
基于多尺度互注意力的遥感图像语义分割网络
2023-08-25 08:05刘春娟乔泽闫浩文吴小所王嘉伟辛钰强
浙江大学学报(工学版) 2023年7期
刘春娟,乔泽,闫浩文,吴小所,3,王嘉伟,辛钰强
(1.兰州交通大学 电子与信息工程学院,甘肃 兰州 730070;2.兰州交通大学 测绘与地理信息学院,甘肃 兰州 730070;3.甘肃大禹九洲空间信息科技有限公司院士专家工作站,甘肃 兰州 730070)
遥感图像具有成像复杂、地物类别丰富、目标物体之间尺度差异大等特点,使得遥感图像语义分割任务具有很大的挑战性[1].
全卷积网络[2](full convolutional network,FCN)是第一个在语义分割问题中使用端到端的卷积神经网络.在FCN的基础上,由Ronneberger等[3]提出的U-net网络第一次引入了编解码结构.在遥感图像中,不同目标物体之间较大的尺度差异给语义分割任务带来了挑战.一种方法是通过多尺度特征融合[4-10]来提高不同尺度物体的分割精度,如Deeplabv3[4]提出空洞空间金字塔池化模块来提取上下文信息.PSPNet[5]提出多尺度金字塔池化模块来扩大感受野.另一种方法是通过注意力机制[11-16]来提高不同尺度物体的分割精度,如DANet[11]提出位置注意力模块和通道注意力模块,捕捉空间维度和通道维度中的依赖关系.CCNet[12]提出十字交叉注意力模块,减少自注意力机制引入的计算量.随着对遥感图像语义分割任务的研究,结合多尺度特征融合和注意力机制的网络取得了更优的效果[17-19],如DA-IMRN[17]通过2个分支分别关注空间和光谱信息,采用双向注意力机制来指导2个分支之间的交互特征学习.
受上述网络的启发,为了解决遥感图像目标物体之间尺度差异大,导致小尺度物体分割精度低的问题,提出新的网络.在网络的编码部分,通过输入不同尺度的遥感图像,增大卷积神经网络对小尺度物体的关注度.引入互注意力模块,平衡不同尺度目标物体所占的权重.在网络的解码部分,引入编码指导上采样机制,在融合编码结构所包含的空间位置信息的同时增加上采样的可学习性,整体提高了语义分割的性能.
1 多尺度互注意力与指导上采样语义分割网络模型
1.1 多尺度互注意力与指导上采样网络结构
多尺度互注意力与指导上采样网络结构如图1所示.将输入分辨率为512像素×512像素的遥感图像通过临近插值法上采样到1 024像素×1 024像素的遥感图像.将2个输入图像分别输入到骨干网络(VGG16[20])中,得到不同尺度遥感图像的特征图.将获得的不同尺度遥感图像的特征图输入到多尺度互注意力模块中,得到不同尺度图像像素间的全局关系,在像素级的层面上平衡不同尺度目标物体所占的权重.将不同尺度的特征图和多尺度互注意力模块的输出进行通道拼接,再经过1×1卷积进行通道压缩.在该网络的解码结构中,将编码结构中每个stage所得到的特征图与待上采样的特征图一起输入到编码指导上采样模块中,通过编码部分的特征图来指导上采样过程,将编码部分牺牲的空间细节信息加入解码部分,使得语义分割结果更加精确.
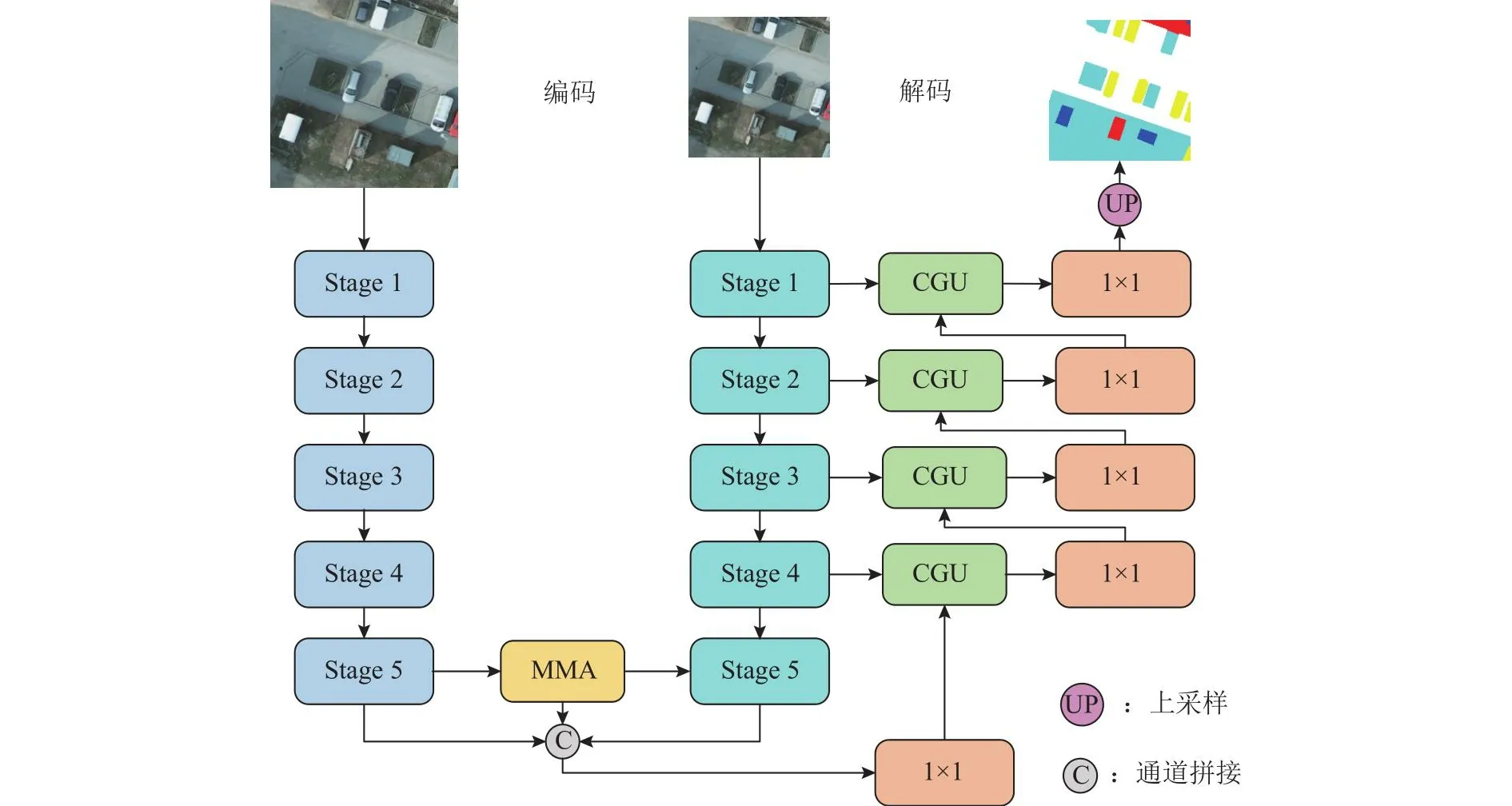
图1 多尺度互注意力与指导上采样网络结构Fig.1 Multi-scale mutual attention and guided upsampling network structure
1.2 多尺度互注意力模块
遥感图像在语义分割任务中存在大尺度目标物体与小尺度目标物体无法兼顾的问题,导致不同尺度目标物体的分割精确度差异较大.提出多尺度互注意力模块(multi-scale mutual attention module,MMA).该模块通过输入不同尺度图像的特征图,计算不同特征图之间像素的全局关系,在像素级的层面上平衡不同尺度目标物体所占的权重,解决目标物体间的类别不平衡问题.
如图2所示,多尺度互注意力模块需要2个输入特征图:一个是分辨率为512像素×512像素的图像经过骨干网络(VGG16)得到的特征图X∈RC×H×W,另一个是将图像尺寸放大为1 024像素×1 024像素后经过骨干网络(VGG16)得到的特征图Y∈RC×H×W.特征图X的分辨率为16像素×16像素,特征图Y的分辨率为32像素×32像素.将特征图X输入到1×1的卷积中进行通道压缩,分别生成2个新的特征图K、V,其中{K,V}∈RC×H×W.对特征图K进行变形和转置得到矩阵K′∈RN×C,对特征图V变形得到矩阵V′∈RC×N,其中N=H×W.将特征图Y经过2倍下采样后输入到1×1的卷积中,生成新的特征图Q∈RC×H×W,对特征图Q变形得到矩阵Q′∈RC×N.将矩阵K′和Q′进行矩阵相乘,经过softmax激活函数得到权重图A∈RN×N,如下所示:
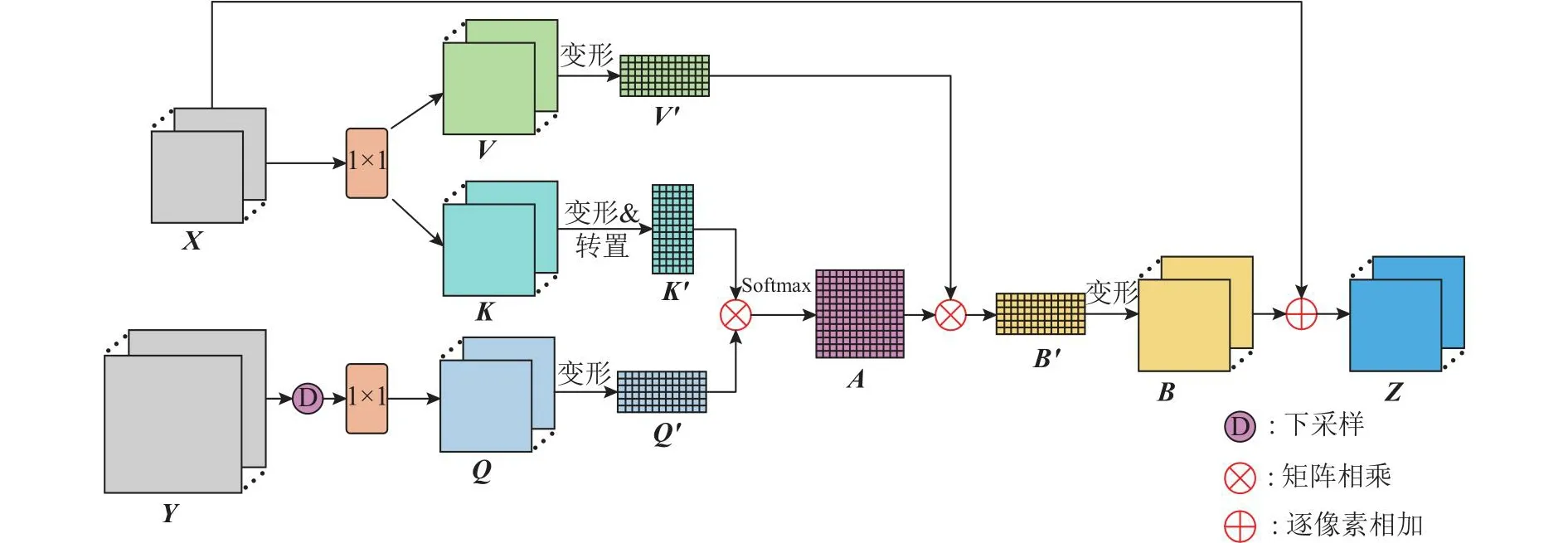
图2 多尺度互注意力模块的结构Fig.2 Structure of multi-scale mutual attention module
将矩阵V′和权重图A进行矩阵相乘得到矩阵B′∈RC×N,对矩阵B′变形得到特征图B∈RC×H×W.将特征图B和特征图X进行逐像素相加,得到特征图Z∈RC×H×W,如下所示:
从式(2)可以看出,特征图Z中不仅包含了特征图X中的所有信息,还包含了不同尺度特征图之间各个像素的全局关系.在遥感图像中,大尺度的目标物体的分割精度高于小尺度目标物体的分割精度.通过将输入遥感图像放大1倍来放大小尺度目标物体的尺寸,经过注意力机制得到不同尺度目标物体的权重图.该权重图平衡了大尺度目标物体与小尺度目标物体之间的权重,在不影响对大尺度目标物体分割精度的前提下,提高了小尺度目标物体的分割精度.
1.3 编码指导上采样模块
在卷积神经网络中,浅层的空间细节信息是必不可少的.直接利用通道拼接引入浅层空间信息的方法不仅融合了很多冗余信息,而且增大了网络的参数量和计算量.
在卷积神经网络的解码部分,大多数网络都是通过临近插值法或双线性插值法对特征图进行上采样操作.利用这种无参数、不可学习的上采样方法,会导致靠近边界的像素被分配为错误类别.
为了在增大上采样可学习性的同时引入网络中的空间细节信息,提出编码指导上采样模块(code-guided upsampling module,CGU),如图3所示.该编码指导上采样模块需要2个输入特征图:一个是编码结构中每个stage输出的包含空间细节信息的特征图X,另一个是待上采样的网络深层特征图H.将特征图X输入到细节块中,提取特征图X中包含的空间细节信息,对提取出的空间细节信息经过softmax函数得到空间细节信息的权重图G.其中,细节块主要由2个block块和1个1×1卷积组成,每个block块由1个3×3卷积层、1个BN层和1个ReLU层组成.对特征图H利用双线性插值方法进行2倍的上采样,得到与权重图G尺寸一样的特征图.将权重图G和特征图进行逐像素相乘,得到包含空间细节信息的特征图U,如下所示:

图3 编码指导上采样模块的结构Fig.3 Structure of code-guided upsampling module
编码结构输出的特征图在对上采样进行指导前引入细节块,不仅提取出了特征图中的空间细节信息,还增加了权重图的可学习性,弥补了上采样不可学习的缺点.
2 数据集及评估指标
2.1 数据集
Potsdam数据集:Potsdam数据集是在德国勃兰登堡首都上空拍摄的数字正射影像图.在实验中,将数据集中的遥感图像裁剪成2 304张分辨率为512像素×512像素的图像.其中的1 612张图像作为训练集,346张图像作为验证集,346张图像作为测试集.
Jiage数据集:Jiage数据集包括4个中等分辨率的遥感影像及相应的真实标签.将数据集中的图像裁剪成分辨率为512像素×512像素的图像.由于数据集较小,使用常用的数据增强方法,共得到3 173张分辨率为512像素×512像素的图像,将其中的2 390张图像作为训练集,400张图像作为验证集,383张图像作为测试集.
2.2 评估指标
在实验中,使用平均交并比(mIoU)、F1得分和像素精度(PA)作为指标,评估多尺度互注意力与指导上采样网络的优越性.
像素精度、F1得分、平均交并比的定义分别如下所示:
式中:TP、TN、FP和FN分别为真阳性、真阴性、假阳性和假阴性的数量;R为召回率,P为精确度,
3 实验设计及结果
提出的多尺度互注意力与指导上采样网络在Pytorch深度学习框架下实现,在64位windows10系统的服务器上开展实验.该服务器的CPU为英特尔至强R处理器E5-2650 v4(2.20 GHz),配备80 GB的内存(RAM).显卡为Nvidia GeForce GTX 1080 Ti,显存为11 GB.
在训练过程中,使用小批次的随机梯度下降法(SGD),批次大小为4,动量为0.9,权重衰减为0.000 1,设置初始学习率为0.001 8.采用“poly”的学习率衰减策略来动态调整学习率,表达式为
式中:l为当前学习率,lini为初始学习率,e为当前的训练轮数,emax为最大的训练轮数.
整个实验过程包括消融实验和对比实验.如表1所示为提出实验策略的4种缩写.其中DCED表示单尺度输入且骨干网络为VGG16的深度卷积编码-解码网络,该网络的输入为单一尺度的图像,输入图像分辨率为512像素×512像素.

表1 所有实验策略的缩写Tab.1 Abbreviation for all experimental strategies
3.1 Potsdam数据集上的消融实验结果展示与分析
在Potsdam数据集上通过实验验证了网络中各个模块的有效性.如表2、3所示为在Potsdam数据集上开展的消融实验结果.表中,IoU为交并比.
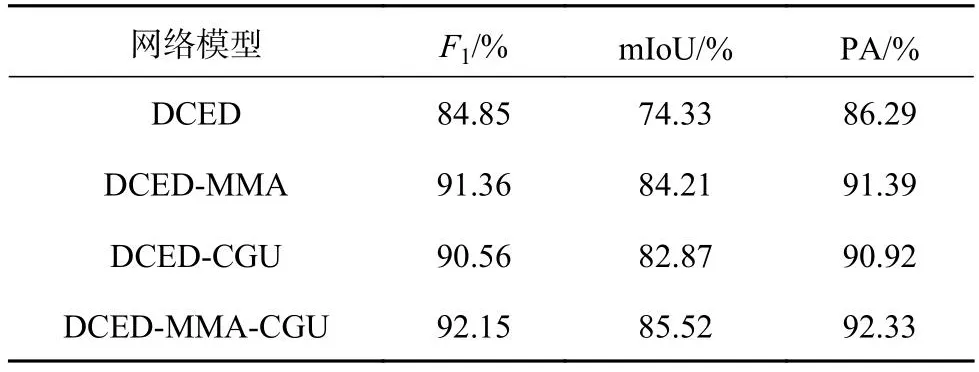
表2 Potsdam数据集上的消融实验结果Tab.2 Results of ablation experiments on Potsdam dataset
3.1.1 增加多尺度互注意力模块(MMA)的消融实验结果 如表2、3所示,在DCED的基础上加入MMA后,较DCED在mIoU、PA、F1上分别增加了9.88%、5.1%、6.51%,特别是背景、不透水表面和树的mIoU提升尤为明显,分别提升了27.39%、8.50%、7.35%.从图4的第4列可以看出,相比于DCED,DCED-MMA对小尺度物体的分割精度有很大提升,特别是对于在图像中占比较少的背景物体.通过多尺度输入策略和互注意力机制,能够更好地平衡不同尺度目标物体,解决物体类间不平衡的问题,提高小尺度物体的分割精确度.
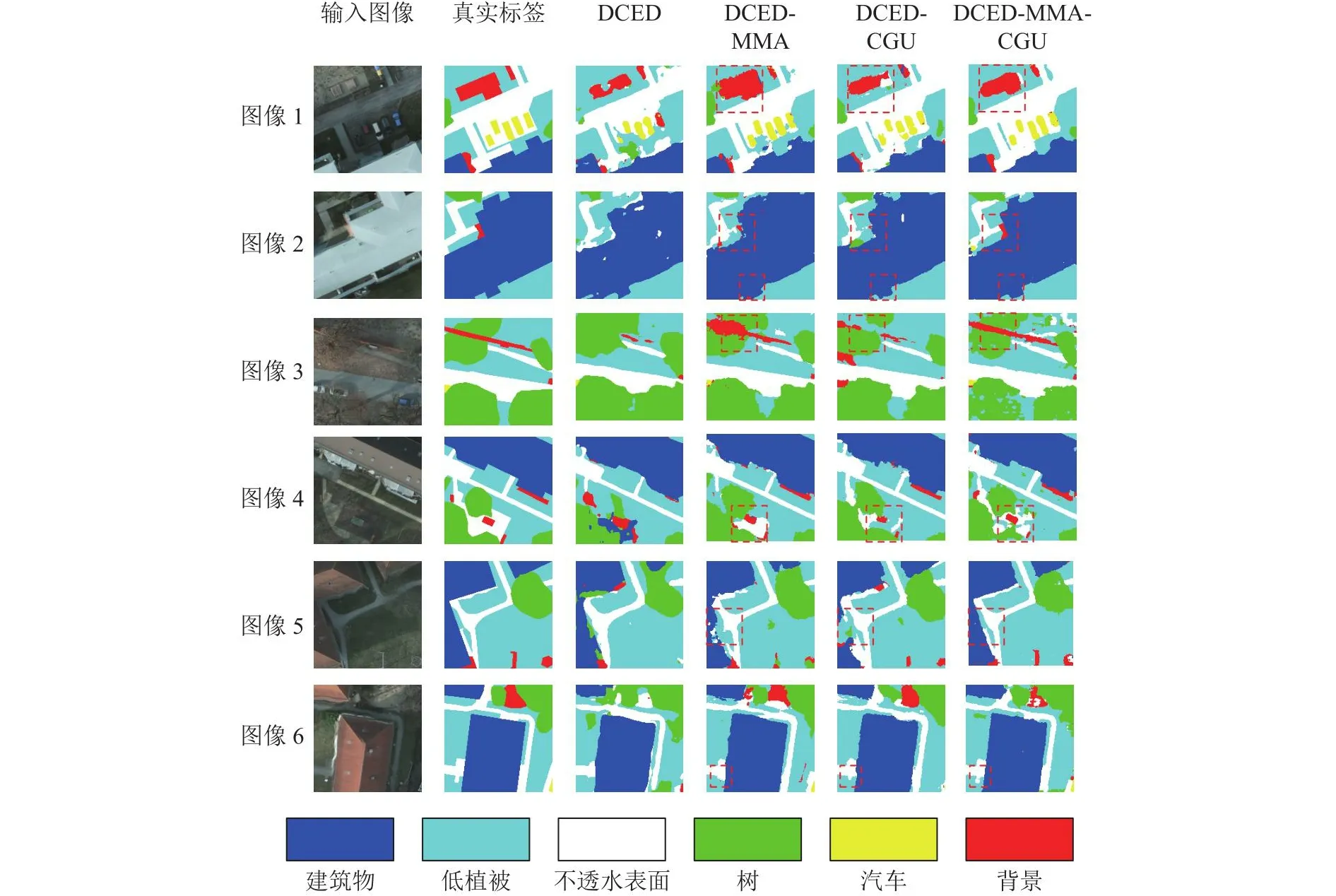
图4 Potsdam数据集上消融实验的局部视觉对比结果Fig.4 Local visual comparison results of ablation experiments on Potsdam dataset
3.1.2 增加编码指导上采样模块(CGU)的消融实验结果 如表2所示,在DCED的基础上加入CGU后,较DCED在mIoU、PA、F1上分别增加了8.54%、4.63%、5.71%,较DCED-MMA在mIoU、PA、F1上分别减少了1.34%、0.47%、0.80%,这说明DCED-CGU的整体性能不如DCED-MMA.从表3可以看出,DCED-CGU对小尺度物体的分割效果不如DCED-MMA,如汽车类别,DCEDMMA的mIoU比DCED-CGU高3.83%.从图4可以看出,与DCED相比,DCED-CGU能够更好地展现物体的细节信息,使得对物体边缘分割更精确.通过编码特征图来指导上采样的策略,可以巧妙地融合空间细节信息,使得上采样具有可学习性,提高物体的分割精度.

表3 Potsdam数据集上各类别的消融实验结果Tab.3 Results of ablation experiments of various categories on Potsdam dataset
3.1.3 增加多尺度互注意力模块(MMA)和编码指导上采样模块(CGU)的消融实验结果 如表2、3所示,在DCED的基础上加入MMA和CGU后,较DCED-MMA在mIoU、PA、F1上分别增加了1.31%、0.94%、0.79%,较DCED-CGU在mIoU、PA、F1上分别增加了2.65%、1.41%、1.59%.从图4可以看出,DCED-MMA-CGU集合了MMA和CGU两者的优点,在保证对小尺度物体分割精度的情况下,增加了空间细节信息,细化了物体的边界信息,提高了各类目标物体的分割精度.DCEDMMA-CGU可以更好地处理遥感图像语义分割任务.
3.2 Jiage数据集上的消融实验结果展示与分析
在Jiage数据集上,通过实验逐步验证了网络中各个模块的有效性.如表4、5所示为在Jiage数据集上开展消融实验的结果.

表4 Jiage数据集上的消融实验结果Tab.4 Results of ablation experiments on Jiage dataset

表5 Jiage数据集上各类别的消融实验结果Tab.5 Results of ablation experiments of various categories on Jiage dataset
3.2.1 增加多尺度互注意力模块(MMA)的消融实验结果 如表4、5所示,在DCED的基础上加入MMA后,在mIoU、PA、F1上分别增加了9.25%、2.84%、6.63%,特别是道路、水和背景的mIoU提升尤为明显,分别提升了25.47%、6.43%、6.07%.从图5的第4列可以看出,与DCED相比,DCEDMMA能够更好地平衡大尺度物体与小尺度物体所占的权重,提高小尺度物体的分割精确度.

图5 Jiage数据集上消融实验的局部视觉对比结果Fig.5 Local visual comparison results of ablation experiments on Jiage dataset
3.2.2 增加编码指导上采样模块(CGU)的消融实验结果 如表4、5所示,在DCED的基础上加入CGU后,较DCED在mIoU、PA、F1上分别增加了8.61%、2.55%、6.22%,较DCED-MMA在mIoU、PA、F1上分别减少了0.64%、0.29%、0.41%.这说明DCED-CGU的整体性能不如DCED-MMA,特别是对小尺度物体的分割效果更差,如道路类别,DCED-MMA的mIoU比DCED-CGU高1.7%.对比图5中的第4、5列可以看出,DCED-CGU能够更好地区分目标物体边界,DCED-MMA对小尺度物体的分割更有优势.
3.2.3 增加多尺度互注意力模块(MMA)和编码指导上采样模块(CGU)的消融实验结果 如表4、5所示,在DCED的基础上加入MMA和CGU后,较DCED-MMA在mIoU、PA、F1上分别增加了2.09%、0.40%、1.32%,较DCED-CGU在mIoU、PA、F1上分别增加了2.73%、0.69%、1.73%.从图5可以看出,与DCED-MMA和DCED-CGU相比,DCED-MMA-CGU的语义分割性能有所上升,特别是对于小尺度物体的分割精度提升尤为明显.DCEDMMA-CGU可以更好地处理遥感图像语义分割任务.
3.3 Potsdam数据集上的对比实验结果展示与分析
在Potsdam数据集上,将DCED-MMA-CGU与最新的网络进行对比.如表6所示为DCED-MMACGU和8个最新的分割网络模型在Potsdam数据集上各个类别的IoU和mIoU的结果.与SegNet[21]、PSPNet、DeeplabV3、MSRF[22]、EMANet[23]、CCNet、DANNet[24]和MagNet[25]获得的mIoU相比,DCEDMMA-CGU的mIoU分别增加了14.62%、9.35%、8.77%、5.47%、3.72%、3.13%、1.43%和1.32%,总体上表现均优于其他模型,得到了最好的效果.

表6 在Potsdam数据集上与8种最先进的方法进行定量比较Tab.6 Quantitative comparison with 8 state-of-the-art methods on Potsdam dataset
从表6可以看出,所有网络对遥感图像中大尺度的建筑物类别和不透水表面类别的分割效果较好,对小尺度的汽车类别和边界复杂的树和背景类别的分割效果较差.传统的语义分割网络如SegNet、PSPNet、DeeplabV3在遥感图像语义分割任务中效果相对较差,近年来提出的网络如DANNet和MagNet在遥感图像语义分割领域中具有一定的优势.与DANNet相比,DCED-MMA-CGU在汽车类别的IoU上提升了5.07%,提升效果明显;在背景和低植被类别的IoU上分别提升了1.02%和1.17%.由此可见,DCED-MMA-CGU对小尺度物体的分割效果有较大提升.与MagNet相比,DCEDMMA-CGU在背景和树类别的IoU上分别提升了3.67%和3.24%.DCED-MMA-CGU不仅提升了小尺度物体的分割精度,而且提升了对边界轮廓复杂物体的分割效果,适合处理遥感图像的语义分割任务.
如图6所示为3个经典的网络(PSPNet、CCNet、MagNet)和DCED-MMA-CGU在Potsdam数据集上语义分割的结果.可以看出,PSPNet的分割效果较差,出现较多分类错误的现象,如第3行将背景错误分类为不透水表面.CCNet的总体分割效果较好,但是一些小尺度物体的分割效果不太理想,如第6行将部分汽车错误分类为背景.MagNet对小尺度物体的分割效果有所提升,如第6行的汽车类别和第1、2、5行中的背景类别,但是对一些类别的边界轮廓出现分类错误的现象,如第4行中对低植被和建筑物的边界分类错误.DCEDMMA-CGU对小尺度的汽车类别和复杂边界的背景类别分类都较准确.虽然MagNet和DCED-MMACGU对遥感图像中小尺度物体的分割精确度都有所提升,但是DCED-MMA-CGU能够对目标物体的边缘进行分割,提高了语义分割的整体性能.
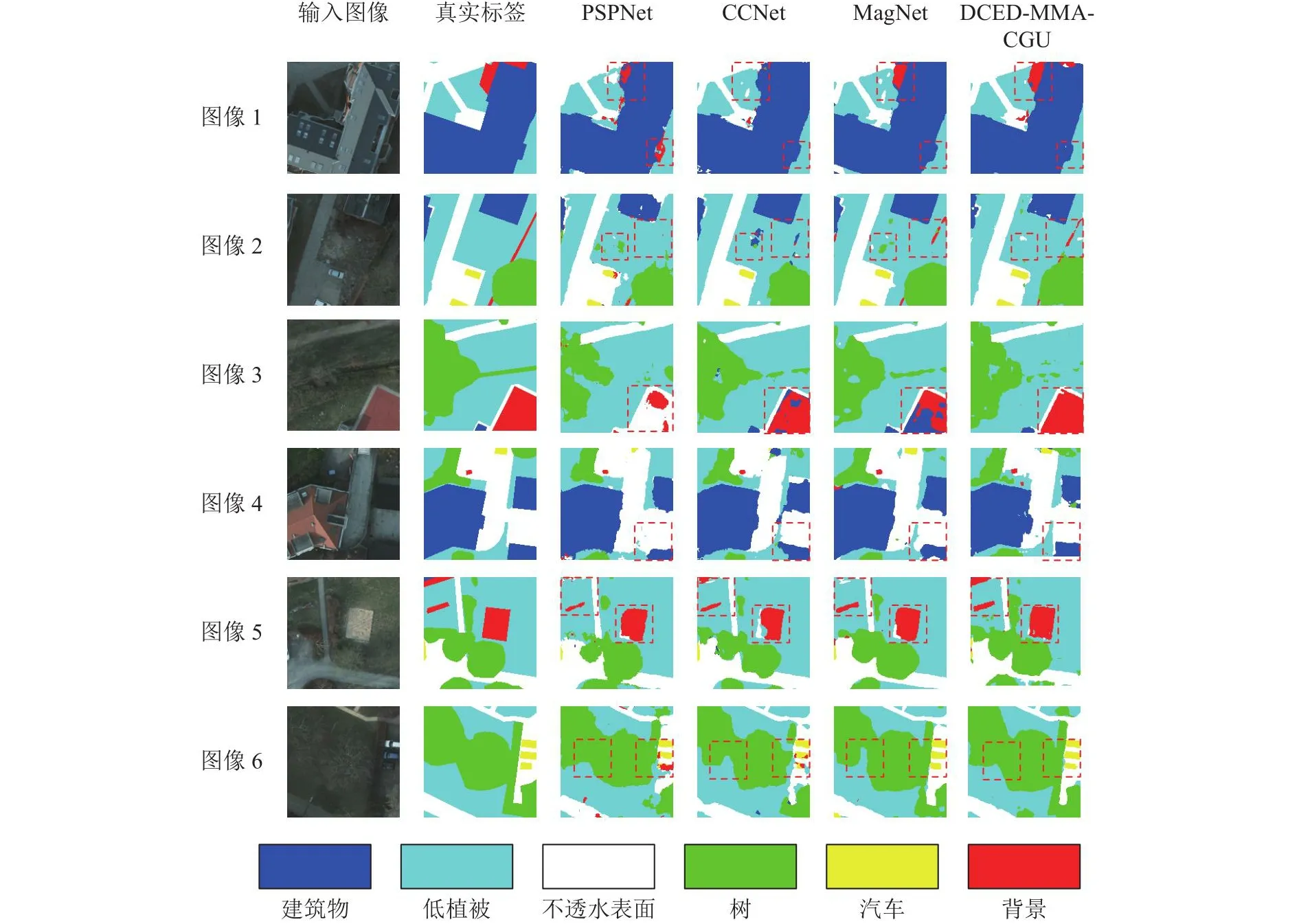
图6 Potsdam数据集上PSPNet、CCNet、MagNet和DCED-MMA-CGU的局部视觉对比结果Fig.6 Local visual comparison results of PSPNet, CCNet, MagNet and DCED-MMA-CGU on Potsdam dataset
3.4 Jiage数据集上的对比实验结果展示与分析
在Jiage数据集上,将DCED-MMA-CGU与最新的网络进行对比.如表7所示为DCED-MMACGU和8个最新的分割网络模型在Jiage数据集上各个类别的IoU和mIoU.与SegNet、PSPNet、DeeplabV3、EMANet、MSRF、CCNet、MagNet和DANNet获得的mIoU相比,DCED-MMA-CGU的mIoU分别增加了16.17%、7.53%、6.60%、4.22%、3.95%、3.36%、2.07%和1.46%,得到了最好的效果.

表7 在Jiage数据集上与 8 种最先进的方法进行定量比较Tab.7 Quantitative comparison with 8 state-of-the-art methods on Jiage dataset
从表7可以看出,所有网络对遥感图像中大尺度的植被类别和水类别的分割效果较好,对小尺度的路类别和边界复杂的背景和建筑物类别的分割效果较差.与MagNet相比,DCED-MMACGU在路类别和建筑物类别的IoU上分别提升了4.84%和3.66%.由此可见,DCED- MMA-CGU对小尺度物体的分割效果有很大提升.与DANNet相比,DCED-MMA-CGU在背景和建筑物类别的IoU上分别提升了2.82%和2.48%.DCEDMMA-CGU在提升小尺度物体的分割精度的同时引入了空间细节信息,使得对物体边界的分类更加准确.
如图7所示为3个经典的网络(PSPNet、CCNet、MagNet)和DCED-MMA-CGU在Jiage数据集上语义分割的结果.可以看出,PSPNet对图像中占比较小物体的分割效果较差,如第2、3行中无法正确区分背景类别.CCNet和MagNet的分割效果相差不大,但均出现了错误分类现象,如第4行中2个网络将背景错误分类为建筑物,第6行中2个网络将背景错误分类为植被.DCED-MMA-CGU相较于其他3个经典网络取得了最好的分割效果,特别是在背景类别和建筑物类别上具有明显的优势.DCED-MMA-CGU包含遥感图像中的细节信息,可以更好地描绘目标物体的轮廓.

图7 Jiage数据集上PSPNet、CCNet、MagNet和DCED-MMA-CGU的局部视觉对比结果Fig.7 Local visual comparison results of PSPNet, CCNet, MagNet and DCED-MMA-CGU on Jiage dataset
4 结 语
针对遥感图像语义分割任务中目标物体之间的巨大尺度差异导致小尺度物体分割精度低的问题,提出多尺度互注意力与指导上采样网络.该网络包括1个多尺度互注意力模块和1个编码指导上采样模块.MMA通过不同尺度的图像输入和互注意力机制,在像素级层面上捕获大尺度物体与小尺度物体之间的全局关系,提升对小尺度物体的关注度.CGU在上采样过程中引入细节信息,使得上采样的过程具有可学习性.在2个数据集(Potsdam和Jiage)上,开展消融实验和对比实验.实验结果表明,在相同的实验条件下,利用提出的方法提高了对小尺度大物体的分割精度,整体效果优于8种最新的网络.随着具体应用越来越依赖于遥感图像处理的实时性,未来可以在不影响分割精度的同时,减少网络的参数量,构建轻量级网络,提高遥感图像的处理速度.
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
太空探索(2016年5期)2016-07-12
新校长(2016年8期)2016-01-10
时代英语·高三(2014年5期)2014-08-26
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
新课程学习·中(2013年3期)2013-06-14
