
算力服务原生技术体系架构研究与实践
2023-08-08 10:22:32唐雄燕霍龙社崔煜喆
信息通信技术 2023年3期
唐雄燕 曹 畅 张 岩 杨 洋 霍龙社 崔煜喆
1 中国联通研究院 北京 100048
2 下一代互联网宽带业务应用国家工程研究中心 北京 100048
引言
近年来,伴随着数字经济的蓬勃发展,互联网、大数据、人工智能同各行各业深度融合,产生的数据量和计算量呈指数爆发,对于目前海量、分散的应用场景,数据的处理与分析需要强有力的算力提供支撑,加速了“云、边、端”为主的算力资源的高效协同,同时服务形态也由最初的云服务向算力服务演进,促进算力技术发展走向多架构并存的道路。
异构算力广泛应用带来了软件层面以及硬件、芯片层面新的技术问题,为算力资源的高效利用以及应用的快速发展提出了挑战,亟需一套解决方案来屏蔽异构算力、异构代码和异构运行环境差异所引入的软硬件兼容问题,以便提高资源利用率,降低开发以及维护成本。基于此背景,本文提出了算力服务原生技术体系,阐述了功能需求、整体架构等相关内容,并在AI算力服务原生方面进行了初步实践,自主研发CubeAI智立方AI算力服务原生系列软件并开源。
1 算力服务原生背景与定义
1.1 背景
需求发展驱动:万物互联使得算力需求日益剧增[1],业界逐渐形成了以“云、边、端”为主的新型算力资源协同和发展的格局[2],构建了多层级的算力基础设施。计算服务对算力的需求促进了算力的多样性[3]和算力性能的不断提升,在不同的应用场景中,期望异构算力协同处理,以发挥最大化的计算效力。尤其对于新兴的人工智能[4]应用场景,面对繁杂多样的计算需求,需要使用遍布在云边端泛在部署的异构算力资源,使业务应用能平滑地在各级算力资源上进行迁移和运行。如何充分利用海量的异构算力资源,是当今计算服务发展的关键点。
技术发展驱动:算力最初的形态为通用CPU,为满足日益丰富的应用场景,多类芯片相继涌现,算力形态呈现螺旋式发展状态。面对AI、网络虚拟化等场景的出现,通用CPU无法满足运算性能的需求,因此专用芯片逐步发展[5];随着当前深度学习等应用场景规模不断扩大和算法逐渐多样化,基于特定算法和流程定制的ASIC(Application Specific Integrated Circuit)无法满足业务需求,针对智算场景的GPU出现并逐渐向通用GPU[6]发展。专用算力虽然满足不同场景中的应用需求,但带来收益的同时也带来系统“碎片化”的挑战[7]。面对高性能计算、人工智能等应用场景的增加,芯片的发展未来将会是专用算力与通用算力并存的形态。
服务形态演进驱动:通用算力为主的云计算技术已成为赋能业务数字化转型的关键[8],但随着企业数字化程度不断加深,用户对算力的感知、度量和利用率等方面提出更高的要求,如图1所示,与此同时云服务也逐渐向算力服务演进[9]。虽然云原生技术为应用在通用算力下的部署提供了支撑,但由于异构算力自身的架构差异,软件与算力的高度定制化等问题,仍无法真正实现基于异构算力的应用部署。因此,要实现真正从代码到应用都屏蔽资源架构的差异,不仅仅要求面向算力服务软件的能力支持,同时面向算力服务基础设施,需要对异构算力进行统一抽象。
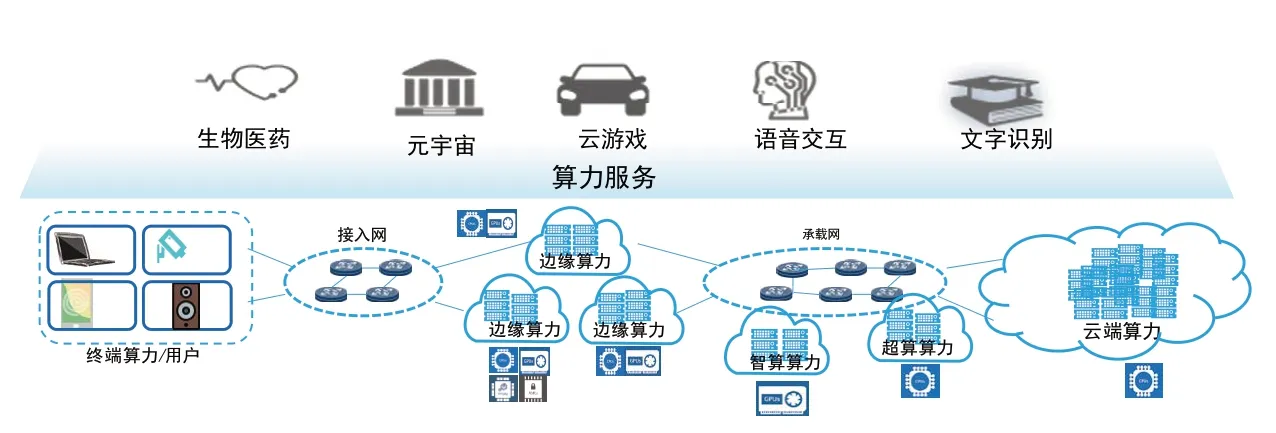
图1 服务形态演进,云服务到算力服务
1.2 算力服务原生定义
算力服务原生是指屏蔽异构代码和异构运行环境间的差异,将一套应用代码封装为规范化的互联网服务,并可部署至任意位置和任意类型的算力上,供用户使用规范化互联网接口随时随地调用和消费。
在此理念下,算力服务原生应实现大规模异构计算资源的统一输出,更加普适性地满足不同量级或不同硬件架构下的算力需求。算力服务原生要统一算力输出的服务化标准,促进算力服务标准化,避免软件被固定形式的算力需求所捆绑,实现算力应用的标准化落地,解决异构算力代码不通用、算力服务化成本高等问题,提高算力在各类场景下的应用效率。
面向算力服务软件,算力服务原生将所有应用代码进行服务化封装,为用户提供统一规范化的服务访问接口和模式,使得所有应用代码(及其依附的算力设施)能够以服务的形式被用户所访问和使用,实现“代码即服务”“算力即服务”,简化普通用户使用和消费应用代码和算力设施的操作和模式。面向算力服务设施,算力服务原生屏蔽应用异构算力引入的复杂软硬件差异,实现同一应用同一套代码,在无需改动的条件下,即可自动适配所有厂家的所有算力设备,应用在异构算力间无感知迁移,达到一套代码,全网通用的目的。
2 算力服务原生与周边技术关系
算力服务原生与云原生、算力网络、人工智能有着千丝万缕的关系,如图2所示,三者共同作用,相辅相成,为用户提供端到端服务的目标进行支撑。
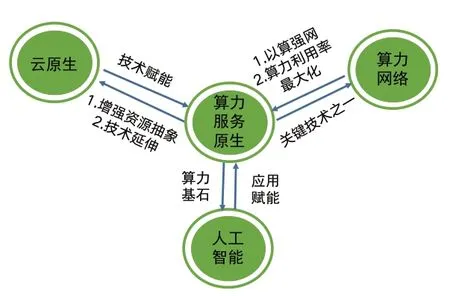
图2 相关技术关系图
2.1 算力服务原生与云原生
算力服务原生是云原生向底层算力资源的延伸。以FaaS等Serverless技术[10]为代表,云原生技术重新定义了PaaS,用户无需关注虚拟机、资源分配、应用扩缩容逻辑等。进一步地,算力服务原生是云原生的扩展,通过异构算力池化、异构算力运行时和统一编程模型等,提供算力即服务的新型服务能力,实现同一套代码在异构算力上无感知迁移和部署。在AI业务特性方面,算力服务原生提升异构算力资源利用率,满足AI业务日益增长的算力需求。在服务特性方面,算力服务原生支持同一套代码基于异构算力资源部署,大幅降低用户跨异构算力的应用开发和部署成本。
算力服务原生增强了云原生的异构资源抽象能力。云原生技术为上层应用程序提供快速部署、弹性扩缩容和动态调度能力,但对于xPU、ASIC、FPGA等异构算力的管理存在一定瓶颈。算力服务原生通过资源池化、标准运行时和统一编程开发框架等技术,实现对异构算力的统一抽象,与虚拟化、容器化等技术相结合,能够有效扩展云原生技术在异构算力下的服务管理、扩缩容能力、应用运维等能力。
云原生作为算力服务原生的子集为算力服务赋能,其作为计算资源面向行业用户的服务通道,为算力服务原生提供通用算力以及微服务等能力,将传统的、有状态的粗粒度应用程序组件拆分解耦,以分布式的形态部署到基于容器化的异构算力设施上,支持将微服务化后的细粒度组件部署到最适合的算力上,最大化异构算力资源服务能力。
2.2 算力服务原生与算力网络
算力服务原生支撑网络技术实现以算强网。SDN与NFV[11]相结合,提供了不依赖于专用硬件的动态灵活的网络管理能力,以满足算力网络对网络的协同性、灵活性、确定性等要求。在SDN+NFV架构下,借助算力服务原生技术,能够进一步利用异构算力资源,将部分加解密、IO吞吐等网络功能卸载到GPU、FPGA等异构化加速设备中,实现跨异构算力的高效灵活的网络调度,同时减少由于网络设备数量众多、架构差异化导致的维护负担。
算力服务原生支撑算力网络实现泛在调度。面向国内外异构算力芯片以及云边端、智算、超算等多样化算力供给方式,算力网络以算力服务原生技术为中间层,向下屏蔽异构算力在指令集、开放框架的差异性,向上提供统一的管理、调度和开发接口,有效降低算力网络对异构算力的纳管和调度复杂度,减少应用迁移调度中的代码重构工作量,在一定程度上保证应用跨异构调度后的整体服务质量。
算力服务原生是算力网络的关键技术之一。算力服务原生依托算力网络,能够充分发挥其在释放行业生产力、优化基础设施建设、提升异构资源利用率的优势,实现算力网络中异构算力布局的合理规划,有效改善当前国产化算力应用生态不完善、发展路径孤立等问题。
2.3 算力服务原生与人工智能
算力服务原生为人工智能大模型训练提供算力基础。随着大模型的推广应用,语言和多模态等相关领域AI模型的参数量和训练数据量巨大,需要强大的算力支撑[12]。基于算力服务原生技术,可以提升训练过程中对硬件的使用效率,加速模型训练的迭代速度,同时有望实现单个数据中心内的异构算力芯片融合协同。未来在芯片间高速互联以及远距直接数据存储(Remote Direct Memory Access,RDMA)[13]等网络技术的辅助下,算力服务原生技术与网络能力深度融合,能够实现多个数据中心间通过数据并行或模型并行的方式协同完成单个大模型的训练。
人工智能能够为算力服务原生赋能。人工智能技术[14]能够在用户服务质量感知、应用与异构算力的匹配、服务性能预测、资源的最优调度、服务编排等方面为算力服务原生提供最优解。
3 算力服务原生技术体系
3.1 功能需求
要实现真正从代码到应用都屏蔽资源架构的差异,不仅仅要求面向算力服务软件的能力支持,同时面向算力服务基础设施,需要对异构算力进行统一抽象。如需要对各种编程语言(Java、Python等)、各种工具平台(PaddlePaddle、PyTorch等)编写的代码进行兼容,提供统一的封装方式,实现无差别接入;对异构算力进行统一化度量,解决软件层面以及硬件、芯片层面新的技术问题;同时,应用异构互联的网络将硬件与硬件、硬件与软件、软件与用户进行互联互通,达到“一码通用”的算力服务软硬件生态。算力服务原生体系架构需要满足以上需求,并实现以下功能。
1)代码即服务、算力即服务:基于统一引擎,以简洁、规范、易用的方式将任意应用程序代码进行服务化封装,能够调度和部署至云边端等任意位置,并为用户提供简洁、规范、易用的服务访问模式和工具。
2)统一编程模型:基于异构计算架构设计的编程模型,能够让开发者可以使用同样的编程语言和工具来编写程序,而无需考虑底层硬件的细节。
3)异构算力运行时:通过提供一种跨平台的、高性能的计算环境,允许计算机程序在异构算力资源上平滑地流转运行,使得开发人员可以轻松地利用异构算力,提高计算性能和效率。
4)异构算力池化:基于池化技术将CPU、GPU等多种不同类型、不同指令集、不同制程架构的计算资源通过池化技术进行集中管理和调度,形成一个纳管异构计算资源的统一资源池。为不同的计算任务提供高效、灵活、弹性和可扩展的计算资源,提高计算效率和性能。
5)异构算力互联:支撑算力抽象层获取异构资源池化层统一标准化计算资源,提升程序在异构算力资源上平滑地流转的能力,使得开发人员可以无感地利用异构算力池化层的计算资源。
3.2 算力服务原生体系架构
如图3所示,从应用对外提供服务所需的技术能力支撑维度,本文提出算力服务原生由软件到硬件自顶向下可分为五层,即应用层、服务层、算力抽象层、异构算力池化层以及设备层。其中算力服务原生技术栈包括:服务层、算力抽象层、异构算力池化层。应用对外提供服务,既依赖软件层面将代码服务化,同时依赖能够执行服务的算力。在本架构中服务层提供将代码、模型封装为微服务的能力,异构算力池化层用于对异构算力进行统一纳管,算力抽象层则起到承上启下的作用,将代码与算力解耦,实现同一套代码可在异构算力资源上平滑流转执行。
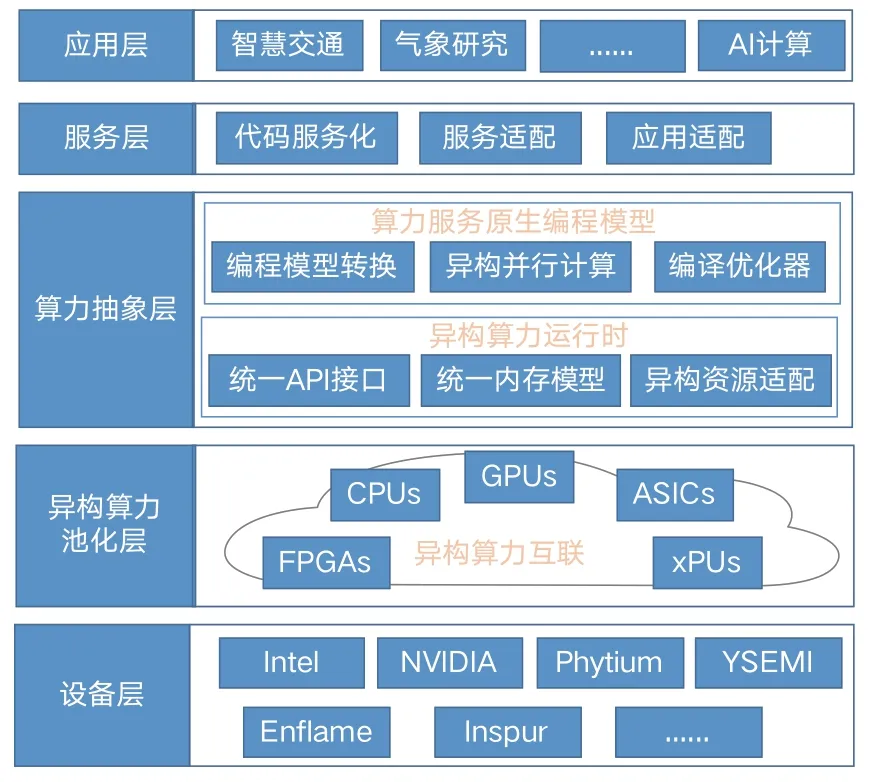
图3 算力服务原生总体架构
1)服务层
服务层维度的算力服务原生,旨在达到代码即服务,算力即服务的目的,所谓“代码即服务”,就是指开发者开发出一套应用代码之后,随即变成可部署至任意位置的规范化互联网服务,供用户使用规范化互联网接口随时随地调用和消费。由于服务化后的应用程序是依附在算力资源(设备)上运行并向外提供服务的,因此又达到了“算力即服务”的目的。
2)算力抽象层
算力抽象层是由算力服务原生编程模型和异构算力运行时组成,其中算力服务原生编程模型基于原生算力统一API、原生编程模型范式以及编译优化部署工具,提供了一种统一的编程方式,开发者可以使用一种或多种高级语言进行应用开发,编译器、库和工具可以将程序转换为特定硬件上的可执行代码,并利用硬件特性来实现高性能计算,实现编程语言对硬件透明化。
异构算力运行时旨在解决传统的计算设备之间由于架构、指令集、内存模型等差异,引发不同计算设备之间的互操作性问题。异构算力运行时通过提供一种跨平台的、高性能的计算环境,允许计算机程序在异构算力资源上平滑地流转运行,使得开发人员可以轻松地利用异构算力,提高计算性能和效率。
3)异构算力池化层
算力资源池通过对底层异构硬件设备进行统一建模,使其不同类型的计算设备统一标准化,同时结合异构算力互联能力,实现异构计算资源的一体池化管理,面对应用层不同的计算任务需求,提供高效、灵活的计算资源调度,同时计算资源的弹性和可扩展能力为业务应对潮汐场景下的服务质量保障提供了有效的应对途径。
4 算力服务原生实践
为了实践算力服务原生基本理念,近年来联通研究院在面向AI的算力服务原生领域展开了较为深入和持续的研究和探索,开发了一套集AI模型自动化服务封装、发布、共享、部署和能力开放等功能于一体的开源AI算力服务原生平台和工具集——CubeAI智立方,实现“代码即服务”和“算力即服务”等理念。
代码即服务:AI模型推理程序经算力服务原生化封装后,随即变成可对外提供函数型API和Web可视化等访问接口的交互式在线网络服务,改变传统模型推理大多采用的静态命令行调用、文件进文件出等非用户友好模式。
算力即服务:经服务化封装的模型推理服务程序一经部署之后,随即启动运行并向用户提供在线AI算力服务,算力天生能够以最为方便、快捷、友好的方式为用户所使用,改变传统AI算力只能够通过命令行和批量式任务等方式进行调度使用的非友好模式。
如图4所示,CubeAI智立方AI算力服务原生开源体系由一系列基础开发工具、应用服务平台和模型示范库等组成。

图4 CubeAI智立方AI算力服务原生开源体系
ServiceBoot服务原生引擎是支撑AI算力服务原生的最基础底层工具软件。使用寥寥几行代码,即可将普通Python程序封装成为可提供高并发函数式HTTP访问的云原生微服务,特别适用于对AI模型推理程序进行服务化封装。ServiceBoot目前同时提供函数式API、WebSocket、Web可视化等多种接口访问方式,以及JSON、二进制、文件等多种数据交换格式。其中Web可视化接口同时支持基于JavaScript的前端开发框架和基于Gradio和Streamlit软件的Python前端框架,既可以开发精美复杂的大型AI应用,又可以使用短短几行Python代码编写优雅的AI交互界面。
CubePy微服务框架是基于ServiceBoot开发的云原生微服务应用基础开发框架,提供微服务注册与发现、统一数据配置、统一内容服务、API网关、用户认证授权、前端主门户模板等基本功能和组件。使用CubePy微服务框架开发出来的应用系统天生可运行于Kubernetes等云原生网络环境,大大提高开发者和运维者的工作效率。
CubeAI系列软件的核心部分是基于CubePy微服务框架和ServiceBoot引擎开发的CubeAI智立方平台,其组网架构如图5所示,又可分为AI模型共享交易和AI模型算力服务两个子平台。经使用ServieBoot进行服务化封装后的AI模型,可以Docker镜像等微服务形式一键发布至AI模型共享交易平台,供用户浏览、评价和交易。在AI模型共享交易平台中获得授权使用的AI模型,可一键部署至AI模型算力服务平台,立即以函数式API或可视化Web等多种接口模式向用户提供AI模型推理服务。除了CubeAI自建的AI模型算力服务平台之外,还可将AI模型共享交易平台中的AI模型一键部署至互联网可访问的任意其他AI算力服务平台,例如鹏城云脑、ModelScope、HuggingFace等。

图5 CubeAI智立方平台组网架构
CubeAI打造了模型示范库,支持“模型即服务”和“源码一键入云”等AI算力服务原生理念。该模型库中所有模型都是采用ServiceBoot对AI预训练模型进行服务化封装的服务原生模型,支持以源代码方式一键自动发布至CubeAI平台进行共享和部署,同时也可使用CubeAI Deployer等工具一键部署至任意其他算力服务平台或者个人服务器。CubeAI模型示范库目前已拥有上百个各类AI模型,使用的AI算法类型包括经典机器学习、深度学习、图像处理、计算机视觉、自然语言处理、多模态大模型等,AI开发框架包括PaddlePaddle、MindSpore、PyTorch、TensorFlow等等。
CubeTools是支撑CubeAI模型示范库开发的常用工具集,其中包括能够适配国内外主流AI框架和CPU/GPU等不同算力装置的通用推理服务组件,为PaddlePallde、MindSpore、ONNX Runtime和OpenVino Runtime等AI推理引擎封装统一的SDK调用接口,达到“一套代码,全框架通用”的开发和使用体验。
CubeAI Deployer是一套AI模型独立部署工具,可用于在脱离CubeAI智立方平台的条件下将CubeAI模型示范库中的AI模型一键自动服务化打包并部署运行。
5 结语
本文在分析和研究业务代码在异构算力不通用以及服务化成本高等问题的基础上,首创提出了算力服务原生的概念,设计了算力服务原生的基础体系架构,讨论了如何基于异构算力基础设施,建设“一套代码,全网通用”的算力服务软硬件生态,实现“代码即服务”“算力即服务”等算力服务原生理念。最后介绍了在AI算力服务原生方面的初步探索,包括CubeAI智立方AI算力服务原生系列软件开发及其开源实践,初步实现了算力服务原生基本能力,CubeAI智立方系列软件已在人工智能开源社区OpenI启智社区开源[15],为AI算力服务原生研究和开发提供了良好生态环境和研究基础。
猜你喜欢
新华月报(2024年7期)2024-04-08 02:10:56
都市人(2023年11期)2024-01-12 05:55:06
卫星应用(2023年1期)2023-02-21 06:51:50
现代经济信息(2022年22期)2022-11-13 18:32:00
运筹与管理(2022年9期)2022-10-20 12:42:26
小学教学研究(2022年5期)2022-04-28 21:29:36
中国工程科学(2017年3期)2017-09-05 09:41:09
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
中国工程科学(2015年7期)2015-02-27 10:51:26
