
应用EpiData软件创建临床研究电子数据库
2023-08-03 06:02王瑞平李斌
上海医药 2023年13期
王瑞平 李斌
(上海市皮肤病医院临床研究与创新转化中心 上海 200443)
EpiData 是丹麦欧登塞的一个非盈利组织开发并推广,该数据库软件的程序设计者是Jens M.Lauritsen、Michael Bruus 和Mark Myatt。EpiData 是一款免费的数据管理软件,研究者可以在http://www.EpiData.dk 网站上下载。EpiData 软件目前最高版本为3.1,包括中文和英文2 个版本可供用户选择。EpiData 软件数据库可承载200 000 ~300 000 条记录,每份记录的界面可以录入999 行问题(变量),基本上可以满足99%以上的临床研究对数据录入的要求[1]。研究者在EpiData 软件官方网站完成下载后,可以通过“setup.exe”在计算机中安装这个程序,也可以通过直接将“EpiData.exe”文件拷贝到计算机桌面,点击运行便可打开EpiData 软件(图1)。

图1 EpiData软件数据库的打开方式示意图
1 创建数据库前的准备
一份完整的EpiData 数据库软件至少应包括:调查表(questionnaire, QES)文件、数据库记录文件(record,REC)和逻辑核查(check, CHK)文件。因此,研究者应用EpiData 完成数据库建立后,应审核数据库文件夹中是否包括QES、REC、CHK 这3 个文件,以判断数据库的完整性。
打开EpiData 软件后,其界面如图2 所示,包括标题、菜单列、过程工具条和编辑工具条。标题仅显示“EpiData 3.1”提示研究者所使用的版本;菜单列与Office 办公软件的菜单列相仿,包括了“文件”“数据录入控制”“数据导入/导出”“数据处理”“工具”“窗口设置”和“帮助”等菜单栏,研究者可以根据需要选择;过程工具条是EpiData 软件建立数据库的核心提示内容和操作步骤,包括“1 打开文件”“2 生成REC 文件”“3 建立CHK 文件”“4 数据录入”“5 数据处理”和“6 数据导出”,初学者根据这些步骤的提示,就可以完成数据库的建立和数据录入;编辑工具条主要是帮助数据库建立中的“打开文档”“复制/黏贴/剪切”等功能,方便数据库的建立。

图2 EpiData软件数据库界面
在创建EpiData 数据库前,研究者应熟悉常用的变量类型。临床研究中,常用的数据变量类型包括数值型变量、字符型变量和日期型变量。数值型变量用“#”表示,一个“#”可以录入一个数字;字符型变量用英文下划线“_”表示,2 个字符“__”即为一个汉字,最多可以录入80 个字符,即40 个汉字;日期型变量用“
如图3 所示,以“流动人口特应性皮炎患病率现况调查”问卷为例。示例共摘录了7 个变量,包括问卷编号和a1 ~a6 这6 个问题。从变量类型看,问卷编号和问题a2 ~a5 均为数值型变量,后续建库用“#”表示;a1 是有关出生年月的问题,为日期型变量,后续建库用“

图3 纸质调查问卷示例
2 创建EpiData 数据库
在清楚识别调查问卷中每个问题的变量类型后,打开EpiData 软件,点击“打开文件→建立新QES 文件”,新建一个空白QES 文件,再把图3 中调查问卷的内容直接复制黏贴到该QES 文件中,保存到在计算机中提前建好的EpiData 数据库文件夹即可。
在新建的QES 文件中,如果原始调查问卷(图3)有每个问题的变量名称,就不需要在QES 文件中设置变量名,如果原始调查问卷没有设置变量名称,研究者需要在建立数据库时给每一个问题指定一个变量名。变量名命名应符合一定的规则和要求:①变量名不能是汉字;②变量名的第一个字符一定是字母(A ~Z),之后可以含字母(A ~Z)和数字(0 ~9),例如“a1b”“ab1”“a1a2”等;③变量名最长为10 个字符,过长则无法被系统识别;④变量名要与后面的问题之间留有空格,如图3 中的“a1 您的出生年月”,不能写成“a1 您的出生年月”,因为汉字与字母、数字连在一起,违反了命名规则,系统会将其判别为错误;⑤注意唯一识别变量的重要性(key unique),每一个数据库务必至少指定一个唯一识别变量,这个变量在后续的数据库合并、双录入一致性检验时都是必不可少的。
研究者完成对每一个问题进行变量名设置后,即可根据变量的不同类型来分别设置每一个变量名对应问题的数据输入格式。如图4 所示,“id 问卷编号”为4 位数的数值型变量,因此录入格式设置为“####”;a2 ~a5这4 个问题全部为数值型变量,因问题选项个数全部为个位数,因此录入格式设置为“#”;a1 为日期型变量,其录入格式设置为“

图4 EpiData软件QES文件格式特点
完成建立QES 文件后,接下来一步工作就是根据建立好的QES 文件自动生成REC 文件。如图5 所示,在EpiData 软件过程工具条中,点击“2 生成REC 文件”按钮后,软件会弹出“根据QES 文件生成REC 文件”对话框,直接点击“确定”即可。

图5 EpiData软件根据QES文件生成REC文件示意图
此时,在EpiData 软件过程工具条中,点击“4 录入数据”按钮后,软件会弹出“打开”对话框,选择刚刚建好的REC 文件,即进入数据录入界面。如图6 所示,EpiData 软件已打开REC 文件,研究者已可以进行数据录入。但是,由于没有添加“数据录入质控”命令,这时录入数据是没有限制的。例如问题a2,根据选项“1男 2 女”,研究者期望的正确录入数字是“1”或“2”,但由于没有添加“数据录入质控”命令,此时可以录入0 ~9 中的任何一个数字,这便增加了录入错误的概率。为了降低和避免这样的错误,可以通过建立CHK 文件,对REC 文件中的每个变量的录入进行限制和控制,提高录入的准确度和效率。

图6 EpiData软件REC文件录入界面示意图
为建立数据库录入的CHK 文件,首先应在EpiData软件过程工具条中,点击“3 建立CHK 文件”按钮,随后软件会弹出“请选择REC 文件”对话框,选择刚刚建立好的REC 文件后点击确定,打开CHK 文件设置对话框。如图7 所示,CHK 文件设置的主要类别包括Range,Legal(合法录入值)、Jumps(跳转)、Must enter(必须录入)、Repeat(重复)和Value Label(变量值标签),研究者根据需要,可以对数据库中的每一个变量进行不同类别的设置。
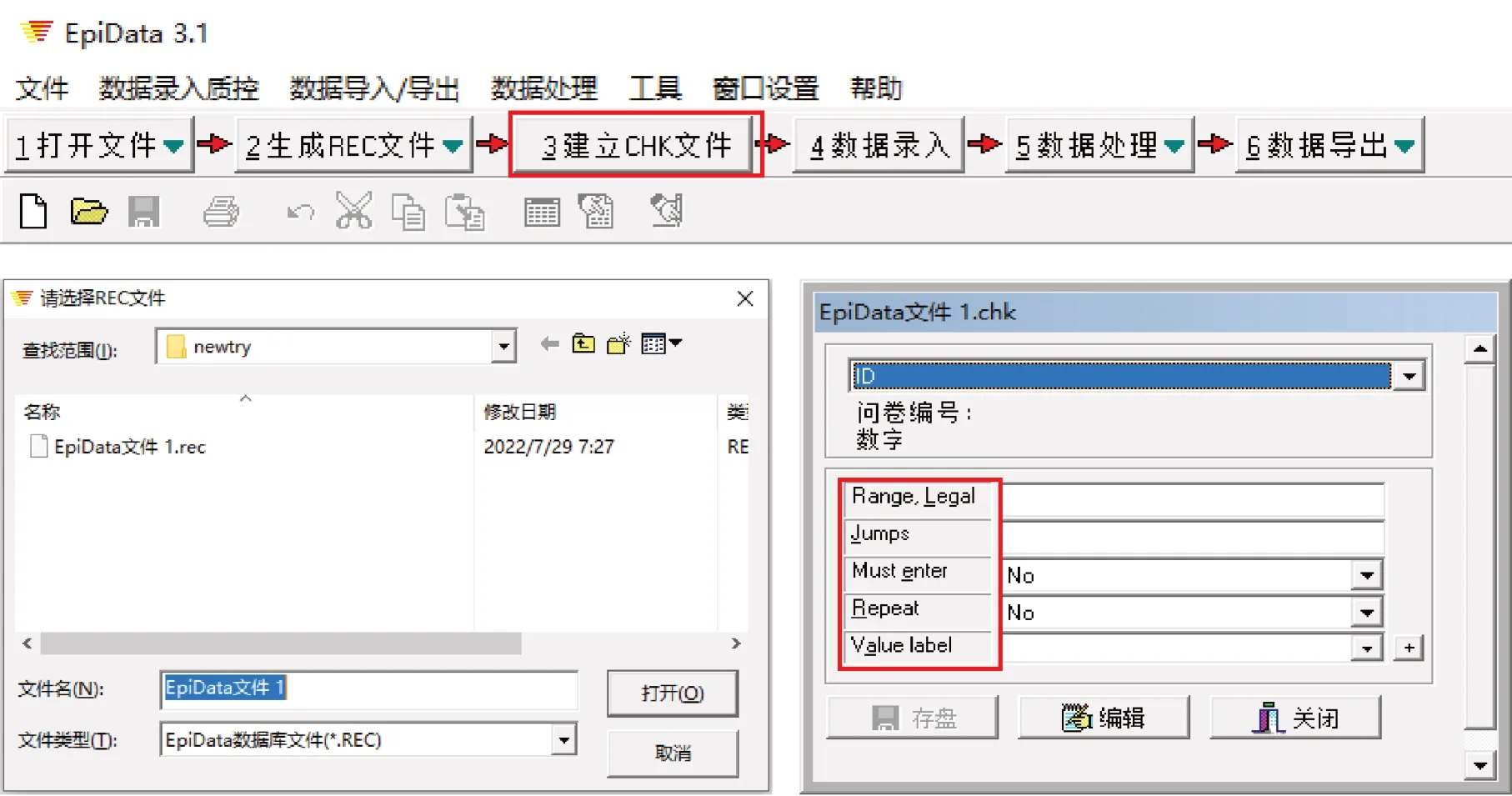
图7 EpiData软件CHK文件建立示意图
“Range, Legal”主要是限定变量的数据录入合法值。例如“Range -15 15”表示允许录入-15 到15 之间的数据;“Range 2005/01/01 2005/12/31”表示允许录入的日期范围;“Range 1-5”表示允许录入1 到5 之间的数据;“Range 1,2,9”表示允许录入1、2 和9 这3 条数据。
“Jumps”表示跳转,因为有些调查问卷会有选择某个选项后,跳转到规定的后续问题继续回答的情况,这时候可以通过设置跳转来方便后续问卷的录入。须注意的是,在设置跳转时应指定当前变量的某个可能录入的数值与对应的跳转目标变量名对应起来。如图6 中,可以指定当问题a2 为“2 女”时,跳转到问题a6。那么,这时候在a2 这个变量中,将Jumps 设置“2 >a6”即可实现。
“Must enter”为定义一些必须录入的变量。研究者可以将数据库中所有核心的变量全部设置“Must enter”为“Yes”,这样在数据录入时便不会遗漏。
“Repeat”命令表示指定一些变量的数量是可以重复的,即完成第一份数据录入后,录入的内容会直接复制到下一份数据该变量的位置,数据录入者不需要重新录入内容,除非录入者需要更新录入的内容再进行修改。由此,该命令加快了录入的速度,常常适合于字符型变量大量重复出现的情况。
此外,最后一个也是最重要的一个设置就是唯一识别变量“key unique”。上文也强调过,一份EpiData 数据库中务必要至少包含一个唯一识别变量。唯一识别变量是数据库横向合并和双遍录入数据进行一致性核对时的识别变量,同时也是对进行数据质量控制,避免重复录入的关键控制点,具有不可或缺性[2]。如图8 所示,首先研究者须确定唯一识别变量(ID),然后选择该变量对应的CHK 文件设置窗口,单击“编辑”按钮,打开“对该字段的录入质控程序进行编辑”,将“key unique”录入编辑窗口,点击“确定并关闭”即可。

图8 EpiData软件CHK文件中唯一识别变量的设置
完成上述所有对变量的设置后,保存CHK 文件。这时研究者事先建立的数据库文件夹中应该包括了QES、REC、CHK 等3 个文件,即是一个完整的数据库。随后,研究者可对新建立的数据库进行测试,通过录入5 ~10份问卷来测试和发现可能存在的问题,并进行针对性的修改完善。最后,把最终确定的数据库保存并备份备用。
猜你喜欢
科技信息·学术版(2021年9期)2021-08-22
河池学院学报(2021年1期)2021-07-10
中国管理信息化(2021年4期)2021-03-16
英语文摘(2019年2期)2019-03-30
中华手工(2018年6期)2018-07-17
科学与技术(2018年6期)2018-01-07
中国建筑装饰装修(2017年1期)2017-02-13
中国卫生(2015年7期)2015-11-08
创新作文·初中版(2015年1期)2015-03-11
创新作文·初中版(2014年5期)2014-07-18
