
金融时间序列数据可视化框架研究
2023-07-07 03:10许红星
计算机应用与软件 2023年6期
罗 超 许红星 段 然
(云南大学软件学院 云南 昆明 650504)
0 引 言
经济市场快速发展,带来资本市场的快速发展。传统的手工交易方式存在着效率低、盲目投资、实效性差等问题,导致手工交易越来越无法满足人们的需求。在手动交易的基础上,人们开发出了量化交易的方式,以先进的数学模型替代人为的主观判断,利用数据挖掘、机器学习、深度学习等计算机技术从庞大的历史数据中海选能带来超额收益的多种“大概率”事件以制定策略[1-4],极大地减少了投资者情绪波动的影响,避免在市场极度狂热或悲观的情况下做出非理性的投资决策。
在研究量化模型和交易策略的过程中,使用的数据主要是时间序列数据。这种数据如果直接以数字方式呈现,会导致难以分析数据的特点,难以直观看出变化规律,对策略的制定会有很大的限制。如果只涉及一般大盘和股票数据,研究者可以选择市面上成熟的股票行情软件作为辅助参考,但这难以满足研究者的个性化需求。例如在研究中自定义了新指标的计算模型、自合成了新板块数据时,不仅要求能静态地显示数据,还要能在策略回测、实盘交易时动态地更新并显示数据,但是常见的量化平台并不提供此类个性化的可视化接口,这给研究工作造成了阻碍。
对于上述个性化的需求,研究者通常采用两种方法解决:股票公司订制数据、自己编程实现。第一种方法最为直接,但是在研究过程中模型和策略的变动比较频繁,订制的内容可能跟不上需求的变更,而且如果是小型研究团队或个人研究者,这也增加了研究成本。第二种方法对编程能力提出了要求,可以使用可视化工具包做出图形[5-6],但一般复用性较差、容错率较低,只能依托固定的平台或程序,不能适应数据的高速变化,甚至没有考虑数据的动态更新,且市面上缺乏完整的可供调用的可视化模型或框架,也缺少对图形绘制的详细描述,这无形中降低了研究效率。
因此,我们从实际出发,针对存在问题和市场需求,建立了一套金融时间序列数据可视化框架,兼容大部分图形和金融指标的显示,也允许用户添加自定义指标,支持数据动态更新的同时,还考虑到了回测和实盘过程中该类数据具有高实时性、高并发性、瞬时数据量大的特点,改进了数据刷新方式,为下游用户做数据分析与量化交易策略研究提供了可靠且高效的上游数据可视化支持。且框架本身也可作为同类型软件UI设计部分的参考,可以在不同平台用不同编程语言实现。最后以实际工作为参考,将框架与各类常见的量化交易平台相结合,验证了框架的实用性、高效性和跨平台性。
1 数据结构
1.1 Tick数据
Tick是交易数据流的一种快照,是金融时间序列数据的基本单位。以期货市场为例,交易系统会实时收到交易所每秒2次的Tick行情推送,其行情信息有最新价、成交量、成交额等,不同市场或不同量化平台提供的Tick数据,在数据结构和推送频率上都有所不同。我们将一个Tick数据定义为一个基本单位t,t的数据结构设计意在满足所有信息能完整获得的情况下,做到每次传输的数据量最小化。作为一种需要高频刷新的数据,其本身的信息携带量过大,会导致传输性能的降低和传输成本的增加。因此,Tick数据的结构设计,只保留交易中的基本数据,其他关键数据,可由基本数据计算出来。综上所述,t被设计为一个四元组:
t=[′price′,′datetime′,′volume′,′amount′]
(1)
式中:price为最新价;datetime为Tick的创建时间;volume为瞬时成交量;amount为瞬时成交额。
1.2 K线数据
K线模型是最常用的数据可视化模型,其数据由单位时间内的Tick数据生成。K线的数据结构设计为一个多元组:
bar=[′datetime′,′open′,′high′,′low′,
′close′,′volume′,′amount′]
(2)
式中:datetime为K线数据的起始时间(或结束时间);open为单位时间内的开盘价;high为单位时间内的最高交易价格;low为单位时间内的最低交易价格;close为单位时间内的收盘价;volume和amount分别为单位时间内的成交量和成交额的总和。
定义T=[t1,t2,…,tN]为Tick数据的集合,间隔频率为x。设K线的单位时间为y,N为单位时间内Tick数据的个数,若xN=y,则K线数据可以由集合T通过以下公式合成:
bar[′datetime′]=t1[′datetime′]
(3)
bar[′open′]=t1[′price′]
(4)
bar[′close′]=tN[′price′]
(5)
bar[′high′]=Max(T[′price′])
(6)
bar[′low′]=Min(T[′price′])
(7)
bar[′volume′]=∑T[′volume′]
(8)
bar[′amount′]=∑T[′amount′]
(9)
2 框架设计
2.1 总体设计
可视化框架的架构分为3层,分别是底层接口、中层引擎和上层应用,如图1所示。
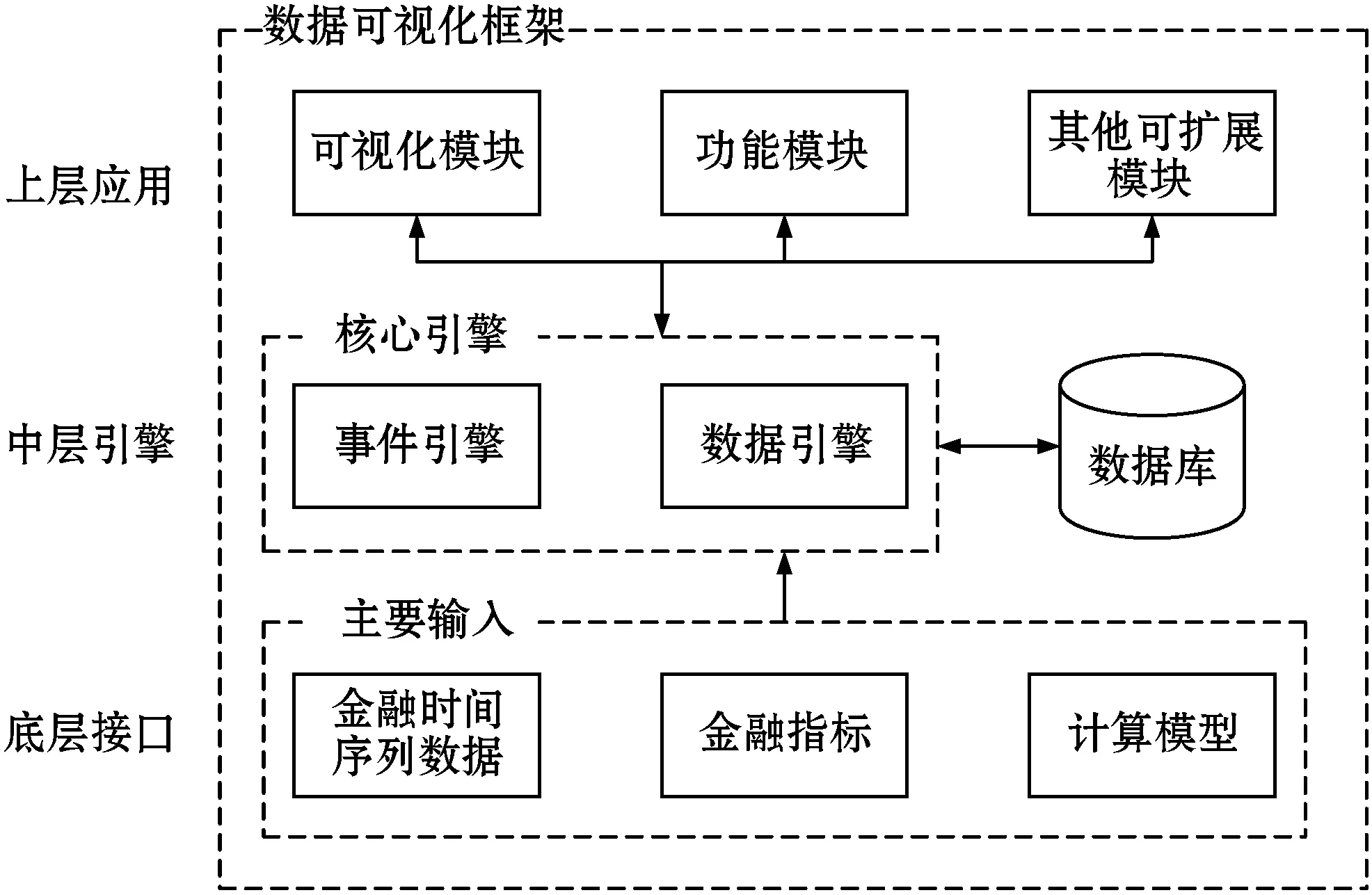
图1 可视化框架架构
中层引擎的设计参考了vn.py框架的设计思路[7],包括数据引擎和事件引擎,往下对接各种数据输入接口,往上服务于各种应用模块。
底层接口负责对接输入数据,主要是时间序列数据、金融技术指标和计算模型。上层应用包括可视化模块和功能模块、可视化模块负责图形的绘制、功能模块涉及与用户的动态交互。
2.2 上层应用
2.2.1 可视化模块计算模型
根据大多数交易员的使用习惯,可视化部分依然采用主流的设计,即1个主图、2个副图的形式。主图用来显示K线图与均线图,副图根据需要可切换显示各种指标。我们以显示区域的左上角为坐标(0,0),右下角坐标为(x,y)建立一个矩形显示区域并划分3个子图区,如图2所示。3个子图区有各自的纵坐标和比例,但是3个图区的横坐标是同步的。
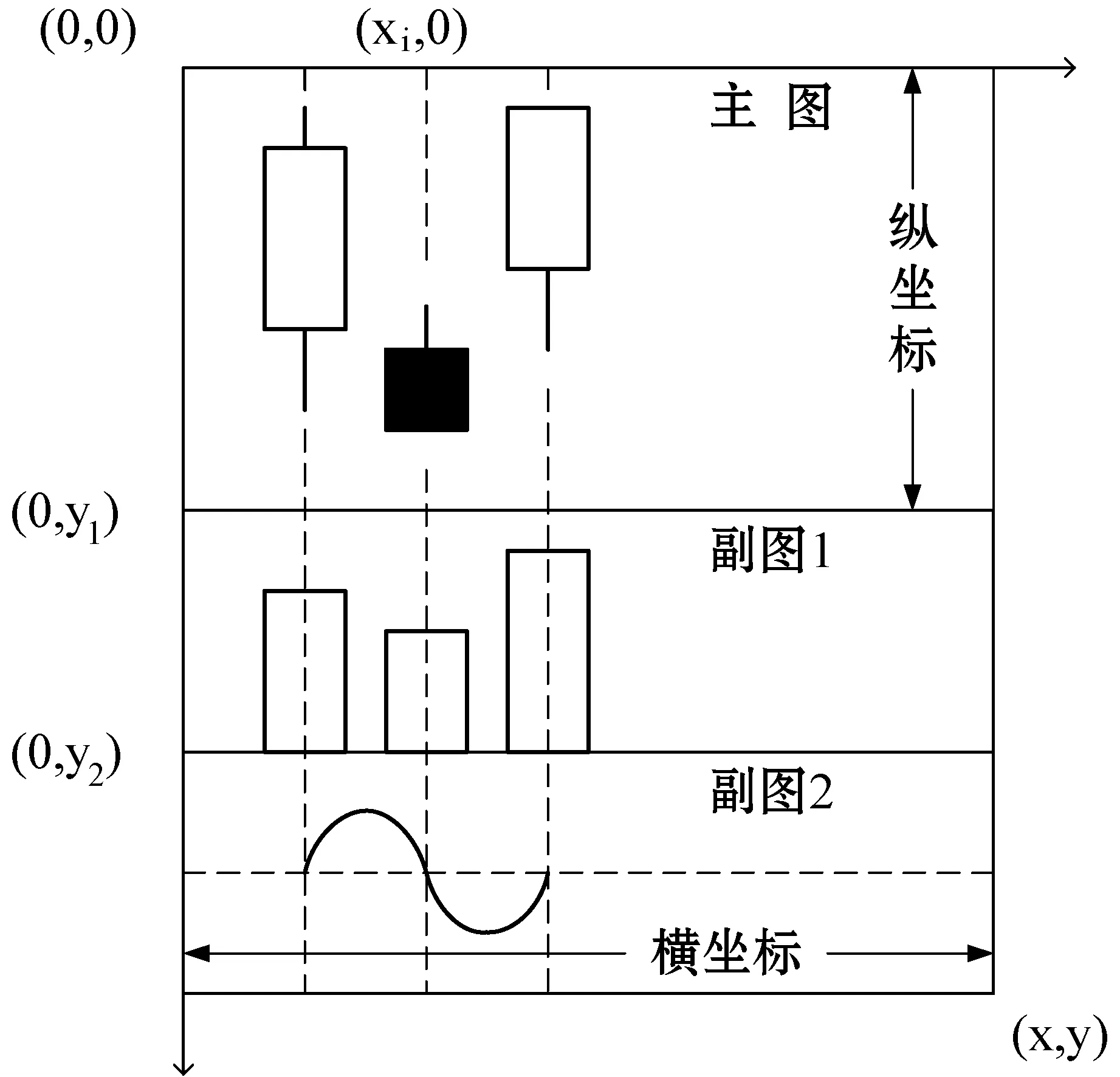
图2 可视化模块
设有一组金融时间序列数据B=[bar1,bar2,…,barN],若此时模块可显示的K线个数为N,即将B全部绘制到显示区域,需要以下几个步骤:
(1) 确立子图的坐标系。计算横纵坐标轴的上下界、比例和显示间隔。
横坐标:将子图的横坐标等分N+1份,可得到N条刻度,刻度的值由此位置所在K线的datetime确定。
主图纵坐标:首先将输入数据中四个维度[′open′,′high′,′low′,′close′]的所有数据看作一个集合,获取集合中的最大值和最小值作为主图纵坐标的上下界,并计算两者差值d。模块中预先设定了15个档位的坐标轴间隔,以及每个档位对应的数据取舍精度,如表1所示。
计算d与各间隔的比值,选择比值最接近10的一档作为主图纵坐标的间隔,表2使用5组具体数据以说明整个计算过程。
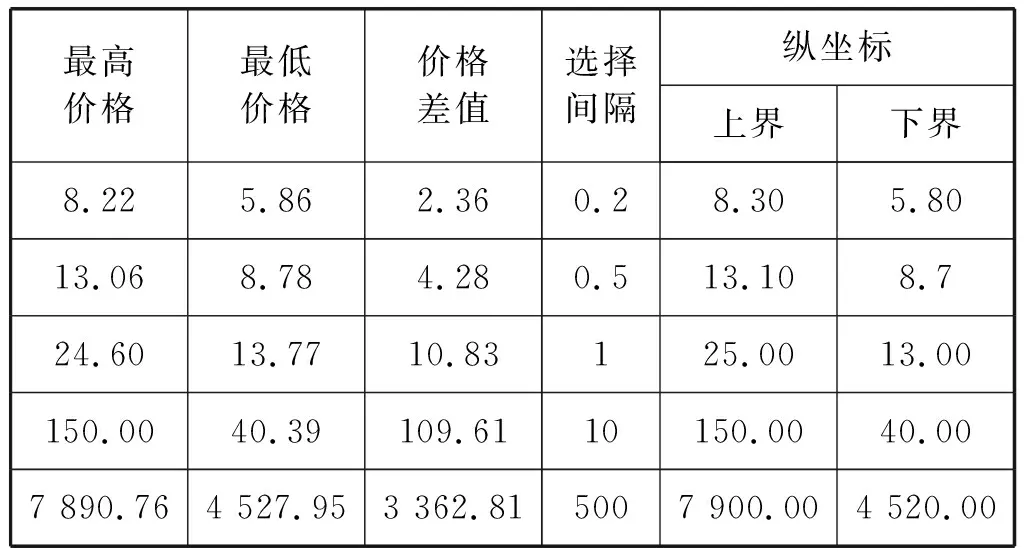
表2 坐标轴间隔及上下界计算示例
副图纵坐标:常见的副图图形主要有柱状图和折线图两种,在确立副图纵坐标时需要考虑输入数据的分布。一种情况是数据只分布在X轴一侧,即全为正数数据或全为负数数据,此时取数据绝对值的最大值计算比例即可。另一种情况是数据分布在X轴两侧,此时X轴需要绘制到区域中心,两侧比例取数据绝对值的最大值计算。
(2) 计算图形坐标。将之前确立的坐标系与显示区域(屏幕)的坐标系作转换,主要绘制的图形有K线图、柱状图和折线图。
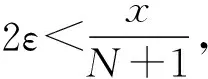
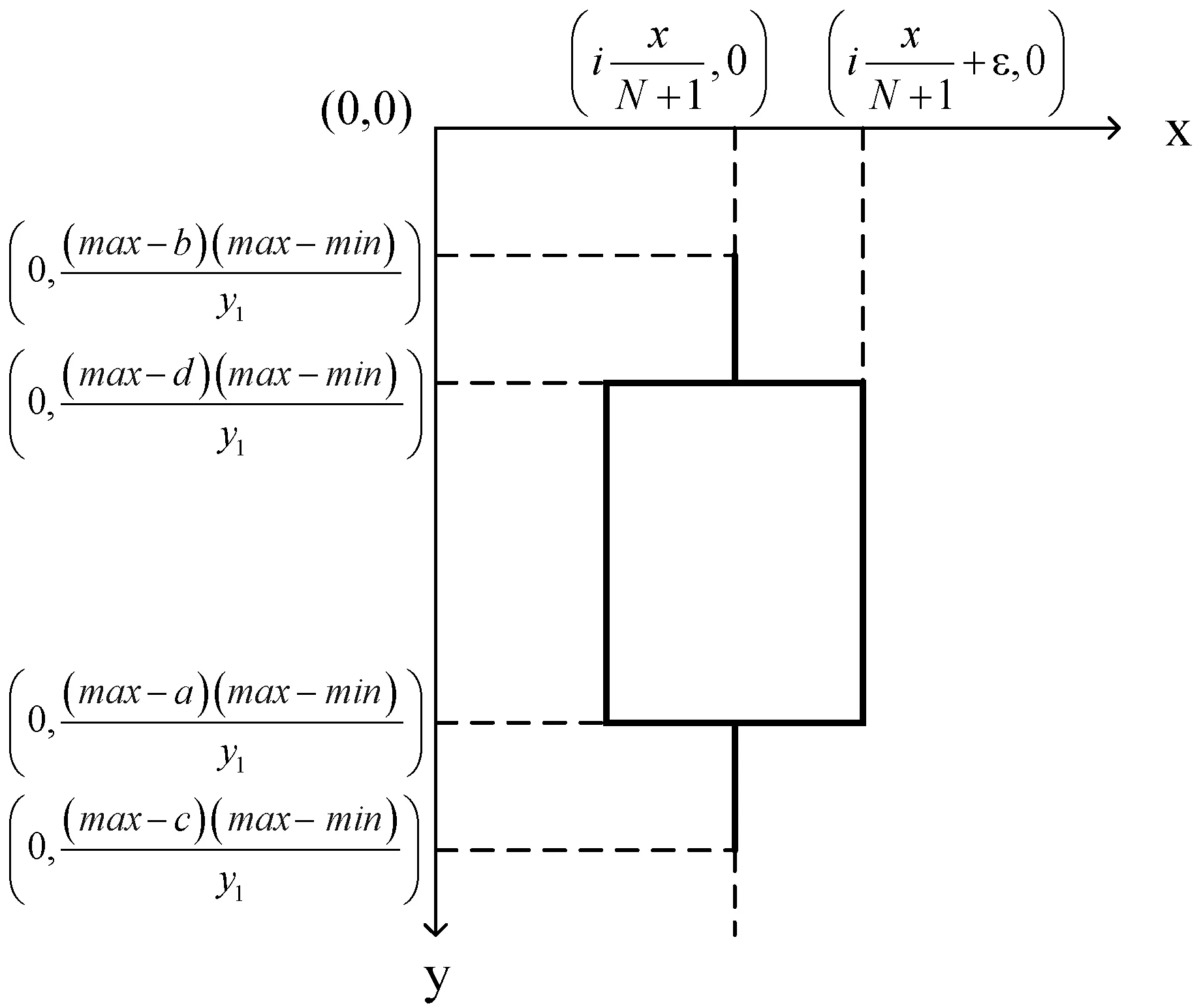
图3 K线图形坐标计算
2.2.2 功能模块计算模型
功能模块要实现的是数据图形在显示区域内的缩放、左右移动以及光标十字线等内容,本质上是接受操作输入,触发可视化模块的重绘机制,实现与用户交互的过程。
(1) 缩放与平移功能。框架内置两个参数,count用于控制显示区域可绘制图形的个数,start用于记录显示区域第一个绘制的图形的下标,2.2.1节中所描述的“设有一组金融时间序列数据B=[bar1,bar2,…,barN],将B全部绘制到显示区域”,就是对应于count=N,start=1的情况。数据B传入框架时不是直接通过可视化模块绘制,而是以参数count和start构成的“滑动窗口”在输入数据B上进行截取,然后再传入可视化模块进行绘制,过程如图4所示。改变count值就可以实现动态放大缩小的可视化效果,同理固定count值并改变start值就可以实现平移效果。
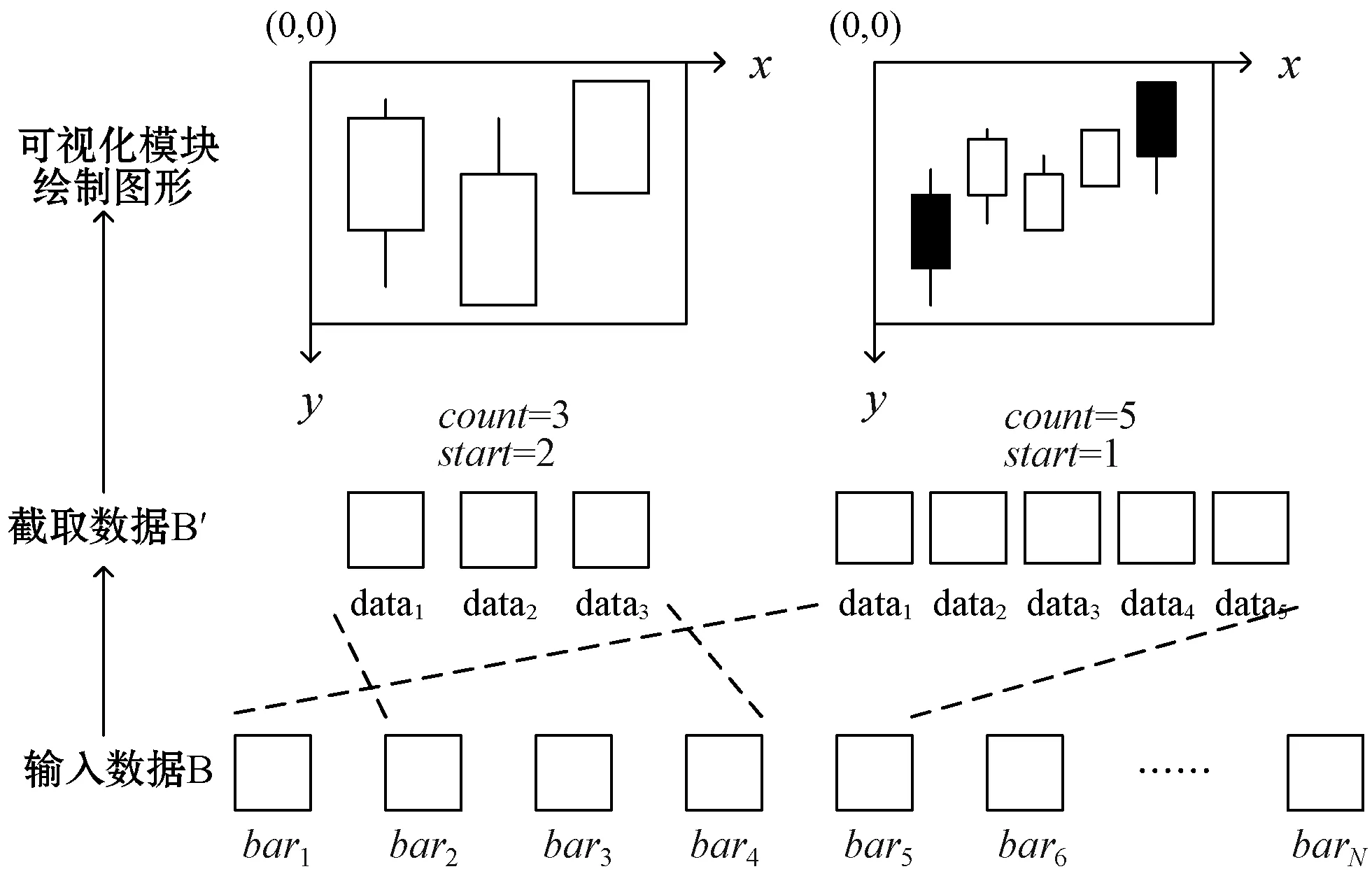
图4 缩放及平移功能
(2) 光标十字线功能。随着光标在显示区域中的移动,实时地以光标为中心绘制水平与垂直两条直线,并有一个浮动窗口显示光标所指处图形数据信息的功能。此功能有助于用户更精准快速地查看数据,核心在于通过光标的显示区域坐标计算出图形数据在“滑动窗口”中的下标,进而获取到数据,过程如图5所示。
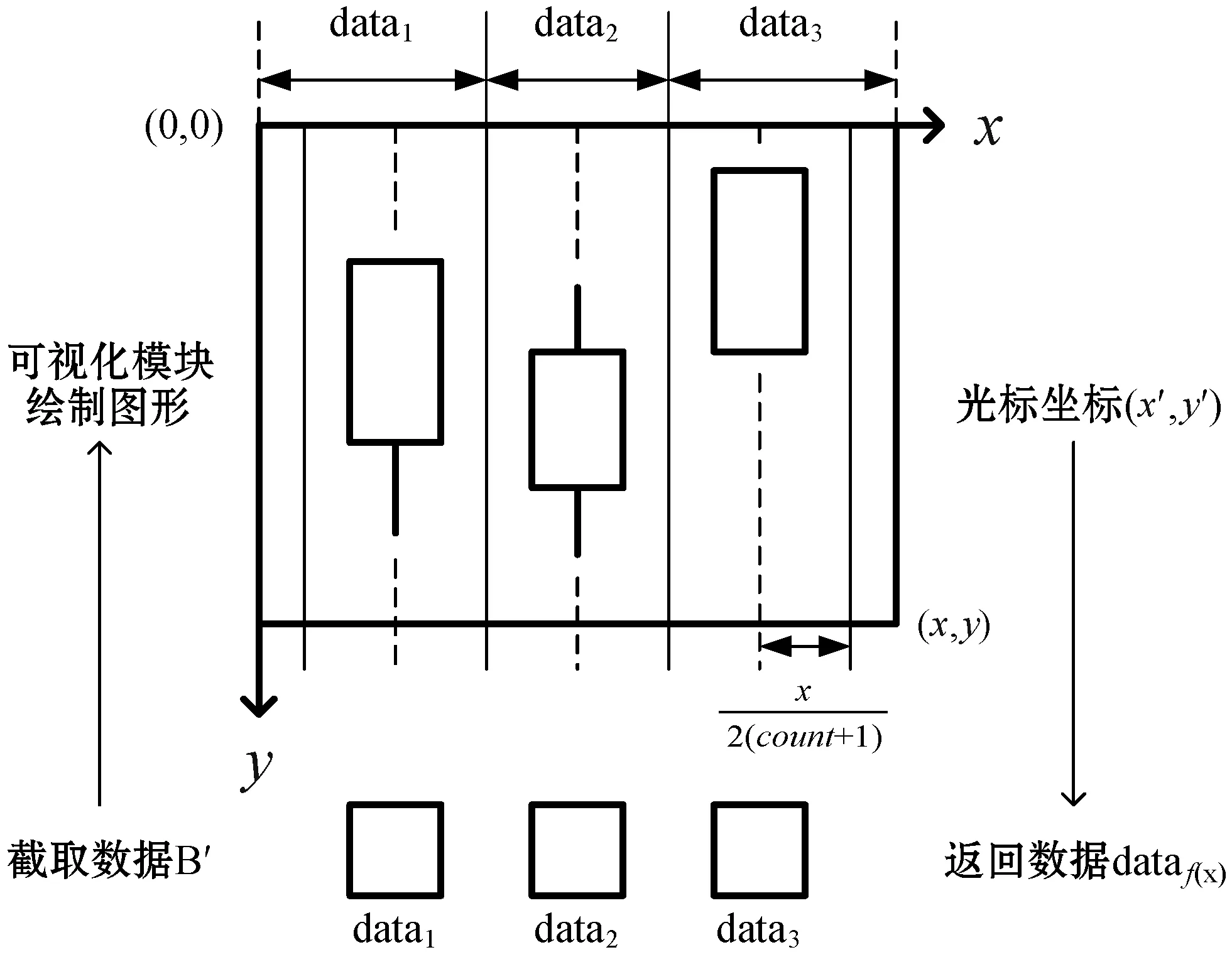
图5 光标获取数据
图中设光标的坐标值为(x′,y′),通过式(10)和式(11)可计算出截取数据的下标f(x′),进而获取数据。
(10)
(11)
2.3 中层引擎
中层引擎的功能是将程序中的各个组件,例如数据库接口、多线程等整合到一个对象中,便于上层应用的调用。下面对事件引擎和数据引擎的工作原理及流程做介绍。
2.3.1 事件引擎
事件引擎工作流程如图6所示。
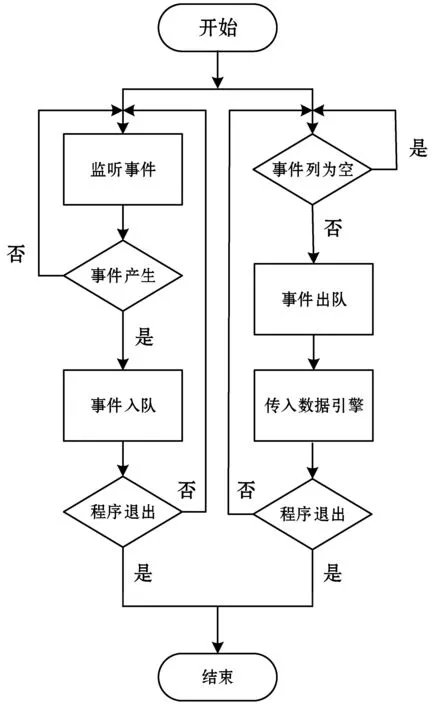
图6 事件引擎工作流程
事件引擎是整个框架的核心组件,也是大多数交易系统或回测引擎,甚至大多数交互程序的设计基础。事件引擎的设计基于事件驱动,事件驱动简单来说就是用户点什么按钮(即产生什么事件),计算机就执行什么操作(即调用什么函数)[9]。事件引擎主要完成的功能是收集事件对象(底层接口数据推送、用户输入)存入事件队列,并依次传入数据引擎作出相应处理。目前本框架中数据引擎承担了所有事件的处理工作,但仍把事件引擎和数据引擎的设计分隔开,是为以后框架更新、加入更多处理引擎做准备。
2.3.2 数据引擎
数据引擎主要负责维护数据在整个框架中的读写、传递与计算,包括计算模块、缓存模块、数据库接口模块三个子模块。主要完成以下两个工作:
(1) 底层接口数据推送的处理。底层接口以某个频率不断向中层引擎推送tick数据,由事件引擎传入数据引擎后,将tick数据保存到数据库并计数,直到tick数据的个数满足合成bar数据的要求,则计算模块将这一段tick数据取出合成bar数据。如底层接口以3秒的频率推送tick数据,显示模块使用1分钟级别的bar数据,则每20个tick数据为一组合成bar数据,合成方法如式(3)-式(9)所示。合成新的bar数据后,添加到缓存模块,以内置参数count和start重新截取显示数据传入显示模块并执行重绘、内置参数及截取方法如式(10)和式(11)所示。如底层接口传入了bar数据,则直接添加到缓存模块。
(2) 用户输入的处理。用户输入是指用户调用了功能模块,或改变内置参数count和start以放大、缩小、平移图形,或移动光标以获取光标所指处图形所包含的数据信息。如是前者,数据引擎将重新截取显示数据传入显示模块并执行重绘,如是后者,数据引擎将根据式(10)和式(11)计算出光标所指处对应的显示数据的下标,然后将数据传入可视化模块并执行重绘。
2.4 底层接口
底层接口是可视化框架的输入通道,金融时间序列数据由此传入中层引擎,且自定义指标和自定义计算模型通过配置文件的形式保存,并由数据引擎中的计算模块调用。
本框架的跨平台性也由底层接口体现。用户通过量化交易平台订阅数据,在平台的回调推送端调用底层接口,即可实现数据的持续可视化及交互,使用效果将在下一节与不同平台对接测试中展示。
3 量化交易平台对接测试
本节以实际工作为例,选取两个代表性的量化交易平台进行对接测试,以说明本框架的主要功能及用途。
3.1 自定义股票板块结构并对接商用平台
现有以下需求:取若干股票,自定义“煤炭”板块,根据所取股票数据合成新板块数据,并对接国内某量化交易平台,使新板块数据在回测时能实时更新显示。板块的计算模型如表3所示。

表3 自定义板块计算模型
第一步,订阅这若干只股票的行情数据,订阅后量化平台将在回调推送端自动传回行情数据。第二步,分析平台传回行情数据的结构及字段信息,编写计算模型,将平台数据转换成式(1)的形式。第三步,在平台的回调推送端直接调用数据传入接口。之后每当平台推送数据,就会触发事件引擎,通知数据引擎根据自定义的计算模型转换数据并存入数据库,并根据显示模块的参数,合成相应的bar数据及其他金融指标,最后由上层应用绘制图形,实现新版块数据的持续可视化与交互。
在测试中,同时定义了多个板块,涉及不同数量的股票数据,添加了键盘事件实现板块切换,并使用多个时间段回测观察性能表现,如表4所示。测试环境:Intel i7-8750H,内存16 GB,以下测试中框架均能正常工作,响应时间小于1秒,能够满足日常研究需要。自定义“煤炭”板块的效果图如图7所示。
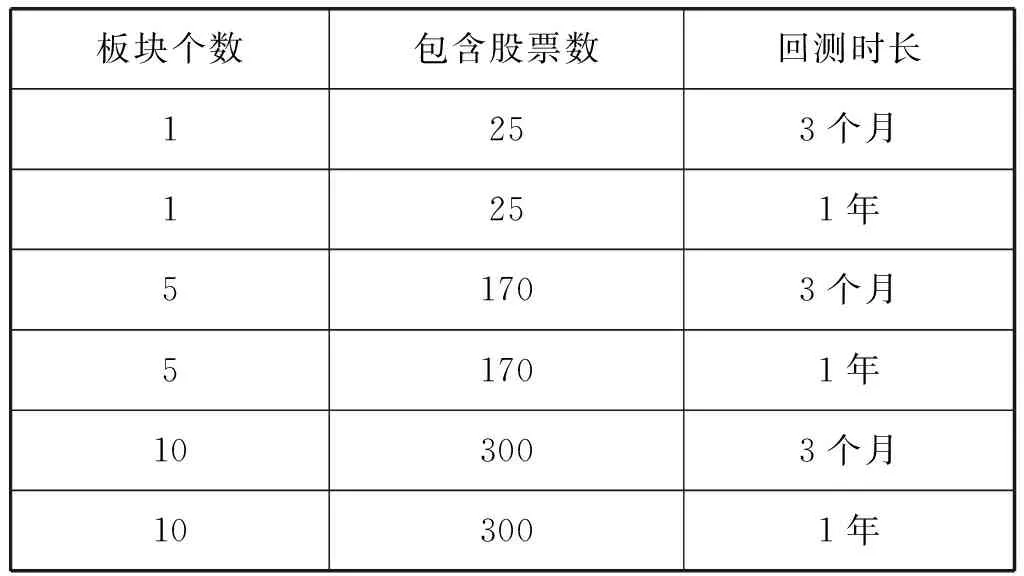
表4 平台对接测试
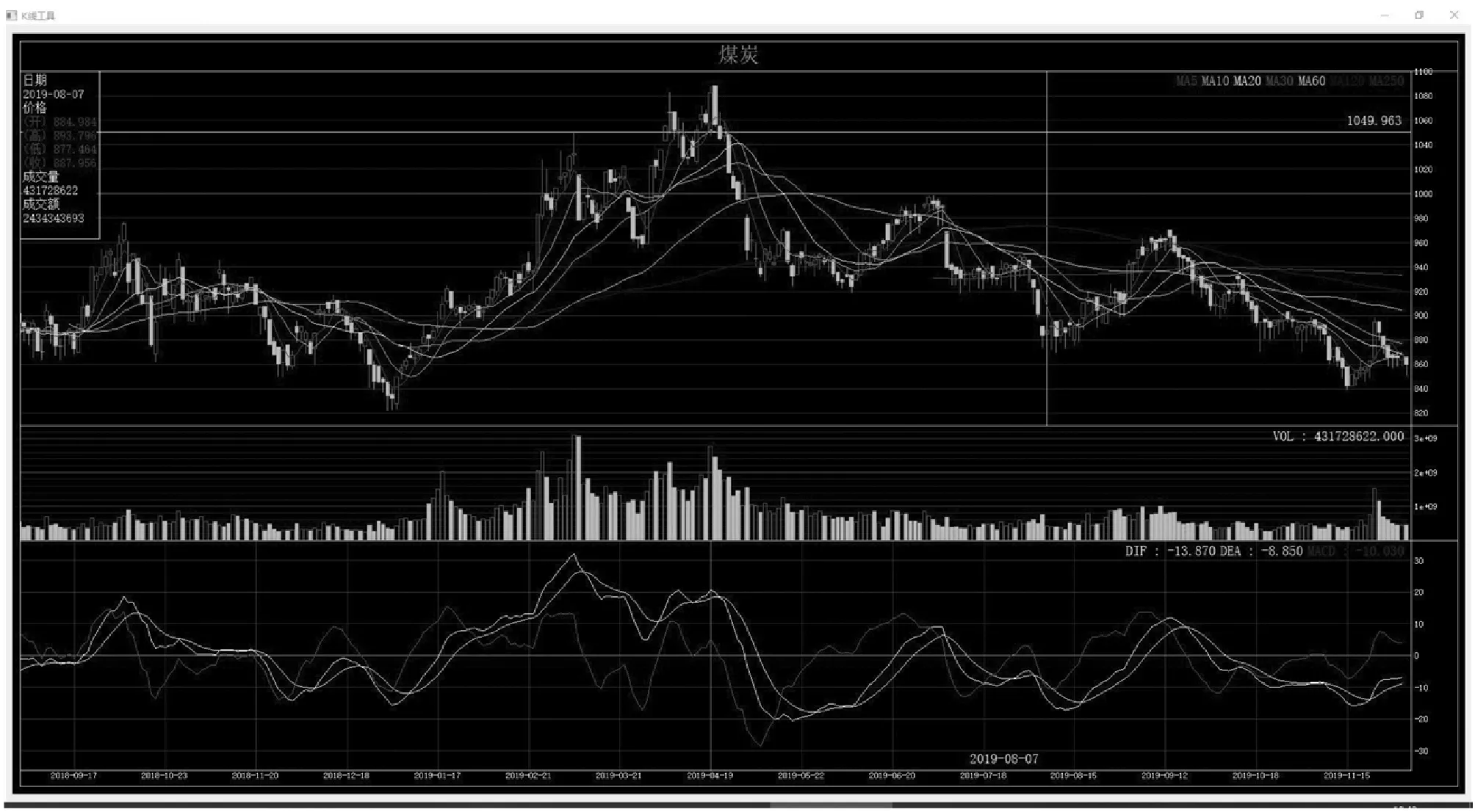
图7 自定义“煤炭”板块效果图
3.2 基于开源平台的二次开发
vn.py是基于Python语言的开源的量化交易系统,基于vn.py二次开发说明了可视化框架可以作为同类型软件UI设计的一部分,不局限于电脑端或手机端。在开发时,由于可视化框架的中层引擎部分就取自于vn.py,所以框架的上层应用可以很好地移植到vn.py中。软件界面如图8所示。
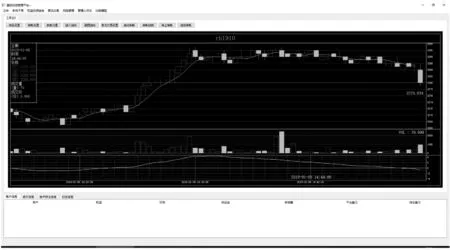
图8 基于vn.py二次开发的软件界面
4 结 语
本框架设计是为了满足量化交易研究过程中个性化定制数据的可视化需求,使用户可以更加注重策略和模型研究本身,直接调用接口,方便快捷,优势在于兼容目前市场上绝大多数的量化交易平台。
此次工作的不足之处:(1) 测试时板块数量与包含股票数量代入不够,未能测试框架所能承受数据量的上限。(2) 回测周期较短,不能说明框架在长时间运行时的稳定性。(3) 没有具体性能指标,只通过主观判断系统运行效果,不具有说服力。针对以上问题将在后期的研发工作中加大测试力度,完善框架的整体性能评价。
最后框架本身还有很多值得改进与扩充的部分,将在今后的工作研究中不断完善和更新。
猜你喜欢
童话世界(2019年17期)2019-07-04
童话世界(2018年17期)2018-07-30
商周刊(2017年22期)2017-11-09
河南电力(2015年5期)2015-06-08
电脑迷(2015年8期)2015-05-30
皖西学院学报(2015年5期)2015-02-28
中国卫生(2014年9期)2014-11-12
博客天下(2010年18期)2010-09-22
意林(2010年10期)2010-09-06
中国土地科学(2010年10期)2010-03-20
