
融合双重注意力机制与并行门控循环单元的晶圆加工周期预测方法
2023-08-08 02:24:30戴佳斌吴立辉
中国机械工程 2023年14期
戴佳斌 张 洁 吴立辉
1.东华大学人工智能研究院,上海,201620 2.东华大学信息科学与技术学院,上海,201620 3.上海应用技术大学机械工程学院,上海,201418
0 引言
晶圆制造系统具有制造设备多、在制品规模大、工艺路线复杂、多层重入等特点,是典型的复杂制造系统[1]。晶圆加工周期是晶圆制造系统的关键生产指标,对晶圆加工周期进行准确预测有利于晶圆制造企业提前预估订单完成时间、合理制定生产计划、优化生产排程,对提高晶圆准时交货率与客户满意度等具有重要意义[2]。
晶圆加工周期受大规模、复杂关联的生产特征数据影响,准确预测困难[3]。国内外学者围绕晶圆加工周期预测开展了大量研究。TAI等[4]、YANG等[5]采用统计分析方法估计晶圆加工周期的分布规律,构建概率统计分布模型预测加工周期,但该方法对晶圆加工周期数据集高度敏感,预测模型的稳定性与准确性较差。YANG等[6]、HSIEH等[7]采用仿真分析方法构建晶圆制造系统模型,通过仿真分析预测晶圆加工周期,然而该方法需要大量时间构建生产仿真模型,预测结果的时效性不足,预测模型的适应性不强。SCHELASIN[8]、CHUANG等[9]采用了排队论或排队网络等数学分析方法对晶圆加工周期进行建模预测,然而该方法的建模需大量时间,且预测精度较低。
近年来,随着工业互联网技术的发展,晶圆制造系统中与晶圆加工周期相关的设备状态、工艺参数、物流搬运系统状态、在制品等大规模生产特征数据被实时采集与存储,构建了良好的大数据基础平台。以各类神经网络为基础的数据驱动方法逐渐用于晶圆加工周期的预测。WANG等[10]设计了一种双边长短期记忆的新型循环神经网络,通过挖掘晶圆层与层之间的相似性,较准确地预测了晶圆的单层加工周期。CHEN等[11]结合PCA、FCM和BPN构建了一种模糊神经网络模型用于晶圆加工周期预测。CHIEN等[12]提出了基于高斯-牛顿回归法与BPN的晶圆加工周期预测方法。TIRKEL[13]利用数据库中发现的知识与BPN神经网络构建了晶圆加工周期预测模型。WANG等[14]采用网络反卷积去除晶圆特征间的间接相关性,建立了预测晶圆加工周期的BPN模型。
相较于传统的统计分析、仿真分析、数学分析等方法,基于长短期记忆神经网络、BPN网络的数据驱动方法具有较好的适应性与预测稳定性,然而这些数据驱动方法存在以下不足:①晶圆制造过程中,大量生产特征数据内部及关键生产特征数据与晶圆加工周期之间具有复杂的相关性,现有的数据驱动预测模型设计未充分考虑上述复杂相关性的影响,难以有效保障晶圆加工周期的预测精度;②相同批次晶圆在加工过程中经历的加工设备及采用的加工工艺存在相似性,所获得的晶圆生产特征数据样本之间的时间相关性强,现有的数据驱动晶圆加工周期预测模型未考虑样本的相关性因素,模型训练效率较低。
为此,本文提出一种融合双重注意力机制与并行门控循环单元(dual attention mechanism and gated recurrent unit, DAM-GRU)的晶圆加工周期预测方法,在数据预处理的基础上,通过构建并行GRU网络挖掘生产特征数据样本之间的时间相关性,设计DAM来学习关键生产特征的相关度信息,从而提高晶圆加工周期的预测精度与预测效率。
1 晶圆加工周期预测问题
数据驱动的晶圆加工周期预测问题以晶圆制造过程中采集的生产特征数据集合X={x1,x2,…,xL}为输入参数,以预测的晶圆加工周期y为输出指标。生产特征数据包括设备负载率、各工序的加工时间、晶圆优先级、物流搬运系统状态、在制品数量。这些数据具有以下特点:
(1)大规模特性。晶圆制造需数十次重入氧化、外延、光刻、蚀刻等加工区,加工工序多达300~1000道。每道工序需要专用设备加工,与加工周期相关的设备、工艺、物流、在制品等相关生产特征参数达数千个。
(2)生产特征数据关联的复杂性。晶圆逐层加工,每一层电路的加工需重入各加工区内的相同设备组 ,采用大量相似工艺,导致部分设备的状态与工艺相关的生产特征数据存在强关联性。由于加工过程中的工艺约束,工艺路线上下游设备间的耦合性强,导致晶圆制造过程中采集的生产特征数据强关联。
(3)生产特征数据样本相关性强。晶圆制造过程中,相同批次的晶圆lot通常同时进入晶圆加工车间,因此采用的加工工艺、经历的加工设备、对应的物流状态、系统在制品状态等具有强相似性,导致晶圆的生产特征数据样本在时间上具有较强的相关性。
2 基于DAM-GRU的晶圆加工周期预测方法
基于DAM-GRU的晶圆加工周期预测方法框架如图1所示。数据预处理包括两个环节:特征提取与特征数据样本集分类。特征提取基于Relief-F方法对生产特征数据集进行降维处理,筛选与加工周期相关的关键特征子集,获得关键特征的关联矩阵W、特征与加工周期关联的向量F。特征数据样本通过模糊C均值(fuzzy C-means, FCM)算法实现基于工艺相似性的分类,将生产特征数据样本集合分解为多个并行数据样本子集合。
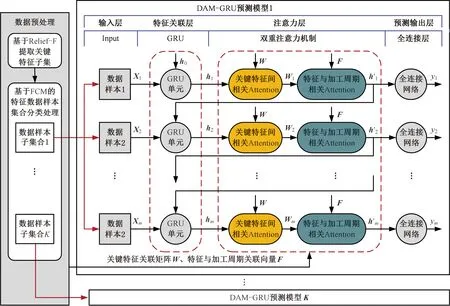
图1 基于DAM-GRU的晶圆加工周期预测方法框架
通过样本数据子集合构建并行DAM-GRU预测模型,各DAM-GRU由输入层、特征关联层、注意力(Attention)层、预测输出层构成。输入层主要从数据样本子集合获取输入数据样本,并对数据进行最大-最小值[1]归一化处理,消除特征量纲差异的影响。特征关联层由并行GRU单元网络构成,并通过模拟同批次晶圆的加工过程与加工工艺相似性,挖掘晶圆生产特征数据样本之间的时间相关性,提高预测模型的训练效率。注意力层通过设计关键生产特征间的相关注意力及特征与加工周期相关的注意力网络,强化关键生产特征对加工周期的贡献差异,提高预测模型的精度。预测输出层为全连接网络层,通过对注意力层输出的隐藏状态向量进行加权求和,实现对晶圆加工周期的预测输出。
2.1 数据预处理
2.1.1基于Relief-F的特征选择
晶圆制造生产特征数据的大规模、复杂关联等特点导致预测模型训练效率低、预测精度差等问题,因此需对生产特征数据进行降维去冗余处理。Relief-F算法的计算时间复杂度与生产特征数量线性正相关,可量化关键生产特征间及特征与预测目标间的复杂相关性,且特征子集能保留数据原始信息[15],适用于晶圆加工周期预测问题的生产特征提取。基于Relief-F的晶圆生产特征与加工周期关联向量Fin=(F(x1),F(x2),…,F(xL))的计算公式为
(1)
(2)
式中,xi为第i个生产特征;F′(xi)为前一轮计算所得特征xi与晶圆加工周期的相关值;q为特征选取迭代次数;R为每次随机选取的生产特征数据样本;Hj为与样本R所属子集相同的第j临近样本;B为与样本R所属集合不同的其他数据集合;Mj(B)为集合B中与样本R第j临近的样本;k为与样本R最临近的样本数量设定值;P(B)为集合B中的样本个数占总样本的数量比例;P(class(R))为R样本所在集合class(R)中的样本个数占总样本的比例。
关联向量Fin归一化处理后,通过设定的阈值筛选出高相关性特征,形成关键生产特征与加工周期的关联向量F=(F(x1),F(x2),…,F(xN)),其中,N为关键生产特征数量。基于F计算特征间关联矩阵[Wi,j]:
(3)
其中,softmax(*)为归一化指数函数。
2.1.2基于FCM的数据集聚类
由于晶圆制造系统加工产品的多样性,晶圆生产特征数据样本集合会因加工批次及加工工艺的差异而具有明显的分类特性。本文从加工工艺相似性角度出发,采用FCM算法[16]对生产特征数据样本进行工艺相似性聚类处理,为提高并行DAM-GRU预测模型的学习效果奠定数据基础。
基于FCM的生产特征数据样本聚类步骤如下:
(1)设定聚类中心的数量C与模糊系数k,随机初始化隶属度矩阵:
(4)
式中,up,q为样本Xp属于第q类的隶属度,p=1,2,…,i;q=1,2,…,j。
(2)基于式(3)计算聚类中心:
(5)
式中,m为生产特征样本数;
(3)基于聚类中心cj更新隶属度矩阵U1,更新后的隶属度ui,j为
(6)
(4)重复步骤(2)、步骤(3),直至
(7)

2.2 DAM-GRU预测模型
2.2.1输入层
输入层主要从预测模型对应的生产特征数据样本聚类子集合中获取输入数据样本X=(X1,X2,…,Xm)T,针对数据样本Xm=(x1,m,x2,m,…,xN,m)各特征数据度量单位多、差异大的特点,采用最大-最小值方法[1]对其进行归一化处理以消除特征量纲差异性影响:
(8)

2.2.2特征关联层
特征关联层针对输入层生产特征数据样本对应的晶圆加工工艺相似性及数据样本之间的时间相关性,构建基于并行GRU单元的特征关联网络。GRU是一种用于处理序列数据的循环神经网络,能保证预测精度和较高的计算效率[17]。并行GRU特征关联网络能模拟晶圆的加工工艺相似性,挖掘晶圆生产特征数据样本之间的时间相关性,具有较高的模型训练效率。


图2 GRU单元结构
zt=σ(Wz[ht-1Xt])
(9)
rt=σ(Wr[ht-1Xt])
(10)
(11)
(12)
2.2.3注意力层
注意力层从特征关联层获得隐藏状态向量,基于生产特征间关联矩阵W构建关键特征间相关Attention,通过特征间相关性实现对隐藏层信息的升维。利用升维后的信息生成Attention权重,实现特征间相关性作用下的第一次注意力分配。在此基础上,通过基于关键生产特征与加工周期关联向量F构建特征与加工周期相关Attention,强化关键生产特征对加工周期的贡献差异,完成全局信息下的生产特征第二次注意力分配,提高预测模型的精度。注意力层结构设计如图3所示,双重注意力的具体实现步骤如下:

图3 注意力层结构图
(1)将特征关联层输出的隐藏状态向量ht与生产特征间关联矩阵W进行哈达玛积相乘,获得细粒度化后的隐藏状态相关矩阵WH:
WH=Hadamard(W,ht)
(13)
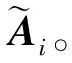
(14)
(4)依次抽取WH的各个列向量,并重复步骤(2)、步骤(3),获得各个特征相关性作用下的注意力分配矩阵。
(5)对各个特征相关性作用下的注意力分配矩阵进行累加平均处理,获得各个特征相关性作用下的注意力分配均值矩阵:
(15)
实现特征间相关性作用下的注意力分配。
(6)将WD进行降维处理:
(16)
(7)将注意力分配均值向量Wd和特征与加工周期关联向量F进行哈达玛积相乘,实现特征与加工周期间的相关性作用下的第二次注意力分配。形成的双重注意力机制作用下的隐藏状态向量h′t=Hadamard(F,Wd)可输出至特征关联层与全连接输出层。
2.2.4预测输出层
预测输出层为全连接网络层,它对注意力层输出的隐含状态向量h′t进行加权求和处理,实现对晶圆加工周期yt的预测输出。全连接层的计算公式为
yt=h′t·vt
式中,h′t为注意力层输出;vt为全连接网络权重;t为预测样本的序号。
3 实例验证分析
3.1 实验数据与参数
为验证本文提出的晶圆加工周期预测方法的有效性,采用某晶圆制造企业的历史生产数据进行实验分析。该历史生产数据(共20000条)集包括晶圆在各设备中的等待与加工时间、晶圆的在制品数量、物料搬运系统的负载、晶圆优先级等775个生产特征参数,输出为晶圆加工周期。
实验验证涉及的参数设置主要包含Relief-F阈值0.6、FCM设定参数(模糊系数2、迭代次数100、迭代终止设定值ε=10-8)、DAM-GRU神经网络学习参数等。DAM-GRU神经网络的学习采用梯度下降法[3],学习参数设置如下:学习率为0.1,动量为0.9,动量抑制因子为0.5,权重衰减为0.01,迭代次数为200。评价指标为均方根误差、平均绝对误差、平均绝对百分比误差以及模型训练时间。
3.2 预测模型消融实验
预处理晶圆制造的历史生产数据集,基于Relief-F方法获得46个关键生产特征;为验证并行GRU网络与DAM的有效性,分别从并行GRU预测模型与DAM这两个功能模块对DAM-GRU预测模型进行消融实验;为保证实验结果的可靠性,采用10倍交叉验证方法[10]选取训练数据集与验证数据集。
3.2.1DAM的有效性验证
利用DAM-GRU、Self-Attention-GRU和GRU分别构建预测模型进行消融试验,实验结果如图4、表1所示。图4表明,40个测试集样本下,DAM-GRU的预测值更接近晶圆加工周期的真实值,DAM-GRU的预测模型具有更高的预测精度。表1中,DAM-GRU预测模型的训练时间为10.3 s,优于Self-Attention-GRU预测模型的训练时间16.6 s。以上结果表明,双重注意力机制能通过强化网络计算过程中的特征相关性差异,提高加工周期的预测精度,且相较于自注意力机制,双重注意力机制具有更高的训练效率。

表1 不同模型的训练时间

图4 不同预测模型的结果
3.2.2GRU的有效性验证
将DAM-GRU与DAM-LSTM进行对比消融试验,结果如图5、表1所示。图5表明,相较于DAM-LSTM,DAM-GRU在精度上有小幅提升。表1中,DAM-GRU的训练时间为10.3 s,相较于DAM-LSTM的14.4 s,训练效率提高约30%,这对提高晶圆加工车间动态调度的实时响应能力具有重要意义。以上结果表明,GRU网络通过模拟晶圆lot在时间相关性上的关联与传递特性,挖掘样本的关联关系,能在保持晶圆加工周期预测精度的同时,提高预测模型训练效率,即本文设计的并行GRU网络是有效的。
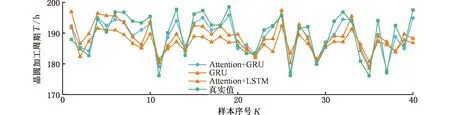
图5 基于DAM-GRU和DAM-LSTM的预测模型结果
3.3 方法有效性分析
将DAM-GRU与基于BPN、PCA-BPN[11]、MLP[18]、RandomForest的晶圆加工周期预测方法进行对比,验证DAM-GRU方法在预测精度与预测效率的优势。其中,PCA-BPN将数据集特征降低到46个(与DAM-GRU相同),其余预测方法保留原有数据集的775个特征进行模型的训练与测试,同样采用10倍交叉验证确保实验结果的可靠性。对比结果如表2所示。

表2 DAM-GRU与传统预测模型的结果
从表2中可知:①相较于PCA-BPN,DAM-GRU预测结果的均方根误差从12.12 h降低到9.43 h,平均绝对误差从8.96 h降低至7.45 h, 平均绝对百分比误差从4.52%降低到3.71%,模型训练时间从13.41 s降低至10.27 s,这证明DAM-GRU较PCA-BPN具有更高的预测精度与预测模型训练效率;②RandomForest方法的均方根误差、平均绝对误差、平均绝对百分比误差分别为10.98 h、7.89 h和3.98%,与DAM-GRU具有相近的预测精度,但模型训练效率远低于DAM-GRU;③DAM-GRU在预测精度及预测模型训练效率上明显优于MLP、Bagging、DecisionTree、SVM。以上对比分析结果表明,基于并行DAM-GRU的晶圆加工周期预测方法是有效的。
4 结论
为提高晶圆加工周期的预测精度与预测效率,本文提出一种基于DAM-GRU的晶圆加工周期预测方法。该方法在对数据进行预处理的基础上,通过构建并行GRU神经网络挖掘相邻晶圆样本之间的时间相关性,以提高模型预测效率;通过设计双重注意力机制学习关键特征间及特征与加工周期的相关度信息,强化特征对加工周期的贡献差异,提高模型预测精度。实例研究表明,DAM-GRU方法是有效的。下一步将继续挖掘晶圆制造生产特征的关系及其在预测模型训练过程中的作用,以提高晶圆加工周期预测模型的预测精度及其鲁棒性。
猜你喜欢
科学与信息化(2024年3期)2024-02-20 01:12:38
科学与信息化(2023年1期)2023-01-31 08:11:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
传媒评论(2017年3期)2017-06-13 09:18:10
读者(2017年5期)2017-02-15 18:04:18
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
通信电源技术(2016年5期)2016-03-22 01:10:14
电子工业专用设备(2015年4期)2015-05-26 09:10:34
