
基于动作捕捉的实时交互影像系统
——以广州国际灯光节实时交互影像制作为例
2023-07-27 03:41骆駪駪
现代电影技术 2023年7期
马 楠 骆駪駪
1.北京电影学院中国电影高新技术研究院,北京 100088
2.北京电影学院影视技术系,北京 100088
1 引言
动作捕捉(Motion Capture)是指记录并处理人或其他物体动作的技术,它可以将人类的动作转化为数字数据,并且实时地在计算机图形中显示出来。而实时交互影像则是一种通过计算机和传感器等技术,使观众能够与影像内容进行实时互动和交流的影像展现形式。近年来,动作捕捉技术被大量地应用在电影、游戏、虚拟现实和增强现实等领域中,而实时交互影像则通过触摸屏、手势识别、姿态识别等技术进行实现。
但目前通过触摸屏、手势识别、姿态识别等技术实现的实时交互影像在交互方式上较为单一,其交互手段多局限于二维,且不包含物理模拟。此外,由于设备的传感器精度、算法的处理能力或通信延迟等方面的问题,目前的实时交互影像在交互精度上也存在不足,因此本文提出了一种基于光混动作捕捉技术的实时交互影像系统。该系统可以使观众在三维场景中实时地与虚拟角色进行交互,并可以使其与虚拟物体进行包含物理模拟的高精度实时交互,大幅提高实时交互影像的多样性和准确度。
2 动作捕捉实时交互影像系统技术基础
如图1 所示,实时动作捕捉交互影像系统的技术流程主要分为场景搭建、角色设计和交互实现三个环节,主要通过三维建模技术,如在传统建模软件3ds Max、3D Maya、Cinema 4D 等中进行三维场景建模、材质贴图和灯光构建,并将搭建完成的场景导入实时渲染引擎;在角色设计环节中,对虚拟角色进行设计、建模、骨骼绑定,并通过动作捕捉的方式实时驱动角色动作;在交互实现的环节中,进行角色交互设计和交互实现等。

图1 实时动作捕捉交互系统的技术流程
动作捕捉是指通过跟踪和记录真实的人体运动过程中,各个标记点在世界空间坐标系下的位置变换过程,以运动数据的形式保存下来,再基于得到的运动数据驱动虚拟人运动[1]。从早期的机械式动作捕捉设备,物体运动带动机械被传感器实时记录下来,发展到现在的光学动作捕捉技术和惯性动作捕捉技术,动作捕捉技术广泛应用于影像制作和数字人等领域的动作设计和交互功能实现。在技术上,光学动作捕捉技术是由相机发出红外光,在标记点上发生反射,从而捕捉到标记点的绝对位置信息。惯性动作捕捉系统是通过惯性传感器来捕捉人的关键骨骼旋转信息,通过算法还原人体运动姿态,如图2 所示。光学相比于惯性,追踪准确性更高,但由于光线容易受到干扰,其对于场地的要求也更加高。因此,本文采用了光混动作捕捉系统,能够弥补光学动作捕捉中标记点丢失等不足。
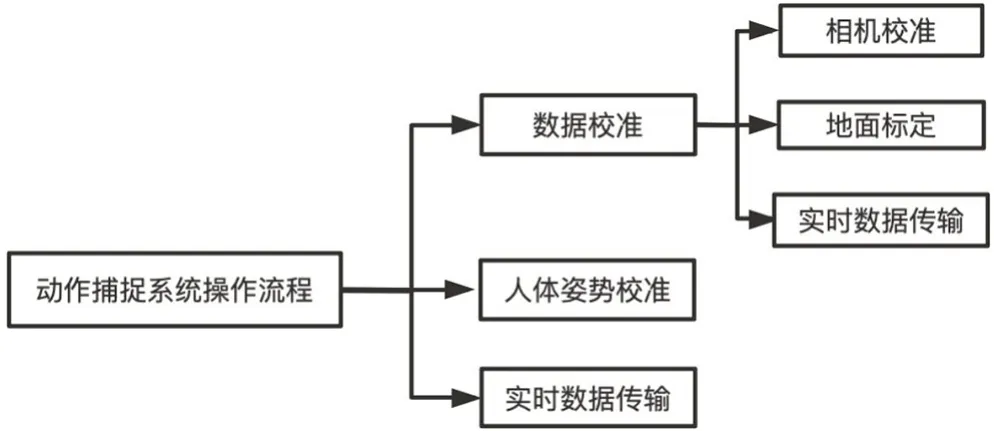
图2 动作捕捉系统操作流程图
交互影像源于20 世纪80 年代开始发展的电子信息技术和当代新艺术形式观念的融合。其本质是通过信息采集技术装置,在空间中采集需要的数据信息,介入计算机系统对数据进行运算处理,再根据需要的交互反应进行展现,从而达到和观众互动的效果。交互影像具有沉浸性、交互性、多感知性等特点,这些特点能更好地表现画面信息,带来更佳的视觉效果。
3 动作捕捉实时交互系统的搭建
动作捕捉实时交互系统主要由动作捕捉系统和实时交互系统组成。
3.1 动作捕捉系统搭建
实时动作捕捉系统使用的是基于诺亦腾光惯混合技术的Noitom VTS 套装,包括8 枚PCC 光学摄像头,惯性数据收发器和光惯混合追踪模块。将光学摄像头使用桁架架设在使用场地上方,桁架下沿一般为2.8m~3m。光学摄像头通过网线与PoE 交换机进行连接,数据收发器将捕捉到的实时动作捕捉数据输入VTS Manager 系统。在全局设置中,在数据网络IP 框中选择摄像头对应的IP 地址,在SIK 选项卡中为对应的频段选择对应的编号。
在场地搭建完成后,对动作捕捉系统进行搭建。首先进行相机校准和地面标定,在VTS Manager 相机管理模块的一级界面中确认相机上线数量和帧率是否和硬件设备预设匹配,之后对场地进行扫场计算以及地面标定。标定结束后,在惯性管理模块采集惯性数据,采集完成后,活动光混部位以及道具使用的光混追踪模块,使之进入光混匹配状态。在数据采集完成后,进行人体姿态校准,在人体追踪的二级界面中,选择对应人体进行姿态校准,按照校准人型全流程A-T-V-B-P 进行校准。对采集到的实时动作数据进行输出,打开MoCap 输出开关,选择对应的协议。如图2所示操作流程,实时动作捕捉交互系统包含了两台计算机节点,计算机节点1负责收发实时动作捕捉数据,计算机节点2负责通过实时渲染引擎实现实时交互部分设计。我们将两台计算机接入了PoE 交换机中,即与诺亦腾设备接入了同一局域网,因此在同一局域网中,可选择通过TCP 网络协议进行数据传输。
3.2 实时交互系统搭建
如上文所述,计算机节点2 与计算机节点1 接入了同一局域网中,主要负责在实时渲染引擎中实现实时交互部分的设计。我们采用虚幻引擎5(Unreal Engine 5,UE5),负责实时交互的实现和渲染输出。在计算机节点2 打开UE 工程文件,安装Neuron Live Link 插件,版本为1.2.16,使动作捕捉的数据能够实时传输到计算机节点2 中。搭建完成的动作捕捉实时交互系统如图3所示。
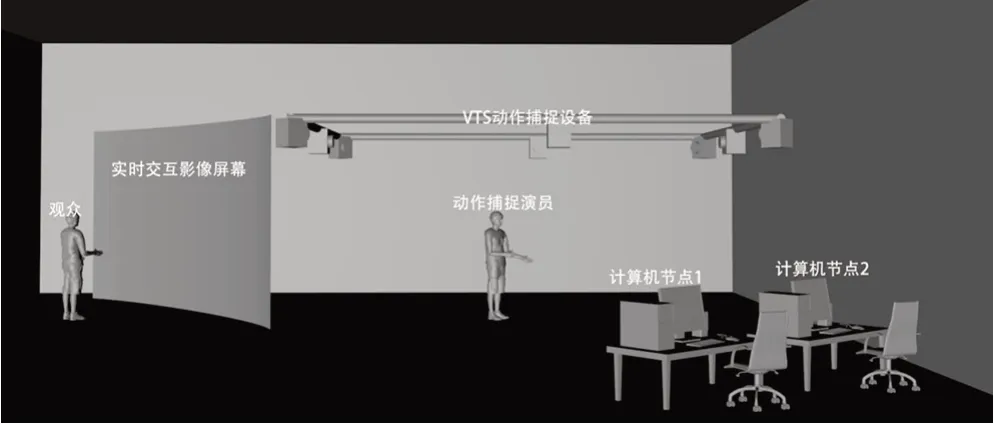
图3 动作捕捉交互系统搭建示意图
4 动作捕捉实时交互影像具体制作
动作捕捉实时交互影像具体制作主要包括主题内容设计、角色和角色动作设计制作以及交互内容设计实现等三个部分。
4.1 内容设计制作
在沉浸式影像内容上,笔者选择了展现广东地区的茶文化。据《广东新语》说,广东种茶始于唐代,唐代曹松把茶种移植到南海西樵山,拉开了广东茶文化的序幕。通过设置实时动作捕捉角色——茶客,展示传统茶馆中的喝茶习惯,与观众进行实时交互展示。
在Cinema 4D 中搭建茶楼的模型,借鉴传统茶楼风格,在中间放置传统方桌椅子,桌上摆放茶碗茶壶,以供客人喝茶聊天。在茶楼场景的左侧设置柜台,负责结账等事宜。将搭建好的场景导入UE5,添加材质、灯光等细化环节,最后形成茶楼内部的景象,如图4所示。

图4 茶楼三维场景效果图
人物角色上设置了两个实时动作捕捉角色,分别为茶客和店小二,在茶馆中负责与观众进行实时交互的部分。实时动作捕捉角色由演员穿戴动作捕捉设备,将采集到的动作捕捉数据传输到实时渲染引擎中的角色上,由演员控制角色与虚拟场景中的物体实现交互动作。在动作上,店小二演员需要给茶客上茶、倒茶和续茶。茶客的演员需要完成叩手茶礼,即弯曲手指,叩手指关节,然后进行喝茶动作,如表1所示。

表1 角色动作设计
笔者使用C4D 建模软件对茶客和店小二的角色形象进行建模,分别如图5、图6 所示。在骨骼绑定过程中,由于实时动作捕捉是以诺亦腾Perception Neuron Studio(PNS)系统设定的骨骼模板进行动作捕捉的,因此绑定需要符合诺亦腾PNS 针对于实时动作捕捉的绑定规范,PNS 绑定规范参考图7。

图5 店小二角色建模和骨骼绑定

图6 茶客角色建模和骨骼绑定
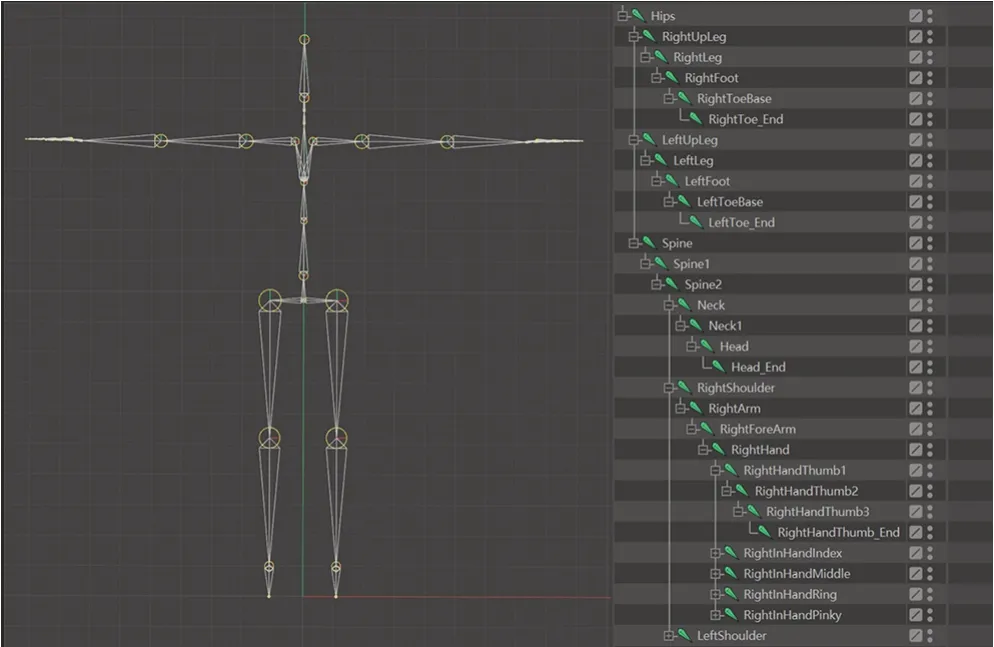
图7 PNS绑定规范
4.2 角色实时交互实现
在角色的实时交互实现上,根据脚本设计,需要实现店小二手持茶壶,向茶杯倒水的效果,主要需要解决的问题是精准地实现虚拟角色与虚拟物体的实时交互效果,要求虚拟物体按照脚本的设定配合虚拟角色的动作。为实现该效果,本文提出了两种解决思路:一种是在虚幻引擎中通过编写蓝图来实现交互,一种是通过动作捕捉设备实现。根据角色动作脚本的设置,角色会与茶杯和茶壶两个虚拟物体进行交互。
方案一的主要思路是通过UE5 的蓝图功能来实现交互。在UE5 中新建Actor 蓝图类,在组件里添加茶杯的静态网格体组件和碰撞体,并将碰撞体设置为可生成重叠事件。根据茶客动作脚本,需要实现拿起茶杯的动作,动作可分解为:识别手碰到茶杯——茶杯附着在手上——茶杯跟随手运动。首先需要让系统识别到角色的手碰到了茶杯,在角色蓝图中添加类型转换节点,用于检测和人物重叠的事件Actor 是否为茶杯。下一步需要实现将茶杯附着在手上,我们通过在角色骨骼添加插槽来实现。将茶杯通过骨骼插槽与角色的特定位置绑定,在骨骼插槽处将茶杯与手的位置调整到最佳,并将对象添加到组件,连接角色骨骼网格体(图8)。此时,当角色触碰到茶杯,茶杯就会附着在左手位置,跟随人的手部进行运动。但编写蓝图的方案存在很大的局限性,因为蓝图编写对每个道具的状态和使用方式都进行了限制,演员需要严格的按照道具的设定进行表演,所以会一定程度上减弱交互性。

图8 蓝图交互实现
在此基础上,我们设计了方案二,通过动作捕捉道具的位置来实现实时交互。按照动作脚本的设计,角色的交互主要体现在茶客、店小二和茶杯等道具的交互上。整体思路是在动作捕捉角色动作的同时,将需要实时交互的物体模型与刚体绑定,捕捉到的刚体运动数据即为场景中物体的运动数据。在VTS Manager 系统中设备管理的二级界面里添加道具(图9),在刚体上装上传感器,对道具信息进行编辑和管理,将茶壶设置道具名称为“teapot”,将茶杯设置道具名称为“teacup”。选择对应ID 的光混追踪模块,并导入对应识别的道具模型自定义光混追踪模块与道具的offset,以实现精准定位和适配。在UE5 中,选择茶杯的静态网格体,在细节面板中添加Live Link Component Controller 组件,在Subject Representation 中选择对应的道具,此时道具的位移数据就已经传输到UE5 的静态网格体中。
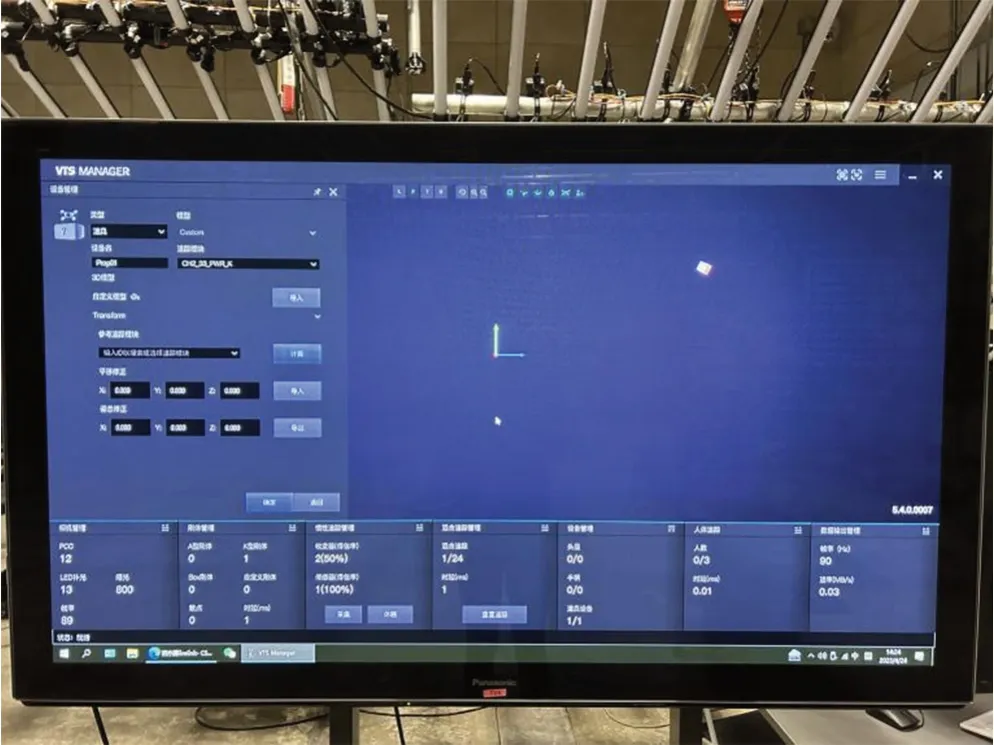
图9 在VTS Manager 中添加道具
为了便于精确调整道具在场景中的位置,需要将场景和道具的位置归零,使用相对位移驱动道具,才能使得道具出现在正确位置。调整道具位置可以通过VTS Manager 的平移修正和Live Link 中的offset,VTS 中平移修正改变的坐标数值是UE 中的1%,因此可以计算出精确位置来进行调整。调整完毕后,人手朝对应位置转动,茶壶就会实现向茶杯倾倒效果(图10)。

图10 茶壶向茶杯倒水实现效果
通过在实时性、精确性和完整性上对两种方案进行测试,在实时性上,方案一只需要动作捕捉人物,而方案二增加了两个动作捕捉道具,所以方案一优于方案二。在精确性上,由于方案一中角色碰到道具后,道具将直接绑定在角色手上,绑定的位置预先设定,所以影响精确度的因素主要在于引擎中交互物体碰撞体的大小、形状以及演员手的位置。如果碰撞体过大或者身体的其他部位误碰到了道具,也会使道具绑定在相应位置。方案二中,道具在手中的方向和运动位置都是实时的,演员需要记住刚体结构的位置点和运动走向,来防止手部穿模以及茶壶倾倒方向错误等。在完整性上,方案一无法实现第二次相同动作,只能进行一次交互,方案二则可以反复实现,更具有灵活性和可操作性。综上所述,实时交互影像制作最终采用方案二。
将计算机节点2 通过HDMI 线连接一台投影,本测试使用的是极米(XGIMI)NEW Z8X 投影,连接完成后,UE5 中的实时渲染画面就被投影在墙面。根据画面的设计调整演员和道具的位置,此时,两位动作捕捉演员的动作实时传输给茶客和店小二这两个虚拟角色。基于动作捕捉的实时交互影像系统的最终效果如图11 所示,现场画面如图12 所示,该系统能够实现动作脚本的设定动作,例如当动作捕捉演员拿起道具做倾倒动作时,实时渲染画面就会显示店小二给茶客倒水的画面。

图11 店小二给茶客倒水最终画面效果

图12 动作捕捉实时交互影像系统最终实现效果
5 结语
本文在广州国际灯光节项目基于动作捕捉的实时交互影像的设计和制作中,通过实时渲染引擎的蓝图功能和动作捕捉道具位置两种方法,实现了虚拟角色和虚拟物体的实时交互功能,丰富了实时交互影像的交互多样性、大幅提升了交互精度。目前,该技术在虚拟直播、沉浸式展览等领域也具有创新内容呈现形式、增强影像交互性等重要意义。未来随着沉浸式交互影像在国内外的不断发展,动作捕捉技术也会被广泛地运用到交互式影像的设计和制作中,为交互影像的内容创新带来更多的可能。
作者贡献声明:
马楠:设计全文框架,搜集文献资料,实验测试,撰写并修订论文,全文文字贡献80%;
骆駪駪:修订论文结构及论文规范,全文文字贡献20%。
猜你喜欢
阅读(高年级)(2022年10期)2022-11-11
快乐作文(5.6年级)(2022年4期)2022-05-07
雪豆月读·低年级(2021年4期)2021-09-10
小学生学习指导(低年级)(2020年11期)2020-12-14
文学少年(原创儿童文学)(2019年5期)2019-05-23
小学生作文(低年级适用)(2018年3期)2018-04-17
少儿科学周刊·少年版(2015年4期)2015-07-07
茶博览(2014年10期)2014-02-08
数学大世界·小学低年级辅导版(2010年12期)2010-11-27
