
基于K-Means和XG-Boost算法的“两步式”船型分类映射
2023-09-02 03:02:26王绍函王翔宇任飞扬
上海船舶运输科学研究所学报 2023年3期
王绍函, 韩 懿, 王翔宇, 任飞扬
1.上海船舶运输科学研究所有限公司, 上海 200135;2.中远海运科技股份有限公司, 上海 200135;3.上海交通大学 船舶海洋与建筑工程学院, 上海 200241)
0 引 言
当前水路运输已成为国际货运的主导力量,承担了世界货物运输量的80%以上。据统计,2022年国际海运贸易总量为226.54亿t,全球集装箱运输总量为2.01亿TEU[1]。海上贸易量在全球生产总值中所占比例不断增大,该变化引发了消费者需求的转变。同时,航运业必须将目光投入到船舶、港口、内陆的稳定和长期可持续发展中。由于船舶具有载货量大和面临的航行海况复杂等特点,保障船舶安全航行和提升航运成本管理水平受到了船公司和政府的高度重视。然而,无论是船舶安全管理还是航运成本管理,大多都是以船队为单位进行的,因此对船队中姊妹船的分类很大程度上决定着对船舶行为进行分析的基本。对于单船而言,包括能耗在内的航行成本往往取决于主机功率、额定转速等船舶基本属性和船舶航行时的实际海况。因此,在对某船的行为进行研究时,往往会将其姊妹船当作同一类型船舶考虑。
随着智能交通的迅速发展、计算机算力的不断提升和物联网技术的逐渐普及,采用大数据挖掘技术对姊妹船进行分类,进而对船舶行为进行分析的方法得到了学术界的广泛关注。很多学者都采用船舶自动识别系统(Automatic Identification System,AIS)作为区分船舶行为的依据,然而这种方法缺乏对船舶的清晰分类[2-4]。以上方法均需对船舶AIS数据进行长期监控,并从中找到相似规律;同时,需要较高的数据质量、较大的数据量和相对类似的航行海况。为解决这些问题,研究人员考虑到不同船型之间存在的建造差异会影响船舶的表现,开始研究在分析航线数据之前对船舶进行分类的方法。SILVEIRA等[5]、GOERLANDT等[6]和MASCARO等[7]提出将船舶类型作为识别AIS行为前的船舶分类标准,但未考虑船体尺寸等基本属性,因此该方法缺少对同类型船舶的细致分类。DE BOER[8]提出将船舶载重量作为分类属性,该方法能对同类型船舶进行区分,但需设定阈值,一方面无法从数据的角度证明阈值设定的准确性,另一方面在处理同类型的多种船舶时会造成分类困难。此外,SHU等[9]和XIAO等[10]采用船舶总吨代替载重吨作为分类依据,MOU等[11]采用总船长配合船舶最近点(Closest Point of Approach,CPA)作为船舶分类和行为识别的依据。这些方法虽然将船舶属性作为分类特征,但采用的属性过少,同时缺少用于验证方法有效性的数据。因此,提出一种基于船舶自身属性的,能对同类型船舶进行细致划分的方法对于基于AIS的船舶行为研究而言具有重要意义。
本文以中国远洋海运集团有限公司(以下简称“中远海运集团”)的干散货船、集装箱船和油船为研究对象和训练集,采用无监督学习方法对包括主机功率在内的9个重要船舶属性进行分类,从数据的角度确定分类数量。在此基础上,采用监督学习方法再次对这些属性进行分类训练。经过2次分类训练,分类模型将具有以下特征:
1) 从数据的角度对同一船型的不同船舶属性进行分类,采用肘部法则计算分类数量,避免人工设定阈值;
2) 合理建立已有标签的数据集与目标数据的映射关系,为未来进行基于船舶分类的船舶行为识别打下基础;
3) 模型具有普遍性和处理数据缺失问题的能力,可应对目标船属性数据不完整的问题;
4) 针对已有数据集可能无法涵盖目标船类型的问题,给出量化的分类映射结果,方便人工改善分类成功率低的情况。
1 研究方法
首先采用K-Means算法对船舶的9个主要属性进行分类。在这9个属性中,主机功率、载重量和排水量等3个属性是在对船舶油耗与船舶属性的相关性进行分析时得到的高相关性属性,另外6个属性是通过整理以往的研究并将其与数据库中的船舶属性字段相匹配得到的。K-Means算法在处理大数据集时具有良好的可扩展性和分类效果,且复杂度较低。针对每种船型分类情况不一和船舶数量不等的特点,K-Means算法先基于肘部法则确定每种船型的分类数量,再给分类的船舶打上分类标签,接着根据标签,采用XG-Boost算法对训练集内的船舶进行训练。利用有监督学习方法能处理数据缺失的问题,建立已知船舶与目标船舶的映射关系。
1.1 肘部法则
在分类分析中,肘部法是一种启发式方法,用于确定数据集中的分类数。该方法将解释的变化绘制为簇数的函数,选择曲线的弯头作为要使用的簇数,可用于选择其他数据驱动模型中的参数数量。在应用该方法时,先在数据集上对K的一系列值运行K均值分类,然后为K的每个值计算所有分类的平均得分(误差平方和),最后计算失真分数,即从每个点到其指定中心的平方距离之和。K值与误差平方和的关系曲线见图1,其中误差平方和表现为分类的平均畸变程度。

图1 K值与误差平方和的关系曲线
当绘制每个模型的总体指标时,可直观地确定K的最佳值。若折线图看起来像一个臂,则“肘部”(曲线上的拐点)是K的最佳数值。“臂”既可是向上的,又可是向下的,若有1个强拐点,则表明基础模型在该点最适合。
1.2 K-Means分类
均值分类是一种矢量量化方法,最初来自于信号处理,旨在将n个观测值划分为K个簇,其中每个观测值属于具有最近均值的簇(簇中心或簇质心),作为簇的原型。这种方法将数据空间划分为Voronoi单元,以实现对簇的定义和分类。K均值分类使分类内方差(平方欧几里得距离)最小化,但不使正则欧几里德距离最小化。
(1)
式(1)中:μc(i)为第i个分类的均值。
设定输入为D={x1,x2,…,xm},分类的簇数为K个,最大迭代次数为N次,K-Means分类算法流程(见图2)可大致归为4个步骤:

图2 K-Means分类算法流程图
1) 从数据集D中随机选择K个样本作为初始的K个质心向量,将分类中心作为初始化均值点{u1,u2,…,um};

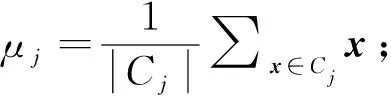
4) 监测这些质心是否发生变化,若无变化,则输出簇划分为C={C1,C2,…,Ck},否则重复步骤3),直至质心不再发生变化为止。
1.3 XG-Boost分类
XG-Boost是梯度增强树算法的一种流行且高效的开源实现。梯度提升算法是一种监督学习算法,试图通过组合多上弱学习器形成一个强大的集成模型。当采用梯度提升算法进行回归时,弱学习器是回归树。
XG-Boost最小化正则化目标函数,该函数结合了凸损失函数(基于预测与目标输出之间的差异)和模型复杂性的惩罚项(回归树函数)。训练以迭代的方式进行,添加用于预测先前树的残差或误差的新树,然后将其与先前树组合,以进行最终的预测。XG-Boost被称为梯度提升,因为其通过采用梯度下降算法使添加新模型时的损失最小化。
图3为XG-Boost原理结构图,其中:αi和ri分别为第i棵回归树计算的正则化参数和残差;hi为第i棵回归树采用数据集X训练预测残差ri的函数。

图3 XG-Boost原理结构图
2 “两步式”船型分类映射
本文基于训练集内的船舶结构和动力数据较为完整的特点,以训练集内的船舶为基础,根据船舶属性建立船舶自动分类模型,并通过类别映射将全球商船映射至训练集内的船舶种类上。以中远海运集团的干散货船、集装箱船和油船为研究对象和训练集,结合船舶多维特征,基于K-Means算法选取主机额定功率、运营航速、载重量、二级船型、总船长、船深、吃水、排水量和主机额定转速等9个船舶属性,通过肘部法则计算分类后簇内平方差之和,确定分类数量,为训练集内的船舶设置分类标签。经过人工修订之后,结合船舶属性和分类标签,采用XG-Boost算法对全球船舶进行分类映射,生成全球8万艘商船与中远海运集团内部船舶的映射关系,并根据相关算法计算分类成功概率。图4为“两步式”船型分类映射流程图。

图4 “两步式”船型分类映射流程图
2.1 分类个数阈值确定
在采用K-Means算法对船舶吃水和宣载量进行分类之前,需采用肘部法则,分别针对集装箱船、干散货船和油船遍历簇的数量,这里假设每艘船都要单独分成1类,从而确定针对每种船型的最合适的簇数。
图5~图7分别为基于肘部法则对集装箱船、油船和干散货船进行分类的结果。根据图5~图7,集装箱船的分类数量为91类,油船的分类数量为87类,干散货船的分类数量为90类。

图5 集装箱船的肘部法则分类结果
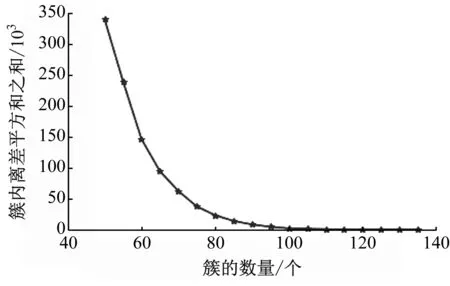
图6 油船的肘部法则分类结果

图7 干散货船的肘部法则分类结果
2.2 训练集数据标签
下面采用K-Means算法和2.1节确定的K值分别对集装箱船、干散货船和油船进行分类,并根据分类结果打上分类标签,见表1~表3。

表1 训练集集装箱船分类结果

表2 训练集油船分类结果
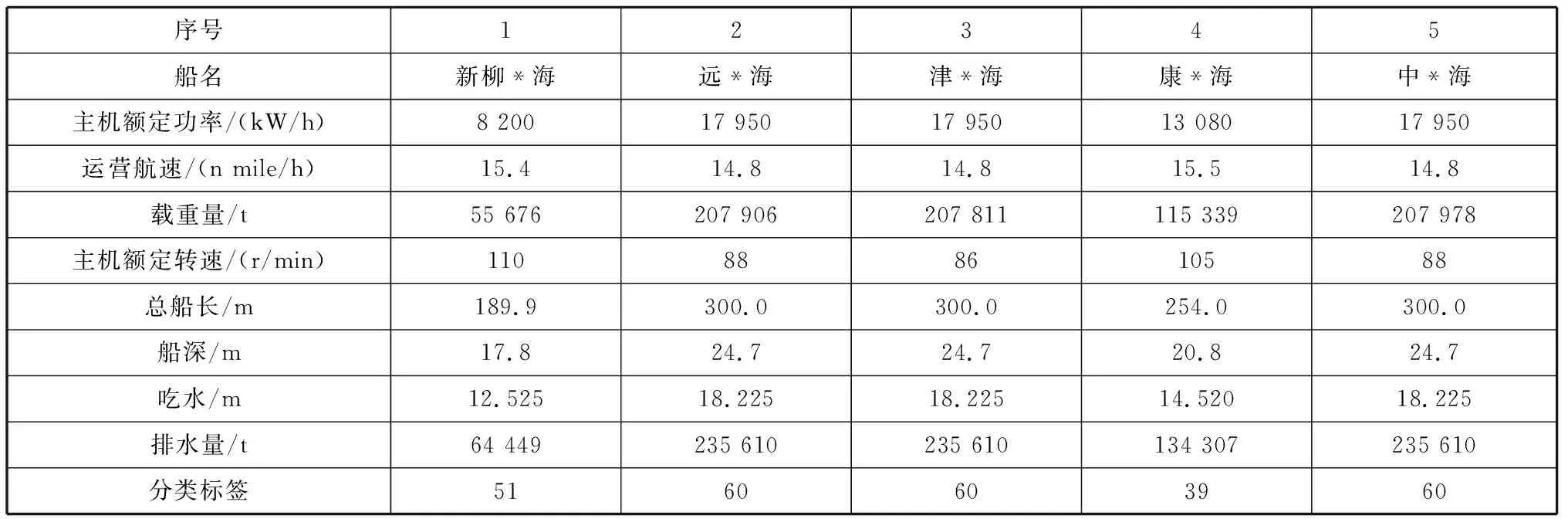
表3 训练集干散货船分类结果
2.3 基于XG-Boost算法的二次分类训练
基于表1~表3所示训练集分类结果,采用XG-Boost算法,分别对3种船型进行二次训练。XG-Boost算法考虑了训练数据为稀疏值的情况,能为缺失值或指定的值指定分支的默认方向,从而大大提升算法的效率。此处采用XG-Boost算法的原因是,K-Means算法作为无监督学习算法,无法有效应对船舶属性(字段)数据缺失的问题。因此,将采用K-Means算法训练的数据(含标签)放入XG-Boost算法中训练,使其具有识别船舶分类的能力,采用XG-Boost算法对无法准确获取船舶属性或油耗报告不可知的船舶进行分类,以形成训练集与测试集之间的映射关系。算法中采用的决策树深度为10,学习率为0.3。根据训练好的模型对目标船(收集到的全球船舶)分船型进行预测,并形成预测概率。表4~表6分别为全球集装箱船、油船和干散货船的分类结果及分类映射概率;图8为全球目标船舶分类映射概率与船舶数量柱状图。
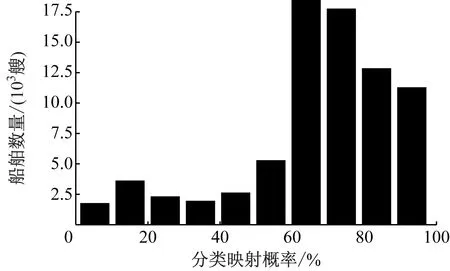
图8 全球目标船舶分类映射概率与船舶数量柱状图
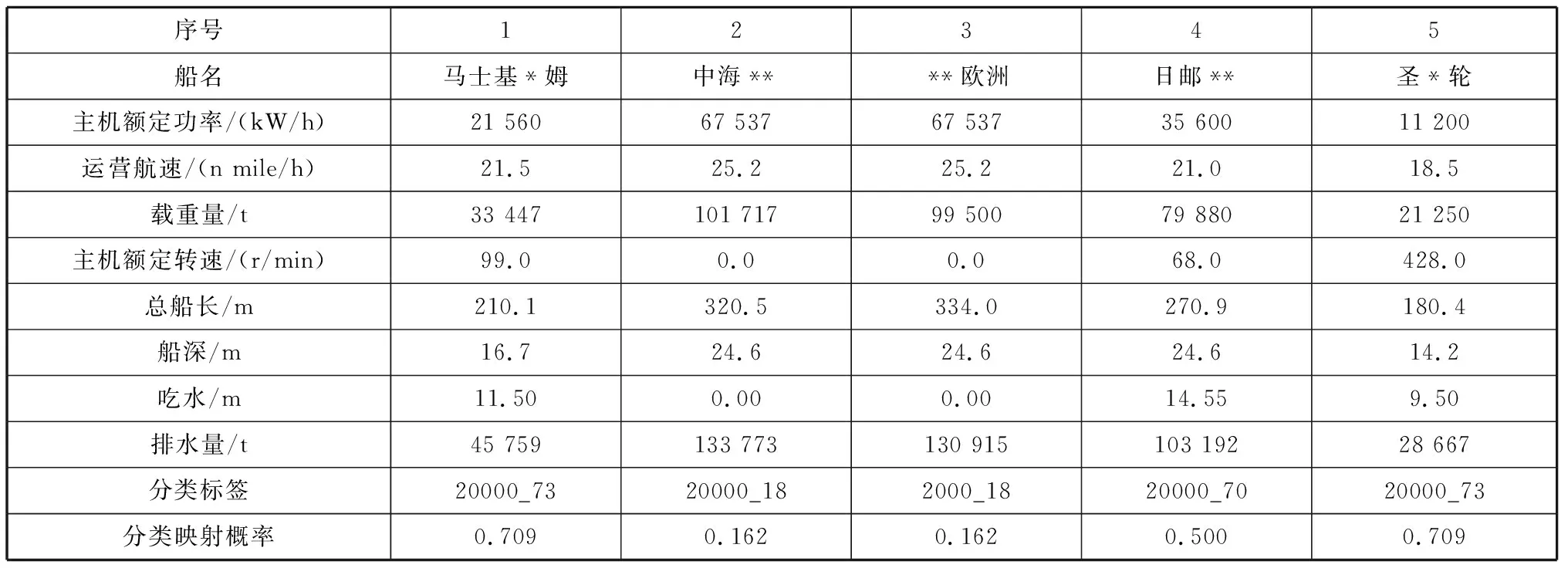
表4 全球集装箱船分类结果及分类映射概率

表5 全球油船分类结果及分类映射概率

表6 全球干散货船分类结果及分类概率
根据表4~表6和图8的结果,综合比较本文建立的“两步式”分类映射概率在60%以上的船舶占船舶总数的77%以上。虽然仍有10%的船舶的分类映射概率在30%以下,但在其中9种属性的缺失率高达50%以上(即缺少4种或4种以上属性数据)。数据缺失是造成分类映射概率偏低的主要原因。解决该问题的方法是:
1) 通过寻找更好的数据源补全船舶属性;
2) 增加训练集内船舶的种类数量,以涵盖更多船舶分类标准;
3) 通过AIS行为分析等船舶识别技术对分类的准确性进行验证,从而根据验证结果反向优化分类模型。
通过对测验的47 122艘船舶的油耗表现进行对比可知,船舶分类结果相对细致,可用于对无法获取准确油耗报告的船舶的油耗进行估算。在分类结果中,对于字段缺失严重的船舶,其主机功率、载重量和排水量等对分类结果影响较大的属性会通过与同类船型建立线性拟合关系补齐,最后人工校对。该方法的劣势在于,分类模型无法对数据集中不存在的船舶类型进行有效分类,给出的分类可信度不高,该问题在后续研究中可通过强化学习等深度学习算法解决。
3 结 语
本文采用K-Means算法和XG-Boost算法对训练集中船舶属性较为完整的数据进行分类映射训练,从而由训练集内的船舶出发,建立这些船舶与全球所有商船的映射关系,主要得到以下结论:
1) 根据训练集内船舶的属性建立其与全球船舶的映射关系,便于监控全球商船的燃油消耗和碳排放等;
2) 提出了一种解决目标船型信息缺失、数据不完整问题的方法。
本文所述船舶分类模型不仅能对数据缺失的船舶进行分类,而且能提供量化的分类概率,应对训练集中船舶种类不足以覆盖目标船舶的情况,方便从业人员人工调整。
猜你喜欢
百科探秘·海底世界(2024年6期)2024-06-27 23:10:58
军事文摘(2023年14期)2023-07-28 08:39:46
中老年保健(2021年2期)2021-08-22 07:29:02
中老年保健(2021年4期)2021-08-22 07:08:46
中老年保健(2021年3期)2021-08-22 06:50:46
中华肩肘外科电子杂志(2019年4期)2019-08-24 06:39:16
军事文摘(2018年24期)2018-12-26 00:57:56
——福船
西部交通科技(2015年4期)2015-07-25 11:29:08
西部交通科技(2015年6期)2015-07-01 23:47:01
中国美容医学(2015年5期)2015-01-21 10:46:53
