
基于PU-Faster R-CNN的手机屏幕缺陷检测算法研究
2023-08-03 00:31李伟朝陈志豪查云威
计算机测量与控制 2023年7期
李伟朝,陈志豪,张 勰,查云威
(1.广东工业大学 自动化学院广东省物联网信息技术重点实验室,广州 510006;2.华南理工大学 电力学院,广州 510630)
0 引言
在手机屏幕的制作工艺过程中,由于环境和技术等因素影响,一些产品难免出现不可避免的缺陷。如果让存在缺陷的手机屏幕流入市场,将会严重影响使用者的体验,甚至危害生命。因此手机屏幕的缺陷检测是手机生产的关键环节。传统的人工检测方法,存在着筛检成本高、耗时长、准确率低等一系列问题。
随着机器学习的发展,其应用场景涉及多个领域。基于机器学习的缺陷检测方法也不断被提出。Huang等人[1]提出了一种检测手机屏幕表面缺陷的框架。该框架包含连续图像切割规范化、原始图像规范化、图像块分割、特征提取和机器学习等方法。Jian等人[2]提出了一种改进的手机屏幕玻璃缺陷识别和分割检测算法。该算法基于轮廓对齐方法生成模板图像。根据对准结果,采用减法和投影相结合的方法识别图像中的缺陷。针对具有模糊灰边界的噪声图像中的缺陷,提出了一种改进的模糊c-均值聚类算法。尽管基于机器学习的特征提取部分能通过专家设定有效的特征,但与深度学习相比,所提取的特征信息丰富度欠缺。此外,基于机器学习的缺陷检测方法需要大量的先验知识,并且缺乏鲁棒性。
为了解决基于机器学习的检测方法的局限性,不少研究人员提出优秀的基于深度学习的检测框架。Guo等人[3]提出了一种高效的缺陷检测网络(EDD-Net)。该模型的骨干网络是高效网络。该模型提出了一种基于手机表面缺陷的特征金字塔模块GCSA-BiFPN。此外,该模型利用一个盒/类预测网络进行有效的缺陷检测。文献[4]提出了一种基于Faster R-CNN小样本学习的手机屏幕表面缺陷检测模型框架。设计了一个深度卷积生成对抗网络(DCGAN),用于自动提取和融合缺陷特征,以增强和生成缺陷样本。Wang等人[5]提出了一种用于手机屏幕缺陷检测的孪生网络。该网络结合对比度损失和交叉熵损失来提高模型的识别能力。Ren等人[6]提出了一种基于“分类网络+带注意力机制的U-Net”的小目标分割和非明显缺陷检测方法。该方法提出了一种改进的解决方案,在分类网络中添加了一个分割网络,并在经典的U-Net中添加了注意力机制,提高了小目标分割和无意义缺陷检测的性能。Zhu等人[7]提出了分层多频注意力网络(HMFCA-Net)。值得注意的是,其提出了一种使用多频率信息和局部跨通道交互的注意力机制来表示加权缺陷特征。另外介绍了一种基于变形卷积的ResNeSt网络,旨在处理各种缺陷形状。以上基于深度学习的缺陷检测框架能达到令人满意的效果,但是对于手机屏幕缺陷检测识别准确率与实际应用的要求还存在一定的差距,仍然存在缺陷目标检测精度不高的问题,特别是对尺寸小的缺陷目标检测准确率偏低。
1 手机屏幕特点分析及缺陷检测问题难点
原始手机屏幕检测样品为透明玻璃面板,需放在指定工控机上,通过光源照射,在背景板用摄像头收集对应的手机屏幕原始图像到指定服务器。手机屏幕图像为灰度图像,背景为黑色像素,白色像素根据不同特征为不同的缺陷。如图1所示,分别是缺陷为气泡、划痕、锡灰和无缺陷的手机屏幕图像。方框仅为缺陷所在位置方便读者阅,其非预测结果。

图1 手机屏幕图像
手机屏幕缺陷检测是一个自动化的目标检测过程,是一个集手机屏幕缺陷特征提取、缺陷分类和缺陷定位的多任务过程。目的是准确找到手机屏幕上的缺陷,确定其类别和位置。具体而言,检测算法要实现3个方面的功能:1)判断输入的手机屏幕图像有无缺陷;2)对有缺陷的手机屏幕图像中的缺陷进行定位;3)对定位的手机屏幕缺陷进行分类。
通过对手机屏幕图像检查过程进行技术分析,手机屏幕缺陷检测主要存在以下难点:1)缺陷特征提取困难。如图1(e)(f)所示手机屏幕图像缺陷特征极其隐晦,缺陷大多数为几十像素甚至十几像素,且缺陷分布不规律。该特性造成缺陷信息复杂,提取特征极度困难。2)如图1(a)(b)大块锡灰和小块锡灰图像和(c)(d)短划痕和长划痕图像所示缺陷尺寸差异大。同种缺陷形状各不相同,尺寸跨度较大,影响了候选框的边框回归效果。3)缺陷特征相似。手机屏幕中一些缺陷特征极其相似,肉眼难以分辨,如划痕纹理与锡灰相似度高。
针对手机屏幕缺陷数据集带来的检测难点,使得基于机器学习和深度学习的检测框架难以达到令人满意的检测效果。因此,本文在Faster R-CNN目标检测模型,提出PU-Faster R-CNN检测框架,针对手机屏幕缺陷图像的检测难点,实现手机屏幕缺陷的高效检测。
2 PU-Faster R-CNN算法模型
本文在Faster R-CNN目标检测的基础上加以改进,提出PU-Faster R-CNN。PU-Faster R-CNN框架结构如图2所示。该模型在原Faster R-CNN模型中提出多层特征增强模块,特征提取网络层采用多尺度特征提取网络,提出了自适应区域建议网络作为区域建议网络。
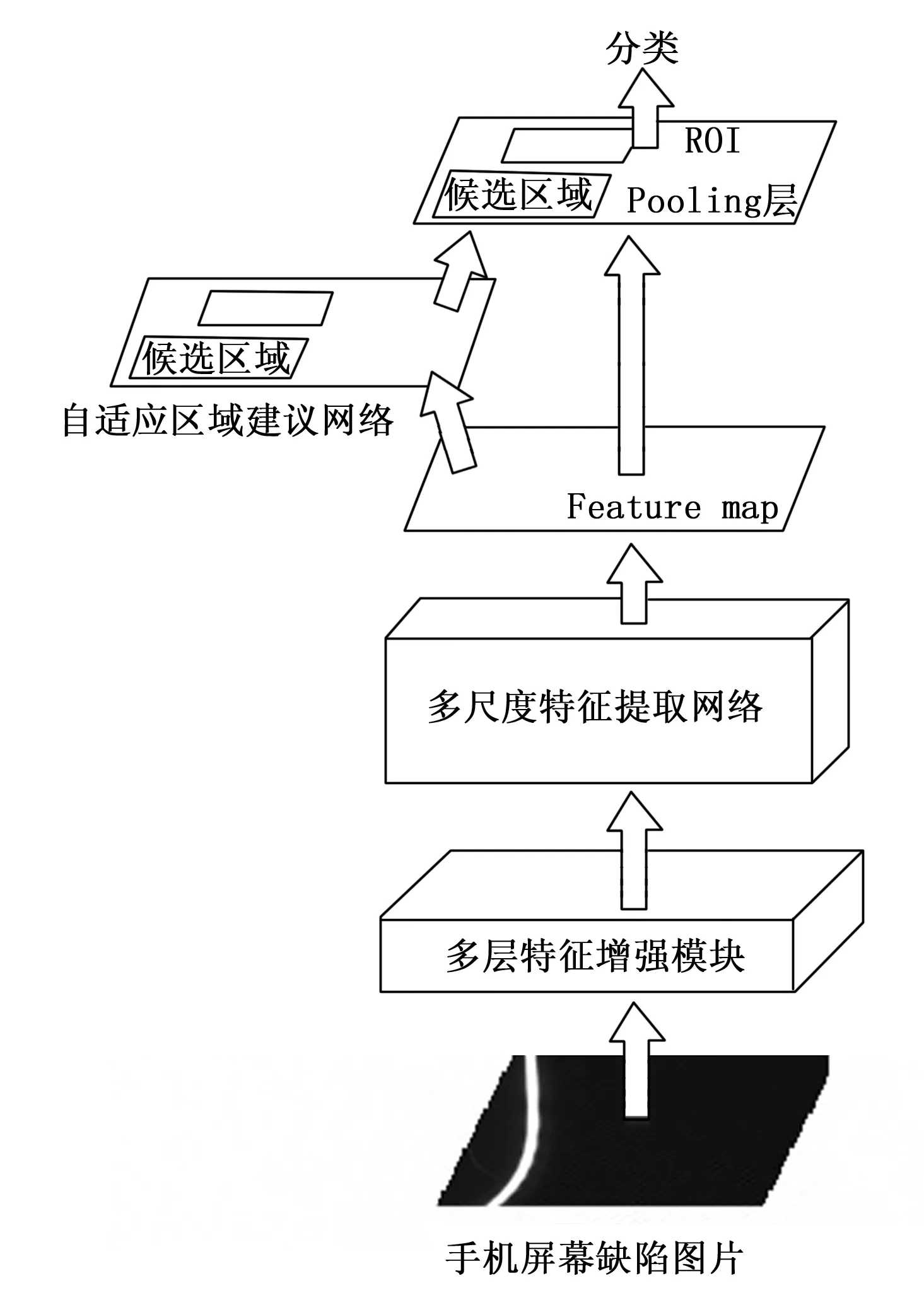
图2 PU-Faster R-CNN框架图
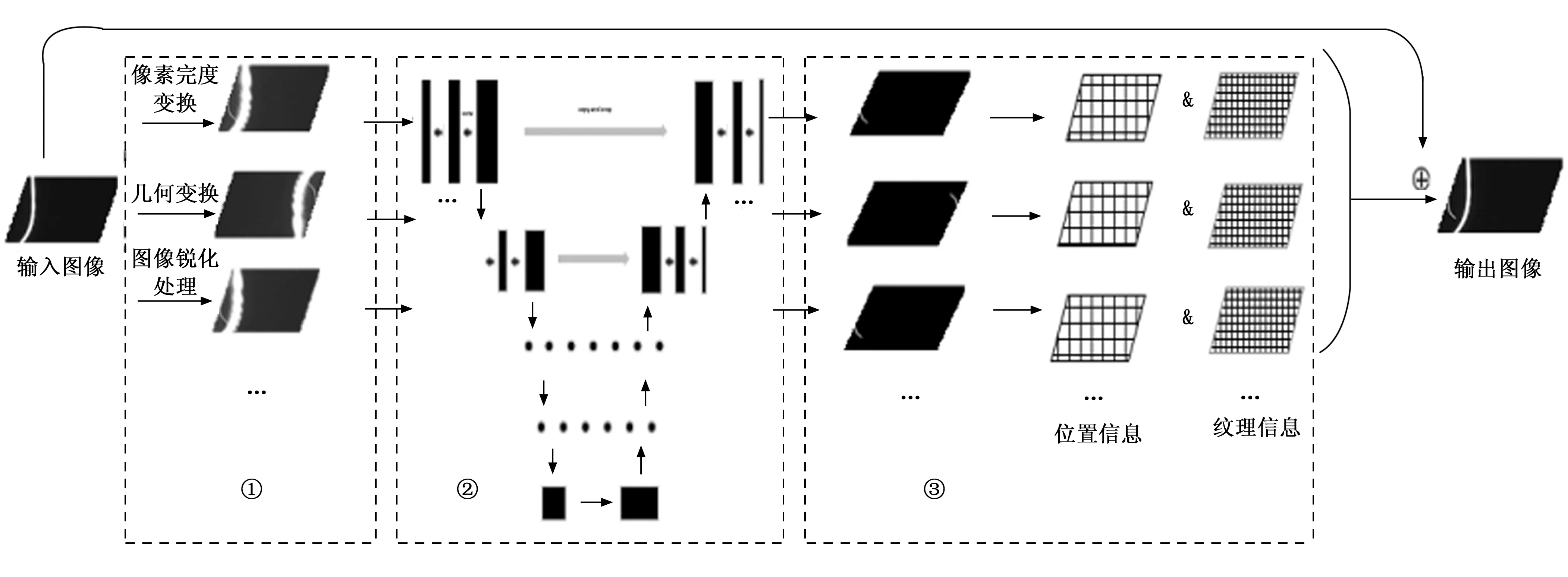
图3 多层特征增强模块
2.1 多层特征增强模块
手机屏幕图像为灰度图像,其中的缺陷通常范围为几十像素甚至十几像素。缺陷特征隐晦,缺乏丰富的特征信息,特征提取层提取到的特征信息缺少该缺陷应具有的关键特征信息,严重影响后续网络层回归和分类,导致检测效果很差。因此,改进网络让特征提取层提取到丰富特征信息,是手机屏幕缺陷检测的关键。
多层特征增强模块主要采用多组图像预处理和U-Net的串联,将手机屏幕缺陷图像中隐晦的缺陷特征信息进行针对性像素加强,进而达到增强图像特征的效果。多层特征增强模块结构如图3所示,该模块分为3个阶段。
第一个阶段对输入图像分别进行像素亮度变换、几何变换、图像锐化等图像处理,得到多组不同图像处理下的原始图像。不同缺陷的特征会因为对应的预处理操作而有效提高了可视程度,各种缺陷特征更清晰,不同类型的缺陷的特征信息得到了不同程度的特征增强,有效为第二阶段的U-Net语义分割提供特征明显的原始图像。
第二阶段,各组图像输入已训练好的U-Net进行语义分割操作,得到多组对应的预测的掩模图。记录各组图像的掩模所在位置信息和对应原图上的纹理特征。
第三阶段,根据对应的位置信息和纹理特征,在原始输入图像对应的位置叠加对应的纹理信息,对同一张原始图像进行相应的特征增强,得到缺陷特征明显增强的输出图像。
手机屏幕图像经过多层特征增强模块处理的先后效果对比如图4所示。容易看到,相比原手机屏幕图(左),手机屏幕缺陷特征变得更加明显,更加突出。其原理如下:
1)图像预处理的使用,扩大图像中不同目标特征之间的差别,抑制不感兴趣的特征,使之改善图像质量,丰富信息量,加强图像判读和识别效果。
2)U-Net串联在图像预处理之后,可以根据U-Net判断每张图像每个像素点的类别得到精确的分割图。记录下分割图的掩膜位置信息以及位置信息对应相应原始图像的位置纹理信息。最终,利用这些位置信息和对应的纹理信息在原始图像上进行叠加,针对性的对原始图像进行特征增强。

图4 效果对比
左列为未处理的手机屏幕缺陷图,右列为经过多层特征增强模块后的手机屏幕缺陷图。方框仅为缺陷所在位置方便读者阅读,非预测结果。
2.2 多尺度特征提取网络
手机屏幕缺陷图像的缺陷目标尺寸很小,多为小目标,一般只有几十甚至几个像素。对于小目标,当卷积池化到最后一层,对于一个RoI区域映射到特征图的特征信息已经很少了。另外,卷积网络中,深层网络能响应高语义特征,但特征图尺寸小,拥有太少定位信息;浅层网络虽然包含定位信息多,但高语义特征比较少,不利于分类。这个问题在手机屏幕缺陷检测中尤为突出,严重影响检测效果。
改进Faster R-CNN的特征提取层,加入特征金字塔网络(FPN,feature pyramid network),改进为多尺度特征提取网络。通过融合上采样后的高语义特征和浅层的定位细节特征,使模型能够融合多个卷积层的多尺度信息,增强特征的表达能力,从而获得更多关于手机屏幕小目标缺陷的有效特征信息,进而提高网络性能。
多尺度特征提取网络结构如图5所示。语义信息增强部分,用ResNet50作为特征提取网络{C2、C3、C4、C5},采用1×1卷积进行横向连接,自上而下地传递语义信息构造{T2、T3、T4、T5},Ti的计算过程为:
(1)
式中,F1×1(Ci)是对Ci进行1×1卷积操作,Up(Ti+1,2)表示对Ti+1进行2倍上采样。表示merge操作。

图5 多尺度特征提取网络
Pi为融合特征部分,其计算过程为:
Pi=F3×3(Ti);i=2,3,4,5
(2)
F3×3(Ti)是对Ti进行3×3卷积操作。
2.3 自适应区域建议网络
手机屏幕图像中,同种缺陷的形状大小各不相同,尺寸跨度极大。因此以人工设置方式在区域建议网络设置的Anchor box模板尺寸和数量与ground truth box存在一定偏差,会影响检测效果。
为提升检测效果,RPN(region proposal network)层引入了Isodata[14]自迭代聚类算法,改进为自适应区域建议网络。通过对Anchor box数据进行自迭代聚类,得到合适的Anchor box模板。灵活数量和大小的Anchor box模板可以有效提高手机屏幕缺陷检测的精度。
Anchor box基本概念为以特征图上可以映射回原图像上的一个点为中心,预先人为设定x个Anchor box模板,称为在这个点上生成的x个Anchor box。Anchor box的生成方式如图6所示,在原始Faster R-CNN中,经过特征提取网络处理之后,得到一个尺寸为m×n的特征图,对应将原图像划分为m×n个区域,即原图的每个区域的中心由特征图上的一个像素点坐标表示。通过上述Anchor机制,在每个区域生成x个Anchor box,x一般人为设置。本文改进的自适应区域建议网络中,x为isodata自迭代聚类算法根据训练集标注尺寸样本聚类得到的聚类中心的数目,各个聚类中心的结果作为Anchor box的模板尺寸。
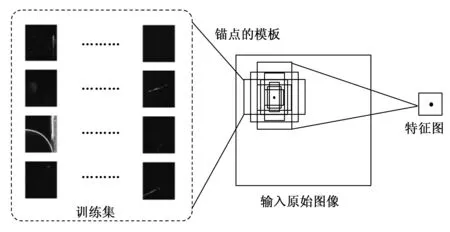
图6 anchor box的生成方式
自适应区域建议网络算法流程如图7所示。自适应区域建议网络基本步骤如下:
1)初始设定K0个Anchor box模板类,每个模板类中最少的样本数为Nmin,输入n个训练集标注尺寸样本,最大迭代次数I。
2)针对每个训练集标注尺寸样本,计算它与模板类中心的距离,将其分入距离最小的模板类中。此时模板类的数目为K1。
3)判断每个模板类中样本数目N是否低于最少样本数Nmin,低于则取消该模板类,类中样本按最小距离原则重新分配到剩余类,令K1减1。
4)根据各模板类中数据,重新计算模板类聚类中心。
5)若K1
6)达到最大迭代次数时终止,输出K=K1,否则返回步骤2继续迭代。K1即为设置Anchor box的模板数量,各模板类聚类中心则为Anchor box模板。
算法根据计算样本与类中心的欧式距离进行分类。距离越小,相似度越大。计算公式为:
(3)
式中,Si是第i个样本,uj为第j个聚类。
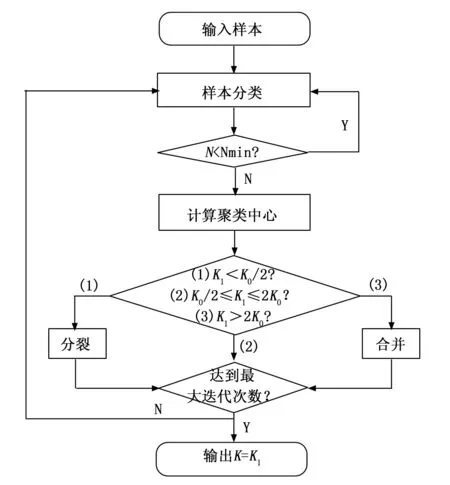
图7 算法流程图
在原RPN网络引入isodata聚类算法,通过迭代聚类训练手机屏幕缺陷样本数据,能够获得合适的Anchor box模板和数量,增强Anchor box的适应性,解决屏幕缺陷尺寸跨度大的问题,提高检测精度。
2.4 损失函数
PU-Faster R-CNN框架的损失函数由两部分组成,RPN部分的损失和Fast R-CNN部分的损失。RPN网络的损失函数是分类损失和回归损失的总和。损失函数计算公式如下:
(4)
其中:Pi表示第i个Anchor box被预测为真实标签的概率。正样本时Pi为1,负样本时为0。ti表示预测第i个Anchor的边界框回归参数。ti表示第i个Anchor对应的ground truth box。Ncls表示一个小批次256中所有样本的数量。Nreg表示Anchor box位置的数量,约为2 400个。
(5)
其中:Lcls是分类损失。Pi表示第i个Anchor box被预测为真实标签的概率。正样本时Pi为1,负样本时为0。
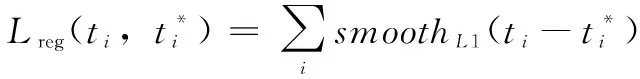
(6)
(7)
ti=[tx,ty,tw,th]
(8)
tx=(x-xa)wa
(9)
ty=(y-ya)haty
(10)
(11)
(12)
(13)
(14)
(15)
(16)
其中:Pi为正样本时为1,为负样本时为0。ti表示预测第i个Anchor box的边界框回归参数。ti表示第i个Anchor box对应的ground truth box。
Fast R-CNN的损失函数部分是PU-Faster R-CNN第二部分的损失函数。Fast R-CNN损失函数由分类损失和边界盒回归损失组成。
L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v)
(17)
其中:p是分类器预测的softmax概率分布。u对应于目标的实际类别标签。tu则对应于由边界框回归器预测的相应类别u的回归参数。v对应于实际目标的边界框回归参数。
L(p,u,tu,v)=-logpu
(18)
(19)
(20)
其中:tu对应于相应类别u·v的边界框回归因子预测的回归参数,而v对应于实际目标的边界盒回归参数。
3 实验结果与分析
3.1 数据集构建与实验设置
实验的数据集来自广东省某手机屏幕生成企业,原手机实体屏幕为透明玻璃面板,需要在指定工控机上通过光源照射,在背景板采集黑白的手机屏幕图像。原始手机屏幕图像如图8所示。

图8 原始手机屏幕图像
原始手机屏幕图像分辨率为6 400×6 400像素,图像尺寸太大,而缺陷只有十几像素甚至几像素,导致目标检测效果不佳。为了获得更加丰富多样的数据,同时深度学习模型的训练要求大量的样本,实验中对数据集进行了数据增强。实验种所采用的数据增强方法为:1)对原始图片进行10×10的切割,最终图片分辨率为640×640像素;2)对于切割后的数据集进行像素变换方法:调节亮度,饱和度,直方图均衡化,高斯模糊;3)对于切割后的数据集进行几何变换方法:翻转,旋转,裁剪。
数据集的标注采用labelImg目标检测数据集标注工具,对每一张数据增强后的图图中的缺陷进行标注,每张图像形成一个xml文件,每个xml文件记录了对应图像所包含的缺陷的种类及缺陷位置信息。
数据集的生成按照PASCAL VOC 2012数据集的相关目录结构和格式生成,最终生成txt文件分别记录每个jpg图像名和xml文件名。
实验的的数据集包含3种类别的缺陷:划痕(scratch)、气泡(bubble)和锡灰(tin_ash)。经过处理后的,数据集图片数量共6 659张,大致按5:1的比例随机选取5 407张图片为训练集,1 252张图片为测试集,如表1所示。在有缺陷的图片中,具体缺陷的数量分布见表2。
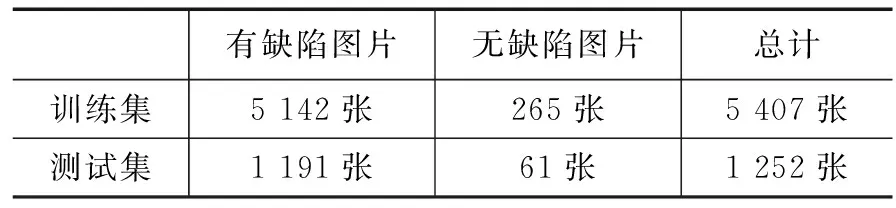
表1 训练集、测试集数量分布

表2 训练集和测试集的缺陷的数量分布
实验采用的计算机硬件配置为Intel(R)Xeon(R)CPU E5-2 650 v4 @ 2.20 GHz,NVIDIA GeForce RTX 3 080 GPU。用Python编程实现改进的PU-Faster R-CNN,用于训练和测试。整个实验是使用开源深度学习框架pytorch实现的。输入图像尺寸为640×640像素。Backbone选择了ResNet50。选择优化算法为Adam算法。学习率为1e-3,使用到的学习率下降方式为cos。训练步数设置为3 000。在获得足够的数据后,使用自适应矩估计(Adam)优化算法进行训练,动量为0.9,权重衰减为0.000 1,beta1为0.9和beta2为0.999。训练批量大小设置为16,以避免局部极小。模型置信度为0.5,非极大值抑制nms-iou参数为0.3。实验分为两部分,第一部分为PU-Faster R-CNN模型和主流的缺陷检测算法的对比实验,参与比较的模型有Yolo系列模型,原始Faster R-CNN模型和SSD模型。第二部分是消融实验,用以验证分析PU-Faster R-CNN各模块对提高手机屏幕缺陷检测性能的有效性。
3.2 实验结果与讨论
论文实验评价指标为目标检测领域常用的评价指标:准确率Accuracy,精确率Precision,召回率Recall,准确度Accuracy of Precision(AP),漏检率Miss rate,错误率Error rate。
3.2.1 对比实验
实验中,为验证所提出的PU-Faster R-CNN对手机屏幕缺陷检测的有效性,将结合不同的主流目标检测框架在手机屏幕数据集场景下进行对比实验。其中参与实验的框架有Faster R-CNN、YoloV3、YoloV4和SSD算法。实验采用数据集见前文,PU-Faster R-CNN针对手机屏幕数据集下的每种缺陷检测效果如图9所示。PU-Faster R-CNN针对手机屏幕数据集下预测每种缺陷的AP和总mAP如图10所示,可以看出,改进后的PU-Faster R-CNN模型在各个类别的手机屏幕缺陷目标检测性能效果都很好。

图9 手机屏幕缺陷检测效果图
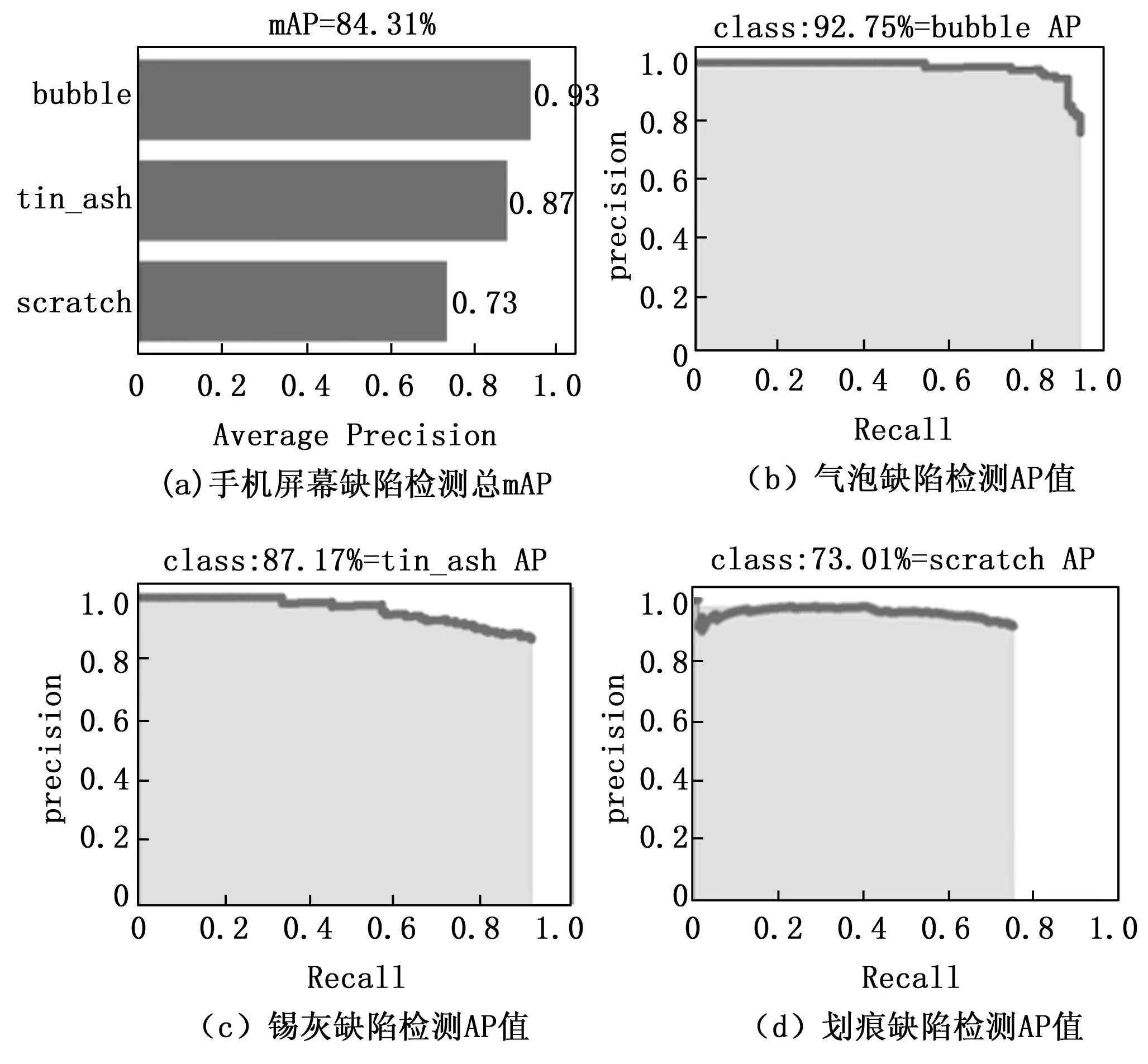
图10 总mAP和每类缺陷预测的AP值
表3分别显示了PU-Faster R-CNN和手机表面数据集上的其他目标检测框架之间的性能比较。与Faster R-CNN相比,PU- Faster R-CNN在mAP指标上提高36.7%、准确率提高了55.5%、精确度提高了52.8%、召回率提高了60.4%、漏检率降低了60.1%、错误率降低了55.5%。框架检测性能提升的原因在于:
1)多层特征增强模块可以显著增强缺陷的语义信息,降低后续检测的难度和提高了检测精度;
2)引入多尺度特征提取网络,提高了模型对多尺度目标的特征提取能力;
3)自适应区域建议网络的提出,通过生成尺寸、数量更合适的Anchor模板,提高预测的精度和框回归的效率。
与YoLo系列模型相比,以YoLoV4为例,PU-Faster R-CNN在mAP性能上提高12.0%、准确率上提高了4.4%、精确度提高了21.4%、召回率提高了7.8%、漏检率降低了7.5%、错误率降低了7.5%。原因在于:YoLoV4骨干部分的BoF特征包括特征CutMix 和 Mosaic增强、DropBlock 正则化和类别标签平滑化,对于特征明显的缺陷检测图像有优秀的效果,而手机屏幕缺陷图片中的缺陷特征隐晦,YoLoV4提取到的特征信息掺杂着一些非关键信息,严重影响回归与分类,导致检测效果略差。PU-Faster R-CNN提出多层特征特权模块,通过语义分割,让用于区分缺陷类别的轮廓特征和纹理特征变得明显,提升了模块对缺陷特征的表达能力,因而检测性能比YoLo系列算法更胜一筹。
与SSD模型相比,PU Faster R-CNN在mAP性能指标上提高24.2%、准确率上提高50.9%、精确度提高了65.0%、召回率提高了0.9%、漏检率降低了0.7%、错误率降低了50.9%。原因在于:手机屏幕缺陷多为小目标缺陷。在众多目标检测算法中,SSD对于小目标的检测表现较差,因为经过多层卷积,SSD对小目标提取的缺陷特征信息丰富度缺乏。PU-Faster R-CNN多尺度特征提取网络融合上采样后的高语义特征和浅层的定位细节特征,充分提取小目标缺陷的特征信息,故能提高性能。
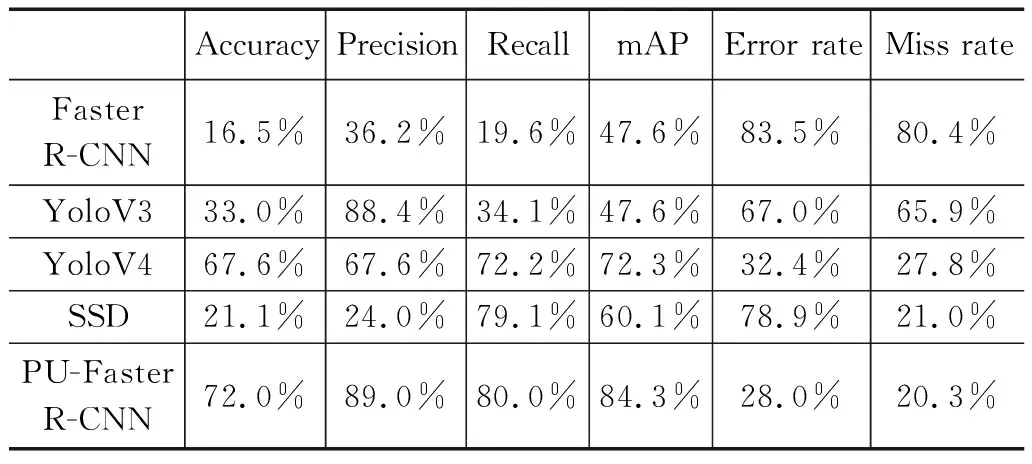
表3 PU-Faster R-CNN与主流技术各项指标对
3.2.2 消融实验
本实验将验证分析PU-Faster R-CNN各模块对提高手机屏幕缺陷检测性能的有效性。如表4,实验中使用了4种不同的方案。方案一选择原始Faster R-CNN作为整个框架;方案二选择基于Faster R-CNN引入多尺度特征提取网络;方案三选择基于Faster R-CNN引入多尺度特征提取网络和多层特征增强模块;方案四是完整的PU Faster R-CNN。4个不同实验方案分别在手机屏幕数据集得到四组实验性能结果。
方案二中基于原始Faster R-CNN加入多尺度特征提取网络,较方案一在mAP指标上提高了5.8%,准确率提高了15.9%,精确率提高了8.4%。原因在于多尺度特征提取网络融合了浅层网络的定位信息和深层网络的高语义特征,实现了特征的跨层连接,进而得到不同尺度的特征图。相比原始Faster R-CNN使用一组基础的卷积层+ReLu激励层+池化层提取图像特征的方法,能提取到更加丰富的特征信息,用于后续分类与回归,故能提高性能。
方案三中基于原始Faster R-CNN加入多尺度特征提取网络和多层特征增强模块,较方案二在mAP性能指标上提高了19.1%,准确率提高了30.0%,精确率提高了13.2%。方案三相比于方案一,在mAP性能指标上提高了24.7%,准确率提高了45.9%,精确率提高了21.6%。数据集中手机屏幕图片特征非常隐晦,缺陷分布不规律,纹理、背景复杂,提取特征极度困难,且缺陷形状大小等属性上的特征呈现多样性,即使同一种缺陷,尺寸和形状上也存在多种分布。多层特征增强模块通过图像预处理和U-Net网络的结合,对不同类型的缺陷特征信息进行特征增强,再经过语义分割得到特征的位置信息以及纹理特征,叠加到原图上,消除了图像无关信息,增强了缺陷信息的轮廓特征和纹理特征,最终从隐晦的手机屏幕图片中提取到丰富的特征信息。
方案四中为完整的PU-Faster R-CNN,基于原始Faster R-CNN加入了多尺度特征提取网络、多层特征增强模块和自适应区域建议网络,较方案三在mAP性能指标上提高了12.0%、准确率提高了9.6%、精确率提高了31.2%。方案四相比于方案二,在mAP性能指标上提高了30.9%,准确率提高了39.6%,精确率提高了44.4%。方案四相比于方案一,在mAP性能指标上提高了36.7%,准确率提高了55.5%,精确率提高了52.8%。原始Faster R-CNN中RPN网络的Anchor box模板尺寸和数量要求人为设置,而在手机屏幕缺陷检测场景下,缺陷形状大小不一,跨度极大,人为设置的Anchor box模板与实际ground truth box存在较大差异。PU-Faster R-CNN的自适应区域建议网络对训练集样本进行自迭代聚类,将聚类得到的聚类中心和聚类中心的数量分别作为Anchor box的模板尺寸和模板数量,这样得到的Anchor box模板与缺陷尺寸的拟合性更高,有效提高屏幕缺陷检测的性能。

表4 PU-Faster R-CNN消融实验性能指标
4 结束语
长期以来,缺陷检测问题一直困扰着工业制造业。手机表面缺陷检测作为工业生产的重要组成部分,越来越受到重视。然而,图像特征隐晦、缺陷尺寸差异大等问题限制了基于深度学习的检测框架。因此,基于PU-Faster R-CNN的手机屏幕缺陷检测框架被提出解决上述问题。针对图像特征不明显,设计了多层特征增强模块,采用一种新颖的方式增强缺陷的特征信息。构建多尺度特征提取网络,有效提取多尺度的缺陷语义信息。论文中设计了自适应区域建议网络,自适应的Anchor box模板生成方式,通过聚类的方式生成拟合性更好的Anchor box模板。实验结果表明,该模型在手机屏幕检测中优于流行的目标检测模型。
最后,该框架适用于低复杂性数据集。然而,当数据集的复杂性增加时,检测结果可能不太令人满意。复杂缺陷的检测也是未来工作的一个新的研究方向。该框架有望成为一种新的目标检测解决方案。它可以应用于手机表面生产,包括应用场景。
猜你喜欢
建材发展导向(2022年23期)2022-12-22
建材发展导向(2022年12期)2022-08-19
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
电子制作(2018年19期)2018-11-14
数学小灵通·3-4年级(2017年9期)2017-10-13
自动化学报(2017年11期)2017-04-04
中国房地产业(2016年24期)2016-02-16
中国卫生(2015年9期)2015-11-10
噪声与振动控制(2015年4期)2015-01-01
