
基于知识图谱的西藏文物问答系统构建与实现
2023-08-04 05:52王博王泽辉张坦杜鹏彭家凯滕俊哲
电脑知识与技术 2023年18期
王博,王泽辉,张坦,杜鹏,彭家凯,滕俊哲★
(1.西藏大学信息科学技术学院,西藏拉萨 850000;2.西藏大学工学院,西藏拉萨 850000)
0 引言
西藏地区位于青藏高原西南部,具有浓厚的民族文化和宗教色彩,孕育了悠久的历史文明。现如今,网络上的数据以指数倍的速度增长,当浏览网页时,经常在不知凡几的数据中迷失方向,这对于想要了解西藏历史文化及文物的人来说,是一件惝恍迷离的事。但目前除了传统的网站、App和微信小程序等形式展现西藏历史文化外,还未发现采用最新的人工智能和大数据等技术来展示西藏文物给广大用户,鉴于此,本文将研究基于知识图谱的西藏文物问答系统,用户可以通过问答的形式了解西藏文物资源。
1 相关理论与技术
1.1 知识图谱概述
知识图谱(Knowledge Graph) 是一种结构化的知识表示形式,用于表达实体、概念、属性及它们之间的关系。知识图谱可以分为通用领域知识图谱和垂直领域知识图谱,通用图谱强调知识的广度,如Wikidata、FreeBase 等,垂直图谱面向特定的领域或行业,强调的是知识的深度,如王电化等人[1]构建的档案领域知识图谱,张德亮[2]构建的小型金融知识图谱等,知识图谱的构建可以分为几个方面,通过将不同来源的数据进行知识抽取、知识融合、知识加工、知识存储,最终形成知识图谱。
知识可以通过资源描述框架(Resource Description Framework,RDF)三元组模型来进行表示,每一个知识可以被分解为(主、谓、宾)三种形式,如(清雍正七世达赖喇嘛金印,意义,是中央政府有效治理西藏、规范藏传佛教仪轨的重要物证),知识可以进行推理,基于图谱中已有的事实或关系推断出未知的事实或关系,假设知识库中存在(刺绣藏传佛教唐卡,内容,佛教哲理),(佛教哲理,目的,传播教化众生)两条知识,可以推断出刺绣藏传佛教唐卡是藏传佛教用来传教步道所用,知识推理在概念层和本体层都要有可满足性,如果不满足说明是空集,那么推理也就不存在,总之,知识推理可以帮助我们对知识图谱中未知的关系以合理的方式进行补全。
知识抽取通过从不同来源、不同结构的数据中进行抽取,形成知识存入到知识图谱中,结构化数据可以使用图映射和d2r 转换,半结构化数据可以使用包装器,纯文本数据可以使用信息抽取,针对非结构化文本的实体关系抽取方式有pipline 和联合抽取两种方式,pipline 先识别出句子中的实体,然后通过文本分类判断两个实体间的关系,例如“清乾隆折枝莲托八宝纹青花盉壶是乾隆皇帝给达赖喇嘛的馈赠礼物”,通过ner 先识别出实体“清乾隆折枝莲托八宝纹青花盉壶”“乾隆皇帝”“达赖喇嘛”,然后判断相邻两者之间的关系,输出(清乾隆折枝莲托八宝纹青花盉壶,御赐,乾隆),(清乾隆折枝莲托八宝纹青花盉壶,馈赠,达赖喇嘛)。由于pipline 模式在实体识别和关系分类任务中完全分离,所以当命名实体识别任务存在误差时,这种误差便会在关系分类任务中累积,而联合抽取在实体识别和关系分类的过程是共同优化的,文献[3]提出casrel(层叠式指针标注)模型,该模型在实体识别和关系分类任务中共享同一个编码器,但使用不同的解码器,指针标注识别句子中的实体,将一个句子中的实体通过两个矩阵进行表示,矩阵长度为原句子长度,实体头标注为1,实体尾也标注为1,实体中间不进行标注,如表1所示:

表1 指针标注
层叠式指针标注即构造多个矩阵对应多个关系,casrel 模型首先识别句子中的主语,然后针对这些主语进行关系判断,看是否存在主谓宾关系,即构造对应的三元组。
完成了知识抽取后,将构造出大量的三元组,但数据可能来源于不同的地方,例如第三方知识库You-Tube,yago,freebase 等,而对于不同的数据来源,它们对知识的表示可能有所不同,需要判断不同知识库所描述的类别,实例,属性是否是真实世界里相同一个对象,所以要将生成的数据进行知识融合,最后将数据进行知识存储,完成知识图谱的构建。
1.2 问答系统概述
问答系统(Question Answering System)是一种人工智能应用,它可以回答用户提出的问题,类似于人与人之间的对话。它是自然语言处理(NLP)领域的一个重要研究方向,旨在将人类语言能力应用于计算机上,使计算机能够理解和回答自然语言问题。
问答系统按照答案来源可以将其分为三类,基于问答对的问答系统、基于机器阅读理解的问答系统、基于知识图谱的问答系统。基于问答对的问答系统通过找到已经存在于知识库中,并且和用户所提问题相似度最高的问句,将结果返回给用户。基于机器阅读理解的问答系统通过在知识库中查找问句对应实体的介绍文本,将其作为阅读理解的上下文输入到系统中得到答案。基于知识图谱的问答系统首先解析用户的问句,对用户的意图进行识别,然后构建查询语句,查询图谱返回结果。由于知识图谱存储的是结构化的语义信息,并且具有知识推理能力,因此查询效率很高。目前Knowledge-based QA 有三种主流的处理方法,基于语义解析、基于信息抽取、基于向量建模,基于语义解析是将用户所提问题变成机器能够理解的查询语言,基于信息抽取的方法识别问句实体,用分类器识别问句信息,结合图谱查询结果,基于向量建模的方法首先将问句和候选答案映射到低维空间,通过训练使得问题向量和正确答案向量之间损失函数最小,最后找到相似度最高的向量作为正确答案。
2 西藏文物知识图谱构建
图谱数据来源分为三个部分,1 采用网络爬虫技术,从互联网爬取了相关西藏文物的一定数据,2采用casrel模型对文本数据进行知识抽取,3前往西藏博物馆实地考察相关的展品。将数据存储为csv 文件格式,标签分别为文物名称、文物介绍、文物起源时间、文物价值、文物地址。
构建西藏文物知识图谱,以文物名称为主体,与文物介绍、文物起源时间、文物价值、文物地址实体建立关系,将数据存储到neo4j 数据库中,Neo4j 是一种图形数据库管理系统,专门设计用于存储、管理和查询图数据。它采用图形数据模型,以节点(Node)和关系(Relationship) 的形式来表示和存储数据。构建成功后用浏览器打开网址localhost:7474,可以看到构建的部分图谱如图1所示。

图1 西藏文物知识图谱
3 西藏文物问答系统设计
问答功能需要使用自然语言处理技术构建出cypher 查询语句,查询语句要实现意图识别和槽位填充,意图识别用文本分类技术实现,槽位填充用命名实体识别技术实现。
3.1 命名实体识别
命名实体识别技术是用来识别文本中的实体信息,一般来说包括人名,地名,时间,组织机构等,NER作为自然语言处理技术的上游任务,可以为知识抽取,机器翻译,文本分类等下游任务提供帮助。命名实体识别技术按照发展时间可以分为三种方法,基于规则,基于统计,基于深度学习,基于规则的方法不需要经过训练,可以基于实体词表和基于规则匹配,词表需要手工构建,在特定领域准确率高,但是需要花费大量的时间,规则匹配可以基于正则表达式,也是依赖于手工对规则的制定。基于统计的方法是利用标注好的数据进行训练,输出为字符作为实体组成部分的概率,如果某个候选字段的概率值大于设定好的阈值,则标注为实体。基于深度学习的方法不需要手工提取特征,使用神经网络进行训练,包括输入层,隐藏层,输出层,常见的深度学习模型有cnn[4],lstm[5]等。
在对西藏文物的命名实体识别中,使用了bilstm_crf[6]模型,如图2所示。
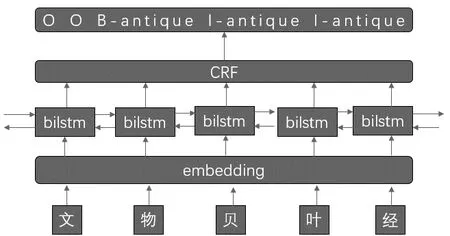
图2 bilstm-crf模型
bilstm作为rnn的扩展,可以处理上下文之间的关系,并且加入了门控机制,可以处理具有长期依赖的信息,crf维护了概率转移矩阵,有效地提升了命名实体识别的精度。
3.2 文本分类
文本分类是一种广泛应用于自然语言处理领域的技术,可以对文本内容进行解析并将其划分到不同的类别,在问答系统中,需要对用户的意图进行识别,例如,“我想了解一下贝叶经”,那么,系统就要将此文本归为“介绍”一类,早期文本分类的方法是基于规则特征匹配的,例如在情感分析中,通过文本中出现了“喜欢,‘讨厌’”等词语来进行评判,随着机器学习的发展,基于统计学习的模型开始占据主导地位,SVM[7]通过寻找最优超平面,将文本归为不同的类别,KNN[8]通过离输入文本最近的k个文本判断所属类别,朴素贝叶斯算法在给定类别的条件下计算不同特征的概率,并使用这些特征判断未知文本所属类别,后来深度学习兴起,机器能够从数据中自动学习特征,并通过神经网络进行分类。和机器学习相比,深度学习在某些领域拥有更好的性能。
对用户输入问题的意图识别使用了Textcnn 模型,TextCNN 的基本思想是通过卷积操作来提取文本中的局部特征,并通过最大池化操作将这些特征合并成全局特征表示。TextCNN 在训练过程中采用交叉熵损失函数和反向传播算法。模型通过不断调整权重来最小化损失函数,以提高分类性能。
3.3 构建问答系统
首先构建查询模板,match(n:antique) where n.antique=‘{name}’return n.‘{intention}’,当用户输入问题如“请介绍一下元八思巴肖像唐卡”时,系统解析出意图为‘intro’,槽位实体为‘元八思巴肖像唐卡’,通过替换查询模板中的‘name’,‘intention’,构建出最终的查询语句match (n:antique) where n.antique=’元八思巴肖像唐卡’return n.intro,通过查询图谱,返回问答结果。
为了能使用户有着更好的体验,对系统进行了前端设计,问答结果如图3所示:

图3 问答结果展示
至此,基于西藏文物知识图谱的问答系统构建完成。
4 结束语
针对目前并未有使用人工智能技术介绍西藏文物,构建了西藏文物知识图谱,采用bilstm-crf 命名实体识别模型,textcnn 文本分类模型,对查询语句进行了意图识别和槽位填充,最终完成了问答系统,问答旨在帮助人们更好地了解西藏的文物,进而对西藏的思想,文化有着更深入的了解,后续会加大工作投入,不断推进问答系统的发展与完善。
猜你喜欢
学与玩(2022年7期)2022-10-31
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
海峡姐妹(2017年4期)2017-05-04
剑南文学(2016年11期)2016-08-22
杂草学报(2012年1期)2012-11-06
