
基于«中国日报»(2019~2021)的安徽形象语料库建设
2023-07-31 07:46秦琬蒋碧晗
现代英语 2023年8期
关键词:安徽
秦琬 蒋碧晗
(淮北理工学院,安徽 淮北 235000)
一、 引言
(一)研究背景
改革开放以来,中国各省迅速发展,区域形象的塑造与推广成为软实力的主要表现,如何调动各方力量塑造区域形象成为发展的题中要义。 软实力愈来愈多地被用于吸引投资和人才,优良的区域形象在经济发展和区域对外交流中日益关键。
安徽具备南北特性,由于其特殊的区域位置,安徽在全国发展中起到承前启后、承东启西的功效。 此外,随着社会经济的迅速发展,智能化和城市化的快速推进,以及中部崛起等有关规划的适用,安徽经济慢慢踏入快车道。 但是,因为资源等因素的限定,安徽社会经济发展面临一些问题,与东部地区尤其是附近省份的差别持续拉大。 要引进外资,得到发展机会,区域形象建设至关重要。掌握安徽形象的现况,找到安徽形象存在的不足,明确其形象定位,对安徽的发展具有重要的意义。本研究即以此为背景,探讨基于«中国日报»的安徽形象语料库建设,通过对新媒体信息的整理,实现对信息资源的历时呈现,不仅可以用于话语分析,更是对语言学和传播学信息资源的重要补充。
(二)研究方法
本研究将采用文献法、语料库方法和人工辅助法。
其一,文献研究法:通过阅读大量有关参考文献,全方位准确地掌握海外语料库的发展趋势和中国语料库的成效,参照诸多学者的研究成果,包含基本思路、研究思路和研究成果,将适合语料库基本建设的一部分消化吸收,运用到本文章的创作中。
其二,语料库方法:收集2019~2021 年度«中国日报»有关安徽的新闻文本,通过Python 根据关键词“安徽”搜集网站上相关语料,然后进行语料清洗,从而构建单语语料库。
其三,人工辅助方法:在语料清洗过程中,需要清洗相应图片、多余的标点符号等,从而确保语料库的质量。
二、 文献综述
与本选题有关的研究主要包括安徽形象研究、语料库语言学研究及基于语料库的安徽形象研究,下文分别对这三方面展开概述。
(一)安徽形象研究
形象就是指“对某事情的意志、观念和印象”。并不是事物自身,只是对物体的感知或观点。 这是一种主观性印象,由传播学、交往经历、成长经历、自然环境等要素建立[1]。 因而,安徽品牌形象可被理解为中国群众对安徽的印象,是对安徽本质整体实力、外在魅力和未来发展前景的实际感知、整体观点和综合考核[2]。
随着安徽经济逐步发展,越来越多的学者对安徽形象进行了研究。 钱智和徐俊结合思维科学、行为科学、区域规划等学科的相关理论,以安徽形象设计为例,提出了区域形象设计概念、基本思想以及操作框架[3];杨杰、吴克明运用“安徽形象评价量表”进行调查,针对安徽形象就人口素养、自然环境及政府治理提出改进措施[4];李彦迪、刘叶青、邹菲菲等就安徽省外宣文本,在语域理论视角下对安徽形象进行建构[5]。
(二)语料库语言学研究
自20 世纪60 年代初以来,语料库至今已经历60 多年的发展,研究语料库的学者也越来越多。 语料库的出现,也对语言研究产生了巨大的影响,拓宽了研究的角度与视野,完成了从定性到定性与定量相结合的转变。 随着计算机技术的发展,1993年,Mona Baker 提出,可以根据语料库对大量翻译文本进行描写和分析,从而证实了翻译可作为沟通媒介这一现象[6]。 Sara Laviosa 介绍了不同类型的语料库在翻译教学中的应用[7]。
相较而言,国内语料库语言学起步较晚,从成果来看,语料库被广泛应用于教学、翻译、词汇、语义、词典和语法等语言研究领域。 如王克非就双语语料库设计构建提出一系列想法[8],张威提出口译语料库的开发与建设[9],胡开宝也就语料库基础特性、研究领域进行了系统梳理[10]。 但语料库就话语分析方面的研究仍处于初期阶段,还需要进一步补充与探究。
(三)基于语料库的安徽形象研究
笔者通过中国知网(CNKI)检索“安徽形象+语料库”,发现与之相关的研究成果数量不多。 左言娜以安徽省人民政府网站和安徽省旅游局网站文本为语料库,搭建语料库,以系统功能应用语言学为理论框架,选用批评性话语分析方式,探讨互联网媒体语句里的安徽旅游国际地位[11]。 同年,左言娜还依据此语料库对新媒体话语中的安徽外宣形象进行探究。 钟紫薇利用语料库检索软件等自建小型语料库,通过收集、整理和分类2016 年China Daily 网站中关于安徽的英语新闻报道,运用语料库语言学理论对不同类别的新闻报道展开话语分析[12]。 以上研究已将语料库引入安徽形象研究中,为提升安徽区域形象做出了较大贡献。
三、 语料库建设
(一)安徽形象语料库建设简介
语料库主要有四种形式:单语种语料库、平行语料库、多语种语料库和可比语料库。 其中单语种语料库仅包含一种语言的文本;平行语料库包含两个单语种语料库,一个语料库是另一个语料库的翻译;多语种语料库包含多种语言的文本,且都是相同文本的翻译,存在与平行语料库相同的方式对齐;可比语料库是一组两个或两个以上的单语语料库,其文本涉及同一主题,但它们不是彼此的翻译,因此没有对齐。 就文章研究需要而言,要建设的语料库为单语种语料库。 此部分主要探索语料库设计、语料收集等。
(二)语料库设计
王克非认为语料库的总体设计是与建库目的密切相关的,需要考虑如下十点:设计目的、语言规模、语料范围、代表性与均衡性、双语比例、共时/历时性、语言类型、语言质量、取样策略和标注加工[8]。 据此标准,建设语料库的参数和特点如表1所示。
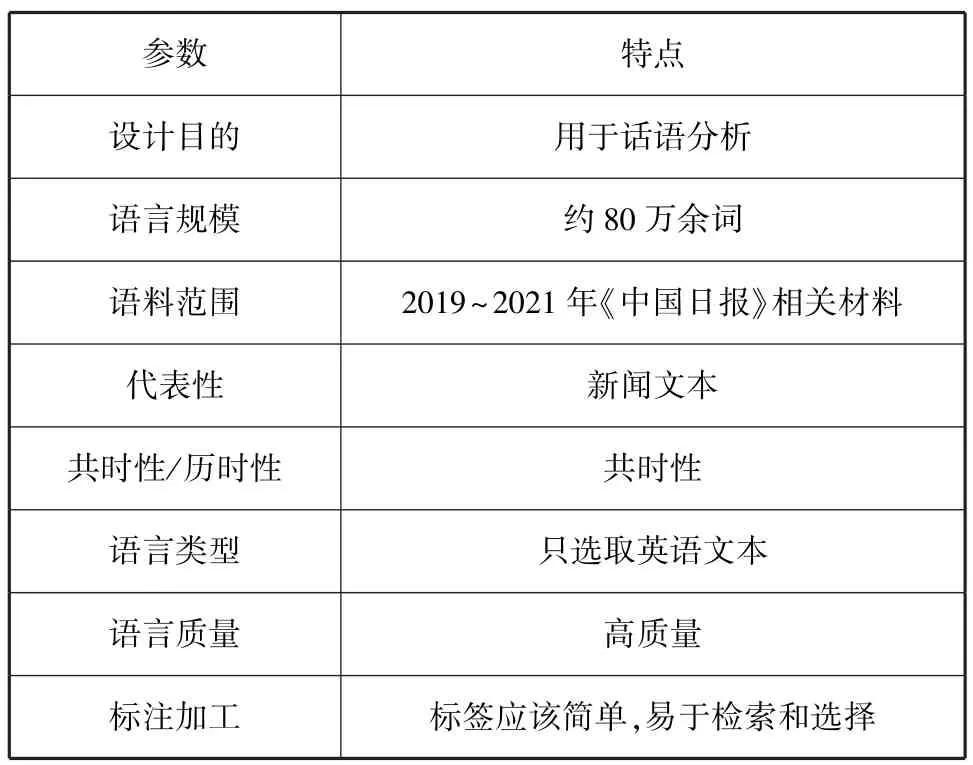
表1 语料库设计参数表
(三)语料采集与清洗
由于文本信息量较大,本次研究使用Python 软件,基于词义相关度进行语料收集,首先打开Python,设定关键词为“安徽”,后设置程序运行。爬取基本操作步骤包括:①寻找文本数据量大的网站URL,形成爬虫的初始URL 队列;②访问网页链接,获得网页数据;③通过下载器对网页数据进行下载;④根据页面的HTML 格式进行解析,编写Xpath 表达式筛选出需要保留的文本信息;⑤再对文本信息分词,存为词汇素材列表,并完成后续的URL 跳转动作使得爬虫持续运行。 得到语料如图1所示。
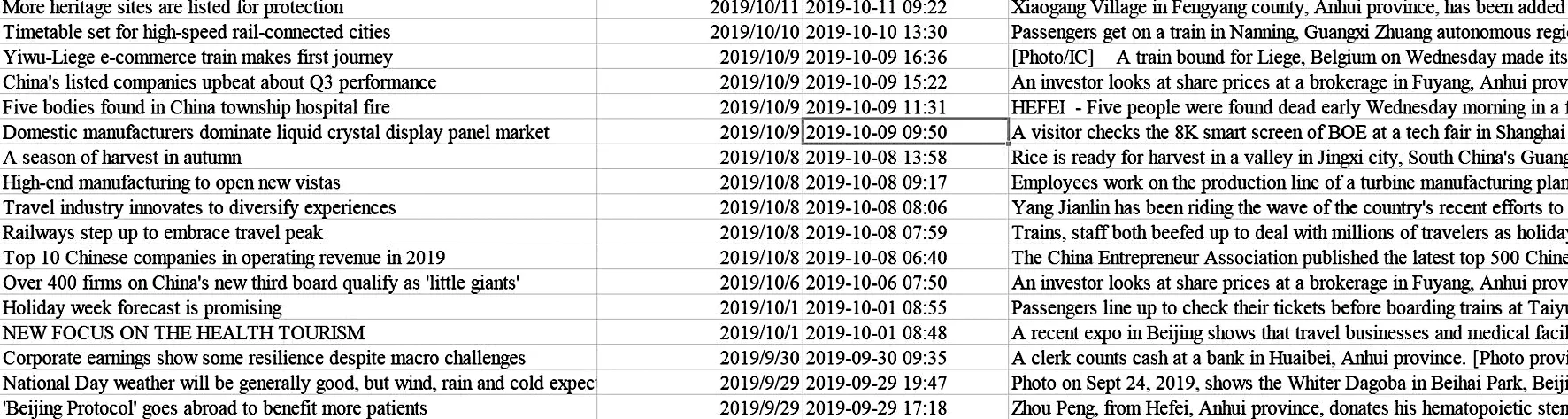
图1 语料爬取数据
研究共收集语料2475 篇,合计80 余万字。 胡开宝提到:语料采集是指将书面语料和口语语料输入电脑,并以电子文本形式储存[10]。 在广泛收集的大量语料素材数据中,部分数据的格式并不符合预期要求,其中存在大量的无效信息,例如夹带着多种的符号、标记,文字间残留大量空格等。 这与预期格式存在差异,为了让计算机可以识别并方便后续的处理,必然要对收集的数据信息进行预处理。所以语料库构建的首个步骤就是对语料素材信息进行规范化处理。 先使用正则表达式对大部分符号进行删除操作,少部分情况特殊处理。 经过对符号的处理可以使绝大部分的文本数据符合格式要求。 再对文本内容的格式进行处理,针对一些特殊格式数据例如小说、诗歌,其中存在非文本数据和无意义文本。 非文本数据指不是文本中主要内容,主要起定义格式、装饰文本作用,例如HTML 标签、URL 地址、乱码等;无意义文本指文本数据中常出现但无实际意义的内容,例如作者附加的内容、广告内容、版权信息和个性签名的部分内容等。
(四)语料库建成
在进行筛选后,导出四个版本文件,为tmx 格式、Word 格式、Excel 格式以及txt 格式。 这四种格式满足不同的需求:tmx 格式作为翻译记忆库,主要适用于计算机辅助翻译软件;Word 格式用于日常查阅,确定表达;Excel 格式便于检索;txt 格式适用于文本转换。 自建小型语料库(图2)包含2475 篇新闻,其中经济类578 篇、政治类634 篇、市民生活类704 篇以及社会文化类559 篇,共计1026876 字符,按照经济、政治、文化等方面进行分类。 后续使用语料检索软件AntConc4.1.2w,通过词频统计、高频词索引行等路径,并结合批评话语分析、评价理论和议程设置理论,对检索结果进行定性、定量分析,通过有理、有力、有节地传递自身声音,构建安徽形象话语体系,让更多人了解安徽、熟悉安徽、亲近安徽。

图2 单语语料库
四、 结语
笔者基于收集到的网站信息,设计语料库(设计目的,语料库规模,语料库范围,语言类型和语言质量)、处理文本(分类、清洗、标注语料),建立小型语料库,旨在帮助分析安徽形象现状,并提出改进安徽形象的策略和建议。 因此,通过个人建立小型单语语料库,可以在一定程度上了解和使用语料库这一新的研究方法,方便研究者在科研领域克服技术难关。
猜你喜欢
中华诗词(2022年3期)2022-12-31
湖州师范学院学报(2022年9期)2022-11-09
加油站服务指南(2022年6期)2022-07-28
今日农业(2020年18期)2020-12-14
黄河·黄土·黄种人(华夏文明)(2019年12期)2020-01-09
中国公路(2017年12期)2017-02-06
中国卫生(2016年6期)2016-11-23
中国卫生(2016年8期)2016-11-12
中国卫生(2016年8期)2016-11-12
中国卫生(2016年5期)2016-11-12
