
基于注意力评分函数的行人重识别研究
2023-08-21 09:57:42刘静怡金彬解祥新李天逸
无线互联科技 2023年12期
刘静怡 金彬 解祥新 李天逸

摘要:行人重识别也称跨境追踪,旨在弥补固定摄像头的视觉局限。针对行人图像容易出现遮挡、视觉与姿态的不同变化、光照变化等影响而出现难以区分行人的状况,最终导致行人重识别准确率低的问题,文章提出了一种使用点积得到计算效率更高的注意力评分函数进行检测的方法。实验结果表明,在注意力机制的加持下,该模型能够有效地增强行人图像特征等关键词的提取,进一步提高模型的鲁棒性,有效地满足实际需要。
关键词:行人重识别;注意力评分函数;鲁棒性
中图分类号:TP311 文献标志码:A
0 引言
近几年,智能化逐渐成为城市发展的趋势,监控视频网络也越来越普遍地被应用到地铁、商场、医院等公共场合,这不仅给人们提供便利,还能确保地区的安全[1]。但是由于摄像头的数量巨大,拍摄场景复杂,拍摄中会出现很多不确定因素,虽然目前的人脸识别技术比较成熟,但是它有一个明显的缺点,就是必须要看到相对清晰的人脸照片。而通过行人重识别技术可以对已有的可能来源与非重叠摄像机视阈的视频序列中识别并检索出目标行人,从而大大提升了数据的时空连续性,使数据更加准确、可靠。因此,将行人重识别技术运用到智能安防、视频监控系统等各个领域能更好地保障社会安定。
目前,行人重识别所采用的方法有基于表征学习的ReID方法、底层视觉特征方法、中层语义属性、高级视觉特征和别的一些组合方法[2-3]。这些方法虽然能从不同角度解决一些问题,但是不能有效解决在面对行人局部特征区域划分后出现离异值使该区域内容不一致的情况。针对目前行人图像易受到外部环境影响的各种问题,本文提出了基于评分函数的方法,进而提高鲁棒性以及局部特征的可区分性。
1 行人重识别理论
1.1 行人重识别问题描述
尽管目前很多学者对行人重识别进行了深入而全面的研究,使得技术的可用性得到了一定的提高,但是由于显示复杂的场景,仍然存在着来自不同背景和视角的挑战。行人重识别存在的难点问题如下:
(1)遮挡。在各种复杂的情况下,行人很容易被多种物品所遮挡,如口罩、墨镜、桌子等,致使行人的姿态和穿着特征很难提取,从而影响重识别的精度。
(2)视角、姿态的变化。行人在路上的姿态行为是不可控的,所以在不同的视角拍到的照片都是有很大区别的,因此这些问题都对行人重识别提出了挑战。
(3)光照变化。由于现实拍摄过程中光照来源、光照强度、拍摄场景以及摄像参数具有很大的不确定因素,导致对于不同分辨率的摄像机敏感度不同,从而拍到的行人也存在着很大的差异。
(4)相似行人的影响。在实际场所下,很多人会面临撞衫的情况,甚至会在外界因素导致之下,不同行人比同一行人更难分辨,导致了相似行人的识别困难,增加了行人重识别的研究难度。
(5)距离的影响。近距离拍摄的图像中大部分是行人,而较远距离得到的图片主要是背景,所以提取目标行人特征后的精确性就会降低。
除了以上问题,行人重识别还存在无正脸照、配饰、服装、穿衣风格以及由于不同的数据集中存在域的偏移問题,使得原数据集下训练的模型在目标数据集下很难取得很好的性能,泛化性能不强。
1.2 常用算法实现
1.2.1 基于表征学习的行人重识别方法
表征学习可以近似看作为样本在特征空间的分界面,主要通过构造网络直接得到模型的鲁棒性,不直接学习图片之间的相似性。并且主要得益于深度学习,卷积神经网络(CNN)是深度学习中最流行的算法之一[4],它可以根据任务需求自动提取表征特征并且可以在网络的输入时使得图像特征表现得更为明显。基于特征表达的方法包括底层视觉特征、中层语义属性特征、高级视觉特征3类。
1.2.2 基于度量学习的行人重识别方法
不同于表征学习的方式,度量学习旨在通过构造网络来检测两张图片的相似度,被广泛用于图像检索领域。度量学习也可以看作在特征空间进行聚类,正样本距离拉近的过程使得类内距离缩小,负样本距离推开的过程使得类间距离增大,最终收敛时使得样本在特征空间呈现聚类效应。度量学习的行人重识别一般分为线性学习和非线性学习两种方法,它们之间都依附于强有力的度量函数,因此度量函数的好坏十分重要。
1.2.3 基于局部特征的行人重识别方法
局部特征是对行人图像特征的局部表达,其思路主要是对图像的某一区域进行特征提取,最后将多个局部特征融合到一起作为最终特征。主要的研究方法为:利用关键点来定位以及区域分块。
1.2.4 基于多层深度特征融合的行人重识别方法
采用卷积神经网络提取目标行人图像的深层特征可以降低表观变化造成的影响,提高目标行人特征的稳定度和可靠性。卷积的本质是滤波,操作是加权平均、乘加运算。与普通的神经网络相比,它具备了“平移不变性”,无论行人目标在哪个位置都能被检测到,并且可以通过卷积层的级联学习到不同尺寸的特征,有效地提取到有用信息。
2 注意力评分函数概述
在注意力机制的背景下,本文将自主性提示称为查询(Query),对于给定的任何查询,注意力机制通过注意力汇聚将选择引导至感官输入,在注意力机制中,这些感官输入被称为值(Value)[5-6]。设计注意力汇聚以便给定的查询(自主性提示)可以与键(非自主性提示)进行匹配,将会引导出最匹配的值(感官输入)。
从宏观上来看,利用评分函数算法实现注意力机制框架,如图1所示。图1也说明了如何将注意力汇聚的输出计算成为值的加权和,其中a表示注意力评分函数,由于注意力权重是概率分布,因此,加权和本质上是加权平均值。
评分函数公式:用数学语言描绘,假设有一个查询q∈Rq和m个“键-值”对(k1,v1),……,(km,vm),其中ki∈Rk,vi∈Rv。注意力汇聚函数f就被表示成值的加权和:
f(q,(k1,v1),……,(km,vm))=∑mi=1α(q,ki)vi∈Rv(1)
其中,查詢q和键ki的注意力权重(标量)是通过注意力评分函数a将两个向量映射成标量,再经过softmax运算得到的:
α(q,ki)=softmax(a(q,ki))=exp(a(q,ki))∑mj=1exp(a(q,kj))∈R(2)
而softmax操作用于输出一个概率分布作为注意力权重[7-8]。在一些特殊情况下,并非所有的值都应该被纳入注意力汇聚。某些文本序列被填充了没有意义的特殊词元,是为了将有意义的词元作为值来获取注意力汇聚,所以本文指定了一个有效序列长度(即词元的个数),以便在计算softmax时过滤超出指定范围的位置。
正如公式所示,选择不同的注意力评分函数a会导致不同的注意力汇聚操作[9]。本文主要使用缩放点积注意力可以得到计算效率更高的评分函数。假设查询和键的所有元素都是独立的随机变量,而且都满足零均值和单位方差,那么两个向量的点积的均值为0,方差为d。为了确保无论向量长度如何,点积的方差在不考虑向量长度的情况下仍然是1,将点积除以d,则缩放点积注意力评分函数为:
a(q,k)=kqTd(3)
在实践中,本文从小批量的角度来考虑提高效率,基于n个查询和m个键值对计算注意力,其中查询和键的长度相同为d,值的长度为v0。查询Q∈Rn×d。键K∈Rm×d和值V∈Rm×v的缩放点积注意力是:
softmax(QKTd)V∈Rn×v(4)
3 实验结果与分析
本系统行人检测模块采用的是Market-1501,这是常用的行人重识别中的数据集,实验选用ResNet-150这种流行的CNN网络。本文注意力模块使用缩放点积算法优化,初始学习率为0.01,权重衰减率设置为0.000 5,迭代次数为50次,测试中,不增加数据增强操作。
3.1 评价标准
为了评估算法的性能,本文采用Rank-1和mAP作为评估标准来衡量识别的效果。Rank-1是指在候选集中得到与检索目标相似性排名最高的图片为目标行人的概率,是排序命中率的核心指标[10]。而平均精度值mAP(Mean Average Precision)是更能全面衡量ReID算法效果的指标,其计算公式为mAP=所有类别的平均精度求和除以所有类别,其中mAP的相对大小是衡量类似任务模型质量的关键标准之一。本文采用了Rank-1和mAP的结果来衡量引入注意力机制识别模型的性能。
3.2 实验结果及分析
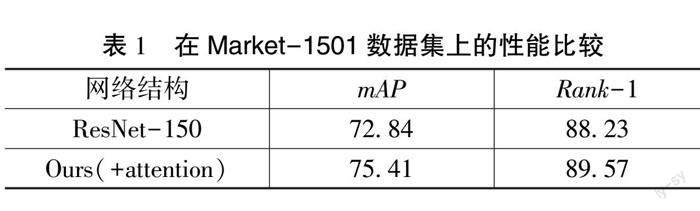
本文做了两组对比实验,对比了在模拟的行人图像各种分辨率共存和尺度不匹配的场景下,引入注意力评分函数和未引入时分别做行人重识别的实验效果,实验结果如表1所示,左边的数据是mAP,即本次实验的平均精度,右边的数据是Rank-1,即实验中排序第一的目标行人图像是所要查询的行人概率。
通过实验得出的结果可知,对收集到的数据集,正面的目标行人图像首位命中率可以达到89.57%,该模型在处理正面行人图像时效果较为准确。并且从以上结果可以看出:本文提出在隐层和输出层之间使用缩放点积注意力评分函数可以增强最终行人重识别的正确率,这表明了本文提出的方法是有效的,并且本文提出的模型并没有经过任何的预训练,这也可以说明本文提出的模型具有较强的鲁棒性。
实验证明引入注意力评分函数的行人重识别技术有一定幅度的提高,网络的表征能力得到了进一步的增强,基于注意力评分函数的行人重识别研究与传统的算法相比有一定的竞争力。但是,行人重识别的数据集的样本数量比较少,缺少样本也是行人重识别的一个重要难题,这也意味着使用庞大的模型需要对样本进行复杂的预处理和数据夸张以及在网络上加入各种的措施避免过拟合。
4 结语
为了解决行人重识别准确率低的问题,本文提出了一种新的基于缩放点积注意力评分函数方法,这种方法通过调优算法来提升性能,优点在于其够全局捕捉联系,不像序列RNN捕捉长期依赖关系的能力那么弱并且可以并行化,十分有效地提高模型的鲁棒性。然而,本文所提出的方法也存在一定的缺点:一是当查询和键是不同长度的矢量时,缩放点积注意力函数没有其他的评分函数计算效率高;二是文中样本数据较少,该实验结果仍存在必然偏差,若增加样本数据量,则模型的鲁棒性能达到更好的预测效果。
参考文献
[1]严灿祥.行人再识别技术研究[D].北京:中国科学院大学,2014.
[2]李承宸.基于局部特征的行人重识别技术应用与研究[D].济南:山东师范大学,2020.
[3]樊霖.基于孪生网络的行人重识别研究[D].天津:天津理工大学,2020.
[4]汤勇.基于深度学习的行人检测与行人重识别研究[D].长沙:湖南大学,2019.
[5]张严.基于注意力机制的对比学习行人重识别[D].武汉:华中科技大学,2020.
[6]罗善益.基于注意力模型的行人重识别算法研究[D].武汉:华中科技大学,2020.
[7]祁子梁.基于混合损失函数的行人再识别研究[D].天津:河北工业大学,2019.
[8]谢以翔.基于视觉注意力机制的行人再识别研究[D].合肥:安徽大学,2019.
[9]张斌艳,朱小飞,肖朝晖,等.基于半监督图神经网络的短文本分类[J].山东大学学报(理学版),2021(5):57-65.
[10]郑付科.基于内容一致性和行人属性的行人重识别研究[D].郑州:郑州大学,2020.
(编辑 王雪芬)
Pedestrian reidentification study based on the attention scoring function
Liu Jingyi, Jin Bin, Xie Xiangxin*, Li Tianyi
(Nantong Institute of Technology, Nantong 226000, China)
Abstract: Person re-identification, also known as cross-border tracking, aims to make up for the visual limitations of fixed cameras, and this paper proposes a method for detecting pedestrians by using the attention scoring function with higher computational efficiency by using the dot product to obtain a more efficient attention scoring function for detection. The experimental results show that with the support of the attention mechanism, the model can effectively enhance the extraction of keywords such as pedestrian image features, further improve the robustness of the model, and effectively meet the practical needs.
Key words: person re-identification; attention scoring function; robustness
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
意林(2021年5期)2021-04-18 12:21:17
农业机械学报(2020年2期)2020-03-09 07:35:30
中华建设(2019年7期)2019-08-27 00:50:18
扬子江(2019年1期)2019-03-08 02:52:34
传媒评论(2017年3期)2017-06-13 09:18:10
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
项目管理技术(2016年12期)2016-06-15 20:29:33
西南交通大学学报(2016年6期)2016-05-04 04:13:11
