
基于CEEMDAN-Transformer的灌浆流量混合预测模型
2023-08-23 07:51任炳昱王佳俊
水利学报 2023年7期
李 凯,任炳昱,王佳俊,关 涛,余 佳
(天津大学 水利工程仿真与安全国家重点实验室,天津 300072)
1 研究背景
灌浆流量、压力和密度等参数的实时监控对于灌浆质量控制意义重大[1-2]。其中灌浆流量是进行优化灌浆过程控制的基础。然而由于地质条件的多样性和未知性,灌浆流量、压力和密度参数存在较大波动大的问题,同时灌浆流量、压力、密度质之间耦合关系复杂,因此,实现灌浆流量的高精度预测难度极大。
在灌浆过程参数预测方面,相关学者进行了以下研究。李斌等[3]基于统计过程控制理论实现灌浆压力的报警,利用灌浆压力设计线、报警线等不同控制线实现了灌浆压力信息的提前预判。李凤玲等[4]利用当前时刻的阀门开度、浆液水灰比、地层吸浆量和灌浆压力,基于Back Propagation 神经网络(BP神经网络)和(Grey Model(1,1),GM(1,1))实现了下一时刻的灌浆压力的实时预测。郭晓刚[5]利用支持向量机算法实现了灌浆抬动的实时预测。在灌浆功率(注入率×灌浆压力)预测方面,王晓玲等[6]基于改进(Support Vactor Regression,SVR)算法实现了灌浆功率阈值预测。邓韶辉等[7]基于模糊信息粒化和灰狼算法改进的支持向量机实现了灌浆功率的时序预测。Xue等[8]利用小波变换对灌浆功率数据进行了预处理并且使用改进的Jaya算法对支持向量机进行优化,实现了灌浆功率的时序预测。在可灌性预测方面,EBRAHIM等[9]使用Q值、裂隙圆盘半径、节理分布、吕荣值、灌浆深度、灌浆压力和水灰比实现了可灌性的预测,预测方法选用多元线性回归和神经网络。YANG等[10]使用均值方法、线性回归方法和BP神经网络方法预测可灌性,预测指标包括岩层、大坝基础位置、孔段深度、灌浆压力和吕荣值。
然而,灌浆流量数据具有强非线性和强波动性的特点,给灌浆流量的精准预测带来了极大挑战。目前在非线性和波动数据的时序预测处理方面,相关研究[11]表明一种“先分解后集成”方法能够明显提高时序预测精度。这种框架的中心思想是将总体的预测指标分解为多个简单的分量,然后分别对分量进行预测,最后对预测的分量值进行集成形成最终的预测结果。“先分解后集成”的方法也广泛应用于能源价格预测[11],风速预测[12],荷载预测[13],生物信号处理[14],故障诊断[15],图像处理[16]等领域研究。当前研究主流的分解方法主要包括小波变换[17],可变模态分解[18]和经验模态分解[19]等。在经验模态分解算法的改进方面,整体EMD(Ensemble Empirical Mode Decomposition,EEMD),完整EEMD(Complete Ensemble Empirical Mode Decomposition,CEEMD),耦合自适应噪声的CEEMD(CEEMDAN)和改进的CEEMDAN(Improved Complete Ensemble Empirical Mode Decomposition with Adaptive Noise,ICEEMDAN)在信号分解方面变得非常流行[20]。通过这些分解方法,总体指标能够分解成多个变量,变量包括高频变量和低频变量,分别预测单个变量后集成相比直接预测整体变量能够提高时序预测精度。
在时序预测算法研究方面,卷积神经网络-长短时记忆网络(Convolutional Neural Network- Long Short-Term Memory,CNN-LSTM)算法作为先进的时序预测方法之一,相关学者进行了广泛研究[21-24]。MI等[21]利用经验模式分解和卷积支持向量机实现了风速的高精度预测;Bao等[17]提出了一种新的深度学习框架,通过组合小波变换(Wavelet Transform,WT)、堆叠式自动编码器和长-短期记忆网络(LSTM)实现股票价格的预测;FU等[22]提出了基于时变滤波器的经验模式组合框架分解、模糊熵理论、奇异谱分析、相空间重构、采用基于核的极限学习机的复合预测模型以及卷积长短时记忆网络以及基于突变和层次结构的混合模型以进行风速的精准预测;ZHANG等[23]提出一种融合经验模态分解、主成分分析和LSTM的组合模型以进行金融时序数据的预测;WANG等[24]提出了组合经验小波变换、随机继承公式纠错算法、深度具有变学习率的双向LSTM神经网络和Elman递归神经网络的混合模型,进行原油价格的预测。综上,CNN-LSTM时序预测方法能够对波动性较强(噪声较大)的时间序列进行有效预测,然而该方法无法有效反映时序测点的上下序列测点之间的关系,并且无法一次性输出多个预测测点数据。循环神经网络(Recurrent Neural Network,RNN)具有良好的处理上下文的能力,利用循环神经网络(RNN)等语言翻译算法在时间序列预测方面也表现出广阔的前景[25]。RAHMAN等[26]利用深度递归神经网络实现商业和住宅的用电量预测。XIANG等[27]利用LSTM-Based Sequence-to-Sequence算法实现24小时的降雨径流模型的序列预测。刘擘龙等[28]基于序列到序列和注意力机制实现超短期风速预测,利用CNN和门控循环单元(Gate Recurrent Unit,GRU)对编码层进行数据预处理。杜圣东等[29]基于序列到序列时空注意力学习实现交通流预测,利用ConvLSTM算法对编码层进行数据预处理。多输入和多输出预测模型研究方面,刘明辉等[30]提出高斯过程回归预测模型实现土石坝料压实特性的多输出预测。CHEN等[31]利用混合灰色动态关联模型通过水位、温度和时间实现大坝变形预测。
综上所述,由于灌浆流量数据存在强非线性和强波动性,灌浆流量预测难度较大。现有的灌浆流量预测存在的不足如下:传统神经网络模型对时间序列特征提取和加工处理不足,导致预测精度有限;传统神经网络模型测试集进行一次计算仅能输出一个结果,进行多个时间步预测需要繁杂的多次计算,单测点预测结果预测时间短并且无法反映灌浆流量序列变化的整体趋势,不利于灌浆流量控制和保障施工质量。针对上述问题,本研究提出基于CEEMDAN-Transformer的灌浆流量混合预测模型。
2 研究框架
研究框架如图1所示,基于现场灌浆记录仪与无线传输网络实现灌浆流量数据实时获取,以作为本研究输入参数。本研究提出基于CEEMDAN-Transformer的灌浆流量混合预测模型,主要方法包括CEEMDAN和多头注意力Transformer。
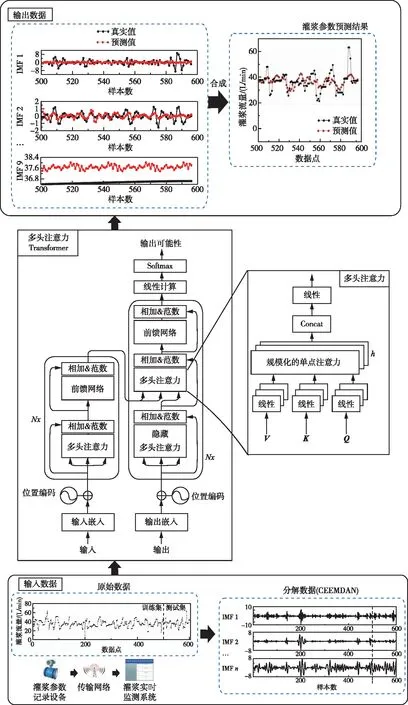
图1 研究框架
本研究采用CEEMDAN对实测灌浆流量进行经验模态分解,分解得到多个本征模函数IMF和残差信号。多头注意力Transformer通过堆叠式自注意力和前馈网络对循环神经网络(RNN)的网络结构进行改进,通过多头注意力机制来构建输入和输出的全局依赖关系,实现多个本征模函数IMF序列到序列的预测,最后通过对预测分量进行融合得到灌浆流量预测值。首先采用CEEMDAN对灌浆流量数据进行分解,分解得到多个IMF分量和残差分量。然后采用多头注意力Transformer对每个时序分量进行预测,通过多头注意力机制、前馈网络和线性计算实现每个分量序列到序列的预测。最后对多个预测的序列分量进行累加合成得到灌浆流量预测结果。基于CEEMDAN方法实现实测灌浆流量的本征模函数与残差信号的分解,解决灌浆流量数据的非线性与强波动的问题;采用多头注意力Transformer实现多个本征模函数IMF序列到序列的预测,采用多头注意力机制来构建输入和输出的全局依赖关系,有效提取动态时序特征,提升时间序列参数特征提取水平;建立时序测点多输入多输出模型实现灌浆流量预测,提升多输出序列计算效率,反映整体趋势的多输出序列能够为灌浆流量控制提供参考。
3 研究方法
3.1 CEEMDANCEEMDAN方法是主流的分解算法之一,在CEEMDAN中,添加高斯白噪声到每个分量中计算一个本征模函数IMF和残差信号。假设给定操作Ek(·),该操作通过EMD产生第k个IMF,CEEMDAN的介绍如下:(1)类似EEMD,CEEMDAN对原始数据(灌浆流量)进行分解并且获得第一个IMFc1和残差r1。(2)接下来第k个IMF(k≥2)和残差计算如下:
(1)
rk=rk-1-ck
(2)
式中:w(i)为第i个需要添加的高斯白噪声;Ek(w(i))为使用EMD对w(i)分解的第k个值;pk为增加的噪声和原始信号的信噪比。当算法残差rk满足终止迭代条件时算法终止,最终CEEMDAN能够计算IMFs和残差,其中残差公式如下:
(3)
式中:R为由CEEMDAN获得的残差;x为初始信号;K为IMFs的数目。
3.2 多头注意力本研究在seq2seq算法[32]的基础上建立了多头注意力Transformer时序预测算法,实现了序列到序列的预测。多头注意力Transformer在语言翻译领域开展了相关研究[33]。通过将多个时序测点作为输入,多个时序测点作为输出建立多输入多输出灌浆流量时序预测模型。
Transformer多数具有竞争力的神经序列传导模型都有编码器-解码器结构。编码器输入序列(x1,…,xn)映射到连续序列(z1,…,zn),对于灌浆流量的时序预测,利用CEEMDAN对灌浆流量进行分解得到分量IMF,分量IMF的序列作为输入序列和连续序列,给定z后,解码器同时生成集合(Y1,…,Yn)。在每个步骤中,模型都是自回归的,在生成下一个符号时,使用先前生成的符号作为附加输入。如图1所示,Transformer完全遵循这种整体架构,使用堆叠式自注意力、逐点方式和全连接层的编码器和解码器。对于前馈网络、输入输出嵌入、Softmax和位置编码的介绍详见文献[34]。
3.2.1 编码和解码器堆栈 对于编码器,一个堆栈由多个相同层组成。每层有两个子层。第一种是多头自注意力机制,第二种是简单的全连接前馈网络。在两个子层周围使用剩余连接,然后进行层归一化。为了促进这些残余连接,模型中的所有子层以及嵌入层生成维度为dmodel的输出。
对于解码器,一个堆栈由多个相同层组成。除了每个编码器的两个子层,解码器插入第三个子层,该子层执行编码输出的多头注意力机制。与编码器类似,围绕每个子层使用剩余连接,然后进行层归一化。对解码器堆栈中的子层的自我注意力机制进行修改以防止位置涉及后续位置。
3.2.2 注意力机制 注意力函数可以描述为一种从查询和键值对集到输出的映射,其中查询、键、值和输出都是向量。输出计算为加权和,分配给每个值的权重由的兼容函数进行计算,使用相应的键值进行查询。采用多头注意力机制来构建输入和输出的全局依赖关系,有效提取动态时序特征,提升时间序列参数特征提取水平。
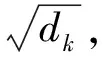
(4)
对于注意力改进的序列到序列算法,计算隐藏状态hj与解码时刻的相关性:
et,j=VT*tanh(WSt=1+Uhj),t,j=1,2,…,Ni
(5)
式中:tanh为激活函数;V、W、U为模型的训练参数。将et,j进行归一化后得到隐藏状态hj的权重at,j。动态语义向量的计算公式如下:
(6)
(2)多头注意力。注意力机制算法示意图如图2所示,规模化的单点注意力如图3所示。与包含键、值和查询的单注意力模型dmodel不同,将查询、键和值进行线性投影h次,分别到dk和dk、dv维度。在每个查询、键、值版本上提出并行注意力,产出了dv维度的输出值。将这些值串联并再次投影,产生最终的结果如图1所示。相比于单头注意力的优势,多头注意力能够允许模型去引入不同位置的表达信息。多头的注意力机制的计算如下[34]:
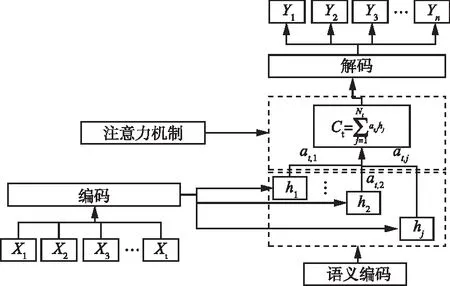
图2 注意力机制算法示意图
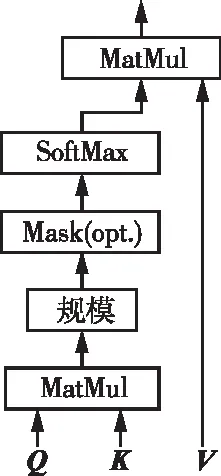
图3 规模化的单点注意力
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
(7)
(8)
Transformer以三种不同的方式使用多头注意力:(1)在“编码器-解码器注意”层中,查询来自前一个解码器层,存储键和值来自编码器的输出。这允许解码器中的位置覆盖输入序列中的所有位置。这模仿了序列到序列模型中的典型编码器-解码器注意力机制。(2)编码器包含自注意力层。在自注意力层中,所有键、值查询来自同一位置,编码器中的每个位置都可以关注编码器前一层中的所有位置。(3)解码器中的自注意力层允许解码器中的每个位置关注解码器中与该位置交互的所有位置。
4 工程应用
4.1 数据说明本研究选取中国西南地区的某混凝土双曲拱坝坝基作为试验地点,实时监控固结灌浆区域的灌浆压力、流量和密度参数。以固结灌浆5#坝段灌浆孔GJB5-4-1为例,监控的灌浆流量如图4所示。灌浆流量为进浆流量和出浆流量的差值,实时监控参数的采集间隔为5 s,测点数目为600个,前500个测点作为训练集,后100个测点作为测试集。数据窗口移动说明如图5所示,训练集数据每次整体移动的个数为输入序列加输出序列的数目,测试集每次移动的个数为输出序列的数目。
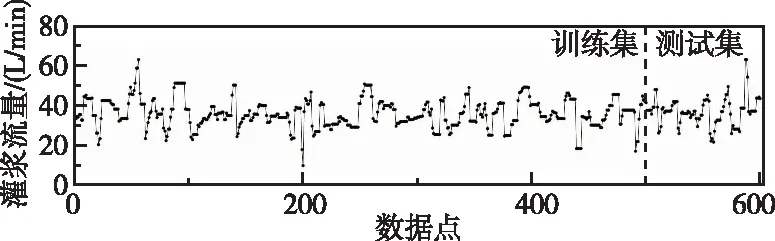
图4 监控灌浆流量数据说明
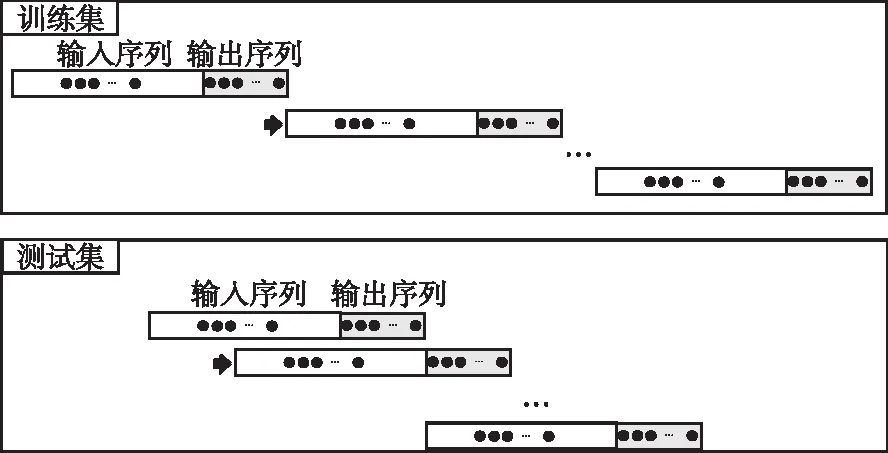
图5 数据窗口移动说明
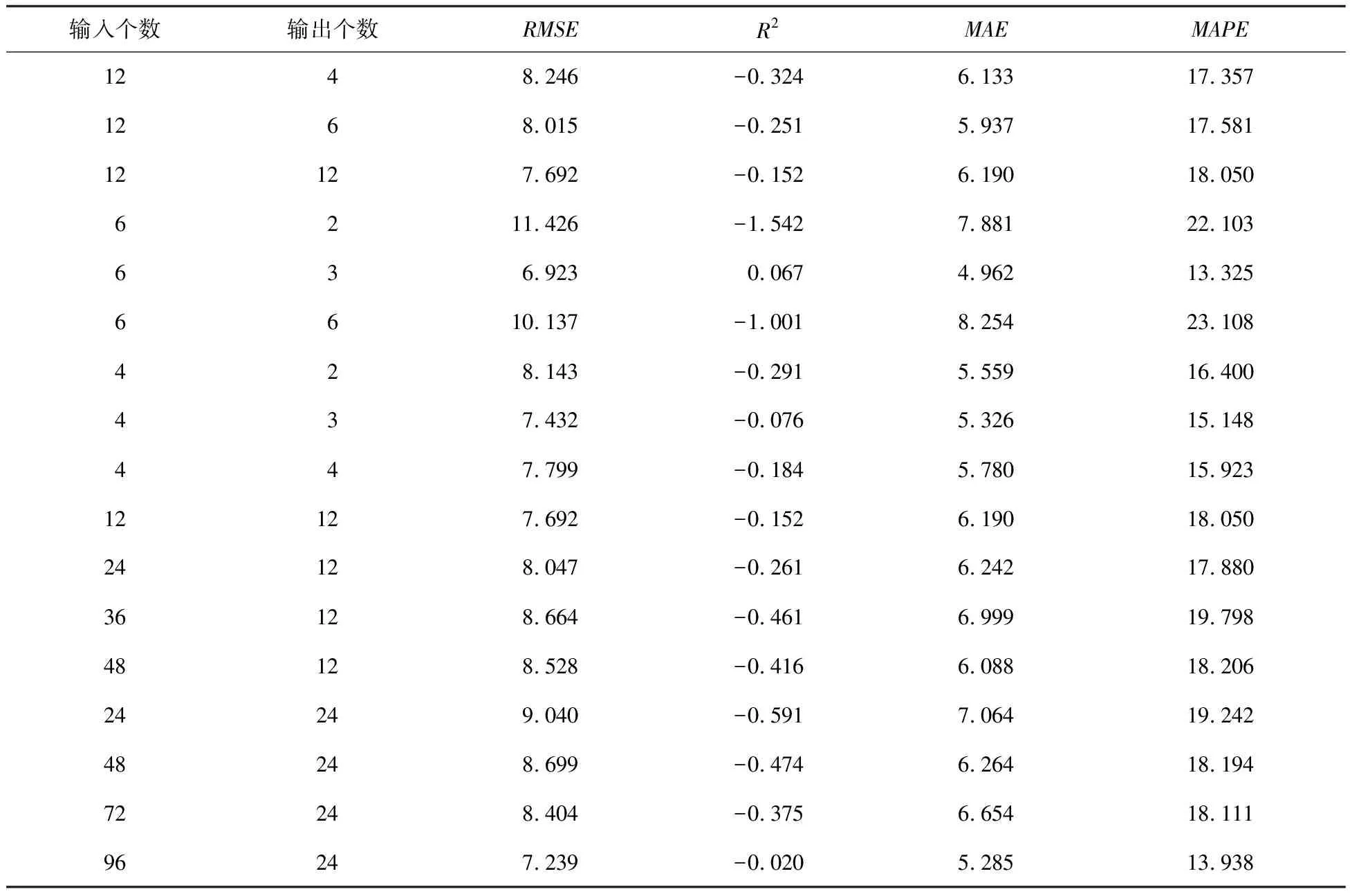
表1 不同输入和不同输出个数的算法预测精度对比
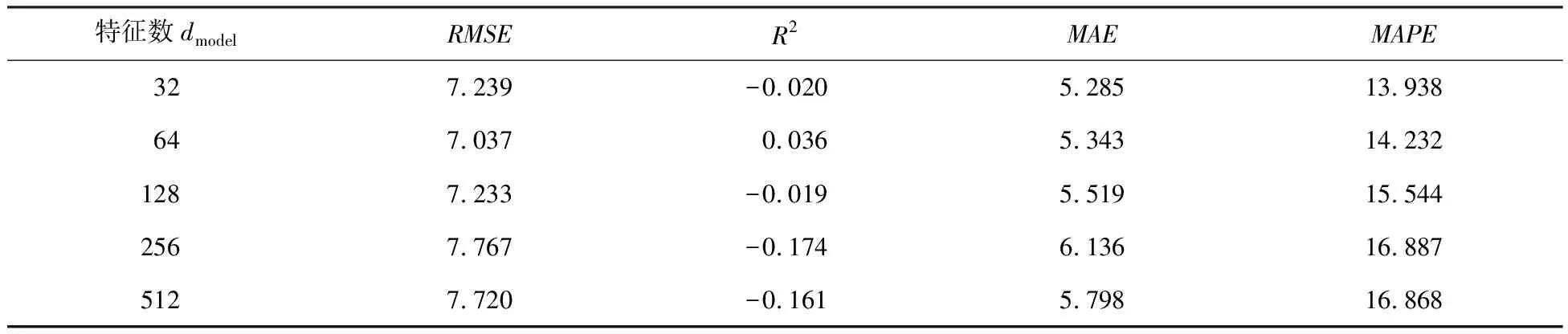
表2 不同特征数的算法精度对比
为了验证多头注意力Transformer算法灌浆流量预测的预测精度,如表3所示选取多种方法进行精度对比,seq2seq、单头注意力Transformer、多头注意力Transformer、CNN+多头注意力Transformer、Fuzzy C-Means(FCM)+CNN+多头注意力Transformer、FCM+多核CNN+多头注意力Transformer方法的输入个数都为96,输出个数为24,Random Forest(RF)、Support Vector Machine(SVM)、BPNN、Extreme Learning Machine(ELM)的输入个数都为96,输出个数为1,进行24次测试计算得到24个预测值。序列到序列seq2seq方法的参数设置如下,迭代次数为100,隐含层维度为64,输入维度为1,输出维度为1,堆叠层数目为2,梯度修剪值为2.5。单头注意力Transformer算法的注意力机制头数设置为1。CNN+多头注意力Transformer算法利用CNN对数据进行特征提取预处理,特征图的像素点尺寸设置为28×28,全连接层的标签值设置为10个,选用两层卷积和两层池化,卷积核的大小设置为5,池化层的尺寸设置为2×2,采用最大池化方案。FCM+CNN+多头注意力Transformer算法在CNN+多头注意力Transformer算法的基础上利用Fuzzy C-Means(FCM)聚类算法[35]对时序测点进行聚类后进行特征提取。FCM+多核CNN+多头注意力Transformer算法在FCM+CNN+多头注意力Transformer算法的基础上采用卷积核尺寸进行特征提取,然后将利用不同卷积核提取的特征值进行拼接得到20个全连接层标签。利用CEEMDAN方法对流量数据进行分解的结果如图6所示,参数设置如下:高斯白噪声(Nstd)=0.2,加入噪声次数=500,最大迭代次数(MaxIter)=5000。灌浆流量分量IMF1,IMF2,IMF3,IMF4,IMF5,IMF6,IMF7,IMF8,IMF9和残差的皮尔逊相关性分别为0.289,0.420,0.547,0.683,0.504,0.351,0.248,0.191,0.164,-0.010。由于残差与灌浆流量的相关性较低,残差分量不参与灌浆流量的预测分量。利用CEEMDAN’方法[36]对灌浆流量进行分解,参数设置如下:高斯白噪声(Nstd)=0.2,加入噪声次数=500,最大迭代次数(MaxIter)=5000。随机森林算法树数目设置为100,树节点分裂变量设置为2。支持向量机算法惩罚因子C设置为50,Radial Basis Function(RBF)核函数方差g设置为0.1,损失因子p设置为0.1。BPNN参数设置如下,训练数选取为1000,训练目标选取0.001,学习速度选取0.01。ELM算法参数设置如下,隐层神经元数设置为30,隐层神经元的激活函数为S型函数。
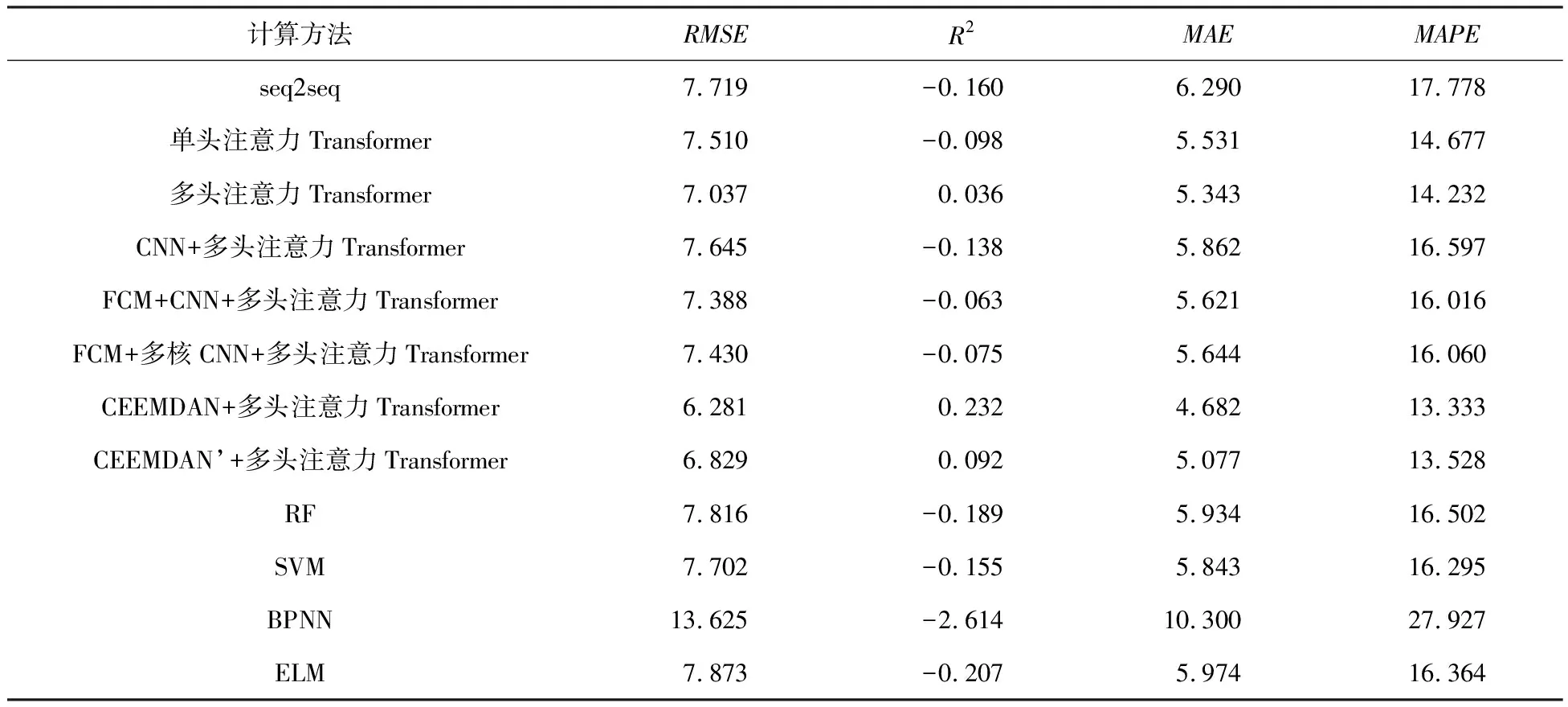
表3 不同算法的计算精度对比
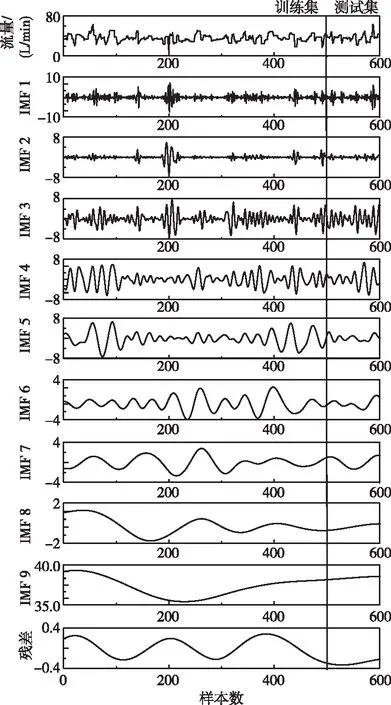
图6 灌浆流量参数分解图
不同算法的对比结果如表3和图8所示,多头注意力Transformer相比seq2seq和单头注意力Transformer具有良好的计算精度,且能够更好地反映灌浆流量的时序变化趋势。在灌浆施工中灌浆压力和灌浆流量需要维持相对稳定的灌浆功率,灌浆流量序列预测提供时间线更长的预测范围,能够为灌浆施工流量管控提供参考并且提高施工质量。CNN+多头注意力Transformer、FCM+CNN+多头注意力Transformer、FCM+多核CNN+多头注意力Transformer、FCM+多核CNN+多头注意力Transformer算法在计算精度和时序趋势方面相比多头注意力Transformer没有明显优势。CEEMDAN+多头注意力Transformer相比多头注意力Transformer计算精度明显提升,CEEMDAN’+多头注意力Transformer相比多头注意力Transformer计算精度也有一定幅度的提升。IMF1至IMF9的分量预测结果如图7所示,通过所有分量合成的灌浆流量预测结果如图7所示。RF和SVM算法计算结果比较平缓,结果的辨识度低,BPNN和ELM计算结果波动性大。总体而言,相比RF、SVM、BPNN、ELM算法,多头注意力Transformer算法在计算精度和时序趋势效果方面都存在明显优势。CEEMDAN+多头注意力Transformer相比多头注意力Transformer计算精度明显提升,同时该算法能够一次计算24个测点,通过序列到序列预测降低了计算的复杂性,增加了预警时间。
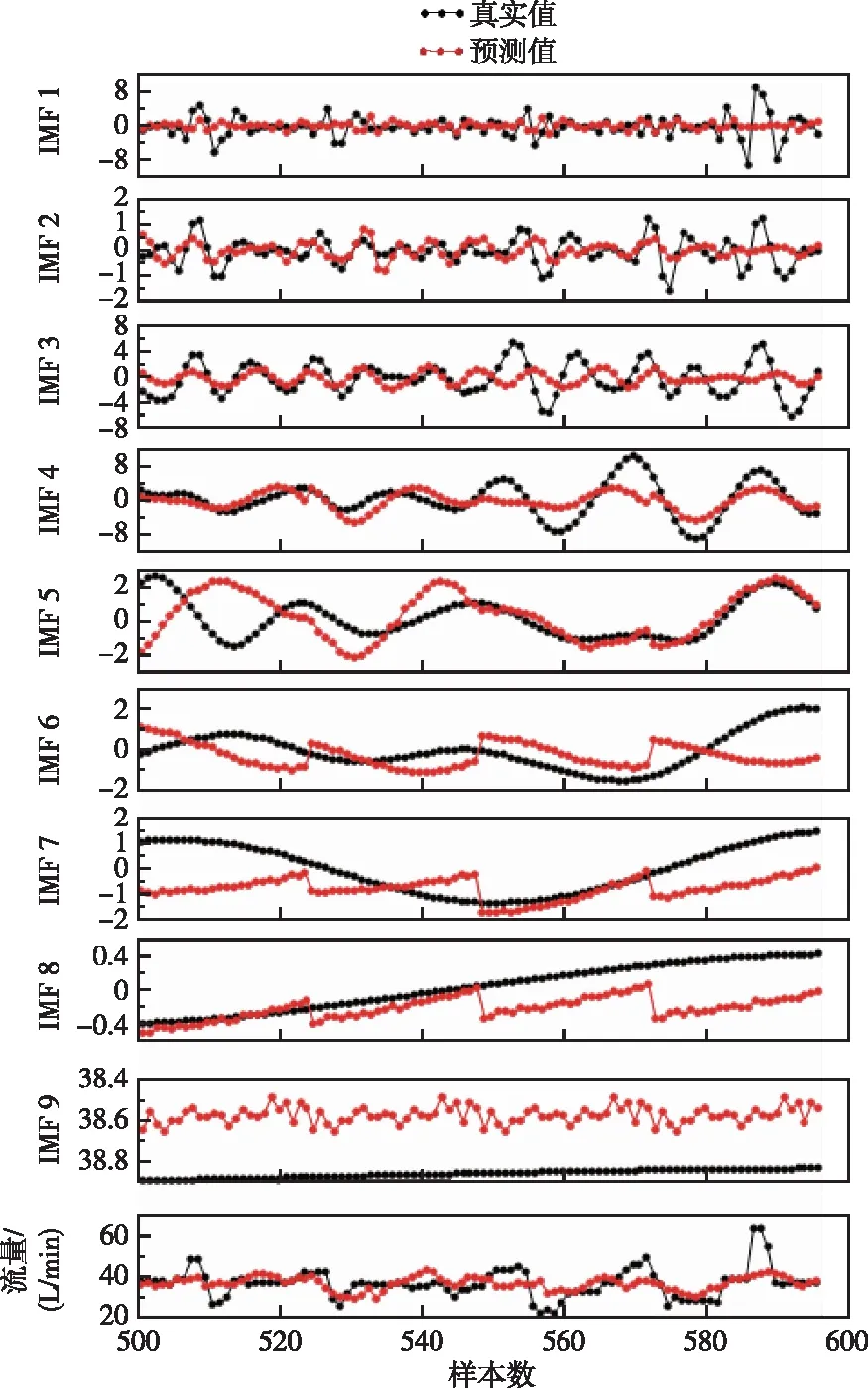
图7 灌浆流量分解参数和灌浆流量预测图
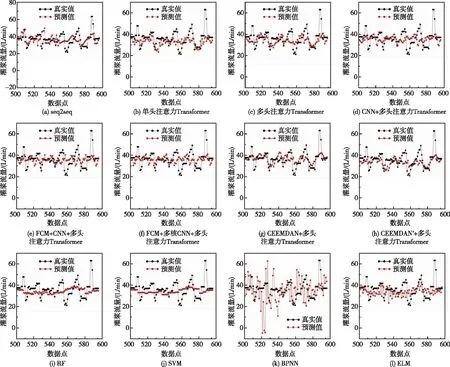
图8 灌浆参数预测结果
5 讨论
本研究实现了灌浆流量的时序预测,考虑到灌浆过程中灌浆压力和灌浆流量是相互作用的,得到耦合灌浆流量、压力的计算结果。灌浆压力的监控曲线如图9所示,同样选取500个数据点作为训练集,100个数据点作为测试集。参数设定与多头注意力Transformer算法一样,选取96个流量数据和96个压力数据进行输入,24个流量数据进行输出,计算得到RMSE,R2,MAE,MAPE分别为7.290,-0.035,5.505,15.006。相比仅通过流量预测流量结果(RMSE=7.037,R2=0.036,MAE=5.343,MAPE=14.232)在算法精度方面没有明显提升。同时比较了灌浆压力的时序预测结果,参数设定与流量多头注意力Transformer算法一样,选取96个压力数据进行输入,24个压力数据进行输出,计算结果如图10所示,计算精度为RMSE=0.294,R2=-0.814,MAE=0.232,MAPE=15.675。选取96个流量数据和96个压力数据进行输入,24个压力数据进行输出,计算精度为RMSE=0.307,R2=-0.967,MAE=0.241,MAPE=16.370,相比通过灌浆压力进行时序预测该耦合方式并没有提高预测精度。
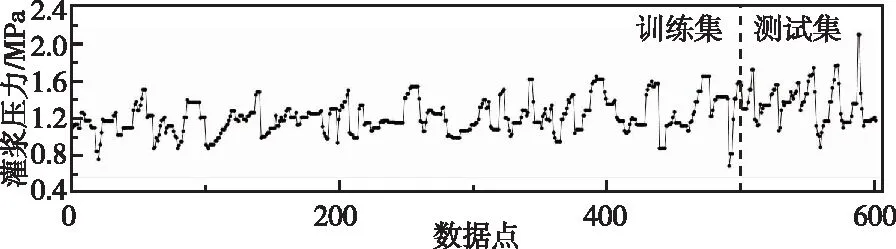
图9 灌浆压力监测数据
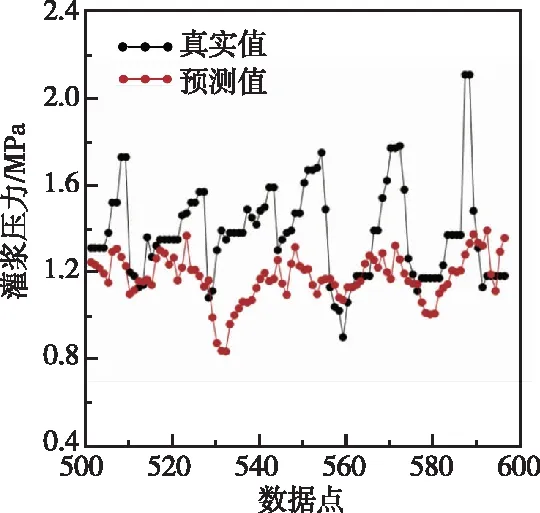
图10 灌浆压力预测结果
6 结论
灌浆流量数据存在强非线性和强波动性的特点,给灌浆流量的预测带来了极大的挑战,本研究建立了基于CEEMDAN-Transformer的灌浆流量混合预测模型,得出以下结论:
(1)CEEMDAN+多头注意力Transformer(RMSE=6.281,R2=0.232,MAE=4.682,MAPE=13.333)相比多头注意力Transformer算法精度(RMSE=7.037,R2=0.036,MAE=5.343,MAPE=14.232)明显提升。
(2)考虑输入和输出的全局依赖关系的多头注意力Transformer算法(RMSE=7.037,R2=0.036,MAE=5.343,MAPE=14.232)相比Back propagation(BP)神经网络算法(RMSE=13.625,R2=-2.614,MAE=10.300,MAPE=27.927)精度明显提升,同时多头注意力Transformer算法相比序列到序列算法(RMSE=7.719,R2=-0.160,MAE=6.290,MAPE=17.778)有一定幅度提升,能够更好地反映序列趋势,并且实现了并行计算。
(3)建立多输入多输出灌浆流量时序预测模型相比传统的单点预测提高了算法精度,CEEMDAN+多头注意力Transformer的计算精度为RMSE=6.281,R2=0.232,MAE=4.682,MAPE=13.333,相比传统RF(RMSE=7.816,R2=-0.189,MAE=5.934,MAPE=16.502)、SVM(RMSE=7.702,R2=-0.155,MAE=5.843,MAPE=16.295)、BPNN(RMSE=13.625,R2=-2.614,MAE=10.300,MAPE=27.927)、ELM(RMSE=7.873,R2=-0.207,MAE=5.974,MAPE=16.364)算法的计算精度存在明显优势。序列到序列预测减少了每次预测的繁杂度和增加了每次预测的预警时间。
(4)利用多头注意力Transformer算法建立了耦合灌浆流量和灌浆压力的混合参数预测模型,灌浆流量混合预测模型精度RMSE,R2,MAE,MAPE分别为7.290,-0.035,5.505,15.006,相比仅通过流量预测流量结果(RMSE=7.037,R2=0.036,MAE=5.343,MAPE=14.232)在算法精度方面没有明显提升;灌浆压力混合预测模型精度RMSE,R2,MAE,MAPE分别为0.307,-0.967,0.241,16.370,相比仅通过压力预测压力结果(RMSE=0.294,R2=-0.814,MAE=0.232,MAPE=15.675)在算法精度方面没有明显提升。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
中国农业信息(2021年3期)2021-11-22
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
电子制作(2017年13期)2017-12-15
电子设计工程(2017年20期)2017-02-10
电子制作(2016年15期)2017-01-15
电子器件(2015年5期)2015-12-29
