
ADIC:一种面向可解释图像识别的自适应解纠缠CNN分类器
2023-08-15 02:53赵小阳李仲年王文玉许新征
计算机研究与发展 2023年8期
赵小阳 李仲年 王文玉 许新征,2
1 (中国矿业大学计算机学院 江苏徐州 221116)
2 (中国矿业大学教育部矿山数字化工程研究中心 江苏徐州 221116)(xuxinzh@163.com)
近年来,对于卷积神经网络(CNN)系列黑盒模型,研究者们提出了越来越多的可解释方法,其中一个主流研究方向是可视化CNN隐藏层中的特征表示.然而,神经网络的特征可视化与神经网络的语义解释之间仍存在巨大差距.对于一个对象实例的判断,人类通常是将该实例分解为对象部分,并与存储在脑中的概念进行匹配,作为识别各对象部分的证据,用这些脑海中已识别的概念解释推理过程,做出最终决定.仿照人脑识别物体机制,确定对象部分并构造概念以实现可解释的智能机器模型是一个有潜在研究价值的新兴方向.本文中提到的“概念”在图像识别任务中的本质是“视觉概念”,即具有语义信息且对模型预测起重要作用的像素集.同一视觉概念在不同图像中的表现形式相似,不同视觉概念具有不同的语义信息.例如,斑马的条纹、汽车的轮胎以及鸟类的羽毛等都可以作为其类别的一个基础视觉概念.本文将视觉概念统一简称为概念.
基于概念解释模型,一个重要问题就是如何量化定义概念.用概念激活向量进行测试(testing with concept activation vectors,TCAV)[1]是最早提出使用概念激活向量(concept activation vectors, CAV)量化定义概念的方法,CAV不再分析网络单个节点的特征,而是尝试学习它们的线性组合来表示预定义的概念.ACE[2]基于TCAV,通过聚类图像块自动发现定义新概念.ICE[3]通过对特征图进行非负的矩阵分解修改ACE框架,为不同实例提供一致的CAV权重,提供概念保真度测量措施.上述3种基于概念的解释方法也称概念向量方法,都针对预训练模型进行事后分析,且都依赖于概念的潜在空间中存在一个易于分类的分类器的假设.然而,网络的潜在空间并无此特性,即概念向量方法其实是基于一个独立于模型的额外的分类器.理想情况下,一个可解释的CNN不应该求助于额外的分类器,而是具有可解释的分类器,即可解释CNN的潜在分类空间如何分类概念(解纠缠)对于用户来说应该是透明的或可理解的.
现如今构造CNN透明潜在分类空间的代表性方法有概念白化(concept whitening, CW)[4]、TesNet[5]和Deformable ProtoPNet[6]等.CW模块通过在网络训练过程中强制约束潜在空间的轴与预定义的类别概念对齐,约束不同的类别概念轴方向彼此正交,从而使潜在空间中的类别概念解纠缠.TesNet引入正交损失以鼓励类内的不同概念之间彼此正交,在Grassmann流形上构造透明潜在空间.Deformable ProtoPNet受TesNet启发,在原型零件之间引入正交损失,鼓励类内的所有原型零件彼此之间正交.CW模块使潜在空间中的所有滤波器的输出完全去相关,TesNet和Deformable ProtoPNet使同一类别内的概念彼此正交,这些约束要求太过绝对.在实践中有很多概念之间是高度相关或者有相对稳定的空间关系,如“飞机”概念和“天空”概念,“车身”与“车轮”的位置关系等.类比人脑识别物体机制,除了对物体本身各部位的识别外,通常还会参照物体所处环境以及参照物等信息.
因此,在保留类别相关概念依赖关系的前提下实现类别的分离,本文引入图卷积神经网络模块构造自适应解纠缠的透明潜在空间,设计了一种可解释的CNN分类器.采用无监督方式自动获取类别的基础概念信息,经可解释CNN分类器,自主完成不同类别及不相关概念之间的解纠缠.本文的主要贡献有2点:
1)引入图卷积神经网络模块,设计了类内概念图编码器(within-class concepts graphs encoder, CGE)自动获取类别基础概念,以图结构形式编码类内概念信息及概念之间的空间信息,学习类内基础概念之间的潜在交互.
2)在CGE编码器之后,设计了一个自适应解纠缠的可解释CNN分类器(adaptive disentangled interpretable CNN classifier, ADIC),通过设置三段阈值将潜在空间中的基础概念分为类内相关概念、类内不相关概念和不同类别概念3种类型,保留相关概念的依赖关系,在不相关概念之间添加强制性正交约束,从而实现类别概念自适应解纠缠.
1 相关工作
目前提高神经网络可解释性的研究主要分为对现有模型的事后可解释性分析(post-hoc explainability analysis)和直接构建固有事前可解释模型(ad-hoc interpretable modeling)2个方向.
1.1 事后可解释方法
事后可解释方法通常是借助模型额外的辅助信息对训练好的神经网络模型节点激活总体趋势的统计,是为了详述黑盒模型内部功能或决策原因而采取的一些行动.根据解释方法的解释目标是模型整体逻辑还是单个输入样本,可以将事后可解释方法分为全局解释和局部解释[7].
全局解释旨在解释模型内部的整体逻辑和工作机制[8-9],主要方法包括激活最大化、代理模型和概念激活向量方法等.激活最大化的思路是合成最大程度激活模型整体或感兴趣神经元输出的输入模式,即表示类别特征的抽象图像.激活最大化方法只能用于连续性数据,例如DeepDream算法[10].代理模型指的是构造一个可解释的更简单的模型模拟原始网络模型决策,包括网络压缩[11-12]、知识蒸馏[13-15]和直接提取[16-18].概念激活向量方法的主要思路是基于“视觉概念”,将一组具有相似特征的图像块或图像称之为一个“视觉概念”,例如一组包含条纹的图像块或图像即代表“条纹”概念.谷歌研究团队提出的TCAV[1]使用视觉概念进行全局解释,利用方向导数量化模型预测结果对沿着CAV方向变化的特定视觉概念的敏感度全局定量评估每个视觉概念对模型预测结果的影响度.TCAV需要预先定义感兴趣的概念,通过手动收集可以表示特定概念的示例集训练线性分类器,以习得CAV.针对TCAV需要手动收集视觉概念的问题,Amirata等人[2]提出了一种自动视觉概念提取方法ACE,通过图像块聚类定义新概念以自动提取视觉概念,然后利用TCAV对提取的视觉概念进行评估.Zhang等人[3]提出了基于可逆概念的ICE框架,采用非负矩阵分解可以为不同实例的相同特征提供一致的CAV权重,并提出一致的保真度测量措施.局部解释通常表现为可视化解释,即以显著图或热力图的形式突出显示输入图像中对预测结果起重要作用的像素区域[19-20].除此之外,Liu等人[21]还提出了稀疏对比编码(sparse contrastive coding, SCC), 通过模型每一层的隐藏状态得到词向量的特征重要性,自适应地将输入分为前景和背景的任务相关性, 采用监督对比学习损失提高模型可解释性和性能.局部解释方法可以大致分为基于扰动的前向传播显著性方法[22-25]、基于反向传播的显著性方法[26-29]和基于类激活映射的显著性方法[30-33]这3种类型.
1.2 事前可解释方法
事前可解释方法是从头设计可以自解释的固有可解释神经网络,自解释模型在应用的同时为用户提供模型输出的决策原因,无需添加额外的信息.事前可解释方法可以避免事后解释方法不忠实于原始模型的偏见,因为事后可解释分析中原始模型预测期间不使用事后解释,预测和解释是2个独立的过程.事前可解释方法可以进一步分为模型翻新和可解释表示[34].
模型翻新是指设计模型可解释组件或新的网络结构编码特定的语义概念,实现模型内置可解释性.例如,Chen等人[35-36]设计基于案例推理的神经网络结构来剖析图像,通过类别典型特征解释模型推理.Wang等人[5]提出可解释的深度模型TesNet,构造类别子空间分离的透明潜在空间,并约束类内概念彼此正交.Jon等人[6]提出Deformable ProtoPNet,提供空间灵活的可变形原型,可以捕捉到目标对象的姿势变化和环境,相比ProtoPNet[35]具有更加丰富的解释.Peng等人[37]提出了类别可解释的神经聚类(interpretable neural clustering, TELL)网络,其将k均值目标重新表述为神经层,实现了算法透明化.可解释表示通常是采用正则化技术在神经网络训练过程中学习更具可解释性的语义表示,从模型的可分解性、单调性和稀疏性等方面设计正则化项,实现模型内部表征解纠缠.例如,Zhang等人[38]设计了一种将每个滤波器响应约束到高层卷积层中特定对象部分的正则化损失,获取解纠缠表示.Lage等人[39]提出新颖的human-inthe-loop正则化项,通过用户评估已完成训练的多个网络模型的响应时间来衡量对模型的理解程度,选择用户响应时间最短的模型.Chen等人[4]提出一种概念白化模块,直接约束潜在空间,强制潜在空间的轴与预定义概念对齐,不同概念之间彼此正交.
基于模型翻新技术的TesNet和Deformable ProtoPNet以及基于可解释表示技术的概念白化模块,均以视觉概念为中间形式实现模型可解释图像识别.概念白化模块、TesNet和Deformable ProtoPNet强制约束类内基础概念彼此正交甚至基础概念块间彼此正交,约束过于绝对,忽略了基础概念之间可能存在高依赖度的潜在交互.另外,概念白化模块使用预定义概念,概念集和模型训练集相互独立.本文针对上述问题,设计了一种自适应解纠缠的可解释分类器,通过引入图结构学习类内基础概念特征及其之间的依赖关系,对具有不同依赖度的基础概念进行不同程度的正则化约束,在保留高依赖度基础概念之间潜在交互信息的同时,实现类内不相关概念及不同类别概念的解纠缠,即实现透明化潜在分类空间.
2 基础理论
2.1 ICE框架
基于概念的可逆解释(invertible concept-based explanations,ICE )框架是一个为预训练的CNN模型提供局部和全局概念级解释的框架,它采用非负矩阵分解提出非负概念激活向量(non-negative concept activation vectors, NCAV),为特征提供一致的权重和一致的保真度测量.
ICE框架主要由CNN模型分割、特征图降维器以及CAV权重评估这3部分组成,框架如图1所示.首先选定预训练CNN的目标层l,将其分解为概念提取器E和分类器C,概念提取也就是高维特征提取.n个输入图像I经特征提取得到尺寸为n×h×w×c(h和w为Al的大小,c为通道数)的特征图Al,El(I)=Al,对特征图Al采用矩阵分解进行降维,先将特征图Al展平为非负矩阵V∈R(n×h×w)×c.接着将V分为特征分数S∈R(n×h×w)×c′和有意义的NCAVP∈Rc′×c,V=SP+U;最小化残差U,minS,P‖V-SP‖Fs.t.S≥0,P≥0.最后,建立分类器C的线性近似,评估每个CAV的重要性.
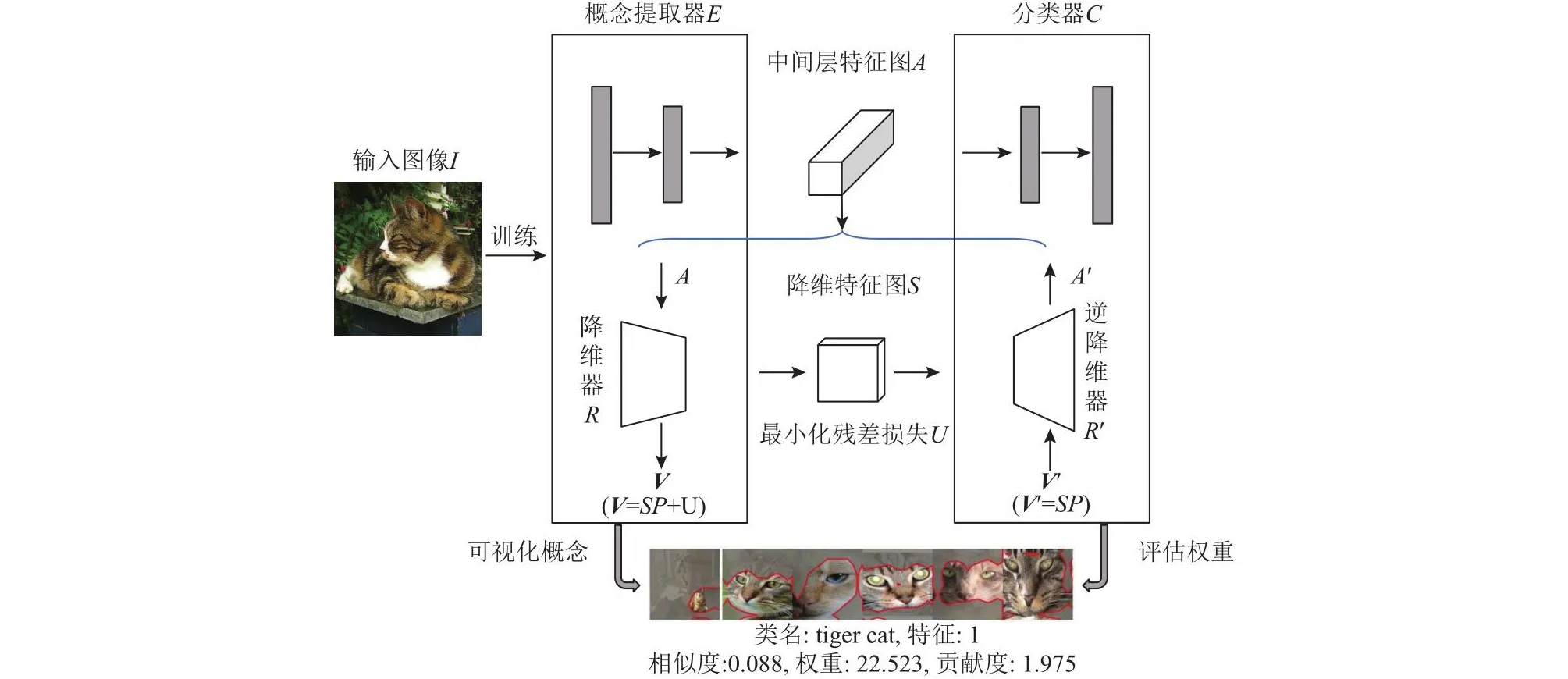
Fig.1 ICE framework图1 ICE框架
对于分类器C的特征重要性的评估,ICE采用TCAV[1]中求方向导数的方法.给定目标层l中已学习的NCAVPl,对于给定的特征图Al,针对k类的权重计算如式(1)所示.
ICE克服了自动概念提取算法ACE通过聚类特征图获取的概念权重不一致的缺点,自动获取高概念分数的类别视觉概念,但其依然需要依赖独立于原始模型的额外的分类器.针对此局限性,本文摒弃ICE的权值评估部分,不使用额外的分类器,设计可自解释的神经网络模型.
2.2 图卷积神经网络
图卷积神经网络(graph convolution neural network,GCN)是CNN针对非欧几里德数据(也称之为图数据)衍生出的网络.拓扑自适应图卷积网络(topology adaptive graph convolutional network, TAGCN)是Du等人[40]提出的针对有向图任务进行处理的GCN模型,其通过设计一组固定大小(大小为1~k)的可学习滤波器执行图上卷积,而不是对图上卷积取近似.
给定有向图G 上的信息及其关系表示为G=(V,E,¯),V 为顶点集,E 为边集,为图的加权邻接矩阵,表示顶点n到顶点m的有向边权值.第f个多项式第c个特征图卷积滤波器表示为为滤波器多项式系数,1Nl表示数值全为1的Nl维向量.输出特征图为来自不同大小滤波器的卷积结果的加权和,是从顶点j到顶点i的所有长度为k的路径,如式(2)所示.
其中,bf为可学习的偏差,Kl∈{1,2,3,…}即图滤波器的尺寸,表示从顶点j到顶点i的所有长度为k的路径权重之和,表示应用于顶点值的激活函数.
2.3 概念白化模块
CW模块是Chen等人[4]在2020年提出的一种直接约束潜在空间,强制潜在空间的轴与预定义的概念对齐是使潜在空间白化(去相关和归一化)的模块.CW模块作为插入模块可以替代CNN中的普通批归一化步骤,即BN层.
CW模块由白化(whitening)变换和正交(orthogonal)变换2部分组成.白化变换主要是对数据进行去相关和标准化,如式(3)所示.令Zd×n为n个样本的潜在表示矩阵,其中每一列zi∈Rd包含第i个样本的潜在特征.对于k个感兴趣的概念c1,c2,…,ck,预先定义k个辅助数据集Xc1,Xc2,…,Xck,Xcj中的样本为概念cj最具代表性的样本.
其中,Ψ为白化变换,µ是样本均值,Wd×d是白化矩阵,Σd×d是协方差矩阵.白化矩阵W不唯一,通过 零相位分量分析(zero-phase analysis,ZCA)和Cholesky分解等多种方式计算获得.
在对潜在空间进行白化变换后,还需在潜在空间中旋转样本,以使来自概念Cj的数据在第j个轴上高度激活.具体地,需要找到一个正交矩阵Qd×d,其列qj就是第j个轴,即正交变换,优化目标如式(4)所示:
其中,Zcj是Xcj潜在表示的d×nj的矩阵.此正交性约束优化问题通过Stiefel流形上基于梯度的方法[41]解决.
3 ADIC设计方法
3.1 类内概念图编码器
仿照人脑识别机制,用概念解释模型,首先需要的是量化定义概念.为了使解释忠于原始模型,不借助额外的分类器对概念进行重要性度量.本文使用ICE提取类别概念,但不评估概念分数,而是对类别内概念进行重新聚类编码,获取类别基础概念.接着,以有向无环带权图表示原始图像,基础概念为顶点,概念中心点间的连接为有向边,概念间的依赖度为有向边的权值.使用TAGCN学习类内基础概念的潜在交互,设计基于GCN的类内概念图编码器CGE.CGE用不同的概念成分或不同的概念交互解释类别差异.CGE的流程如图2所示.
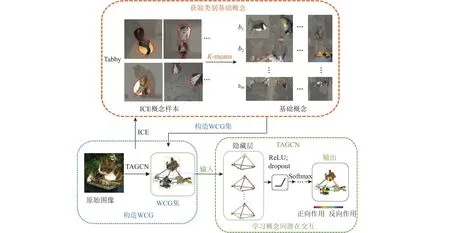
Fig.2 CGE flow chart图2 CGE流程图
首先,采用无监督的K均值聚类算法,对基于ICE生成的概念样本按类别进行重新聚类编码,获取类别基础概念为每一类的基础概念数,Cn为类别数.不进行基础概念的影响度评估,如图2上图所示.接着,构造类内概念图(within-class concepts graphs, WCG),将原始输入图像表示为有向无环带权图的形式,如图2左下图所示.以基础概念为顶点bj∈V;概念bj中心点到概念bi中心点的连接表示为有向边为加权邻接矩阵,表示顶点j到顶点i的有向边权值.最后,添加TAGCN模块,以WCG集为输入.基于TAGCN学习类内概念间的潜在交互,即基础概念之间的依赖度,如图2右下图所示.参照式(2),因为WCG集仅关心一阶路径的邻居顶点,故图滤波器的尺寸仅取1.因此,对于一个WCG,其第l层GCN层的第f个输出特征图的表示为:
其中,i表示第i个顶点,为滤波器多项式系数.向量xlf∈RNl指第f个特征(f=b1,b2,…,bm,基础概念bi)的所有顶点上的第l层的输入数据.Nl为第l层的顶点数.N(i)为顶点i的一阶相邻顶点集.揭示顶点i和j之间的依赖关系,为可训练的标量可以取任意实数值或复数值.表示对于类c,概念bi和bj之间的依赖关系.用计算顶点i与领域顶点j的权重之和.
本文在CGE中采用2层GCN结构,即TAGCN模块含有2层隐含层.依照TAGCN,每个GCN层包含16个图卷积滤波器,以提取图数据特征并捕获顶点间的聚合权值.在隐藏层之后添加一个ReLU激活,以进行非线性激活操作,使GCN层输入特征图的所有分量都为非负的.在ReLU激活之后添加dropout操作防止过拟合.在第2个GCN的dropout之后,使用Softmax函数获取顶点(概念)的逻辑回归值和概念间的相互依赖关系.
3.2 基于CGE的相关概念依赖性度量
给定一小批量输入图像集{x1,x2,…,xt}∈X,{y1,y2,…,yt}∈Y为它们的标签.X经过CNN特征提取子网络进行特征提取,随后经过ICE模块获取类别概念样本,实现类别预分离.再经过CGE对类别概念样本进行重新聚类编码,保留各基础概念簇的预分离类别信息.本文实验中在每个预分离的类别内随机选择4个基础概念构造一个WCG,将输入图像集X经过CGE编码器,转变为WCG集{G1,G2,…,Gt}∈G.
按照预分离的类别信息,逐类别输入GCN模块.使用TAGCN学习顶点间的聚合权值,对于每一小批量的WCG集 {G1,G2,…,Gt}∈G,进行式(5)的图卷积操作之后再使用一个非线性操作单元,如式(6)所示.
为了更好地获取基础概念之间的依赖关系,参照Christopher等人[42]捕捉概念间关系的思想,将WCG的顶点特征和边特征进行连接(concatenate)训练.基于式(5)的顶点特征,顶点特征和边特征的连接表示如式(7)所示.
3.3 自适应解纠缠的可解释CNN分类器
由CGE自动获取类别基础概念,并学习初步预分离类别内基础概念之间的依赖关系.设置概念间的依赖度阈值,将潜在空间中的类别基础概念划分为相关概念和不相关概念.保留相关概念的依赖关系,通过在不同类别概念和类内不相关概念之间添加不同的解纠缠约束,设计了具有自适应解纠缠潜在空间的可解释分类器ADIC,使不相关概念彼此正交、不同类别彼此分离,即实现潜在分类空间透明化.图3展示了基于ADIC的CNN框架.
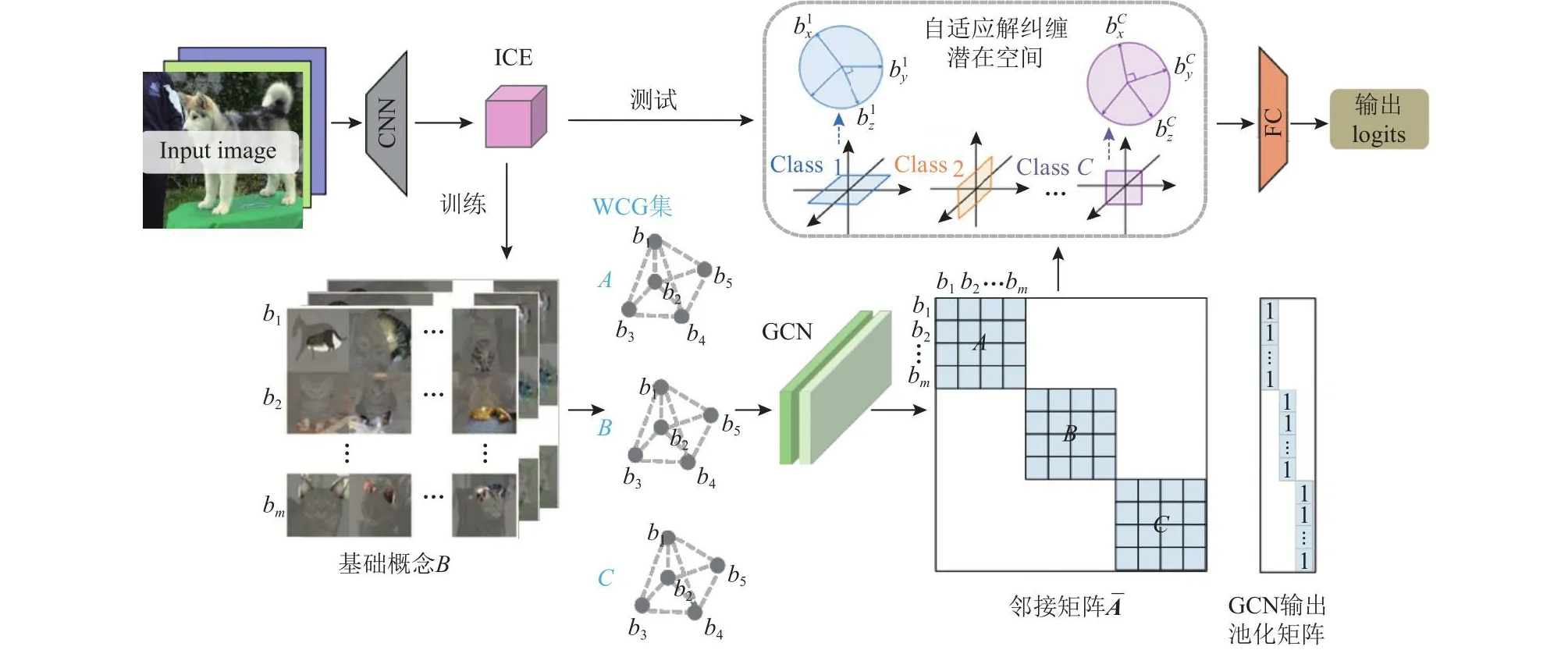
Fig.3 ADIC-based CNN framework图3 基于ADIC的CNN框架
图3所示的基于ADIC的CNN框架具体操作流程为:
1)设置类内基础概念的依赖度阈值.假定一小批量输入图像集{x1,x2,…,xt}∈X,输入CGE构造对应的WCG集{G1,G2,…,Gt}∈G,经GCN模块后将WCG集的邻接矩阵连接成一个稀疏的块对角矩阵,批量处理图像集.块对角矩阵的每一块对应一个WCG的邻接矩阵.对稀疏矩阵按图级输出进行池化,以池化矩阵形式表示;再通过GCN模块最后的Softmax函数获取基础概念(顶点特征)以及基础概念间依赖度(边特征)的逻辑回归值(logits),取值范围为[-∞,+∞].根据经验设置logits阈值,将输入图像集的所有基础概念分为3种情况:
其中,nodei表示顶点i的logit,edgeij和edgeji分别表示顶点i到顶点j的有向边logit和顶点j到顶点i的有向边logit.对于每个预分离类别的WCG集中的所有基础概念,若情况是式8(a)将被视为同类别的相关概念;若情况是式8(b)将被视为同类别的不相关概念;否则将被视为不同类别的概念,即式8(c).
2)实现式8(c)不同类别的基础概念正交分离.不同类别,即图3中的Class 1、Class 2和ClassC参照CW模块通过在Stiefel上进行曲线搜索,强制约束潜在空间中预定义概念彼此正交的思想.Stiefel流形是一种特殊的黎曼流形,由正交矩阵组成,D为单位矩阵.本文同样通过在潜在空间中寻找一个正交矩阵使不同类别的基础概念沿Q的不同列方向高度激活,采用在Stiefel流形上计算梯度的方法优化正交约束,进而促使不同类别的基础概念相互正交分离.
对于一批属于情况式8(c)的基础概念集{B1,B2,…,Bt}∈B(c),不同类别基础概念正交约束损失Lorth,其具体数学表达式如式(9)所示.
其中,qk为正交矩阵Q的第k列.Bk表示感兴趣的k类的基础概念集,bkj为k类的基础概念样本.Φ(·)表示特征提取器,参数为θ.得到概念样本的潜在特征zk∈Rm.Z∈Rm×nk表示nk个基础概念样本的潜在表示矩阵,zk为Z的列元素.类比CW模块,Ψ(·)为白化变换,具体表达形式如式(3)所示.
对于Stiefel流形上的参数矩阵优化,通常采用Cayley变换交替更新.本文采用Cayley变换[41]更新正交矩阵Q,具体数学表达式为:
其中,α为学习率,G为网络分类损失函数的梯度.
3)实现式8(b)同类别的不相关概念正交归一化分离.对于ClassC的不相关概念,即图3中的和.对于一批属于情况式8(b)的基础概念样本集以矩阵形式表示为B(b)∈Rt×d,为每一行为同一类别的一个不相关的基础概念,d为基础概念特征向量的维度.本文采用正交归一化损失,使类内不相关的概念之间彼此推开.
同类别不相关基础概念正交归一化损失Lorth_norm,其具体数学表达式如式(11)所示.
其中,Cb为存在符合情况式8(b)基础概念的类别数.Dt∈Rt×t为单位矩阵.‖·‖F为弗罗贝尼乌斯范数(Frobenius norm),即对矩阵内元素求平方和再开方.则表示求矩阵内元素的平方和.通过最小化Lorth_norm,实现不相关概念之间的分离.
4)实现基于基础概念的分类.在不同类别及不相关概念解纠缠分离之后,优化分类器的总体识别损失,以确保ADIC的分类准确性.本文以基础概念为单位,采用标准交叉熵损失实现最终分类.给定训练集,ADIC识别损失Lre,其具体数学表达式如式(12)所示.
其中,Cn为总类别数.yic表示输入样本xi的one-hot编码标签的第c个元素.g(·)表示分类器,参数为ω,最后一层满足归一化条件为经CGE编码器编码后预分离的第c类的基础概念集.
综上,ADIC嵌入相关基础CNN架构进行端到端训练时,联合优化目标可表示为式(13)的形式.
其中,λ1和λ2为网络训练过程中平衡各项的超参数.
训练完成后,实现分类空间的解纠缠,得到不同类别基础概念分离,以及同类别不相关概念分离的透明分类潜在空间.测试时,将测试图像中的潜在图像块与解纠缠之后的各类别基础概念依据相似度进行匹配,得到属于各类别的概念相似度分数;再判断潜在图像块之间的交互关系(WCG集的邻接矩阵,即边特征)和潜在空间中的基础概念之间的依赖关系是否相符,得到概念间关系的相似度分数;最后,将概念相似度分数和概念间关系的相似度分数的加权和作为最终的相似性度量,以此判断测试图像所属类别.
4 实 验
为了验证本文提出的自适应解纠缠分类器ADIC的有效性和可解释性,本文以VGG-16、ResNet-18和ResNet-50模型为基础CNN架构,搭载ADIC分类器,在Mini-ImageNet和Places365数据集上进行实验.分析搭载ADIC分类器的模型的性能表现,针对Mini-ImageNet特定测试实例实现可解释图像识别.
4.1 实验设置
Mini-ImageNet数据集为ImageNet的部分节选,共有100个类,每类600张RGB图像,常用于模型设计或者小样本学习研究,满足本文验证可解释分类器的需求.Places365数据集是一种遵循人类视觉认知原则的场景分类数据集,常用于对象识别、事物预测,以及理论推理等高级视觉理解任务.Places365数据集共包含365个独特场景类别,每类5 000~30 000张RGB图像.
本文实验环境具体为:CPU为Intel Xeon Gold 6148,实际内存63 GB,GPU为NVIDIA Tesla V100,显存16 GB.所有实验均采用PyTorch深度学习框架,使用CUDA 10.1.所有模型都从头开始训练,均采用动量为0.9的随机梯度下降算法对网络模型进行优化,权值衰减率设为0.000 1,输入批尺寸设为64,epoch设为100,初始学习率设为0.05.
4.2 基于ADIC分类器的CNN模型实验
本节验证ADIC分类器的解纠缠能力,将ADIC分别嵌入VGG-16、ResNet-18以及ResNet-50 这3种经典CNN模型中.在Mini-ImageNet数据集上训练6个模型:VGG16、ResNet18和ResNet50,以及添加了ADIC的ADIC-VGG16、ADIC-ResNet18和ADIC-ResNet50.由于本文主要采用正则化技术实现模型内部基础概念解纠缠,属于事前可解释表示方法.因此,与同样采用可解释表示技术的CW模块进行对比,在Places365数据集上训练6个模型:ResNet18和ResNet50,添加了CW模块的CW-ResNet18和CW-ResNet50,以及添加了ADIC的ADIC-ResNet18和ADIC-ResNet50.结果分别如表1和表2所示,通过2组对比实验,验证ADIC分类器的解纠缠能力,即分类能力.
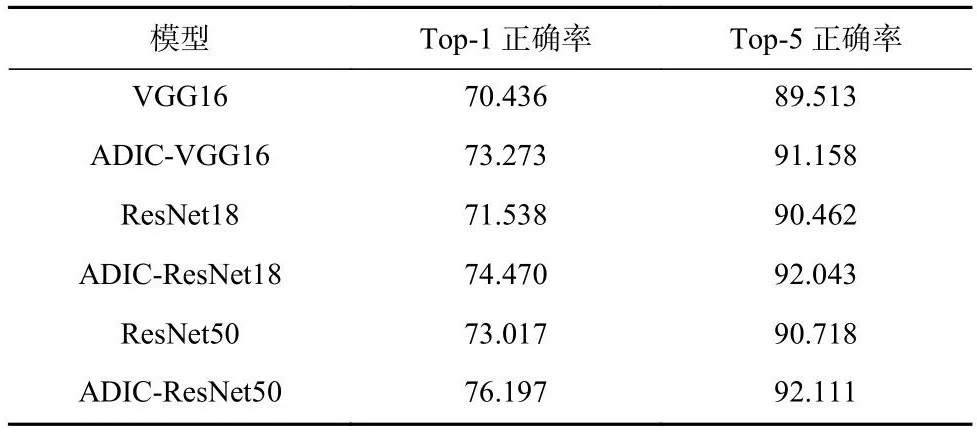
Table 1 Comparison Results on Mini-ImageNet Dataset表1 在Mini-ImageNet数据集上的对比结果%
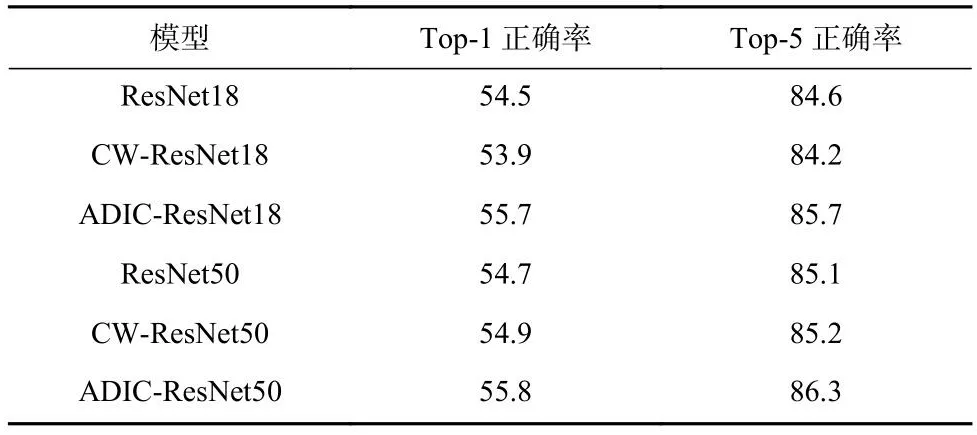
Table 2 Comparison Results on Places365 Dataset表2 在Places365数据集上的对比结果%
从表1可以看出,添加ADIC分类器可以提高原始模型的分类精度.相较于原始CNN模型,在 Top-1正确率上,精度提高了大约3个百分点;在Top-5 正确率上,精度提高了大约1.5个百分点.不同的网络结构结果具有一定差异.
从表2的结果可以看出,添加了CW模块的可解释CNN模型,即CW-ResNet18和CW-ResNet50,它们的精度与原始模型保持1%的差异.而添加本文设计的ADIC的CNN模型,ADIC-ResNet18和ADICResNet50,精度均高于原始模型和CW可解释模型.因此,得出ADIC分类器可以有效实现类别分离,提高模型性能.
另外,为了验证ADIC添加到网络不同深度层可能产生的差异,表3和表4分别展现在ResNet18和ResNet50的不同位置添加ADIC时模型性能的变化.其中,该数值表示ADIC添加到该数值的构建块之后,如2即ADIC添加到第2个构建块之后.
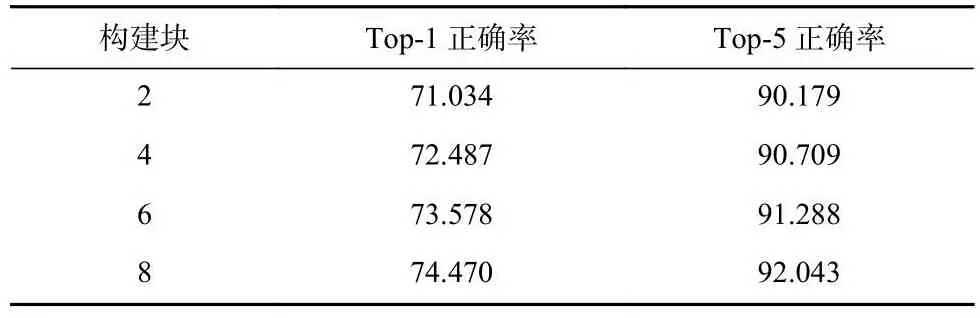
Table 3 Results of the ADIC Located in Different Depth Layers of ResNet18表3 ADIC位于ResNet18不同深度层的结果%
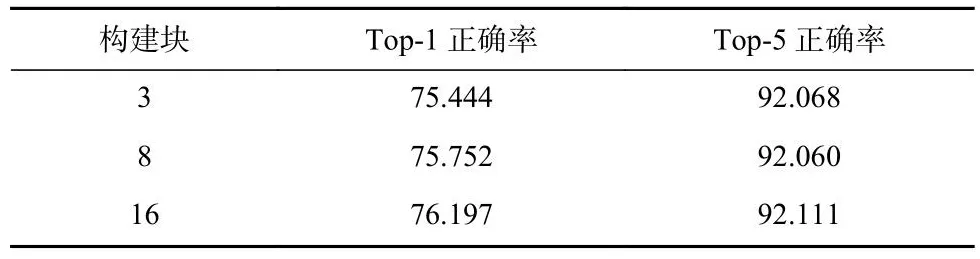
Table 4 Results of the ADIC Located in Different Depth Layers of ResNet50表4 ADIC位于ResNet50不同深度层的结果%
由表3和表4可以看到,将ADIC添加到ResNet更深层的性能表现优于将其添加到ResNet更浅层,精度随添加的深度增加而提升.因为层次越深,ADIC获取到的特征越丰富.因此,为了获得更好的模型表现,添加ADIC的最佳位置应选择在全连接层之前的最后一个卷积层后.
4.3 Mini-ImageNet相似实例的可解释识别
本节以添加了ADIC的ADIC-ResNet18为主干网络,针对Mini-ImageNet数据集中的相同物种以及具有相似特征的不同物种的特定测试图像,通过可视化测试图像中与对比类别相关的潜在部位(类别基础概念)以及部位之间的位置交互(基础概念之间的依赖关系),实现可解释的图像识别.对于相同物种,以Mini-ImageNet数据集中的Japanese_spaniel(n02085782)、Blenheim_spaniel (n02086646)以及Shih-Tzu (n02086240)这3类狗类样本为例.图4~6分别展示了这3类样本中的一张测试图像的可解释识别过程,分别可视化与指定类别相关度前4的潜在图像块(顶点根据潜在图像块相关度排名指定颜色)以及相关度前6的位置关系(有向边颜色取决于顶点间依赖值大小).
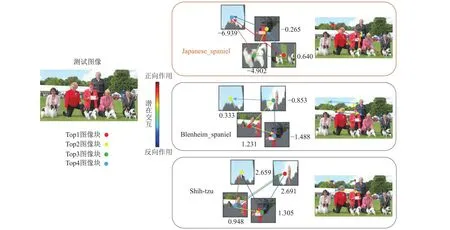
Fig.4 Interpretable image recognition of the Japanese_spaniel class test image图4 Japanese_spaniel类测试图像可解释图像识别
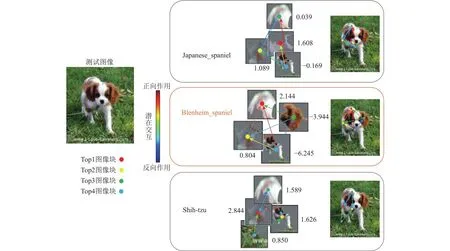
Fig.5 Interpretable image recognition of the Blenheim_spaniel class test image图5 Blenheim_spaniel类测试图像可解释图像识别
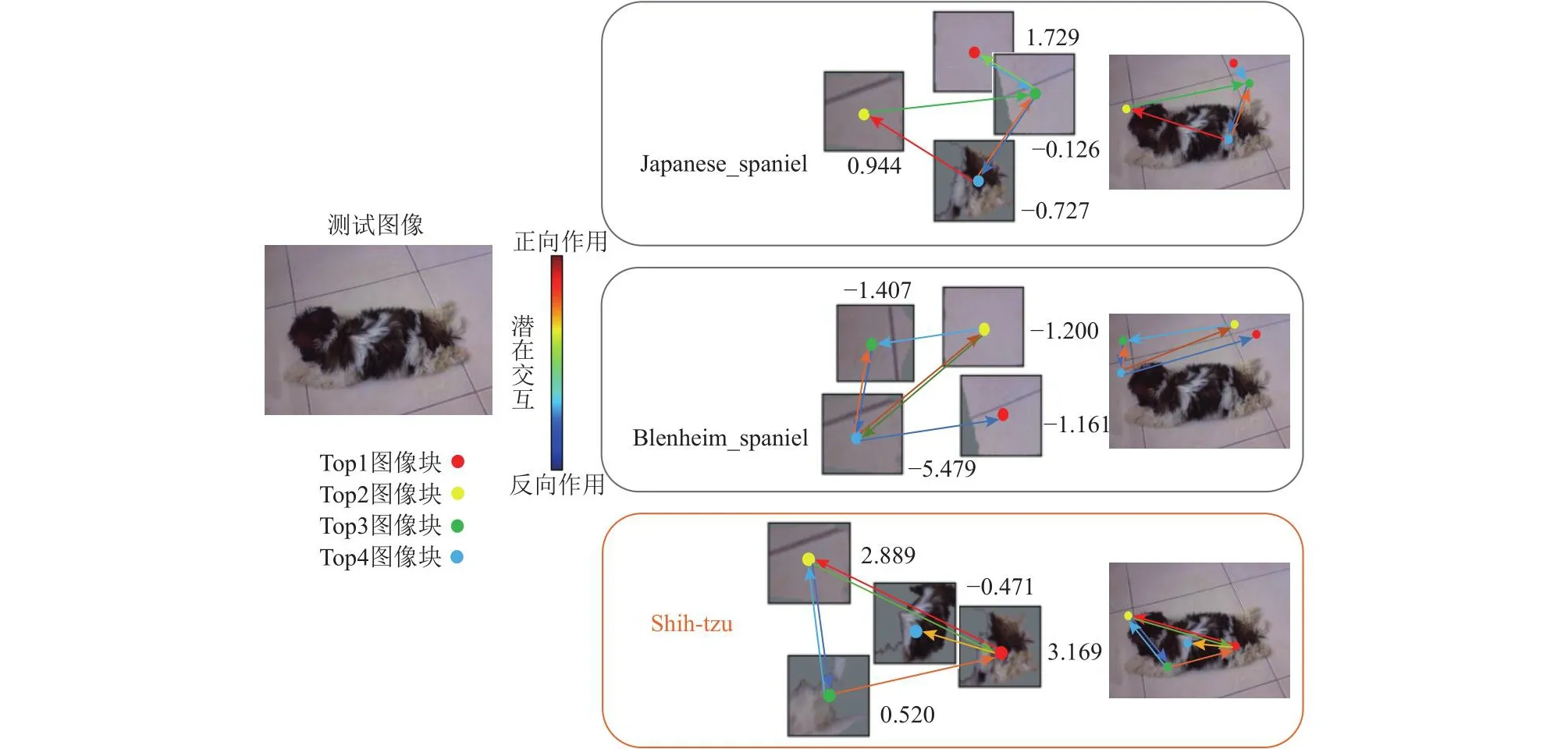
Fig.6 Interpretable image recognition of the Shih-Tzu class test image图6 Shih-Tzu类测试图像可解释图像识别
从图4可以看到,对于一张真实类别为Japanese_spaniel的测试图像,其潜在图像块与Blenheim_spaniel类和Shih-Tzu类的相关度均高于其对于Japanese_spaniel类的相关度值,且其判断真实类别的前4个图像块中包含天空和衣服这种和所判断的真实类别明显无关的图像块.但模型依然可以判断天空与狗之间,以及人类与狗之间的潜在交互关系(位置关系)与ADIC已学到的相关概念之间的依赖关系相符(有向边大多趋向于正向作用),而与学习到的针对Blenheim_spaniel和Shih-Tzu这2个类别内的相关概念的依赖关系不相符(有向边大多趋向于反向作用),因此模型最终可以正确预测该测试图像属于Japanese_spaniel类.
由图4~6的可视化结果可以得出,对于一张图像的识别,模型不仅关注感兴趣类别的基础概念(潜在图像块),还关注基础概念之间的潜在交互(位置关系).需要指出的是,由于Mini-ImageNet数据集中部分类别的训练图像包含较复杂场景,或者目标对象占整体图像区域的比例较小(例如图4中Japanese_spaniel在整张测试图像中的占比较小),可能会导致模型最终学习到的类别基础概念并不全部来自于目标对象本身.尽管如此,ADIC依旧可以准确学习到基础概念之间的位置关系,最终通过概念相似度和概念间的相对位置关系对图像所属类别进行最终决策.
对于具有相似特征的不同物种,以Mini-ImageNet数据集中的Malamute (n02110063)和Timber_wolf(n02114367) 以及Tabby (n02123045)和Snow_leopard(n02128757)这4张测试图像为例,4类2组样本的可解释图像识别可视化对比结果如图7和图8所示.

Fig.7 Interpretable image recognition of the Malamute class and the Timber_wolf class test images图7 Malamute类和Timber_wolf类测试图像可解释图像识别
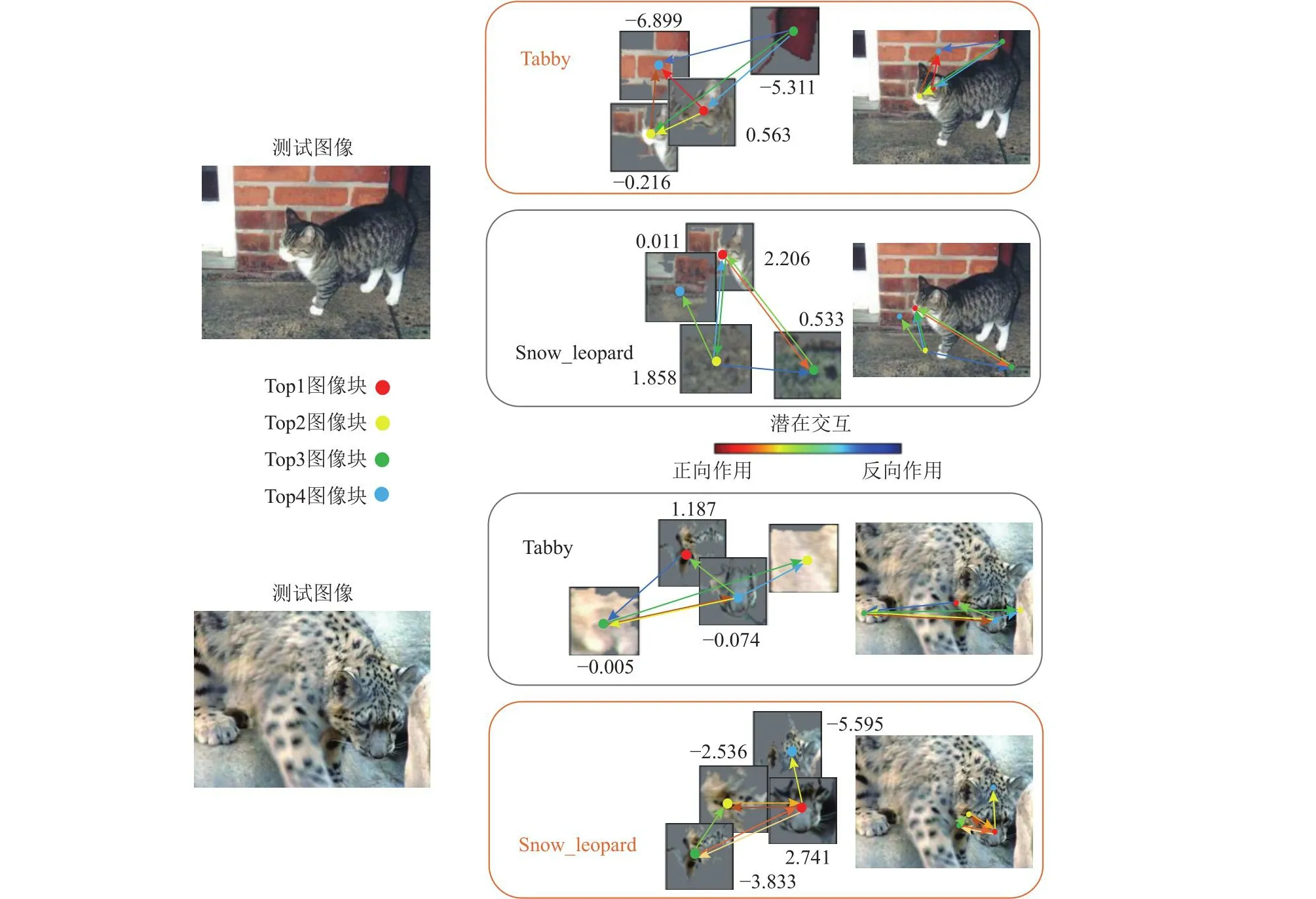
Fig.8 Interpretable image recognition of the Tabby class and the Snow_leopard class test images图8 Tabby类和Snow_leopard类测试图像可解释图像识别
从图7~8中可以看到,具有相似特征的不同物种对象,例如Malamute和Timber_wolf皮毛的颜色及分布接近,Tabby和Snow_leopard具有相似的猫科动物特征(花纹、胡须等).与相同物种的不同类别对象识别类似,模型匹配感兴趣类别的基础概念和基础概念之间的潜在交互,并做出最终预测.对于正确预测,模型能正确聚焦到测试图像中类别对象的关键部位(类别内相关概念),而对于其它错误类别,模型检测到的大多是背景信息或者其它类别信息(不相关概念).上述可视化图都是模型正确预测后的可视化结果,图9展示了模型对于一张Snow_leopard类测试图像错误预测的可视化结果.
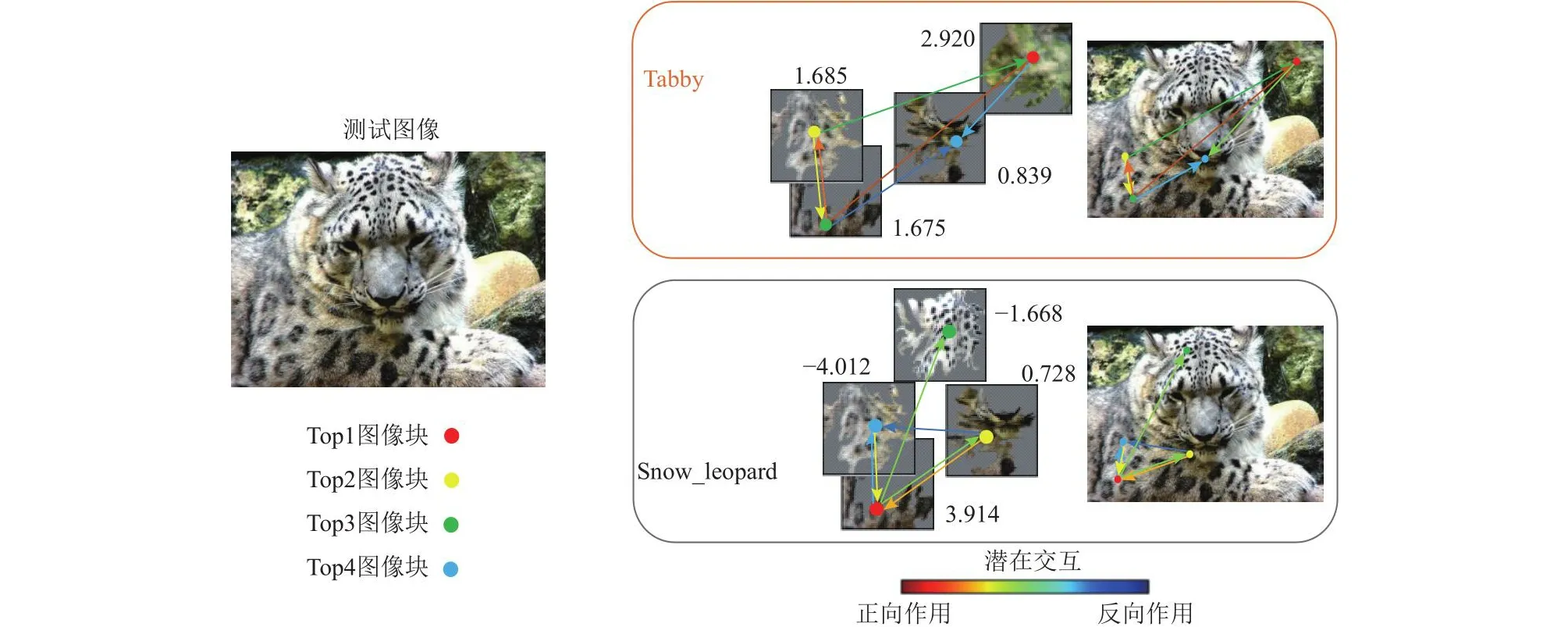
Fig.9 Visualization result of model error identification图9 模型错误识别的可视化结果
在图9中,模型将真实类别为Snow_leopard的测试对象错误识别为Tabby,可以看出模型提取到的该测试图像中的潜在图像块与Tabby类基础概念相关度高于Snow_leopard,并且潜在图像块之间一半以上的位置关系(正向作用)符合已学习的Tabby类相关概念间的依赖关系,因此模型做出了错误的判断.
综上,本节通过可视化模型决策依据(类别基础概念及概念间依赖关系),实现模型推理透明化,验证了模型的自解释性,即ADIC的自解释性.综合3.2节在Mini-ImageNet数据集上图像分类的实验结果,验证了添加ADIC分类器能进一步提高原始CNN模型精度,且保证了模型的自解释能力.
5 结 论
本文引入图结构设计潜在空间自适应解纠缠的可解释CNN分类器,在保留具有高依赖度的相关概念潜在交互的前提下,实现不相关概念的自动化分离.首先,利用K均值聚类算法自动获取初步预分离的各类别的基础概念.接着,引入图卷积模块设计类内概念图编码器,用有向无环带权图形式编码潜在分类空间中的特征图,获取类内基础概念的顶点特征及基础概念间的依赖关系.然后,提出了自适应解纠缠的可解释分类器ADIC,设置三段阈值将所有基础概念样本划分为同类别相关概念、同类别不相关概念以及不同类别概念3部分,通过添加在Stiefel流形上的正交矩阵优化和正交归一化损失,依次实现不同类别基础概念分离和类内不相关概念分离.最后,将ADIC分别嵌入VGG16、ResNet18和ResNet50这3种经典CNN架构,在Mini-ImageNet数据集和Places365数据集上进行图像分类实验和可解释图像识别实验,实验验证了ADIC的适用性和可解释性,且具有较好的解纠缠能力.
作者贡献声明:赵小阳提出主要研究思路,完成实验并撰写论文;李仲年提出指导意见,参与论文修订;王文玉协助完成部分实验,参与论文修订;许新征指导论文写作,修改和审核论文.
猜你喜欢
中等数学(2021年9期)2021-11-22
山东科学(2018年6期)2018-12-20
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
电测与仪表(2014年15期)2014-04-04
中国中医药现代远程教育(2014年16期)2014-03-01
食品科学(2013年8期)2013-03-11
