
基于多智能体强化学习的微装配任务规划方法
2023-08-30 03:17徐兴辉唐大林顾书豪左家祺王晓东任同群
计算机测量与控制 2023年8期
徐兴辉,唐大林,顾书豪,左家祺,王晓东,3,任同群,3
(1.大连理工大学 微纳米技术及系统辽宁省重点实验室,辽宁 大连 116024;2.北京航天测控技术有限公司,北京 100041;3.大连理工大学 高性能精密制造全国重点实验室,辽宁 大连 116024)
0 引言
国防高端武器中常用的传感器、惯性器件等,具有尺度小、精度高的特点,装配是其制造过程中的重要环节。装配任务就是基于视觉、力觉等传感器对作业环境的感知,控制引导多操作臂协作完成序列零件的拾取、搬运、位姿调整对齐以及释放等操作,即多操作臂的协同操作。由于任务需要综合考虑装配序列信息,操作臂运动区域等条件,导致在操作臂前往目标位置的途中,难以始终保持连续、直线的运动路径,因此通常需要对任务路径进行规划。目前,大多在调试阶段通过多次人工试验找到一个优先保证安全的控制方案。然而这种方式相当耗时,且在试验过程中由于没有明确目标,容易操作失误,造成操作臂之间的运动干涉,甚至产生硬件损坏[1-2]。除此,人工方式不能全局规划,所得运动控制方案并非最优,势必牺牲一定的装配效率。此时,微装配任务自主规划就成为了传统微装配演变成数字化智能微装配的关键手段之一[3]。
针对规划问题,典型的方法是人工势场法[4]及其衍生的算法[5-7]。其优点是收敛速度快,路径平滑,运行稳定[8]。还有学者将各类智能搜索算法如遗传算法、模拟退火以及模糊控制算法等融入人工势场法[9-11],以此来增加算法的搜索能力,改善局部最优问题。微装配的任务由操作臂连续动作决策所构成,因此可将其归为序贯决策问题。强化学习(RL,reinforcement learning)的出现主要用于序贯决策问题,能够增加了操作臂的适应能力,且只需要操作臂在探索过程中不断地从错误中学习,即可得到稳定的路径[12]。近年来,针对大维度数据带来的迭代复杂问题,有学者将深度学习(DL,deep learning)融入RL中形成深度强化学习(DRL,deep reinforcement learning),如控制机械臂重新排列物体[13],完成协作任务[14],在非结构化区域中抓取目标对象[15]。
在装配领域,李彦江利用多智能体深度确定性策略梯度算法(MADDPG,multi-agent deep deterministic policy gradientalgorithm)算法,实现了双关节臂的协同装配并进行了仿真验证[16]。李妍等将模糊贝叶斯与深度Q网络结合,提高了狭窄空间中的运行效率[17]。微装配系统特有的支撑框架、直角坐标、空间密集使其对精度、空间等要求较高。而障碍物与目标点集中等特征加剧了迭代复杂、局部最优问题,因而传统的人工势场法等并不适用此类规划问题。一次任务中有不同的子任务,而各子任务的操作臂个数、障碍物布置等均不同,此类先验信息、环境信息的变化将导致使用智能搜索算法规划时需要重新构建环境,耗费了大量资源。当前DRL方法多用于移动机器人的路径规划[18-19]、无人机导航与任务分配[20]、以及实际生产线上的人机协作问题[21]等。然而上述工况与微装配任务特点差异较大,存在动作空间不符、奖励函数条件不合理等可能导致微装配实物训练难度大的问题,以及精确度低的仿真环境可能导致训练失败。
综上所述,提出了多智能体强化学习(MARL,multi-agent reinforcement learning)下更契合微装配任务的动作、状态、奖励条件的构建方法。同时,基于MADDPG算法,利用Coppelisiam软件对已有测量设备进行物理建模,构建了任务的深度强化学习模型并进行训练得到可工程化的路径,实现了微装配设备的自主规划。
1 多智能体强化学习算法
1.1 深度强化学习机制
深度强化学习方法将深度学习较强的感知能力与强化学习具有的决策能力相结合。主要思想是利用深度神经网络实现对原始低层特征输入的非线性变换,增强智能体的环境感知能力,并结合强化学习的探索能力,形成一种将原始环境状态输入直接映射为动作决策输出的端对端的学习方法[22]。与强化学习一样,深度强化学习框架中也由智能体(Agent)、动作、状态及奖励等要素组成。
策略(Policy),状态集(State)与动作空间(Action):策略π是智能体与环境交互时的行为选择依据,π(s,a)智能体在状态s下根据π选择动作a。状态空间S表示智能体状态信息的集合,是智能体训练过程中制定决策和获取长期收益的交互依据;动作空间A包含了智能体在某状态下所能做出所有可选动作的集合。S→A表示状态空间到动作空间的映射。
奖励函数(Reward):奖励函数r反映当前环境状态St∈S下所选择的动作At∈A对达成目标的贡献度,其将任务目标具体化和数值化,是实现操作臂与环境之间交互的载体,影响着智能体策略的选择。奖励值是否合理,决定着智能体通过训练之后选择的动作能否有利于达成目标。
价值函数(Value Function):价值函数Q(s,a)表示某个状态下在选择某动作时的价值,其由带有折扣因子的未来奖励组成,因此表示选择动作的潜在价值。从定义上看,价值函数就是回报的期望:
Rt=rt+λrt+1+λ2rt+2+…
(1)
Q(s,a)=
E[rt+λmaxQ(st+1,at+1)|St=s,At=a]
(2)
其中:λ为奖励的折扣因子。在DRL中,使用神经网络逼近拟合价值函数。
经验回放池(ER,experience replay):深度学习对训练数据的假设是独立同分布的,然而在DRL中,训练数据由高度相关的“智能体环境交互序列”组成,不符合采样数据独立性条件。智能体在探索状态空间的不同部分时是主动学习的,因此训练数据的分布是非平稳的,不符合采样数据独立同分布条件。ER机制使DRL中的智能体能够记住并回放过去的经验数据,通过与最近数据混合,打破观测序列的时间相关性,有助于解决数据非独立同分布造成的问题。
1.2 MADDPG算法
由于微装配任务规划是一个典型的多操作臂问题,在利用多智能体强化学习进行求解时,存在环境不稳定问题,当前状态优化的策略在下一个变化的环境状态中可能又无效了,这就导致不能直接使用ER来进行训练,因此适用于单智能体的DRL方法需要改进。由Lowe等提出的MADDPG算法将多智能体思想融入了基于深度强化学习的演员-评论家算法[23],MADDPG算法采用集中学习,分散执行的方法解决了多智能体竞争、合作或者竞争合作共存的复杂环境中存在的环境不稳定问题。集中学习指的是环境中的所有智能体的信息是全局共享,分散执行指智能体在做出决策时,仅依靠自己观测得到的环境情况进行选择合适的动作,无需其他智能体的状态或动作,因此该算法解决了之前单智能体算法只能获得自己的状态动作的问题。微装配环境中,各操作臂既有多操作臂共同完成一项工作的合作关系,同时也有不同模块间避免干涉的竞争关系。因此在使用多智能体强化学习训练多操作臂时,应具体分析微装配任务特点设计合理的环境交互机制,对动作、状态,特别是奖励函数进行针对性设计。
2 微装配测量设备训练模型构建
分析微装配任务特点:其通常采用直角坐标机器人,运动方式不能脱离支撑框架,难以完成顺滑的非直线运动轨迹,因此一些高精度避障、协调的动作难以通过插补实现。同时,规避干涉时应尽量避免停顿和反向运动,以减小控制难度和装配精度损失;其次,多操作臂拥挤在狭小的操作空间内,既有协作也有竞争(运动干涉),使得规划求解空间有限;最后,操作臂的运动轨迹相对于操作空间多为长序列,且易干涉区域相对集中,使得协同运动时干涉的风险增加。动作、状态以及奖励函数构建以上述特点为依据。
2.1 状态空间与动作空间构建
状态空间的设计包括子任务划分、观测空间的建立。在微装配中,操作臂应尽量避免反向运动,但还是存在如操作臂取放工件,相机观测不同位置零件等难以避免反向运动的情况。因此可将这些装配任务中运动方向的临界位置作为各子任务的划分点,既便于进行精度控制,又便于后续动作空间设计后续路径的训练。观测空间是状态空间的基础,决定了要对哪些操作臂的状态进行观测,并将观测结果输入策略网络以及价值评价网络。在进行观测时,各模块操作臂所处位置可作为观测空间的组成部分,为了便于网络输入,对实时位置应当进行归一化处理:
(3)
其中:pr是当前操作臂位置,pf是子任务中操作臂需要运动的总长度。同时,对于无碰路径,还需要对实体之间的碰撞情况进行观测,最终得到的观测空间为:
S={Collision,Rle}
(4)
动作空间决定了操作臂动作库的动作数量。动作空间的设计应具有完备、高效以及合理的特点。在进行动作空间设计时,应当对无效动作进行屏蔽。无效动作是指操作臂选择的动作违反其所处的实际环境。不同于无人机控制、关节机械臂的应用场景,微装配设备在运行时由于高精度要求,需要尽量避免停顿和反向运动的无效动作,以减少频繁启停和回程误差造成的装配精度损失,尤其在进行干涉规避时,更应避免随意反向运动等无效运动;停顿次数过多也会导致脉冲计数误差增大,增加操作臂的控制难度。因此微装配测量系统的子任务中,操作臂一旦朝向一个方向运动,原则上就不能再向反方向移动,但仍可以接受由于避碰而导致的较少次数的停顿。对于已经到达目标点的操作臂,其动作将始终为0,因此动作空间设计为:
(5)
其中:v为操作臂所选择动作的速度,包括选择速度为0的停顿,dir为操作臂的运行方向。每一个step开始时,都通过将操作臂当前的状态输入策略网络得到选择不同动作组合的概率,并以概率最大的动作组合作为该step的动作。
2.2 奖励函数设计
操作臂的训练过程就是不断试错的过程,奖励函数作为评价操作臂所选择动作的好坏评价标准,直接决定了能否训练出成功的方案。微装配任务中,各操作臂通过环境给予的奖励得知自己在某一状态下采取的动作是否合理,因此奖励函数的本质是建立状态动作对与奖励之间的映射关系,并将这种关系用于对操作臂所采取的动作的评价和约束。奖励函数直接影响了算法的收敛性,与微装配环境契合的奖励函数是实现设备无碰、高效的前提。
各操作臂的首要任务是到达目标位置,因此奖励函数应具有吸引操作臂前往目标点的功能。以操作臂所处位置为自变量,构建主要的奖励函数为:
(6)
其中:Δp是操作臂当前位置与目标点之间的距离。pf是子任务中操作臂需要运动的总长度。该函数下,随着操作臂靠近目标点,Δp不断减少,则正向奖励值不断增大。动作空间中包含速度为0的停止动作,对每个子任务而言,为了保证精度以及保证操作臂的运动可控性,频繁启停将会导致精度损失,显著增加控制难度,在规划时需要避免,因此操作臂的停顿次数应当越少越好。然而在MADDPG算法中,为了让操作臂保证一定的探索性,各动作的选择概率具有一定的随机性,所以对停顿次数过多的行为进行惩罚:
(7)
其中:s0为子任务中操作臂选择动作为0的step个数,s为操作臂在路径中所经历的step个数,α为对应的系数。由于对于路径的要求还有无碰的要求,因此当操作臂产生碰撞时需要给予较大的惩罚,即为:
R3=-a
(8)
其中:a为一常量,表示碰撞结果一经产生,就给予操作臂固定的惩罚。然而,微装配设备中多为狭小空间,多臂协同动作时碰撞极易发生,这导致操作臂即便通过大量冗余试验也不能明白碰撞前的路径是低价值的,此时若仅当产生碰撞时才惩罚,则会由于相关信息不直接而导致操作臂始终选择低价值动作,避碰失败,在这种情况下,操作臂需要通过大量冗余试验才能明白碰撞前的路径也是低价值的。其中,正是因为与控制目的相关的信息并未在奖励函数的设计中得到体现,而导致此类问题的产生。此时就需要使用奖励函数进行外部干预,这意味着奖励函数不仅需要对碰撞行为进行惩罚,还需要能够对碰撞进行预测。具体到微装配中,就是以实体对象之间的距离为依据,构建奖励函数为:
R4=ω(Δd-Dt)
(9)
其中:ω为系数,用于调节该部分奖励函数对整体奖励的影响程度。Dt为碰撞检测阈值,Δd为实体之间的实时距离,当实体距离小于Dt时,则R4为负值,对操作臂开始惩罚,反之进行正向奖励。综上,可得符合微装配测量设备的奖励函数为
(10)
3 微装配设备仿真
3.1 物理仿真环境搭建
采用CoppeliaSim软件对已有的测量设备进行物理建模,基于前述奖励函数的设计方法,在CoppeliaSim中以MADDPG算法进行训练并验证。训练过程中,利用仿真软件自身提供的实体间碰撞以及距离检测功能,实现零部件之间的距离检测和碰撞检测,操作臂实时位置监测等操作,这些信息通过软件的消息机制送给训练算法,再由训练算法处理并将得到的策略通过远程控制实现仿真运动,训练环境与仿真环境关系如图2所示。目标设备为课题组研制的“航天陀螺仪气浮动压马达间隙测量设备”,结构如图3所示。设备中,由9自由度操作臂协同完成马达轴向及径向μm级间隙的测量任务[24]。
CoppeliaSim是一款机器人仿真平台,其具有完备的物理引擎,支持实体重构模型、距离检测、实体碰撞检测等,支持通过Python远程控制关节进行移动。为了节约仿真计算量,通常将复杂的模型部件进行重构,将各零部件有具有精准细节的实体转换为凸包体,因此利用开源的V-HACD库对操作臂组成部分进行凸分解,实现粗略建模,同时由于对夹指、工件、测头等进行较为精细的重构,使凸包体与部件形状接近一致,如图4所示。最终得到的物理模型如图5所示。
虽然操作臂的运动是一个连续的动作,但连续运动时,持续性的碰撞检测将使得训练时间成本过高,如平均两个零部件之间的碰撞检测就需要1.5 s的时间,导致操作臂连续运动时进行训练、处理仿真软件信息流的延迟过大。因此,将操作臂的连续运动简化为离散匀速运动,即在仿真环境中以操作臂在固定时间的位移表示其在实际设备中的速度。则在间隔时间确定的情况下建立操作臂在实际设备中与仿真模型中运动的模型映射关系为:
s=vT
(11)
其中:T为确定的间隔时间,v为操作臂运行的实际速度。Coppeliasim机械臂控制器中的Background Task通过UDP向外部程序每隔50 ms循环发送当前各轴位置,确定T为50 ms的整倍数即可。基于MADDPG算法构建设备操作臂的训练算法。对动作、状态空间以及奖励函数进行重构,各step之间的间隔为T。
3.2 仿真实验
以图6中的工件姿态旋转子任务为例,该子任务包含多臂协同、避障两个动作要求。旋转模块上的夹指沿Y轴运动并夹住工件后,操作臂的具体目标位置为:旋转模块Y轴执行后退动作至限位位置使零件退出上料区域,在Y轴退出的同时,旋转模块R轴旋转90°使马达由水平转至竖直状态。同时,三爪夹持模块的X轴与Z轴也同时向目标位置运动,以准备零件的对接工作。
在Pycharm中搭建好基于Python的训练所需环境,然后使用基于MADDPG算法的训练算法对设备整体进行多个episode的训练。训练算法输出的策略通过封装好的函数对仿真软件中的物理模型进行远程控制。物理仿真环境中实时交互产生的操作臂位置、零部件间的距离、碰撞检测结果等作为观测值返回到训练算法。
首先构建好训练所需的动作,状态空间。然后根据式(6)设计仅以目标点吸引作为正向奖励的奖励函数,通过多次训练,得到两个操作臂位移变化曲线、动作选择曲线以及所经历的各位置处的奖励值如图7所示。
虽然位移的实际运动曲线显示操作臂成功避障并到达了目标位置,但由动作选择曲线可看出,操作臂运行时存在断断续续反复启停的问题,选择了过多无必要的零动作,无法保证连续稳定的运动,这违反了微装配任务规划的准则,如此频繁的启停增加了控制难度,不能契合微装配的操作特点,使得训练结果无法实际工程化。同时,该路径花费时长较大,使用了近100多个step,观察实时奖励值可看到当操作臂选择了朝向目标位置的运动动作时,环境给予一定的奖励值,然而当操作臂选择停止时,并无任何奖惩。因此,根据式(7)增加对停顿次数有约束效果的奖励函数,再次训练,可得到相关曲线如图8所示。
可以看到,动作选择曲线中再未出现操作臂频繁启停的现象,但由于缺少对碰撞的约束,操作臂始终在刚开始就产生碰撞,从图中可看出操作臂在第5个step就产生了碰撞。因此依据式(8)增加碰撞约束的奖励函数得到图9路径曲线,经过训练后可以由运动曲线图和动作选择曲线看到,旋转模块R轴的积极性被打消,不再进行任何的旋转动作,这是由于操作臂运动初期在狭窄的空间中较易产生碰撞,进而很容易就得到很大的惩罚,导致探索难度增大,这种惩罚使得操作臂产生“积极性丧失”的现象。为了降低操作臂初期的探索难度,根据式(10)对奖励函数进行改进,提升对碰撞情况的预测能力,得到各操作臂的相关曲线如图10所示。可以看到,旋转模块R轴在运动初期静止不动,直到Y轴操作臂运动了一定的距离后R轴的旋转运动才开始,最终实现避障,且为了避碰而产生的停顿集中,路径效率较高,在目标点吸引的正向奖励中做出更加有利于路径整体规划的动作选择。
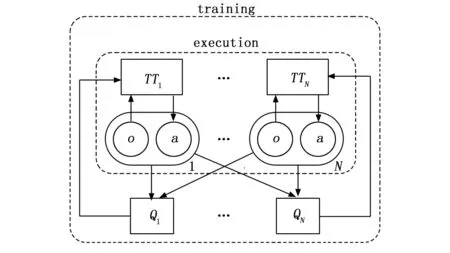
图1 MADDPG算法框架示意图[22]
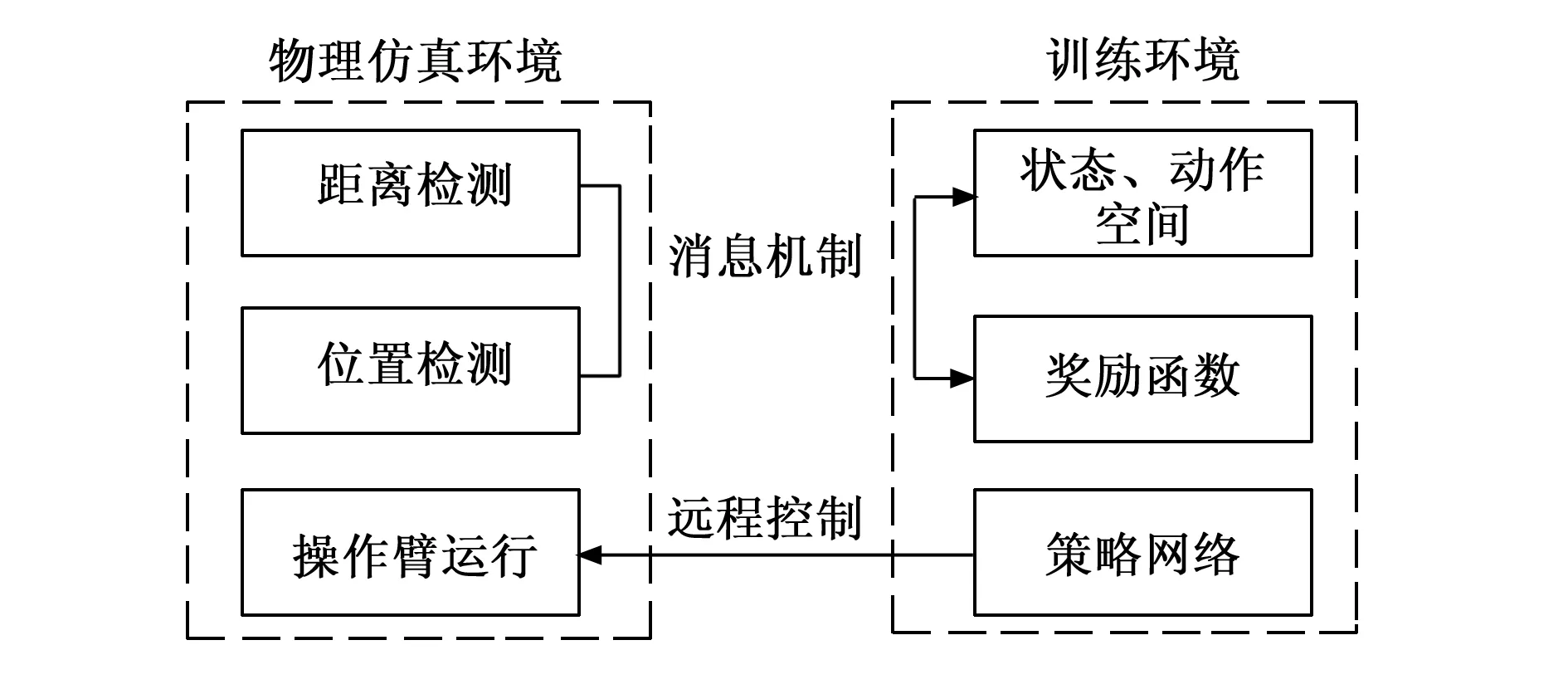
图2 训练环境以及仿真环境关系示意图

图3 气浮轴承间隙测量设备实物图[24]
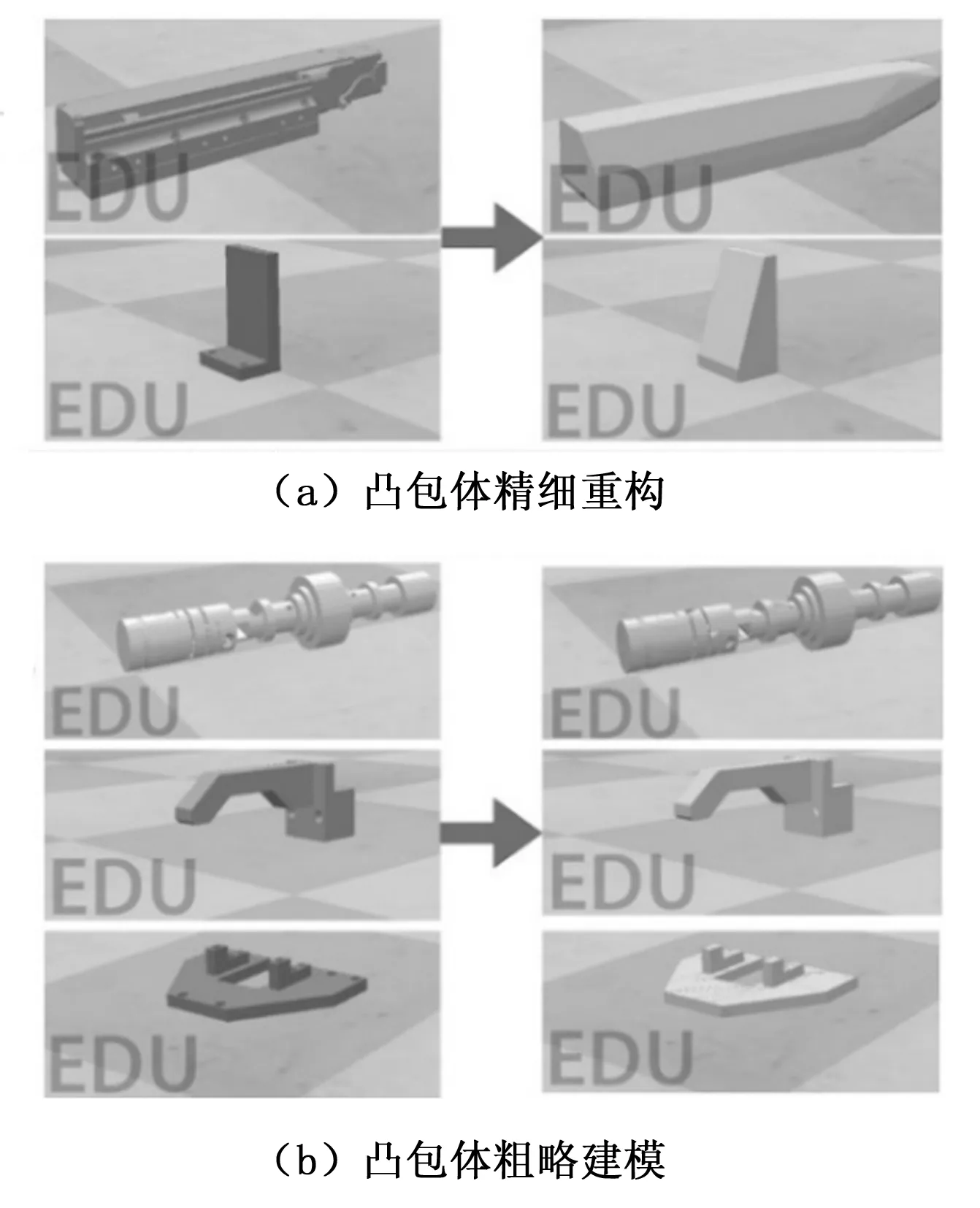
图4 凸分解构建凸包体示意图
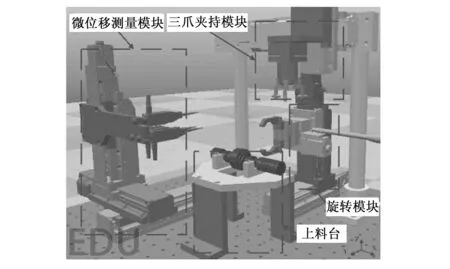
图5 待规划设备在CoppeliaSim中的物理模型

图6 工件姿态旋转子任务实验对象
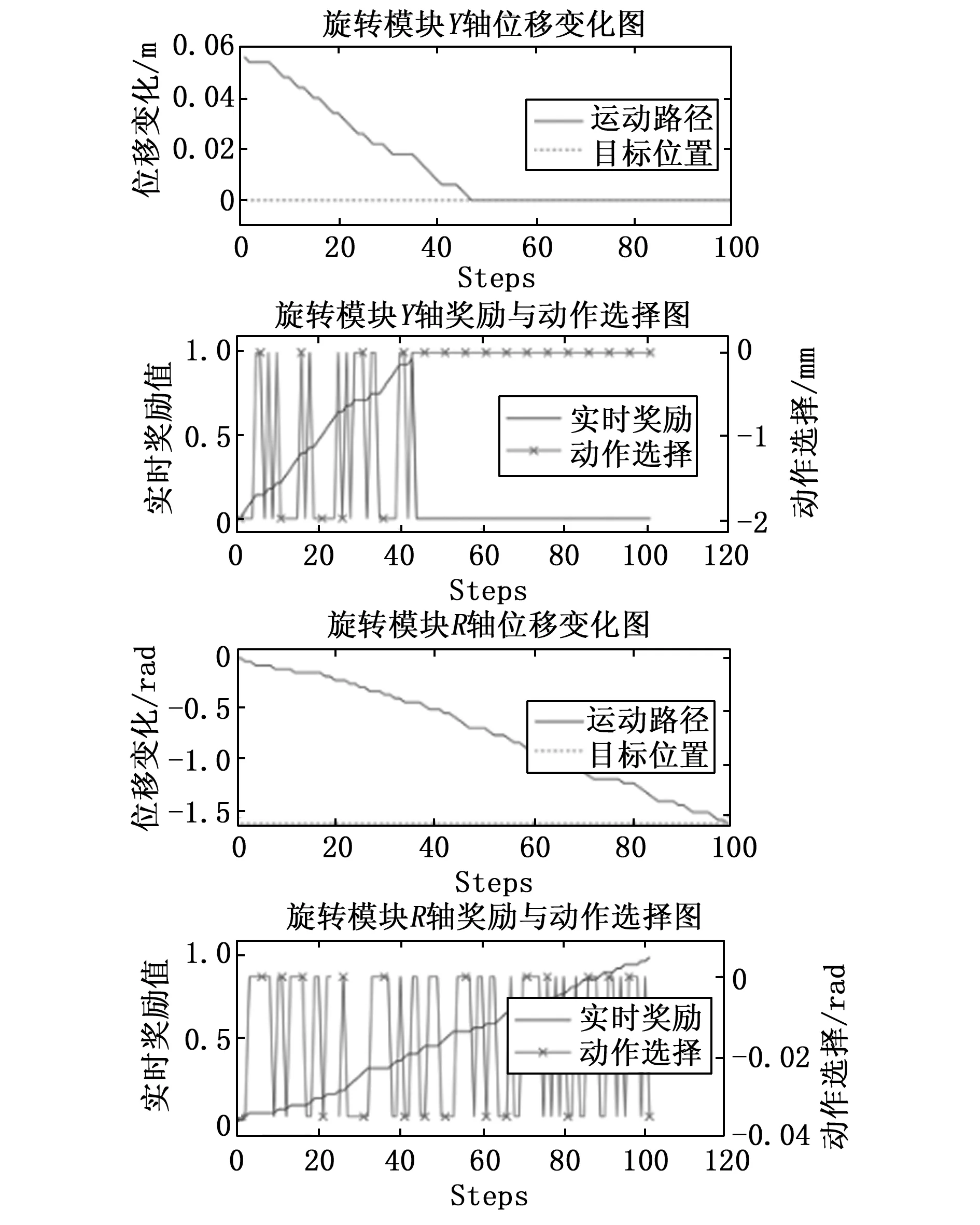
图7 仅以目标点吸引的正向奖励为奖励函数
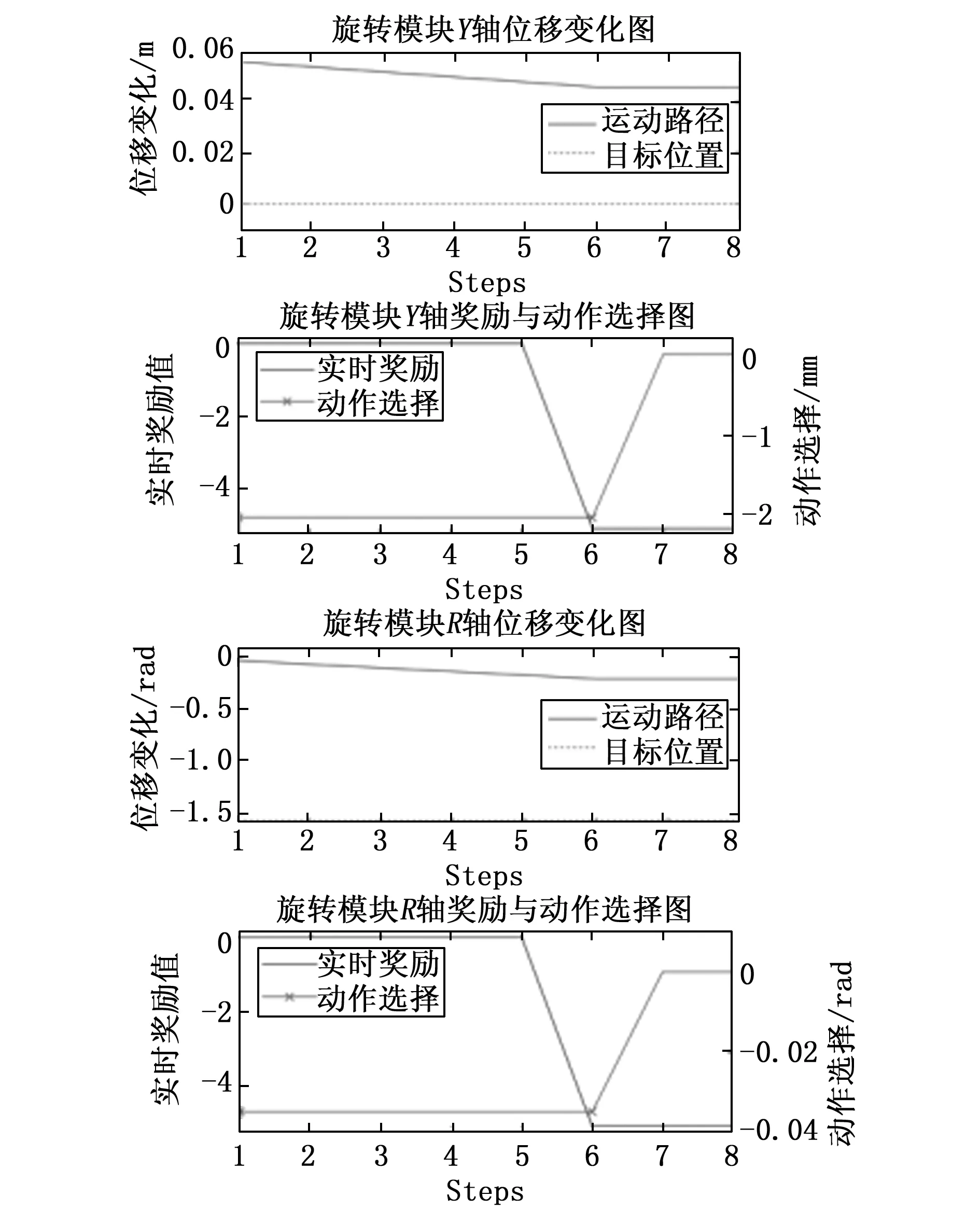
图8 增加停顿次数奖惩的路径曲线
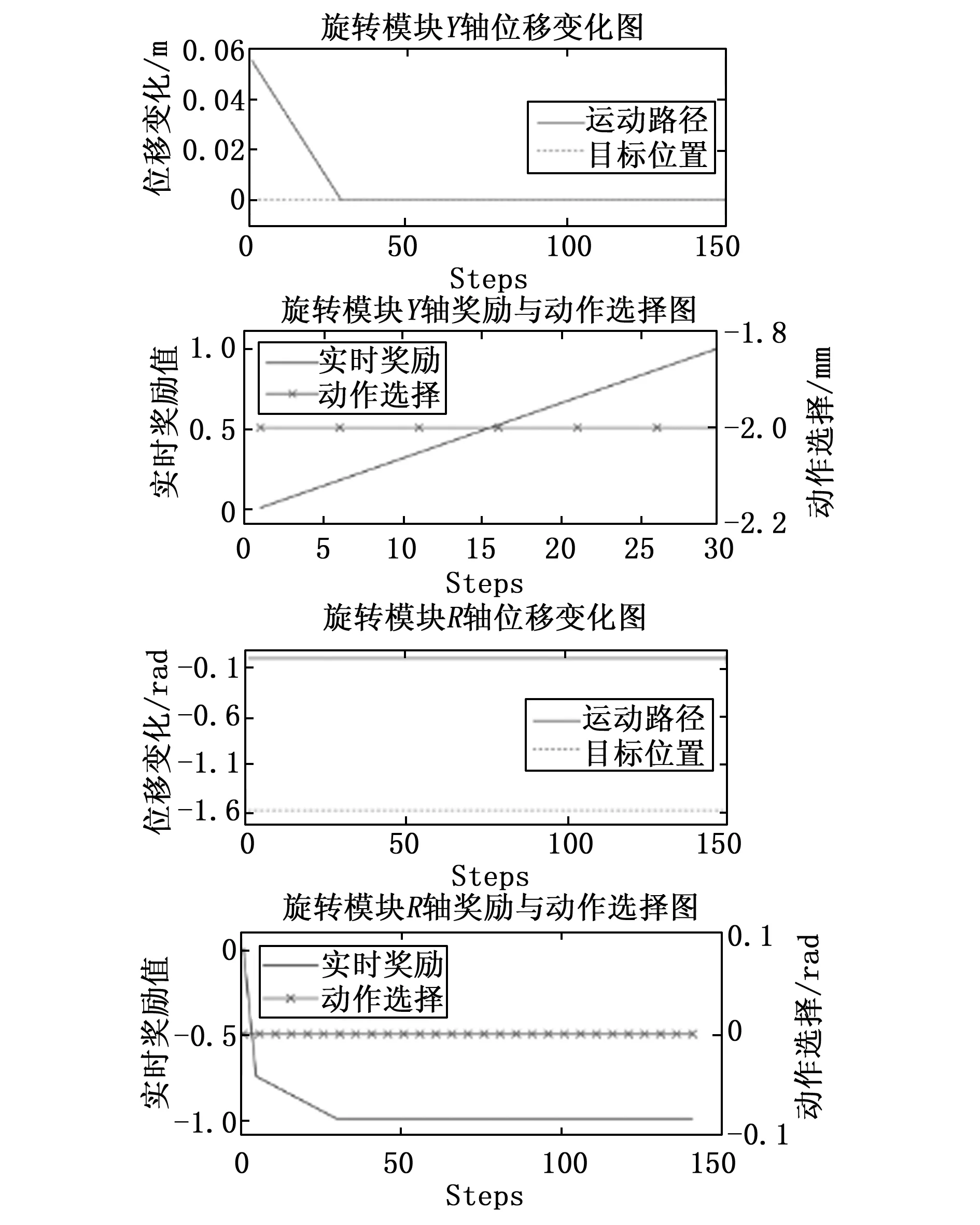
图9 增加碰撞约束奖励函数
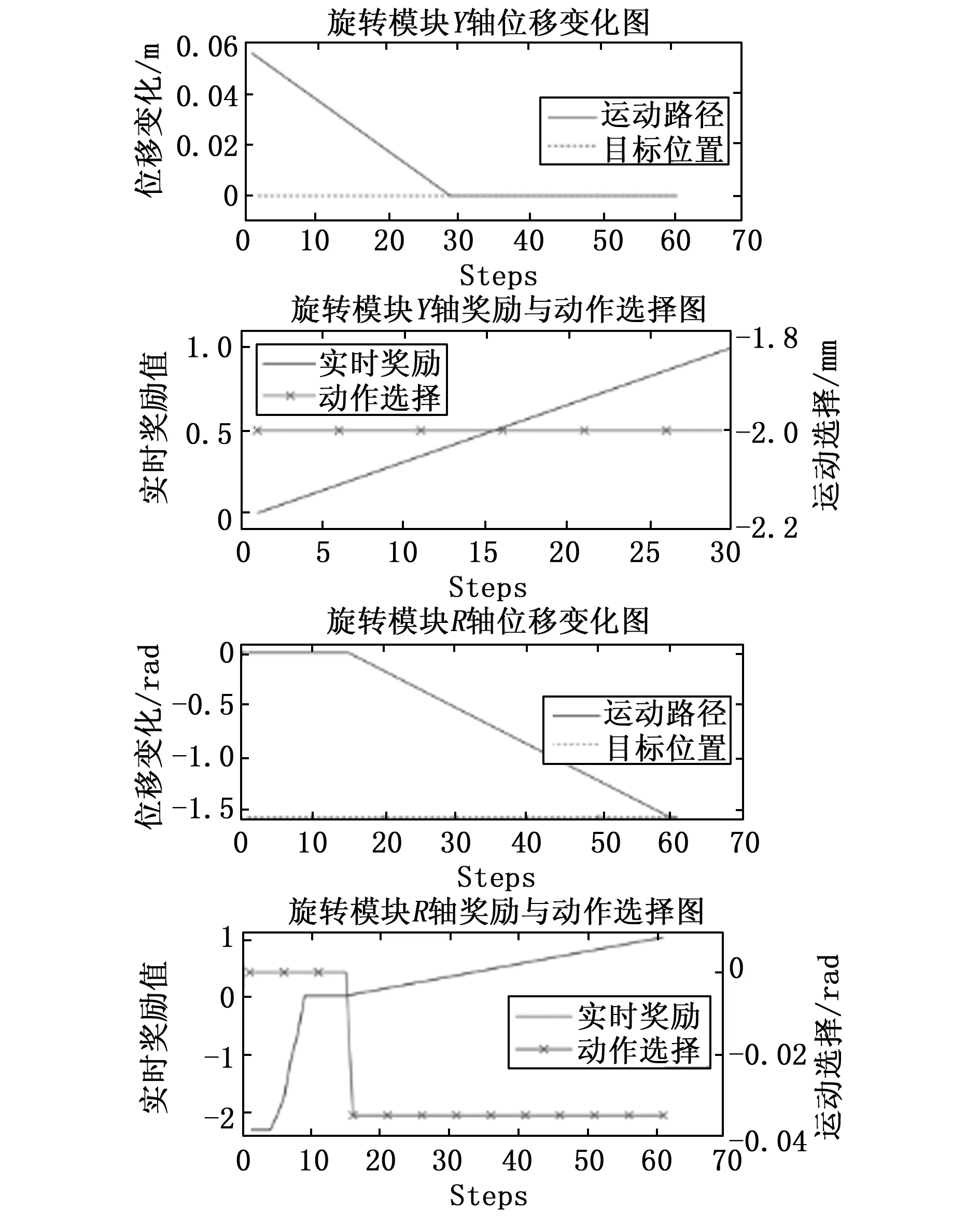
图10 根据式(10)训练后的曲线图
可以看出在该稳定路径下的一个episode中,当操作臂未到达目标位置时,奖励值随step的增加而稳定增加。从动作选择曲线中可看出,受奖励函数约束,动作选择能够保持稳定,符合微装配设备操作臂运行特点。
4 结束语
分析了微装配的任务特点,提出了微装配任务动作、状态、奖励条件设计准则以及构建方法,使得多智能体深度强化学习与直角坐标下的微装配任务更契合,克服了现有环境不符合微装配特点的问题。在仿真软件中对已有的测量设备各零部件进行了凸分解。最后,基于MADDPG算法模型进行训练,得到了完整的测量方案,并通过试验证明设计的奖励函数能够使得路径更加符合微装配的实际工况,为微装配自主规划提供了理论、技术支撑。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
小学生作文(低年级适用)(2019年5期)2019-07-26
小学生作文(低年级适用)(2018年3期)2018-04-17
读友·少年文学(清雅版)(2018年12期)2018-04-04
山东青年(2016年3期)2016-02-28
少儿科学周刊·少年版(2015年4期)2015-07-07
