
基于迁移学习的航天器遥测数据异常检测技术
2023-08-31 06:25上官子卓李嘉玺
空间控制技术与应用 2023年4期
刘 切, 上官子卓, 李嘉玺
重庆大学, 重庆 400044
0 引 言
随着我国航天事业的飞速发展,航天器的结构日趋复杂、工作环境更加恶劣多变,航天器故障风险日益增加,对高精度的遥测数据分析技术需求迫切[1].
航天器遥测数据值来源于航天器上各传感器数据[2],包含了表示航天器状态的重要信息[3],分析航天器遥测值能够实时了解其在轨状态,发现异常状态,为航天器状态干预提供依据,从而确保其安全可靠运行.因此,对航天器遥测数据异常检测是航天器运维关键技术.
近年来,对航天器的遥测数据进行异常检测引起了国内外学者的广泛关注.彭喜元等[4]将遥测数据异常检测技术分为4类,即基于人工监测结合阈值的方法、基于专家系统的方法、基于专家经验的模型构建方法和基于数据驱动的异常检测方法.其中基于数据驱动的异常检测应用最广泛,MARTIN[5]在2007年提出一种高斯混合模型对航天器主发动机进行异常检测,SCHWABACHER等[6]应用最近邻算法,开发了Orca系统,并在两个火箭发动机数据集上进行实验,验证其在大数据量系统的适用性,文献[7]针对航天器单变量时间序列,提出综合预测算法并证明其有效性;崔广立[8]将自回归模型与反向传播神经网络结合,并引入遗传算法进行优化,证明了该方法的实用性和有效性.
计算能力与神经网络技术的进步使得众多深度学习模型也被应用于时间序列异常检测任务中[9].其中,长短期记忆网络(long-short term memory, LSTM)作为循环神经网络的一种特殊结构,在对时间序列进行预测时可以有效处理历史信息,在保持长期依赖性记忆上有很大优势,因此被广泛应用于时间序列预测.文献[10]通过变体LSTM循环神经网络动态调整模型参数,使模型更适用于长时间序列异常检测.HUNDMAN等[11]应用LSTM算法提出一种单通道遥测数据实时异常检测模型对当前数据进行实时异常检测.
由于航天领域数据集样本小,人工标注数据任务量大[12],成本高且异常标记数据缺乏,在进行异常检测时很难获得精度较高的模型.鉴于以上问题,本文针对NASA公开的火星科学实验室漫游车好奇号探测数据(soil moisture active and passive, MSL)和土壤水分观测数据集(soil moisture active and passive, SMAP)提出了一种基于迁移学习的时间序列异常检测方法.由于航天器遥测时间序列数据具有强相关性的特点,本文利用LSTM进行时间序列预测.但是传统LSTM缺少对未来数据的利用,导致其模型精度欠佳,因此本文通过双向长短期记忆网络对输入时间序列进行正向和反向计算,提高模型预测精度,同时注意力机制更擅长捕捉时间序列动态变化,所以在LSTM模型中引入了注意力基础,从而能更好提取数据特征.最后针对时间序列数据量大,有标签数据少的问题,引入迁移学习策略对预训练模型进行参数微调,实现了LSTM模型的迁移.提出的模型与最新的异常检测算法进行比较,结果表明本文基于迁移学习的注意力机制LSTM模型提高了异常检测效果,泛化能力较强.
1 遥测数据异常检测原理
本文基于迁移学习的异常检测模型建立在数据预测基础上,为了更清晰地理解模型的工作原理,本节首先对深度学习进行异常检测的原理做简单介绍.
1.1 LSTM模型
长短期记忆网络是循环神经网络模型(recurrent neural network, RNN)的一种变体,能够解决标准RNN存在的反向梯度消失和梯度爆炸的问题并保留其优势[13],由HOCHREITER等[14]于1997年提出,用来解决神经网络长期依赖的问题.LSTM相比于标准RNN结构更加复杂,其核心是增加了细胞状态(cell state)来保存历史信息,更好处理长时间序列.
标准RNN的前向计算方式如式(1)~(2)所示
ht=σh(Whxt+Ghht-1+bh)
(1)
yt=σy(Wyht+by)
(2)
式中,xt为时间序列输入向量,ht为隐藏层状态,σh为隐藏层激活函数,Wh为输入向量权重矩阵,Gh表示循环单元权重矩阵,bh为隐藏层偏置向量,by为输出层偏置向量,σy为输出层激活函数,yt为神经网络输出状态.
定义时间序列模型的损失函数如式(3)~(4)所示
(3)
(4)
得到循环单元权重矩阵导数为
(5)
(6)
Sigmoid函数定义域为(-∞,+∞),值域为(0,1),当输入数据为负无穷大时,其输出为0,输入为正无穷时,输出为1,Sigmoid函数可以用来表示概率.tanh定义域为(-∞,+∞),值域为(-1,1),tanh函数可以将任意大小的输入产生的输出值限定在固定范围中.

图1 LSTM基本结构Fig.1 Basic structure of LSTM
LSTM包括3个门结构:遗忘门、输入门和输出门.遗忘门决定从细胞状态中丢弃哪些信息,输入门决定向细胞状态中加入哪些新信息,输出门用来产生输出结果.
遗忘门机理可以描述为
ft=σ(wf[ht-1,xt]+bf)
(7)
输入门中Sigmoid层、tanh层输出、细胞状态ct更新分别如式(8)~(10)所示
it=σ(Wi[ht-1,xt]+bi)
(8)
(9)
(10)
输出门权重ot和隐藏层状态为ht如式(11)~(12)所示
ot=σ(Wo[ht-1,xt]+bo)
(11)
ht=ottanh(ct)
(12)
式中,W和b为相应门权重和偏置项.
1.2 双向LSTM和注意力机制LSTM原理
双向LSTM(Bi-directional long short-term memory,BiLSTM)在传统LSTM中加入了后向LSTM,共同连接输出层,BiLSTM利用经典LSTM网络对输入时间序列进行正向和反向计算,得到两层不同隐藏层特征,并通过线性融合计算出最终隐藏层的特征结果.两个相反方向的LSTM克服了传统模型对数据集未来信息利用不足的问题,能更好地捕捉双向依赖,提高模型的预测精度,BiLSTM结构如图2所示.
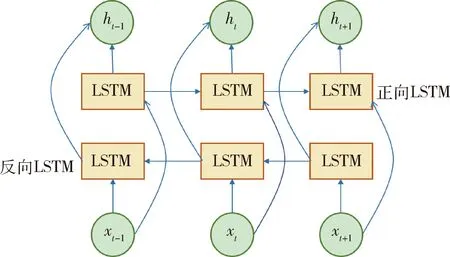
图2 BiLSTM基本结构Fig.2 Basic structure of LSTM
注意力机制的基本原理与人类视觉处理机制类似,当人获取到信息时会优先关注重要信息并投入更多注意力,从而更好地提取关键信息[15].类似地,注意力机制根据给定目标的重要程度分配不同注意力权重,并通过加权求和的到上下文向量.注意力机制将输入数据看作(key,value)键值对形式,首先计算给定任务查询值(query)与关键项(key)的相似系数
f(Q,Ki)=QTKi
(13)
将相似系数归一化得到权重系数
wi=softmax(f(Q,Ki))
(14)
权重系数与Value加权求和得到上下文向量
(15)
式中,Q、K和V分别为查询值Query、键值中Key和Value.
注意力机制的详细计算公式[16]如式(16)~(18)所示
et=utanh(wht+b)
(16)
(17)
(18)
式中,w为注意力权重系数,ht为t时刻输入特征的隐藏层状态,b为偏置,et为隐藏层状态ht所对应的注意力概率分布,st为最终输出特征值.
1.3 异常检测原理
本文中异常检测过程为两部分内容,分别为首先对时间序列进行预测,最后计算预测值与实际值的差并对其进行平滑处理,设定异常点阈值并将平滑误差与阈值的大小进行比较,若某时刻平滑误差大于阈值且出现在标签异常点的范围内,则表示该异常点被正确检测出来,将检测出的点与真实异常值对比,以此计算出精确率、召回率和f1分数验证模型性能,异常检测原理如图3所示.
图中b表示时刻t异常检测批大小(batch size),n表示异常检测序列长度.
2 基于迁移学习的异常检测技术
传统LSTM由于其记忆功能而被广泛应用于时间序列预测任务中,但是在航天领域,航天器异常往往较为罕见,且对数据集进行人工标注专业性强、任务量大,因此航天器遥测数据常面临标签样本缺乏的问题,同时因为遥测值维度高,数据量大,因此异常检测模型的训练对设备的计算力提出了较高要求,极大地制约了航天器异常检测技术的发展,针对上述问题,本文在传统机器学习模型的基础上引入迁移学习算法,提高模型有效性.
2.1 迁移学习
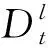
迁移学习的一些定理如下:
定理1.域D由x和P(x)两部分组成,其中x表示特征空间,P(x)表示边缘分布概率,其中x=x1,x2,…,xn.
定理2.任务T由Y和F(x)两部分组成,Y表示标签空间Y=y1,y2,y3,…,ym,F(x)表示能够对样本x进行标签预测的预测函数,F(x)越接近真实的P(y|x)映射效果越好.
定理3.定义源域Ds和任务Ts,目标域Dt和任务Tt,迁移学习通过利用Ds和Ts提高Dt中预测函数F(x)的预测能力,且Ds≠Dt,Ts≠Tt,Xs≠Xt,Ps(X)≠Pt(X).
2.2 迁移学习全连接层
全连接网络(fully connected layer)每一结点都与上一层所有节点相连,是最基本的神经网络,基本结构如图4所示.
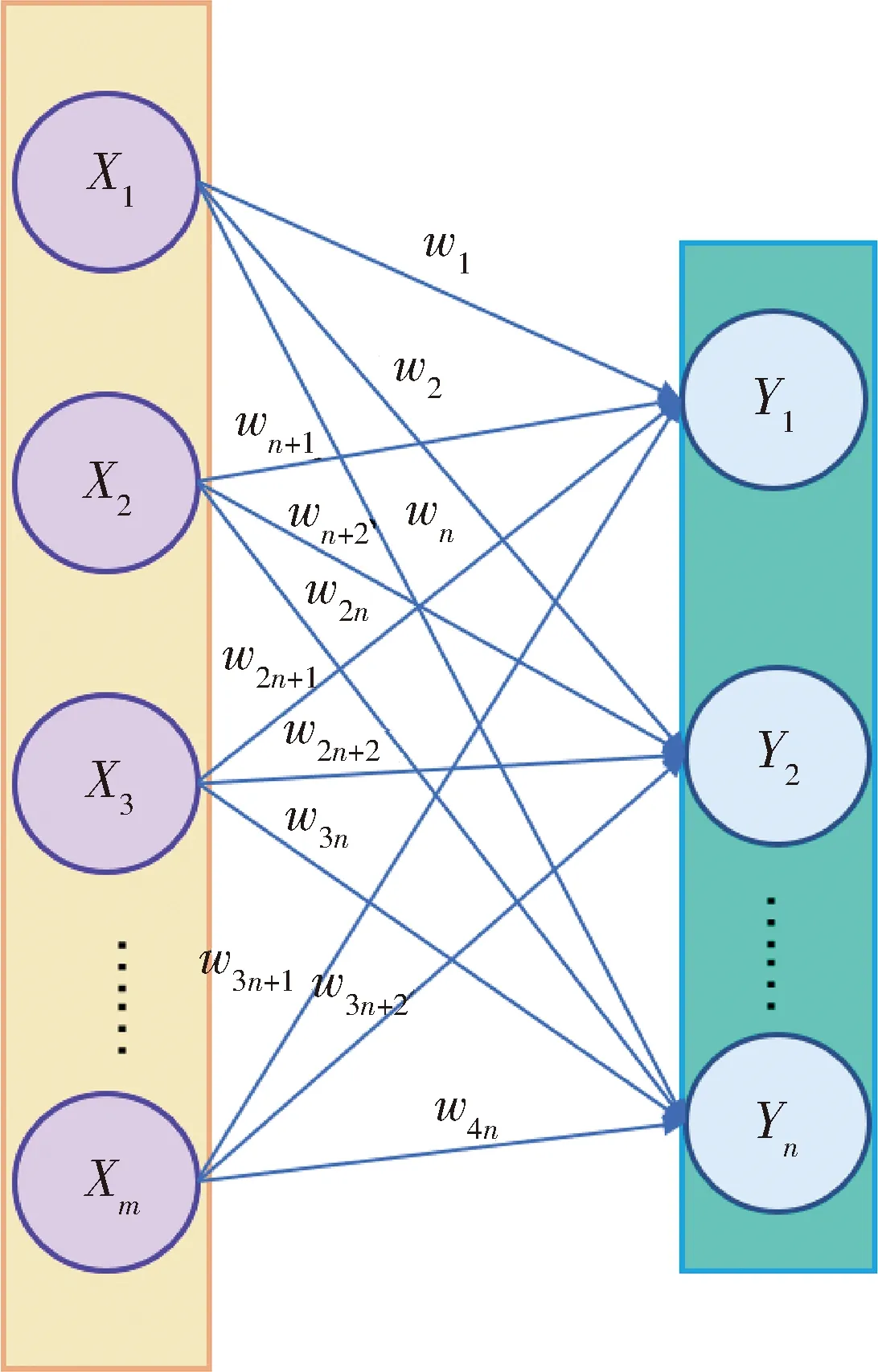
图4 全连接网络结构Fig.4 Fully connected network structure
网络输出为
Y1=w1x1+wn+1x2+w2n+1x3+…+w3n+1xm+b1
(19)
Y2=w2x1+wn+2x2+w2n+2x3+…+w3n+2xm+b2
(20)
Yn=wnx1+w2nx2+w3nx3+…+w4nxm+bn
(21)
式中,w为神经网络各层权重,b为全连接网络偏置项.
全连接网络输入为m维数据,输出n维数据,通过全连接层改变输入特征向量的数据特征表现,而数据内层结构不发生变化.在预测模型中全连接层对输出数据进行降维,在迁移学习模型中全连接层将源域和目标域数据统一在同一维度提高迁移学习效果.
2.3 基于迁移学习的异常检测模型搭建
采用预测值与实际值之间差的绝对值来进行神经网络各连接层权重的更新,称为平均绝对误差损失(MAE),也称为L1loss.其数学表达式如下:
(22)
异常检测的原理是计算某一时刻的预测值与实际值差的绝对值,得到一组误差序列为
(23)
通过比较误差与阈值的大小判断数据点是否为异常点,若误差大于阈值则该点通常会被判定为异常点.但是误差变化稳定性较差,当误差值较大时无法确定产生误差的原因(可能为异常点或是模型精度较低导致预测不准确),所以在计算出误差后需要对其进行平滑处理,减小模型本身对误差的影响.
本文使用指数加权移动平均法(exponentially weighted moved averages,EWMA)处理误差,得到平滑误差.若平滑误差异常高或异常低,则判断该点是否为异常点能有效避免模型本身对异常检测的干扰[17].计算出的平滑误差如式(24)~(25)所示.
(24)
(25)
本文中异常检测模型选择LSTM、BiLSTM以及注意力机制LSTM,在源域训练好异常检测模型后通过微调的方法对预训练模型的特征提取层采用较小学习率,输出全连接层FC采用较大学习率进行迁移学习异常检测,在预训练模型的基础上,根据目标域数据集的特征,保留特征提取层模型参数,对全连接层各层权重进行更新,得到迁移学习模型.模型共分为4部分,结构如图5所示.图中第1部分为源域数据预处理,第2部分为模型搭建,第3部分为模型训练,第4部分为迁移学习.
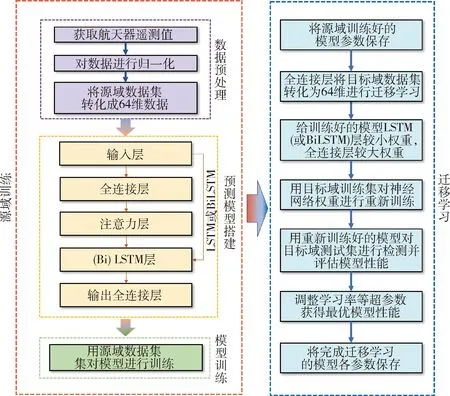
图5 异常检测结构流程Fig.5 Anomaly detection structure process
图5中采用微调的迁移学习方法进行遥测数据异常检测,通过全连接层对源域和目标域数据集进行特征变换,将数据集统一为64维,提高其相似度,最后对输出数据维度进行压缩,得到遥测数据预测值.
3 实验设置
本文的实验数据集采用NASA公开的数据集SMAP和MSL,通过与传统的LSTM、BiLSTM以及注意力机制LSTM进行对比,检验引入迁移学习的异常检测效果,并对3种迁移学习模型进行比较,选择最优模型与其他最新异常检测算法进行性能对比,验证最优模型有效性.
3.1 数据集介绍
本文使用NASA公开的数据集MSL和SMAP验证模型有效性,数据集部分信息如表1所示.

表1 数据集相关信息Tab.1 Dataset related information
为了消除不同数据之间量纲差异的影响,用min—max方法对数据集归一化处理,将数据限定在0~1范围内.
(26)
式中,x0为归一化数据,x为数据集中具体遥测值,min(x)、max(x)分别为数据集中最小值和最大值.
3.2 异常检测评价指标
本文采用异常检测时最常用的评价指标评估了不同模型性能,包含精确率、召回率和f1分数.
混沌矩阵用来表示预测值和实际值的对应关系,如表2所示.
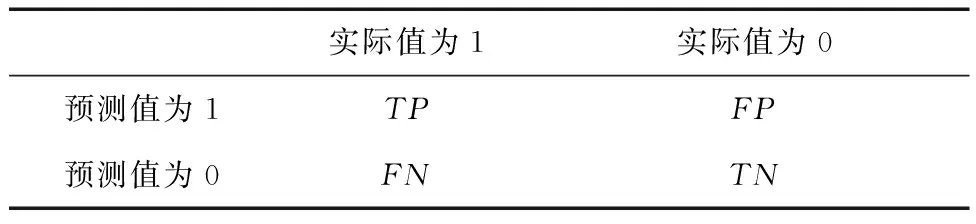
表2 混沌矩阵Tab.2 Chaos matrix
其中TP、FP、FN和TN表示真阳性、假阳性、假阴性和真阴性的数量,根据混沌矩阵的原理,对异常检测指标进行计算,如式(27)~(29)所示.
(27)
(28)
(29)
3.3 模型结构
(1)设备环境
本文中时间序列异常检测模型基于pytorch基本结构搭建,设备相关参数信息如表3所示.

表3 实验设备参数Tab.3 Experimental equipment parameters
3.4 基于迁移学习LSTM异常检测结果
以数据集MSL为源域,SMAP为目标域,在经典LSTM模型上进行异常检测,交换源域与目标域,在不同数据集上检测模型通用性,预测模型网络参数如表4所示,不同数据集前5 000个时间戳异常检测结果如图6.
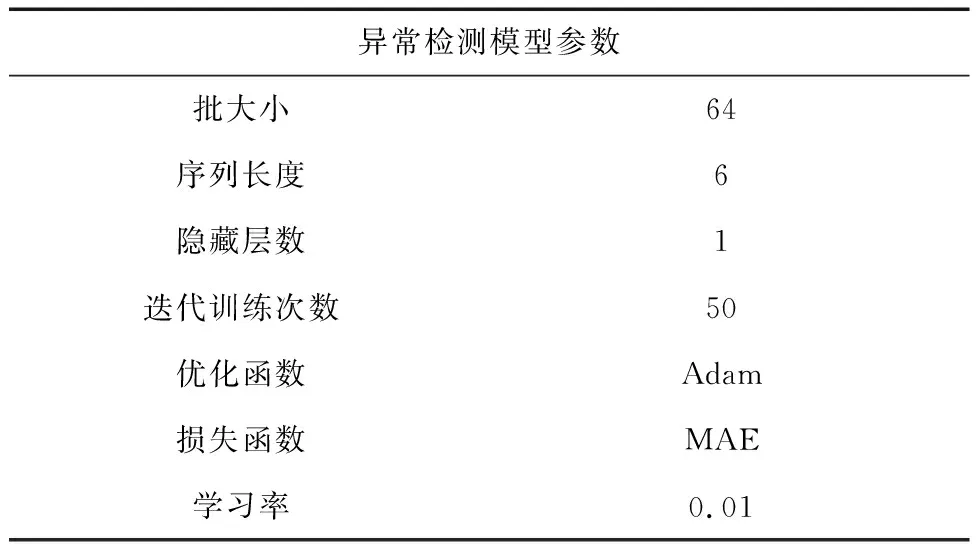
表4 异常检测网络参数Tab.4 Anomaly detection network parameters
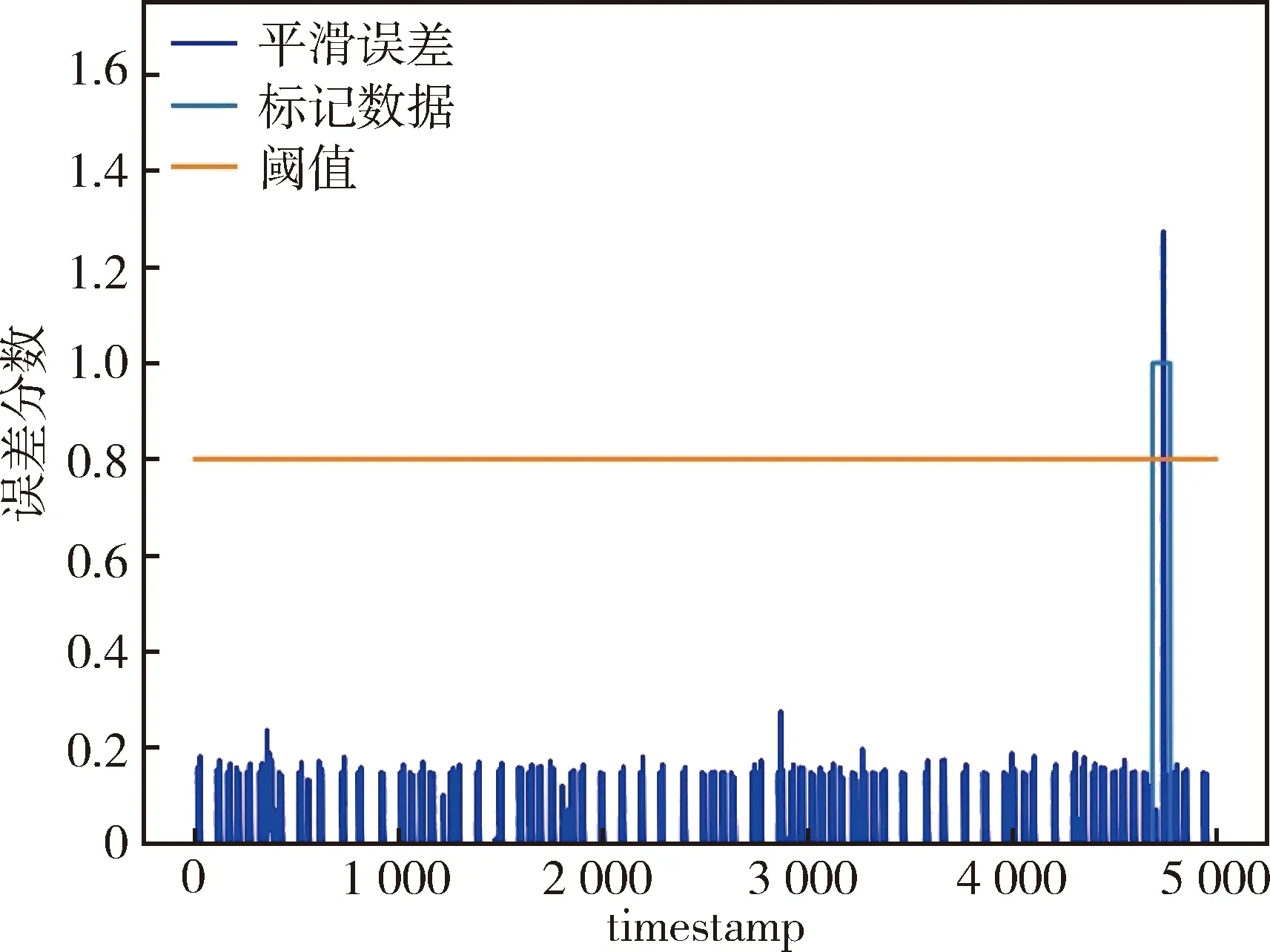
图6 目标域SMAP误差损失Fig.6 Target domain SMAP error loss
图6和图7分别为目标域SMAP和MSL误差损失,选取阈值为0.8,当误差损失大于阈值且出现在异常点范围内,模型异常检测成功,将其与实际异常值对比,计算精确率、召回率和f1分数评价模型性能.
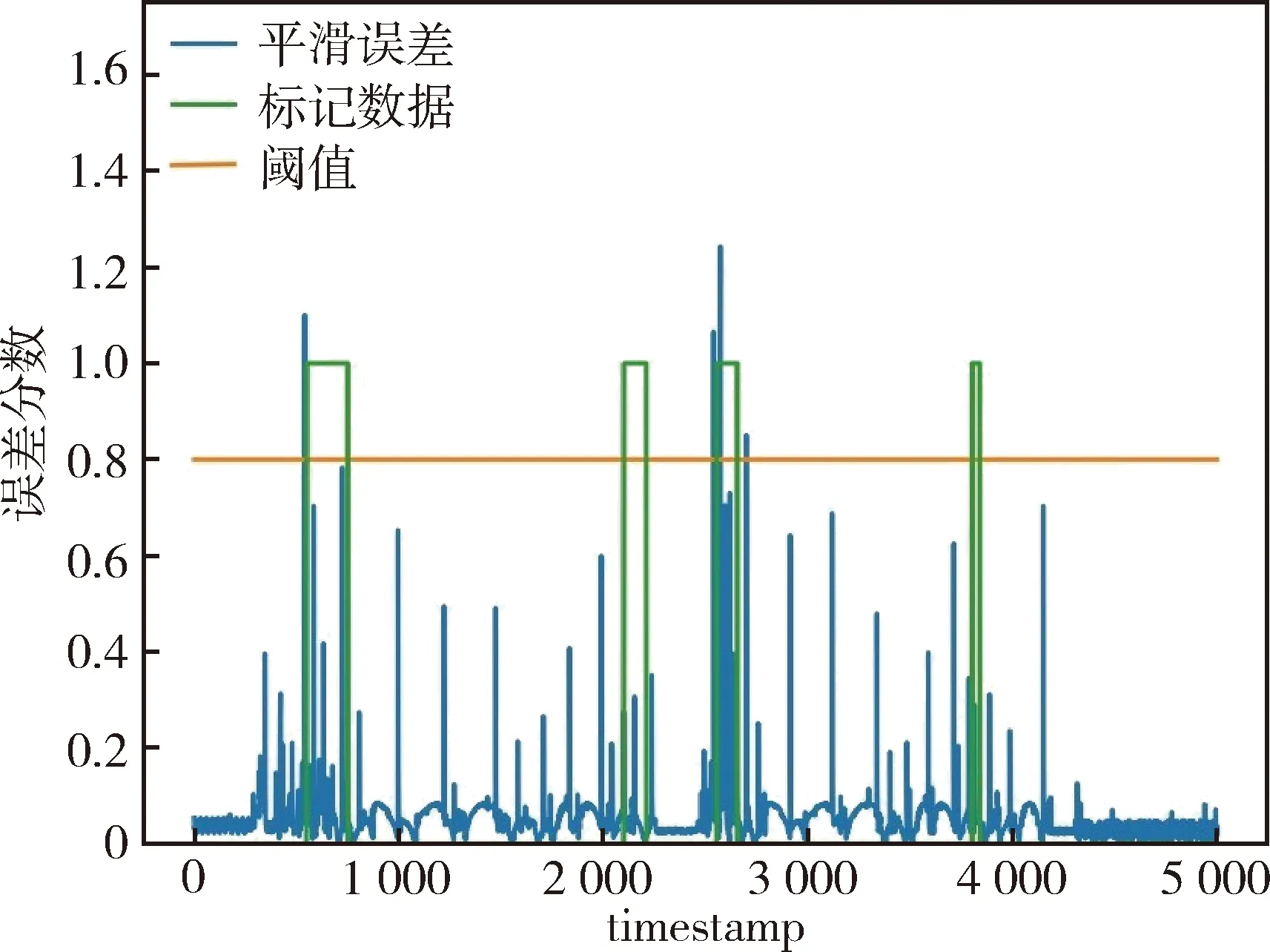
图7 目标域MSL误差损失Fig.7 Target domain MSL error loss
3种算法LSTM、BiLSTM以及注意力机制LSTM及其迁移学习模型在数据集MSL和SMAP上进行异常检测,得到相关性能指标对比结果如表所5示.
在表5中,在数据集MSL中将迁移学习算法引入3种异常检测模型,模型精确率都略微降低,召回率和f1分数都有提升,其中LSTM召回率从78.44%提升到87.39%,提升8.95%,BiLSTM召回率从89.98%提升到95.29%,提升了5.31%.

表5 数据集MSL异常检测评价Tab.5 MSL anomaly detection evaluation
从表6可以看出,与MSL数据集相比,迁移学习算法在SMAP数据集上效果较好,异常检测指标都有大幅度提升,在注意力机制 LSTM模型上,精确率,召回率和f1分数分别提高14.58%、28.04%和15.99%,LSTM在检测精确率上有较大优势,但召回率和f1分数较低.
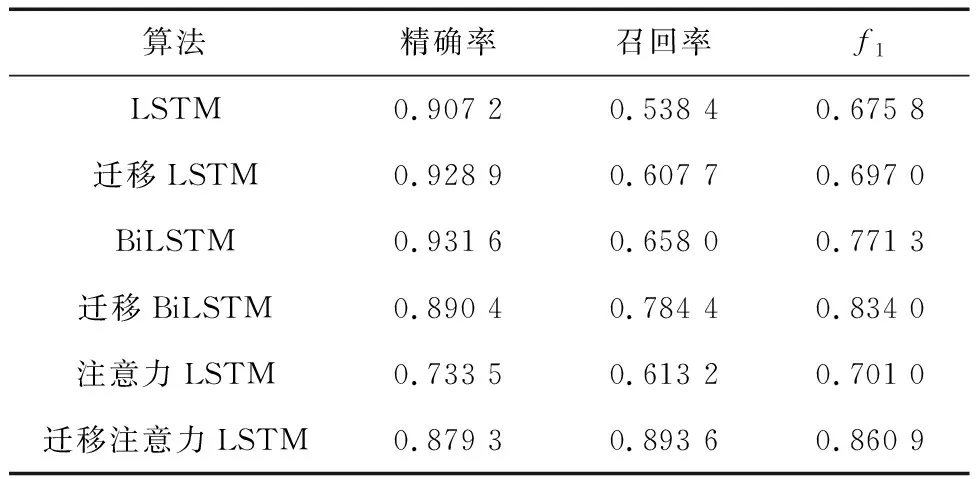
表6 数据集SMAP异常检测评价Tab.6 SMAP anomaly detection evaluation
同时在两个数据集上将各模型检测效果进行对比,可以发现在MSL上进行异常检测效果较好,各指标数值都在75%以上,在数据集SMAP上,经典异常检测算法召回率和f1分数均较低,多数在70%以下.
在数据集SMAP和MSL中,将本文中3种基于迁移学习的异常检测模型性能对比,结果如图8~9所示.
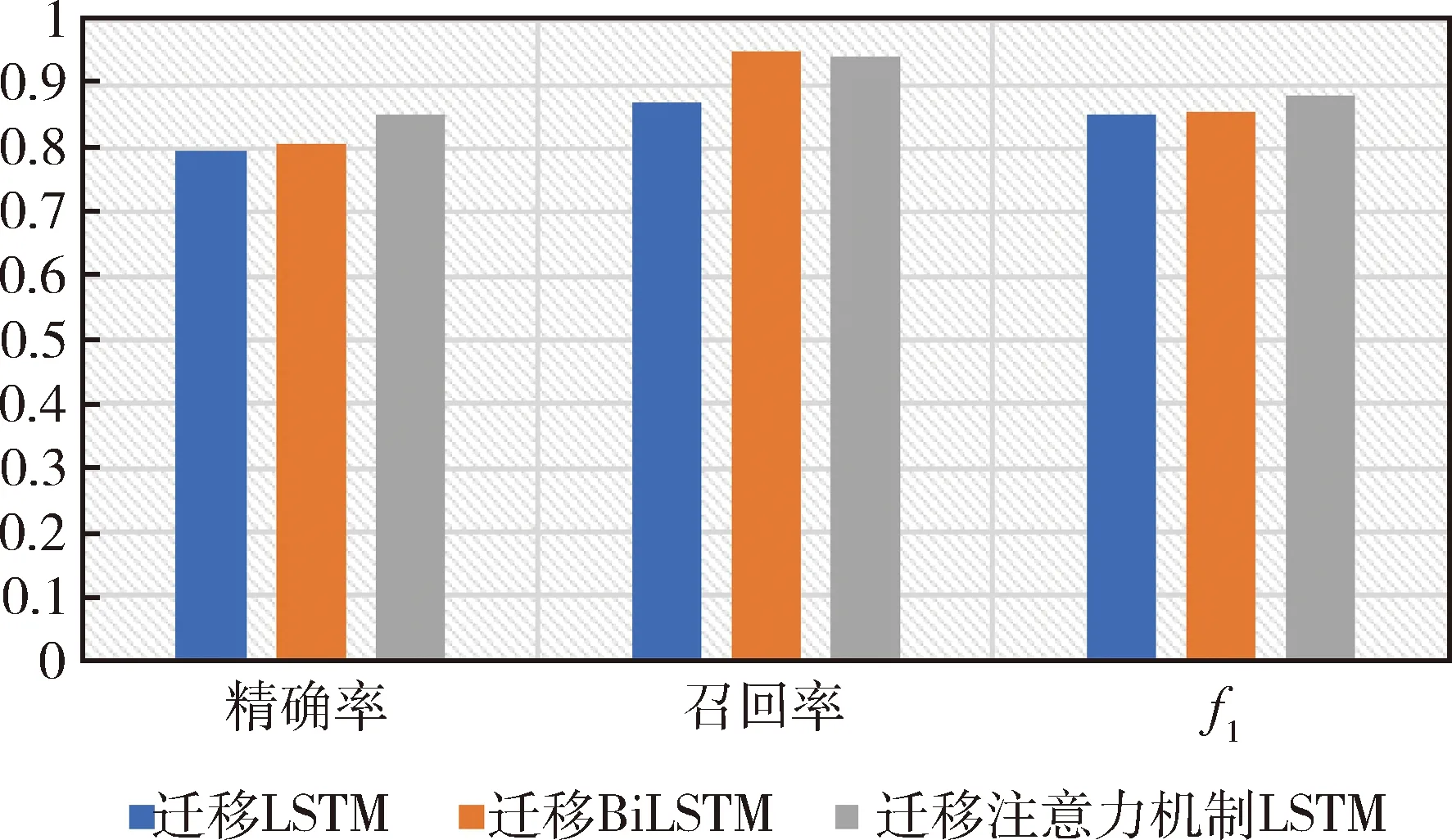
图8 3种方法在MSL上的评价指标Fig.8 Evaluation indicators of three methods on MSL

图9 3种方法在SMAP上的评价指标Fig.9 Evaluation indicators of three methods on SMAP
由图8~9可以看到,在数据集MSL和SMAP中注意力LSTM异常检测性能最好,各指标都达到85%以上,因此基于迁移学习的注意力机制LSTM是本文中的最优模型.
将本文中提出的基于迁移学习的注意力LSTM模型与一些用于异常检测的先进模型做详细比较.对比模型包括3种基于重构的模型和一种基于预测的模型.
LI等[18]在2018年提出基于生成对抗网络的多元时间序列异常检测方法GAN-AD,成功捕捉了网络物理系统传感器和执行器的时间序列分布,并在2019年提出MAD-GAN[19]采用LSTM-RNN作为生成器和鉴别器充分利用了时间序列分布潜在的相关性.
MIRSKY等[20]提出一个基于集成的自编码系统(kitsune)成功完成了在线网络入侵检测,其核心算法是KitNet,能够有效检测多种攻击,拥有较强的实用性和较高的经济价值.
HUNDMAN等[11]提出了一种单变量时间序列异常检测无监督学习算法(LSTM-NDT),具有针对NASA数据集无监督非参数的异常阈值方法.
本文提出的模型在基于注意力机制的LSTM异常检测模型的基础上引入迁移学习,为了解决航天器时间序列遥测数据有标签的异常样本缺乏的问题.
表7[1]展示了在2个数据集上5种模型的异常检测效果,由表中数据可以看出基于迁移学习的注意力机制 LSTM异常检测模型在数据集MSL上各项性能指标都优于其他算法,精确率、召回率和f1分数分别高于MAD-GAN算法0.32%、4.48%和1.08%,在数据集SMAP上精确率和f1分数分别低于LSTM-NDT算法1.72%和2.96%,但LSTM-NDT算法在数据集MSL上表现不佳,各项指标都低于60%,模型通用性较低.鉴于上述分析,在进行航天器遥测数据异常检测时,以注意力机制 LSTM为基本异常检测模型,引入迁移学习策略能够弥补数据集缺乏有标签样本的不足,有效提升模型异常检测性能.
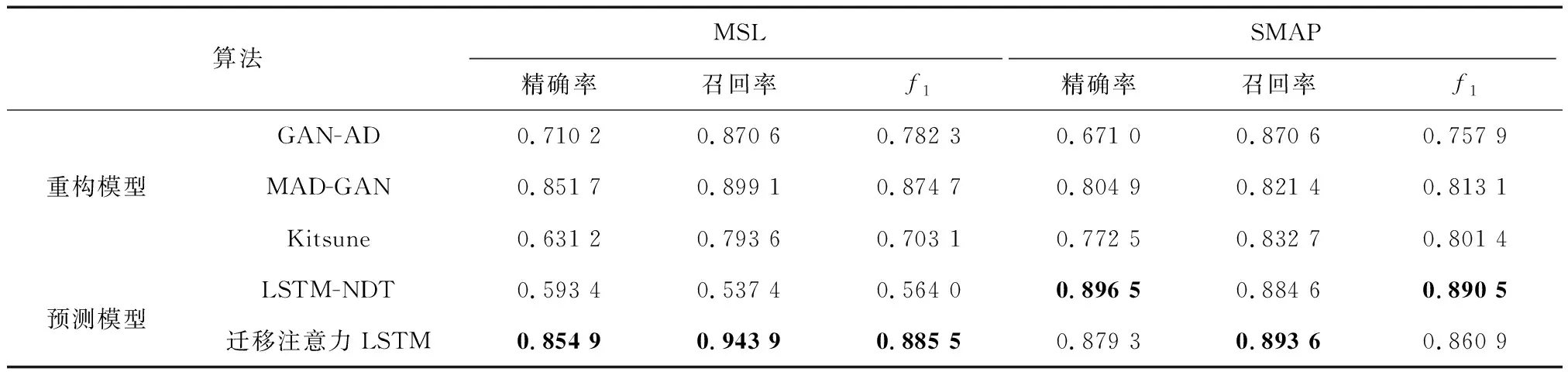
表7 5种模型异常检测效果对比Tab.7 Comparison of anomaly detection effects among five models
本文将经典异常检测算法LSTM、BiLSTM和注意力机制LSTM与基于迁移学习的优化模型比较,发现在标签数据缺乏时,迁移学习能有效提高异常检测模型性能.同时将3种迁移学习优化模型对比,结果表明注意力机制在数据集MSL和SMAP上效果最好,是本文的最优模型.最后与4个常用的异常检测算法比较,发现以注意力机制LSTM为基础引入迁移学习算法在数据集MSL上异常检测效果优于其他4种算法,在数据集SMAP上召回率最高,精确率和f1分数略低于LSTM-NDT模型,高于其他3种模型,但LSTM-NDT在数据集MSL上表现最差.因此从总体来看,本文所提算法在2个数据集之间通用性较强,更加适合时间序列异常检测任务.
4 结 论
针对航天器遥测数据中有标签的异常样本缺乏、数据量大、维度高和当前设备算力弱导致的训练效率低等问题,提出了一种基于迁移学习的时间序列异常检测策略.通过对不同模型迁移学习性能进行比较,发现将注意力机制引入LSTM并进行迁移学习在数据集SMAP和MSL都能产生较好的异常检测效果.LSTM能较好学习到时间序列不同时刻的相关性,注意力机制能够提取到数据动态变化的特征,采用迁移学习的方法,在源域中对模型进行预训练,赋予训练好的模型特征提取层较小的学习率,FC全连接层较大的学习率并在目标域重新训练,提高了模型训练的效率,证明了提出模型的有效性.实验发现文中经典异常检测模型在数据集SMAP上召回率和f1分数较低,可能的原因是遥测值在很长一段时间都保持为数值1,在时间戳为8 500时产生突变减小,随后在±1之间震荡,预测难度较大,导致模型表现不稳定.
本文提出的方法仍有不足之处尚未解决,首先,文中对异常数据的检测是一个二分类问题,局限于数据点是否为异常点而没有对异常点类型做出判断,后续研究将对异常点类型进行划分以更高效地修复航天器故障.其次文中通过经验法对模型超参数进行选择,后续可以引入参数优化智能算法选择最优参数.最后针对本文模型在数据集SMAP上表现不稳定的问题,后续研究可以着眼于采用插补去噪等方法对数据集进行预处理,提高模型异常检测精度.
猜你喜欢
国际太空(2022年7期)2022-08-16
小雪花·成长指南(2022年1期)2022-04-09
国际太空(2019年9期)2019-10-23
电子制作(2019年11期)2019-07-04
国际太空(2018年12期)2019-01-28
国际太空(2018年9期)2018-10-18
电子测试(2018年13期)2018-09-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代工业经济和信息化(2016年6期)2016-05-17
