
基于深度学习的金刚线光斑点检测
2023-08-29 03:15:10丰宗强应一鹏章甫君于勇波刘毅
光学精密工程 2023年15期
丰宗强, 应一鹏, 章甫君, 于勇波, 刘毅
(燕山大学 机械工程学院,河北 秦皇岛 066004)
1 引 言
金刚线[1]是硬脆材料的切割工具,广泛应用于宝石、硅片[2]、太阳能板[3]的切割作业中。在金刚线生产线[4]上,任何额外的接触带来的振动或者其他不稳定因素都有可能导致线受力不均而断裂。所以金刚线断裂的快速检测和断线位置的准确捕捉是金刚线生产过程中的重要课题。目前,金刚线断线普遍在生产线线头和线尾采用拉力传感器进行检测,通过测量线的张力来判定金刚石线是否断裂,此方案具有可靠且稳定的优点,但是此方法只有断线位置接近线头线尾时才能触发报警,故受限于金刚线1.5 m/s的线速,存在断线反馈滞后导致增加损失且设备成本较高的缺点,原有方案的实际滞后时间为50~90 s。
由于在激光照射下金刚线网呈现明显的光斑点,故将金刚线是否断线的状态表征为光斑点有无。通过视觉检测金刚线反射的亮斑点达到检测是否断线的目的,将断线检测转化为视觉光斑点目标检测的问题。斑点检测是机器视觉研究的重要内容之一,随着图像处理技术的日趋成熟,斑点检测已经应用于产品缺陷检测[5]、医学图像检测[6]、遥感识别[7]等诸多领域,众多应用方案已经在工业生产与实际生活中实施。针对传统图像处理方法斑点检测的缺点,研究人员将深度学习技术应用到斑点检测任务中,并取得了不错的效果。Xu[8]等提出UH-DOG斑点检测模型,联合DOG法和U-Net深度学习模型,在细胞斑点检测中取得了优异的检测结果。张轩宇[9]等则利用VGGNet和ResNe-t34卷积神经网络实现了遥感图像中船舶、养殖箱等不同形状的斑点物体的检测及分类。Cao[10]等也利用YOLOv3卷积神经网络结构实现了遥感图像中船舶斑点的识别和检测。
目标检测是相对斑点检测更高的范畴,目标检测的主要任务是确定目标在图像中的位置、尺寸和边缘等信息,这依旧是当前计算机视觉领域充满挑战性的问题[11]。Redmon[12]等提出了YOLO系列目标检测算法,马立[13]等针对小目标漏检率高的问题,提出了改进的Tiny YOLO3模型,对算法的特征提取网络、预测网络和损失函数进行改进。Ahmad[14]等将低级特征的特征图与常规SSD的反卷积层相结合提出EDF-SSD模型。王宸[15]等利用YOLOv3对轮毂焊缝缺陷进行检测。陈仁祥[16]结合注意力机制提出多注意力的Faster RCNN结构对电路板进行缺陷检测。Kumar[16]等结合空间金字塔操作,对Yolov4模型进行改进,提高了口罩检测的准确率。
本文以生产线上金刚线的反射光斑点为研究对象,在前期算法开发中经过灰度处理、空间滤波和图像增强的方法对图像进行预处理,并分别结合基于阈值的亮斑点分割方法、图像形态学操作对目标亮斑点进行了有效检测,得到了较理想的光斑点分割与检测效果。但由于经典图像处理方法主要利用单通道图像进行检测,且在阈值分割过程中会丢失大量的图像特征,同时依靠人为提取特征进行目标分割,步骤多、程序复杂度高。传统图像检测方法易受环境光照条件的影响,为解决传统图像处理的问题,研究了基于深度学习的光斑点目标检测算法,并对算法存在的网络层次较深、模型体积较大、检测实时性较差的问题,进行轻量化改进和优化,将深度学习技术应用于工业领域的亮斑点检测任务中,简化检测流程,提高断线检测的准确率,并将改进后的模型部署于嵌入式平台,提出了一套工业落地的深度学习嵌入式金刚线断线检测方案。
2 材料与方法
2.1 检测原理与智能检测平台
光斑点视觉检测系统原理如图1所示。以线扫激光光源向生产线上的金刚石线投射激光,激光照射在金刚石线网上形成一排光斑点,将识别金刚石线的运动状态表征为金刚石线上漫反射形成的亮斑状态,并通过CCD摄像头进行图像采集及视觉检测,从而判定金刚石线的工作状态。
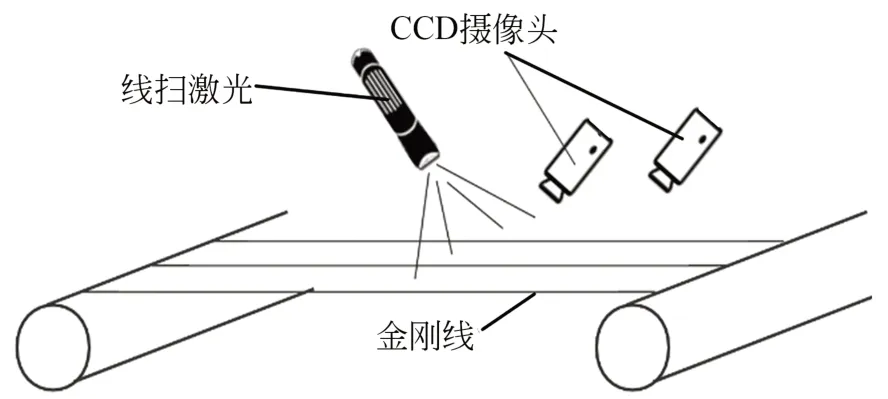
图1 光斑点视觉检测系统原理Fig.1 Schematic diagram of light spot vision detection system
检测系统分为图像采集端和控制器端两部分。图像采集端由图像采集和辅助功能组成,辅助功能包括光源以及LED交互灯组的控制,图像采集和传输主要依靠3个720P工业相机模组和有源USB H-UB模组。前期研究发现,在绿光下斑点的成像效果最优,故光源选择一字线绿色激光灯,相机使用LRCP7650_720P高清面阵工业相机,其最大分辨率为1 280✕720,帧频为30 frame/s,数据接口为USB2.0。USB HUB模组可输出4个USB2.0接口。
图像采集端以STM32作为控制器接收控制信号并控制舵机、LED灯组和激光笔等从设备,从控制器接受控制器指令调整光源角度和人机交互模组提供良好的图像识别环境。控制器端由Jetson Nano嵌入式模组和外围电路组成,控制器端的Nano模组接收相机模组的视频流数据并进行目标检测,硬件框架组成如图2所示。

图2 光斑点视觉检测硬件组成Fig.2 Hardware composition of light spot vision detection system
如图3所示,在金刚线生产线上,系统对金刚线网实时扫描,捕捉实时图像并进行光斑点目标检测,实现对产线上线网状态的过程监测。金刚线网由63条金刚线组成,为了满足实际检测工况、成像效果、相机视野覆盖金刚线网等条件,需将金刚线网均分为左、中、右3个部分检测,图像采集端左、中、右3个相机分别捕获金刚线网的左、中、右区域的图像,即分别对各自区域的21个光斑进行检测,并使用黑色光面亚克力板隔除复杂背景,创造良好的成像环境。系统控制端循环获取3个相机的图像帧进行目标检测,完成一次金刚线网的断线检测,图4为检测系统左、中、右相机采集的原始图像。

图3 金刚线断线智能检测平台Fig.3 Prototype of light spot vision inspection system

图4 检测系统左、中、右相机采集的原始图像Fig.4 Raw images captured by left, center, and right cameras of inspection system
2.2 数据采集与制作
对处于生产状态下的不同产线进行光斑点图像采集,将图像分为多段,针对不同段,选取不同图像阈值,便于标注时斑点的识别同时缩小目标数量,使目标标注的区域选择更加准确。数据增广是深度学习模型训练的常用方法之一,能够有效增加训练数据,避免模型过拟合,同时提升模型的鲁棒性,并采用镜像变换、旋转、透视变换、亮度调整、添加噪声等方法对数据集进行增广,再对数据集进行标注。图5为采集图像处理后的部分数据集。

图5 部分光斑点检测数据集展示Fig.5 Partial presentation of blob detection dataset
对实际生产线上采集得到的原始图像进行筛选,滤除斑点代表性较差、图像过度模糊、图像相似度高的图像,并利用数据增广方法进一步扩充数据集,最终挑选出15 000张较为理想的图片作为模型训练的数据集,各阶段数据集的参数如表1所示。

表1 数据集参数表Tab.1 Dataset parameter
将得到的训练数据集按照8∶1∶1的数量比例随机划分为训练集、验证集和测试集3个部分供后续模型训练。其中,训练集12 000张,验证集1 500张。实验使用图像标注工具LabelImg,标注图像数据中光斑点的位置,共标注13 500张图像。为进一步验证光斑点目标检测的准确率,在测试数据集中增加了500张非金刚线反射形成的光斑杂点作为干扰项,模拟实际产线的成像环境。
2.4 模型训练与部署
本文模型训练及相关实验均在相同的设备上完成,采用的硬件配置和软件版本的具体参数如表2所示。模型训练采用迁移学习方法Pytorch官方提供的预训练模型进行模型参数初始化,同时采用冻结模型的训练方法,模型总共进行100个Epoch的训练。在前50个Epoch训练过程中,先冻结模型的主干特征提取网络的权重系数,使之不进行反向梯度更新,冻结阶段网络训练的batch_size为8,初始学习率为0.001。在后50个Epoch的训练过程中,再将主干特征提取网络解冻,此时对整个网络模型参数进行反向梯度更新。由于需要更新的参数量增加,为避免超出内存,减小输入模型的图片batch_size为4,且由于解冻阶段模型更深,故减小初始学习率为0.000 1。在两个阶段的训练过程中,模型的学习率变化均采用固定步长衰减的策略,学习率每隔一定步数(1个Epoch)就衰减为原来的0.92倍。

表2 实验的硬件配置和软件版本参数Tab.2 Experiment hardware configuration and software version parameter
在相同的软硬件配置下,本文分别对Yolov4,Yolov5和与前两者模型大小相近的Yoloxm 3个模型进行训练。检测速度和检测平均精度(mAP)的关键指标统计如表3所示。
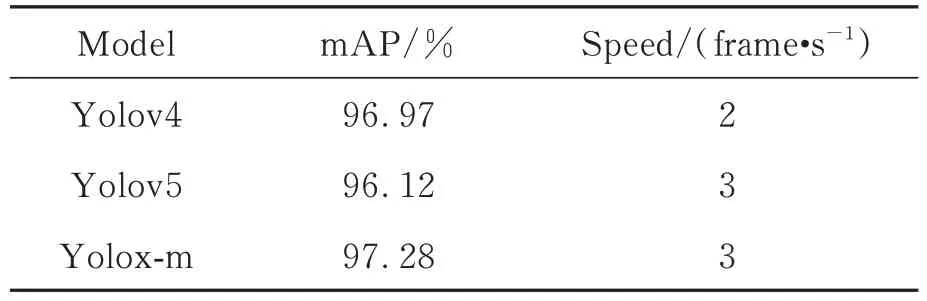
表3 Yolo系列光斑点的检测精度与速度Tab.3 Spot detection accuracy and speed of Yolo series
由表3可见,3种模型均具有较好的检测效果,mAP值均在96%以上。其中Yolox-m的检测精度最高,达到了97.28%,但三者的检测速度均较低,只有2~3 frame/s,主要是由于三者模型层次较深且体积较大,实时性较差,需进行轻量化改进。在检测系统的实际应用中,从检测速度和平均精度考虑,选择对Yolox-m进行轻量化改进。图6为Yolox-m模型的光斑点检测结果。

图6 Yolox-m模型的光斑点检测结果Fig.6 Detection results of light spots in Yolox-m model
3 关键算法
3.1 Yolox原理
Yolox目标检测算法是新一代高性能目标检测算法,其算法框架可分为主干特征提取网络、加强特征提取网络和分类器三部分,如图7所示。算法框架中,主干特征提取网络为CSPDarkNet网络,它主要由5个局部跨阶段(Cross Stage Partial,CSP)残差网络块构成。加强特征提取网络(Feature Pyramid Network, FPN)主要由空间金字塔操作(Spatial Pyramid Pooling Network, SPP)和路径聚合网络(Path Aggregation Network, PANet)组成。输入图片经过CSPDark-Net和FPN得到3个特征图完成图像特征提取,最后在Yolo Head中完成目标检测。与Yolov4最大的不同在于:分类器中Yolox将回归预测和置信度预测进行解耦,并采用无锚框(anchorfree)的边框预测方法代替原有的基于锚框(anchor-based)的边框预测方法。

图7 Yolox目标检测算法框架Fig.7 Schematic diagram Yolox target detection algorithm
Yolox采用解耦检测器,模型在检测器中增加预测分支,将边界框的位置及宽高的回归任务和种类置信度预测的二分类任务相分离,去除检测器在预测过程中回归任务和二分类任务可能存在的不利耦合作用,最后再通过通道堆叠操作将输出的3个预测三维张量进行通道堆叠。解耦检测器虽然增加了少量的模型计算量,但有效地提高了模型训练的收敛速度和预测精度。解耦检测器结构如图7中右侧框检测器所示,其中通道堆叠前的卷积层不执行批归一化和激活函数操作。
相较于早先Yolo系列模型的基于anchorbased的边界框预测方法,Yolox采用了目前流行的anch-orfree的预测框回归策略。在进行正负样本选择时,基于锚框的边界框预测方法需要进行大量的真实框与锚框的交并比计算。
无锚框回归采用点回归的形式,在预测目标物体边缘框的过程中不再借助锚框尺寸。特征图中每个栅格只有一个预测点,根据经过解耦检测器得到的预测参数tx,ty,tw,th可以确定该预测点的预测框形状。如图8所示,与Yolov4不同,经过网络预测得到的宽高的预测参数通过指数函数后直接得到预测框的宽高,而不再是预测框相对于锚框的比例系数。

图8 预测框位置及宽高示意图Fig.8 Schematic diagram of position and width and height of prediction box
根据网络所得的预测参数可得预测框的中心点坐标及其宽高,计算公式如下:
其中:bx,by为预测框中心坐标相对于图像左上角的偏移量,bw,bh为预测框宽高,tx,ty为预测框中心点坐标的预测参数,tw,th为预测框宽高的预测参数,dx和dy为预测点所在栅格左上角点与图像左上角点的距离。
通过解耦检测器可得到3个包含预测参数的三维张量,分别对应加强特征提取网络输出的3张特征图,根据式(1)即可利用三维张量中的预测参数得到相应特征图中每个栅格的预测框。若特征图尺寸为n×n,则每张特征图可得到n×n×1个待分类样本,与基于锚框预测的模型相比减少了2/3的待分类样本数目。但由于负样本数量相对正样本数量的比例依旧较大,为了进一步减小正负样本的数量差距,利用Simple Optimal Transport Assignment (SimOTA)算法进行正负样本分类,增加正样本的数量。在SimOTA算法中,先将真实框内及真实框向外扩展2.5个栅格的区域划分为候选区域,位于候选区域的预测点作为候选点,候选点对应的预测框为候选框。再计算候选框与其对应的真实框的IOU值,并计算候选框与真实框的代价函数,代价函数为:
其中:Lcls为候选框的分类误差,Lreg为候选框的回归误差,x为系数取0.5。
再由图像中真实框的数量确定参数y,y的计算公式如下:
取出每个真实框IOU最大的前y个候选框,将其IOU值相加得到y'。将每个真实框的候选框中代价函数最小的前y'个候选框作为正样本,y'最小值取1,其余样本为负样本。若一个正样本候选框对应多个真实框,则该候选框归为代价函数值小的真实框的正样本。
Yolox中SimOTA算法在限制的候选区域内进行正样本分类,保证了正样本质量,同时根据算法确定自适应的选取样本数,选取多个预测框为正样本,提高正样本的数量。再将其余预测框归为负样本,由于预测框总数减少了2/3,所以有效控制了负样本数量,进而提高了正负样本比例,使用于模型训练的正负样本数量更加均衡。同时由于放弃了锚框,模型不再需要提前指定参考锚框的尺寸,使模型训练更加简便。
3.2 主干特征提取网络替换
结合深度可分离卷积的模型轻量化方法和倒残差块的结构设计对Yolox模型的网络结构进行轻量化改进,将Yolox中的CSPDarknet主干特征提取网络替换为采用倒残差块结构的轻量化网络Mobile-Netv3-Large,得到初步的轻量化网络模型Yolox-MobileNetV3。在主干特征提取网络替换前,删去M-obileNetv3-Large模型最后的全连接层。Yolox模型中默认的输入图像尺寸为640×640,故主干特征提取网络输出的3个特征图的宽高分别为20×20,40×40,80×80,MobileNetv3-Large网络的3个输出特征图的尺寸应与之相同。
3个特征图的输出位置及裁剪后的Mobile-Netv3-Large网络结构如表4所示。图中,3×3,5×5表示残差块中卷积操作中卷积核尺寸,s表示卷积操作步长。Scale通道为输出特征图通道,3个输出的特征图尺寸和通道数分别为80×80×40,40×40×112和20×20×160。

表4 裁剪后的MobileNetv3-Large网络结构Tab.4 Cropped MobileNetv3-Large network structure
3.2 加强特征提取网络的改进
在对主干特征提取网络进行轻量化修改后,对加强特征提取网络也进行轻量化修改。由于Yolox模型的加强FPN中也含有大量的卷积网络层和传统残差结构块,为了进一步减小模型大小,还可以对FPN进行轻量化改进。FPN主要由上采样、下采样、普通卷积层和CSP层组成,CSP层为CSP残差块结构。原加强特征提取网络结构如图9所示。
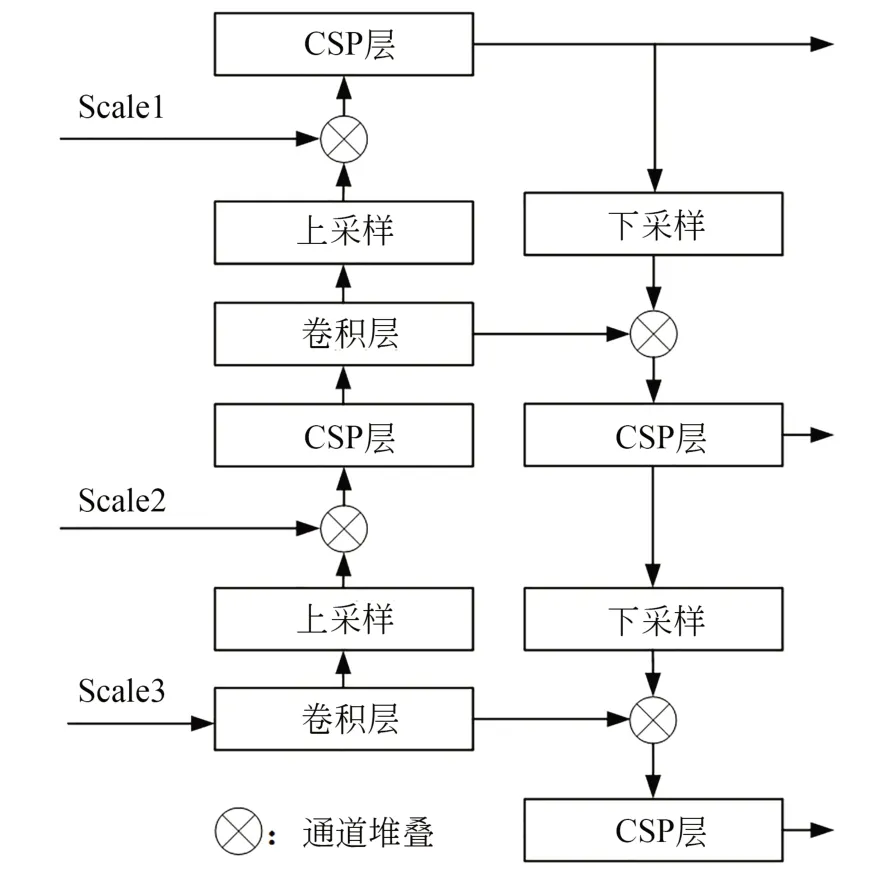
图9 原加强特征提取网络结构Fig.9 The original enhanced feature extraction network structure
加强特征提取网络的轻量化即将FPN的卷积层中的普通卷积替换成深度可分离卷积,并对CSP层中的卷积结构和残差结构进行改进。
Yolox的FPN中CSP层的轻量化改造如图10所示。为了清晰描述网络结构,省略了批归一化层和激活函数,图中左部分所示网络结构为原始CSP残差块结构;右部分所示为轻量化后的CSP残差块结构,其中卷积层中执行普通卷积操作,DP卷积中执行深度可分离卷积操作,m表示残差块的堆叠次数。
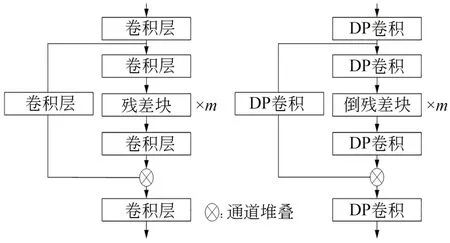
图10 CSP层结构轻量化Fig.10 Lightweight CSP layer structure
将改进后的加强特征提取网络FPN和改进后的主干特征提取网络进行组合,最终轻量化改进模型结构Yolox-MobileNetV3如图11所示。在最终轻量化改进的模型结构中,将主干特征提取网络和加强特征提取网络均进行轻量化处理,同时对于Yolox模型的Yolo Head检测器,保持其原有的解耦检测和无锚框的检测机制。图中,Scale通路表示从修改的主干特征提取网络中输出的3个特征图,Scale通路左部分为采用经过裁剪的Mobi-leNet网络替换后的主干特征提取网络,Scale通路右侧紧接着的是轻量化后的加强特征提取网络,模型的Yolo Head检测器依旧保持原有结构。DP卷积表示深度可分离卷积层,InvCSP层表示轻量化改进的采用倒残差结构的CSP层。
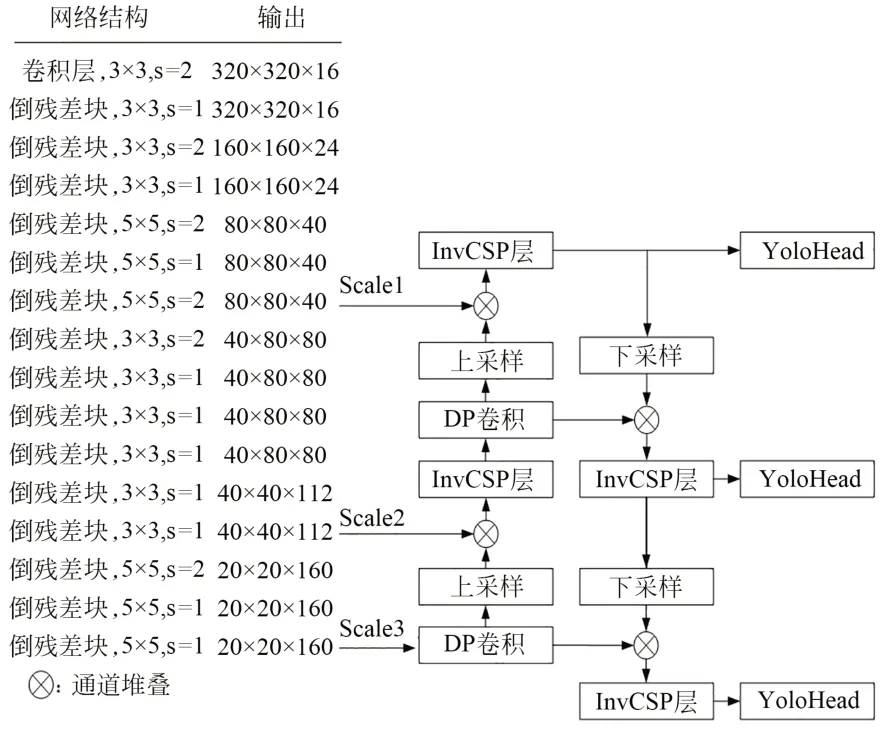
图11 轻量化改进后的Yolox-MobileNetV3网络模型结构Fig.11 Lightweight and improved Yolox-MobileNetV3 network model structure
3.3 基于CA的注意力机制改进
添加注意力机制是提高模型性能的有效手段。由于斑点目标存在较强的空间分布特征且斑点之间存在线性的空间分布规律,故增强网络的空间特征信息的提取能力有助于目标斑点的识别。
在CA机制中,为了有效地捕捉位置信息和通道关系。通过将SE中全局池化的H×W池化核更换为H×1和1×W的两个池化核,将二维全局池化操作分解为两个一维池化编码,沿宽度方向和高度方向的编码方式如下:
其中:H,W分别表示特征张量的高和宽,h表示水平池化所在行高度,w表示竖直池化所在列的宽度表示沿高度方向的编码值表示沿宽度方向的编码值。
CA模块的添加位置如图12所示。为了避免破坏MobileNet原有的网络结构导致预训练权重失效,故在主干特征提取网络的3个特征图输出通道后添加CA模块。同时在加强特征提取网络FPN中,在特征图上采样之后也添加CA模块以增强网络采样在空间方向上的灵敏度。将经过轻量化及添加CA机制的Yolox模型记为MCA-Yolox模型。
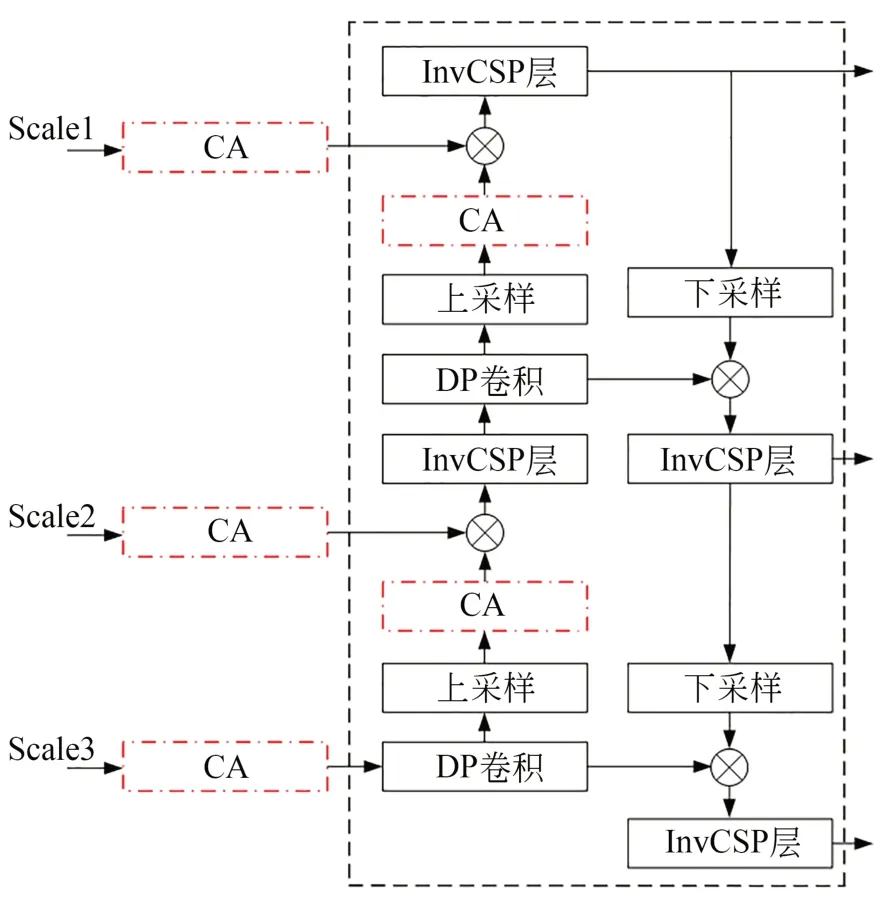
图12 注意力机制改进网络Fig.12 Improved network of attention mechanism
4 实验与结果
4.1 模型评价指标
深度学习中通常用模型的平均精度(Average Precision,AP)作为衡量模型目标检测效果的指标。而模型的平均精度受模型的精确度(Precision)和召回率(Recall)影响。准确率表示预测为真的样本中正样本数的比例,召回率表示在所有真实情况为整的样本中预测为真的样本数的比例。精确度和召回率的计算公式分别为:
其中:TP表示预测为真的正样本(True Positive),FN表示预测为假的负样本(False negative),FP表示预测为假的正样本(False posi-tive)。AP是不同召回率下的准确率的平均值,mAP表示不同类别的AP值的平均值。mAP的计算公式为:
其中:P表示精确度,R表示召回率,C表示目标类别数。
F1分数(F1-score)是Precision和Recall的调和平均数,最大为1,最小为0,分数越高,说明模型越稳健,计算公式为:
由于受到嵌入式平台算力成本限制,在实际应用场景中除了模型的检测能力,人们往往更关注模型的复杂度,通常用模型前向传播的每秒浮点运算次数(Floating-Point Operations Per second,FLOPs)和模型参数个数(Parameters)来描述模型的复杂度。对模型进行实验比较时,需要结合模型的准确度和复杂度来选择。
4.2 网络轻量化对比
除了MobileNet模型,常见的轻量化网络模型还有ShuffleNet,GhostNet和EfficientNet等系列。为了验证Yolox-MobileNetV3模型的性能,选取Yolox-ShuffleNetV2,Yolox-GhostNet和Yolox-Ef-ficientNet 3种轻量化模型,采取与Yolox-MobileN-et相同的方式替换Yolox模型的主干特征提取网络,在相同的数据集上进行对比实验。Mobilenet网络中为了灵活控制模型大小,设置了两个超参数,通道因子α和分辨率因子β,分别用来控制模型中特征张量的通道数和尺寸,通过因子参数可以控制模型大小。实验中默认通道因子和分辨率因子均为1.0。
模型训练的学习率依旧采用固定步长衰减的策略,学习率每隔一定步数(1个Epoch)就衰减为原来的0.92倍。训练采用先冻结主干特征提取网络,再解冻的训练步骤,模型训练100个Epoch,冻结的训练阶段为前50个Epoch。各模型的mAP值默认取threshold为0.5时的mAP值。
如表5所示,与Yolox-m模型相比,4个轻量化改进模型的参数量、大小和运算量均大幅地减小。Yolox-mobileNetV3模型的检测精度在4个模型中最高,mAP值达到了95.02%,模型的大小也仅有20.23 Mb,在模型的检测准确率和模型存储上都比较优秀。

表5 模型实验参数Tab.5 Parameters of model experiment

表5 不同主干特征提取网络替换模型参数Tab.5 Model parameter for different backbone feature extraction network replacement
训练过程中,4种轻量化模型的mAP值变化曲线如图13所示。图14为模型训练后期的mAP变化曲线。在模型解冻即训练50个Epoch后,模型得到进一步的训练,模型的mAP值有较大的提高。4种轻量化改进模型在训练70个Epoch后趋向收敛,mAP值趋向于稳定。与其他模型相比,利用MobilenetV3轻量化改进的模型在模型训练后期能够达到更高的mAP值,体现出MobileNetV3的改进模型相比于其他几个模型在该斑点数据集上具有更高的检测准确率。
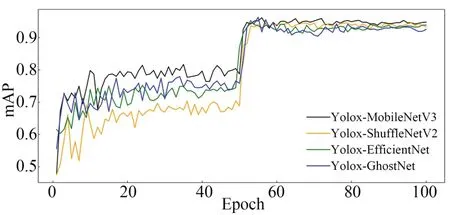
图13 模型训练过程中mAP值Fig.13 mAP in target detection of light spot

图14 训练后期模型mAP值Fig.14 mAP value of post-training model
4.3 改进模型性能验证
为了验证改进模型的检测精度,同时为了进一步验证添加CA机制对提高模型检测精度的有效性,对Yolox-MobileNetV3,MCA-Yolox,Yolox-Tiny和Yolov4-Tiny的检测精度进行比较。
4个模型训练过程中的mAP曲线、F1值曲线分别如图15和图16所示。4个模型在模型解冻后,模型的mAP值和F1值均有较大的提升,说明模型得到进一步收敛,模型的检测精度进一步得到提升。与其他模型相比,在训练过程中改进模型MCA-Yo-lox均保持较高的mAP值,说明改进模型具有较高的检测精确度。由实验数据得到,MCA-Yolox模型的mAP值达到95.43%左右,Yolox-MobileNetV3,Yolox-Tiny和Yolov4-Tiny的mAP值分别在94.52%,94.24%和92.52%左右。在模型F1值上,改进模型比其他3种模型更高,说明模型同时具备更高的Precision和Recall值,模型检测性能更加稳定。MCA-Yolox模型的F1值达到0.952左右,Yolox-MobileNetV3,Yolox-Tiny和Yolov4-Tiny的F1值分别在0.943,0.922和0.922左右。
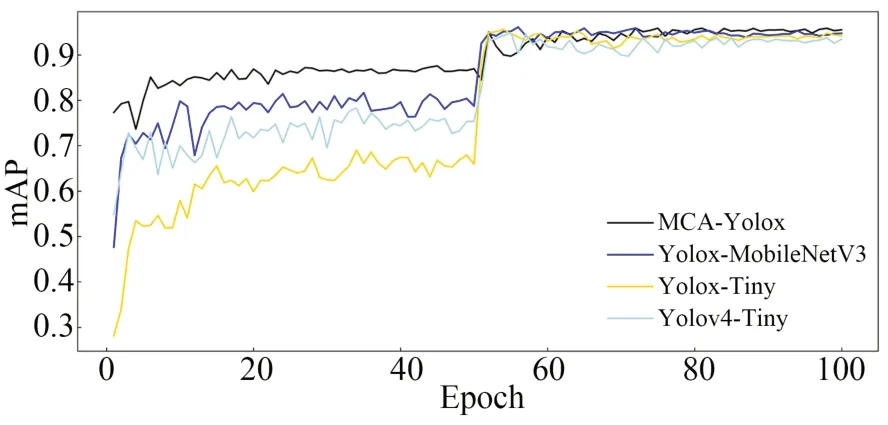
图15 模型训练的mAP曲线Fig.15 mAP curve of model training
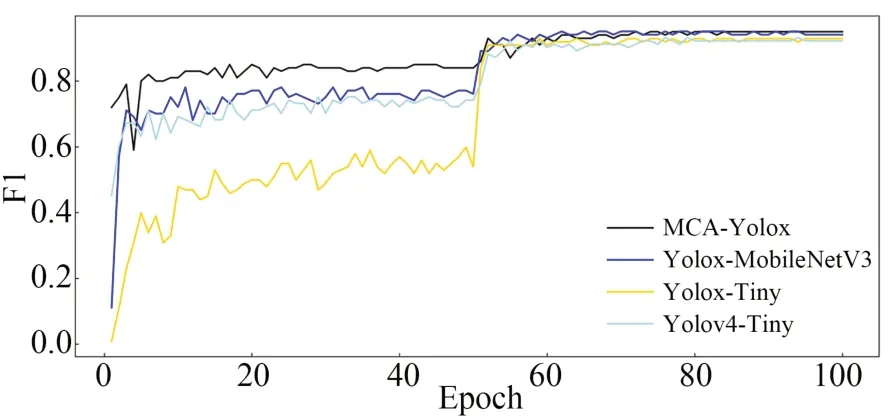
图16 模型训练的F1曲线Fig.16 F1 curve of model training
模型的Precision-Recall(PR)曲线如图17所示,可验证模型的mAP和F1曲线的特征。改进模型MCA-Yolox的PR曲线基本将其他模型的曲线包围,曲线与横纵坐标轴包围的面积比另外3个模型的面积都要大,说明改进模型具有较高的mAP值,曲线的右上角点同时满足更高的Precision和Recall坐标值,说明模型具有更高的F1值。综上,从模型的mAP值和F1值参数上比较,改进模型MCA-Yolox模型具有最好的检测精度和准确率。同时,MCA-Yolox模型比Yolox-MobileNetV3模型在mAP值上提升了约1%,验证了添加CA机制对模型性能的提升。
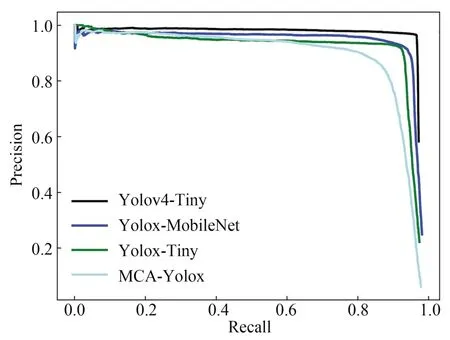
图17 模型训练的PR曲线Fig.17 PR curve of model training
各模型在Jetson Nano平台上的实验参数如表6所示。经过模型的轻量化,改进后的MCAYolox模型的参数量仅占到Yolov4模型的1/13左右。在模型大小和运算量方面,MCA-Yolox也只有Yolov4模型的1/10左右。与Yolov4-Tiny和Yolox-Tiny模型相比,MCA-Yolox在模型大小和运算量相差不多的情况下,mAP提升了1%以上,体现出更佳的检测性能。
Yolov4-Tiny,Yolox-Tiny和改进模型MCATiny在Jetson Nano平台上的检测结果如图18所示,可以看到Yolox-Tiny和Yolov4-Tiny模型对于金刚线网边缘较暗的光斑点都有出现漏检的现象,Yolov4-Tiny对于金刚线网中间形状较不规则的亮斑点也出现了漏检,而改进的MCAYolox模型则成功地检测出图像中的所有亮斑点。同时Yolox-Tiny和Yolov4-Tiny模型检测出的亮斑点的置信度都在0.60~0.75之间,而MCA-Yolox模型检测出的亮斑点的置信度都高于0.75,体现出MCA-Yolox模型更高的检测精度和稳定性。轻量化检测模型中Yolov4-Tiny模型的检测速度最快达到15 frame/s,MCA-Yolox模型也达到12 frame/s。

图18 各模型检测效果对比Fig.18 Comparison of detection effect of each model
最后,利用TensorRT库对改进后的模型进行加速优化,随后将优化后的模型部署于智能检测嵌入式平台,经过TensorRT加速后的MCA-Yolox模型的检测速度能够达到30 frame/s左右,若不考虑系统图像传输时间,系统可在0.1 s左右内完成3个相机捕获的图像帧斑点检测,并进行断线异常报警。从模型存储空间、检测速度和检测准确率等方面考虑,改进的MCA-Yolox模型在满足检测实时性的要求上,检测准确率较高,达到了理想的光斑点检测效果。
5 结 论
本文针对传统图像处理算法易受外部环境干扰,实时性较差等问题,引入深度学习算法对光斑进行检测,并提出了一种改进的轻量化目标检测模型MCA-Yolox,对Yolox模型提出了3点改进策略:利用MobileNetV3轻量化特征提取网络替换 Yolox模型的主干特征提取网络对模型进行了轻量化改进;利用深度可分离卷积和倒残差结构对加强特征提取网络进行了轻量化改进;对模型添加CA机制,提高了模型的检测精度。实验结果表明,改进后的MCA-Yolox模型的大小和运算量减小到Yolov4和Yolox模型的1/3以下,相比同样规模的Yolov4-Tiny和Yolox-Tiny轻量化模型具有更高的检测精度,其mAP值高于 Yolov4-Tiny约2.9%,高于Yolox-Tiny约1.2%。在Jetson Nano设备上的检测实验中,MCA-Yolox模型体现出最好的亮斑点检测效果,并达到12 frame/s的检测速度。最后,将加速优化后的模型部署于智能检测平台,检测速度可达30 frame/s。
猜你喜欢
大自然探索(2024年1期)2024-02-29 09:10:30
新作文·小学低年级版(2022年3期)2022-08-30 07:36:46
精密成形工程(2022年2期)2022-02-22 05:44:14
智慧少年·故事叮当(2021年5期)2021-08-23 02:25:31
智富时代(2019年2期)2019-04-18 07:44:42
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
专用汽车(2016年1期)2016-03-01 04:13:19
专用汽车(2015年4期)2015-03-01 04:09:07
