
建设项目随机离散型工期-成本优化算法的改进
2023-07-31 07:42:20王家唐敬奇周忠宝韩淙吉
湖南大学学报(自然科学版) 2023年7期
王家 ,唐敬奇 ,周忠宝 ,韩淙吉
(1.湖南大学 土木工程学院,湖南 长沙 410082;2.湖南大学 工商管理学院,湖南 长沙 410082)
作为建设项目计划与管理的重要内容,工期-成本优化问题旨在合理分配建设项目实施所需的各种资源,以达到项目工期和成本的最佳权衡.工程实践中,建设项目中各工序的资源分配往往呈现出离散化的特征,故其实施方式只能从有限个执行模式中选取.因此,工序执行模式作为决策变量的离散型工期-成本优化问题(Discrete Time-Cost Trade-off Problem,DTCTP),受到学者的广泛关注[1].离散型工期-成本优化问题的求解方法主要可分为精确算法和启发式算法[2].精确算法包括整数规划、动态规划等方法,适用于规模较小的问题[3-5].当问题的规模较大时,求解中主要采用启发式算法,包括和声搜索算法[6]、粒子群算法[7]、蚁群算法[8]、遗传算法[9-10]等.同时,伊长生等[11]基于模糊规划理论,构建了工程项目在多模式环境下的工期-成本优化模型,并提出了基于遗传算法、模糊模拟和神经网络的混合智能算法.He 等[12]将BIM 技术与遗传算法结合,构建了针对离散型工期-成本优化问题的五维BIM 决策平台.
同时,建设项目所处的环境,易受生产效率波动、施工现场条件改变等不确定性因素的影响.鉴于此,研究人员采用PERT网络来考虑不确定性因素对项目工期和项目成本的影响,开展了大量研究工作[13-14].其中,为克服传统PERT 方法的缺陷,Balles⁃teros 提出一种可纸上作业的项目工期估算技术M-PERT[15].针对大型建设项目的项目工期风险分析,Jun 等[16]基于多元正态积分法和图论的遍历方法,提出一种兼顾准确度和计算效率的新型算法.
但是,在建设项目的离散型工期-成本优化问题中,纳入项目工期和项目成本的不确定性度量,进行随机离散型工期-成本优化的研究仍然偏少.Ke等[17]建立了两种随机离散型工期-成本优化模型,并提出了遗传算法为外循环、蒙特卡罗模拟方法(Monte Carlo simulation,MCS)为内循环的双层循环算法框架.然而,该研究并未过多考虑算法的计算效率,随机离散型工期-成本优化算法的计算效率提升,仍有较大的研究空间.因此,本文针对双层循环算法中内循环的按期完工概率约束条件检验,根据按期完工概率蒙特卡罗估计值的概率特性,提出一种计算资源的高效、动态分配策略,以提升现有优化算法的计算效率.通过算例验证,本文建议的改进优化算法可高效、稳定地求解建设项目随机离散型工期-成本优化问题.
1 建设项目的随机离散型工期-成本优化模型
考虑包含Na项工序、Np条路径的某一建设项目.该项目中,任一工序i的执行模式总数假设为Ki(i=1,2,…,Na),工序i在第k个执行模式下的持续时间和成本分别表示为ti,k和ci,k.采用xi,k作为工序i执行模式的指示变量,如工序i选择第k个执行模式,则xi,k=1,否则xi,k=0.工序i的工期ti和成本ci可分别表示为:
考虑到任一工序i只能选择一个执行模式,指示变量xi,k需满足如下约束条件:
项目中任一路径工期Tj(j=1,2,…,Np)可由该路径上所有工序的工期求和得到,即:
式中:λji(j=1,2,…,Np;i=1,2,…,Na)为路径j上工序的指示变量(可由进度网络图得到),如工序i在路径j上,则λj,i=1,否则λj,i=0.项目的总工期T为所有路径工期的最大值,可表示为:
项目的总成本C为所有工序的成本之和,可表示为:
如采用X={xi,k,i=1,2,…,Na;k=1,2,…,Ki}包含所有工序的执行模式指示变量,由公式(5)和公式(6)可知,项目总工期和总成本为X的函数,可分别表示为T(X)和C(X).
考虑到生产效率波动、现场条件改变等不确定性因素的影响,给定执行模式下工序的持续时间ti,k和成本ci,k更适宜描述为服从一定概率分布的随机变 量.例如,ti,k和ci,k可采用三点估计值基础上的Beta分布来描述:
其中:ati,k、mti,k、bti,k分别为ti,k的最乐观、最可能、最悲观估计值;aci,k、mci,k、bci,k分别为ci,k的最乐观、最可能、最悲观估计值.表1 为某桥梁工程项目中大孔板梁安装工序在不同执行模式下的成本和工期估计值.

表1 大孔板梁安装工序在不同执行模式下的工期、成本估计值Tab.1 Estimates of the duration and the cost for the activity of installing plate beam(with large holes)at different execution modes
考虑不确定性因素影响下,项目的总工期T(X)和总成本C(X)为随机变量,此时项目的随机离散型工期-成本优化问题可描述为如下模型[16]:
同时,项目的实施模式X,应确保项目的按期完工概率Pr {T(X) ≤T0}(项目工期T(X)不超出目标工期T0的概率)较高,高于给定的限值1 -αt.
2 基于遗传算法的双层循环算法
针对公式(9)的随机离散型工期-成本优化问题,可采用现有的双层循环算法框架进行求解.双层循环算法的框架如图1 所示,外层循环采用遗传算法[18-20]搜寻、考察更优的解,内层循环需利用蒙特卡罗模拟方法估算考察解的按期完工概率,以检验按期完工概率约束条件,判断考察解的可行性.原双层循环算法中,针对不同考察解的按期完工概率估计,蒙特卡罗模拟方法均采用相同次数的项目进度网络分析(相同的样本数),导致优化问题求解所需的分析次数过多.如外层循环搜寻10 000个考察解,内层循环的蒙特卡罗模拟方法采用5 000 次分析来估计每一考察解的按期完工概率,则整个优化过程需进行5×107次项目进度网络分析.因此,当问题规模较大(涉及工序较多)时,原双层循环算法所需的计算资源过多,耗时过久.

图1 双层循环算法框架Fig.1 Framework for the double loop procedure
有鉴于此,研究在保持原双层循环算法框架基础上,对内层循环的蒙特卡罗模拟方法动态分配计算资源(例如样本数在200~5 000间动态调整),以提升双层循环算法的计算效率.本节讨论双层循环算法中外层循环的遗传算法实现,内层循环中蒙特卡罗模拟方法的计算资源动态分配在第3节介绍.
2.1 编码与解码
随机离散型工期-成本优化问题适合采用实数编码的方式.具体而言,可将染色体表示为序列θ=(θ(1),θ(2),…,θ(Na)),θ(i) (i=1,2,…,Na)为[1,Ki]内的自然数,代表工序i的执行模式.例如,考虑包含7 项工序的某工程项目,各工序执行模式的总数分别是2,5,6,4,3,6,5,则编码后的染色体可能为θ=(2,4,3,2,1,5,3),表示第1~第7 项工序的执行模式依次为第2,第4,第3,第2,第1,第5 和第3.采用上述编码方式的染色体,其对应的原问题的解X={xi,k,i=1,2,…,Na;k=1,2,…,Ki},可直接根据xi,k的含义得到,解码过程非常简便.考虑前例中的染色体θ=(2,4,3,2,1,5,3),其解码得到的X见表2所示.
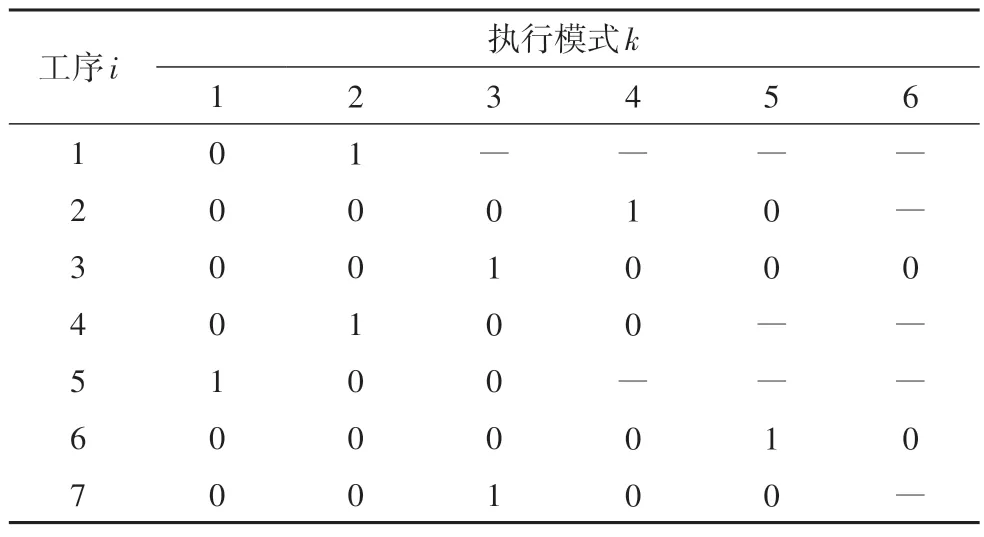
表2 典型染色体解码对应的原问题解XTab.2 The solution of X corresponding to a typical chromosome
2.2 适应度函数
针对染色体个体θ,其对应的项目成本C(θ),可通过将解码值X(θ)代入公式(6)得到:
项目成本C(θ)为随机变量,其概率分布由式(11)和ci,k的概率分布共同确定.θ对应的目标函数值,满足条件≥1 -αc,可通过蒙特卡罗模拟方法估算.同时,估算时仅涉及ci,k随机抽样样本的简单求和,MCS 方法中大量重复模拟所需的计算资源较为有限.遗传算法中,一般根据染色体个体的适应度函数值决定其遗传到下一代的概率.本算法中,适应度函数F(θ)定义为的倒数,即:
2.3 种群迭代过程
遗传算法为迭代算法,通过初始染色体种群的生成和相邻种群的迭代,来实现染色体种群的进化和全局最优解的搜寻.本节讨论第i代染色体种群到第i+1 代染色体种群Ai+1=的迭代过程,包含选择、交叉、变异、约束条件检验的操作,而初始染色体种群的产生方法参见第4节.
1)选择:针对第i代染色体种群Ai=,可根据公式(12)计算种群中各染色体对应的适应度函数值,j=1,2,…,M.本文采用轮盘赌准则进行选择,以各染色体的相对适应度函数值(归一化后的数值)作为选中概率,从种群Ai中随机选择出两个染色体,以进行后续的操作.除轮盘赌准则外,典型的选择算子还包括锦标赛选择策略、随机遍历抽样法等[21].不同选择算子间的优劣,学界尚未达成共识.因此,本文采用遗传算法中广泛采用、使用简便的轮盘赌准则,并在后续研究中考察不同选择算子对算法的整体影响.
2)交叉:本文的交叉操作采用单点交叉算子,并根据交叉概率pc进行.针对选择操作得到的两个染色体,如需进行交叉,则随机选择交叉点位置,并互换交叉点后的基因,以形成新的两个染色体个体.
3)变异:针对交叉操作后的两个染色体,根据变异概率pm进行变异操作.具体而言,两个染色体上的所有基因值根据概率pm,变异为其他数值(该基因值对应的工序的其他执行模式).
4)约束条件检验:每一代种群中的染色体个体,其解码值需满足公式(9)中的约束条件.由2.1 节和2.2 节的讨论可知,公式(9)中的约束条件中,仅需检验按期完工概率约束条件,其他两类约束条件可自动满足.因此,针对变异操作后的两个染色体,可采用MCS 方法(详见第3 节),检验按期完工概率约束条件.如满足按期完工概率约束条件,则放入下一代种群Ai+1中,否则应舍弃.
3 内层循环中计算资源的动态分配策略
针对染色体个体θ=(θ(1),θ(2),…,θ(Na)),需根据其解码值X={xi,k,i=1,2,…,Na;k=1,2,…,Ki},检验按期完工概率约束条件.根据公式(5),θ对应的项目工期为:
根据公式(9)中优化模型的要求,项目工期T(θ)需满足约束条件Pr{T(θ) ≤T0}≥1 -αt.为方便论述,后续采用PR(θ)表示染色体下的按期完工概率,即PR(θ)=Pr {T(θ) ≤T0}.
随机离散型工期-成本优化算法的双层循环流程中,内循环采用MCS 方法估计染色体θ下的按期完工概率PR(θ),并检验约束条件PR(θ) ≥1 -αt.MCS 方法根据ti,k的概率分布进行随机抽样,并利用关键路径法执行项目的进度网络分析,以得到染色体θ下的项目工期样本.重复上述步骤N次,可得到染色体θ下项目工期的N个随机样本进而得到如下的按期完工概率的估计值[22]:
式 中:NR为随机样本{T(1)[X(θ)],T(2)[X(θ)],…,T(N)[X(θ)]}中数值不大于T0的个数.采用上述流程得到的估计值具有随机性,其准确度可用变异系数(样本标准差和样本均值的比值)进行衡量,通过公式(15)估算[22].
为确保估算的准确度,此时的样本数量N不能过小.由公式(15)可知,随着样本数量N(与计算资源的消耗相关)的增加,估计值的准确度得到提高(对应的变异系数R减小).
考虑到PR(θ) ∈[0,1],上述极大可能区间的上下界计算中引入了0 和1.该极大可能区间类似于不同概率分布下以期望值为中心、以4 倍标准差为宽度的区间.在不同的概率分布下,该区间对应的概率均接近1.例如,正态分布下该区间对应的概率为95.46%,均匀分布下该区间对应的概率为100%,指数分布下该区间对应的概率为95.02%.因此,公式(16)定义的区间有较大概率包含PR(θ),可作为PR(θ)的极大可能区间.随着采用样本数N的增加,估计的准确度提升(变小),包含PR(θ)的极大可能区间逐渐缩窄,如图2所示.

图2 极大可能区间随样本数量的变化Fig.2 The most probable range at different number of samples
内层循环采用MCS 方法的目的,是检验约束条件PR(θ) ≥1 -αt是否成立,而非准确估计PR(θ).因此,包含PR(θ)的极大可能区间并非都需要估计至非常狭窄,其与边界值1 -αt能够区分即可.当PR(θ)距离边界值1 -αt较远时,准确度较低的估计足以提供可靠的检验判断.如图3 所示,虽然此时采用的样本数较少,对应估计值的准确度较低,包含PR(θ)的极大可能区间较宽,但是,此时的极大可能区间的上限小于1 -αt,足以可靠地说明约束条件PR(θ) ≥1 -αt此时不成立,因此并不需要额外增加计算资源(样本数量).当PR(θ)距离约束条件边界值1 -αt较近时,较小样本数量得到的极大可能区间包含了边界值1 -αt,无法提供约束条件PR(θ) ≥1 -αt的可靠判断,此时需额外增加计算资源(样本数量),直到缩窄的极大可能区间不包含1 -αt为止,如图4所示.
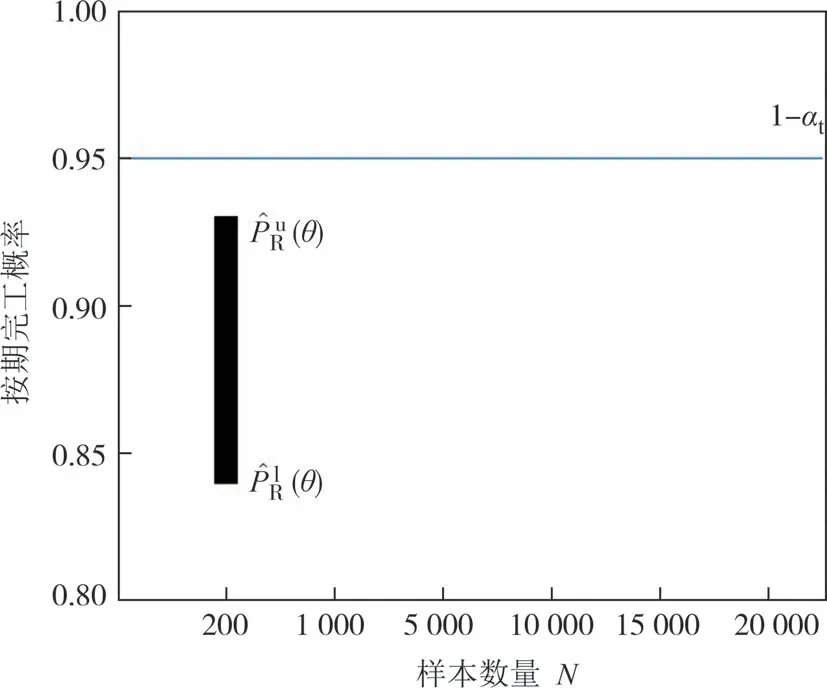
图3 仅需较少计算资源的约束条件检验情形Fig.3 Constraint examination in which few computational resources are required
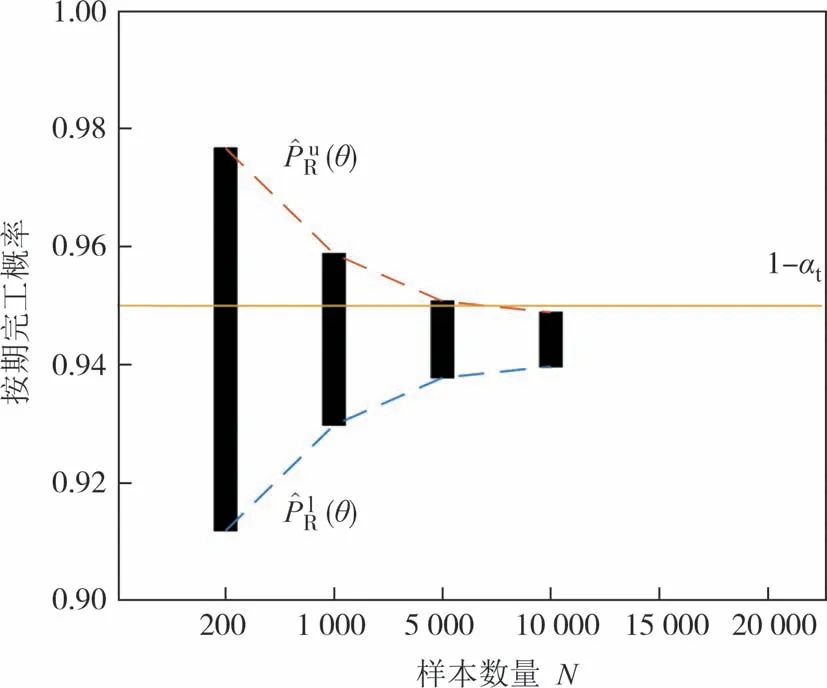
图4 需较多计算资源的约束条件检验情形Fig.4 Constraint examination in which more computationalresources are required
因此,为提供约束条件PR(θ) ≥1 -αt的可靠检验,MCS 方法中的样本数N,应使包含PR(θ)的极大可能区间与边界值1 -αt区分开来,即但是,当PR(θ)极其靠近1 -αt时,如仍采用上述原则,则会使MCS 方法中分配的样本数量过于庞大.所以,应对样本数量N的上限进行限制,即N应低于设定的限值Ntol.综上所述,为提供约束条件PR(θ) ≥1 -αt的可靠判断,本文采用极大可能区间指标和样本数量上限相结合的原则,动态分配MCS方法中的样本数Nreq:
4 初始染色体种群的改进生成方法
现有的随机离散型工期-成本优化算法中,遗传算法的初始染色体种群,采用随机产生并检验约束条件PR(θ) ≥1 -αt的方法.但是,若满足约束条件的染色体占比较小,则上述方法的效率过低.如满足约束条件的染色体占比为5%,为得到满足约束条件的100 个染色体,平均需要随机产生2 000个染色体,并进行按期完工概率约束条件的检验,将耗费大量不必要的计算资源.
基于上述考量,研究采用“带有反射壁的随机游动”的马尔可夫链蒙特卡罗(Markov Chain Monte Carlo,MCMC)方法[23],来产生初始染色体种群.具体而言,为得到马尔可夫链{θ1,θ2,…}的起点θ1=(θ1(1),θ1(2),…,θ1(Na)),令其基因值θ1(i),i=1,2,…,Na为工序i的最赶工执行模式序号.例如,第6 节算例中各工序的最赶工执行模式序号均为1(见表3),此时起点θ1=(θ1(1),θ1(2),…,θ1(Na))的基因值均选为1,即θ1(i)=1,i=1,2,…,Na.该θ1在所有染色体中,最有可能满足约束条件PR(θ) ≥1 -αt,如其亦不满足,则说明该优化问题无可行解.马尔可夫链{θ1,θ2,…}中θk=(θk(1),θk(2),…,θk(Na))到θk+1=(θk+1(1),θk+1(2),…,θk+1(Na))的迭代操作如下:
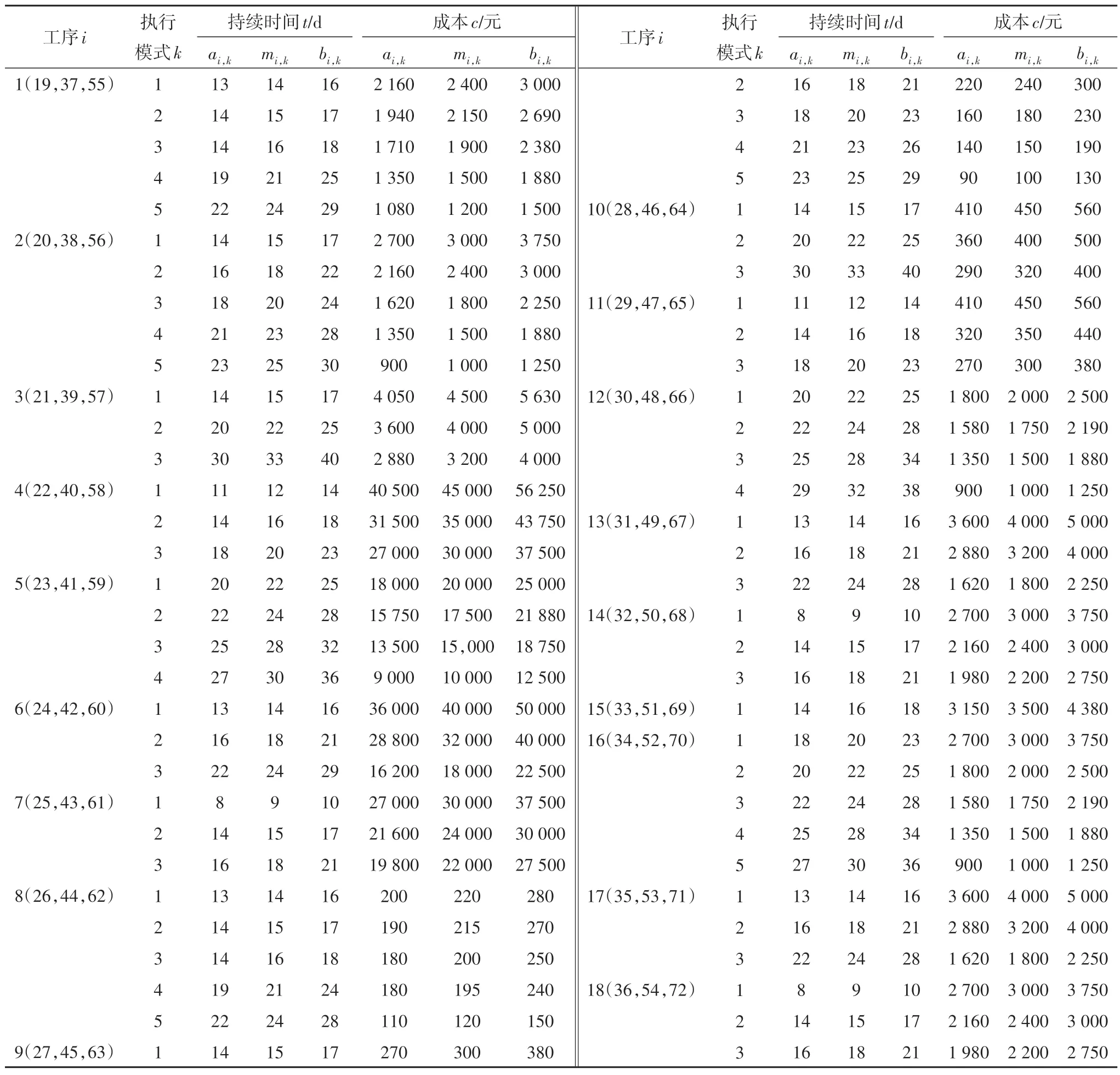
表3 不同执行模式下的工序数据Tab.3 Data of the activities at different execution modes
1)从染色体θk=(θk(1),θk(2),…,θk(Na))中随机选择一个可变基因θk(r)(对应工序的执行模式总数大于1,即Kr>1).
3)采用第3 节的动态检验方法,检验备选状态点是否满足约束条件PR(θ) ≥1 -αt.如满足约束条件,则将备选状态点作为下一状态点,即θk+1=否则重复上一状态点,即θk+1=θk.
5 建议的改进优化算法总结
针对建设项目的随机离散型工期-成本优化问题,本文建议对现有的双层循环算法(遗传算法为外循环、蒙特卡罗模拟方法为内循环)进行改进.改进优化算法的具体步骤总结如下:
1)确定算法中各参数的取值,包括遗传算法中的迭代代数NG、种群规模M、交叉概率pc、变异概率pm,检验约束条件时动态分配MCS 样本数所需的参数值Nl和Ntol.
2)利用第4 节的MCMC 方法,产生满足按期完工概率约束条件的初始染色体种群A0=,并令迭代指示变量i=0.
3)计算第i代种群Ai中各染色体的适应度函数值根据精英保留策略,选择Ai中适应度函数值最高的染色体,直接放入下一代种群Ai+1中.
4)执行选择、交叉、变异及约束条件检验操作,直至得到下一代种群的M个染色体Ai+1=令迭代指示变量i=i+1.多次重复步骤3)~4),直至迭代次数i达到NG.选择最后一代种群中的最优解,作为随机离散型工期-成本优化问题的最优解.
6 算例分析
研究通过算例来检验建议优化算法的性能,采用的计算机硬件配置为处理器Intel(R)Core(TM)i7-8700、内存16 G,软件配置为MATLAB R2020b.基于文献[8]的案例,本文将其中的项目网络图重复4 次,以增加算例复杂程度,构建了图5 所示的算例项目网络图(虚线内为原案例的项目网络图).算例项目中包含72 项工序,不同执行模式下各工序持续时间和成本的三点估计值如表3 所示.算例项目的随机离散型工期-成本优化问题中,目标工期T0为550 d,工期和成本约束条件中的限值1 -αt和1 -αc均为95%.
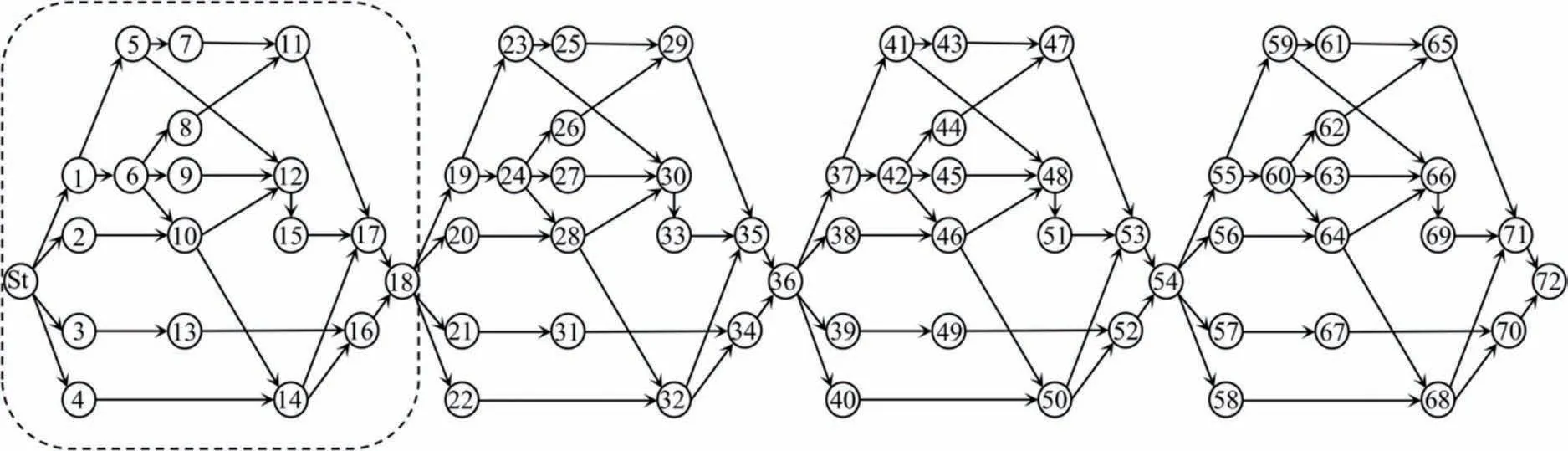
图5 算例项目的单代号网络图Fig.5 The activity-on-node network of the example project
针对算例项目的优化问题,建议算法采用如下的参数:遗传算法中种群规模M为100,交叉概率pc为0.4,变异概率pm为0.01,终止迭代代数NG为140.同时,为确定MCS 方法中动态分配策略的参数值Nl和Ntol,研究利用公式(15)和(16)计算了给定样本数量下MCS 方法的失效范围.图6 绘制了样本数N=200 时不同按期完工概率MCS 估计值的极大可能区间.由图6可知,当按期完工概率估计值时,其极大可能区间的上限,此时按期完工概率约束条件不成立的判断较为可靠.当按期完工概率估计值时,其极大可能区间的下限,此时按期完工概率约束条件成立的判断较为可靠.当,其极大可能区间包含边界值0.95,因此不能提供约束条件的可靠判断,此时MCS 方法检验失效.类似地,当样本数N=5 000 时,计算出的MCS 方法失效范围缩窄至[0.943,0.956],满足较好的精度要求.因此,动态分布策略中的参数值取Nl=200 和Ntol=5 000.对应更高的计算精度时,可提高Ntol的数值,以便其所对应的MCS方法失效范围缩窄至可接受的目标范围.

图6 样本数N=200时按期完工概率MCS估计值的极大可能区间Fig.6 The most probable range for the MCS estimator with N=200
研究考察了采用上述参数的建议优化算法的求解过程.图7 描述了一次典型求解中最优目标函数值随迭代阶段的变化.由图7 可见,算法经过140 代后已收敛到最优解,对应最优目标函数值434.175千元.针对求解中所考察的14 026个解,研究统计了约束条件检验所动态分配的MCS 样本数,并由表4 给出了不同样本数区间对应的考察解的比例.由表4可知,14 026个考察解中,98.97%的解分配了较少的MCS 样本数Nreq=200.该结果说明大部分考察解的按期完工概率距离边界值0.95 较远,因此较少的分配样本数就足以提供按期完工概率约束条件的可靠判断.同时,其他的1.03%的解所分配的样本数,散布于Nl=200 和Ntol=5 000 之间,验证了按期完工概率约束条件的动态检验方法的有效性.
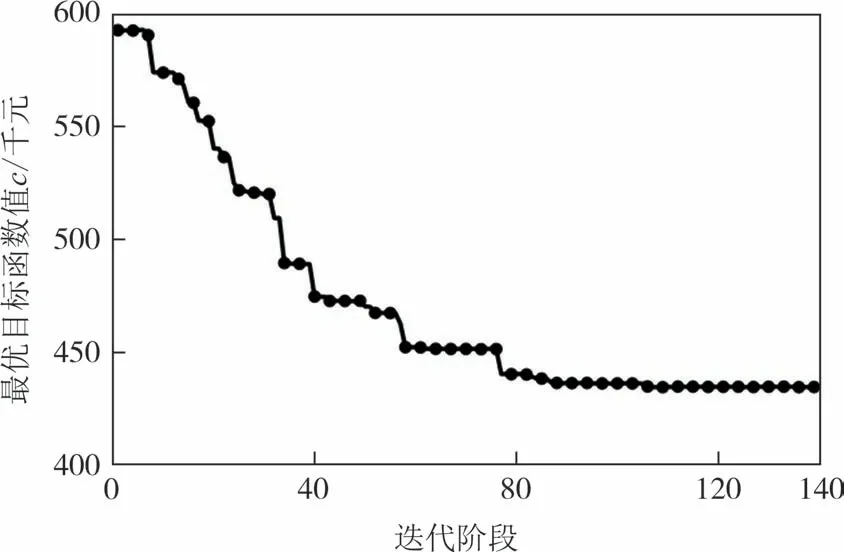
图7 建议优化算法典型求解中最优目标函数值随迭代阶段的变化Fig.7 Optimal objective function value at different stages in a typical run of using the proposed method
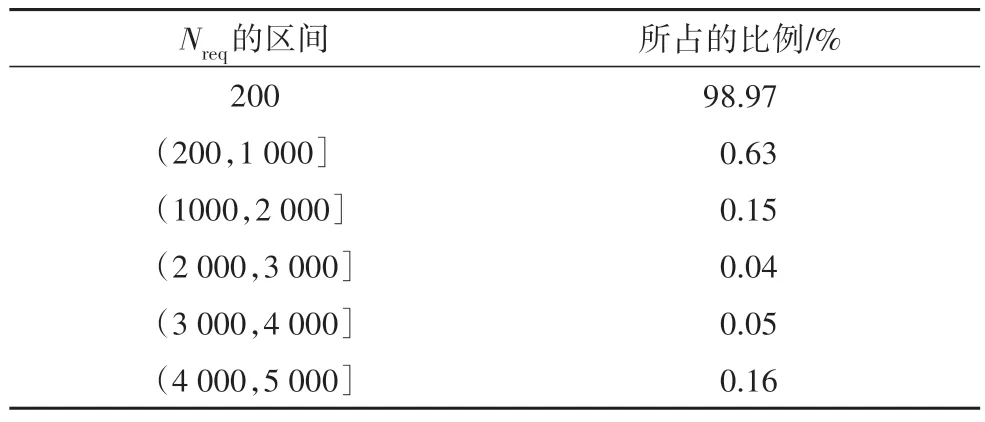
表4 不同Nreq区间对应的考察解的比例Tab.4 The ratio of examined solutions at different ranges of Nreq
为检验动态分配策略对优化算法准确度和稳定性的影响,研究将建议优化算法与现有优化算法(与建议优化算法类似,但未采用动态分配策略,约束条件检验采用固定样本数5 000下的MCS方法)的求解进行比较.同时,为排除初始样本种群的影响,两种算法采用相同的初始样本种群.研究将两种算法的对比独立进行了30 次,算法运行所得最优解的目标函数值和按期完工概率如图8 所示,最优目标函数值的统计结果如表5 所示.由图8 和表5 可知,建议优化算法和现有优化算法的求解结果基本类似,30 次运行结果中,最优目标函数值的最大值、最小值、平均值、标准差都很接近.因此,采用动态分配策略,可保持与现有优化算法类似的求解准确度和稳定性.同时,建议优化算法的单次运行耗时约为0.54 h,而现有优化算法单次运行耗时约为7.12 小时.与现有优化算法相比,采用动态分配策略的建议优化算法的计算效率提升了约13倍.

图8 两种算法独立运行30次所得最优解的目标函数值和按期完工概率Fig.8 The objective function value and the completion reliabil⁃ity for the optimal solutions obtained by the 30 independent runs of using two different methods
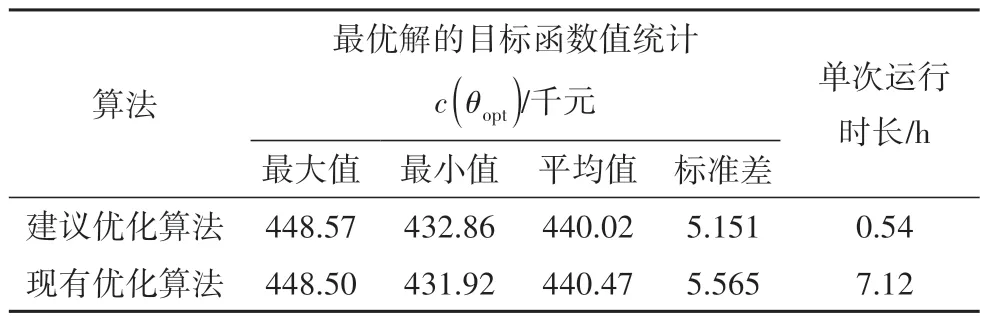
表5 两种算法独立运行30次的统计结果Tab.5 Statistical results of 30 independent runs using two different methods
7 结论
本文针对建设项目的随机离散型工期-成本优化问题,研究遗传算法为外循环、蒙特卡罗模拟方法为内循环的优化算法的改进,主要研究结论如下:
1)内层循环中采用蒙特卡罗模拟方法检验按期完工概率约束条件时,可利用按期完工概率估计值的极大可能区间,进行计算资源的动态、高效分配.
2)针对外层循环中遗传算法所需的初始染色体种群,可采用“带有反射壁的随机游动”的马尔可夫链蒙特卡罗方法,以提高染色体种群的产生效率.
3)通过算例验证,与现有优化算法相比,建议优化算法的求解准确度和稳定性类似,而计算效率有较大的提升(约13倍).
猜你喜欢
电机与控制应用(2022年4期)2022-06-27 06:29:28
湖南林业科技(2021年3期)2021-12-02 21:15:32
Frontiers of Nursing(2018年1期)2018-05-21 02:34:14
高中生·天天向上(2016年6期)2016-11-22 09:39:34
水利规划与设计(2016年7期)2016-02-28 15:06:32
小说月刊(2015年5期)2015-04-19 07:29:20
计算机工程与应用(2015年19期)2015-04-16 08:51:36
棉花科学(2014年4期)2014-04-29 00:44:03
城市道桥与防洪(2014年9期)2014-02-27 07:29:37
中国农业信息(2013年10期)2013-09-05 03:04:12
