
基于局部对比度和全卷积网络的小空间碎片检测
2023-08-03 00:31曹云峰
计算机测量与控制 2023年7期
陶 江,曹云峰
(南京航空航天大学 航天学院,南京 211106)
0 引言
空间碎片数量的急剧增加是在轨运行航天器的主要威胁。一般而言,空间碎片是指在地球轨道上或重新进入大气层的人造物体,不再具有任何用途,包括其碎片和部件[1]。空间碎片可以通过不同的方式产生,例如航天器的超高速撞击、高强度爆炸或低强度爆炸、失效卫星和火箭上面级[2]。截止2018年,太空中的空间碎片质量超过300万公斤,且还在大幅增加。2018年2月的统计数据表明,尺寸大于10厘米的空间物体数量已超过18 500个,其中75%是空间碎片[3]。由于其高轨道速度,小尺寸碎片也可能导致灾难性破裂,这不仅会损坏正在运行的航天器,还会增加轨道上的危险碎片数量,进而导致进一步的空间碰撞。因此,空间碎片监视对于避免潜在的碰撞风险和确保空间活动的安全具有重要意义,其中,基于天基监视平台的空间碎片检测对于准确的威胁度评估至关重要。
为了给碰撞规避预留充足的时间,需要在较远的距离检测空间碎片,尽管远距离的空间碎片大小为几十米,但是其在整个图像中占据几十个像素甚至几个像素,属于典型的“小目标”。与大目标相比,小目标没有形状、纹理、颜色和局部特征等视觉特征,呈现出斑点状,因此空间碎片小目标检测难度较大。此外,宇宙噪声和星空背景(恒星等)也为空间碎片检测增加了难度。为了解决上述问题,本文利用空间碎片与天体背景中恒星运动特征的差异,并结合多帧星图对空间小目标进行检测。
在过去的几十年中,小空间目标检测方法受到了广泛关注[4],如背景减除法[5,6],光流法[7-9],检测前跟踪法[10],帧差法[11-12]。局部对比度法(LCM,local contrast method)[13]是一种有效的小目标检测方法,可以在增强目标信息的同时抑制背景杂波,但忽视了视频中的帧间信息。近年来,提取显著区域和计算时空显著性在视频目标检测中得到了广泛应用,取得了一定的进展[14-16],但受限于光流估计的计算复杂度,导致实时性较差。随着深度学习的发展,通过训练的端到端全卷积网络(FCN,fully convolutional network)可以直接生成像素级显著性图[17],通过学习帧间的关联,避免了耗时的光流计算[18]。与传统的卷积神经网络(CNN,convolutional neural network)不同,CNN是在最后一个卷积层后采用全连接层得到固定长度的特征向量从而实现目标或图片分类。而FCN是在最后一个卷积层后连接反卷积层,实现对卷积层得到的特征图进行上采样,使得特征图恢复到和输入图像相同的尺寸,最后对每个像素进行损失计算,从而对每个像素都可以实现预测。这样既保留了原始输入图像的空间信息,又实现了对最后的特征图的逐像素分类。由于FCN具有精细的目标检测优势,近年来被广泛应用于空间目标探测中。Andrea等人[19]提出了一种基于U-Net的空间目标轨迹提取方法。U-Net也是一种全卷积网络,和FCN[20]有两个区别:(1)U-Net采取了编码器-解码器网络结构,编码器和解码器对称,而FCN的解码器只有一个反卷积层。(2)U-Net采取了跳跃连接,将反卷积上采样的结果和编码器结构中输出的相同分辨率的特征图的模块进行拼接操作(concentration),作为解码器中下一个子模块的输入。而FCN中采取的是相加操作(addition)。相加操作的特征图通道数不变,但每个特征图包含了更多的信息;而拼接操作使特征图通道数增加,每个特征图保留了更多的位置信息,对于像素级分类任务更有优势。Guo等人[21]提出了一种改进的U-Net方法Channel and Space Attention U-net(CSAU-Net)用于单帧图像的空间目标分割。该方法通过添加注意力模块使得网络更充分地利用小尺度特征图信息并增强空间目标的注意力。然而上述方法忽略了空间目标的运动特性以及连续时域信息,无法实现对序列图像中的空间目标检测。
本文提出了一种针对序列图像的高效空间碎片小目标显著性检测方法。首先,基于局部对比度度量获得局部对比度映射;然后,将对比度映射馈送到深度网络,并通过深度神经网络学习帧间信息,捕获时空显著性。本文的主要结构安排如下:第1节介绍了空间碎片小目标显著性检测的主要框架,以及单帧局部对比图和时空显著性模型;第2节讨论了实验结果和分析;第3节对全文工作进行总结。
1 空间碎片小目标显著性检测方法
1.1 算法总体方案
在介绍算法的具体细节之前,首先对空间碎片小目标显著性检测算法的总体方案进行概述。本文算法的思想为:人类视觉系统[22-23]表明,静态视觉显著性和动态视觉显著性等低级视觉特征是在人类注意前阶段处理的,本文受此启发,将基于亮度的对比度和基于运动的动态显著性结合到空间碎片显著性检测模型中。将一系列天基监测视频帧输入显著性模型,可以从模型中获得空间碎片小目标的显著性分析结果,即更亮的图像像素意味着更高的显著性。本文根据空间碎片小目标的时空特性,设计了如图1所示的空间碎片小目标显著性检测模型。该模型包括两个模块:1)单帧模块。受对比机制的启发,该模块采用了局部对比度度量方法,并利用核模型来度量单帧图像的局部对比度;2)帧间模块。以空间碎片视频相邻帧的图像作为输入,直接生成时空显著性图。该模型采用全卷积网络进行像素级时空显著性估计,并采用基于大规模图像数据集的预训练模型来节省训练时间。

图1 基于深度卷积神经网络的空间碎片小目标检测算法流程图
1.2 单帧模块
局部对比度测量将天基监测视频中的灰度图像作为输入,并输出空间碎片的局部对比度图。由于空间碎片区域具有与其周围区域不连续的特点,并且集中在一个相对较小的区域,可以认为是一个均匀、紧凑的区域。同时,周围的背景与其相邻区域一致[24],因此,图像中与邻域不一致的像素区域很可能是一个目标,可以通过对比度图来描述。如图2所示,w表示单帧图像,u表示空间碎片,v是一个滑动窗口可以移动的图像。因此,可以通过在单帧图像w上移动窗口v来生成图像块。当移动到目标u所在的位置时,v中除u以外的区域目标的背景区域。然后,将获取的图像分为九个单元。

图2 图像块和图像栅格
图像块的中心单元标记为0,空间碎片可能出现在该区域。第i个单元格的灰度平均值由以下公式计算:
(1)

(2)

(3)
因此,局部对比度度量可以通过式(4)计算得到:
(4)
上述方程式表明,Cn越大,出现空间碎片小目标的可能性就越大。
最后,将中心像素值替换为当前图像块的局部对比度值Cn。重复上述过程,可以获得与整个图像相对应的局部对比度图。考虑到空间碎片的大小随运动而变化,采用了多尺度局部对比度测量方法。首先给出了一系列的尺度l,然后计算每个尺度的局部对比度Cl,然后通过式(5)计算多尺度局部对比图。
(5)
其中:lmax是最大比例,p和q分别表示对比度图像矩阵的行数和列数。
1.3 帧间模块
基于FCN的空时显著性网络如图4所示。该网络以序列图像的前后帧为输入,结合局部对比度测量产生的局部对比度信息作为显著区域的先验信息(潜在显著区域),直接生成最终的时空显著性图。该网络由5个卷积层和5个反卷积层组成,学习时间显著性和空间显著性信息。图中的CRn表示n个卷积(convolution)+非线性校正单元(ReLU)模块,DRn表示n个反卷积(deconvolution)+非线性校正单元(ReLU)模块。首先,前后帧(It,It+1)和当前帧It的局部对比度图Pt在通道方向上连接,即张量拼接操作(contact),张量拼接示意图如图3所示。前后帧以及当前帧对应的局部对比度图均具有相同的宽h和高w。前后帧图像均为RGB三通道的彩色图像,局部对比度图为一维的灰度图。

图3 全卷积网络和局部对比图结合过程
通过拼接得到维度为(h,w,7)的张量,其中7和h,w分别表示张量的通道数和高度、宽度。因此,维数为(h,w,7)的张量被输入到基于全卷积网络的时空显著性网络中。通过对输入特征图进行卷积操作加上偏差可得到输出特征图,该特征图表示对于输入特征图所有位置上的特征表达。定义输入特征图为I,输出特征图为F,卷积核为W,偏差为b,卷积步长为s,则输入特征图和输出特征图的关系如式(6)所示:
F(I,W,b,s)=W*sI+b
(6)
在每个卷积层的输出中应用校正线性单元(ReLUs)的非线性特性,以提高特征表示能力,在此之后连接最大值池化层以得到更加鲁棒的特征表达能力,例如对输入特征图上微小变化的抗扰能力。由于卷积核池化操作使得输出的特征图分辨率较低,而对于显著性检测,需要获取精确的像素级显著性预测,因此在卷积层之后添加多个反卷积层,以实现对卷积层和最大池化层获得的特征图上采样。定义输入图像为I,通过卷积操作得到的输出特征图为F,反卷积层为D,上采样因子为s,则通过反卷积操作得到的输出特征图Y可表示为:
Y=Ds(F(I,ΘF);ΘD)
(7)
其中:ΘF和ΘD分别表示卷积操作中和反卷积操作中的可学习的参数。最后一个卷积层的卷积核大小为1×1,结合sigmoid激活函数实现将特征图映射为显著图。sigmoid激活函数的作用是将每一个预测值映射为0到1之间。最终,通过结合局部对比度先验信息和空时域显著性学习网络实现对当前帧的显著性预测。
本文方法和现有的基于FCN的方法的主要区别在于:(1)输入端引入了当前帧的局部对比度图作为先验信息。由于该局部对比度图不仅具有增强目标信息的优点,同时可以抑制空间背景噪声,因此,可以极大改善网络对于空间域信息的学习性能。(2)通过同时输入连续的视频序列图像,可以避免传统的FCN将图像作为独立个体的缺点。充分利用了连续帧的空时域上下文线索,使得网络具备对空时域显著性的学习能力。

图4 空间碎片空时域显著性检测网络示意图
在训练过程中,利用视频序列数据集的前后帧和空间碎片的当前帧的显著性标签对神经网络进行训练,同时从空间动态场景中学习空时域显著性。卷积网络对应于VGGNet网络中的前5个卷积层。因此,在训练过程中,首先在大型数据集上训练权重[26],其他层的权重随机初始化。采用大小为1×1的卷积核和sigmoid激活函数的全卷积网络来产生空时域显著性结果。每个元素的输出都有一个从0到1的实值。采用5幅图像的小批量随机梯度下降(SGD)和初始学习率为0.000 01的多项式学习策略来最小化损失函数。由于空间碎片属于小目标,最终预测得到的显著图中显著性区域和非显著性区域像素个数极不平衡,因此采取加权交叉熵损失函数来解决正负样本不平衡的问题。加权交叉熵损失函数定义如下:
(8)
其中:G表示当前帧的显著性真值图,P为当前帧的显著性预测图,α表示显著性像素面积在真值图中的比例,G∈{0,1}h×w,P∈{0,1}h×w,gi∈G,pi∈P。
训练完成后,给定一对帧间图像和当前帧的局部对比度图作为输入,空时域显著性网络就可以输出当前帧对应的显著图。获取当前帧显著图后,迭代输入下一帧就可以实现整个视频序列图像的显著性预测。和当前的两分支视频显著性预测网络[27-29]相比,本文通过直接将局部对比度和空时域显著性网络相结合的方式更加简洁,避免了分别学习空域特征和时域特征并另外设计空时域特征融合网络架构。此外,本文方法可以直接输出空时域显著图,避免了耗时的光流计算。和当前的两模块方法[30]相比,本文方法通过局部对比度方法直接获取当前帧的空间域信息,避免了单独设计和训练空域显著性网络。
2 实验结果
2.1 评价指标
为了评估该方法的性能,本文给出了定性和定量的比较结果。本文中使用的量化指标是准确率/召回率(PR)曲线、F-score和平均绝对误差(MAE)。
首先采用PR曲线来评估显著性检测结果的性能。准确率表示正确生成的显著性像素在所提出方法检测到的所有显著像素中所占的比例,召回率表示正确生成的显著像素占显著性真值的百分比。通过将操作点阈值从0变为255得到256个准确率和召回率点对,从而绘制PR曲线。
为了全面评估显著图的性能,同时使用F-score度量。F-score定义为:
(9)
根据前期Achanta等人的研究工作[31],β2设为0.3。
2.2 实验设置
由于缺乏关于空间碎片的真实视频序列数据集,本文在TERRIER[32]等人提出的阿波罗航天器三维模型基础上,并通过3dsMAX[29]进行渲染,构建了一个空间碎片视频仿真数据集,以验证所提出的方法。该数据集是一个视频序列,模拟了空间碎片、太阳和空间监视平台之间的相对运动,总共包括2 000幅可见光图像。该场景描述了一个空间碎片接近位于近地轨道(LEO)的天基监视平台。为简化实验,本文目前不把其他行星(如地球)和恒星(如太阳)作为图像背景的一部分,只考虑远距离恒星。模拟图像背景时,位置、运动参数和光度数据参考Tycho-2星表。视频序列图像大小为640×480。模拟的空间碎片与可见传感器之间的最远距离为30公里,最近距离为20公里。国际光学工程学会对小目标的定义,模拟的小目标总像素不超过80[33]。视频序列中的空间碎片最大像素数量为50个,距离为20公里,符合标准小目标的定义。此外,本文参考林肯实验室的天基可见光传感器[34-35],设置了图像传感器的参数。模拟的空间碎片视频序列数据集的具体参数如表1所示。图5为不同观测距离下的空间碎片视频图像。如图5(a)所示为距离观测传感器为30 km的空间碎片图像,空间碎片的大小为16像素;图5(b)为距离观测传感器为20 km的空间碎片图像,空间碎片的大小为50像素。

图5 不同距离和像素大小的空间碎片

表1 实验参数设置
2.3 实验结果分析
定性分析:如图6所示为第71~74帧的空间碎片视频序列图像,相应的显著性真值图如图7所示。图8为局部对比度图。如图8所示,仅考虑空间信息的显著性检测方法在动态场景中面临巨大挑战,因为该方法没有充分利用时域信息导致一些恒星被同时检测。空时域显著性检测结果如图9所示。从图9可知,网络输出的显著图只包含空间碎片目标,滤除了图8中残留的少量背景恒星目标,实现了对视频序列图像中空间碎片的准确检测。
定量分析:由于本文提出的视频显著性检测方法是目前已知的首次将其用于空间目标检测的方法。因此,本文没有与其他相关方法进行比较。但本文使用了文献[18]中提出的视频显著性目标检测方法对我们的数据集进行了测试,但测试结果表明,该方法对动态场景中的小目标具有局限性。由于宇宙背景中存在白噪声,参考文献[31],本文建立了方差为0.005和0.01的两组零均值高斯白噪声。不同方差下的PR曲线和F-score曲线如图10所示。从图10左图可知,本文提出的方法在不添加噪声时的检测准确率最好,当高斯噪声方差值变为0.005和0.01时,检测性能变化不大,显示了该方法对方差变化具有良好的鲁棒性。从图10右图可知,当高斯噪声方差值变为0.005和0.01时,检测性能下降不大,同样显示了该方法检测准确率的鲁棒性。为了真实地模拟天基传感器,还讨论了眩光效应[36]。眩光效应是指在光学传感器的透镜系统中,由明亮的光线衍射(如阳光)引起的透镜眩光效果。眩光效果可通过3dsMAX渲染软件中的filter参数进行设置。设置了大小为1和2的两组眩光效果。不同方差下的PR曲线和F-score曲线如图11所示。其中图11左图为不添加眩光、眩光大小为1、眩光大小为2三种情况的PR曲线图。当不添加眩光时,该方法具有较好的检测准确率;当眩光大小为1时,检测性能显著下降;当眩光大小为2时,检测性能较低。图11右图为不添加眩光、眩光大小为1、眩光大小为2三种情况的F-score曲线图。和PR曲线图具有同样的检测性能变化程度。因此由实验结果可知,该方法对眩光效果非常敏感。

图6 部分原始视频序列图像

图7 显著图真值

图8 视频序列的局部对比图

图9 视频序列的显著图
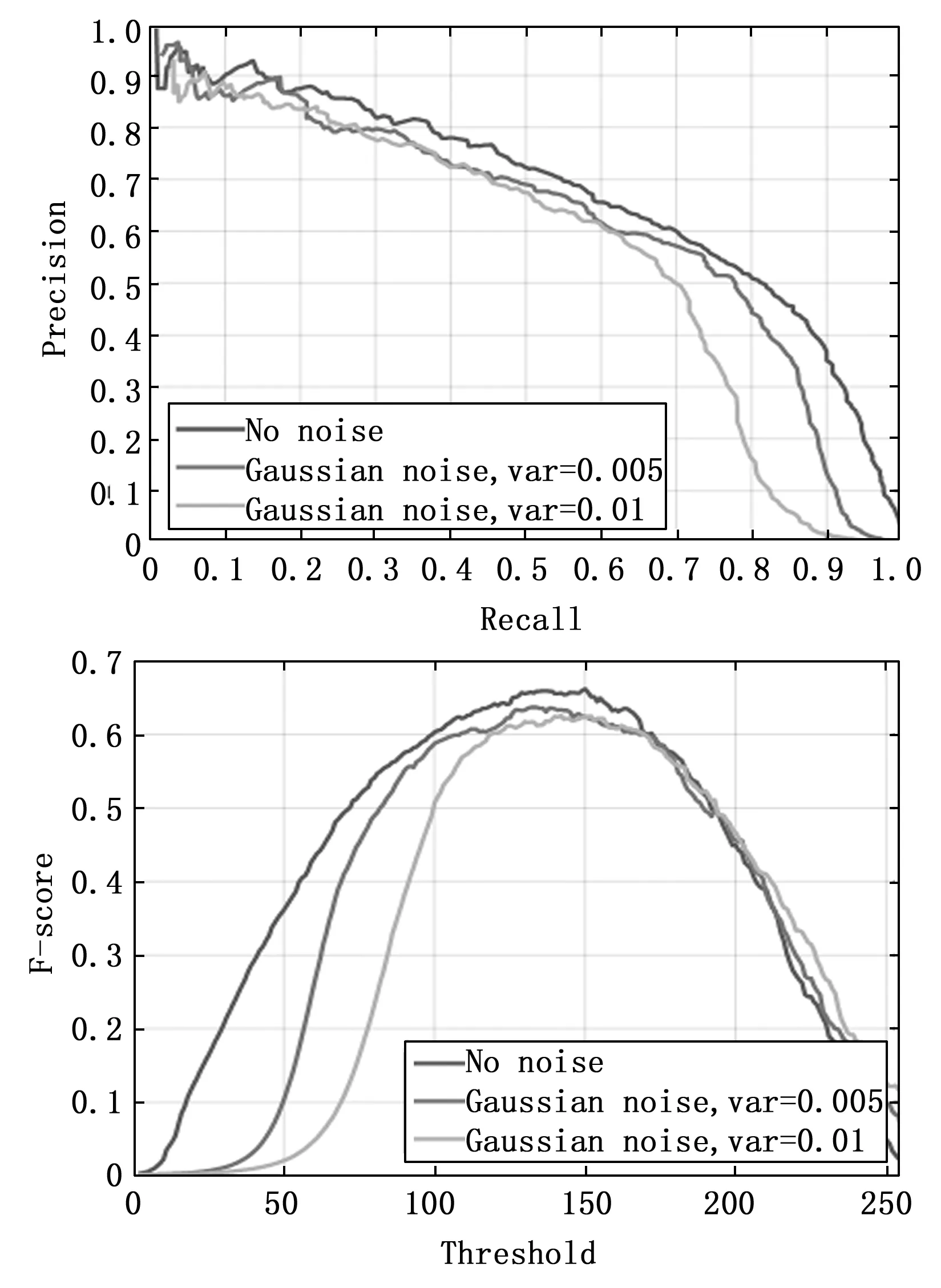
图10 不同方差下的PR曲线和F-score曲线

图11 不同眩光效果下的精度-召回率曲线和F值曲线
3 结束语
本文提出了一种基于深度卷积神经网络的天基监视平台空间碎片显著性检测方法,分为局部对比度和空时域显著性网络两部分,分别获取动态场景的空间信息和空时域信息。该方法将局部对比度度量输出的局部对比度图和时空显著性网络进行融合,能够捕获小目标的显著性先验信息,同时学习帧间时间信息。通过本文构建的空间碎片视频序列数据集上测试了本文提出的方法,并在不同的宇宙噪声下对其进行了评估。验证结果表明,该方法对于空间碎片小目标显著性检测非常有效,并且在不同噪声背景下具有良好的鲁棒性。由于该方法对于太阳眩光较为敏感,下一步可通过结合语义分割的方法对太阳预处理,实现太阳背景下的空间碎片准确检测。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
西南交通大学学报(2018年5期)2018-11-08
北京航空航天大学学报(2018年1期)2018-04-20
中国与非洲(法文版)(2017年10期)2017-11-23
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20
知识产权(2016年8期)2016-12-01
