
基于本体重构的工业知识图谱搭建方法*
2023-08-17 12:38翟值楚靖琦东
通信技术 2023年5期
翟值楚,靖琦东,滕 磊,李 倩
(中电工业互联网有限公司,湖南 长沙 410205)
0 引言
知识图谱具有鲜明的应用灵活性、知识表示精准性和独特的图结构特征[1-2],因而被广泛地应用到工业领域,以解决设备诊断和异常检测等问题,并能有效减少制造设备的停机时间、资源消耗、错误率等。由于工业领域拥有海量的结构化数据和半结构化数据,以及该行业的多样性,自动生成对应的知识图谱非常理想,但本体搭建问题却制约了相关技术的发展。
本体通常分为面向知识的本体和面向领域数据的本体两类[3-4]。其中,全行业领域专家共同搭建的本体通常为面向知识的本体,它被要求尽可能地涵盖整个行业所涉及的知识,因此具有涉及面广、知识精度高、本体复杂度高、人工成本巨大的特点。而面向领域数据的本体,则是在已有领域的知识本体库中搭建合适的本体来表示该领域子行业或子领域数据。工业数据可能包含数十个类别,许多属性存在于同一类数据集中,但在其他类别数据集中却没有。此外,面向领域数据本体的许多术语并不存在于所有数据集中,通常以该特定领域数据为导向,使用已有的知识型本体库。因此,面向领域数据的本体在构建时可能会产生大量冗余或大量空白结点,从而导致数据稀疏问题。
知识图谱的搭建是将已有的结构化或半结构化数据按照建立的映射关系进行实例化的过程,具体如图1 所示。首先,由领域专家参与构建,因为其反映了行业领域内的知识细节,通常需要多位专家进行密集的讨论,才能创建出反映一般领域知识的高质量本体库;其次,根据不同细分领域及数据的特殊性,行业专家在本体库中对本体进行选择,构建出符合当前领域的数据模式;最后,根据已有的数据模式与数据做映射,生成对应的知识图谱。然而,上述知识图谱搭建方法还存在一些问题:一是通常不支持非结构化数据;二是需要大量的人工标注,最后生成的实例中会出现复杂度较深及空白的节点。

图1 知识图谱搭建流程与关系映射
针对上述问题,本文提出了一种基于本体重构的工业知识图谱搭建方法,具体贡献如下:
(1)在已有的工业领域本体重构算法中加入了多模块匹配机制,以工业领域具体数据为导向,根据规则库对工业领域通用本体库中的本体进行重构,降低了重构过程中的人力成本。
(2)使用初始的工业领域知识图谱对工业领域具体数据进行分析与总结,扩充并获得新增规则库;然后采用新增扩充规则库对工业领域通用本体库进行修改,减少了空白节点;还使构建的知识图谱的更新形成闭环,自动完成本体重构及知识图谱更新。
(3)使用工业领域真实数据,构建了认证机构领域的知识图谱框架,并与未使用此框架的其他构建方式进行对比,证明了所提出方法的可行性。
1 相关工作
近年来,知识图谱在工业领域得到了广泛的关注,主要用于提取海量结构化或非结构化数据的高价值信息,从而辅助业务决策[1-2]。工业领域由于其行业的多样性及数据的复杂性,通常使用通用的本体库作为基础,再根据细分领域以数据为导向转化为较小的本体库,这类方法通常涉及本体模块化及本体摘要[5-6]。但是,这些方法通常只关注获取本体的子集,而忽略了获取虚实体导致生成图谱复杂度较高的问题[7]。例如,Suárez-Figueroa 等人[8]提出了本体重构的方法,但是并未精确瞄准某个专业领域自动构建并反映领域数据的特殊性。Zhou 等人[9]首次针对工业领域数据使用本体重构的方式构建知识图谱,并提出了本体重构的相关算法,但是在本体重构过程中加入了大量人工标注信息,增加了不同程度的人力成本。在上述研究的基础上,本文提出了自动化的本体重构过程,并规范了工业领域使用本体重构方式创建知识图谱的整个流程。
2 整体框架设计
基于本体重构的工业领域知识图谱搭建框架如图2 所示,主要包括如下步骤:

图2 基于本体重构的工业知识图谱搭建框架
(1)由各专家构建工业领域通用本体库。这里的工业领域通用本体库为专家通过密集讨论,对本体库进行扩展,最终形成的可以反映工业领域的通用知识本体。一般使用Protege 软件生成owl 格式文件。本体库的构建应具备通用性,搭建完成后可供行业中多个细分领域继续使用。
(2)加入多模式匹配机制。以工业领域具体数据为导向,根据规则库对所述工业领域通用本体库中的本体进行重构,得到具体工业领域本体库。所述具体工业领域本体库包括由属性、关系与实体构成的本体。
(3)根据数据模式生成对应的实例,搭建对应知识图谱。构建所述本体与数据模式之间的映射关系,并根据所述数据模式生成所述本体对应的实例,搭建初始的具体工业领域知识图谱。
(4)使用初始的具体工业领域知识图谱对工业领域具体数据进行分析与总结,扩充并得到新增扩充规则库。该部分使用SPARQL 作为查询语句,对已有数据进行查询,查询类型包含信息摘要、数据检验等。
(5)使用新增扩充规则对领域本体库进行修改。该步骤采用新增扩充规则库对所述工业领域通用本体库进行修改,然后返回到步骤(1),从而形成本体重构的闭环。
3 本体重构方法
3.1 问题描述
直观来看,这里的本体重构是基于一些启发式规则和已定义规则的规则库,从一个较大的本体库中获取以数据为导向的本体库子集。本体重构过程是在已知原始本体等信息的情况下生成特定领域的数据模式,重构公式为:
式中:S为数据模式;O为原始本体库;D为具体工业领域的原始数据;M为工业领域的具体数据表名与工业领域通用本体库之间的映射关系;R为根据用户备注信息及部分启发式规则生成的规则库。
3.2 本体重构过程
面向工业领域知识图谱搭建的本体重构过程加入了多模式匹配机制,包括匹配算法模块、相似度加权计算打分模块和本体仲裁模块。具体过程如下:
(1)使用启发式规则初始化规则库R。
(2)使用标注本体AC 初始化数据模式S。根据规则库中数据模式的类名,增加、删除和更改规则库中与工业领域通用本体库对应的类名、属性及关系。例如,在原始本体中“认证机构”和“证书”是“拥有”的关系,但依据规则,将其改为“认证”的关系。
(3)将表名通过映射关系M映射到CClass,并将CClass映射到S。将工业领域通用本体库O可能被映射为类名的属性添加进属性集合CAttribute中,并将剩余的类名添加进类名集合CClass中。例如,将“检查员”添加到CClass集合中,并将“检查员CCAA注册号”“生产企业编号”等添加进集合CAttribute中。
(4)将属性集合CAttribute中的特殊属性名转换为类名,并放入类名集合CClass中,其中特殊属性是指可以唯一标识实体的部分属性。例如将属性“企业ID”名转换为类名并添加进CClass集合中。
(5)基于多模式匹配机制,将属性集合CAttribute和类名集合CClass与工业领域通用本体库O中的字段进行关联重构,得到具体工业领域的本体库D。如图3 所示,多模式匹配机制包括匹配算法模块、相似度加权计算打分模块和本体仲裁模块。

图3 多模式匹配机制
多模式匹配机制的具体关联过程如下:
①将规则库中的新增字段集合OT与具体工业领域本体库D中的类名与属性集合AT中的元素做元素匹配,得到元素对。这里有3 种匹配情况:一是将集合中的类名与类名进行匹配;二是将新增属性名所属的类名与集合中的类名匹配;三是将新增属性值与匹配类名对应的所有属性值进行匹配。
②将元素对输入匹配算法模块进行相似度匹配,并通过相似度加权计算打分模块进行打分与标注。匹配算法模块包括词性分析单元、句法结构相似度单元、字符串相似度单元、规则相似度单元和规则库单元。具体计算过程如下:
a.通过词性分析单元计算元素对的词性相似度,判断元素对词性是否相同,相同为1,不相同则为0。追溯元素对在文本中出现的句子并进行采样。分析采样句的句法结构,并计算句法相似度。包含的语法标记如表1 所示。

表1 语法标记
b.通过句法相似度单元计算元素对的句法结构相似度,即:
式中:p为字段a的采样句子个数;q为字段b的采样句子个数;sameword表示相同两句子中相同字段个数;maxeffectword表示句子主干成分中相同字段的个数。
c.通过字符串相似度单元计算元素对的字符串相似度,即:
式中:simedit为字段a到字段b的编辑距离;n为字段a的字符个数;simcos为字段a和字段b之间的余弦相似度。
d.将所述元素对输入匹配算法模块进行相似度匹配,并通过相似度加权计算打分模块进行打分与标注,将打分超过阈值的元素对存入缓存中,得到标注的本体。通过匹配算法模块进行相似度匹配计算,得到4 种相似度。对4 种相似度通过相似度加权计算打分模块进行打分,打分公式如下:
式中:simword为词性相似度;simsent为句法结构相似度;simstr为字符串相似度;simrule为规则相似度。
e.本体仲裁。将4 种相似度进行加权打分后,设置一个阈值,然后对相似度低于阈值的元素对进行舍弃,将大于阈值的元素存入缓存中,并由高到低进行排序。相似的元素若在原始的通用本体库中存在,则自动进行标注。通过本体仲裁模块的筛选后,本体库表现出非连续特点,同时其空白节点减少,匹配的准确率更高。通过本体仲裁模块得到标注的本体集合AC。该标注的本体集合AC构成具体工业领域本体库。
3.3 构建知识图谱
针对工业互联网领域,构建本体与数据模式之间的映射关系,并根据数据模式生成本体对应的实例,搭建初始的具体工业领域知识图谱。本文使用R2RML 中的自动化匹配框架[10]。首先,通过自定义映射方式将数据从关系型数据库与RDF 进行转化,映射过程可以设置启发式映射规则,例如:table to class、column to property、row to resource、cell to literal value、in addition cell to URI、if there is a forging key constraint 等。然后,将RDF 数据导入到图数据库neo4j 中,生成对应的实例。本体与数据模式之间的映射如图4 所示。
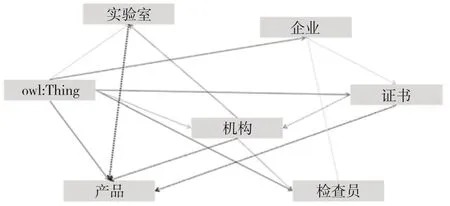
图4 本体与数据模式映射
3.4 工业数据分析
使用初始的具体工业领域知识图谱对工业领域具体数据进行分析与总结,扩充规则库,得到新增扩充规则库。具体地,该部分使用SPARQL 协议作为查询语句[10],对已有数据进行查询。查询来源包括:使用用户关键词查询方式,获取用户关心的关键词;数据分析师输入关键信息的方式,得到查询信息;预警过程中对出错数据进行的查询。查询过程如下:
(1)预警信息查询。本文采用如图5 所示的数据追溯与预警框架,包括预警模块、数据追溯模块和可视化模块。其中,预警包含阈值预警、事件预警、风险预警3 个部分,阈值预警针对已设置阈值的情况进行定时扫描,事件预警针对数据源中发生的事件,风险预警针对数据源中未发生的潜在风险进行定时检测。数据追溯模块可以针对预警的发生,判断预警发生的时间、位置和状态等元信息。可视化模块可将预警的状态、处理时间等信息可视化。

图5 数据追溯与预警框架
(2)数据自检。输入信息后,数据分析员会对涉及的字段进行检查与纠正,该类查询会返回对应的属性列表。
(3)信息摘要。对同一类数据的统计信息概述,例如,“检察员叫张三的人有多少?”“腾讯科技公司拥有多少项证书?”
(4)异常处理。针对已经报错的异常信息,数据分析师会找寻其周围环境,查询异常发生的附近环境,如检测异常的证书、操作等。
最后,采用新增扩充规则库对工业领域通用本体库进行修改,将修改后的工业领域通用本体库当作原始本体,从而形成本体重构及知识图谱更新的闭环。
4 实验与性能分析
本文实验采用了市场监督管理总局认证监督管理司及各认证机构提供的数据集,数据集中包含200 万家企业提供的认证数据,共涵盖150 余个字段、5 000 余万条记录。实验中面向知识领域的本体由专家生成,包含282 个类和305 个属性。将原始数据中所有的属性与本体中的属性进行映射,其中用户信息包括用户指定信息或其他可能的相关属性设计信息。为了测试本体重塑在数据集D中的表现,将数据集随机分为6 个子数据集。每个子集反映了不同的数据复杂度,将子集中的属性数量增加10 倍,对子集重复采样10 次以减少随机性。
作为对比,本文使用未进行本体重构的数据集作为基准方法,直接使用领域本体作为数据模式,以平均查询深度和最大查询深度作为评估指标,最终实验结果如表2 所示。
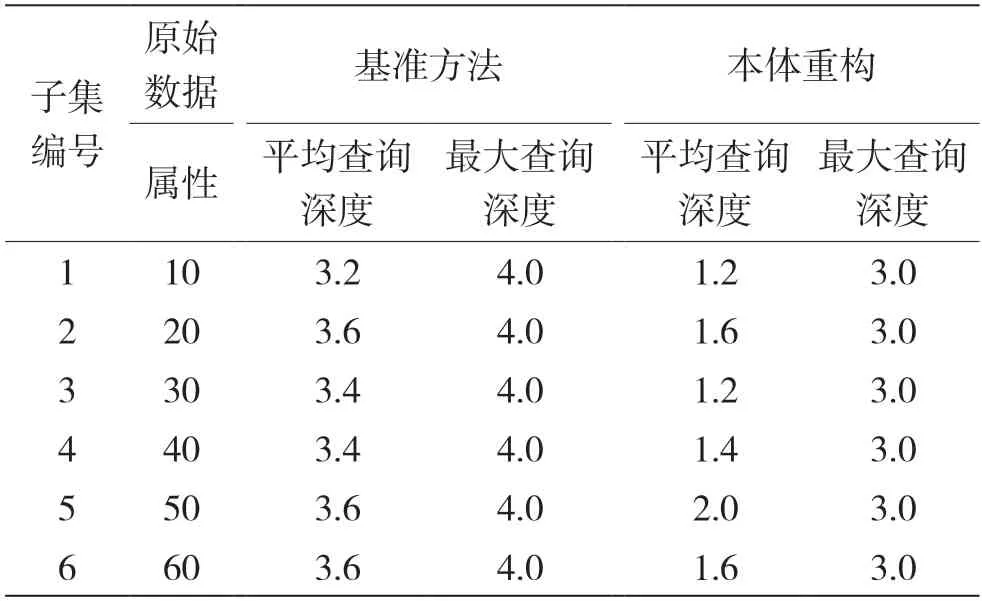
表2 实验结果分析
实验结果表明,当检索相同的答案时,本文所提出的方法大大简化了查询深度,有效降低约2 个平均查询深度,这表明生成的数据模式针对该领域的数据变得更加实用,可以通过更短的查询来获得相同的信息。此外,笔者还观察到,在进行本体重构之后,数据模式变得更加简单有效,生成速度加快了近10 倍,实体的数量减少到基准方法的1/3,存储空间减少为之前的一半,空白节点的数量几乎减少到零。因此,总体来说,本文所提出的方法可以有效降低重构成本,加快生成与查询速度。
5 结语
针对工业领域的知识图谱搭建问题,以真实工业数据为导向,提出了一种基于本体重构的工业知识图谱搭建方法。相比于以往方法,在已有本体重构算法中加入多模块匹配机制,根据规则库对工业领域通用本体库中的本体进行重构,降低了重构过程中的人力成本。在此基础上,使用初始的具体工业领域知识图谱对工业领域具体数据进行分析与总结,扩充规则库,并基于新增扩充规则库对工业领域通用本体库进行修改,减少了空白节点,使构建的知识图谱的更新形成闭环。最后,基于真实的工业数据集验证了方法性能,实验结果表明所提出的方法可有效降低重构成本,加快数据生成与查询速度。
猜你喜欢
摄影世界(2022年1期)2022-01-21
少先队活动(2020年12期)2021-01-14
知识经济·中国直销(2018年12期)2018-12-29
商周刊(2017年6期)2017-08-22
中成药(2017年3期)2017-05-17
制造业自动化(2017年2期)2017-03-20
山东大学法律评论(2016年0期)2016-08-16
领导科学论坛(2016年9期)2016-06-05
文学教育(2016年27期)2016-02-28
图书与情报(2013年1期)2013-11-16
