进行时频域分析。假设Z(t)是输入的原时域信号,连续小波变换可以表示为
(1)
式中:a为伸缩因子;τ为时间平移因子;ψ(·)为小波基函数,是满足一定条件的基本小波函数。
1.2 卷积神经网络
卷积神经网路(convolutional neural network,CNN)是一类强大的处理图像数据的神经网络,传统的CNN模型主要由卷积层、池化层、全连接层和Softmax分类器构成。传统的CNN结构图如图1所示。
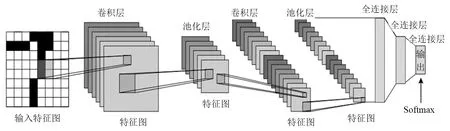
图1 传统的CNN结构图Fig.1 Traditional CNN structure diagram
卷积运算的的数学表达式为
(2)

池化层分为最大池化层和平均池化层,运算符由一个固定形状的窗口组成,以输入步幅的大小在所有区域上滑动,其计算的方式如图2所示。
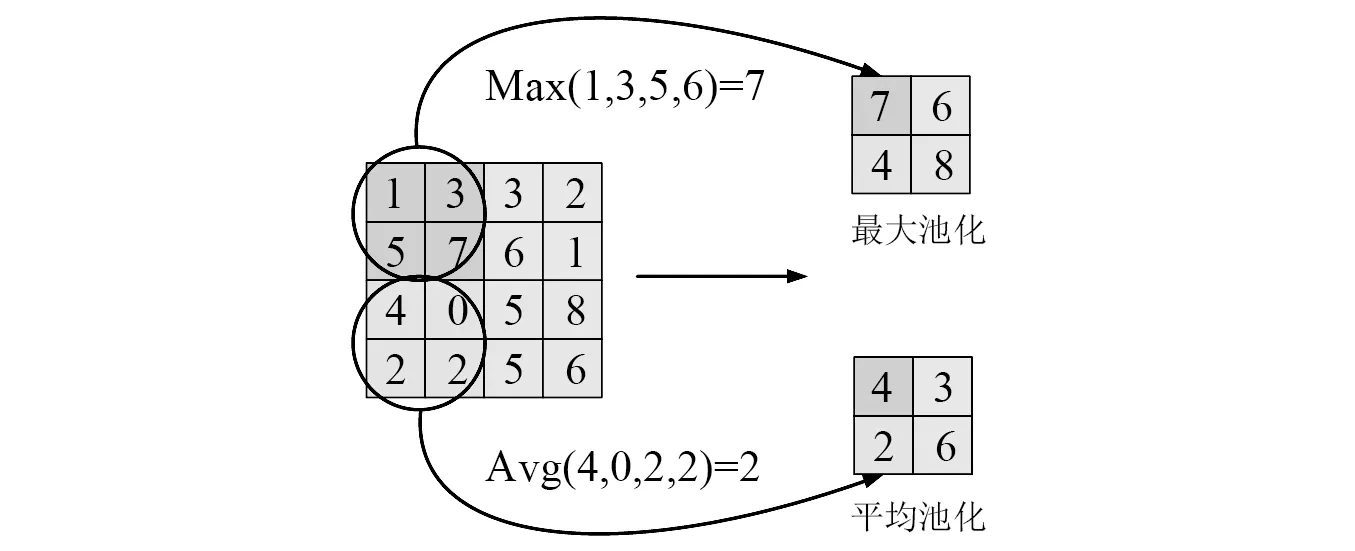
图2 池化层计算方式Fig.2 Calculation method of aggregation layer
CNN的最后一层为一个全连接层,用于执行分类或回归任务,其数学定义为
(3)
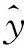
对于分类任务通常使用Softmax激活函数,其定义如下
(4)
在CNN的训练中,通常使用交叉熵函数,来评估真实标签与预测概率之间误差,定义如下
(5)
式中:1{·}为指示函数,当大括号内的判断为真时,取值为1,否则为0;假设训练集的样本总数为N,则交叉熵损失函数定义如下
(6)

1.3 残差神经网络
随着神经网络层数的不断加深,网络就会变得难以训练,并且网络的训练精度达到饱和,出现网络退化的现象。因此,He等[18]提出了残差网络(residual network,ResNet)结构来解决该问题,ResNet采用快捷连接方式实现了网络层恒等映射的多个残差模块堆叠构成。
残差模块没有去拟合多个网络层堆叠的直接映射,而是拟合残差映射。让我们聚焦于神经网络局部:如图3所示,假设我们的原始输入为X,而希望学出的理想映射为F(X)(作为图3下方激活函数的输入)。图3左图正常块直接拟合出该映射F(X),而右图部分则需要拟合出残差映射F(X)-X。残差映射在现实中往往更容易优化。在残差块中,输入可通过跨层数据线路更快地向前传播。能有效降低映射的学习难度,加快模型的收敛速度。

图3 正常块和残差块Fig.3 Normal block and residual block
在ResNet模型中残差块结构形式如图4所示,降采样层用来保持特征图的尺寸和通道数一致。
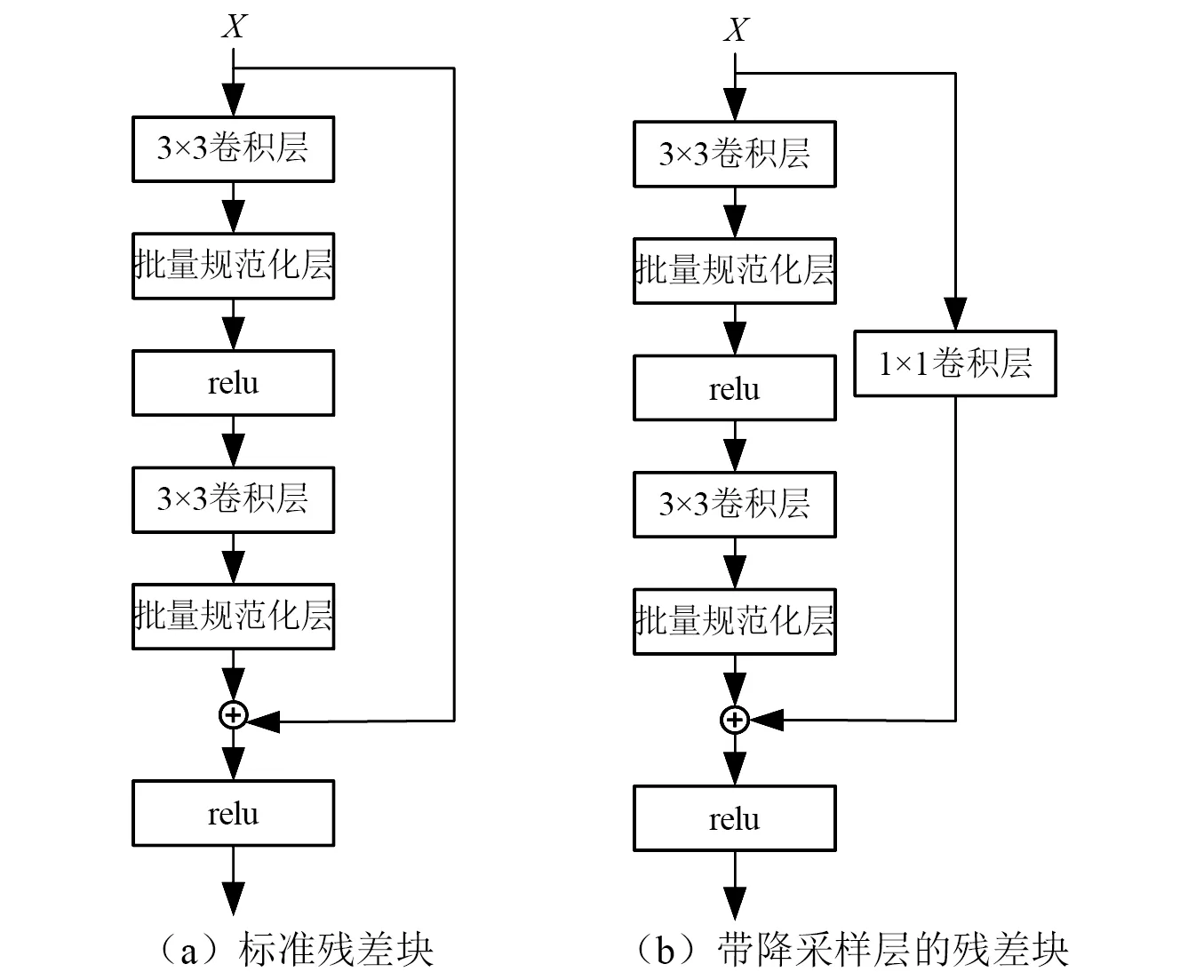
图4 标准残差块和带降采样层的残差块Fig.4 Standard residual block and residual block with falling sampling layer
1.4 注意力机制
注意力机制的产生来源于人类的视觉注意力。人类特有的视觉信息处理系统能够让人们仅依靠有限的注意力资源从待处理信息中得到关注焦点,注意力机制的核心逻辑就是从关注全部到关注重点。本文对ResNet模型优化,使用了注意力模块中的SENet和CBAM。
SENet由Hu等[19]在2017年的ImageNet竞赛中提出,SENet的结构如图5所示。
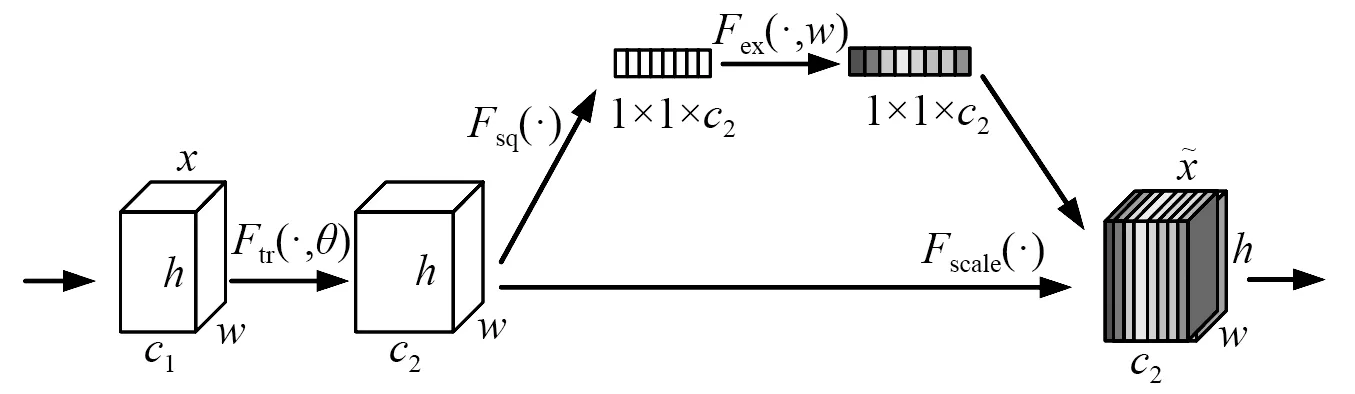
图5 SENet的结构图Fig.5 Structure diagram of SENet
图5是提出的SENet模块的示意图。与传统的CNN不一样的是通过Squeeze和Excitation 2个操作来重标定前面得到的特征。首先是Squeeze操作,顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,使得靠近输入的层也可以获得全局的感受视野,具体算法公式为
(7)
式中,xi为输入为尺寸h×w的第i个特征图。
其次是Excitation操作,主要由2个全连接层和2个激活函数组成,算法公式为
yi=Fex[Fsq(xi),ω]=σ{ω2δ[ω1Fsq(xi)]}
(8)
式中:σ为ReLU激活函数;δ为Sigmoid激活函数;ω1为第一个全连接层;ω2为第二个全连接层;Fsq(xi)为Excitation操作后的输出值。
CBAM[20]是由通道注意力模块(channel attention module,CAM)和空间注意力模块(spatial attention module,SAM)构成的,CBAM的结构如图6所示。

图6 CBAM的结构图Fig.6 Structure diagram of CBAM
CAM与SENet相比,只是多了一个并行的Max Pooling层,CAM的结构如图7所示。

图7 CAM的结构图Fig.7 Structure diagram of CAM
将输入的特征图F∈Rc×h×w分别经过基于h和w的全局最大池化和全局平均池化,得到2个c×1×1的特征图,接着,再将它们分别送入全连接层运算后相加,生成一维通道注意力Mc∈Rc×1×1。然后与输入特征图F相乘,调整后获得F1其过程公式为
F1=Mc(F)⊗F
(9)
式中:Mc(F)为F经过通道注意力的输出权值; ⊗为特征图加权乘法运算符号。
SAM的结构如图8所示。
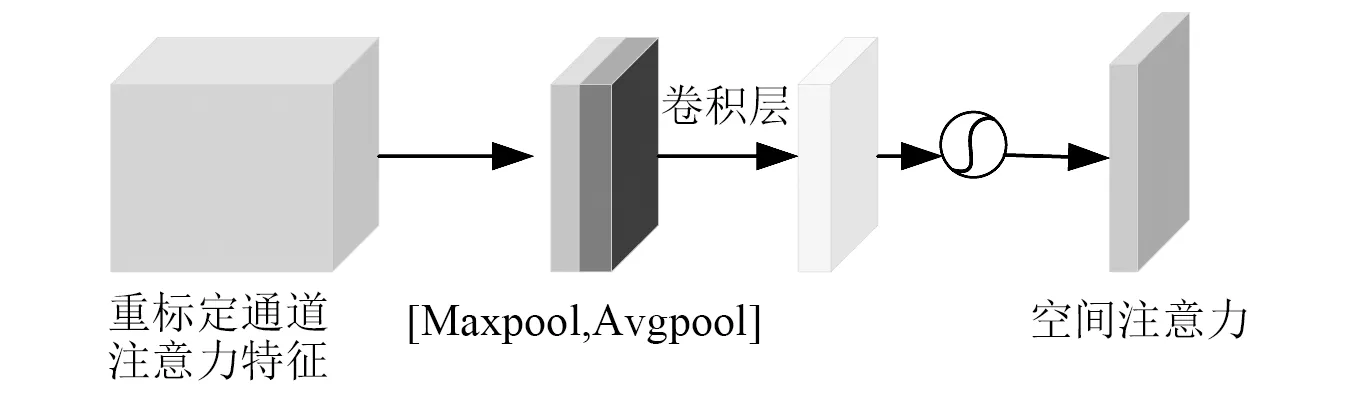
图8 SAM的结构图Fig.8 Structure of SAM
将通道注意力模块输出的特征图F1作为本模块的输入特征图。首先做一个基于通道的全局最大池化和全局平均池化,得到2个1×h×w的特征图,将这2个特征图基于通道做拼接操作。然后进行卷积操作得到二维空间注意力Ms∈R1×h×w,最后与F1按元素相乘。其过程公式为
F2=Ms(F1)⊗F1
(10)
式中,Ms(F1)为F1经过空间注意力的输出权值。
2 算法详解
本文提出的基于注意力机制对残差神经网络进行优化,能够从时频图中自动提取出轴承的故障特征信息。本算法的框架如图9所示,ResNet模型详细参数如表1所示,具体分为时频图像生成、训练模型和优化模型3个步骤。

表1 ResNet模型详细参数Tab.1 ResNet model detailed parameters
(1) 时频图像生成:将原始时域信号每2 048个数据点组成一个样本,为了保证每个数据点都能采集到,每2个样本点会有重叠的548个数据点,滑动窗口的步长为1 500,然后将这些样本点经过连续小波变化生成时频域的图像。
(2) 训练模型:本文的预训练模型是在ImageNet图像数据集上训练的ResNet18模型上改进的。如果直接迁移ResNet18模型,收敛速度很慢,迭代到139次才开始收敛,而且迭代时波动性比较大。本文提出的ResNet模型在保留原始ResNet18模型的大部分架构,将残差层中的带采样残差块BatchNorm层去掉,只用conv1×1的卷积层,残差块引用2个卷积层和2个BatchNorm层,迭代到第10次就开始收敛,而且两者最后收敛的准确率一致,大大加快了模型的运算速度。两种模型的迭代对比如图10所示。

图10 训练速度对比图Fig.10 Comparison of training speed
(3) 优化模型:本文采用基于注意力机制的方法对ResNet进行优化,分别将注意力机制里的SENet模型和CBAM添加到ResNet模型里的4个残差层中,得到SE-ResNet模型和CBAM-ResNet模型。
3 试验验证
为验证本文提出基于注意力机制优化残差神经网络故障诊断算法的有效性,仿真试验使用的深度学习框架为pytorch,编程语言为Python,在AMD Ryzen 5 4600H,8 G内存,GTX1650,Windows 10操作系统下,每次训练的批量大小设置为7个样本,采用SGD优化方法,反向传播更新深度学习模型的参数,学习率设置为0.001,使用经典的交叉熵损失函数。
3.1 轴承故障数据源与处理
本文使用凯斯西储大学(Case Western Reserve University,CWRU)的滚动轴承数据集,试验平台如图11所示。

图11 CWRU试验平台Fig.11 CWRU test platform
CWRU数据集中使用的是由SKF公司生产,型号为6205和6203的滚动轴承来开展故障诊断试验。本次试验采用了12 kHz采样频率的驱动端轴承的故障数据,并采集了4种不同工况时(0,735 W, 1 470 W, 2 205 W)的滚动轴承振动信号。在每种工况下,对滚动体、内滚道和外滚道分别引入直径为0.177 8 mm,0.355 6 mm,0.533 4 mm的单点故障的滚动轴承进行了试验,加上正常滚动轴承的试验数据,每个工况都有10种不同的故障类型,如表2所示。
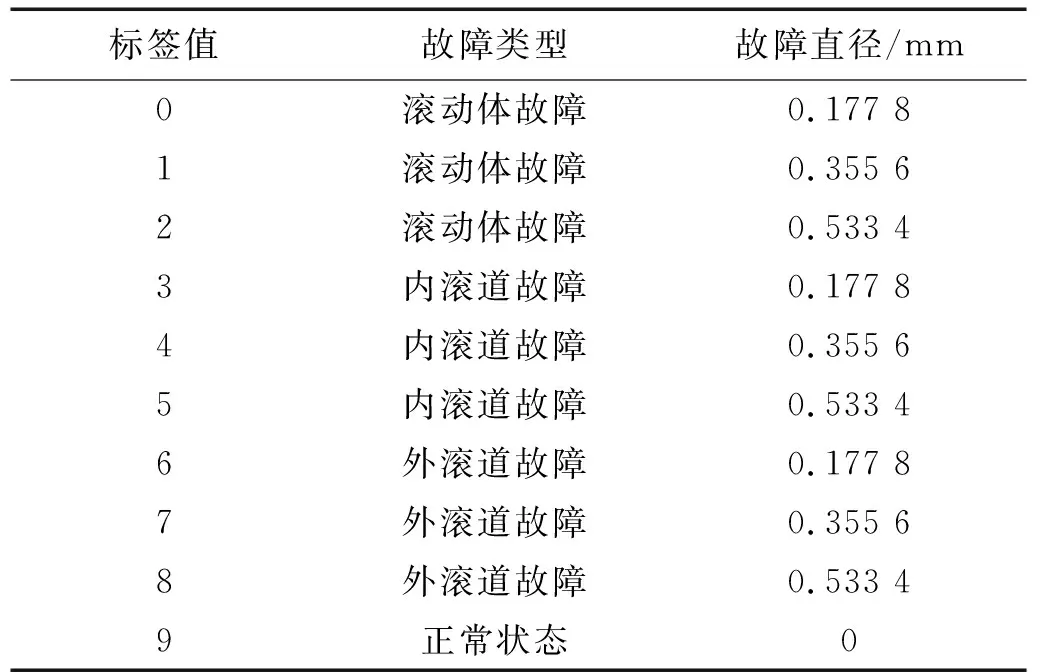
表2 CWRU轴承故障分类及标签值Tab.2 CWRU bearing fault classification and label value
将原始时域信号每2 048个数据点组成一个样本,每2个样本点会有重叠的548个数据点,滑动窗口的步长为1 500,训练集、验证集和测试集的具体设置如表3所示。
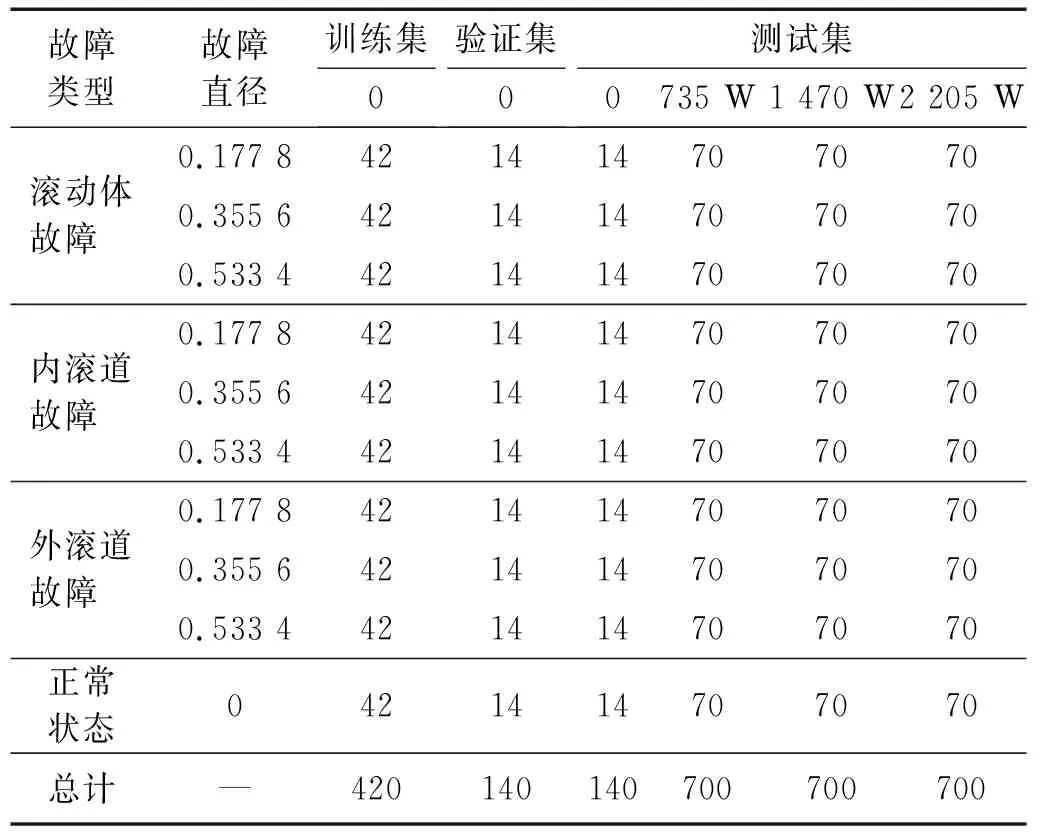
表3 试验数据说明Tab.3 Experimental data description
对每个状态的故障经过CWT处理转换成二维时频域图像,其中工况0部分的转换如图12所示。
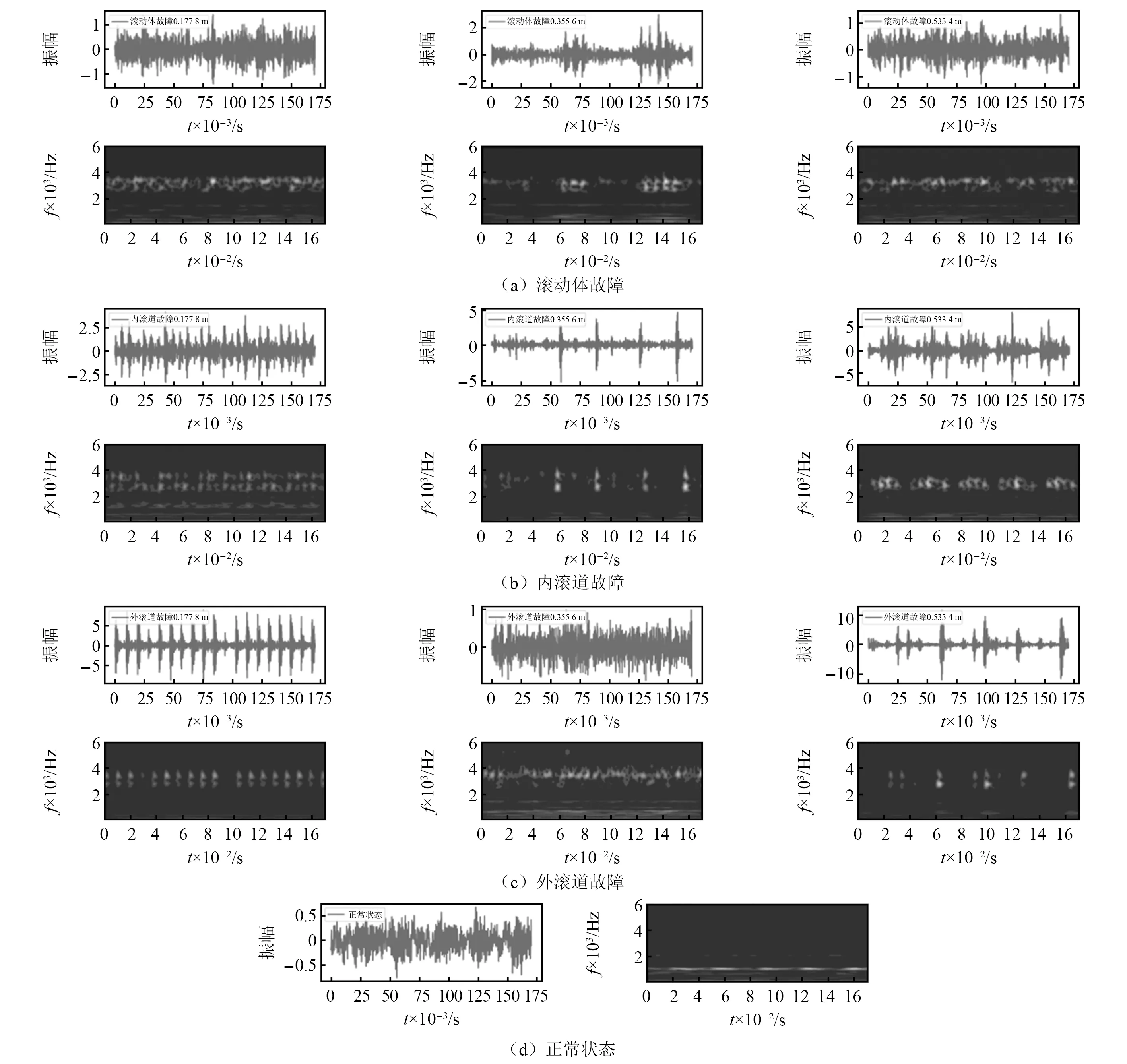
图12 图像数据集Fig.12 Image data set
3.2 不同预训练模型的结果与分析
为验证残差神经网络的有效性,采用不同深度学习常用模型对CWT变换后的二维时频域图像进行故障诊断分析,本文采用3种常用的深度学习模型(LeNet、CNN和BiLSTM)作为预训练模型的对比试验。
LeNet模型有2个卷积层。在传统LeNet模型的基础上把平均池化层改成了最大池化层,激活函数采用relu,后面把原先的3个全连接层换成了2个全连接层。采用的CNN模型有4个卷积层,模型中加入了批量规范化,可持续加速深层网络的收敛速度。BiLSTM相比较于传统单位LSTM添加了反向传递信息的隐藏层,可以进行双向传递,以便于更好的处理信息。
模型训练在0工况下,将该工况下的滚动轴承数据集样本按照60%,20%,20%的比例随机分配到训练集、验证集与测试集中。
图13(a)和图13(c)是在0工况条件下,4种算法在迭代50轮之后的训练集和验证集的损失,LeNet、CNN和ResNet训练损失出现了明显的下降,其中ResNet模型下降速度最快,而且训练损失最小,达到0.012 4,验证集损失达到0.001 9。图13(b)和图13(d)反映4种算法的训练集和验证集的准确率,CNN和ResNet模型上升趋势明显,而且收敛较快,特别是ResNet模型在迭代到第10轮时就出现了收敛,最后稳定在一个定值,训练集稳定在100%,验证集稳定在96.59%。

图13 0工况下不同模型训练Fig.13 Training of different models under 0 condition
表4给出了在0工况下测试集的准确率和测试时间,ResNet模型在测试集的准确率最高,但是测试时间相对较高,是因为ResNet模型里面有4个残差层,相对于其他深度学习模型复杂度较高,随之测试时间也比较长。
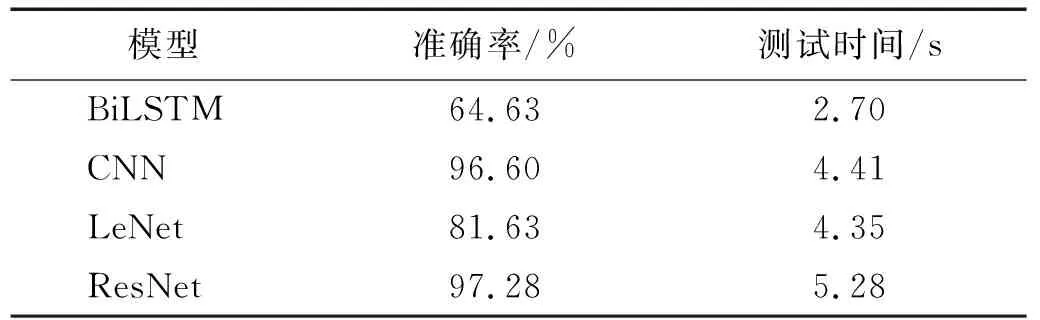
表4 0工况下不同模型测试集准确度Tab.4 Accuracy of test sets of different models under working 0 condition
3.3 不同工况间的模型迁移试验结果与分析
利用在CWRU数据集提供的4种不同的工况,首先在0工况下训练模型,直接迁移到735 W, 1 470 W, 2 205 W工况中,把全部的数据当成测试数据,其测试结果如图14所示。ResNet模型虽然相较于有训练集的测试准确率有所下降,但整体来说下降不多,下降最大幅度为3%,但是对于其他模型来说下降很明显,尤其是CNN模型,在0工况下有训练集的测试准确率为96.60%,但是在无训练集时向其他3种工况直接迁移的测试准确率仅在55%~67%,下降最大幅度达到41%,由此可以看出CNN模型泛化性很差,相对于其他模型来说ResNet模型表现较好。

图14 不同工况间的模型迁移对比图Fig.14 Model migration comparison between different working conditions
3.4 基于注意力机制的ResNet模型优化
由3.3节可知,虽然ResNet模型相较于其他深度学习模型表现出了较强的泛化性,但整体还是有所下降,所以本小节在基于注意力机制对ResNet模型进行优化,来提高ResNet模型的泛化性。主要采用注意力模块中的SENet和CBAM,构建SE-ResNet模型和CBAM-ResNet模型。
通过t-SNE分布领域嵌入算法可以提取出的故障特征,降维至二维平面,并以散点图的形式呈现。将未经过时频域处理的原始数据和经过ResNet模型变换后的数据进行可视化,降维可视化结果如图15所示。从图15中可以看出,ResNet模型具有出色的特征提取能力。
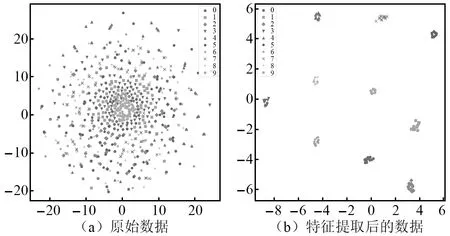
图15 t-SNE可视化结果Fig.15 t-SNE visualization results
为了便于直观地观察优化后的SE-ResNet模型和CBAM-ResNet模型的准确率,本文还使用了混淆矩阵,通过混淆矩阵更加清晰的显示测试集对滚动轴承状态的识别状况,不同工况间的模型迁移结果如图16、图17和图18所示。
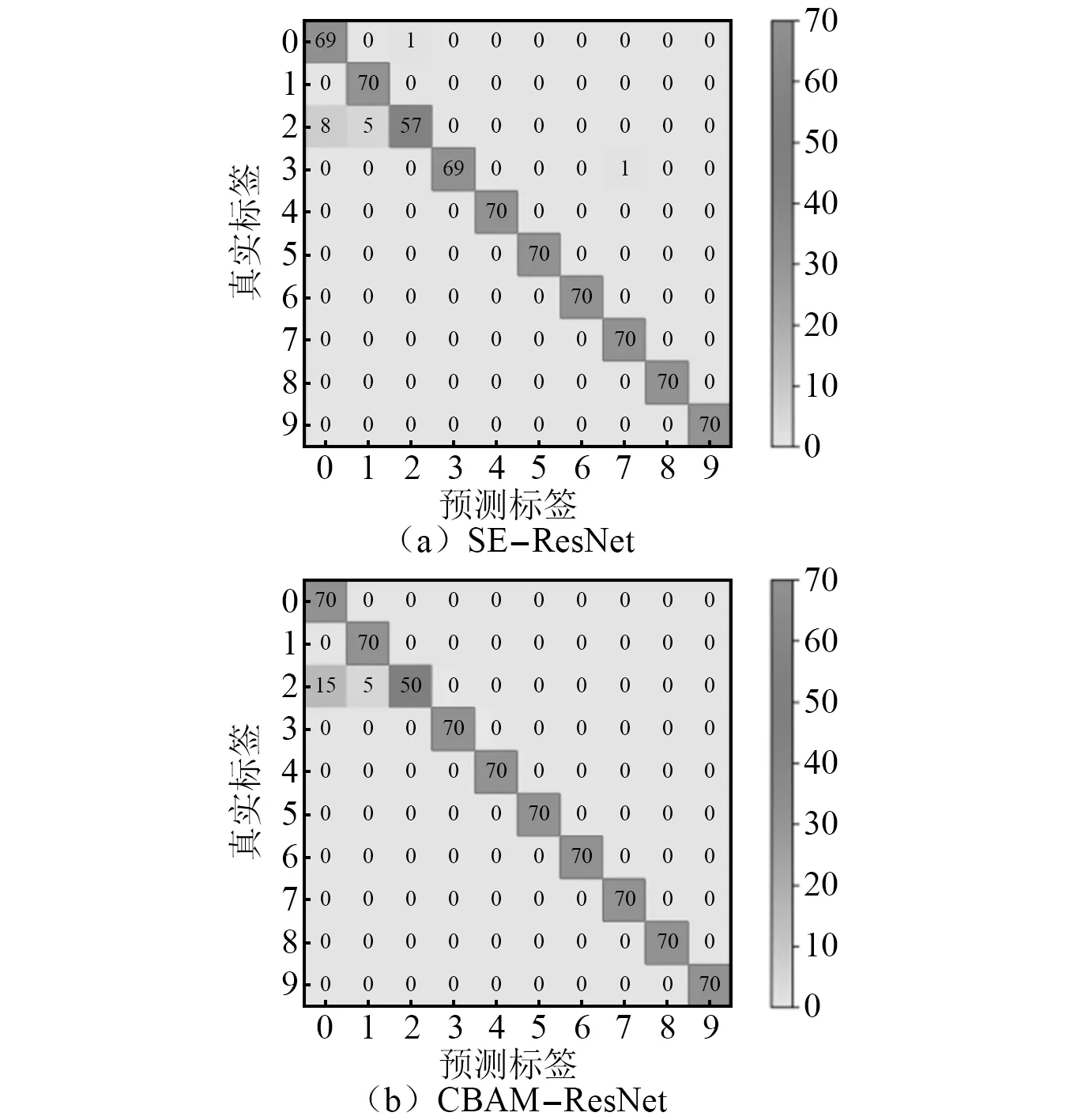
图16 0→735 W混淆矩阵图Fig.16 0→735 W confusion matrix diagram
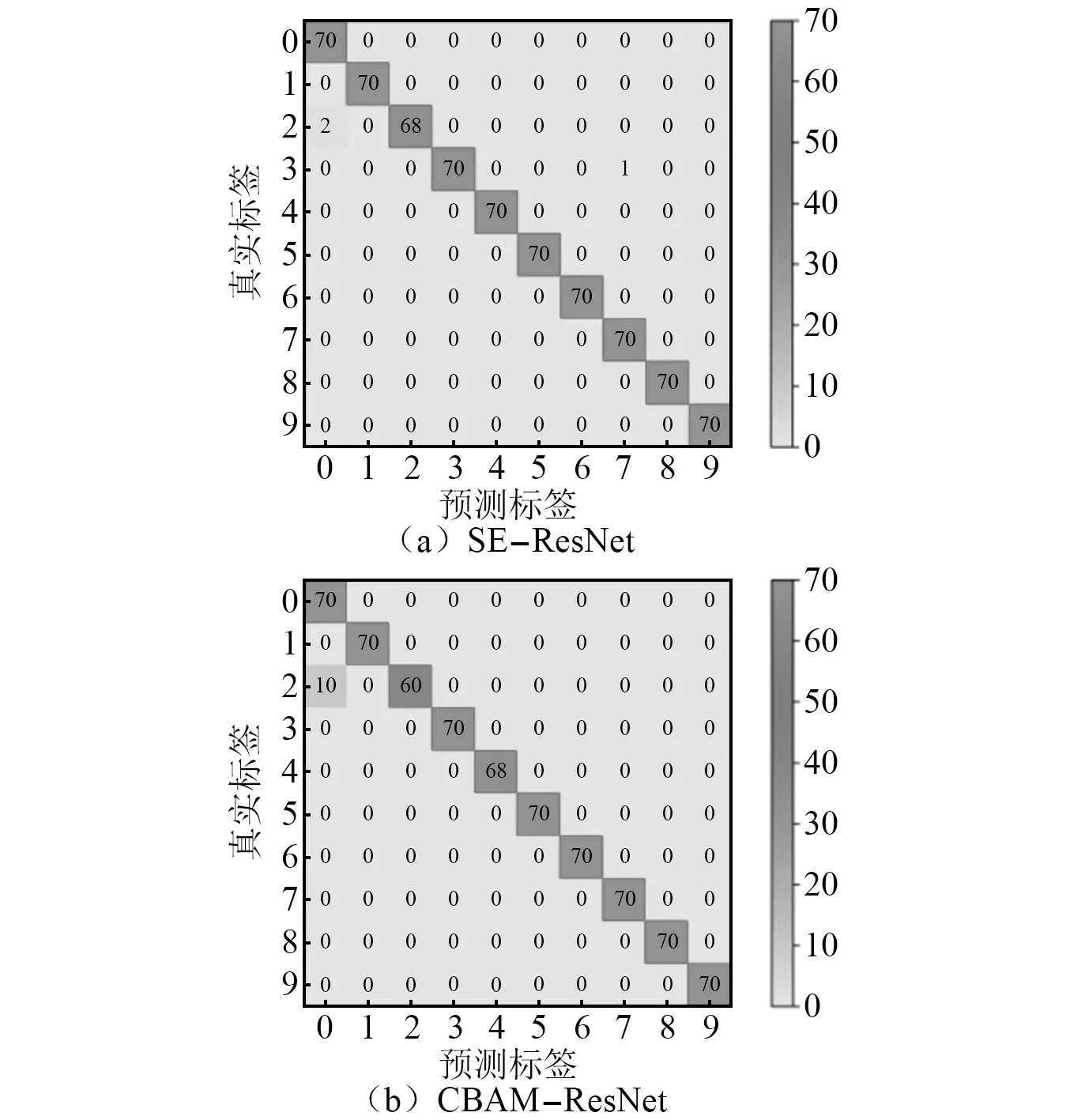
图17 0→1 470 W混淆矩阵图Fig.17 0→1 470 W confusion matrix

图18 0→2 205 W混淆矩阵图Fig.18 0→2 205 W confusion matrix
由混淆矩阵图可以看出,在由工况0向其他3种工况迁移过程中,SE-ResNet模型和CBAM-ResNet模型出现标签识别错误的次数很低。在测试速度(如图19所示),本文提出的两种模型的测试速度在9~10 s,相比较于ResNet模型相差不大,说明两种模型虽然加深了网络,但是整体没有影响模型的运算速度。在测试精度上(如图20所示),SE-ResNet模型和CBAM-ResNet模型在向其他3种工况迁移的准确率都高于ResNet模型迁移的准确率,SE-ResNet模型和CBAM-ResNet模型测试准确率分别高达99.71%和98.86%,都高于ResNet模型在同工况有训练集97.28%的准确率,表现出比ResNet模型更高的准确率和泛化性,起到了模型优化的目的。
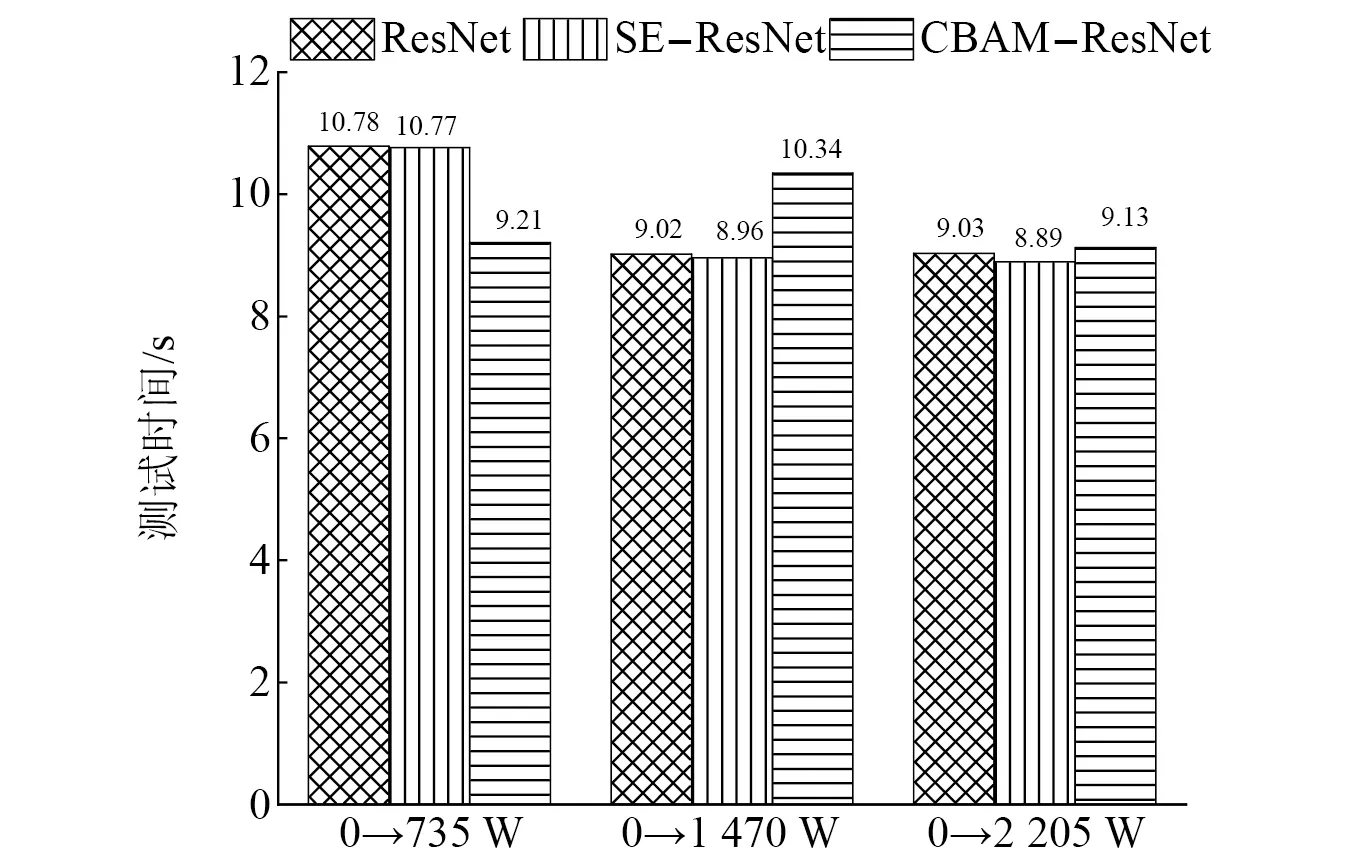
图19 模型测试时间对比图Fig.19 Model test time comparison diagram
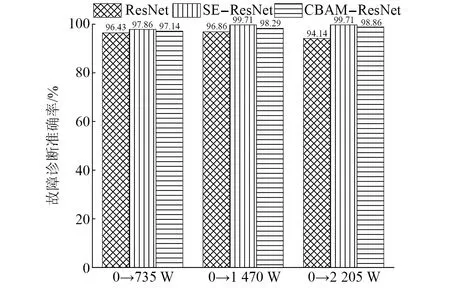
图20 模型优化效果对比图Fig.20 Comparison diagram of model optimization effect
4 结 论
针对滚动轴承在不同工况环境中故障诊断训练时间长、准确率低和泛化性能能弱的问题,提出了一种基于注意力机制改进残差神经网络的轴承故障诊断方法。得出的结论如下:
(1) 提出的ResNet比ResNet18模型具有更快的收敛速度。与其他3种常用的深度学习模型(LeNet,CNN和BiLSTM)相比无论是在同工况还是不同工况之间的模型迁移,ResNet模型的测试精度远远高于其他几种深度学习模型。
(2) 对于模型的优化,SE-ResNet模型和CBAM-ResNet模型虽然加深了网络,但测试速度相比较于ResNet模型变化不大。在测试的准确率上,SE-ResNet模型在不同工况迁移的准确率达到97.86%~99.71%,CBAM-ResNet模型在不同工况迁移的准确率仅为97.14%~98.86%,高于ResNet模型在不同工况迁移的准确率,而且大部分测试高于同工况有训练集的准确率,表现出比ResNet模型更强的准确率和泛化性,起到了模型优化的目的。
(3) 基于注意力机制改进残差神经网络的算法实现了不同工况间的直接迁移,注意力机制的本身特点就是注意到有用的信息,抛弃无用的信息,虽然加深了网络,但不会减慢模型的运算速度,而且在测试的准确率上高于其他常用的深度学习算法不同工况的直接迁移和同工况有训练集的准确率。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
河南科技(2015年8期)2015-03-11
振动、测试与诊断(2014年5期)2014-03-01
机械与电子(2014年1期)2014-02-28
