
水利工程文本中抢险实体和关系的智能分析与提取
2023-08-23 07:54杨阳蕊朱亚萍刘雪梅陈思思李慧敏
水利学报 2023年7期
杨阳蕊,朱亚萍,刘雪梅,2,陈思思,李慧敏
(1.华北水利水电大学 信息工程学院,河南 郑州 450000;2.黄河流域水资源高效利用省部共建协同创新中心,河南 郑州 450000;3.华北水利水电大学 水利学院,河南 郑州 450000)
1 研究背景
水利工程抢险措施是防汛应急预案的重要组成部分[1]。关于险情抢护的一系列知识散乱分布在各种无结构的水利工程文本中,这些知识包括险情部位、连带险情、抢护方法、所需材料等[2],本文称这些为水利工程抢险实体。这些实体之间的关系也同时包含在文本描述中。例如:“横向裂缝处理采用横墙隔断法”,这个关系表达了出现“横向裂缝”要采取“横墙隔断法”进行处理。“当无法在临河堵漏时采取背水坡导渗排水”这个关系表达了“临河堵漏”和“背水坡导渗排水”的功能是相似的。这些实体和关系一旦被提取出来,就可以组织成三元组和知识图谱的结构化形式[3],进而为应急预案智能生成、数字孪生[4]等任务提供结构化知识支撑。
有关研究已经开发了工程文档智能管理方法以实现工程文本维护[5-6]。关于对文本内容智能提取的研究,例如将Attention融入CBOW模型提取水利水电工程专业词[7],采用BILSTM+CRF识别水网实体[3],将Word2vec与TFIDF相结合进行水利工程质量监督文本特征提取[8],这些研究主要集中在单一实体的提取,但只有实体无法表达出实体与实体之间的语义关系[9]。从非结构化文本中提取关系三元组的现有方法主要有两种,一是基于规则或模式匹配的方法[10-12],此方法需要人工观察所有语句的描述模式并制定适应所有语句的匹配规则,水利工程文本中语句表达的多样性,使得人工总结出适应所有句型的规则变得困难;二是基于序列标注的方法[13-15],该方法使用传统深度学习模型进行实体抽取和关系抽取,需要大规模标注样本完成模型从无到有的训练[16],而各个专业领域的信息抽取研究普遍存在标注样本稀缺问题,传统深度学习模型不具备先验知识,训练样本类型的局限性导致模型所能处理的问题类型有限。手工为大量语句标注实体和关系存在着巨大的人力成本,且远程监督获取标注数据的方法[17]需要现存知识库这一前提,在水利工程抢险任务上并不满足。2017年Transformer[18]的提出带来了ERNIE[19]、T5[20]等大型预训练语言模型,预训练+小样本微调的迁移学习思想在垂直领域的关系抽取任务上得到了广泛关注[21]。
为了减轻传统方法带来的人力成本,本文将水利工程抢险实体和关系抽取视为从序列到序列的生成任务,提出了一种使用大型预训练语言模型(T5-v.1.1-large)联合提取水利工程抢险实体和关系的方法。与传统深度学习模型不同,T5是Google利用其搜索引擎上浩如烟海的开放域语料完成预训练并开源的语言模型[20],存储了大量先验知识,可以作为现实世界实体和关系的神经知识库[22]。此外,T5可以提供更好的模型初始化和强大的学习能力[23]。通过使用一小组任务相关的训练数据对T5进行微调,通用语义信息结合水利工程抢险领域语义信息,也即是预训练(通用信息)+微调(领域信息)的最新范式,可以使T5具有识别出当前语句中存在的水利工程抢险实体和关系的能力。例如:“每隔10分钟巡视一次,同时,对滑坡处24小时看护”,句子中通用时间信息(10分钟、24小时)与水利工程抢险领域知识(巡视、滑坡处)结合,可提取出“隔10分钟巡视”与“滑坡处24小时看护”的完整实体,并通过语义分析出二者之间的“协作”关系,从而得到意思表达完整的〈隔10分钟巡视,协作,滑坡处24小时看护〉三元组结构化知识。此外,当使用一小组任务相关数据激活大模型对水利工程抢险知识的认知后,T5具有先验知识的优势在提取非连续实体时表现尤为明显。例如:“库区出现漂船、漂木等难以通过泄洪道的漂移物体”,句子中并列语义结合“库区、漂移物体”等领域信息,可提取出“库区漂船、库区漂木”这些在传统方法中难以提取的非连续险情实体。在近期通用信息抽取(UIE)[24]工作的启发下,本文采用了将实体和关系进行联合抽取的统一框架。然而,UIE中的T5面对复杂句子,尤其是包含多种实体类型和关系的冗长且模棱两可的句子时会出现错误,因为它只使用包含所有关系类型的静态提示序列来指导T5识别出输入语句中的目标实体和关系。当面对复杂句子时,需要识别的关系类型越多,它所遭受的噪音就越多。针对静态提示的噪声问题,本文受提示调整方法[25]启发设计了动态提示生成器,它根据实际输入语句中潜在的少量关系为当前输入语句生成动态提示,而不是对所有句子都使用相同的静态提示。由于动态提示缩小了提示范围,过滤掉了造成干扰的关系类型,降低了噪声,因此可以提高水利工程抢险实体和关系的提取精度。融合“联合抽取”和“动态提示”思想,设计了水利工程抢险实体和关系联合抽取框架——WRERJE,它由动态提示生成器和实体关系联合抽取器两部分组成。动态提示生成器的内核是基于预训练掩码语言模型(BERT)[26]的文本分类器,用于对输入语句进行预分类,每一个类别代表水利工程抢险实体之间的一类关系。动态提示生成器根据当前语句中潜在的前N个关系生成动态提示序列,将此序列输入到由T5实现的实体关系联合抽取器中。针对水利工程抢险领域标注样本稀少问题,本文采取基于依赖动词替换和基于随机插入的方法进行领域数据增强[27-28],以获得相对多的标注样本来提升模型鲁棒性[29]。最后以水库防洪任务中的堤防和大坝等水利工程文本为主要实验数据,通过实验对WRERJE性能进行测试,同时评估了两种文本数据增强策略的有效性。
2 领域知识建模
2.1 初始语料收集本文以堤防防汛抢险手册、水利工程施工技术要点、近20个水库的防洪预案文本作为初始数据源。所需的目标语句为水利工程抢险领域的非结构化文本描述,首先对文本中存在的冗余描述进行段落级筛选,利用PyLTP对筛选后得到的目标段落以句号为分隔符进行分句处理。为了确保所得句子的有效性,对其进行句子级别的二次处理,处理指对于以句号分隔后仍然过长的句子,以句子中的逗号为分隔符做二次分句,并过滤掉与水利工程抢险知识无关的描述。处理后的目标语句都是长度适中,且与水利工程抢险知识相关的描述。
2.2 数据模式定义垂直领域数据模式(Schema)的定义需要依赖领域专业知识[30]。水利工程抢险任务涉及到的实体类型定义为“部位、险情、方法、物料”,观察目标语句中的语义描述,定义出这些实体类型之间潜在的6种关系类型。
“现象”关系类型,即某一工程部位出现了某种险情,则将部位类型与险情类型之间定义为“现象”关系。
“连带”关系类型,即某一工程险情的出现可能会导致另一种工程险情的发生,则将此类险情之间定义为连带关系。
“采取”关系类型,即出现某一工程险情时需采取某种方法来进行抢护,则将险情类型与方法类型之间定义为采取的关系。
“功能相似”关系类型,即两种方法的功能是相似的,当实施第一种方法比较困难时,可用另一种方法替代去实现相同的功能,则将此类方法之间定义为功能相似的关系。
“功能协作”关系类型,即需要同时实施两种方法协作去完成一个任务,则将这类实体之间定义为功能协作关系。
“使用”关系类型,即在险情抢护过程中实施某种方法时需要使用某种物料,则将方法类型与物料类型之间定义为使用关系。
以上关系类型的语句实例如表1所示。

表1 各关系类型实例
3 WRERJE框架原理及主干模型训练
根据信息抽取任务端到端结构生成思想,将异构的水利工程抢险实体抽取和关系抽取任务统一建模为序列到序列生成任务[31],并提出了一种使用动态提示的水利工程抢险实体和关系联合抽取框架——WRERJE。该框架使用“编码-解码(E-D)”思路进行工作,包含两部分核心组件组成,分别是动态提示生成器和实体关系联合抽取器,如图1所示。动态提示生成器结合预先定义的schema为当前输入语句生成动态提示序列,动态提示序列引导实体关系联合抽取器从当前输入语句中同时抽取出水利工程抢险实体和关系。
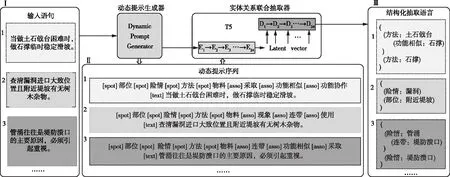
注:图中E1,E2,E3,…,E24与D1,D2,D3,…,D24分别为24层编码与24层解码。图1 WRERJE总体框架
3.1 动态提示生成器
3.1.1 动态提示序列组成 动态提示序列由实体类型和关系类型结合当前输入语句共同构成,实体类型、关系类型与输入语句的标识分别定义为[spot]、[asso]与[text],三类组成部分分别由相应标识进行标注。例如,“[spot]部位[spot]险情[spot]方法[asso]现象[asso]采取[text]坝顶若有漫溢危险时,应及时抢筑子埝”,其中由[spot]标注的“部位、险情、方法”指实体类型,[asso]标注的“现象、采取”指发生部位与险情之间的现象关系,以及险情与所用方法之间的采取关系。一个输入语句中有可能包含多种关系,动态提示序列能够指导抽取器同时抽取句子中存在的多个关系三元组。注意,例子中只展示了Schema中定义的部分实体类型与关系类型。在实验部分第一个基准模型WRERJEw/oDP的实际输入中,提示序列应包含2.2节定义的Schema中全部关系类型。
3.1.2 动态提示序列生成 通常情况下,一个输入语句中不会同时包含全部的关系类型。静态的提示序列包含Schema中定义的所有关系类型,关系类型越多,实体关系联合抽取器接收到的噪声就越多。这对确定输入语句中包含的水利工程抢险实体属于哪类关系造成了干扰,在面对较长且表达模糊的句子时干扰更为严重。因此,通过动态提示去缩小提示范围,更具有指导意义。如图1(Ⅱ)所示,动态提示序列只包含当前输入语句中最可能存在的前N个关系类型,前N个关系类型通过动态提示生成器确定。
动态提示生成器的内核是基于Bert的文本分类器[32],因为Bert中CLS标记的隐藏向量可以更好的表示句子特征,将该向量输入线性分类层,得到所有关系类别的概率P,选取前N个关系类型为当前输入语句生成候选关系列表。基于Bert实现的动态提示生成器如图2。动态提示序列生成过程可表示为:
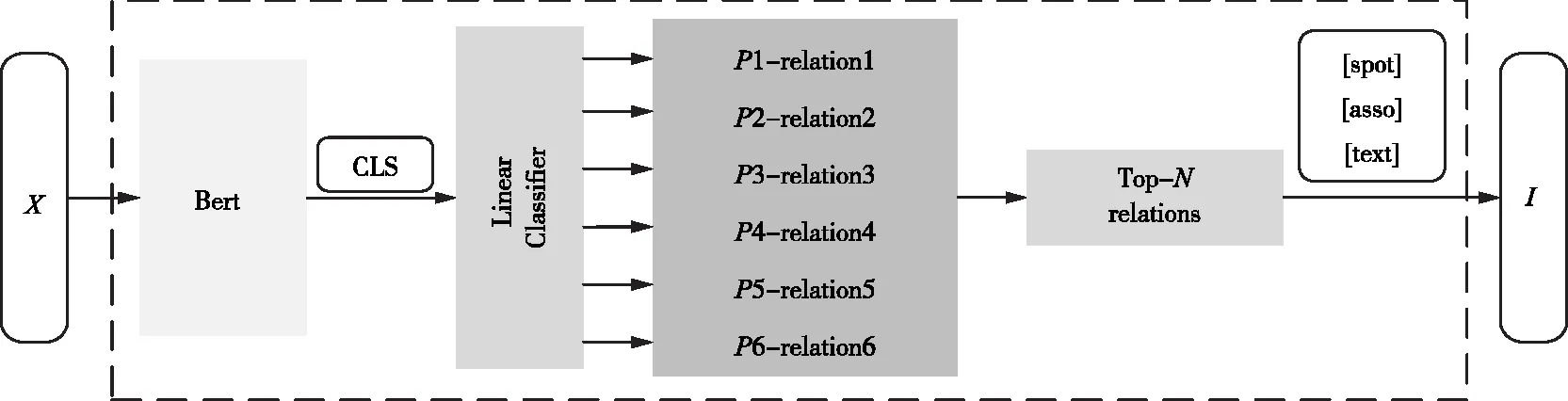
图2 动态提示生成器
DG([x1,x2,…,xx])=[I1,I2,…,II]
(1)
式中:DG为动态提示生成器(函数);X=[x1,x2,…,xx]为当前输入语句;[I1,I2,…,II]为生成的动态提示序列,其具体形式可表示为:
(2)
式中:entitytype为实体类型;relationtype为关系类型。
动态提示生成器旨在缩小指导范围并提供有可能的候选关系列表,而不做最终关系类型的确定。若当前语句中包含的水利工程抢险实体之间不存在关系,抽取器并不会从不正确的候选关系类型中盲目选择,并强制附加到实体。例如图1(I)2语句,即使动态提示生成器为该语句生成了“现象、连带、使用”的候选关系列表,但该语句中包含的险情“漏洞”和部位“附近堤坡”之间并不存在实际关系,抽取器不会为之强制附加关系。过多的候选关系依旧会造成干扰,过少的候选关系则很可能过滤掉正确的关系类型,因此选取合适的N是动态提示生成器的关键。
3.2 实体关系联合抽取器
3.2.1 结构化抽取语言 异构任务编码成统一表示形式是将实体和关系进行联合抽取需要解决的问题之一。采用一种结构化抽取语言(Structured Extraction Language,SEL)[24],将实体抽取任务和关系抽取任务的结构编码成统一表示形式,从而可以在序列到序列的生成框架中统一建模异构的水利工程抢险实体抽取和关系抽取任务。输入序列指动态提示序列,生成序列指SEL。SEL序列是由“Spot Name、Asso Name、Info Span”三种元素组成的层次结构,来对不同信息抽取任务的结构进行编码。其中“Spot Name”表示实体类型,“Asso Name”表示关系类型,“Info Span”表示特定类型下的实例对象。实例如图3。
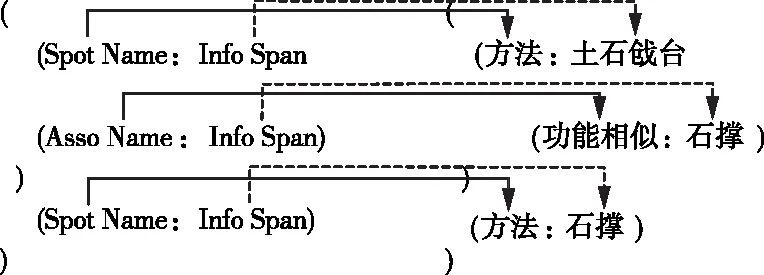
图3 结构化抽取语言图示
3.2.2 SEL序列生成 水利工程抢险实体和关系联合抽取器是一个序列到序列的生成框架,生成过程可表示为:
ERJE([I1,I2,…,II])=[y1,y2,…,yy]
(3)
式中:ERJE指实体关系联合抽取器,由基于Transformer的T5实现;I=[I1,I2,…,II]为输入的动态提示序列;Y=[y1,y2,…,yy]为生成序列,即包含水利工程抢险实体和关系的SEL序列。在WRERJE框架中,将动态提示生成器所生成的序列I输入到T5中,由T5生成Y序列,从而获得水利工程抢险实体和关系的三元组知识。
总的来说,WRERJE使用“编码-解码”思路进行工作。具体为将动态提示序列I输送到T5,由T5计算I=[I1,I2,…,II]的隐向量H,计算过程可表示为:
H=Encoder(I1,I2,…,II)
(4)
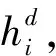
(5)
式中Dncoder即解码器,是Transformer架构中的Dncoder模块,用于预测yi的条件概率P,概率P的具体表达式为:
P=P(yi|y1,y2,…,y(i-1),I)
(6)
式中:y1,y2,…,y(i-1)为前i-1个输出;I为输入到T5的动态提示序列。
3.3 主干模型训练
3.3.1 数据预处理 根据2.2节中定义的Schema对收集到的目标语句进行标注,标注的同时进一步验证句子是否准确包含水利工程抢险实体以及实体间语义关系。标注时不要求每个句子中实体之间都必须包含关系,只要该句子包含水利工程抢险相关实体,即认为该句子可用。标注员明确具有水利工程抢险领域的专业知识,可以对语句中是否含有水利工程抢险相关实体及语义关系进行验证并识别。为保证数据标注的一致性,将6名标注员分为3组,每组内2名标注员标注相同的句子。在标注完成之后由2名作者来处理标注结果的冲突,使用kappa系数来衡量结果一致性,计算kappa系数值为0.837,即认为标注结果几乎一致[33]。最终得到1652条有效标注样本,其中247条只包含实体,实体间不存在语义关联,1405条包含实体同时实体间具有语义关系。
3.3.2 数据增强 规范的标注数据集让WRERJE学习到普通情况下水利工程抢险实体与其语义关系特征。由于汉字的多义性和文字输入的随机性,非正式的水利工程抢险文本难免存在随机错别字或描述模糊等噪声现象。为了提高WRERJE从噪声数据中识别目标实体及其语义关系的能力,设计了两种文本数据增强策略以增加训练数据中的噪声数据,提升模型的鲁棒性。
(1)依赖动词替换。使用PyLTP来定位语句中的动词,然后用同义词替换这些动词。例如在“可用棉被顺坡铺盖”中,将“铺盖”替换为“覆盖”,在“上面再压土袋”中将“压”替换为“堆”。这些替换并不会改变句子语义,因此可以基于此方式获得同一关系类型的更多不同的描述,使WRERJE学习到更多样的特征。
(2)随机插入。基于随机插入的数据增强方式本质是在规整的数据集中加入一定的噪声。首先定位语句中的一个词,然后将这个词的同义词插入到语句中的随机位置。此方法可获取更多描述模糊但实体和关系均正确标注的语句,学习此类语句可使WRERJE拥有从模棱两可的句子中准确识别出水利工程抢险实体和关系的能力。
将1652条有效标注样本,以7∶3的比例划分,得到1159条语句作为初始训练集,493条语句作为初始测试集。将以上文本数据增强策略分别应用于初始训练集和初始测试集,两种数据集分别进行增强以确保突变前后的语句在同一类数据集中,防止发生数据泄露[34]。经过增强策略后得到包含3471条语句的最终训练集和包含1485条语句的最终测试集。最终训练集用于微调T5,最终测试集用于测试微调后T5的性能。此外,从最终训练集中选择包含实体且实体间具有语义关系的2953条语句作为分类器训练集,从最终测试集中选择包含实体且实体间具有语义关系的1265条语句作为分类器测试集。
3.3.3 基于Bert的分类器训练 将Schema中定义的6种关系建为语句上的6个离散标签,基于Bert的分类器进行句子级预分类,得到每个输入语句最可能的N种关系类型,动态提示生成器根据N种关系类型生成相应的动态提示序列。
分类器由Bert结合线形层组成。存在6种关系类型,线性层的输出维度设置为6。使用分类器训练集对分类器进行训练。将语句作为Bert的输入,从CLS字段中获得隐藏向量VL,从CLS中获取的隐藏向量VL相比其他位置能更好的表征句子特征,从而获得更好的分类性能。然后将VL输送到线性层中,该线性层生成6维向量,每个维度各对应一个关系类型。在反向传播中,使用交叉熵损失调整Bert与线性层参数。损失函数为:
(7)
式中μ=(μ0,μ1,…,μr-1)表示线性层的输出结果,r为句子的真实标签。
3.3.4 基于T5的联合抽取器微调 WRERJE框架的设计思想是将抽取任务视为序列到序列的生成任务,生成式语言模型T5被证实具有捕获丰富语义信息的能力[35],并且在各种下游NLP任务中表现出了良好的性能。本文的抽取器基于大型预训练语言模型T5(T5-v1.1-large)实现。
为了微调T5,将最终训练集中的每个句子转换为SEL序列,将其输入动态提示生成器以获取动态提示序列I,最后构建带标签的语料库:De={(I,y)},在带标签的语料库上,使用学习率为10-4的Adam优化器和教师强制(teacher-forcing)交叉熵损失,损失函数为:
(8)
式中θe、θd分别为编码器和解码器参数。
4 实验设置
4.1 数据集数据集共有3组,第1组为由标注员标注出水利工程抢险实体和相关语义关系的初始数据集,其中247条只包含实体,1405条同时包含实体和关系。第2组为应用了两种文本数据增强策略之后的最终数据集,其中741条只包含实体,4218条同时包含实体和关系。第3组为从最终数据集中选择的同时包含实体和关系的4218条分类器数据集。3组数据集的训练集和测试集比例为7∶3,具体如表2。
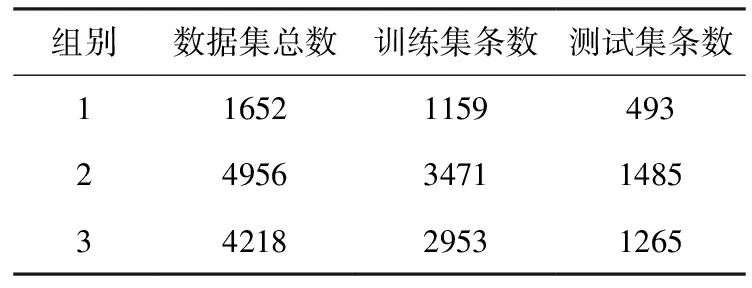
表2 数据集设置
4.2 动态提示关系类型最佳数目N的选择如3.1.2节所述,给定输入句子,动态提示生成器使用基于Bert的分类器对当前输入句子进行预分类,以生成一组候选关系列表,然后将其封装进动态提示序列中以引导随后的实体关系联合抽取器。此实验的目的是确定动态提示中应包含的关系类型的最佳数目N,即多少种候选关系类型可以为实体关系联合抽取器提供最有效的提示。
4.3 数据增强策略的有效性检验为了减少人工标记工作并改善模型训练,设计了如3.3.2节中所述的两种数据增强策略。通过实验检验,经两种数据增强策略获得的描述模糊但标注正确的语句是否可以提高WRERJE对水利工程抢险实体和关系的抽取能力,以验证两种数据增强策略的有效性。
4.4 基准模型对比实验设置
4.4.1 动态提示有效性检验 WRERJE框架的设计使用了“动态提示”方法。因此,将动态提示方法与静态提示方法进行对比,以检验WRERJE工作的有效性。有效的动态提示由最合适的N种关系类型组成,将其与包含全部关系类型的静态提示进行实验对比。为此,实现了一个使用静态提示的基准模型WRERJEw/oDP。
4.4.2 联合抽取的有效性检验 单任务抽取指分别进行水利工程抢险领域的实体抽取任务与关系抽取任务。WRERJE是将实体抽取任务和关系抽取任务统一建模的多任务框架,为验证联合抽取的有效性,实现了第二个基准模型WRERJEsingle,它将水利工程抢险实体抽取和关系抽取分离为两个独立的任务,定义特定于独立任务的Schema,仅针对单一任务对模型进行微调。对于水利工程抢险实体抽取任务,Schema中只含“部位、险情、方法、材料”4种实体类型。对于水利工程抢险关系抽取任务,Schema中只含“现象、连带、采取、功能相似、功能协作、使用”6种关系类型。WRERJEsingle进行关系抽取任务时,依然采取动态提示,即选择Schema中最佳的N种关系类型作为提示。最后将实体识别的结果与关系抽取的结果合并作为最终结果。例如,从“输水洞洞身存在未处理的裂缝”语句中识别出的实体有“输水洞洞身”和“裂缝”,从中抽取出的语义关系“现象”,将其合并为(输水洞洞身,现象,裂缝)作为最终三元组。
4.4.3 大型预训练语言模型先验知识的有效性检验 WRERJE框架中联合抽取器的主干模型为T5-v.1.1-large,为验证大型预训练模型所具备先验知识的有效性,设计了第三个基准模型WRERJEbase,它用轻量级T5-v.1.1-base模型作为联合抽取器,依然使用动态提示。将WRERJE与WRERJEbase同在第二组数据集上进行训练与测试,以验证大型预训练语言模型的先验知识对抽取性能的影响。
5 实验结果
5.1 动态提示关系类型最佳数目N的选择结果依次选取1到5中的每个数字作为动态提示生成器中候选关系类型的数目进行实验,每次实验均使用第2组数据集对WRERJE进行微调,且在同一测试集下进行测试。不对N=6进行检验,因为N=6本质上等同于将所有关系类型都封装进提示序列的静态提示。不同N值的实验结果如表3。
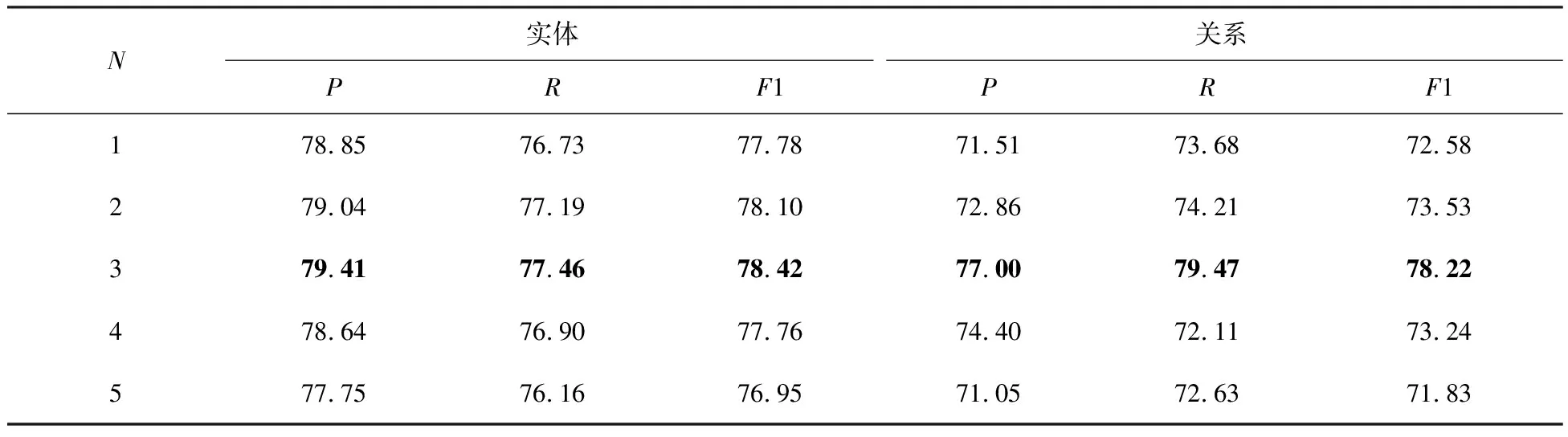
表3 不同N值的实验结果
表中P为精确率(识别正确实体关系数量与识别实体关系总数量之比)、R为召回率(识别正确实体关系数量与总实体关系数量之比),F1为二者的调和平均值,以F1为主要评价指标;实验结果表明更改N值对模型进行实体识别影响较小,因为N表示动态提示中关系类型的数量,它不直接影响实体的识别。在N=3时,WRERJE达到水利工程抢险实体识别的最佳性能,此时F1值为78.10。对于关系抽取,更改N值对P和R都有较明显的影响。从N=1开始,随着N值增加,关系抽取的P和R都会提高,直到N=3。当N=3时,WRERJE的P、R和F1值均达到最高值。为了更直观展示更改N值对WRERJE进行关系抽取性能的影响,图4以折线图的形式展示了不同N值下实体和关系抽取任务中F1值的变化趋势。
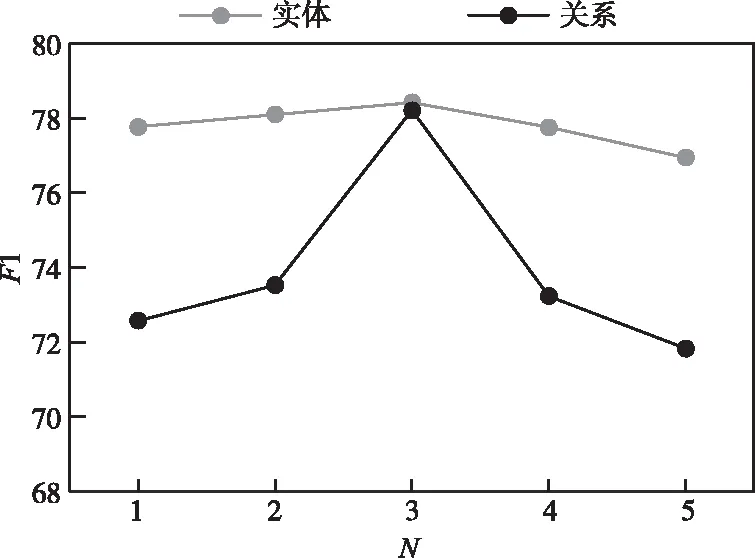
图4 不同N值下F1指标的变化趋势
实验结果表明动态提示序列中关系类型最佳数目为3。正如3.1.2节中所述,动态提示生成器不做最终关系类型的确定,只为联合抽取器提供一个候选关系列表。当N小于3时,WRERJE在关系提取任务上的F1值偏低,是因为范围过小的提示可能会遗漏正确的关系类型。例如“非正常渗漏导致坝体、坝基发生管涌、流土或脱坡”语句,分类器预测的前3个候选关系列表为“现象、功能相似、连带”。当N=2时,处于列表中第三个位置的“连带”关系会被分类器忽略。导致抽取器不能正确抽取出“非正常渗漏”与“管涌、流土、脱坡”之间的连带关系。
反之,当N大于3时,由于候选关系列表范围太大,包含过多不正确的关系类型,噪声数据给联合抽取器造成误导,使其在关系抽取上的F1值偏低。综上,动态提示关系类型最佳数目为N=3。
5.2 数据增强策略的有效性检验结果设计WRERJEwda和WRERJEw/oda两种场景以进行数据增强策略的有效性检验,WRERJEw/oda在第1组未经增强的训练集上接受训练,WRERJEwda在经过数据增强后的第2组训练集上进行训练。WRERJEwda和WRERJEw/oda最终都在第2组测试集上进行测试。实验结果如表4所示。

表4 数据增强策略对WRERJE性能的影响
实验结果显示,在水利工程抢险实体抽取上,WRERJEwda的精确率、召回率和F1值分别为79.41、77.46和78.42,经过数据增强策略后的训练集在实体抽取上的F1值比WRERJEw/oda模型提高了约2.96。在水利工程抢险关系抽取上,WRERJEwda的精确率、召回率和F1值分别为77.0、79.47和78.22,各项指标均显著高于WRERJEw/oda。WRERJEw/oda采用了未经增强的第一组训练集进行训练,模型只学习到了普通情况下的数据特征,因此模型鲁棒性不如WRERJEwda。以上结果证实了使用一些描述模糊但标注正确的句子对模型进行微调有利于提升WRERJE对正确和非正确实体与关系的区分能力,验证了数据增强策略的有效性。
5.3 基准模型对比实验结果将WRERJE与三种基准模型WRERJEsingle、WRERJEw/oDP和WRERJEbase进行对比,以检验动态提示、联合抽取与大型预训练模型先验知识的有效性。基准模型有关配置如4.4节所述,所有模型均在第2组数据集上进行训练和测试。各模型性能对比实验结果如表5。

表5 基准模型性能对比实验结果
从表5中可以看出WRERJE对于实体抽取的各项指标均高于基于静态提示的WRERJEw/oDP模型和基于轻量级T5-v.1.1-base的WRERJEbase模型,WRERJE对于实体抽取的F1值仅比最佳模型WRERJEsingle略低0.27,但WRERJE对于关系抽取的F1值比WRERJEsingle高出6.88。实验结果表明,大型预训练语言模型(T5-v.1.1-large)具备的通用语义信息结合了水利工程抢险领域语义信息后,能够使WRERJE在该领域实体和关系联合抽取上表现出较WRERJEbase更优的性能。动态提示对水利工程抢险实体抽取影响不大,但是可以显著提高对抢险关系抽取的能力。将实体抽取和关系抽取任务联合对预训练语言模型进行微调比仅针对单一任务进行微调更有效。联合抽取和动态提示使得WRERJE可以取得较之其他基准模型更优的表现。
以某省20个水库防洪预案文本为抽取对象,将WRERJE最终生成的SEL序列转化为三元组,各关系类型部分三元组实例如表6。
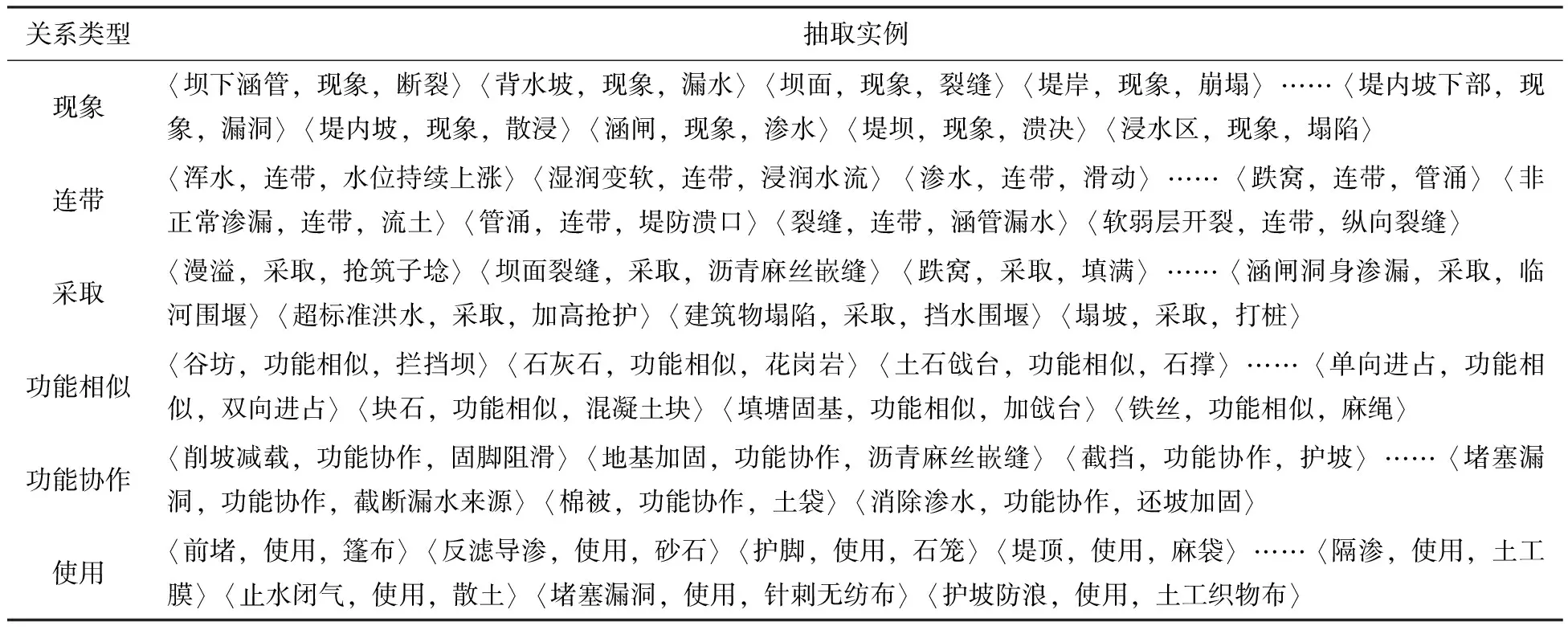
表6 部分三元组实例展示
6 结论
本文将异构的水利工程抢险实体抽取和关系抽取任务制定为序列到序列的生成任务,使用水利工程抢险领域数据微调预训练语言模型T5来进行领域内实体和关系的联合抽取;提出动态提示方法,设计了动态提示生成器。基于此提出了使用动态提示引导T5以进行目标领域内实体和关系联合抽取的WRERJE框架,用来从水利工程抢险领域的非结构化文本描述中同时抽取实体和关系。通过将WRERJE与三个基准模型进行实验对比。结果表明,WRERJE通过微调之后在水利工程抢险实体和关系联合抽取任务上具有较高的抽取精度,验证了“联合抽取”和“动态提示”的有效性。
本文以从无结构水利工程文本中同时提取出抢险实体和关系,并将其组织成三元组结构化形式,以支撑应急预案智能生成任务为出发点。目前工作基本实现了实体和关系的智能抽取,但还存在两点主要问题需进一步研究与改进。一是实验数据中水利工程类型覆盖不充分;二是数据模态单一。主要以堤防和大坝为主要实验对象(考虑其在防洪抢险任务中的基础性与重要性),在使用描述堤防和大坝等工程抢险措施的文本激活T5对领域知识的认知后,其可以在一定程度上处理其他工程类型中具有相似描述的文本。下一步工作将通过实验测试WRERJE在其他工程类型的文本中抽取目标实体和关系的准确率;同时丰富数据形态,利用“图生文”技术将水利工程抢险领域的视频、图像等转化为自然语言描述,结合图像理解技术开展多模态的抢险知识抽取研究。未来可将其应用到任何需要进行水利工程抢险实体关系抽取的工作中,构造以水利工程抢险为主题的多模态的知识库与知识引擎,推进水利工程险情抢护的高效化与智能化。
猜你喜欢
新世纪智能(语文备考)(2020年4期)2020-07-25
水利建设与管理(2020年5期)2020-06-18
水利规划与设计(2020年1期)2020-05-25
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
水利水电工程设计(2017年1期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中国水利(2015年4期)2015-02-28
语文知识(2014年4期)2014-02-28
