
呼吸声分类技术研究及检测系统设计∗
2023-07-13 12:20:20张书文刘泽华张锦龙
应用声学 2023年3期
张书文 侯 猛 刘泽华 张锦龙
(河南大学物理与电子学院 开封 475001)
0 引言
随着新冠疫情在全球范围内的肆虐,许多患有呼吸问题的病人需要不断监测其呼吸状态。当病人出现呼吸异常的情况需要及时向医生问诊。医护人员通过分析病人的呼吸情况可以找寻和分析病人出现这种呼吸状况的原因。呼吸声的诊断一般使用听诊器来获取听诊信息,但是传统听诊器存在着很大的局限性。人耳能够听取的声音频率范围为20∼20000 Hz,而医院所用的听诊器因为在500 Hz左右会产生低频响应,所以会导致误差的产生,使医护人员不能获取到500∼2000 Hz 以外的有效信息[1]。而且诊断结果的准确性与医护人员的专业经验与相关参数有关。在初级诊断治疗阶段,初级医生识别听诊声的正确率一般从20%∼80%不等。而导致高误诊率的原因有很多,例如漏诊、错诊和延误等。
病人的呼吸道出现异常呼吸声的原因很多,例如气道痉挛或者水肿、异物阻塞、肺部呼吸道感染等。由于每个病人的体质和呼吸道受损情况不同,其表现出的呼吸声也会有所不同。通过呼吸特征可以分辨病人的肺部情况,为病人的病情做出诊断。常见的肺部听诊声包括:支气管呼吸声、湿罗声、干罗声、胸膜摩擦声、哮鸣声等[2]。
张伟君[3]通过功率谱方法和线性预测方法对呼吸声进行分类,其分类的准确性会随呼吸声混合的不同类型变化。当鼾声与罗声混合时,其识别准确度仅有25%。崔星星[4]通过使用支持向量机(Support vector machine,SVM)和后向传播(Back propagating,BP)神经网络对呼吸声的分类进行研究,虽然该方法能取得较为准确的识别,但是其计算识别过程较为复杂,且并未实现便携式检测系统研制。本文使用聚偏二氟乙烯(Polyvinylidene difluoride,PVDF)薄膜传感器采集呼吸声,采集的呼吸声经过处理之后可以提取Mel 频率倒谱系数(Mel frequency cepstral coefficients,MFCC)。提取的特征值可以判断识别病人的呼吸状态,且采集的呼吸声可以通过存储介质存储起来,以便为医护人员分析一段时间内的呼吸状态提供参考。
1 呼吸声的采集与特征提取
1.1 PVDF薄膜传感器
PVDF 传感器是一种独特的柔性动态应变传感器,适合应用于人体表面以及人体内部声音信号的采集[5]。其原理是当PVDF传感器在受到拉伸或者弯曲之后,薄膜上下电极表面会产生一个电信号,该信号与拉伸或者弯曲的形变成比例。图1 和图2为MEAS 公司生产的两种不同制造工艺的PVDF传感器。

图1 PVDF 薄膜传感器类型1Fig.1 PVDF sensors Type1

图2 PVDF 薄膜传感器类型2Fig.2 PVDF sensors Type2
常见的声音采集拾声器有电容式、驻极体式、动圈式等。但是这些声频采集拾声器对人体呼吸声信号采集都存在一定的局限性,例如采集的声频范围小、功放后声频混乱、安装不适宜等。此外采声效果接近PVDF 薄膜传感器的电容式拾声器因具有造价昂贵、结构复杂等特点所以不适合长时间反复采集人体微弱的体声信号。电容式驻极体传感器和PVDF 薄膜传感器虽然都具有体积小的优点,但电容式驻极体传感器不具有柔性,且其在低频信号的采集效果并不理想。综上,PVDF 薄膜传感器是最适合采集人体呼吸声的传感器,它可以避免以上传统声频采集装置的缺点,因此可以应用于医学呼吸声监护。本文所述的PVDF薄膜传感器检测装置采用的是第一种传感器。该传感器采集人体的呼吸声信号效果最好,分辨率最高,最适宜与人体皮肤组织接触[6]。该传感器采集信号的下限频率很低,信号的频率范围为8 Hz∼2.2 kHz,其灵敏度为40 V/mm,电子噪声的典型值为1 mV。
1.2 异常气道声
人的说话声可以通过声调以及发音方式来区分,但呼吸声不能使用这些特点进行区分[7]。在人体呼吸过程中,气流经过呼吸道会与呼吸道的组织以及气管相互作用产生声音。病人的呼吸道或者肺部可能有病变(例如分泌物、气泡等)产生,这导致气流在流经呼吸道时会产生异常声音[8]。这些异常声音并没有声调及发音方式的不同,只是其在产生方式不同。人耳可以区分出来这些异常呼吸声,所以可以将呼吸声经过类似人耳听觉的Mel滤波器分析之后可以提取声音特征进行区分。根据这些特征可以分辨这些异常呼吸声。
每种声音的不同可以根据其声音的频谱图来区分,频谱图中包含声音的特征[9]。图3 中列出了正常呼吸声和几种异常气道声的频谱图。红线为正常呼吸声的频谱图,其表示健康人呼吸道以及肺部没有任何病变的呼吸声。绿线为支气管呼吸声的频谱图,其形成原因主要有肺组织实变、肺内大空腔、压迫性肺不张等原因。蓝线为湿罗声的频谱图,其形成原因是气流通过呼吸道分泌物(如渗出液、痰液、血液等)形成的水泡致其破裂产生声音或气体流经分泌物粘连而陷闭的肺泡和细支气管时致其重新充气张开产生声音。湿罗声的细分种类很多,包括粗湿罗声、中湿罗声和细湿罗声等,蓝线显示的是其中一种。黄线为干罗声的频谱图,其形成原因是气体通过狭窄的支气管或震动了黏液弦而产生的声音。其细分种类也有多种,其包含哮笛声、憨声等,黄线所示仅为其中的一种类型。
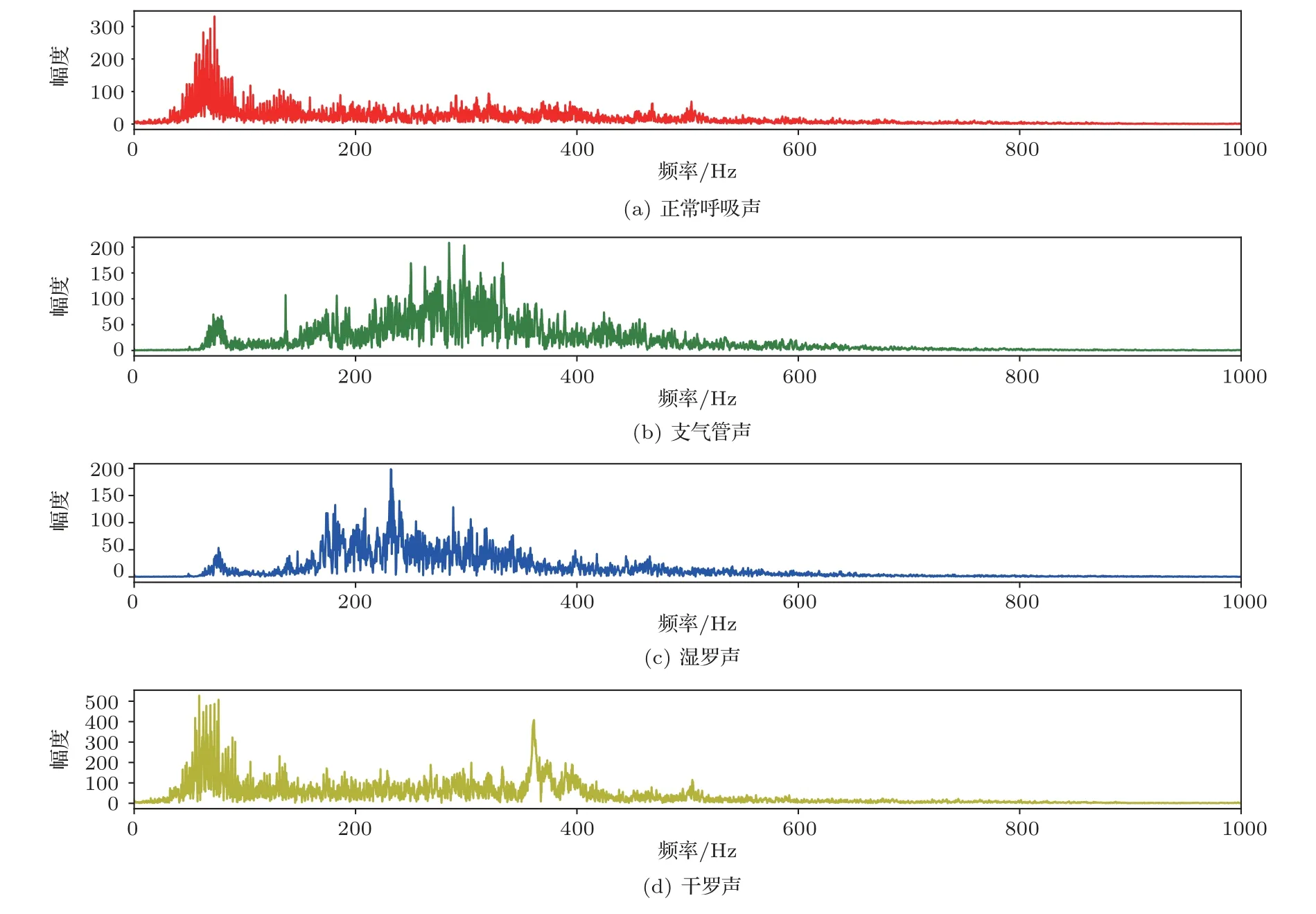
图3 4 种不同典型声音的频谱图Fig.3 Spectrograms of four different typical sounds
1.3 呼吸声的倒谱系数计算
声音频谱包络含有共振峰信息。而提取呼吸声的特征值重点就在于如何提取频谱包络[10]。频谱图反映的是整个声音信号的频谱分布,但是人耳的听觉感知不是整个频谱范围,而是在某些特定的频谱范围。MFCC是最常见的语声特征。MFCC模拟了人耳的听觉特性,将原始频谱经过Mel 频谱变换之后转化为基于Mel 频谱的非线性频谱进行分析[11]。这样做的好处是对呼吸声信号进行降维,更容易得到呼吸声信号的特征值[12]。
Mel 滤波器将信号的不同频率映射到Mel 频率,以此来模拟人耳的听觉系统。式(1)是两者的变换关系:
式(1)中,f对应的是输入声音信号的频率,fMel表示经过Mel 变换的听觉感知频率。图4 为Mel 滤波器组在人耳感知范围内的频响图。从图4 中可以看出滤波器组对低频段更加敏感并且其分布更加密集。这一分布情况与人耳的感觉特性是一致的[13]。
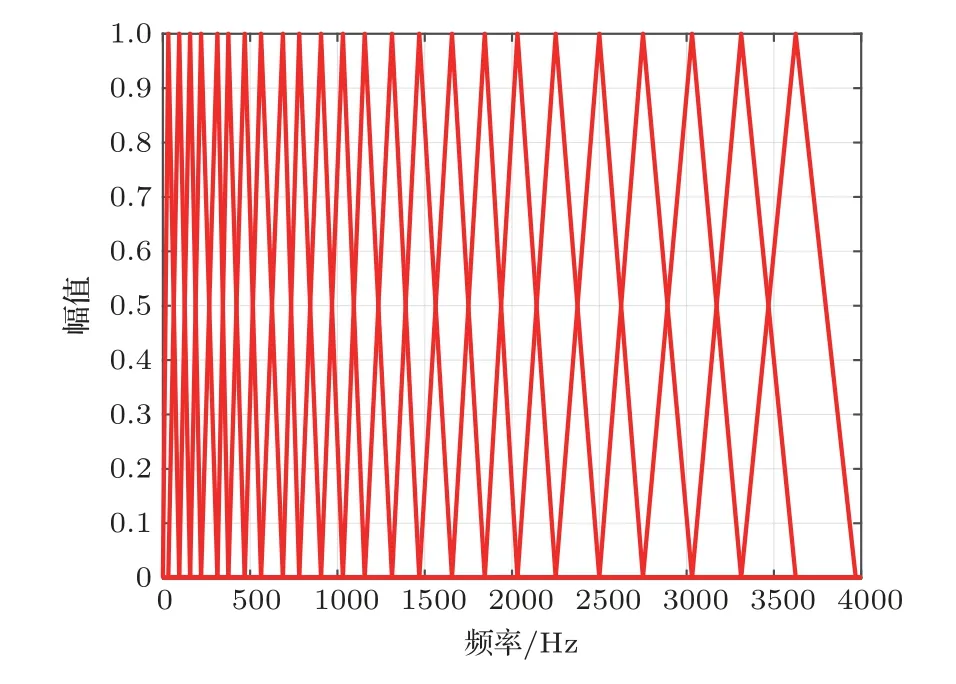
图4 Mel 滤波器组Fig.4 Filter banks
对信号进行倒谱分析需要经过如下的过程:
(1) 人体的呼吸声在一个呼吸周期内是一种非平稳时变信号。对呼吸声音进行预加重、分帧和加窗处理之后可以将信号认为是一种平稳时不变信号[14]。这些处理可以提升信号中的高频部分,突出高频的共振峰,同时也可以减少信号的频谱泄露。
(2) 对经过预处理之后的信号进行快速傅里叶变换(Fast Fourier transform,FFT)将时域信号转化为频域信号:
式(2)中,x(m)为经过预处理之后的声频离散序列,X(k)为经过FFT变换的频域信号。
(3) 对输入呼吸声所在的频域范围内设置一系列的滤波器,这些滤波器组成Mel 滤波器组。其滤波器的设置满足式(3)中的关系:
式(3)中,k指的输入信号的频谱分量,m指第M个滤波器,f(m)指滤波器的中心频率。这里滤波器组个数m设置为26。
(4) 根据式(4)计算每个滤波器输出的对数能量。然后根据式(5)做离散余弦变换(Discrete Cosine transform,DCT),进而得到具有13 个维度的Mel倒谱系数。
式(5)中,M为滤波器的个数,n为DCT计算之后的特征个数。
经过以上计算得到的Mel 倒谱系数可以作为该呼吸声的特征值。该特征值后续可以作为动态时间规整(Dynamic time warping,DTW)处理的数据内容。
1.4 DTW
提取呼吸声的MFCC 特征值会得到一个随时间变化特征的序列,但由于不同个体在呼吸过程中,其呼吸时间长短并不是固定的。为了计算特征序列的相似性,需要使特征序列保有最大的相似度。因此需要DTW 自动扭曲时间序列,也即对时间片段进行局部缩放,此时计算的两段序列相似度(序列距离)更为准确。图5 显示的是两个序列波形相似但是时间轴上未对齐的片段在经过DTW处理之后寻找到相似对齐点,其中虚线指示的为序列对齐点。
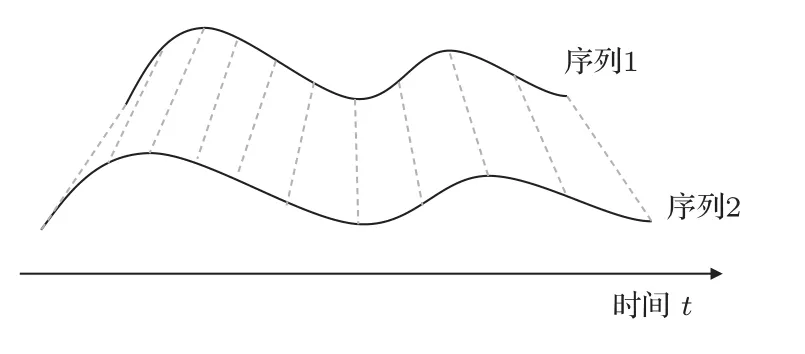
图5 声音信号的DTW 处理Fig.5 DTW processing of sound signal
假设匹配A(a1,a2,a3,···,ai,···,an)和B(b1,b2,b3,···,bj,···,bm)两个序列的相似性,为了对齐两个序列,需要构造一个矩阵网格C,该网格由矩阵元素C(i,j)构成,C(i,j) 表示序列aj与bj的欧氏距离,该网格中存在一个最短路径使得距离累加值Dist 最小。该累加值也就是两个声音序列的相似值。
经过DTW处理之后的时间片段可以减少因呼吸速率及发音震动缓急产生的特征值误差。通过将不同语声以及自身的MFCC特征序列进行DTW处理可以得到DTW 矩阵(欧几里得相似距离矩阵)和相似值(距离)。由DTW 矩阵得到的相似值可以表明不同语声信号的相似性,所以该矩阵可以作为K 最临近(K-nearest-neighbor,KNN)划分样本空间的依据。
1.5 KNN算法分类
采集的呼吸声音进行Mel 倒谱系数的计算提取之后,需要使用某种方式对呼吸声音进行分类。由于异常呼吸声音的样本采集较为困难,不能提取大量数据。尤其是针对于卷积神经网络这种需要大量数据进行迭代回归等方式。所以选择KNN 算法进行呼吸声音的分类。
KNN 算法的核心思想是当一个样本空间k个最邻近的样本中大多数属于某个类别,则样本也属于这个类别,并具有该类别的特征。KNN 方法主要依据的是靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或者重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN 算法的原理有两种,一种是蛮力实现原理,另一种是KD 树实现原理。蛮力实现原理是计算预测样本与所有训练集中的样本距离d。这种方式对于样本特征数过多时时间耗费较大,因此只适合样本较少的简单模型中。
第二种KD树实现原理并不是直接对样本进行测试与分类,而是先对训练集建模,建立的模型就是KD 模型,然后在对数据进行预测。图6 为KD 树的计算流程图,KD 数采用的是从样本的N为特征数量中取方差最大的第k个特征值作为根节点,然后根据此根节点,将数据按大于还是小于划分为左右子树,最后通过同样的办法递归形成KD树。
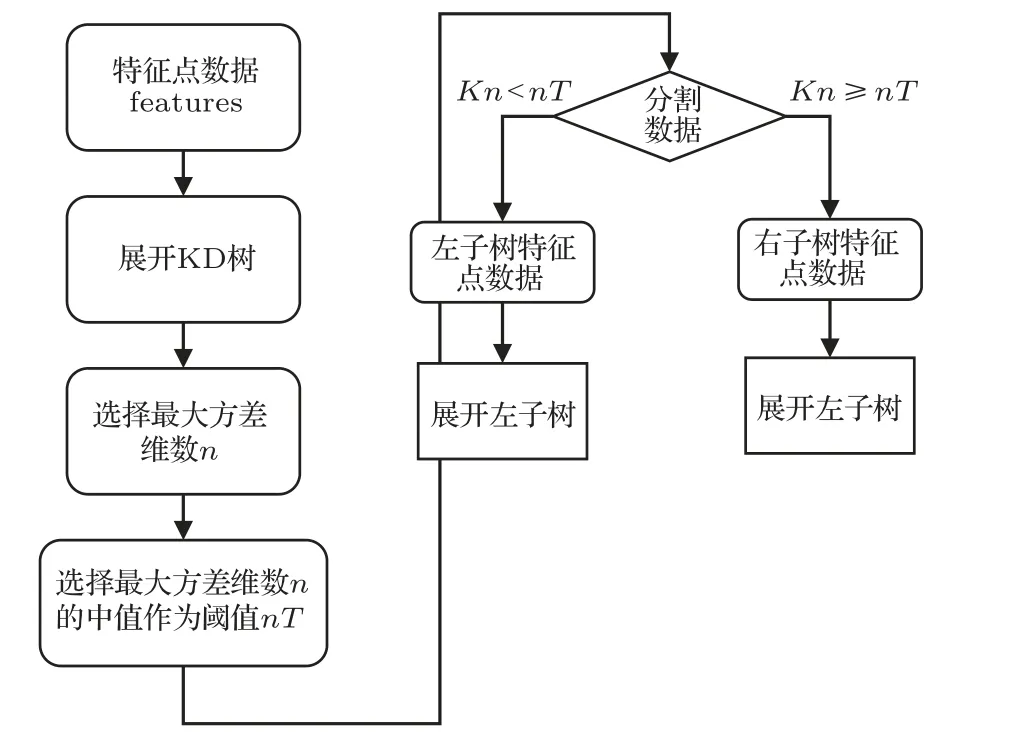
图6 KD 树计算流程图Fig.6 KD tree calculation flowchart
2 系统设计
传统声频采集装置对微弱的体声信号采集达不到要求,其采集效果往往不是很理想。而本文提出的使用PVDF 薄膜传感器来采集呼吸声信号的检测系统采集声频信号分辨率高,可以检测到低频小信号。
图7 是该呼吸检测系统的实物图。该系统采用36 V 供电电压、3300 mAh 电池容量的锂电池为整个系统供电。电源经过直流降压之后给PVDF薄膜传感器提供10 V 的工作电压。此设计电路最大可以同时为4 组声频采集电路供电,可以为后续采集多个不同部位的体声信号进行扩展。

图7 检测系统实物图Fig.7 Picture of detection system
该系统还包括声频采集部分和数据处理部分。图8 是该检测系统采集和处理结构图。PVDF薄膜传感器采集的模拟声频信号经过VS1053b 芯片转化为数字信号,转化后的数字信号经过以STM32ZET6 作为主控和处理的芯片进行计算和存储。
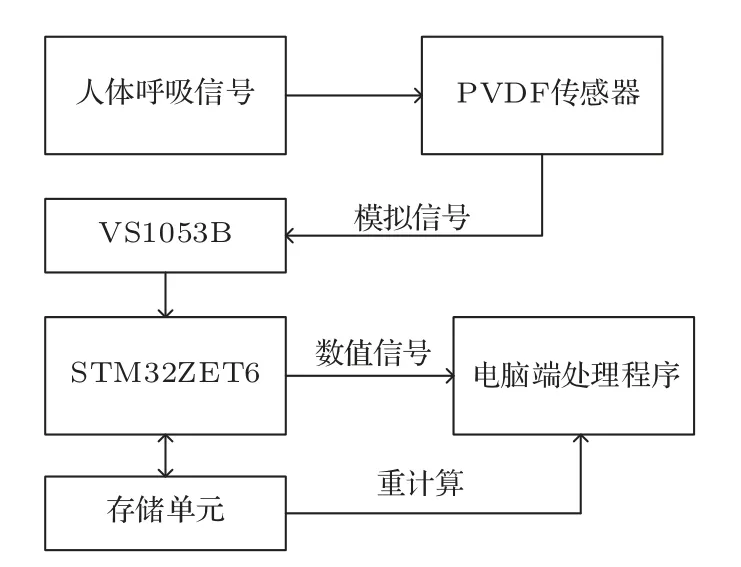
图8 检测系统采集和处理结构图Fig.8 Detection system acquisition and processing structure diagram
存储的声频信号由PC 端的程序进行KNN 神经网络的学习训练,进而得到该分类的网络模型。
3 测试结果与分析
3.1 实验测试过程
项目组与河南大学第一附属医院展开合作,对近三个月呼吸科内出现呼吸声异常的病人与正常呼吸人群进行数据采集。在测量过程中,测量结果的准确性会受到使用者操作方式、外部噪声环境和采集部位等因素的干扰。因此在采集过程中,需要将病人隔离到一个安静的房间内,然后将检测装置的PVDF 薄膜传感器用医用绷带固定到被采集人喉咙部位,启动设备,进行呼吸声的采集。该过程中尽量保持采集部位一致,减少因采集部位不同给实验结果造成的影响。最终采集的数据会被保存到系统的存储器中。
使用呼吸声检测装置总共采集了673个声频数据,除去声频数据中存在异常或者呼吸特征不明显的37 个呼吸声,实际参与分类标号的共636 个。样本声频数据包含163 个正常呼吸声,162 个支气管声,156个干罗声,155个湿罗声。这些数据需要经过KNN 进行训练之后建立模型才能对呼吸声进行预测分类,因此这些数据也需要根据一定的依据划分为训练集和验证集[15]。除此之外,为了验证模型的泛化能力,还需要除了训练集和验证集以外的声频数据对模型的分类准确率进行测试。
3.2 不同呼吸声异常的MFCC特征
该检测系统中选取了4 种呼吸声(不同病人所产生的)作为该识别的种类。图9 显示了这几种呼吸声的MFCC 特征分布图。MFCC 特征分布图描述的是在一个完整的呼吸过程中特征值随着时间变化的倒谱系数图。图9(a)为正常呼吸声的MFCC图,图9(b)为支气管呼吸声的MFCC 图,图9(c)为湿罗声的MFCC图,图9(d)为干罗声的MFCC图。
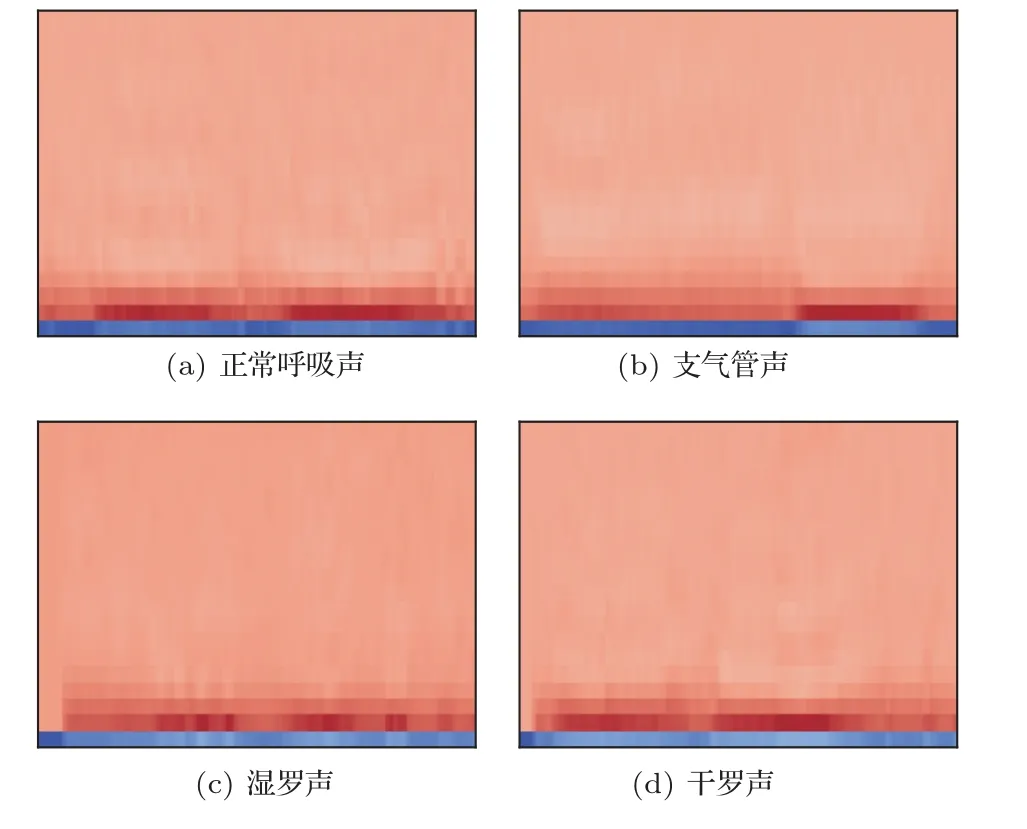
图9 呼吸声音的MFCC 特征图组Fig.9 MFCC feature maps group for breathing sounds
从4 个特征图中可以发现,不同声音中其MFCC 特征具有很大的差异,其在频域上体现在不同频率的包络值不同。对于特征值来说,其反应呼吸声的能量在人耳感知域的分布情况。
3.3 分类测试结果
由于呼吸声采集较为困难,呼吸声样本数据较少,为了使KNN 有较高的分类准确率,同时避免由于在划分训练集和测试集产生的片面误差,需要对数据集进行K折交叉验证,通过尝试利用不同的训练集和测试集来提高系统模型的可靠性。
K折交叉验证的过程是首先将全部样本(4 种不同类型呼吸声)按同比例划分成k个大小相等的样本子集;然后依次遍历这k个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行模型的训练和评估;最后把k次评估指标的平均值作为最终的评估指标。在后续的KNN 分类测试中,K折交叉验证的k值选择为经典值10。为了使采集数据更方便的划分,将采集的声频样本数据随机剔除12 个,剔除后的声频样本数据620 个。最终样本声频数据包含正常呼吸声160 个,支气管声160 个,干罗声150个,湿罗声150个。
KNN 分类测试中选取KNN 的k值为5,选取最近5 个临近对象,并采用KD 树作为最近临近的算法,然后根据这5 个临近对象标记的平均值作为预测分类的结果。经过K折交叉验证之后可以得到10组分类模型的准确率(图10)。该四分类模型的平均准确率为89.84%,且当k值为5时,模型的识别效果最好,其准确率为93.5%。
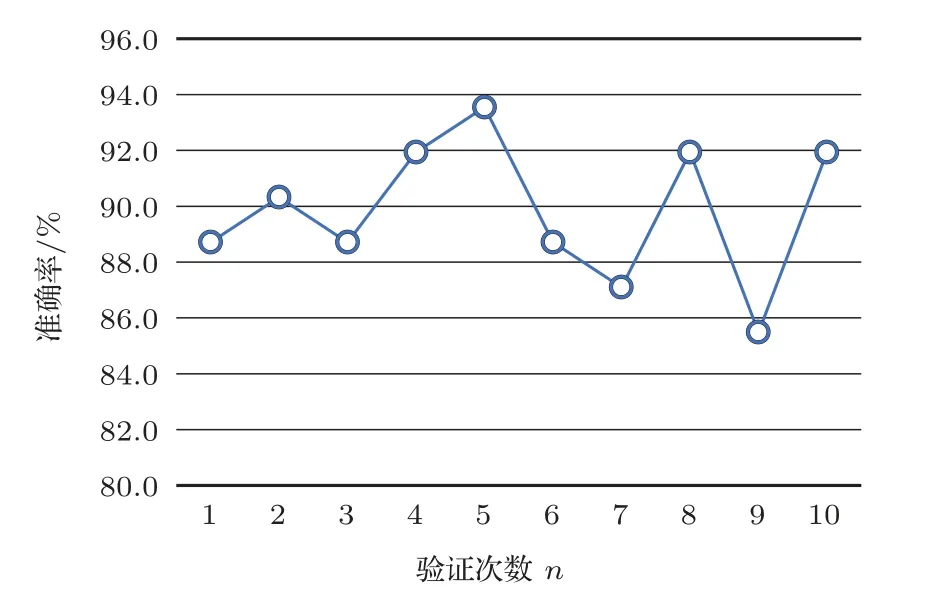
图10 四分类10 折交叉验证准确率图Fig.10 The 10-fold cross validation accuracy of four categories
为探究KNN 模型识别准确率是否会与分类的类型数量有关系,另取正常呼吸声和支气管声音进行对比实验,对以上相同的样本数据进行同样的处理,其测试结果如图11所示。
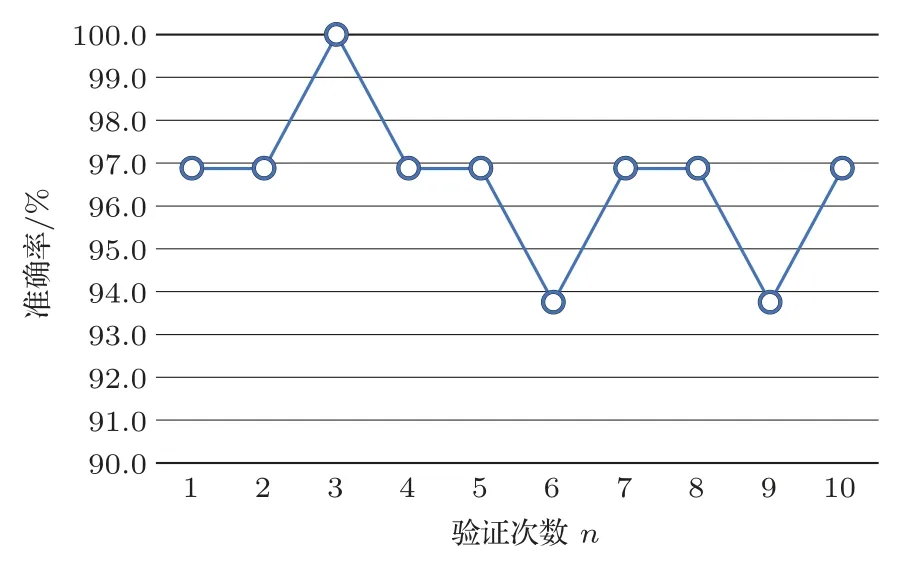
图11 四分类10 折交叉验证准确率图Fig.11 The 10-fold cross validation accuracy of two categories
从图11 测试结果可以看出二分类模型的平均准确率为96.56%,当K为2 时,模型的识别效果最好,可以达到100%。通过对比测试结果图10和图11可以看出,当呼吸分类种类减少时,模型的分类准确率会大幅度上升,从四分类模型平均准确率89.84%上升到二分类模型平均准确率96.56%。
为了验证由KNN 训练得到的模型是否具有优良的泛化能力,使用呼吸声检测装置采集了50 名包含呼吸声异常病人(非测试集和验证集中被采集的人员)的呼吸声,并由上述所得k为5 的四分类模型进行呼吸声分类识别,测试结果如表1 所示。从表1 中数据可看出,基于K折交叉验证和KNN 识别模型的准确率对该50 人测试样本的识别准确率为94%,与四分类K折交叉验证中模型时最佳准确率(k=5) 93.5%基本保持一致,因此该识别方法表现出了较好的泛化能力,可以作为识别和分类异常呼吸声的方法。
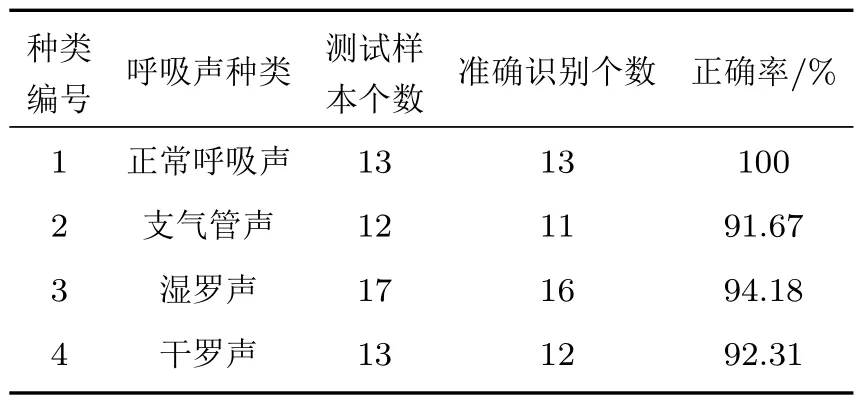
表1 测试结果Table 1 Test results
将基于KNN 识别方法的准确率与双谱法[16]、SVM[4]、小波+LDA[17]、功率谱法及线性预测法[3]进行呼吸声识别的结果进行比较,其结果如表2 所示。通过对比几种识别方法的正确率可得,在这几种方法中,KNN 识别正确率次于小波+LDA 方法的识别正确率,但高于其他呼吸声的识别方法。小波+LDA 方法虽然准确率较高,但其时间复杂度O(k×n)却会随着其迭代次数而大幅增加,因此其迭代收敛速度低于KNN的时间复杂度O(n)。综上,虽然KNN 识别正确率不如小波+LDA 方法,但是其计算过程及处理速度却远远快于小波+LDA 方法,同时KNN也能保持较高的识别率。
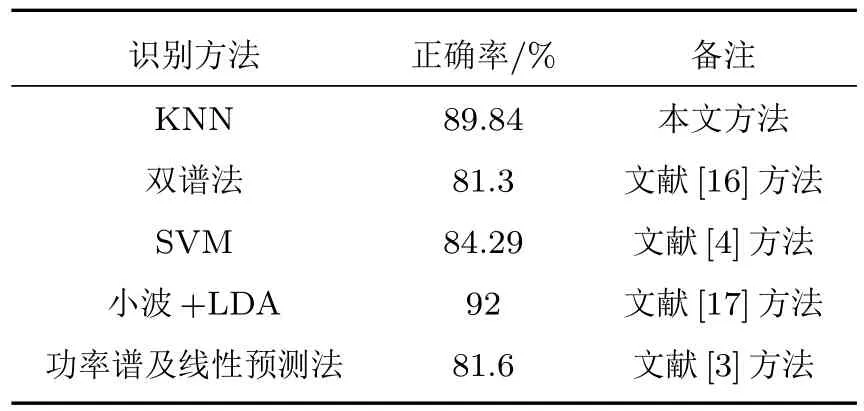
表2 不同方法的识别正确率Table 2 Recognition accuracy of different methods
综合来看,通过该方法检测与分类的正确率会随着种类的细分程度而改变,但其正确率均在85%以上,且比功率谱法及线性预测方法识别分类的准确率高,因此具有较高的可行性和一致性。此外该检测设备具备操作方法简单、计算速度快、携带方便等优点,该方法也可以为其他人体微弱体声采集和分析提供可以套用的范例。
4 结论与讨论
为了能够识别和分类人体微弱的呼吸声信号,本文使用柔性PVDF 薄膜传感器对微弱信号进行采集,然后对采集的呼吸声信号进行特征提取和识别分类。在呼吸声识别和分类过程中使用KNN 算法不但可以达到较高的准确率,又可以保持较快的识别速度。因此该系统可以为实时采集和分析人体微弱的体声信号提供一种很好的实例方法。
目前本检测系统还处于实验室研发阶段,投入实际使用还需大量临床数据和不断改进检测装置。例如,在本系统测试与采集过程中,采集声音的部位是病人喉咙部位。在后续测试和补充阶段,该装置将会放置于病人的胸部,模拟医生听到的听诊声。此外该系统目前采集的声频会受到环境与使用者的操作等影响,这些影响均会导致实际采集信号与病人呼吸声存在偏差。为解决以上问题,目前已经与河南大学第一附属医院展开合作,针对问题提出相关的解决方案,更好地完善该系统,为医护人员以及病人提供医疗便利。
猜你喜欢
科技信息·学术版(2021年17期)2021-11-22 01:17:47
哈尔滨工程大学学报(2021年8期)2021-09-07 12:03:46
空间科学学报(2021年6期)2021-03-09 06:20:14
莫愁·小作家(2020年6期)2020-06-01 18:41:16
测控技术(2018年7期)2018-12-09 08:58:22
东坡赤壁诗词(2018年2期)2018-05-10 11:08:24
青年文学家(2017年28期)2017-11-28 22:43:14
声学技术(2017年3期)2017-10-26 06:23:20
作文周刊·小学六年级版(2016年30期)2017-03-06 20:19:29
听力学及言语疾病杂志(2015年5期)2015-12-24 01:47:08
