
基于鉴别注意力融合的仪表细粒度分类方法
2023-07-21 07:50:22孙荣艳李晓明
计算机技术与发展 2023年7期
孙荣艳,李晓明
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引 言
指针式仪表广泛应用于工业领域;随着智能化生产的升级改造,基于视觉的仪表自动巡检读数成为了一项重要的研究内容;仪表的读数通常通过检测指针的位置来确定。不同规格型号的仪表,指针指向相同位置所代表的具体读数不同,因此,预先识别仪表的详细类别是进行自动读数的重要前提。
迄今为止,许多学者对仪表的检测识别和读数已经做了很多研究,但有关仪表细分类的研究比较少。目前的文献在仪表读数相关研究中,通常采用经典的目标检测模型(如Yolo等)实现仪表的检测,并假设仪表的类别是已知的,回避了仪表的细分类问题。究其原因,主要是由于不同类别的仪表外观差异较小,相同类别仪表又因光照强度变化和环境等导致差异较大。如图1所示,相同厂家相同类型的仪表只有量程和刻度数不同,再加上有效样本数量少,背景干扰大,因此,现有的基于通用目标检测的分类识别模型在样本量较少的情况下对于仪表细分类的准确率较低。基于此,一些研究者们应用细粒度图像分类算法挖掘仪表的鉴别特征。文献[1]通过图像生成器增广数据集,从而为细粒度分类模型提供更多可鉴别粒度;文献[2]使用基于注意力机制的裁剪方式增广图像达到扩充训练数据集的目的,提高了细粒度识别的准确率。

图1 某变电站仪表数据示例图
针对上述仪表数据的特点,该文提出了基于鉴别注意力融合的仪表细粒度图像分类方法,设计的鉴别注意力模块(Discriminant Attention Model,DAM)是通过双线性池化进行融合的,亮点在于利用浅层网络提供的位置空间信息引导模型分类;通过添加鉴别注意力模块和构建类别区分力更强的正交损失函数,突出了仪表之间的细微区别,从而有效改善了仪表细分类的性能。贡献总结如下:
(1)针对仪表图像细化分类问题,提出了DAM模块,该模块能有效利用浅层特征信息引导分类。
(2)采用DAM模块生成的鉴别注意力图和骨干网络输出的高级特征进行融合,生成的特征矩阵使网络不同层信息互补,提升模型关键鉴别特征表征能力。引入正交损失,提高表盘不同类型鉴别特征的正交性。
(3)通过实验对比验证了所提仪表细粒度分类方法的性能,为仪表后续自动读数提供了可靠保障。
1 相关工作
近年来,基于深度学习的目标检测算法应用广泛,许多学者引入目标检测算法对仪表进行识别。文献[3]使用目标检测算法YOLOv4-tiny[4]检测表盘区域,但只针对了特定类型的仪表,没有细化分类,难以应对实际应用中仪表种类繁多的情况。文献[5]利用Faster-RCNN对仪表做了单分类的粗识别。文献[6-8]通过标注仪表上的多个关键点,应用经典检测算法进行识别,但不同仪表表盘内刻度数字丰富多变,标注关键点十分耗时。且在实际工业环境中,采集到的有效样本量少也是表盘细化分类效果不佳的原因之一。一般的基于卷积神经网络的图像分类[9-11]模型,也不能很好地应用于仪表的细粒度分类。此外,仪表细粒度分类还受复杂背景的干扰。仪表表盘由于其特殊外形易于被检出,但仪表细化分类所需的鉴别性特征都存在于表盘内,以往细化分类效果不佳的重要原因就是模型无法充分学习到仪表的关键鉴别特征。YOLOv5与其它YOLO系列算法相比,准确率和速度都达到最优平衡,可以简便快捷地对表盘鉴别区域做粗提取。
双线性网络[12]是细粒度分类的经典模型。文献[13-14]采用双线性特征融合网络提取鉴别特征完成细粒度分类,但两个特征提取器也增加了网络模型的复杂度和深度。仪表图像不同于一般细粒度分类任务,表盘浅层纹理特征丰富,过深的网络结构可能会导致网络失去纹理信息位置编码等重要鉴别粒度,因此仪表细粒度分类任务采用ResNet34[15]作为特征提取器,不会由于网络过深过浅而导致鉴别特征提取不足,但基础模型无法充分利用网络浅层特征对细粒度分类的引导作用。
此外,多分类任务中常用的交叉熵损失由于采用类间竞争机制,更关注类间显著特征信息,但在细粒度分类中,隐藏层的共有特征存在交叉,因此对于仪表细粒度分类任务中学习到的特征,单纯使用交叉熵损失存在忽略特有特征的问题,结合正交损失[16]可以平衡交叉熵损失的不足。
2 提出的方法
针对以往经典分类识别方法在仪表细粒度分类中的不足,提出基于鉴别注意力(DAM)融合的模型进行表盘的细粒度分类,处理流程如图2所示。
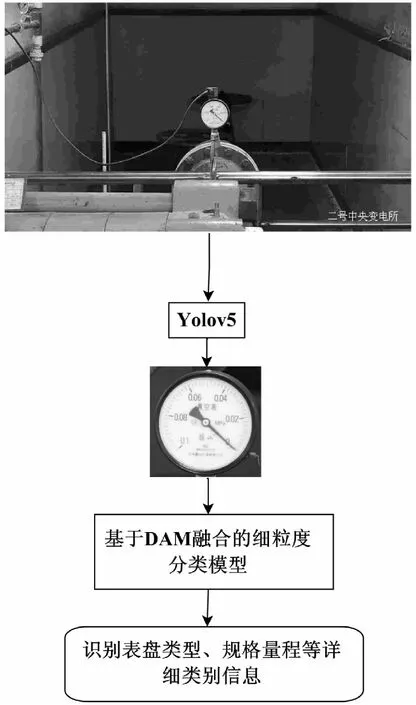
图2 仪表细粒度分类识别流程
仪表表盘有大量刚性粒度特征信息,浅层网络能够提取到丰富纹理特征,但网络层数过深或网络复杂会导致网络学习到更多高层语义信息,而忽略大量浅层关键鉴别特征,使得仪表细粒度分类准确率达到饱和甚至下降。考虑浅层纹理特征以及空间位置信息对细粒度分类的引导作用,该文添加鉴别注意力生成模块,通过将生成的鉴别注意力图和骨干网络最后一层输出的特征图进行双线性融合,提升模型关键鉴别特征表征能力,有效改善仪表细分类的性能,如图3所示。
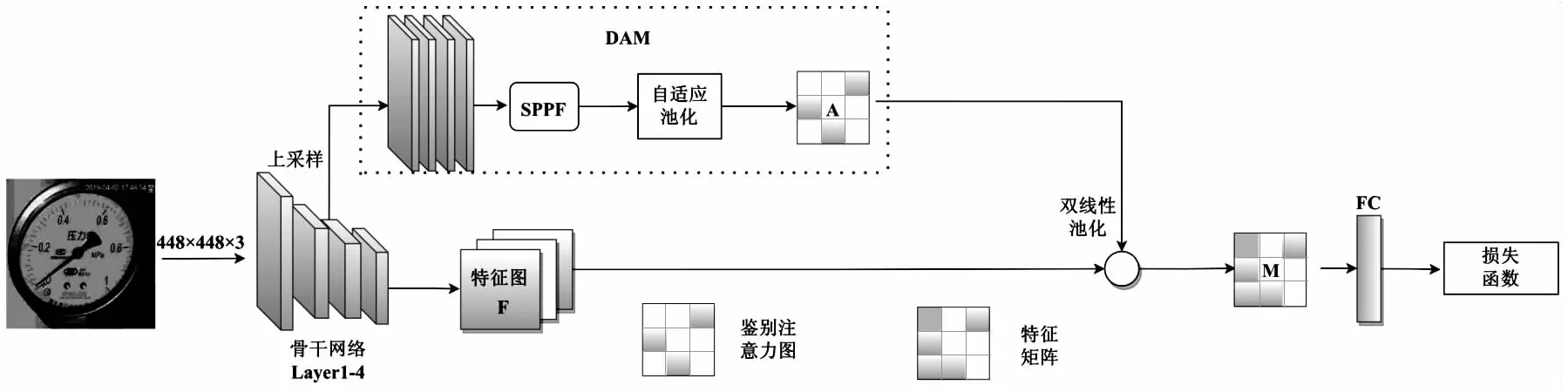
图3 基于DAM融合的仪表细粒度模型
2.1 鉴别注意力模块(DAM)
浅层特征图每个像素点对应的感受野重叠区域小,保证了网络能捕获更多细节。随着网络不断加深,卷积次数以及感受野的增加,感受野之间的重叠区域也不断增加,此时网络获得的是更多部件之间的语义信息。
浅层网络拥有更多纹理、量程、数字的位置和空间信息,这些信息可作为仪表细粒度分类的关键鉴别特征,但同时也由于表盘边缘和刻度线等噪声信息影响分类性能,文献[13-14]添加了更多双线性层,通过融合更多层的卷积特征来提升网络分类性能。
该文改进双线性融合所需的特征提取器,增加鉴别注意力模块进行双线性池化。将骨干网络的Layer2,3,4层特征分别上采样至与Layer1尺寸大小相等,并将它们拼接起来,结合浅层粒度信息能有效提升仪表图像特征表达能力。
随后对上采样对齐的特征图通过SPPF[17]结构,SPPF在提升感受野的同时,有效融合上下文层信息,再经过自适应池化层,最后生成与Layer4尺寸相等的结合浅层信息的鉴别注意力图A,每个通道代表不同的粒度部件。
算法流程具体如下:
给定一组批量输入图像:B为批量大小,图像尺寸为H×W,通道数为3。通过Layer1后,得到B×64个尺寸为H/4×W/4的特征图,Layer2获得B×128个尺寸为H/8×W/8的特征图,Layer3获得B×256个H/16×W/16的特征图,Layer4获得B×512个尺寸为H/32×W/32的特征图。将Layer2,3,4上采样至与Layer1尺寸大小一致,表示为:
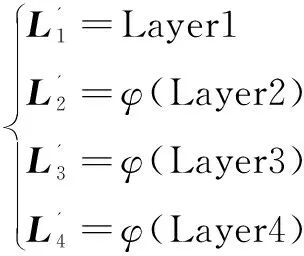
(1)
其中,φ为采用双线性插值的上采样操作。
(2)
其中,φ为自适应池化操作,Ak∈RH×W,N为一个批次内所有类的鉴别注意力特征图的个数。如图4所示,直观展示了一种仪表类型不同层的粒度注意力热力图。

图4 不同层注意力热力图
2.2 双线性融合
每个粒度注意力图代表一个仪表类别的某个鉴别粒度区域,将骨干网络经过Layer4后输出的特征图F重塑为F1,与鉴别粒度注意力图A执行双线性池化,再通过全局平均池化提取出所有类别的局部鉴别粒度特征,如图5所示,生成特征矩阵M,由f1,f2,…,fN组成,表示为:
(3)
其中,g为全局平均池化操作。
2.3 损失函数
不同分类任务中所需特征不尽相同。仪表粗分类中,表盘内显著的字体丰富的刻度以及表盘外形可以帮助从复杂背景中识别出仪表类别。但在细粒度分类中,这些仪表的共有特性会将同规格同类型不同量程的仪表归于同类,这就造成了仪表细粒度分类准确率下降。为使网络更关注不同类别特有鉴别性特征,通过引入正交损失函数来缓解类间分离性不足的问题。交叉熵函数(Cross Entropy Function)通常作为分类任务的损失函数,并没有强制不同类的特征进行分离,直接将得到的特征矩阵M输入分类器,不能充分分离共有特征和鉴别性特有特征。既要保持相同类之间的聚合性,又要提高不同类之间的分离性,就需要对模型所得特征矩阵M施加正交性,来改善交叉熵损失的不足,从而直接加强了类间分离性,提升了仪表细粒度分类性能。
(4)
(5)
(6)
Lol=(1-sim)+β·|dis|
(7)
其中,〈·,·〉表示余弦相似度,余弦相似性运算需要对特征向量进行归一化操作,‖·‖表示L2范数归一化,|·|表示绝对值。Mfi和Mfj表示同类样本的两个特征,Mfi和Mfk表示不同类别的两个特征。Lol为正交损失表达式,约束sim→1,使得同类别样本的特征聚集;约束dis→0,使得不同类别样本特征正交。通过β控制这两个不同约束sim和dis的权重,确定类间分离和类内聚集两个任务的优先级。
网络的整体损失函数如下:
Loss=Lce+λLol
(8)
其中,Lce为交叉熵损失。
在实验中,通过调节(β,λ)的取值,使同类特征聚合,不同类特征更加疏远,提高类间方差,使模型达到最好的效果。参数调节过程中,表明当β,λ分别取0.9和1时,文中的仪表细粒度分类模型达到最好效果。
3 实 验
3.1 评价指标
在分类识别领域,使用准确率(Accuracy)、召回率(Recall)、混淆矩阵对分类算法的性能进行评价。
准确率Acc是所有样本中模型正确识别的样本占比,公式表示为:
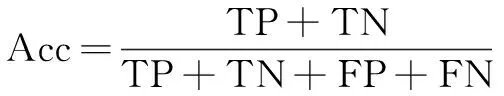
(9)
召回率R又称查全率,是实际为正的样本中被预测为正的概率,公式表示为:
(10)
其中,TP表示正样本被模型正确识别为正样本;TN表示负样本被模型正确识别为负样本;FP表示负样本被模型错误识别为正样本;FN表示正样本被模型错误识别为负样本。模型要同时兼顾准确率和召回率。
混淆矩阵统计每个类别预测正确和不正确的样本数量,显示了分类模型在进行预测时所产生的类别混淆,既可以直观分析模型的错误预测,又可以看到发生错误的类型,补充了分类准确率所带来的局限性。
3.2 数据集及实验细节
该文使用的是某变电站实际场景采集的八种不同规格压力表图像,实际采集280张,分辨率为1 920×1 080,增广扩充至400张后输入到YOLOv5检测模型中进行识别训练。通过YOLOv5对仪表表盘进行粗提,得到仪表细粒度分类数据集,从表盘数据集中选出129张作为测试集。将数据集中剩余图像扩充至838张,并将仪表细粒度分类数据集按照训练、验证8∶2进行划分。
所有实验都是在NVIDIA GeForce RTX 3090上进行的,GPU内存为24G,使用深度学习框架Pytorch1.7、CUDA11.4实现了模型的训练验证。粗提取的表盘图像归一化至448×448的输入大小,随后采用ResNet34(在ImageNet上预训练)作为骨干网络,动量设为0.9,初始学习率为0.001,使用标准优化器SGD,权重衰减设为0.001,batch size 设为8,经过50个epoch。
3.3 实验结果与分析
3.3.1 鉴别注意力模块(DAM)对比实验分析
采用基于鉴别注意力模块的双线性融合。为验证DAM模块在仪表细粒度分类任务中的性能,使用文献[13-14]提出的YOLOv3结合双线性特征融合的细粒度分类算法在文中仪表细粒度分类测试数据集上进行比较。
文献[13-14]都是通过YOLOv3粗提取目标以后,在双线性融合的基础上添加了新的双线性层。从表1可以看出,文中的仪表分类准确率比使用上述两个方法分别提高3.9百分点和2.3百分点,召回率比上述两个方法提升3.9百分点,表明基于DAM模块的双线性融合方案更有助于模型对仪表表盘的细粒度分类。
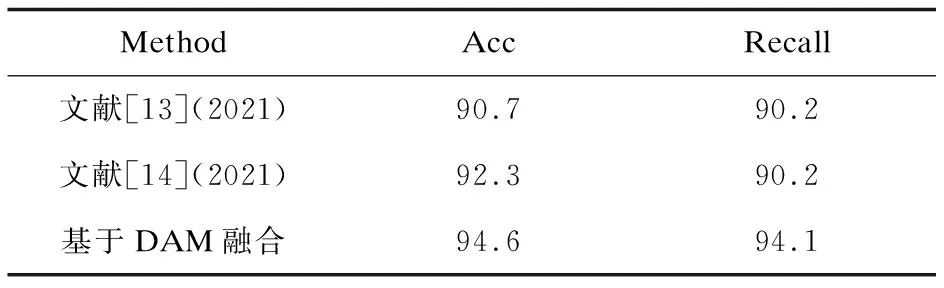
表1 文中方法与现有模型的实验对比结果 %
为进一步评估提出的DAM模块的有效性,应用Grad-CAM[18]对融合DAM模块后的网络层进行可视化,如图6所示。Grad-CAM是通过特征图的加权求和形成的,它可以显示每个区域对其分类的重要性。对于同厂家同规格同类型不同量程的仪表,识别出关键量程字样是细粒度分类准确的关键。由图6可以看出,基准模型无法提取到关键鉴别部件,网络更关注一些显著性特征;文献[13-14]通过改进的双线性融合算法使得模型关注到部分鉴别特征,但没有充分获取浅层鉴别粒度的位置和信息;文中提出的DAM模块,使模型关注到了关键量程数字1,能利用更多浅层关键鉴别粒度引导模型分类,提高了模型对仪表细粒度识别的准确率。

图6 不同模型分类可视化对比
3.3.2 消融实验
表2展示了不同模块消融实验的结果对比。可以看出,加入DAM引导的仪表细粒度分类识别准确率较基准模型(YOLOv5结合ResNet)提升了7.8百分点 ,召回率提升了9.7百分点,表明文中方法得到了更多有效的分类信息,降低了类间差异较小目标的错检率。加入正交损失函数准确率提升了2.2百分点,召回率提升了0.7百分点,正交函数使得同类之间的距离更加接近,不同类之间的距离更加疏远,从而提高了分类准确率,降低了仪表表盘细粒度分类误差。
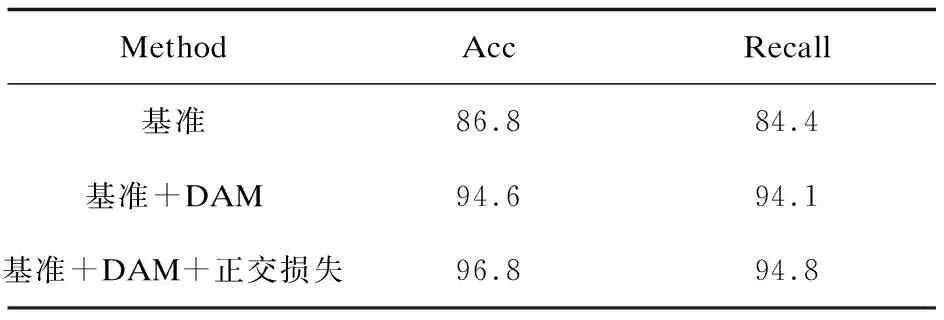
表2 消融实验对比 %
3.3.3 文中方法对比实验分析
量程为0.6的压力表记为pressure_0.6,与量程为1 的压力表记为pressure_1较为相似,同样较为相似的pressue_0.1和pressure_0.9使用经典分类识别方法也不能完成很好的细化区分。图7是由129张测试集数据生成的两个混淆矩阵。由图7可以看出,基准模型在类间差距较小的仪表之间分类识别效果较差,将pressure_0.6误识别为pressure_1等,pressure_0.9和pressure_0.1的误识别率也较高,而文中方法可以很好地识别pressure_0.6,提高了类间差异较小类别的召回率。基准模型不论是不同规格仪表,还是规格相同粒度差异较小的仪表,分类误差都相对较大,文中方法则在准确度和召回率上都有所提升。分析pressure_0.9召回率较低的原因是测试数据集中该类别存在采集时较为模糊的肉眼也难以分辨的图像,没有剔除。因此,文中模型基本符合工业场景下仪表细化分类的要求。
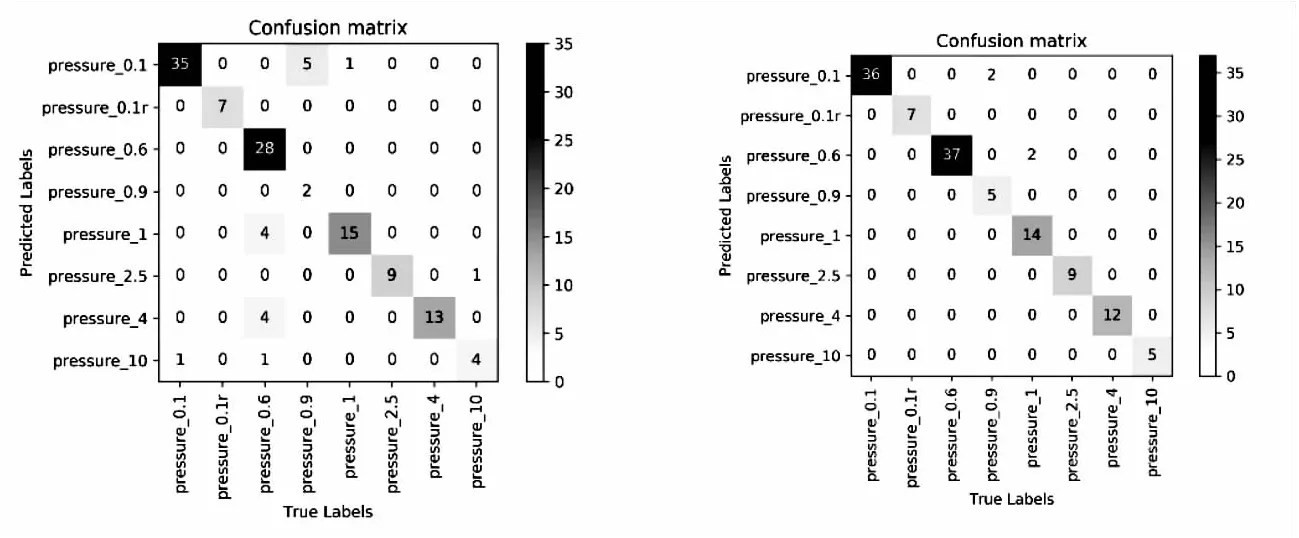
(a)基准 (b)文中图7 混淆矩阵
进一步将整体网络模型的注意力区域进行可视化。图8以文中测试集中同规格同型号量程分别为0.6、1、2.5的压力表图像为例,第一行为YOLOv5粗提取的仪表表盘图像;第二行为基准分类识别模型的可视化,基准网络没有很好地识别到关键可鉴别粒度,其注意力过于集中在显著区域,例如仪表的类型(压力表等)字样,但三类仪表都属于压力表,导致类间差异小的类别不易区分;第三行为文中模型,网络关注到了关键可鉴别的数字粒度以及更多其他鉴别性粒度部件,使得类间相似度高的仪表也能得到很好的细化区分,提高了仪表表盘细粒度分类结果的可靠性。

图8 文中方法可视化效果
4 结束语
提出一种基于鉴别注意力融合的仪表细粒度分类识别方法。在构建的仪表细粒度分类测试数据集上,平均准确率达96.8%,与其它细粒度融合方案的对比表明,基于鉴别注意力融合的仪表细粒度分类方法提升了模型对表盘鉴别粒度部件的识别能力,能满足工业仪表自动读数任务中仪表预先进行细粒度分类的需求。
猜你喜欢
建筑与预算(2023年2期)2023-03-10 13:13:36
红外技术(2022年11期)2022-11-25 03:20:40
建筑与预算(2022年5期)2022-06-09 00:55:10
建筑与预算(2022年2期)2022-03-08 08:40:56
粉末冶金技术(2021年3期)2021-07-28 06:26:16
高技术通讯(2021年1期)2021-03-29 02:29:24
南京大学学报(自然科学版)(2021年1期)2021-01-30 14:01:04
电脑与电信(2018年11期)2018-02-16 05:41:32
系统工程与电子技术(2016年12期)2016-12-24 07:19:14
信息安全研究(2016年3期)2016-12-01 06:06:41
