
基于HRNet 的形体动作识别算法设计
2023-08-19 09:59闫琳
电子设计工程 2023年16期
闫琳
(西安航空职业技术学院,陕西 西安 710089)
近年来,随着计算机视觉技术逐渐走向成熟,越来越多的基于视觉检测的应用被普及。形体动作识别是机器视觉技术的一个重要应用领域[1],通过该技术能够快速、精准地识别运动员或舞蹈演员的不规范动作,并分析训练制约因素以提高学习效率,从而实现智能化标准形体动作培训[2-3]。
形体动作识别旨在对人体的各个关键点进行检测,进而判断人体的动作姿态,其关键是人体姿态估计技术。早期的人体姿态估计是通过预设的人体姿态模板来拟合图片中的人体,随着深度学习(Deep Learning,DL)的发展,业界学者逐渐采用基于卷积神经网络的算法来完成姿态估计。文献[4]在姿态估计任务中引入深度学习算法并提出DeepPose 算法。文献[5]将姿态估计看作是检测任务,设计Flow Convnet输出热力图。文献[6]提出了Hourglass 网络,通过递归使用下采样及上采样来高效地学习多尺度信息。文献[7]设计了GlobalNet 与RefineNet 以提高算法对困难关键点的挖掘能力,并凭借其优异的性能,该算法获得Face++2017 年COCO Keypoints Challenge 的冠军。由于大部分网络均是由高到低的结构,因此会导致最终表示的分辨率较低。因此,中国科技大学联合微软公司的学者设计了一种新的网络结构,即HRNet(High-Resoultion Net)[8]。与其他网络不同,HRNet 在前向传播过程中始终保持高分辨率特征,同时通过密集连接以获取深层语义。随后在图像分类[9]、人体姿态估计[10]及图像分割[11]等机器视觉任务中证明了有效性。
形体动作识别需对一些微弱与复杂的动作进行识别,这便需要较强的语义信息。因此,采用HRNet网络结构进行特征提取。但由于始终保持高分辨率传输及密集运算,HRNet 具有复杂的网络结构,导致其计算效率较低。随着Transformer[12]在自然语言处理中取得巨大成功,众多学者将其拓展至计算机视觉领域。实验表明,Transformer 在视觉任务中能够在保持较高准确率的同时,实现更高的计算效率。此外,Transformer 由多头注意力和自注意力构成,可捕捉不同关键点特征间的联系[13-14]。为此,基于HRNet 网络结构,该文引入Transformer Block 设计了一种高分辨率形体动作识别算法,以用于形体动作的识别。
1 基于HRNet的形体动作识别方法
为提升模型对形体动作的识别性能,基于HRNet网络结构,引入了Transformer 模块,设计了一种多分辨率特征相关的形体动作识别算法,其能够在整个过程中维护高分辨率,并挖掘特征的相关性。
1.1 基于HRNet的网络结构
相比于日常的人体动作,舞蹈形体较为夸张,尺度变化也更为剧烈,这便给形体动作识别带来了挑战。基于HRNet 的网络结构通过高分辨率计算,可获取更为精细的局部特征。而利用密集连接多分辨率的深度特征,可提取包含全局信息及深层语义的特征。因此,该文采用HRNet 结构来搭建姿态估计网络模型[15-16]。
HRNet 的具体网络架构如图1 所示,特征提取部分包含4 个阶段:第1 阶段的特征图分辨率缩放比为1∶4,主要包含两个Bottlenect Block,每个由两个1×1卷积和一个3×3 卷积组成;第2 阶段在原有分辨率特征图的基础上增加了8 倍降采样的支路,该阶段同样由两个Block 组成,但与第1 阶段不同,从第2 阶段起Block 替换为能够捕捉特征相关性的Transformer Block;第3 阶段和第4 阶段依次增加16 倍降采样支路和32 倍降采样支路,且每个支路还包含有两个Transformer Block 来进行特征提取。每个阶段衔接处进行多尺度特征融合,以交换多分辨率信息。

图1 基于HRNet的形体动作识别算法
该文方法的多尺度特征融合部分是一个密集连接块,需通过上采样和下采样操作统一尺度后再进行融合,如图2 所示。
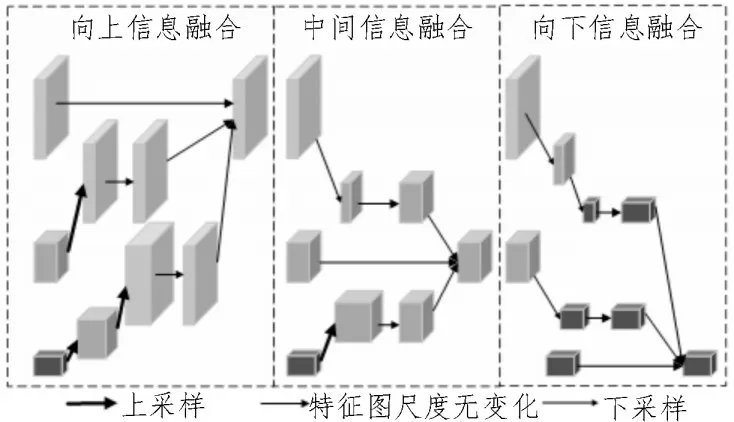
图2 多分辨率特征融合示意图
向上信息融合模式对于小尺度特征,采用两次上采样操作将特征图统一为大尺度特征,通过1×1卷积将特征图通道数与大尺度进行统一;对于中尺度特征,采用一次上采样操作,然后通过1×1 卷积将特征图通道数与大尺度进行统一;最后,将所有结果按相应通道进行叠加。
在中间信息融合模式,大尺度和小尺度特征分别采用降采样和上采样操作实现特征图分辨率上的统一。然后通过1×1 卷积整合通道数,最后将所有结果按相应通道进行叠加。向下信息融合模式与向上信息融合模式相似,大尺度和中尺度特征分别通过两次和一次降采样操作将特征图降为小尺度,将通道数和尺度均统一为小尺度的三个特征图进行叠加。
1.2 Transformer Block设计
由于Transformer 具有高效率、高扩展性的特点,将基于HRNet 结构引入Transformer Block,以降低HRNet 的计算复杂度,进而提升形体动作识别的性能。
首先,将输入的特征图X∈RN×D平均裁剪成一组无交叉的窗口特征图序列,即{X1,X2,…,Xp}。其中,N表示特征图大小,D表示通道数,每个窗口特征图的尺寸为k×k,p则表示窗口数量,且每个窗口分别执行多头注意力。第p个窗口的多头注意力模块计算方法为:
式中,Wo∈RD×D,H表示多头注意力的Head 数,每个Head 由一个自注意力机制构成。文中多头注意力机制的Head 数与降采样倍数正相关:特征图在4、8、16、32 倍降采样后的多头注意力操作对应Head 数为1、2、3、4。MultiHead(·)为多头注意力机制,具体计算如下:
其中,Head(·)为自注意力机制,具体计算如下:
其中,Wq,Wk,Wv∈RD×D/H,均为自注意力机制的参数权重。XMHSA表示多头注意力输出结果,具体操作为聚合每个窗口中信息,如式(4)所示:
由于所有的自注意力在窗口特征图单独执行,所以窗口特征图之间缺少信息交换。因此,在信息聚合后采用一个3×3 卷积进行通道间信息交互,具体如图3 所示。

图3 Transformer Block结构图
2 实验和分析
2.1 实验数据集
在Balletto 数据集上进行实验,该数据集是一个芭蕾舞形体动作数据库,共有9 845 张标注的形体动作图片,按2∶1 进行训练集与测试集分配。
2.2 实验环境
该文实验均在Ubuntu18.04 系统下进行,GPU 采用Nvidia RTX2080Ti,深度学习框架采用了Pytorch框架。
2.3 各阶段性能评估
将Transformer Block 引入HRNet 会造成整体网络结构的参数规模与运算复杂度发生变化。为了测试HRNet 各阶段网络结构对形体动作识别的性能,对其各阶段逐一进行消融实验。实验结果如表1 与图4 所示。表1 中,2 Stage、3 Stage 和4 Stage 分别指2 阶段、3 阶段和4 阶段的HRNet 结构。

表1 HRNet网络结构阶段性能测试实验结果
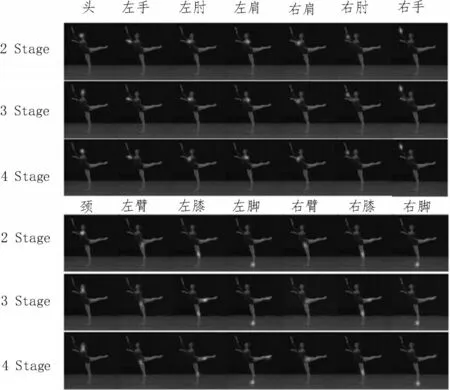
图4 HRNet网络结构阶段性能测试效果
由图表可知,在第2 阶段,参数量与浮点计算量大幅降低,但由于特征提取不充分,导致准确度与召回率受到影响。而图4 中舞者动作幅度过大的腿部关键点检测性能不足,故左腿未能成功检出;对于第3 阶段,其网络参数量为2.1 MB,浮点运算量仅为3.8 GFLOPs,准确率和召回率也均较为理想;而在第4 阶段,相比前两个阶段,左右腿关键点检测获得了提升。据分析,深层特征与Transformer 的结合,有助于挖掘特征相关性,提升了关键点检测准确率。
2.4 形体识别性能评估
表2 所示为CPN、Hourglass、HRNet 及该文方法在数据集上对人体姿态估计的定量结果,主要采用模型大小与浮点运算量来衡量模型的复杂度,并用各关键点的KOS 准确率来评估模型精度。

表2 模型各关键点准确率分析
在模型的准确率测试中,CPN 的平均关键点检测准确率为85.7%,Hourglass 的平均关键点检测准确率为85.9%,但HRNet 及该方法准确率均达到了86.1%。这表明,基于HRNet 的网络结构在形体识别中具有更优的特征提取能力。在具体关键点检测中,手部和足部等关键点尺度变化剧烈,经常互相交错遮挡,因而检测难度较大。但文中方法引入Transformer Block,借助自注意力机制(Self Attention)和多头注意力机制(Multi-Headed Attention),充分挖掘各个阶段特征间的自相关性与互相关性,从而达到了较好的检测效果。相比于原HRNet,手部及足部关键点的检测准确率分别提高了0.8%和1.3%。
在模型复杂度的分析中,基于Hourglass 的算法模型参数量最大,为92 MB。CPN 和HRNet 的参数则相差较小,分别为27 MB 和28.5 MB。而该文方法的模型参数量最小,仅为7.8 MB,且浮点运算量为6.2 GFLOPs。经分析,该算法采用Transform Block 取代卷积操作,大幅降低了模型参数量。
3 结束语
为了提升形体动作识别的性能,文中设计了一种针对关键点交错遮挡隐藏场景下的形体动作识别算法。在Balletto 数据集中进行的实验结果表明,相比于原HRNet,该算法的计算效率得到显著提升,且在一些交错关键点中表现出了更高的检测精度。但该算法对于其他关键点的检测仍略显不足,这将在未来的研究中对此进行改进。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
西夏学(2017年2期)2017-10-24
兽医导刊(2016年12期)2016-05-17
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
中国医疗美容(2015年1期)2015-07-12
中国卫生(2014年2期)2014-11-12
