
M-Cholesky分解法快速求解GNSS整周模糊度
2023-07-26 04:41李克昭田晨冬
大地测量与地球动力学 2023年8期
李克昭 田晨冬
1 河南理工大学测绘与国土信息工程学院, 河南省焦作市世纪路2001号,454003 2 北斗导航应用技术协同创新中心,郑州市科学大道62号,450001
目前应用最广泛的模糊度固定方法是基于整数最小二乘原则在模糊度域中确定模糊度的最小二乘模糊度去相关算法LAMBDA[1]。LAMBDA算法主要包括3个步骤:模糊度降相关、模糊度搜索、模糊度检验。其中,模糊度降相关涉及大量矩阵运算,耗时较长,因此有必要对其降相关过程进行研究,提高计算效率。国内外学者对降相关过程进行了大量研究:Liu等[2]基于上下三角过程构造联合去相关算法;Xu[3]使用Cholesky分解法构建整数高斯矩阵,在高维情况下分解得到条件数最小的浮点解协方差矩阵;陈树新[4]提出一种以降低协方差矩阵条件数为准则的模糊度去相关算法;Liu等[5]克服了Z变换可能带来的矩阵病态分解,减少了20%的解算时间;安向东等[6]根据频间偏差率范围,采用搜索方法和线性模型去除相位频间偏差对宽窄巷模糊度的影响;邱蕾等[7]提出在位移值较大的情况下通过多种载波相位组合方法解算短基线GPS整周模糊度。自从Hassibi等[8]将格理论中的规约算法Lenstra-Lenstra-Lovász(LLL)应用于模糊度降相关以来,诸多学者从格基规约理论出发分析LLL的降相关性能:Xu[9]提出一种性能优于整数高斯去相关算法和LLL算法的逆整数Cholesky去相关方法;范龙[10]基于分块Gram-Schmidt正交化算法改进LLL算法;谢恺等[11]基于系统旋转的Houscholder正交变换对LLL算法进行改进;卢立果[12]采用分块降维方法改进LLL算法。
上述方法中,Cholesky去相关法效果较好,但也存在一定的缺陷:1)L、D、LT子矩阵的形成过程过于复杂;2)在实际编程计算中,L、D、LT矩阵元素需要较多的存储矩阵;3)各矩阵元素只能按顺序求出;4)未能有效利用各子矩阵元素之间的关系。基于此,本文提出一种改进的M-Cholesky分解法,用合成矩阵取代L、D、LT矩阵,简化了L、D、LT子矩阵的关系;之后,利用高斯算法中的四角规则计算各子矩阵元素,提升分解时的解算效率,可减少约40%的计算元素个数。
1 基于Cholesky分解的模糊度去相关模型
GNSS观测方程的模型求解可以等价于求解下式的最小值问题:
(1)
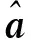
由于模糊度分量之间通常具有很高的相关性,因此搜索效率较低。为了使求解过程更高效,可以通过整数高斯变换(Z变换)将其转化为新的最小二乘问题:
(2)
(3)
式中,Z为幺模矩阵,即矩阵的行列式为1。矩阵Z的元素均为整数。
(4)

(5)
式中,I为n维单位矩阵,η为对L矩阵的第i行第j列的元素取整,ei和ej为单位坐标向量。
2 M-Cholesky分解算法
传统Cholesky分解模型复杂,且需要4个数组分别存放Q、LT、D、L矩阵。本文通过研究矩阵间各元素的相应关系,引入合成矩阵来减少计算所需的数组,并结合高斯算法中的四角规则提出一种改进的M-Cholesky分解法。
以4阶矩阵Q为例,给出其Cholesky分解:
(6)
将LT、D、L矩阵整合得到的合成矩阵与Q矩阵各元素进行比较,合成矩阵与Q矩阵的对应元素关系如式(7)中的合成矩阵所示:
(7)
可以看出: 1)利用式(7)进行Cholesky分解时,可在Q矩阵的基础上直接计算得到合成矩阵,仅需要1个数组即可存放原本需要3个数组存储的内存;2)合成矩阵中的元素lij与lji关于主对角线元素对称相等,因此在进行Cholesky分解时,可以仅计算对角线元素以上的lij元素,lji=lij。
在上述分析的基础上,利用四角规则给出M-Cholesky算法中合成矩阵元素的计算步骤:
1)基于dii对第i行元素进行规约化处理,得到lij元素;

3)将第i行的lij赋值给第i列的lji元素;
4)对(i-1),(i-2),…,1行依次循环,完成所有计算。
其中,步骤2)中参与计算的元素为:
(8)

由式(8)可以看出,每次参与合成矩阵计算的4个元素均位于矩形的4个角上,因此称之为四角规则。在M-Cholesky算法计算过程中,所有计算元素转换为相应的对角元素、交叉元素和消元元素时,最多只用到3个元素,因此可以将该计算过程视为规约化后的消元计算。M-Cholesky算法与Cholesky算法在计算过程中所需的计算元素个数如表1所示。

表1 M-Cholesky算法与Cholesky算法所需计算元素个数对比Tab.1 Comparison of numbers of computing elements required by M-Cholesky algorithm and Cholesky algorithm
由表1可见,M-Cholesky算法可减少约40%的计算元素,提高了计算效率,且不影响计算结果的精度。
3 实验验证
解算精度与时间效率是判断一个模糊度解算算法是否可行的关键,但由于本文所提出的M-Cholesky算法仅改变了计算元素,并不影响定位精度,因此仅采用仿真数据与实测数据对Cholesky算法与M-Cholesky算法的运行时间进行比较。
本文基于Microsoft Visual Studio 2019,利用C语言进行M-Cholesky算法的程序设计,并进行数值模拟测试。所有计算均在Windows 10操作系统的电脑平台上进行,处理器为16 GB内存的Intel(R) Core(TM) i7-8750H CPU@ 2.20 Hz。
3.1 仿真实验
参照文献[13]的仿真参数进行仿真实验,仿真维数为5~40。为避免偶然情况的出现,每次仿真实验取100次均值。2种算法的平均运行时间如图1所示,所有情况下40维的平均运行时间如表2所示。

图1 平均运行时间Fig.1 Average running time

表2 40维解算时间对比Tab.2 Comparison of 40 dimensional solution time
由图1可见,在观测维数为5~40的情况下,2种方法的计算时间虽然偶尔有波动,但整体上都随维数的增加而增加,其中M-Cholesky算法计算时间总体低于Cholesky算法,且计算效率也随维数的增加而提升。由表2可见,M-Cholesky算法的计算时间更短,相比于Cholesky算法,情况1~7中,M-Cholesky算法计算时间分别提升10.6%、13.5%、12.5%、16%、15.7%、13.5%、20.3%。
3.2 实测实验
实测实验分为3组:1)短基线组采用和芯星通UB4B0-MINI板卡采集的静态观测数据,基线长89.83 m,采样间隔1 s,截取3 000个历元对解算时间和结果进行分析;2)中长基线组采用武汉大学IGS数据中心下载的香港地区HKSL和HKWS站的IGS数据,2站构成的基线长度为42.51 km,采样间隔30 s;3)长基线组采用武汉大学IGS数据中心下载的香港地区HKSL和武汉地区JFNG站的IGS数据,2站构成的基线长度为903.26 km,采样间隔30 s。所使用的数据均为标准RINEX格式数据,包括星历数据和观测数据。
采用GPS、BDS、Galileo、GLONASS多系统数据进行整周模糊度融合解算,3种基线解算时间对比情况如图2~4所示。

图2 短基线解算时间对比Fig.2 Comparison of short baseline solution time
由图2可见,Cholesky算法的解算时间大致在(1.6~1.8)×104μs之间,而本文提出的M-Cholesky算法解算时间大致在(1.5~1.7)×104μs之间,所需解算时间较少,且M-Cholesky算法的整周模糊度解算结果相对稳定。由图3、4也可以看出,M-Cholesky算法在解算时间和解算稳定性上表现更好。需要说明的是,短基线实验结果是从观测到的17 570个历元中截取的3 000个历元,采样间隔为1 s,而中长、长基线的观测时段长于短基线,采样间隔均为30 s,因此图2解算时间曲线较图3、4更平缓。

图3 中长基线解算时间对比Fig.3 Comparison of medium baseline solution time

图4 长基线解算时间对比Fig.4 Comparison of long baseline solution time
4 结 语
本文分析影响Cholesky算法计算效率的因素,引入四角规则,提出一种改进的M-Cholesky算法。实验结果表明,相对于Cholesky算法,M-Cholesky算法求解模糊度的计算时间减少约15%,提高了整周模糊度固定的效率,且解算精度与Cholesky算法一致。
如何处理四角规则中分母为0或接近0时的特殊情况,是完善M-Cholesky算法需要进一步考虑的问题。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
高技术通讯(2021年3期)2021-06-09
科学(2020年5期)2020-11-26
数学物理学报(2020年3期)2020-07-27
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
舰船电子对抗(2016年5期)2016-12-13
数学物理学报(2016年5期)2016-08-24
数学物理学报(2016年6期)2016-04-16
四川师范大学学报(自然科学版)(2015年2期)2015-02-28
