
基于VizQL的汽车工业数据可视化系统的设计与实现
2023-08-11 07:16:52杨国丹
现代计算机 2023年11期
杨国丹
(西南交通大学制造业产业链协同与信息化支撑技术四川省重点实验室,成都 611756)
0 引言
随着我国经济的快速发展,人民生活水平日益提高,汽车也走进了千家万户。中国汽车保有量继2020 年底赶超美国成为全球第一之后,继续保持高速的增长,2021 年中国的汽车保有量将突破3 亿大关[1]。随之产生的海量的、不同形式的、不同来源的数据应该如何更好地为汽车产业中的产品设计和研发、制造过程优化、营销和销售、服务和售后赋能是我们亟待解决的重要问题之一。
针对上述问题,本文设计了基于VizQL 的汽车行业数据可视化系统,帮助汽车研发人员更直观地了解市场需求、产品特性和竞争对手情况,有利于进行产品设计和研发;帮助企业进行生产计划和流程优化,提高生产效率和质量;帮助企业了解消费者需求、市场趋势和竞争对手情况,从而制定更合适的营销策略和销售计划,提高销售效率和市场占有率;帮助汽车企业和经销商提高售后服务质量,满足消费者需求。
1 相关工作
数据可视化是将数据转化为图形或图表等视觉元素的过程。通过将数据可视化,我们可以更直观地看到数据之间的关系、趋势和模式,进而更好地理解和分析数据。数据可视化可以使得大量的复杂数据更易于理解和沟通,使得数据分析更加高效、准确。
文献[2]提出了一个数据可视化推荐系统DeepEye,通过将一组算子转换数据集,以一种强制的方式自动可视化给定的数据集。文献[3]提出了一个可视化推荐引擎SeeDb,在给定的数据子集中,SeeDb智能地探索可视化空间,评估其最有趣的可视化推荐。
一些针对于实际场景的数据可视化分析系统,包括:邓智豪[4]通过数字驾驶舱的方式实现了自定义可视化分析引擎的系统,用户可以根据不同的业务场景来定制适合业务的可视化面板;丁超凡[5]使用Web 技术和数据可视化技术设计了交通数据可视化分析系统,通过多角度分析,呈现交通特性和演变规律。
2 VizQL
2.1 VizQL概念
VizQL 是由斯坦福大学的Polaris[6]系统演化而来,它是数据可视化查询语言,它允许用户通过拖放和点击的方式直接操作可视化元素,从而轻松地探索和分析数据。VizQL将用户的可视化请求转换为SQL 查询,然后将查询结果渲染为交互式可视化。通过VizQL,用户可以直接在可视化过程中进行数据操作,例如对图表中的数据点进行筛选、排序、聚合等操作,而无需手动编写代码或执行SQL 查询。这种交互式的数据探索方式使得数据分析变得更加直观和灵活,降低了使用者的技术门槛,并帮助用户更快速地发现数据中的关键信息。VizQL的主要优势之一是其高度的可扩展性。它支持多种数据源,包括关系型数据库、非关系型数据库、文本文件、Web 数据等,并且可以将多个数据源组合在一起,以便更好地分析和理解数据。此外,VizQL还支持自定义计算字段、多维度分析、动态参数控制等高级功能,以满足各种数据分析需求。
2.2 VizQL的工作原理
2.2.1 表代数
首先需要定义一个正式的机制来指定表配置,为此定义了一个代数。一个完整的表配置由这个表中的三个单独的表达式组成。其中两个表达式定义了表的x轴和y轴的配置,将表划分为行和列。第三个表达式定义了表格的z 轴,它将显示划分为多个层次。
这个表代数中的操作数是数据库的维度和度量字段的名称。我们将用X、Y和Z来表示维度场(如数据库表中的企业名称、企业地址等),用P、Q和R来表示度量场(如数据库表中的企业年收入、月收入等)。我们以下述方式为每个字段分配有序集:对维度字段,我们分配字段的维度域的成员;对度量字段,我们分配包含字段名的单个元素集。
将集合分配给符号反映了两种类型字段在表结构中的编码方式的差异。维度字段将表划分为行和列,而度量字段将在空间上编码为窗格中的轴。在代数中,一个有效的表达式是一个由一个或多个符号组成的有序序列,在每对相邻的符号之间有运算符,并用括号来改变运算符的优先级。代数中的运算符是交集(×)、阈值(/)和关联(+),按优先顺序列出。每个运算符的精确语义是根据其对操作数集的影响来定义的。
其中关联的运算为
交集的运算为
阈值运算为
其中:R表示要分析的数据集;r被定义为一条记录;X(r)表示记录r的字段X的值。
对每个运算符使用上述集合语义,代数中的每个表达式可以简化为单个集合,集合中的每个条目是零个或多个维度值与零个或多个度量字段名的有序连接。我们称这个表达式的集求值为规范化集形式。表达式的规范化集合形式决定表的一个轴:表轴被划分为列(或行或层),因此规范化集合中的集合条目和列之间有一一对应关系。
2.2.2 生成数据库查询
通过上述生成可视化规范查询对应于生成数据库查询,该查询选择用于分析的数据子集,然后筛选、排序将结果分组到窗格中,最后将数据传递给图形编码。
首先我们先选择数据源,对于维度字段X,用户可以将字段的域的子集指定为有效。如果filter(x)是用户选择的子集,那么表示x的过滤器的关系是Xinfilter(X)。
对于度量字段P,用户可以将字段的域的子集定义为有效。如果min(P)和max(P)是这个子集的用户定义范围,那么表示P的过滤器的关系是(P≥min(P)&P≤max(P) )。
所以我们可以将上述关系表示为第一阶段的SQL语句:SELECT*WHERE{filters} 。
其次将检索到的记录划分为对应于表中每个窗格。正如前文所讨论的,表轴表达式的规范化集合形式决定了表的配置。表被划分为与这些集合中的条目相对应的行、列和层。假设Row(i)是表示第i行选择标准的代表,Col(j)是表示第j列选择标准的代表,Layer(k)是表示第k层选择标准的代表。如果表的y轴是由规范化集定义的:{x1y1P,x1y2P,x2y1P,x2y2P}。
那么可以通过一下查询检索到要分区到第i行、第j列、第k层交汇处的窗格中的记录:
最后一步就是转换每个窗格内的记录。如果可视化规范包括聚合,则必须为数据库中的每个度量值分配聚合运算符。如果用户没有指定运算符,那么我们默认地为度量值设定聚合运算符为SUM。度量值的运算符由两个组成,定义为
所以最终形式的SQL语句为
3 系统展示
本文基于VizQL 开发了汽车工业数据可视化系统,并对该系统的应用进行情况说明。
我们根据指定的数据源,选择不同的场景需求,可以指定以下可视化分析界面,不同类型界面见图1、图2、和图3。
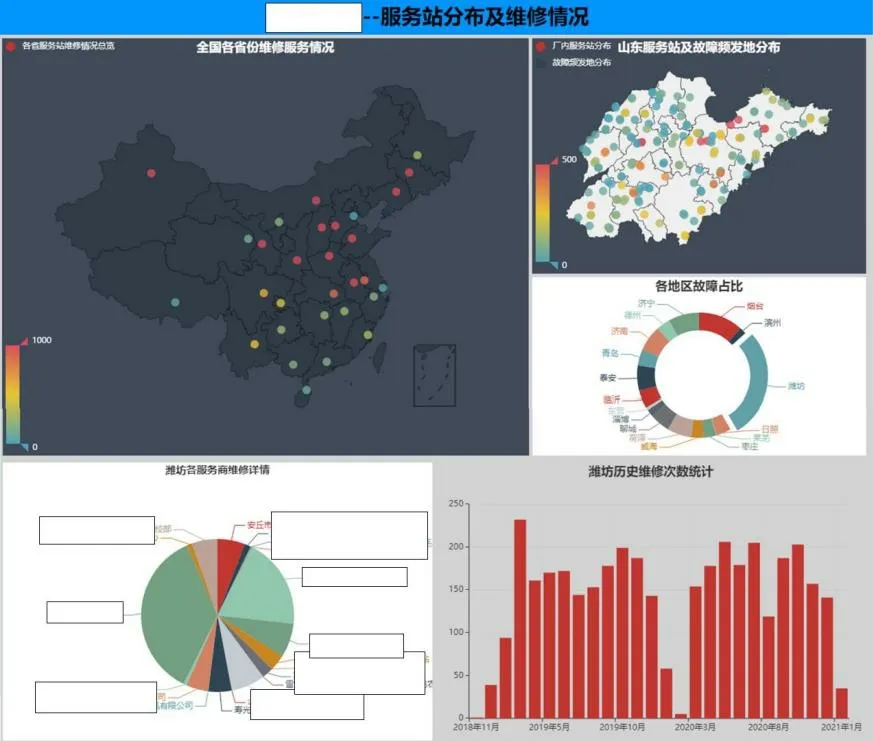
图1 服务站分布可视化分析界面
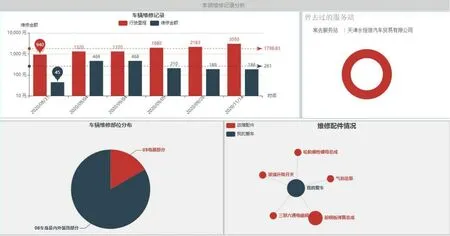
图2 维修售后数据可视化分析界面
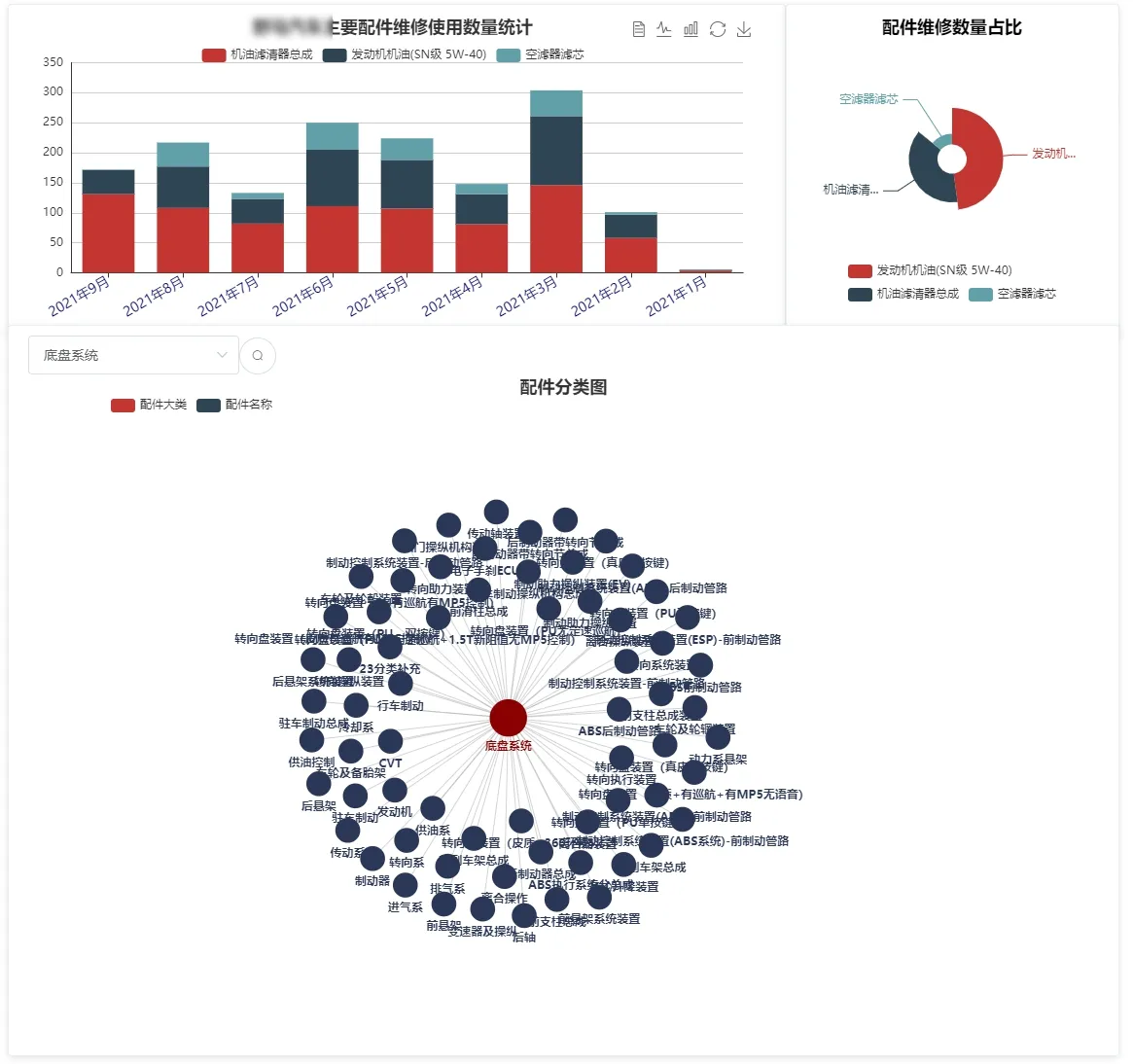
图3 实体关系可视化分析界面
4 结语
本文提出了一种基于VizQL 的汽车行业数据可视化系统,通过利用VizQL 语言实现对汽车行业数据可视化的转换,使用户可以获得更丰富的可视化界面和分析界面。在未来的工作中,交互式响应率和交互历史是一个值得关注的问题。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17 09:07:36
科学24小时(2021年10期)2021-10-09 23:09:37
数学物理学报(2020年2期)2020-06-02 11:29:10
安顺学院学报(2020年1期)2020-04-05 10:57:20
现代计算机(2019年6期)2019-04-08 00:46:50
图书馆建设(2015年10期)2015-02-13 03:48:27
新世纪图书馆(2014年7期)2014-09-19 12:20:40
价值工程(2014年17期)2014-04-16 03:29:20
图书馆建设(2014年3期)2014-02-12 15:41:35
长春大学学报(2012年10期)2012-09-21 07:14:12
