
体育赛事用户情感监测系统搭建实验
——以斯巴达勇士中国区赛事为例
2023-08-02 09:00郭雨丝
当代体育科技 2023年19期
郭雨丝
(首都体育学院 北京 100191)
随着社会经济发展,休闲体育活动和体育赛事逐渐受到越来越多人的青睐,但是由于产业处于发展初期,各项体育赛事发展参差不齐。随着高速发展而带来的风险与问题层出不穷。2021 年,甘肃白银百公里越野赛21人遇难,更是将赛事运营的专业性和各类比赛体验差别的讨论推向了舆论高峰。通过赛后问卷中参赛者的评分和评价内容,对文本信息进行挖掘,从而可以制作一个用户的情感分析器,该系统经过长时间的数据积累和分析校正,可以用于监控相关账户社交媒体、微信群中的用户情感状态,可以在数据初筛和监测方面起到重要作用。
现阶段,对于数据的收集、整理、分析多通过人工进行,在数据量较小、赛事分布不够密集的时候尚可进行,而在未来产业的高速发展中,机器学习和文本挖掘在体育赛事用户情感信息的反馈和监控中将发挥巨大效用。
1 相关已有研究
以“体育赛事”和“文本挖掘”为检索词,在中国知网(CNKI)、万方、维普三大平台内进行搜索,仅有1 篇相关文章,通过对微博相关内容进行文本挖掘,研究东京奥运会的网民情感情况,以期对北京冬奥会的舆情管理提供建议。以大众体育赛事为研究对象,关注赛事运营本身的质量和参赛者体验的研究尚未出现。
研究方法方面,沈昕怡等[1]在对东京奥运会的网络舆情研究中,选择使用Python 对微博平台的热搜话题数据及对应推文进行爬取,通过词频统计、感情分析等方法,了解社交网络媒体中网民所关注的奥运会主题及感情倾向,而对具体使用的算法并未提及;王瑾璟[2]在对五星级酒店在线外卖评价的研究中,使用八爪鱼采集器对饿了么和美团外卖平台的相关点评进行数据爬取,并使用Python中的jieba工具进行分词,人工标注1 000 条情感倾向评论数据(有效数据共1 595条),通过朴素贝叶斯模型进行情感分析,使用算法工具包sklearn 中的feature_extraction.text.CountVectorizer工具实现词向量的标记,并通过native_bayes 工具包构建模型,最终模型的测试准确率为0.835;郭凌云等[3]在对民宿用户满意度的研究中,使用Python爬取途家网、携程网、Airbnb和缤客网的民宿用户评论数据,并使用LDA 主题聚类模型进行聚类分析,从而得出中美两国影响民宿用户满意度的因素及程度;邱冬阳等[4]在对双十一活动消费者满意度的研究中,使用Python 爬虫程序对不同时期美妆品类的消费者评论进行获取、清洗,利用jieba 分词工具将句子进行切分,并引入SnowNlp 情感分析,通过情感词库匹配法实现情感分类,建立LDA(latent dirichlet allocation)主题模型,进一步分析满意度的影响因素及形成因子。
2 数据来源与选择
此次实验以斯巴达勇士赛中国赛区的比赛为例。斯巴达勇士赛(Spartan Race)是一项风靡全球的系列障碍赛,自2009年起源于美国以来,已有来自美洲、欧洲、亚洲、大洋洲、非洲的20 个国家和地区被授权举办这项顶级赛事,2016 年,斯巴达勇士赛正式登陆中国,并在3年内高速发展为13座城市36场的大型系列赛事。斯巴达勇士赛与其他障碍路跑有些许不同,其拥有完善的竞赛体系、进阶体系和荣誉体系[5]。在同一套的赛事体系、赛事规则、执行标准和运营团队指导的前提下,其数据量和用户数量快速增长,已经基本可以达到引入机器学习和数据挖掘的需求。
2.1 数据来源
2016年,第一场斯巴达勇士赛中国赛举办后,举办方即开始了赛后问卷的收集工作,问卷内容不断更新修改,于2018年开始基本确定整体框架,主要分为区域满意度评分、赛事信息服务评分、整体意见、历史参赛情况、本次参赛相关信息、运动习惯等个人信息,共计6大部分,70余项内容。
2.2 数据的选择
此次实验选用2018 年的6 场赛后数据作为训练组,2019年的5场赛后数据作为实验组,赛事级别和赛事规模相对接近,举办城市、参与人群均存在部分的重叠。通过整理和筛选,此次实验仅使用净推荐值(NPS)、综合评分、文字形容、赛后意见4 项内容,详见表1。

表1 数据选择及相关信息
3 实验方法及过程
3.1 数据提取及预处理
该实验使用Python 对数据进行处理,首先引用pandas包对相关数据表格进行阅读,并使用切片语句,将上述提到的4列数据分别进行切片和查看。由于各场比赛的赛后问卷结构不是完全相同的,需要分别进行切片。
数据的整合过程中,由于各表格的标题内容不完全一样,需要提前使用rename 函数将所有表格的标题分别进行修改和重命名,分别将“您会向同事或者朋友推荐斯巴达勇士赛吗(满分10分)?”改为“NPS”;将“您如何评价本次斯巴达勇士赛的整体体验(满分10分)?”改为“评分”;将“请用一个词形容您心中的斯巴达勇士赛”改为“形容”;将“斯巴达赛事如何可以做得更好?请您留下任何可以想到的意见!”改为“意见”,从而获得标题统一的多个数据集。
3.2 文本分词
引入停用词stopwords 词表,包含各类标点,如“;”“.”“。”“?”“!”“-”“~”等,以及一些没有实际意义的语气词,如“啊”“唉”“吧”“被”“而且”“不过”等,共768个词组,对文本进行分割,在分割内容后插入空格。并使用jieba分词工具将评论语句进行分词。
3.3 训练数据集
引用sklearn中的TfidfVectorizer和LogisticRegression 包,对数据进行机器学习的中文语言处理,通过对词项的IDF 值进行定义和判断,机器实现数字与文字的对应,将每段文字赋予一个数字化的向量值(学习),再通过逻辑回归的方式,计算文字所对应的向量值(预测),并与原标记值进行比对(测准)。
sklearn 库全称为Scikit-learn,是基于Python 编程语言用作机器学习的开源数据包,具有分类、回归、聚类、数据预处理等算法,具体包括支持向量机(SVM)、随机森林、k-Means、DBSCAN、主成分分析(PCA)等方法[6]。
此次数据采用了两组10 分指标和两组文字评价。净推荐值(NPS值)是指是否愿意将赛事推荐给自己的朋友,是一种计量某个客户将会向其他人推荐某个企业或服务可能性的指数。作为一个流行的顾客忠诚度分析指标,研究顾客口碑如何影响企业或品牌的成长,多家国际公司都用其作为评价市场口碑情况的重要数据。这个数值一定程度上表现了用户满意度,但是对比发现,用户的整体体验评分与NPS仍有一定差异,通过两个数值与文字的匹配回归结果来看,整体体验评分的准确值更高。
文字内容的选择上,由于问卷问题的设计“请用一个词形容您心中的斯巴达勇士赛”在最初是用作“用户第一印象”的文字云作为表达的,简短的词汇或词组很难表达用户的情绪,且单个形容词或名词的表述与评分数值的相关性较差;“斯巴达赛事如何可以做得更好?请您留下任何可以想到的意见!”项内容,由于提问方式的表达问题,整体文本偏负面,但相比单词形容来讲,其测算出的准确值相对高一些。
因此,在该实验的测试集中,选用“评分”和“意见”两组数据进行训练与测试。
3.4 实验对比
由于实验初期对于数据的选用和数据量的划分情况难以确定,因此做了多组对比实验,包括不同数据内容间的对比、不同数据集的对比、不同数据量的对比、不同的训练集与测试集的比例等之间的对比等,通过训练集和测试集的预测精确度进行方法和数据的选择。
3.5 数据优化
在数据选择和新数据引入中,发现文字处理和回归的过程无法对Int格式和float格式的内容进行处理,因此,在数据预处理的部分增加了遍历并删除的工作。使用iterrows 函数,对dataframe 进行遍历,搜索到格式为整数或浮点数的行进行删除[7]。
在尝试提高精确度的过程中,发现无论是对赛事感受较好的10 分选手还是感受较差的0~5 分选手,均存在未提意见的现象,造成同样的文字对应不同评分,对训练过程造成干扰。因此,在数据预处理部分增加了遍历空值并删除对应行的工作。
对于TfidfVectorizer 函数来讲,训练集与测试集的比例会影响TF-IDF 值的计算[8],因此,在后期计算中,将训练集与测试集大致为1∶1的比例调整为大约5∶2,但是结果显示精确度变化不大。
4 实验结果与问题
4.1 实验结果
通过以上实验过程,最终使用2018 年的6 场赛后问卷数据和2019 年的1 场赛后问卷数据作为训练集,共计4 897 条,经过筛选处理,将不符合要求的格式内容以及空值内容删除后,有效数据4 566 条;使用2019年的4场赛后问卷数据作为测试集,共计2 112条,经过筛选处理,将不符合要求的格式内容以及空值内容删除后,有效数据2 031条。
训练集的模型评估报告如图1 所示,10 分评论占全部数据的40.87%,7~9分评论占全部数据的55.32%,0~5 分的评论数量非常少,仅为全部数据的3.81%,由此可见,对于低分评论的训练内容非常有限。且在高分评论中,很多选手虽然整体感受满意度较高,但是仍为赛事提出了一些建设性的意见,导致模型整体的准确率较低。
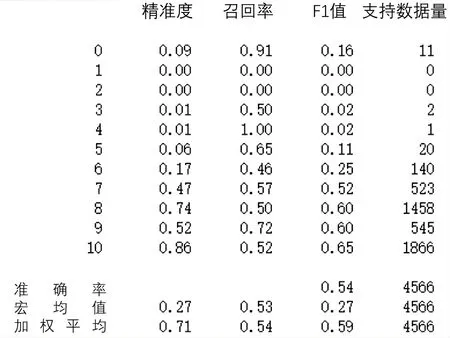
图1 训练集模型评估报告
在测试集中,10分评论占全部数据量的51.6%,7~9分的高分评论占全部数据的46.58%,0~5分的低分评论仅有3条,且其准确率较低,整体拉低了模型的准确程度。
4.2 遇到的问题
4.2.1 数据集的有效性问题
即使在实验过程中进行了多次优化,实验数据本身仍然存在许多无效信息未被排除,此次仅对浮点、整数格式以及“(空)”值和“无”值进行删除,但在浏览过程中发现,仍存在“没有”“暂无”等信息,需要进一步进行优化,人工进行排除,提高数据集本身的质量。
4.2.2 数据集的信息来源问题
由于此次选用的数据本身存在负面性,其文字所提即为意见内容,即使是10 分评价,可能也会出现部分负面词语,而通过与赛事运营人员的沟通,了解到问卷的回收机制本身即是自愿填写,而其福利为“折扣复购”,因此,大量抱怨的参赛者并不会填写这个相对内容较为冗杂的问卷内容,从而导致低分评价非常少,并不是不存在,只是未被收集。
4.2.3 评分量表分散的问题
已有研究中,大量的情感分析均只用0、1 的二级量表,仅对文字信息进行正面、负面的两性判断,部分进行了0、1、2 的三级量表,增加了“中立性”的内容[9-10]。而该实验采用的10 计量表,将用户的情绪进行了分散,且不同用户对自己的情绪感受评价非常主观,对于机器学习并不友好。
5 结语
总体来看,此次实验的结果虽然准确率不高,但是为未来的研究提供了一种可能,建议未来对于问卷数据的收集过程中,应尽量做到数据分层,有效对不同情绪感受的参赛者征集全面的情感信息,尤其要增加负面情绪的表达内容及相关信息;对于数据的有效性和量表的一致性问题,在数据库建立初期,可以考虑通过人工分拣的方式,对不同信息的内容进行二级或三级的分类,以增加机器学习和监测系统的准确性;或可以考虑使用已有的“中文正面/负面评价”词表对数据进行赋值,并人工修正。
后期可以通过自动爬取微信群、社交媒体和网络信息中对于相关赛事的评论,预判赛事在区域的影响力和城市参与度,并在一定程度上预测报名情况,对赛事运营前期的筹备和中期的组织具有较大作用。
猜你喜欢
羽毛球(2022年7期)2022-07-05
少林与太极(2020年1期)2020-07-14
少林与太极(2019年11期)2019-02-04
中国建筑装饰装修(2017年1期)2017-02-13
意林·少年版(2016年14期)2016-09-09
做人与处世(2016年12期)2016-07-21
创新作文·初中版(2015年1期)2015-03-11
上海体育学院学报(2015年2期)2015-02-28
创新作文·初中版(2014年5期)2014-07-18
