
面向多源异构数据的航天器故障知识图谱构建方法
2023-08-31 06:29唐荻音丁奕州刘文静王淑一赖李媛君
空间控制技术与应用 2023年4期
唐荻音, 丁奕州, 王 轩, 刘文静, 王淑一, 赖李媛君
1. 自动化科学与电气工程学院,北京航空航天大学, 北京 100191
2. 北京控制工程研究所, 北京100094
0 引 言
随着我国航天事业的蓬勃发展,在轨运行航天器的数量不断增多,为保障航天任务的正常执行,对于航天器的性能维护与故障诊断也愈加重要.现如今,航空航天领域中的系统设备向着智能化、模块化、复杂化和精密化方向发展.航天器装备机电系统中传统的模拟系统逐渐被数字系统所取代,信息化程度不断提高,带来了航天器故障定位、隔离、监测以及维护困难等问题.
航天器全生命周期的各个阶段产生并积累了大量的数据和专家知识,这些数据的来源以及存储介质各不相同,数据形式不一,结构多样.如何从这些多源异构的海量知识和数据中过滤出有用的信息,将其处理形成结构化的知识并在知识间形成有效融合,对航天器故障诊断以及性能维护有着非常重要的意义.
知识图谱作为描述海量知识、知识属性及知识间关系的有效工具,自2012年谷歌提出以来,受到了学术界和工业界的广泛关注.它可以通过机器学习、自然语言处理等相关算法,以资源描述框架和属性图的形式进行自动化图谱构建,并实现高效、快速的信息搜索.航天器故障类型多、故障原因复杂、影响因素广泛和排查难度大,知识图谱能够借助其在构建知识网络与展现知识关联方面的巨大优势,为具有复杂关系的航天器故障知识信息提供一种新的获取、存储、组织、管理、更新和展示的手段,并提供更符合认知习惯的故障知识应用与故障推理方式,从而提高故障定位的效率和精准程度.
目前,在多个领域,已有学者基于领域故障数据构建了故障知识图谱.文献[1]采用文本挖掘的故障短语抽取方法,建立了高铁列控车载设备故障知识图谱,为高铁的安全运行和故障排查提供保障.文献[2]提出了一种发动机故障知识图谱构建方法,基于BERT和BiLSTM-CRF相结合的实体识别框架,提取故障资料中的专家知识生成数据层中的实体以构建知识图谱.文献[3]提出了一种自顶向下和自底向上法相结合的航天软件信息知识图谱构建方法,并采用改进的骨架法构建本体.文献[4]设计了一种汽车故障知识图谱构建流程,在传统构建流程的基础上加入文本预分类和实体重组流程.
然而,目前故障诊断领域关于知识图谱构建的方法往往聚焦于从文本和表格数据中提取知识,而没有考虑对象系统在测试、运行期间产生的大量实测数据中所蕴含的故障知识.同时,虽然航天器的故障知识来源广泛,但描述形式差别大、数据量也十分有限,因而基于纯故障数据挖掘实体和关系的工业界常用图谱构建方法也并不适用.因此,面对包含时序数据在内的航天器多源异构故障信息,本文提出一种本体-实体双向约束的知识图谱构建方法.一方面自顶向下基于领域专家知识初步构建本体,另一方面自底向上通过故障数据挖掘实体以优化本体,通过本体与实体的双向约束,实现多源异构故障信息的知识融合.采用上述方法,本文以航天器控制力矩陀螺为例,构建了故障知识图谱,验证了方法的可行性和有效性.
1 航天器多源异构数据分析
当前,实际应用的航天器故障诊断技术主要依赖设计、制造和分系统地面测试期间积累的专家知识.这些知识通过FMEA分析表、故障案例、排故经验和航天器日志等方式积累,故障知识稀疏、分散、独立且结构形式多样,难以覆盖全部故障并实现知识间的共通互享.其次,历史及在轨遥测数据中隐含的大量与故障相关的信息没有被有效利用,故障模式之间、数据与故障之间的隐性关联关系没有得到充分挖掘.
本文首先依据数据结构类型对航天器故障数据分类,将多源异构故障数据划分为有限数量的类别进行后续处理.以航天器控制力矩陀螺为例,根据目前所掌握的资料,可分为文本非结构化数据、表格半结构化数据、结构化规则知识以及航天器运行遥测数据.
1.1 结构化规则知识
结构化的数据一般指可以使用关系型数据库表示和存储、可以用二维表来逻辑表达实现的数据.该类数据存储和排列都符合一定规则.在航天器故障知识中,专家规则一般以结构化数据的形式进行存储.专家规则由领域专家根据设计指标或经验设定的相关规则组成.本文涉及到的航天器专家规则存储在以规则代号、判别表达式、故障现象和故障等级等为列名的关系数据库中,如表1所示.因为结构化的规则数据一行表示一个实体信息,每一列数据的属性相同,因此无需过多对结构化规则知识进行预处理,可以直接根据构建的本体模型映射生成知识图谱.

表1 故障事件判别规则Tab.1 Fault event discriminatory rules
1.2 半结构化表格数据
半结构化数据是并不符合关系型数据库的数据模型结构.它的特点是,数据的结构和内容混合,二者间没有严格的区分,但包含相关标记,可以用来分隔语义元素以及对记录和字段进行分层.航天器故障知识存在着许多以表格形式存在的半结构化数据,如FMEA分析等.该类数据的不能直接映射到知识图谱中,但较之非结构化的数据更加便于被提取为结构化的知识.针对此类资料,采用人工分析构建包装器来提取规则,从而将半结构化数据转化为结构化数据.
1.3 非结构化数据
非结构化数据是没有固定结构的数据.航天器上产生的以文本形式为载体的大量非结构化数据主要源于设计资料、航天器日志、故障记录以及异常报文等.来源于航天器的非结构化数据属于文本密集型,航天器的故障知识就暗含在这些文本数据中.通常,故障文本的形式如图1所示.文档中会包含航天器可能发生的故障现象、故障原因以及维修措施,故障文本按照一定的规范记录,便于文本的预处理和知识的获取.非结构化数据将采用文本处理方法进行实体、关系和属性的挖掘.

图1 文本数据示例Fig.1 Text data example
1.4 航天器遥测数据
航天器中除了设计和可靠性专家本身所能提供的专家经验外,其使用过程中的知识挖掘也是对诊断知识的重要补充.这部分数据除了航天器日志、异常报文等文字材料,还包括大量运行遥测数据.通过遥测数据的异常表征可以获得航天器的故障信息.图2展示了本文案例中涉及的经脱敏和预处理后的遥测数据样例.数据随时间变化,其异常表征与航天器故障模式直接关联.遥测数据存在着数量大、范围广、实体不明确、关系不清晰和属性不全面等缺陷,需借助数据挖掘技术,挖掘其隐含的异常规则,用于扩充故障知识来源,丰富故障知识图谱.
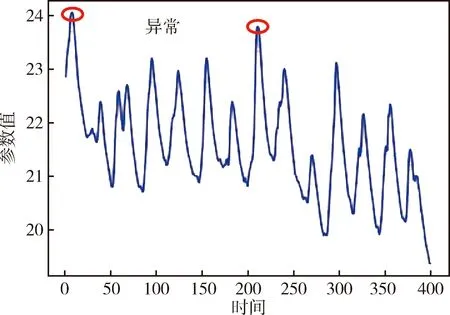
图2 遥测数据示例Fig.2 Telemetry data example
2 故障知识图谱构建方法概述
本文知识图谱的架构包含逻辑框架以及技术框架,并用三元组作为基本表达方式.逻辑框架由本体层和实体层组成,其中本体层用来规范实体、关系以及属性间的联系,实体层中知识图谱的知识以事实的形式存储.知识图谱的技术框架由构建知识图谱时所采用的技术手段组成,包含数据预处理、知识抽取、知识融合、知识存储等方法.
知识图谱逻辑框架的构建方法一般分为自顶向下和自底向上两种[5].自顶向下的方法指先构建知识图谱的本体层并定义本体,再依据本体从数据中抽取知识,抽取所得的实体、关系以及属性与本体定义的实体类型、关系类型以及属性类型相对应,是一个从抽象到具体的过程.而自底向上的方法则是先从数据中抽取出实体、关系和属性构成实体层,再归纳聚类,抽象出本体形成本体层[6].本文所采用的逻辑框架构建方法为一种本体-实体双向约束的方法,具体描述如下节.
2.1 故障知识图谱构建流程
虽然航天器的故障知识来源广泛,并通过FMEA分析表、故障案例、排故经验和航天器日志等多种载体记录,但数据量十分有限,难以直接通过故障知识和数据归纳抽象出本体层以及自底向上构建图谱.另一方面,采用自顶向下的方法则被专家定义的领域知识本体框架所限制,无法完全覆盖从设计资料、实测数据等间接故障信息中挖掘到的新故障知识.因此,本文采用自顶向下和自底向上相结合方法构建航天器故障知识图谱,构建本体-实体双向约束.该方法具有自顶向下方法准确性的同时也具有自底向上方法对新故障知识的包容性.
如图3所示,本文中知识图谱的构建流程为:首先初步分析航天器的多源异构数据,筛选可用的故障信息资料.对于结构化程度高的故障信息,直接提取知识;而对于结构化程度低的间接故障信息,则需对其进行数据清洗以及预处理.其次,本文提出一种改进的IDEF5法,依据专家定义的领域知识和预处理的数据结果归纳构建知识图谱本体层,并依据挖掘的新故障知识不断优化完善本体层.然后,针对不同的故障信息资料采用不同的方法提取知识,生成实体、关系以及属性,与本体层中规范的本体模型相对应.最后,提取知识在实体层融合后将知识图谱储存到图数据库Neo4j中并可视化展示知识图谱.
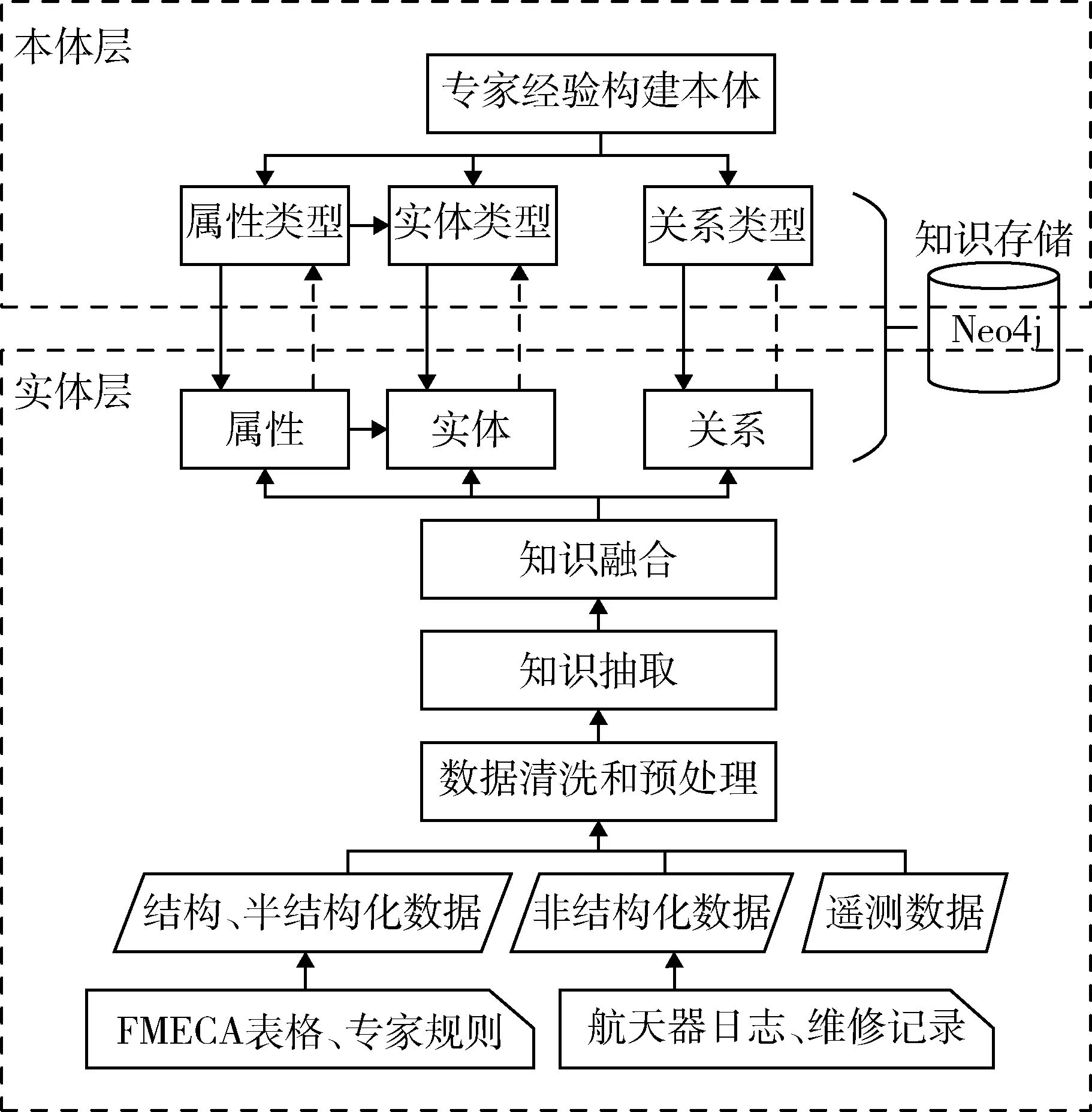
图3 知识图谱构建框架Fig.3 Knowledge graph construction framework
2.2 本体的构建
由于航天器故障知识专业性强、来源多样,因此在专家经验的指导下,采用改进的IDEF5法构建本体.传统的IDEF5法[7]的本体构建方法流程分为5步包括:组织和范围、数据收集、数据分析、初始化本体和本体的确认.本文根据航天器故障数据特点在传统IDEF5法的基础上对本体构建方法进行改进,增加了优化和验证环节,以确保本体的准确率和覆盖率.
改进后的 IDEF5法流程为:
1)确定本体的领域和范围.将本体限定在航天器故障诊断领域内.
2)数据收集.收集了多种形式的航天器故障数据,例如控制力矩陀螺的FMEA分析表、航天器故障专家规则、维修排故文本资料等.
3)数据分析.对原始数据分析,将专家规则和控制力矩陀螺FMEA表格中专业术语进行整理分类,并分析故障文本资料确定其中与故障有关的关键词.
4)知识本体的初步开发.根据数据分析的结果和专家经验建立初步本体模型,其主要以专家经验为指导、以现有故障资料为补充,以项目名称、故障模式以及规则代号为核心实体类型构建.
5)本体的优化与验证.用从间接故障信息中抽取的知识优化验证本体.从遥测数据中挖掘新规则,从非结构的文本数据中抽取实体,用以补充知识图谱,并优化本体模型,同时也可用新产生的知识反复验证本体的准确率和覆盖率.
采用改进的IDEF5法构建的知识图谱本体模型如图4所示.
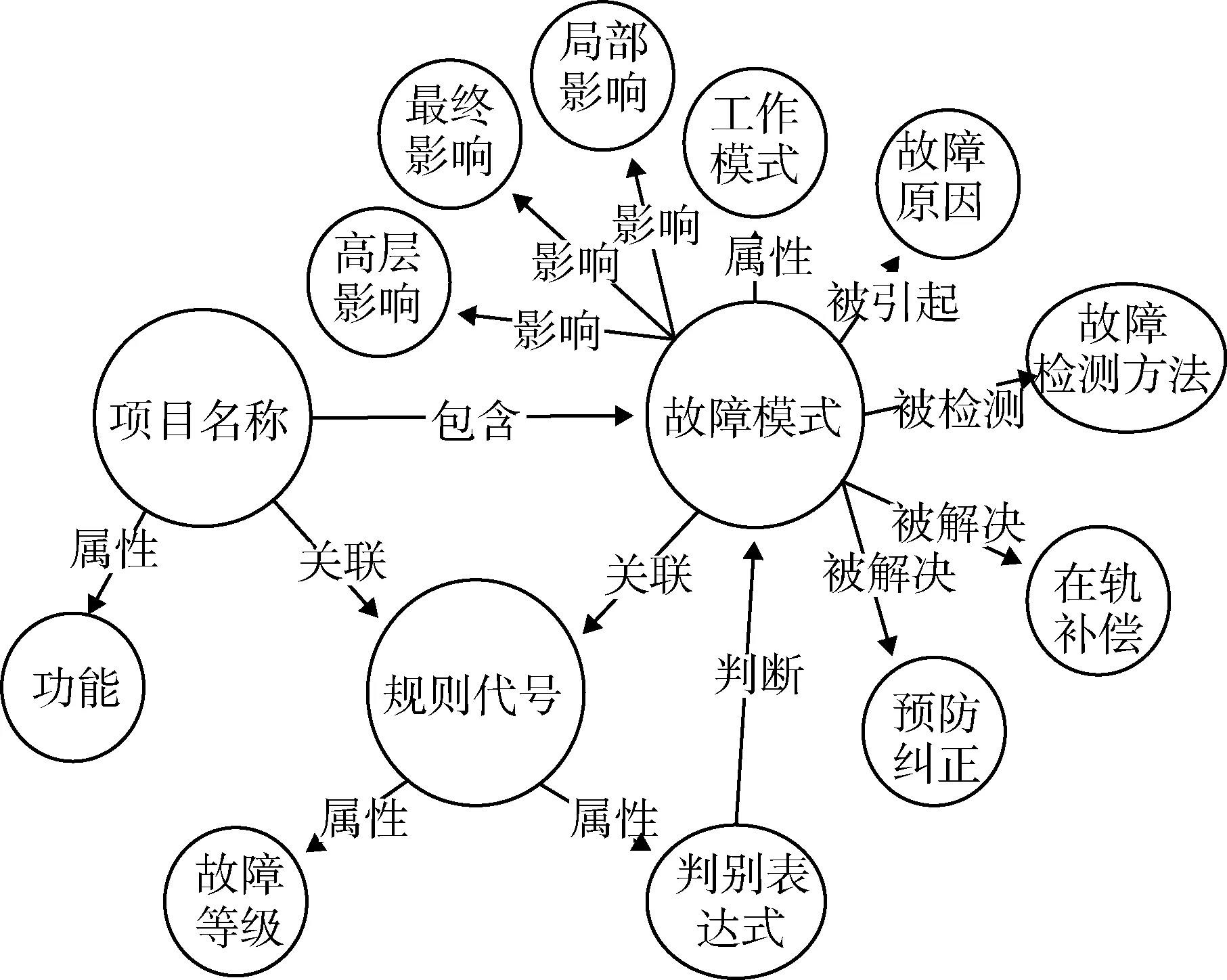
图4 知识图谱本体模型Fig.4 Knowledge graph ontology model
以控制力矩陀螺故障知识资料以及专家规则为例构建的本体包含14种实体类型(如故障模式、故障原因和故障检测方法)、8种关系类型(如判断、包含和关联).根据抽取的知识验证本体模型,其能够覆盖原有的专家知识也能容纳从航天器遥测数据中挖掘产生的新故障知识.
3 多源专家知识的图谱转化
3.1 (半)结构化数据的图谱转化
本文中航天器的专家知识来源于专家规则以及专家经验资料.专家规则以结构化的形式存储在关系型数据库中,而部分专家经验资料以结构以及半结构混杂的形式储存在FMEA分析表中.本文针对知识的不同形式提出相应的提取方法.
关系型数据库中的知识存储模式为整套表格的完整设计,图数据库中的知识存储模式为节点、关系及其标签、属性.图数据库中一个实体(含关系)是一个基本存储单元.标签是划分实体和关系类型的依据,有标签名这一个要素;属性存储节点信息,有属性名、属性值两个要素.本文将关系型数据库的模式映射到图数据库中的模式,以此来实现知识转化.
面对存储在表文件中的知识,按照图结构的方式进行转存,统一对有标签的、可结构化处理的故障数据进行“实体”、“关系”的转换.以图5中控制力矩陀螺的FMEA分析表为例,说明该分析表中的结构化和半结构化的数据如何将进行三元组构建与转储.由于本文所应用与故障诊断领域的知识图谱较通用知识图谱的数据来源略少、数据量级较低,因此知识图谱的构建上多采取以空间换时间的原则,提出两种知识转化方式.
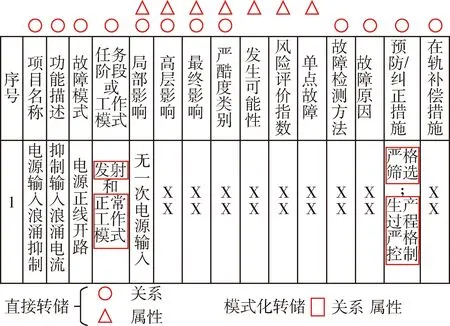
图5 某型控制力矩陀螺FMEA分析表Fig.5 FMEA analysis table of a certain type of control torque gyro
(1)直接转储
对表格中已经规范化的结构化的信息,可以直接进行转储.关系数据库中的列名,对应于图数据库中的标签、属性或关系,应根据包含信息和功能的不同注意以下事项:1)表格中的某些列名可以同时作为属性或标签,或者关系;2)为了查询或推理的便利,某列表格中的值既可以作为节点,又可以重复作为其他节点的属性值;3)作为边的关系种类应尽可能的少,以降低推理的难度.
(2)模式化转储
表格中的多数信息是规范的、格式化的,但存在部分需要清洗的半结构化数据,直接通过标志字符或停用词检查对长子句结构化抽取与语句合并.在本体的指导下,对合并结果进行归纳整理,然后将结果中的实体、关系以及属性与本体相对应.
图5以某型控制力矩陀螺FMEA分析表为例展示了本文面向功能需求将结构化数据直接进行三元组转储的过程.在这个过程中根据本体规范,列名可以是节点标签也可以同时是属性或者关系.将表格中存在的大部分信息直接转储,而预防/纠正措施中的内容采用模式化转储方法,分割内容后完成转储.最终将构建的三元组存储到图数据库Neo4j中.总共从FMEA表格中共提取出281个实体,512条关系.
通过Neo4j中Cypher查询语言对构建结果进行验证,以项目名称为核心节点进行搜索,即可获得该项目有关的故障知识,查询结果如图6所示.结果展示了一次电源等5个项目以及与之有关的故障模式、导致故障产生的原因以及解决措施等相关信息,同时体现了不同项目间的关联关系.验证了本文(半)结构化数据图谱转化方法的有效性和可行性.
3.2 文本数据的知识提取
随着自然语言处理技术的发展,涌现出很多较为成熟的中文文本处理工具.航天器故障诊断专业领域的相关资料多具备一些规范的表述和逻辑,但可供中文文本处理工具训练的数据稀少.因此,本文充分利用规范表达的优势,减少数据依赖,采用本体-实体双向约束逻辑,提出关键词识别+文本分类的方式对具有一定结构的故障文本进行知识抽取.在实体层,采用经典CNN模型与多头注意力机制CNN模型相结合的方式抽取实体以及关系,并对比验证;在本体层,根据抽取的实体以及关系对应的类型优化完善本体.
本文的知识抽取过程,使用现有工具jieba分词和pyltp,对文本资料预处理,内容包括分词、停用词去除、分句等文本清洗工作.
本文采用经典的CNN文本分类模型提取实体.在该方法中,模型首先根据语料库将文本子句转化成id表示的向量形式,进行序列填充对齐后再接全连接层,作为网络输入;以实体类型作为网络输出.采用关系分类的多头自注意机制CNN分类模型提取关系,则是根据语料库对句子进行分词,将词转换成向量形式,进行序列填充对齐后再接全连接层,作为词嵌入特征;同时将每个词与句中两个实体的相对距离也转为嵌入向量,作为距离特征;两特征拼接后才是整体网络输入;以关系类型作为网络输出.两种方法互为补充,经典的CNN模型解决已知关系类型的实体标签分类问题,关系类型由分析文本所得.而多头自注意机制CNN分类模型,解决实体及标签已知的关系分类问题.因此方法能够相互验证,提高知识抽取的准确率.故障文本抽取的流程如图7所示.
以图1中的文本模块为例,首先构建所需的专业词典、语料库以及关系类别,并确定用于划分语句的关键词,如“故障现象”、“故障原因”等.然后通过分词确定长文本中关键词语等词句的位置,以标点、关键词和停用词等为标识,进行长文本分割.针对实体抽取采用经典的CNN文本分类模型.在去符号后构建较为规整的子句,经关系词提取和文本分类[8-9]得到初步的三元组列表.而针对关系抽取则采用多头注意力机制改进的CNN文本分类模型,输入完整句子并进行实体标注,后经关系分类得到初步的三元组列表,将两种方式得出的三元组列表,对比验证,得到最终的三元组将其去重后导入知识图谱.
针对故障文本中提取出的不符合本体模型的三元组可以将其拆分并对应本体或对本体模型优化以覆盖抽取的新实体,利用本体将不同来源的知识进行融合.例如,故障现象在本体中没有对应的实体类型,经分析把内容拆分为项目名称和故障模式,以对应本体中的实体类型,从而将由多源异构数据组成的三元组纳入统一本体.由于数据来源质量高,且有本体指导实体保证知识图谱的质量,只需进一步利用Neo4j中节点相似度算法计算节点相似度,并设置阈值筛选异常节点,最后人工审核处理异常节点,删去或者合并冗余节点实现知识融合.
将故障文本中提取出的三元组存储到Neo4j数据库中并可视化展示,利用Cypher查询语言验证方法的可行性,查询结果如图8所示.其中以项目名称为核心节点,列举了电源等4个项目有关的故障模式、故障原因和解决措施等相关信息.
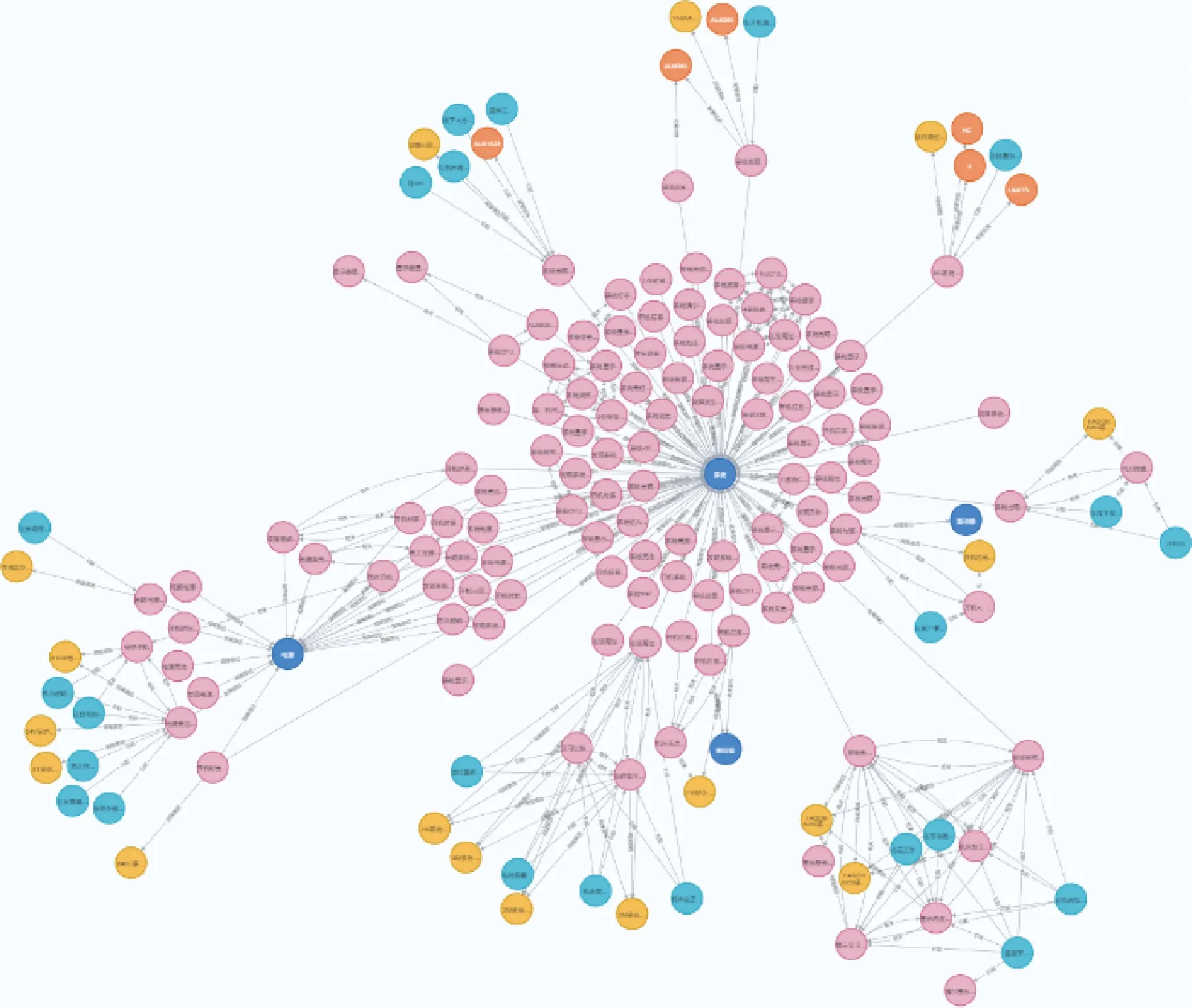
图8 故障文本提取结果Fig.8 Fault texts extraction results
4 遥测数据规则挖掘
航天器的海量遥测数据中暗含着异常信息,如何从中挖掘出故障知识,对生成专家规则意义重大.而生成的专家规则是构建航天器故障知识图谱的重要数据来源.
本文提出一种基于航天器遥测数据规则挖掘的知识提取方法.首先根据专家经验以及遥测参数的物理含义,确定发生故障的项目名称以及故障模式,由二者组合形成故障描述,并从中提炼出故障名称.其次根据领域专家经验确定与故障相关的参数,再使用基于图卷积网络的空间模块挖掘遥测参数之间的关联关系.然后对每个涉及的遥测参数进行单独的阈值挖掘,确定单个参数的阈值区间.最后根据参数的关联关系以及单参数的阈值生成故障判别表达式,再由人工审核查验分析规则的可用性,查验可行后判定故障等级以及给出该条规则的规则代号和预案编号.规则生成完成后存储在关系数据库中形成结构化的专家知识,以便接下来转化成为知识图谱进行可视化展示.
4.1 遥测参数的相关关系挖掘
针对海量的航天器遥测数据,在参数相关关系挖掘前,需要对数据进行清洗和预处理.因为遥测参数序列平稳部分占比大的特点,采用分段聚合近似对遥测数据采样处理[10].方法的核心思想是将时间序列分割成子列并求均值,用均值替代原始序列,达到缩减数据量的效果.序列分割的方法则是采用等长分割的方法,提前依据遥测数据总量以及特征,设定子序列长度切割原序列.
本文提出一种基于图卷积网络的空间模块,并通过它自动创建遥测参数之间的相关性网络图,以描述和可视化遥测参数之间的空间相关性特征.给定一个有I个输入参数的数据集X,该数据集的图可以表述为G=(V,E),其中V={v1,v2,…,vI}是I个节点的集合,E是边的集合.E中的边可以描述为e=(vi,vj)∈E,其中vi和vj是V中的任意两个节点.邻接矩阵A⊂RI×I显示了节点之间的关联性,其计算方法是
(1)
其中Aij是邻接矩阵的一个元素,wij表示节点vi和vj节点之间的关系度.
为了构建邻接矩阵,本文将MIC相关系数计算方法嵌入到算法中,以捕捉所有的函数关系(特别是非线性函数),以及不同函数的叠加.
由于缺乏先验知识,遥测参数之间的相关性可能是未知的,所以本文通过训练迭代来自动学习邻接矩阵.动态构建邻接矩阵的过程如图9所示,随着训练样本和迭代次数的增加,提取到的参数相关性变得更加准确.
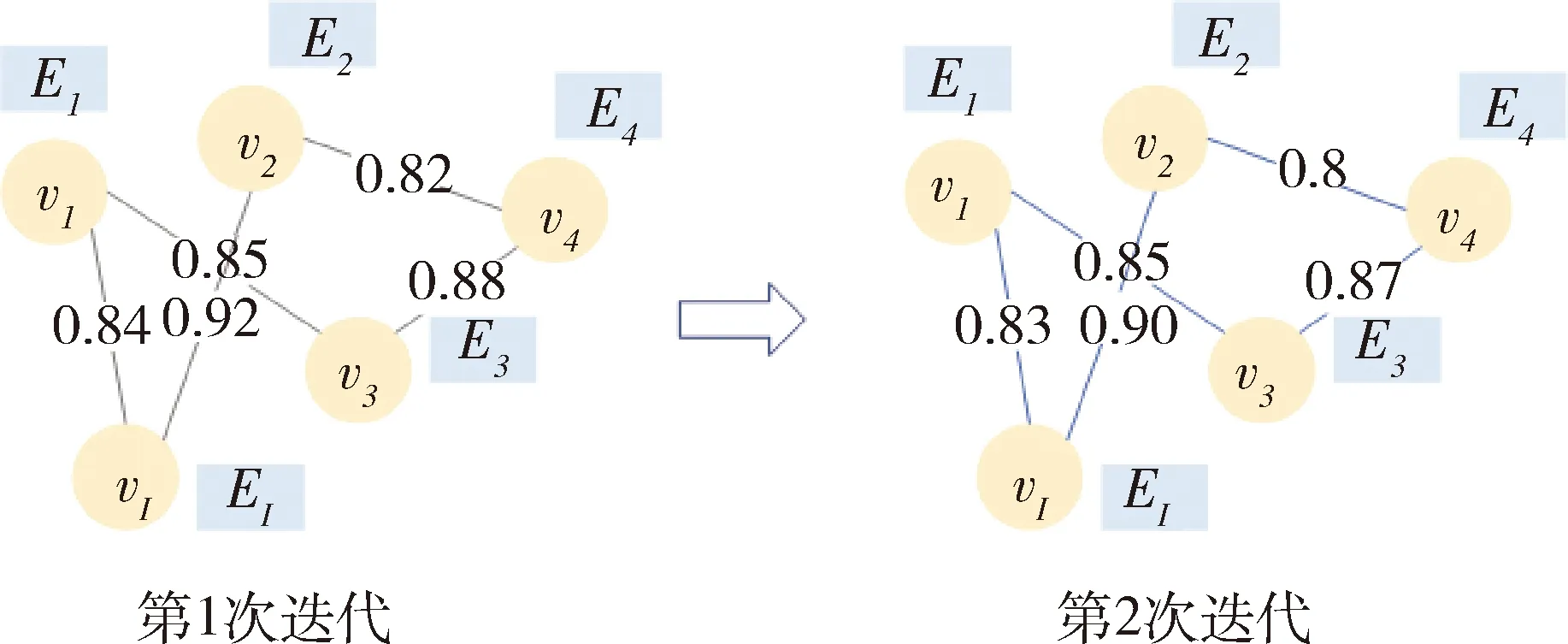
图9 动态链接结果Fig.9 Dynamic linking results
(1)获得每个节点的嵌入向量
Bi=tanh(yEmb(vi))
(2)
其中,Bi是节点vi的嵌入向量,它是随机初始化之后,在训练过程中不断迭代学习;γ用于进行线性变换,tanh用于进行非线性变换.
(2)构建邻接矩阵
Aij=Relu(MIC(Bi,Bj))
(3)
其中MIC(Bi,Bj)用于计算节点嵌入向量Bi和Bj之间的关联性.Relu是用于避免负相关的激活函数.
(3)使邻接矩阵稀疏化
(4)
其中,为了降低图卷积的计算成本,通过设置预定义的阈值τ,任何低于τ的Aij将被设置为零,来消除遥测参数之间的弱相关关系,使邻接矩阵变得稀疏.
并且设定终止阈值,若遥测参数间的相关性数值大于终止阈值,则说明参数间的相关关系已挖掘成功.
4.2 遥测参数的规则挖掘
本文采用流数据阀顶点理论模型(streaming peaks over threshold,SPOT)来挖掘遥测数据的阈值[11].该算法假设极值与数据分布之间相关性趋向于0,可以忽略原始数据的分布情况,适用于遥测数据挖掘.
SPOT算法首先进行POT计算,然后将其作为初始化步骤并将流数据作为输入.采用算法挖掘数据阈值的流程为.1)对前n个数据进行POT计算,得到初始阈值;2)对新数据进行判断,超出初始阈值为异常数据,大于经验阈值小于初始阈值则为峰值数据;3)如果是异常值指标,则直接标出不参与迭代计算,如果是峰值则继续参于迭代计算,计算当前阈值.
以表1中规则代号为Fault_011的专家规则为例,说明如何生成规则中的判别表达式.首先根据专家的经验知识可知故障与D1、D2和D3参数有关,其次通过相关关系挖掘得出D1、D2、D3与D4、D5之间存在强相关关系,其中一个参数异常就可判断故障发生,则参数间用or连接.然后挖掘每个参数的正常阈值,对其取反即可得到参数异常的不等式,如D1>3.5.最后参数有机组合得到判别表达式为(D1>3.5或D2>3.5或D3>3.5或D4>3.5或D5>3.5).之后再由专家审核后,便可生成专家规则.
在生成专家规则后,需要依照本体将专家规则,在实体层进行融合.由于专家规则经过严格的审核和校对,知识质量高,可利用本体确保知识的准确性,实现初步知识融合.进一步,在多源数据全部存储在知识图谱中之后,采用Neo4j中的节点相似度算法计算节点相似度,人工处理相似度异常的节点,实现知识更深层次融合.
利用Cypher查询语言验证方法的可行性,搜索知识图谱中规则代号为Fault_011与Fault_032的专家规则融合结果图10所示.例如,以滤波母线电路(项目名称)为核心节点进行搜索,未融合前只显示该节点的故障信息,融合后增加了规则代码、严酷度等级以及规则判别表达式3个节点,丰富节点信息,完善知识图谱.此外,该图谱还能为基于规则的航天器故障诊断提供知识支持,可利用网络节点中的规则信息实现故障判别以及故障严酷度等级划分,有实际的工程应用意义.
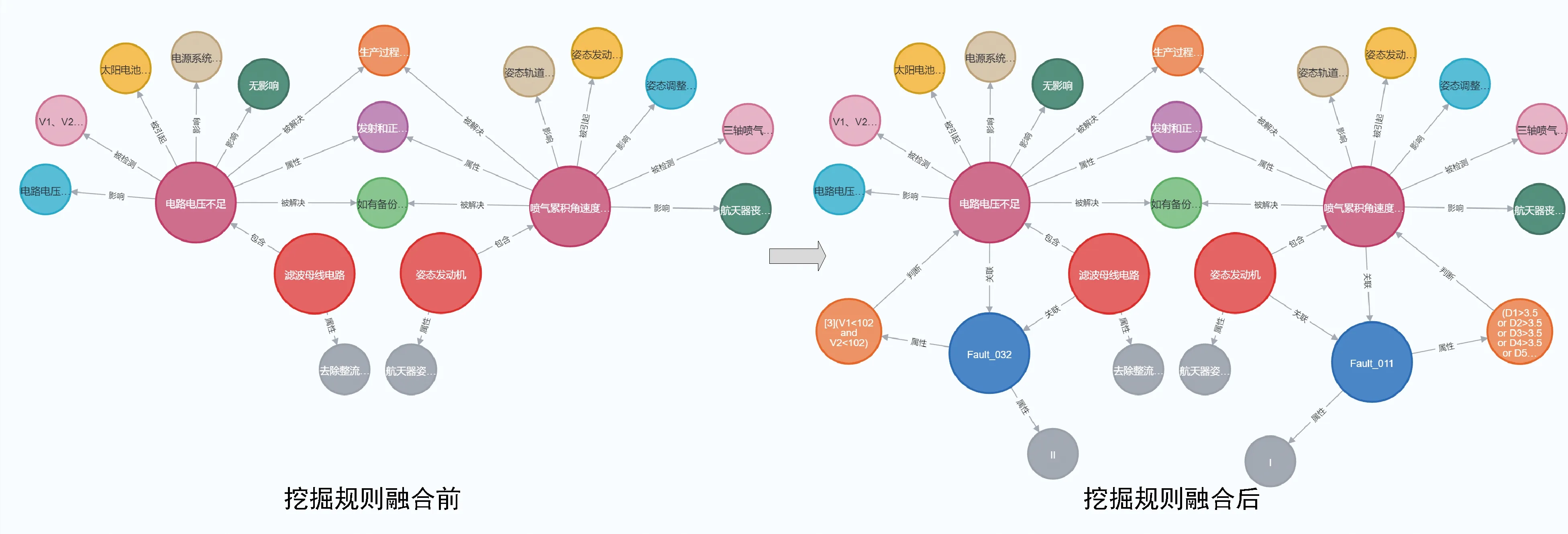
图10 挖掘规则融合结果Fig.10 Mining rules fusion results
5 结 论
本文针对航天器多源异构故障数据的特点,提出一种本体-实体双向约束的知识图谱构建方法.自顶向下依据专家知识初步构建本体,自底向上挖掘实体以优化本体,通过本体-实体双向约束实现航天器多源故障信息的融合.针对来源不同、结构化程度不同的故障数据,本文提出3种不同的知识提取方法.以控制力矩陀螺为例,采用上述方法构建了航天器故障知识图谱,并用Neo4j图数据库可视化展示构建结果.验证了本文方法的可行性和有效性,为航天器故障知识图谱构建提供了一种新思路.
猜你喜欢
国际太空(2022年7期)2022-08-16
河北理科教学研究(2021年4期)2021-04-19
计算机教育(2020年5期)2020-07-24
国际太空(2019年9期)2019-10-23
电子制作(2019年11期)2019-07-04
国际太空(2018年12期)2019-01-28
国际太空(2018年9期)2018-10-18
电子测试(2018年13期)2018-09-26
现代工业经济和信息化(2016年6期)2016-05-17
计算机工程(2015年8期)2015-07-03
