
高光谱技术结合网格搜索优化支持向量机的桃缺陷检测
2023-09-01 00:57张立秀张淑娟孙海霞薛建新任锐刘文俊
食品与发酵工业 2023年16期
张立秀,张淑娟,孙海霞,薛建新,任锐,刘文俊
(山西农业大学 农业工程学院,山西 晋中,030801)
“久保桃”是水蜜桃的一种早熟品种,营养丰富,深受消费者喜爱[1]。在久保桃的生长过程中,由于自然因素造成的果面损伤即果面缺陷。根据NY/T 586—2002,常见的果面缺陷有疮痂桃、虫咬桃和鸟啄桃。这些缺陷的存在降低了桃的品质,影响了我国桃果实的出口。目前,市场上主要依靠人工进行分拣缺陷桃,存在效率低下[2]的问题,因此研究一种快速、高效、批量检测桃果实外部缺陷的方法具有实际意义。
高光谱技术具有分辨率清晰、波段数多的特点,被广泛应用于水果缺陷的无损检测[3]。BARANOWSKI等[4]将高光谱图像与主成分分析法进行结合,研究苹果损伤后的生理指标变化,检测精度达到97%。WANG等[5]将高光谱成像技术结合逐步判别法判别虫害枣和完好枣,判别率为94.8%。LORENTE等[6]利用高光谱成像技术结合化学计量法,检测柑橘的腐烂,检测率达到了85%。许建东等[7]采用高光谱技术结合变量选择方法判别完好与冻害甘薯,判别率为98.05%。池江涛等[8]采用高光谱技术结合多元线性回归模型对茄子外部缺陷进行识别研究,判别率为96.82%。吉亚敏[9]采用高光谱成像技术和机器学习相结合的方法对马铃薯的外部缺陷进行了分类,模型的平均判别率为92.08%。章海亮等[10]利用高光谱成像技术检测柑橘的结痂、黑斑、蒂腐、褐腐病的4种缺陷,最终的判别率为94%。LI等[11]采用高光谱成像技术结合多元线性回归模型,预测哈密干枣的可溶性固形物含量,最终其预测集的准确率为85.7%。
支持向量机(support vector machines, SVM)是一种机器学习算法,常用于解决小样本、非线性及高维的数据模型问题[12],SVM模型分类性能的好坏取决于模型参数的选择,因此出现了许多SVM的优化算法。国内外许多学者采用高光谱结合SVM及其优化算法对果蔬的品质进行了研究。SIRINNAPA等[13]将高光谱成像技术与偏最小二乘法(partial least squares, PLS)、SVM等方法结合,检测芒果和黄瓜的虫害,芒果虫害判别率为93.4%,黄瓜虫害判别率为82%。WANG等[14]采用高光谱成像技术结合最小二乘支持向量机,研究了不同预处理方法对柑橘黄龙病叶上、叶下表面光谱模型的影响,结果表明,在二阶导数预处理下,识别率分别为100%和92.5%。王梓萌[15]将近红外光谱与粒子群优化支持向量机(particle swarm optimization support vector machines, PSO-SVM)结合检测霉心病苹果,检测效率达到了93.33%。黄林生等[16]将高光谱技术与遗传算法优化支持向量机(genetic algorithm optimization support vector machines, GA-SVM)模型结合检测小麦赤霉病,检测精度为75%。罗强[17]基于高光谱技术与网格搜索优化支持向量机(grid search optimization support vector machines, GS-SVM)相结合,检测茶鲜叶含水量,检测精度为87.64%。谈文艺[18]将高光谱成像技术与GS-SVM模型相结合,判别苹果外部损伤,判别准确率为97.5%。
上述研究均采用单一优化算法进行建模分析,检测精度低。将高光谱信息与多种优化模型相结合,通过对比不同优化模型在参数相同的情况下的建模效果与模型运行时间,进而寻找出一种运行时间短、判别率高的最优模型,实现久保桃外部缺陷的快速检测。因此本文基于高光谱技术结合GS-SVM、GA-SVM、PSO-SVM三种优化方法建立判别久保桃外部缺陷的3种模型,综合比较各模型的性能,选出最优判别模型,以实现久保桃外部缺陷的定性判别。
1 支持向量机模型的参数优化
由于传统SVM模型随机生成参数值,导致分类精度不稳定[19],因此需要对SVM模型进行优化。训练模型的核函数(radial basis function,RBF)径向基函数的参数优化决定整个模型的效率,径向基函数的参数包括核参数g与惩罚参数C,文章采用遗传算法(genetic algorithm,GA)、粒子群算法(particle swarm optimization,PSO)、网格搜索算法(grid search,GS)3种优化方法对C和g值进行优化。
1.1 基于遗传算法的SVM参数优化
GA作为一种经典的寻优算法,具有适用性好、搜索速度快、效率高的特点。其核心步骤是:参数编码、设定初始群体、设计适应度函数、设计遗传操作、设定控制参数、筛选出适应度高的个体[20]。文章设置种群初始数量为20,最大进化迭代次数为200,5折交叉验证,惩罚参数C与核参数g的取值范围为[0,100],将参数对输入SVM模型中,对样本训练,计算个体的适应度值,直到达到最大迭代次数,停止搜索,输出(C,g)值,实现GA对SVM的参数优化。
1.2 基于粒子群算法的SVM参数优化
PSO具有收敛速度快且收敛于全局的特点,它从随机解出发,通过迭代粒子的位置与速度寻找最优解,并用适应度评价最优解[21]。文中设置PSO参数局部搜索能力C1为1.5,PSO参数全局搜索能力C2为1.7,种群初始数量为20,最大进化迭代次数为200,5折交叉验证,惩罚参数C与核参数g的取值范围为[0,100],通过更新粒子的位置与速度,计算粒子的适应度值,直到达到最大迭代次数,输出(C,g)值,实现PSO对SVM的参数优化。
1.3 基于网格搜索算法的SVM参数优化
GS是一种最基本的参数优化算法,它将C和g参数放在一个规定的空间内,依据拟定的坐标系划分成等大的网格,坐标系中每一组向量代表一组(C,g)值,通过将区间内的每一组(C,g)值带入SVM中验证预测性能,直到找到最优(C,g)值[22],确定SVM的最优参数。GS-SVM模型建立流程如图1所示。

图1 网格搜索法优化流程
2 实验方法
2.1 实验样本
实验样本选用2个批次,共302个久保桃样本,均采自于山西省晋中市太谷区西山底村桃园,其中第一批242个样本用于建模集和测试集,第二批62个样本用于验证集。将242个样本[120个完好桃,122个缺陷桃(50个疮痂桃和72个腐烂桃)]利用Kennard-Stone算法将三类样本按照3∶1的比例随机分为180个校正集和62个预测集。图2为三类样本图。
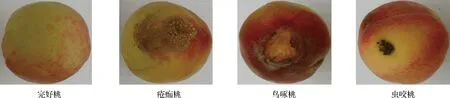
图2 完好桃与缺陷桃样本图
2.2 高光谱仪器及数据处理软件
文章采用的高光谱分选仪是来自北京卓立汉光公司,型号为:ZOLIX Gaia Sorter型的“盖亚”高光谱分选仪。设定样本的曝光时间为20 ms,样本到镜头高度为22 cm,电控移动平台前进的速度为2 cm/s,采集样本后需要进行黑白校正,具体校正方法见参考文献[23]。
高光谱图像采集与样本的黑白校正在软件Specview中完成,采用ENVI4.7软件(ITT Visual in formagtion Solutions, Boudler,美国)提取样本的光谱信息,采用The Unscrambler X10.1(CAMO AS, Oslo,挪威)软件、Matlab R2016a(The Maths Works,Natick,美国)软件进行光谱预处理、特征波长的提取及模型的建立与分析。采用Origin8.5(Origin Lab,美国)绘制原始光谱图、平均光谱图。
3 结果与分析
3.1 原始光谱曲线
感兴趣区域(region of interest, ROI)的选择应是最能代表图像内容特征的部分,该部分区域的选择能极大地提高图像处理和光谱数据分析的准确率和精度[24]。文章选择三类桃样本的表面80像素×80像素的ROI,经处理得到三类样本的原始光谱和平均光谱如图3所示。
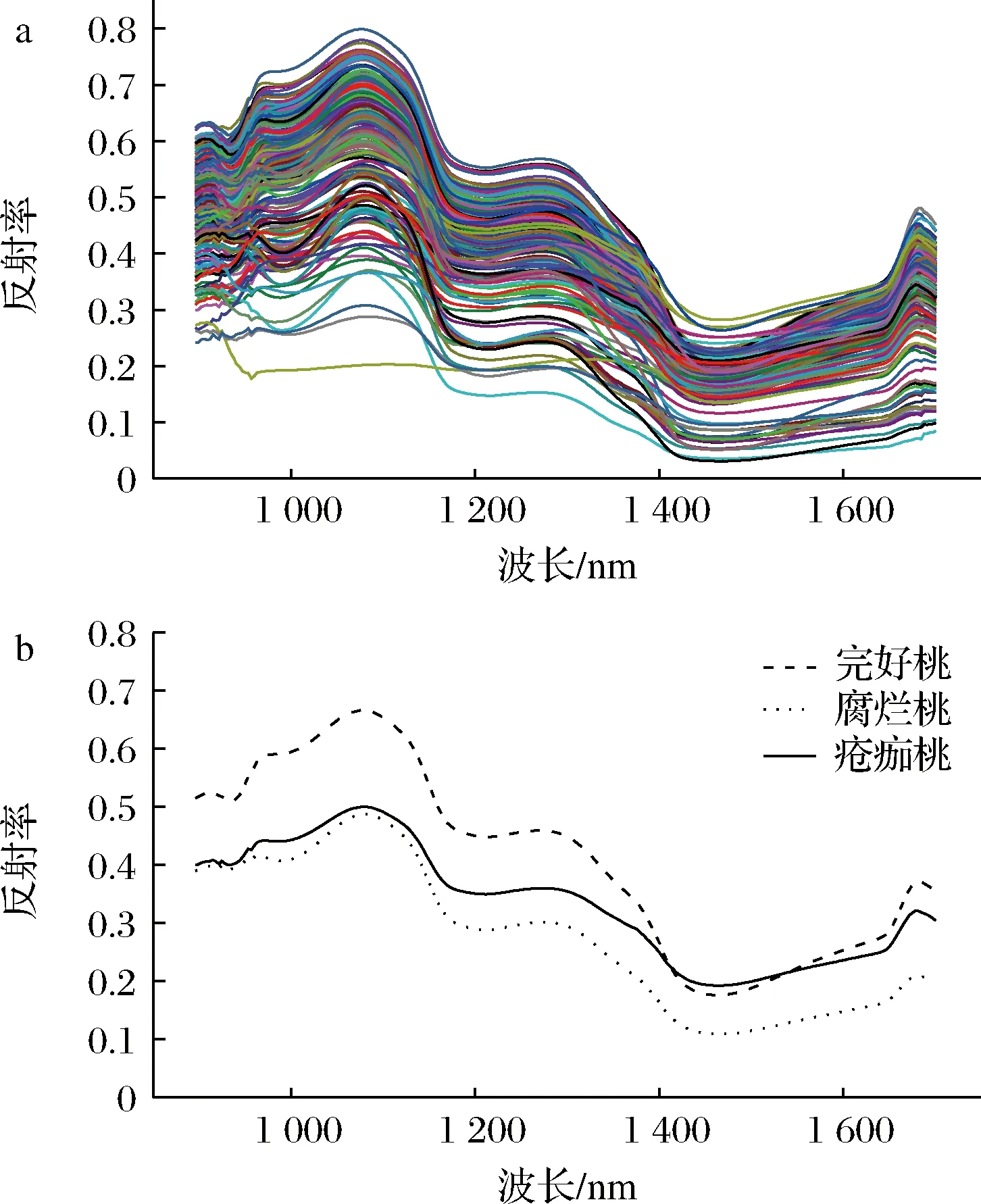
a-原始光谱曲线;b-平均光谱曲线
由图3可知,三类久保桃样本的平均光谱曲线存在着较大差异。三类样本均在1 211 nm和1 462 nm处出现明显吸收峰,其中900~1 211 nm处的吸收峰与久保桃表皮及桃果实细胞中叶绿素和类胡萝卜素的吸收有关,1 462 nm处的吸收峰与久保桃的内部水分和糖分吸收有关,分别为O—H三级和二级倍频特征吸收峰[25],三类样本的总体反射率呈现下降趋势。
3.2 光谱预处理
对采集到的光谱数据进行预处理可有效优化原始光谱数据,提高模型的精度[26]。PLS模型是一种经典的线性拟合模型,可用来解决变量之间的相关性及小样本问题[27]。文章采用导数间隙段(derivative-gap-segment)、基线校正(baseline)、中值滤波(median filter,MF)、导数卷积平滑(derivative-savitzky-golay)、光谱学(spectroscopic)等5种预处理方法来对原始光谱数据进行处理,对比原始光谱与经预处理后的光谱数据所建立的PLS模型的相关系数R2和交叉验证均方根误差(root-mean-square error,RMSE)来确定最佳光谱预处理方法(注:所建立的模型相关系数越大,均方根误差越小,所建模型精度越高)。光谱预处理结果见表1。
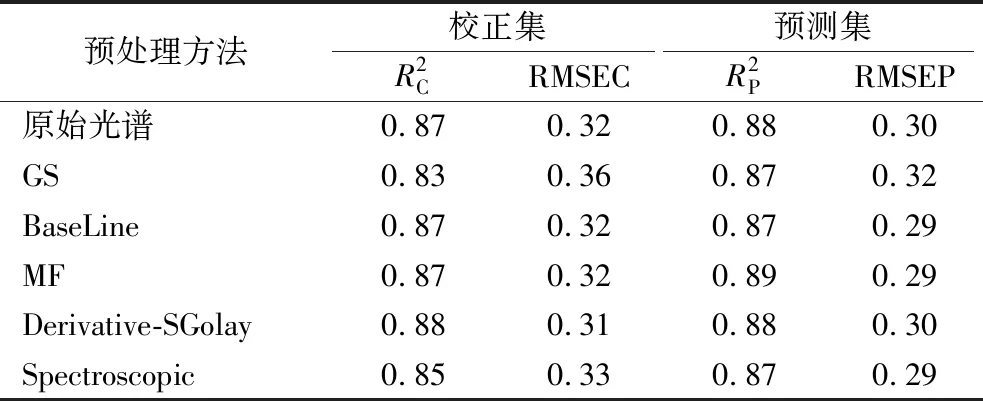
表1 不同预处理方法建立PLS模型
由表1可知,经MF预处理后的模型精度相对较高,标准偏差相对较低。其校正集决定系数为0.87,均方根误差为0.32。预测集决定系数为0.89,均方根误差为0.29。因此选择经MF预处理后的数据进行后续研究。
3.3 特征波长的选取
特征波长的提取是指通过从全波段中挑选一些有代表性的波长,冗余程度最少,共线性最小的,可以代表样本主要信息的优选值[28],这样做可以极大地提高运行速度,减少运行时间。本文采用回归系数法(regression coefficient, RC)和竞争性自适应重加权算法(competitive adaptive reweighted sampling,CARS)提取特征波长。
3.3.1 RC回归系数法
RC回归系数法是在采用PLS的预测模型中得到的,应用每个局部光谱信息的波长信息对应的RC系数来判断所构建的模型的预测能力的强弱的一种方法[29]。所以可根据RC系数绝对值的大小选择特征波长从而确定所需要的提取值,RC回归系数法提取过程如图4所示。
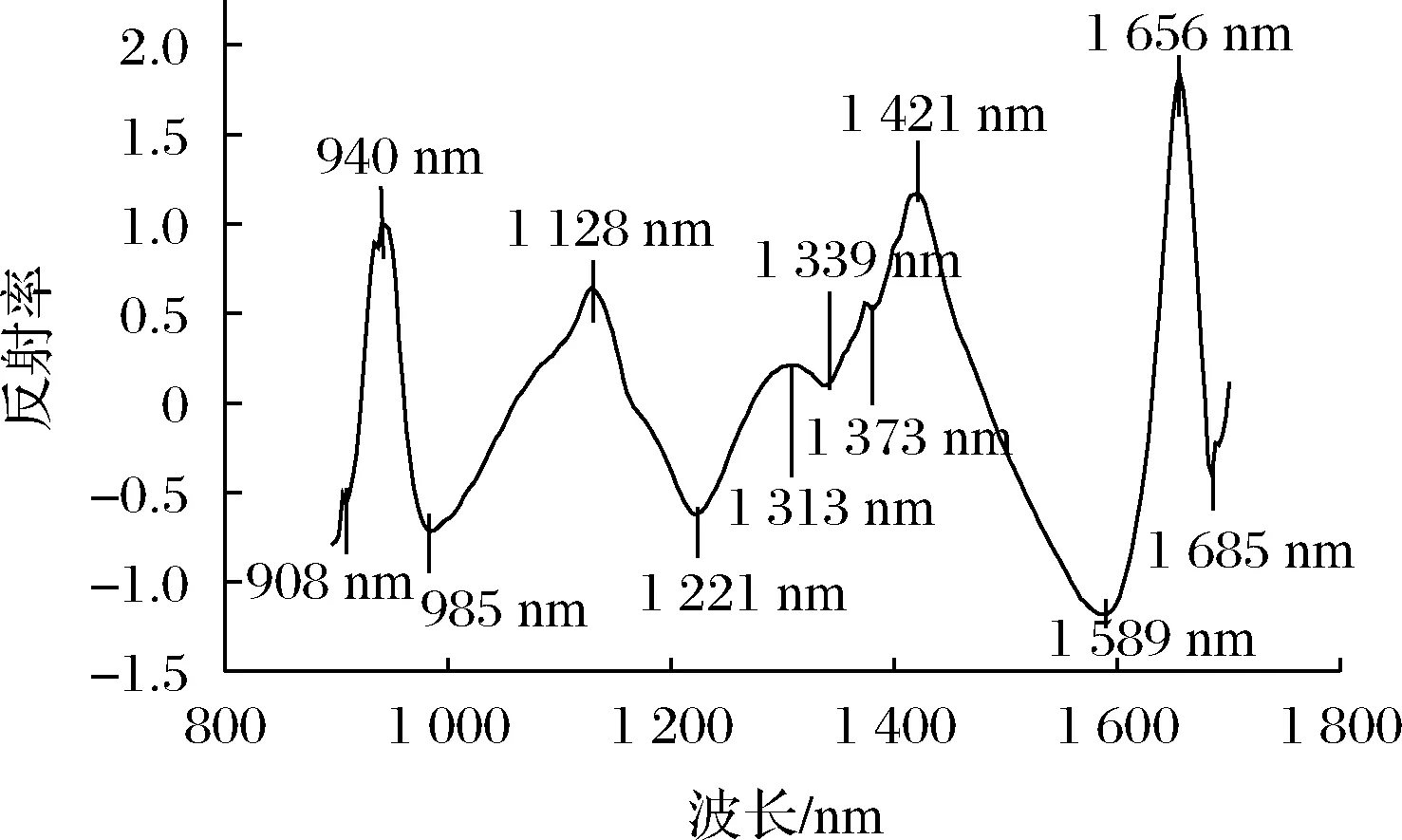
图4 RC提取特征波长
综上所述,根据RC系数极值绝对值的大小选择所需特征波长提取,文章从小到大依次选取了12个特征波长,分别为:908、940、985、1 128、1 221、1 313、1 339、1 373、1 421、1 589、1 656、1 685 nm。
3.3.2 CARS竞争性自适应重加权算法
CARS竞争性自适应重加权算法的原理是将蒙特卡罗采样与偏最小二乘回归系数法相结合来实现变量优选,本质是依据达尔文的生物进化论中的“适者生存”的原理,在进行变量优选的过程中,首先根据指数衰减函数进行无用变量的剔除,再将剩余的光谱数据利用自适应重加权算法建立模型[30]。CARS提取特征波长过程如图5所示。

图5 CARS提取特征波长
由图5-a可以看出,随着蒙特卡罗采样次数从1次增加到50次,所采集的变量在逐渐变少;从图5-b可以看出,RMSE值在第24次采样时均方根误差最小,最小值为0.323 4;从图5-c可以看出,第24次采样时均方根误差值最小,运行次数为24时,选取了25个特征波长,分别为:966、1 131、1 217、1 227、1 310、1 316、1 319、1 418、1 421、1 424、1 427、1 558、1 567、1 577、1580、1 583、1 596、1 599、1 605、1 643、1 650、1 653、1 656、1 659、1 685 nm。
3.4 预测模型的建立及结果分析
对久保桃的外部缺陷进行分类时,设定完好桃类别为1,疮痂桃类别为2,腐烂桃类别为3。运用GS-SVM模型,设置C与g的取值范围为[0,100],最终得到最佳参数对为;C=48.50,g=0.11。将此最佳参数对输入到SVM模型中,对SVM参数进行优化。
为了检测GS-SVM模型的性能,选取GA-SVM模型,PS0-SVM模型进行比较,将经过MF预处理后RC和CARS提取的特征波长值和类别值作为输入,得到GA-SVM模型的最佳参数为:C=6.38,g=0.61;PS0-SVM模型的最佳参数为C=35.63,g=0.10,将各个模型的最佳参数对带到模型中,对久保桃的外部缺陷进行分类,通过综合考虑模型的训练效果与预测效果,选择出最优的分类模型,结果如表2所示。
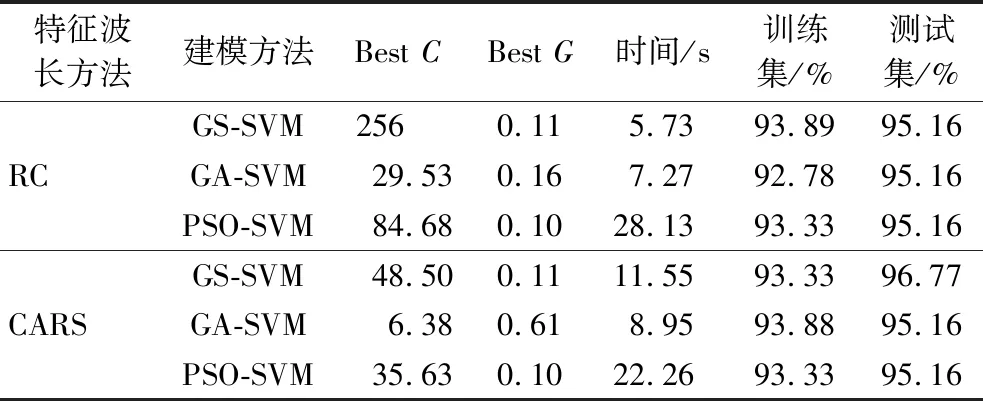
表2 三种模型精度对比
由表2可知,3种优化模型的判别准确率均达到了95%以上,其中基于CARS算法提取的特征波长所建模型的准确率较高。说明CARS为有效的波长提取方法。基于CARS所建的GS-SVM模型预测集的判别准确率最高,为96.77%,运行时间为11.5 s;GA-SVM模型、PSO-SVM模型预测集的判别准确率均为95.16%,但GA-SVM模型训练集的判别率为93.88%,且运行时间较短,为8.95 s;PSO-SVM模型训练集的判别率为93.33%运行时间为22.26 s,所以GA-SVM模型优于PSO-SVM模型。综合比较来看,CARS-GS-SVM判别模型最优,CARS-GA-SVM模型次之,CARS-PSO-SVM判别模型相对来说最差。因此选择CARS-GS-SVM模型为最优判别模型,其训练集的判别率为93.33%,预测集的判别率为96.77%,运行时间为11.5 s。
图6、图7、图8分别是CARS-GS-SVM模型、CARS-GA-SVM模型、CARS-PSO-SVM模型的寻优过程和预测结果。图6-a是GS对SVM参数的寻优结果三维图,图中三维坐标中的纵坐标代表分类准确率,横坐标代表参数(C,g)的值。由图可知,优化后的参数BestC为48.50,Bestg为0.11,图6-b是训练集与测试集的判别结果。由图6-b可以看出,测试集的2个误判数是将1个疮痂桃识别为完好桃,这是由于疮痂面积过小容易造成误判,1个疮痂桃识别为腐烂桃,则是由于疮痂桃表皮部位下面损伤造成的误判。完好桃与腐烂桃的判别率为100%。

a-寻优过程;b-训练集预测结果;c-测试集预测结果
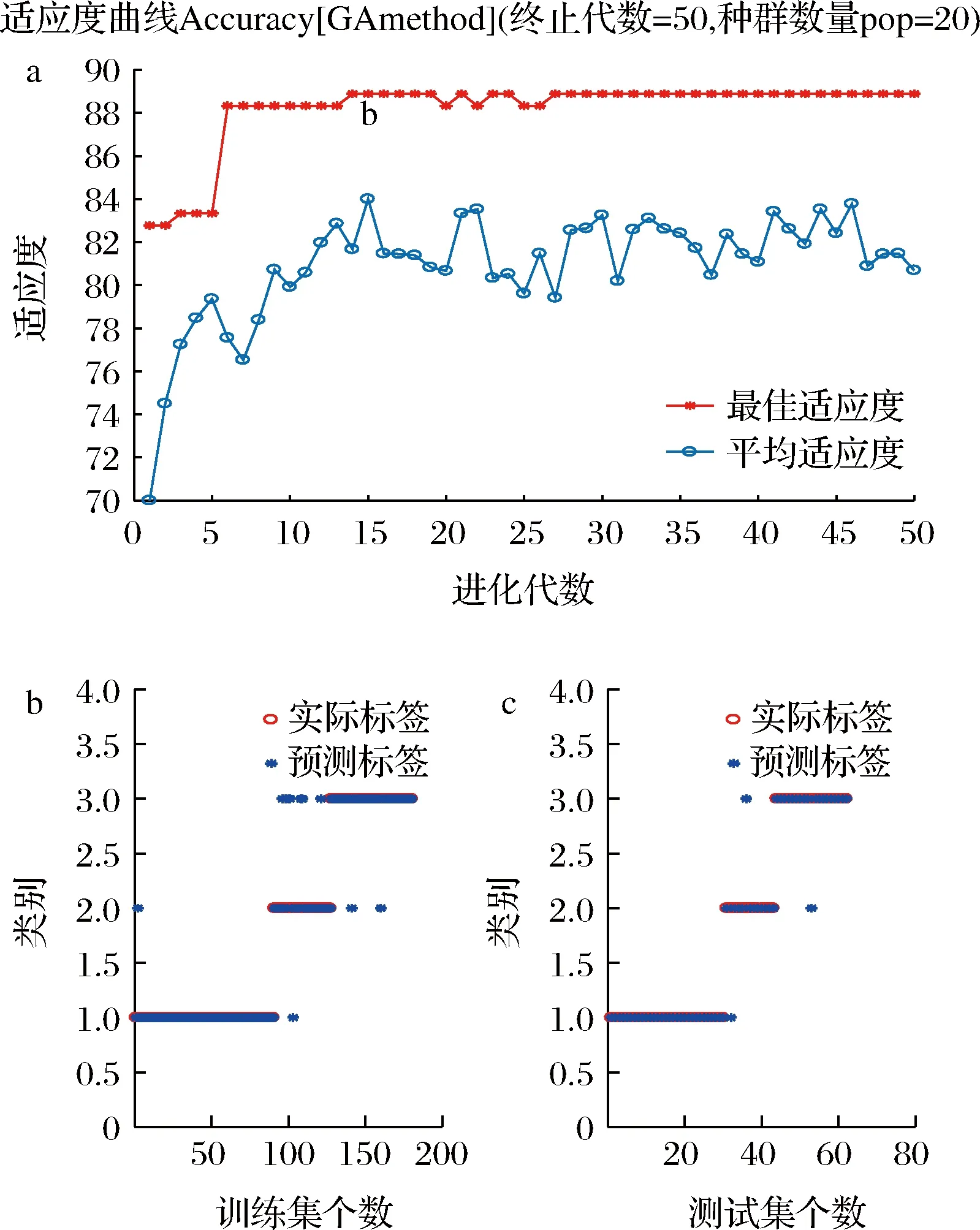
a-寻优过程;b-训练集预测结果;c-测试集预测结果

a-寻优过程;b-训练集预测结果;c-测试集预测结果
3.5 模型的外部验证
为了验证以上模型的准确性和稳定性,提升实验结果的可信度,利用第二批采集的久保桃样本进行模型的外部验证。挑选完好桃、疮痂桃、腐烂桃共计62个桃样本组成验证集,采用CARS算法提取特征波长后,将特征波长代入上述3种优化模型中进行预测,模型的参数与上述模型保持一致。模型外部验证的判别准确率如表3所示。
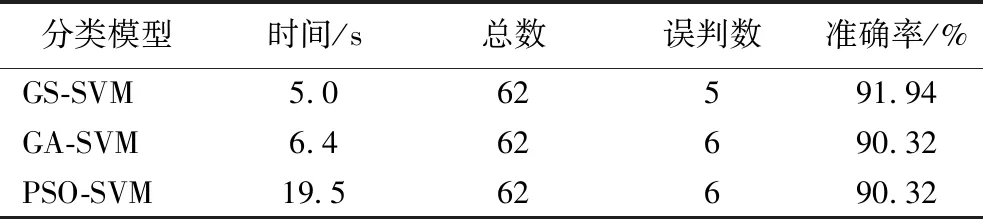
表3 各模型验证集分类结果
综合比较可知,GS-SVM模型判别准确率最高为91.94%,用时5.0 s;GA-SVM模型与PSO-SVM模型判别准确率相同,为90.32%,GA-SVM模型用时6.4 s,PSO-SVM模型用时19.5 s。GA-SVM模型所用时间低于PSO-SVM模型,因此GS-SVM判别模型最好,GA-SVM模型次之,PSO-SVM模型相对来说较差。与上述结论一致,说明CARS-GS-SVM模型稳定性好。
3 结论
为了快速检测久保桃的外部缺陷,实现优果优价。文章采用高光谱成像技术对久保桃的外部缺陷进行了研究,将高光谱技术的光谱信息结合不同的光谱预处理方法,分别建立GS-SVM、GA-SVM、PSO-SVM模型进行对比分析。结果如下:
b)基于RC、CARS两种方法提取的特征波长分别建立GS-SVM、GA-SVM、PSO-SVM模型,比较多种模型可知,CARS-GS-SVM模型效果最优,其训练集的判别率为93.33%,预测集的判别率为96.77%,验证集的判别准确率达到了91.94%,运行时间为11.5 s。较好地实现了久保桃外部缺陷的检测。研究结果表明,高光谱成像技术可以用来实现久保桃的外部缺陷检测,为开发久保桃的分级分选设备提供理论基础。
猜你喜欢
特产研究(2022年6期)2023-01-17
北京航空航天大学学报(2022年8期)2022-08-31
制导与引信(2017年3期)2017-11-02
实用口腔医学杂志(2017年6期)2017-09-19
中国照明(2016年4期)2016-05-17
工业设计(2016年11期)2016-04-16
中国光学(2015年5期)2015-12-09
环境科技(2015年6期)2015-11-08
物理实验(2015年9期)2015-02-28
电网与清洁能源(2015年2期)2015-02-28
