
基于平均模型和误差削减网络的语声转换系统∗
2023-07-13 12:20:14王媛媛王新宇张明阳
应用声学 2023年3期
王媛媛 王新宇 张明阳 周 锋 赵 力
(1 盐城工学院信息工程学院 盐城 224051)
(2 新加坡国立大学电子与计算机工程系 新加坡 117583)
(3 东南大学信息科学与工程学院 南京 210096)
0 引言
语声转换是一种修改源说话人的语声,使其听起来像目标说话人的技术。语声转换技术已被成功应用于许多领域中,如文本到语声系统(Textto-Speech,TTS)[1]、说话人去识别化[2]和言语辅助[3]。
语声转换可以被描述为估计源特征和目标特征之间映射函数的回归问题。研究者们已经提出了许多成功的语声转换方法,如高斯混合模型的方法[4−5],它是基于频谱参数轨迹的最大似然估计。动态内核偏最小二乘法[6]将内核变换集成到偏最小二乘法中,以对非线性转换关系进行建模以及捕捉数据中的动态特性。稀疏表示方法[7−8]可以看作是一种数据驱动的非参数化方法,作为传统的参数化语声转换方法的替代。基于频率弯曲的方法[9−10]旨在改变源频谱的频率轴,使其接近目标频谱。此外,还有一些语声转换的后置滤波器方法来提高语声质量[11]。
近年来,深度学习方法在语声转换领域开始流行。例如,基于深度神经网络(Deep neural network,DNN)的方法[12−14]研究了平行训练数据条件下的频谱转换,通过使用大量的平行训练数据来实现高质量的语声转换。此外,关于变分自动编码器方法的研究[15],有效提高了语声转换的性能。
上述语声转换框架将每帧的频谱特征视为独立的特征,并不关注语声序列所特有的长时依赖性。标准的递归神经网络(Recurrent neural network,RNN)可以用来解决这个问题[16−17],但由于RNN存在梯度消失的问题[18],限制了其在上下文信息建模方面的能力。此外,标准的RNN 只能捕获前向序列的信息,而忽略了后向序列的信息。
为了解决RNN 的这些问题,研究者们提出了深度双向长短时记忆(Deep bidirectional long short-term memory,DBLSTM)的方法来进行语声转换[19−20],与传统的基于DNN 的语声转换框架相比,DBLSTM 的应用获得了显著的性能提升[19]。CBHG(1-D convolution bank+highway network+bidirectional gated recurrent unit(GRU)) module 最早出现于一个端到端的语声合成系统Tacotron 中[21],它由一组一维卷积滤波器、高速公路网络和一个双向门控循环单元(Bidirectional gated recurrent unit,BiGRU)组成。CBHG网络可以更好地对序列数据处理,提取序列信息。
虽然这些基于深度学习的语声转换框架可以实现很好的语声转换性能,但仍然存在对大量训练数据的依赖性问题。而对于语声转换任务来说,在实际应用时大量数据通常是很难获取的,只能采用有限的数据。剩下的问题就是如何找到一种方法,使有限的数据得到很好的利用。与以往的研究不同,本文利用CBHG 这一强大的深度学习框架,提出了一种在有限的平行数据条件下能够产生高质量语声的语声转换框架。具体来说,本文做出了以下贡献:(1) 由于CBHG 网络可以通过对语声语句的长时依赖性进行建模来实现高性能的语声转换,本文利用多说话人的数据建立了一个基于CBHG的平均模型。(2) 由于基于CBHG 的平均模型可以很容易地用少量数据进行自适应,本文利用有限的目标数据对基于CBHG 的平均模型进行自适应训练,以实现转换后的声音接近于目标声音。(3) 误差削减网络只需要用少量的源和目标的平行训练数据进行训练,所以本文提出了一个应用于自适应的CBHG 网络的误差削减网络,可以进一步提高语声转换质量。总的来说,本文提出了一种基于平均模型和误差削减网络的语声转换框架,可以用少量的训练数据产生高质量的语声。
1 基于CBHG网络的语声转换
CBHG 网络用于更好地从序列数据中提取上下文信息,模型结构如图1 所示。输入序列首先与K个一维卷积滤波器进行卷积,其中第k个卷积滤波器的卷积宽度为k(k=1,2,···,K)。这些滤波器显式地对局部信息和上下文信息进行建模(类似于对一元、二元,直到K元信息进行建模)。卷积输出堆叠在一起,并在时间轴上进行最大池化处理,以增加局部稳定性。所有的卷积滤波器步长均设为1,以用于保留原始的时间分辨率。滤波器处理后的序列进一步传递给几个固定宽度的一维卷积,其输出通过残差连接与原始序列相加。同时将批归一化操作应用于所有的卷积层。接着,卷积输出被送入一个多层的高速公路网络,以提取高层次的特征。最后,序列经过了一个双向门控循环单元,以从前向和后向上下文中提取序列特征。
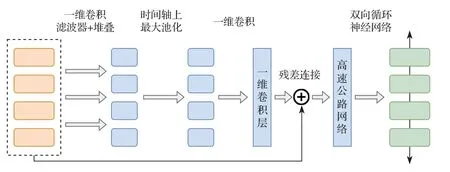
图1 CBHG 网络模型结构Fig.1 Model architecture of CBHG network
基于CBHG网络的语声转换的整体框架如图2所示。在这个模型框架中,对包括频谱特征、logF0和非周期分量(Aperiodicity,AP)在内的3 个特征流分别进行转换。频谱特征由CBHG 模型进行转换,基频转换通过将源说话人logF0的平均数和标准差归一化为目标说话者的平均数和标准差进行线性转换,AP 分量则是直接从源特征中复制而不进行转换。模型将整个语句的特征作为输入,使系统可以从前向和后向序列中获取长程上下文信息。本文中所提出的方法是在有限的训练数据条件下,利用CBHG模型进行语声转换。
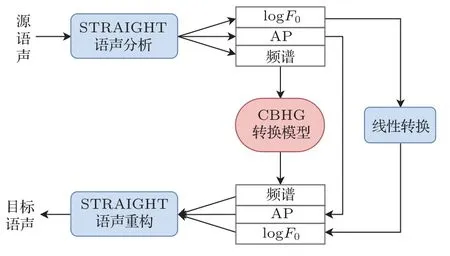
图2 基于CBHG 网络的语声转换系统Fig.2 Voice conversion system based on CBHG network
2 基于平均模型和误差削减网络的语声转换
虽然第1 节所描述的基于CBHG 网络的语声转换具有很好的性能,但是需要同时收集大量的来自源说话人和目标说话人的平行数据,在实际应用中成本较高。为了解决这个问题,提出了一种基于平均模型和误差削减网络的语声转换。
2.1 训练阶段
本文所提出的语声转换框架如图3 所示,整个训练过程可以分为3 个训练阶段。在训练阶段1 中,利用除源说话人和目标说话人以外的多说话人数据,训练一个CBHG 平均模型,用于语声后验图(Phonetic posterior grams,PPG)到梅尔倒谱系数(Mel-cepstral coefficients,MCEPs)的映射。MCEP是一种梅尔对数频谱逼近参数(Mel-log spectrum approximation,MLSA),表示梅尔频率倒谱系数(Mel-frequency cepstral coefficients,MFCC)的近似。输入语声的音素信息是使用一个预训练好的ASR 系统提取的,ASR 模型的输入是语声帧的MFCC 特征,输出是PPG 特征,表示对应语声帧的音素类别的后验概率。训练一个基于CBHG 网络结构的模型,学习PPG 特征和对应的MCEP 特征帧之间的映射关系,MCEP 由STRAIGHT 声码器[22]提取。将训练好的模型称为平均模型,它只能生成训练数据中说话人的平均语声的MCEP特征。
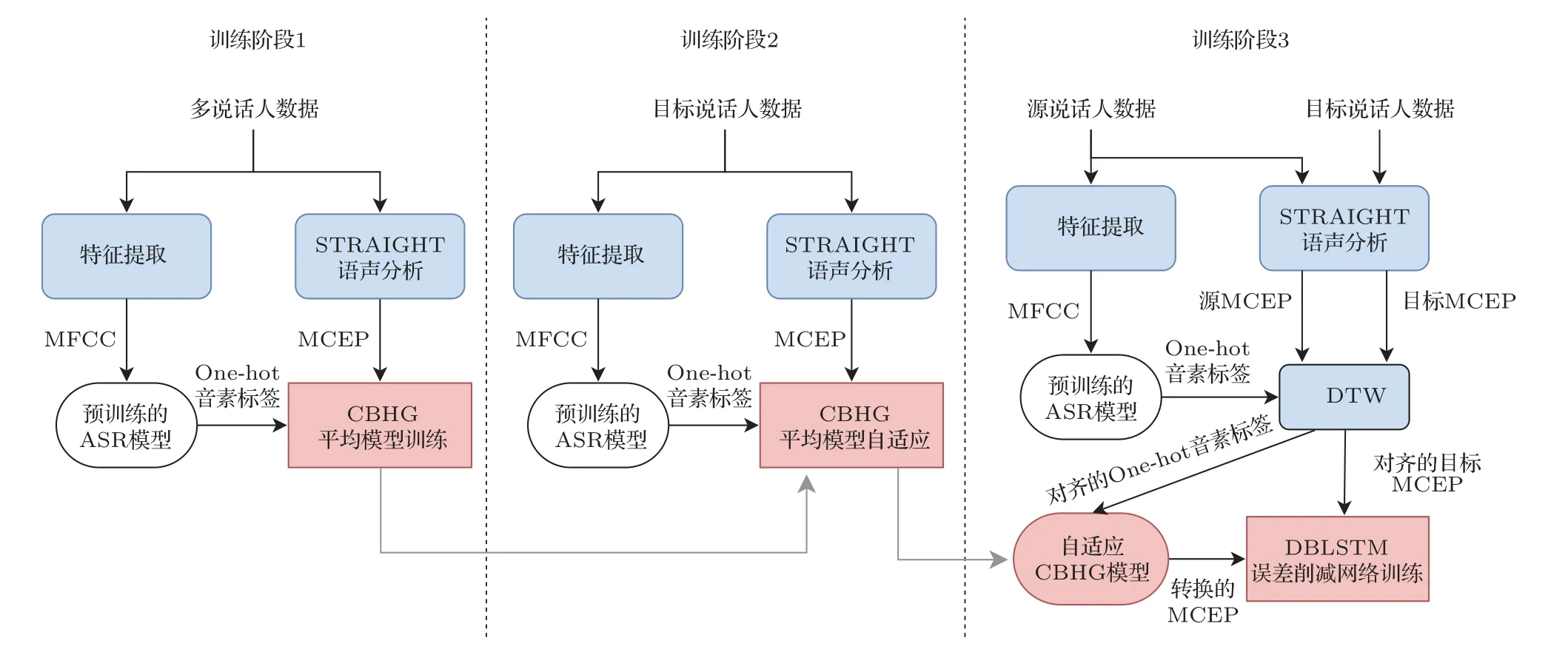
图3 本文所提出的语声转换系统Fig.3 Thevoice conversion system proposed in this paper
在训练阶段2,使用少量的目标说话人数据对平均模型进行自适应。自适应过程与平均模型的训练类似,不同点在于使用训练好的平均模型对网络进行初始化,自适应训练使用的数据是目标说话人语声数据。自适应训练后,模型的输出将从平均语声向目标说话人靠近。将该阶段训练好的模型称为自适应平均模型。然而值得注意的是,不管转换网络的性能如何,转换后的特征和目标特征之间总是存在一个误差,这种误差会降低转换后语声的质量和说话人相似度[23]。为了减少这种误差,提出了应用于自适应平均模型的误差削减网络。
训练阶段3 中涉及误差削减网络的训练,它本质上是一个附加的DBLSTM 网络,用于将转换后的MCEP 映射到目标MCEP。误差削减网络的目的就是使最终的输出MCEP 特征更接近于目标说话人。误差削减网络训练时使用的数据为来自源说话人和目标说话人的平行数据,同训练阶段2 中自适应平均模型训练所使用的目标数据为同一组数据。使用相同的ASR 系统来生成源语声的PPG特征,通过动态时间规整(Dynamic time warping,DTW)技术对来自源语声和目标语声的平行语句MCEP特征进行对齐,同时利用对齐信息得到对齐的PPG 特征。然后将PPG 特征输入到自适应平均模型中,生成对齐的转换后MCEP。在误差削减网络的训练中,输入的是对齐的转换后MCEP,输出是目标语声的原始MCEP 特征。训练后得到的误差削减网络可以进一步降低之前训练阶段中所产生的误差。
在所有的训练阶段中,均采用生成的MCEP和原始MCEP 特征之间的均方差作为模型的优化目标函数。
2.2 实际运行阶段
在转换阶段,输入的是来自源说话人的一整个语句。logF0和AP的转换与第1节中所描述的基于CBHG 的语声转换系统相同。将源语声的MFCC特征输入到预训练的ASR模型中,获得输入源语声的PPG 特征。然后,训练好的自适应平均模型用于将PPG特征转换为MCEP特征。最后,将转换后的MCEP 特征输入到误差削减网络中,得到最终的转换结果。最终的输出MCEP 特征与转换后的logF0和AP分量结合,由STRAIGHT声码器重构得到输出语声。
3 实验结果与分析
3.1 实验设置
本节中进行了一系列测试实验来评估本文所提出的框架性能,即基于平均模型和误差削减网络的语声转换系统。第1 节中所描述的基于CBHG 的语声转换系统和第2 节中所描述的基于CBHG 的自适应平均模型作为本文实验的基线模型,同所提出系统进行了比较。自适应平均模型是本文提出的算法的一个中间步骤,图4 展示了自适应平均模型在实际运行时的转换过程。图5 展示了本文提出的系统在实际运行时和自适应平均模型之间的差异。
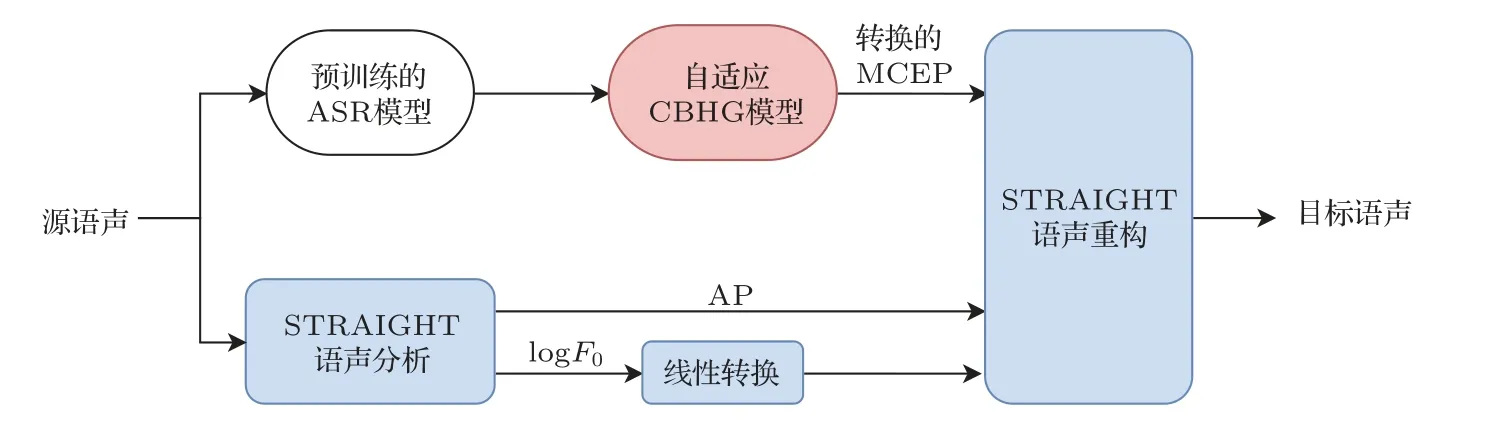
图4 自适应平均模型的实际转换过程Fig.4 The actual conversion process of adaptive average model
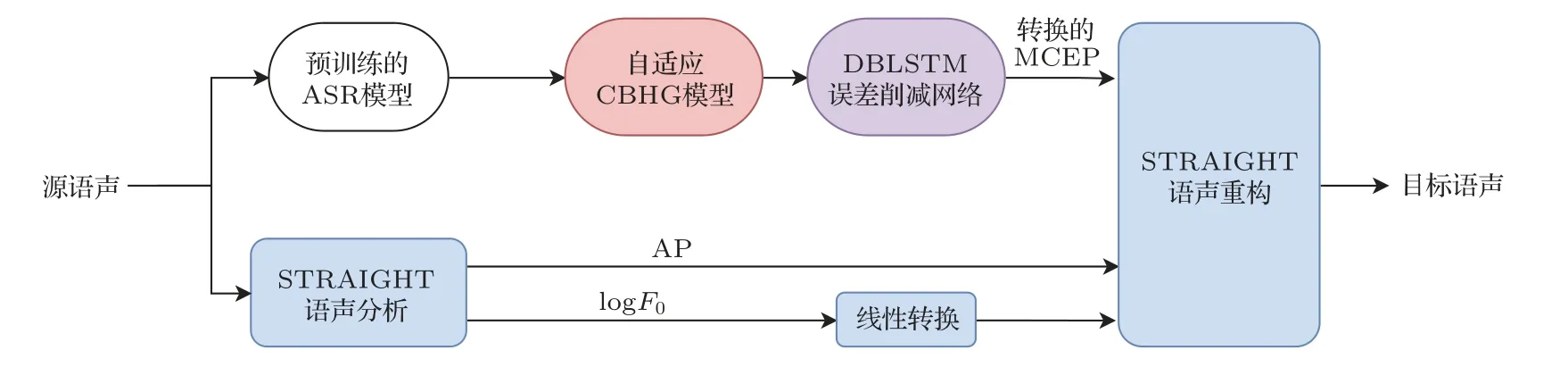
图5 本文所提出模型的实际转换过程Fig.5 The actual conversion process of the proposed model
实验中使用的数据库是CMU ARCTIC 语料库[24]。由于语声转换研究中跨性别语声转换是最具挑战性的工作,本文选择了跨性别的语声转换作为任务目标。语声信号的采样频率为16 kHz,单声道,通过STRAIGHT 提取40 维MCEP 作为声学特征,窗长为25 ms,帧移为5 ms。在基于CBHG 网络的平均模型训练中,使用了4个男性说话者(awb、jmk、ksp、rms)的数据,其中训练数据和测试数据分别为4433 句和489 句。在训练阶段2 中,分别使用目标说话人(slt)的45 个和5 个句子来作为训练数据和测试数据进行平均模型自适应训练。在误差削减网络的训练中,来自源说话人(bdl)的训练数据是自适应平均模型中使用的目标语声的平行数据。PPG 特征的维度为171,通过一个基于DNN-HMM的预训练ASR系统获取[25]。
详细的模型结构和参数如表1 所示。CBHG 网络中的一维卷积滤波器组K设为16,最大池化步长为1 宽度为2,之后的一维卷积投影层宽度为3,所有卷积层的通道数均为128。高速公路网络由4 层全连接层组成,每层包含128个单元。双向门控循环网络包含128 个单元,最后通过线性映射层生成40维MCEP。模型训练前,将所有训练样本归一化为零均值和单位方差。在误差削减网络训练中,为了更好地利用上下文信息,采用3 个连续帧的转换后MCEP 作为输入特征,即当前帧、当前帧的上一帧和当前帧的下一帧特征。误差削减网络的网络结构中共有3个隐层,每层的单元数分别为[120 128 256 128 40]。
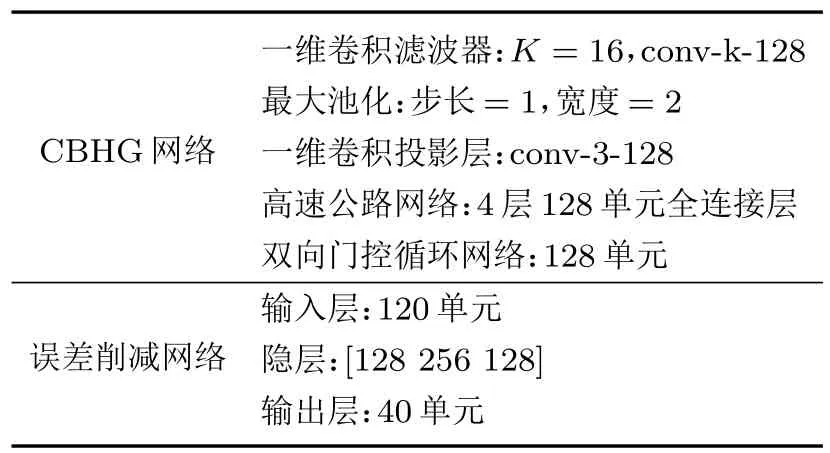
表1 详细的模型结构和参数Table 1 Detailsof model architecture and hyper-parameters
在作为基线系统的基于CBHG 网络的平行语声转换系统训练中,采用来自源说话人和目标说话人的100 个平行语句作为训练数据。基线模型网络结构与自适应平均模型的配置相同。在模型训练中,学习率为10−5,动量因子为0.9。
3.2 客观评估
使用梅尔倒谱失真(Mel-cepstral distortion,MCD)作为客观评价指标,评测转换后的频谱和真实目标频谱之间的距离,用公式表示为
表2 中列出了不同系统的跨性别语声转换的MCD得分结果。从结果中可以看出,本文提出的方法优于CBHG基线模型和自适应的平均模型。还可以看到,自适应平均模型的训练中没有使用平行数据,因此自适应平均模型的MCD 得分不如CBHG基线模型。但是经过仅使用50 组平行数据训练得到的误差削减网络后,性能可以得到明显的提升,优于自适应平均模型和使用100组平行训练数据的CBHG基线模型。

表2 不同语声转换系统的MCD 结果比较Table 2 Comparison of MCD results of different speech conversion systems
3.3 主观评估
为了评估不同系统转换后语声的质量和说话人相似度,进行了主观听力测试,邀请10 名参与者对每个系统所生成的10个语句进行评价。
进行了平均意见得分(Mean opinion score,MOS)测试,参与者对听到的语声质量按照5 分制的规定进行评分: 1=极差,2=差,3=一般,4=好,5=极好。在本节实验中,分别对以下3 个系统进行了MOS 测试:(1) 基线方法,基于CBHG的平行语声转换系统,训练数据为100 组平行数据;(2) 第2 节中所描述自适应平均模型;(3) 本文所提出的方法。MOS 测试的结果和95%的置信区间如图6 所示。基线方法、自适应平均模型和所提出的方法得分分别为3.28、3.57和3.83。
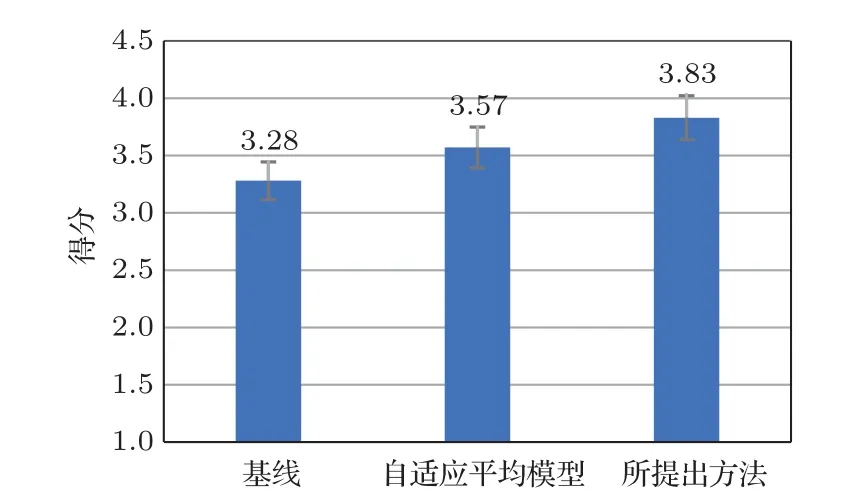
图6 语声质量和自然度的MOS 测试结果及其95%置信区间Fig.6 MOS test results of speech quality and naturalness and their 95% confidence intervals
此外,还进行了ABX 偏好测试来评估两个不同系统生成的转换语声的说话人相似度。在基线方法和本文提出的方法之间,以及自适应平均模型和所提出方法之间进行ABX 偏好测试,参与者要求从给出的A 语句和B 语句中,选择出听起来更接近目标说话人语声X的一个。说话人相似度的偏好测试结果如图7所示。
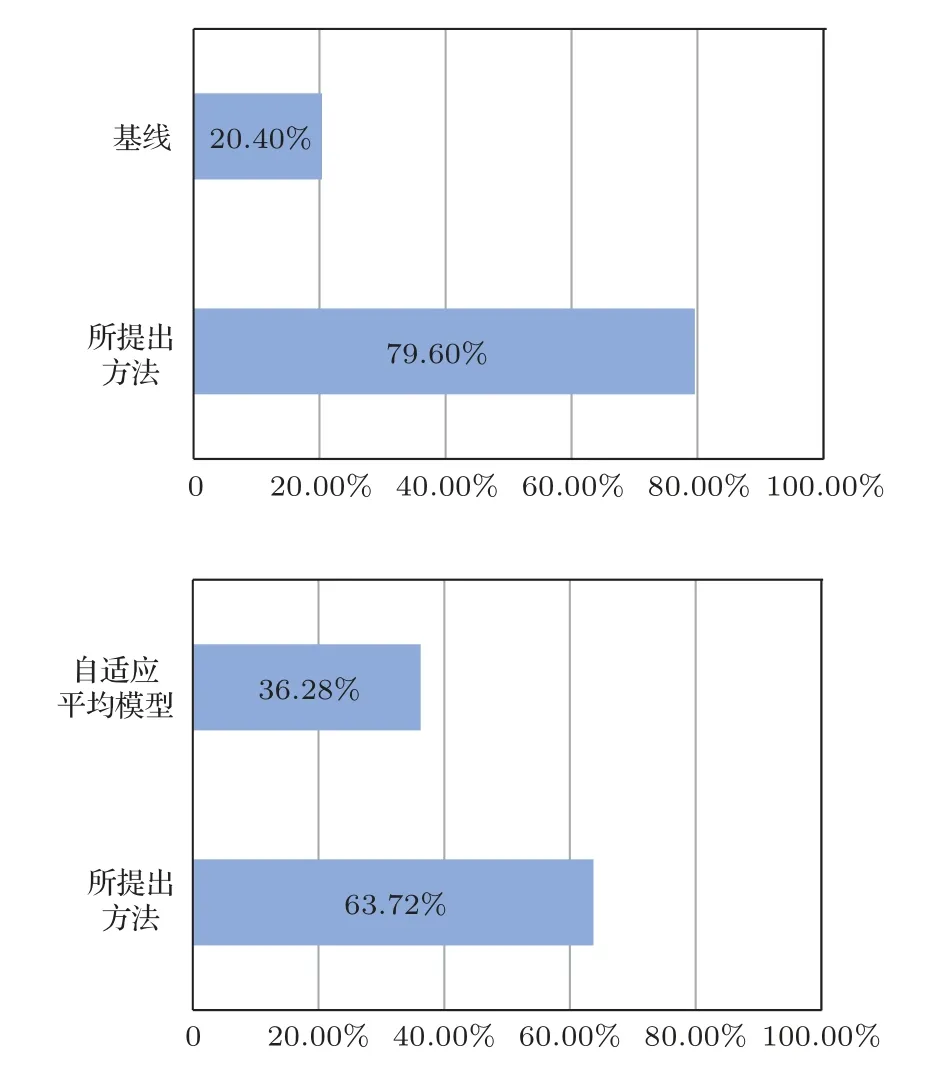
图7 说话人相似度的ABX 测试结果Fig.7 ABX test results of speaker similarity
总的来说,MOS 测试和ABX 偏好测试的结果都表明,本文提出的基于平均模型和误差削减网络的语声转换方法,在有限的平行训练数据条件下,在语声质量和说话人相似度的评估上都优于使用大量平行数据的基线方法。由于平均模型的训练中使用大量的训练数据,达到了比基线方法更好的平均语声质量,对接下来系统模块的性能提升有很大帮助。
4 结论
本文提出了一种基于平均模型和误差削减网络的语声转换系统,在源说话人和目标说话人的平行数据有限的情况下,可以实现良好的转换性能。首先,提出使用排除源说话人和目标说话人的多说话人数据,训练一个PPG 特征到MCEP 映射的平均模型。然后,提出用有限的目标说话人数据来进行平均模型的自适应。此外,还实现了一个可以提高语声转换质量的误差削减网络。客观和主观评估的实验结果表明,本文提出的方法可以很好地利用有限的数据,实现优于基线方法的系统性能。在接下来的工作中,将研究使用WaveNet 声码器来替代STRAIGHT 声码器,逐样本生成原始声频波形,以提高转换语声的质量和自然度。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
思维与智慧·上半月(2022年4期)2022-04-08 21:24:29
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
小哥白尼(神奇星球)(2021年4期)2021-07-22 03:17:22
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
今日中国·法文版(2020年7期)2020-07-04 02:53:48
电子制作(2019年11期)2019-07-04 00:34:38
中国特种设备安全(2019年1期)2019-03-13 01:06:26
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
山东青年(2016年2期)2016-02-28 14:25:41
