
唐蕃古道典型文物知识图谱可视化研究*
2023-07-30 08:40:12杨嘉炫雒伟群张兆基
西藏科技 2023年6期
杨嘉炫 雒伟群 张兆基
西藏民族大学信息工程学院,陕西 咸阳 712082
唐蕃古道,这是一条唐代以来跨越陕西、甘肃、青海、四川和西藏五省的道路,被称之为我国古代三大通道之一,吐蕃来唐使者已知的往来次数就多达19次,由此可见,唐蕃古道沿线典型文物知识图谱可视化研究对挖掘研究唐朝与吐蕃王朝之间政治、经济、文化等各方面的关系都有深远的意义。本文对唐蕃古道沿路典型文物的可视化研究,为之后的深入研究文物蕴含的历史意义以及考古价值甚至推动社会长治久安都有着十分重要的意义。
知识图谱[1]概念最早于2012 年由Google 公司提出,为了优化其搜索引擎,之后被应用到多个不同的领域中,知识图谱是一个语义网络,包含很多语义信息,其基础组成单元是三元组,即由“实体—关系—实体”以及实体与自身相关的属性值对,由关系关联不同的实体,构成网状的知识结构[2],知识图谱中的实体表示与图中的节点类似,节点之间的关系用边来表示[3],知识图谱将知识的抽象化转换为了图形表示,这为我们提供了总结变化规律等的重要价值。知识图谱的构建是唐蕃古道文物知识库发展建立的基础,由于数据源和流程之间的差异,知识图谱的构建方法分为自顶向上和自顶向下[4],其中自顶向上的构建方法是从开放链接的数据源中提取实体、属性和关系,加入到知识图谱的数据层,然后将这些知识要素进行归纳组织,逐步向上抽象为概念,最后形成模式层。而自顶向下构建则是从模式层开始构建,建立本体概念,再依据模式层进行数据层的实现。针对多方面的本文使用自顶向下的构建方法,在百度百科数据链爬取和其他数据源提取非结构化、半结构化的唐蕃古道典型文物,以此为基础抽取实体、属性及关系信息,再将数据处理为三元组,存储在唐蕃古道典型文物知识图谱中,再利用Neo4j 进行可视化展示,完成唐蕃古道典型文物知识图谱可视化研究。
1 唐蕃古道知识图谱构建过程
唐蕃古道知识图谱构建过程主要分为两大部分,一是典型文物的模式层构建,由此可以构建形成文物的实体和关系,二是典型文物的数据层构建,依照模式层的实体和关系进行关键数据提取,最后形成知识图谱三元组,为后面的可视化提供数据。
1.1 唐蕃古道典型文物模式层构建
模式层(Schema)指知识图谱的概念及概念之间的关系[5]。本体指采用形式化方式,描述某个领域内的概念及其关系。本体的知识表示就是要把两个概念实体之间的关联找到,本文利用本体[6]的描述思想,构建唐蕃古道典型文物知识图谱的模式层,构建内容包括唐蕃古道相关的实体、实体属性以及文物与属性之间的关系,即(概念实体、关系、概念实体)三元组。
对于唐蕃古道中的典型文物定义不同的实体与关系,依据文物的信息定义了八个实体类和五个关系类,实体类分别是文物名称、文物类别、文物材质、文物朝代、文物尺寸、收藏位置、所属路线段、文物价值。例如西藏段的文物名称有:唐蕃会盟碑、铜镀金聚莲塔、八宝纹珐琅净水瓶、布画祖孙三代法王像、合金宝生如来像、银质錾八宝纹坛城;文物类别有唐卡、碑、杯、坛城、瓶、塔、锦、盘、壶等;文物材质有石头、合金、布、银、铜、金、玻璃、丝绸等;文物朝代有明朝、唐代、清朝等;文物尺寸有长度、宽度、高度等;收藏位置有西藏博物馆、海西州民族博物馆、甘肃省博物馆、青海省博物馆、四川博物馆等;所属路段分别为陕西段、甘肃段、青海段、四川段和西藏段;五个路线段和大部分文物还有其文物价值的描述,比如唐蕃会盟碑,属于唐蕃古道的终结路段西藏段的文物,它是汉藏两大民族团结友好的历史见证,具有重大的历史意义。五个关系类分别是分类关系、属性关系、时间关系、空间关系、关联关系。例如分类关系表示文物所属的类别;属性关系表示文物的属性,如文物的材质和尺寸等;时间关系表示文物的产生时间,如唐代、明朝等;空间关系表示文物的空间特征,如文物的收藏位置;关联关系表示文物关联的路线段,即五大路线段。
1.2 唐蕃古道典型文物数据层构建
唐蕃古道典型文物的数据层构建属于知识抽取部分,通过半结构化和非结构化的数据抽取文物的相关信息,再将这些信息与模式层所构造的概念与关系一一对应起来。
1.2.1 知识获取。数据获取常用的途径有由知识工程师从专家获取、由智能编辑程序从专家获取、由归纳总结程序从大量数据中归纳出所需知识、由文本理解程序从教科书或科技资料中提取出所需知识。在数据源[7]方面,本文中用于构建唐蕃古道典型文物的本体库资料来源主要有:一是知网等资源型搜索引擎;二是百度百科等开放链接资料集;三是从事藏区文物科研的机构等渠道;四是文物藏品展览会信息。对于第二种来源,本研究采用python 爬虫技术,先用urllib模块爬取百度百科相关文物的网页源代码,再利用正则表达式进行数据分析,保留所需要的文本内容,形成唐蕃古道文物的数据集。
从获取文物的百度百科词条地址可以观察出,只要在https:∕∕baike.baidu.com∕item∕后加上所需的实体名称即可获得其URL,对网站中的源码,再进行筛选操作,以唐蕃会盟碑的数据提取为例,词条如图1 所示。
先获取唐蕃会盟碑的url 链接“https:∕∕baike.baidu.com∕item∕+“唐蕃会盟碑””,在爬取过程中为避免被网站限制访问,须在headers 中添加User-Agent,这是为了模拟现实用户真实的访问网站,将其设置为电脑浏览器的访问,再利用urllib 模块进行爬取,此时爬取的内容是二进制形式,不能用于提取所需要的信息,所以需要用decode 函数进行解码操作,即decode(“utf-8”),这一代码可以将其类型转化为字符型,完成后运行打印操作就可以看到二进制转化为了可以利用的信息,再根据模式层中的概念实体,比如:文物材质、文物类别等,所以我们需要在获取的源码中保留的部分是碑上内容,以及包含其收藏位置的简介第二段,因此最后进行正则表达式筛选,所写的正则表达式为<div class="para" label-module="para">(?P<a>.*?)<.*?data-lemmaid="15719689">(?P<b>.*?)<∕a>(?P<c>.*?)<∕div>,提取结果如表1 所示。
以此类推,收集其他百度百科来源的文物数据。从以上四种方式获取大致两百条数据,除去重复和非五省文物实际收集可用文物为92件,实体和关系达到496条,从唐蕃古道典型文物而言,数据量适中。
1.2.2 命名实体识别和关系抽取。命名实体识别又称实体抽取,是指是指判断出给定文本中具有特殊且固定含义的实体,主要内容包括人名、地名、机构名、专有名词等[8],实体识别常用的方法有基于模版和规则、基于序列标注的机器学习方法、基于深度学习的方法、结合迁移学习、对抗学习等新方法,本文根据1.1 节中的模式层的实体属性与关系,在1.2.1 节获取的语料集中进行抽取操作,例如唐蕃会盟碑、镶金兽首玛瑙杯、三彩载货卧驼俑等文物名称。构建唐蕃古道典型文物的数据层,抽取的文物朝代有魏晋十六国、唐代、清朝等,通过上述过程可以获取在唐蕃古道中的典型文物的相关的实体。
所谓实体关系抽取[9]即从文本中抽取出两个或多个实体之间的语义关系,是文本获取知识图谱三元组的主要技术手段,也为构建可用并且质量有保证的知识图谱打下坚实的基础,关系抽取大致有几种常用的模型,一是基于规则匹配的方法,这是一种早期关系抽取最常用的方法,即由专业的熟悉知识的语言学者参与,当规则制定得很完善并且语料集受限制时性能较好,但是该方法通用性较低很难移植到其他不同的领域,并且人工的劳动量不小,代价比较昂贵。二是基于词典或者知识库的方法,可以根据词典本身的关系来识别匹配,单词方法受限与词典的容量,并且对同义词、反义词之类的关系很难识别。
唐蕃古道典型文物的关系抽取则是根据1.1 节模式层的构建来提取实体关系三元组,以唐蕃会盟碑的数据为例,对于“树于”“保存位置”等词,进行替换,替换为所定义的统一的实体关系,即“收藏位置”。
命名实体识别技术的实现是利用label-studio,这是一个开源的数据标注、注释工具,功能十分强大,可以进行命名实体识别、文本分类、图像分类等AI任务。label-studio 在虚拟环境运行比较稳定,因此在conda中创建虚拟环境进行安装。进入标注工具,标注的输入语料集类型须为txt,并且以每一行的数据作为一个待抽取任务,因此数据源中各个文物的信息需按行添加至文本文档。
添加至label-studio 中后数据集会按行自动转换为同等数量的待标注集,在标注标签中,按1.1中的实体属性和关系进行自定义,可根据模式层所的关系进行设置,比如文物名称、文物材质、文物尺寸、文物朝代、文物类别、收藏位置等,以唐蕃会盟碑标注为例,标注结果如图2所示。

图2 标注结果
标注结果有多种存储方式,本文为方便用excel打开并提取,选用csv文件格式转出,如表2所示。

表2 标注导出结果
类似数据集进行同样处理,除此之外其他大部分数据有较为明显的实体信息,利用python 进行文字提取即可,处理之后得到(概念实体,关系,概念实体)的三元组,以唐蕃会盟碑为例,即(唐蕃会盟碑,属性,石头)......这些典型文物的形式全部转化为三元组后就可以用于之后的可视化展示。
2 唐蕃古道知识图谱可视化
2.1 技术实现
Neo4j 是一款开源的图数据库,它可以存储节点、关系以及图数据,并提供了强大的查询和分析功能。与传统的关系型数据库不同,Neo4j 对于图形数据的处理效率更高,可以更好地支持复杂的数据建模和查询操作。在Neo4j 中,节点是数据库中的基本单元,节点之间通过边(也称为关系)相连,从而构成图。每个节点和边都可以包含属性信息,这些属性可以帮助更好地理解数据结构。此外,Neo4j 还支持节点和边的标签,便于对不同类型的节点和边进行分类和查询。Neo4j 提供了Cypher 查询语言用于查询和操作图数据。Cypher 具有简洁的语法和易于理解的查询方式,可以轻松地执行复杂的查询和数据修改操作。
故本文展示的知识图谱的可视化就是通过Neo4j在JDK 17 版本的Java 虚拟机上进行可视化关系图展示。
2.2 可视化展示
Neo4j 节点和关系有多种存储方式,最常用的有主动创建以及利用csv 文件批量导入节点,由于手动添加工作量大,故本文采用文件导入的方式添加实体和关系。基于前面定义的模式层和数据层获取的唐蕃古道典型文物数据,并且由于实体和关系中包含中文,故将其利用记事本的方式转换为以utf-8 编码的csv 文件,部分实体数据如图3、关系数据如图4 所示,将实体和关系文件传入Neo4j 下的import 文件夹,利用cypher 语句进行导入,以文物名称实体类为例,其代码如下:

图3 部分实体数据图
图4 部分关系数据图
load csv with headers from′file:∕∕antique.csv′as line
create(:文物名称{name:line.name,id: line.id,des:line.des,picadd:line.picadd});
file 后面的则是实体所存储的文件,文物名称则是这些节点所属的实体类,表格第一行是节点的属性,包括文物价值、id 号以及图片url。关系类代码如下:
load csv with headers from′file:∕∕∕时间.csv′as line
match(from:`文物名称`{id:line.from_id}),(to:`文物朝代`{id:line.to_id})
merge(from)-[:时间{property:line.property}]->(to)
与节点代码相类似,只是最后进行了id 匹配,借助两个实体类中的唯一标识id 来创建关系。后续如若有新的文物及关系需要添加或修改,可以直接加入表格,在导入代码的march 中进行重复性筛选重新导入即可。
由于neo4j 的查询检索功能完善,也可以进行知识图谱展开与收缩,知识图谱可视化价值体现以三方面为例:局部文物可视化,唐代文物可视化和总体典型文物可视化。图5 是生成的局部文物知识图谱截图,每一个圆形节点都是一个实体,右侧有它的各种属性,不同实体之间的连接线就是它们的关系,每个关系都有属于它的起始节点、目标节点、标签和方向,而方向则赋予了图的语义化特征,其中我们还可以看到有关唐蕃会盟碑方面的概念,揭示了唐代发生的历史事件和与各个概念节点的关系,通过这些概念可以复现文物故事,向我们展示了藏汉民族在文化、经济交流中情比金坚的友谊,对于沿线地区与祖国关系的挖掘具有深远的现实意义。

图5 文物局部特征可视化
根据唐蕃古道所涉及的五个省份,将文物划分为五条路线,起始为唐蕃古道,目标节点为五省份,关系为路线,关联路线的可视化在导览和展览优化方面具有十分有意义的价值:通过图谱中的所属路线段关系,可以基于路线段的关系和文物的特征来优化文物导览和展览的安排,设计更有逻辑和连贯性的展览路线,提供更丰富和有意义的参观体验。
其次,通过将文物数据汇总再进行某一关系的展示可以得到学术研究、文物保护和旅游教育等方面的价值,以唐代文物为例,输入命令match(n:`文物朝代`{name:′唐代′})return n可以得到对唐朝文物的汇总,以更好地理解唐代沿线地区的文化遗产和交流,如图6所示。

图6 唐代文物可视化
通过对汇总文物节点的分析,我们可以观察到唐代文物在沿线地区的艺术风格和工艺技术的传播和演变。例如,三彩绞胎骑马狩猎俑和三彩载货的卧驼俑展示了唐代三彩工艺在沿线地区的流行和发展。这些文物节点提供了唐代艺术和工艺技术在唐蕃古道沿线的影响和演进的见证。还有一些文物节点反映了唐代沿线地区与蕃部族群之间的文化交流。例如,彩绘胡人俑头和彩绘骑马带帽女陶俑展示了当时与胡人文化和民族交流的痕迹。这些文物节点可以帮助我们了解唐代沿线地区的多元文化交汇和融合。
通过将这些唐代文物节点与唐蕃古道沿线的文化历史相结合,我们可以理解这些文物的共同历史背景和文化传承,也能更全面地了解唐代在这一古道上的繁荣和交流,有助于我们更深入地探索和传承唐代文化遗产,以及彰显唐蕃古道在历史上的重要地位。
最后是唐蕃古道典型文物的全图可视化,如图7所示。
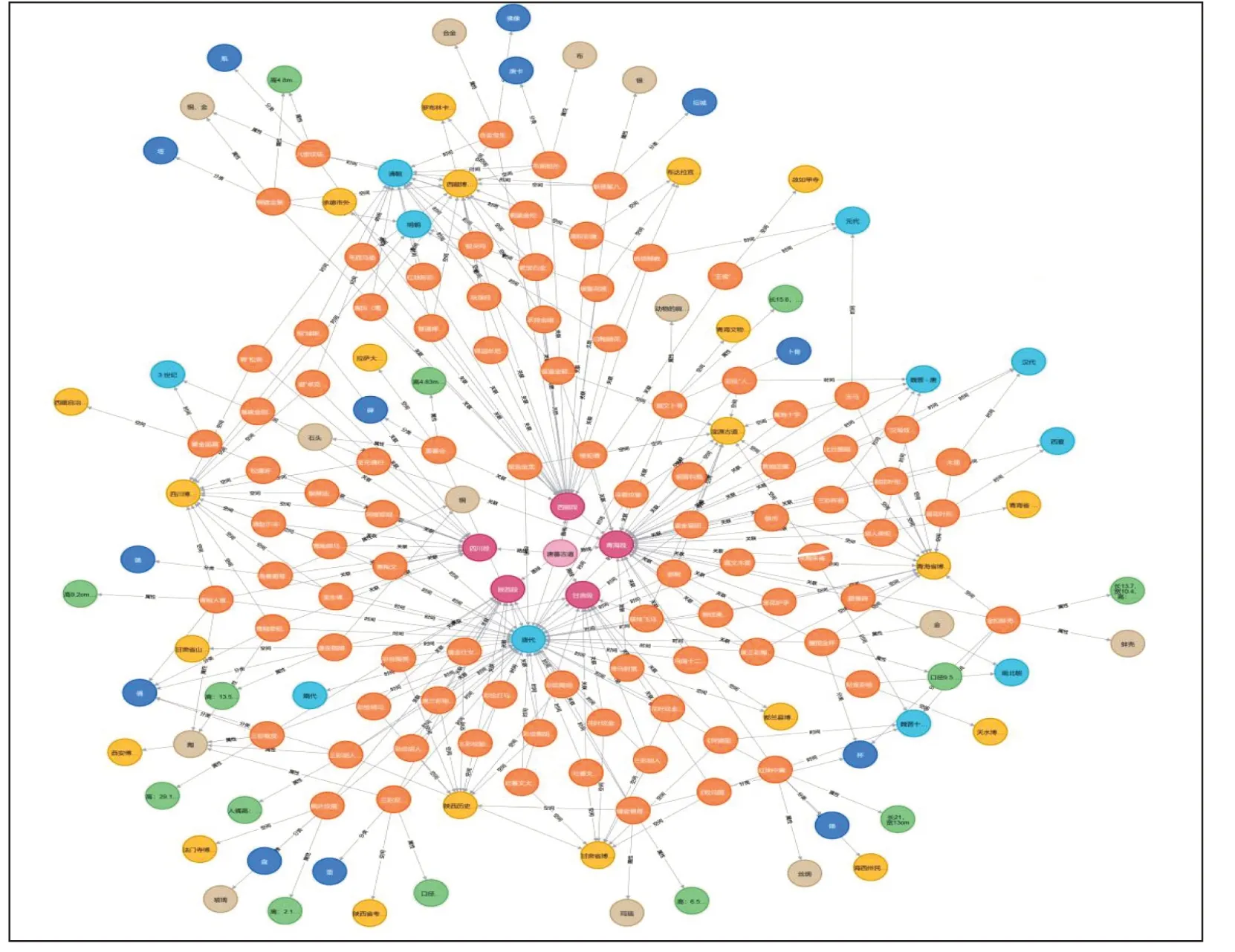
图7 唐蕃古道典型文物知识图谱可视化全图
通过总图我们不但能够在图谱中直观地了解文物之间的联系和共同特征以及它们在唐蕃古道沿线的地位和作用,也可以为文化遗产的保护和管理提供指导等。通过观察图中文物节点的收藏位置和所属路线段,管理者可以更好地了解唐蕃古道沿线的文物分布情况,制定合理的保护策略。例如,镶金兽首玛瑙杯和鎏金仕女狩猎纹八瓣银杯分别在不同的收藏位置,管理者可以根据图谱中的信息,采取相应的措施,确保这些文物的安全和完整性。
不仅如此,就应用而言,可以将文物之间隐含的关系和知识挖掘出来呈现给用户,再结合相应的技术,为之后的唐蕃古道知识图谱应用,比如自动问答(知识图谱的问答功能会按照用户提出的要求直接在知识图谱中搜索、判断推断,把知识图谱作为知识与问答结合起来,从而得到答案)、语义检索(在用户所输入的词语中提取关键字,再根据关键字匹配知识图谱中的不同实体或关系,然后由知识图谱的相关概念构造来完成解析,最后把多个相关知识反馈给用户。)、智能推荐(利用知识图谱的图结构,将智能推荐交互看作“实体-关系”路径,从而基于路径计算预测文本偏好。等功能提供数据源。
3 总结
本文首先分析了研究唐蕃古道可视化的意义,解释了知识图谱的相关概念,通过定义的不同实体构建了知识图谱的模式层并以实例说明,再通过模式层中完成的概念构造数据层。在获取数据源时,采用的是python爬虫技术,利用urllib库通过一系列代码获取所需的百度百科数据,再基于label-studio 平台进行命名实体识别以及关系抽取操作,将数据清洗为三元组形式,存储到csv 文件中,最终利用Neo4j 技术可视化知识图谱。唐蕃古道典型文物知识图谱的构建,不仅为可视化展示提供知识库,还有多方面如自动问答、文物活化、文物阐释等的拓展应用,对藏民族优秀文化传承有着积极的推动作用。
猜你喜欢
小学生作文(低年级适用)(2022年10期)2022-10-31 01:51:28
东方少年(2022年25期)2022-10-18 06:52:46
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:13:52
云南画报(2021年10期)2021-11-24 01:06:54
现代临床医学(2021年1期)2021-01-26 00:56:32
西夏研究(2020年1期)2020-04-01 11:54:30
河南电力(2020年6期)2020-01-12 11:52:22
科学中国人(2017年23期)2017-07-12 09:03:07
大众考古(2014年10期)2014-06-21 07:12:14
延河(下半月)(2014年2期)2014-02-28 21:06:02
