
基于区块链的链下数据库高吞吐量数据可信保障方法
2023-07-04 02:52:02雷建云彭佳丽帖军孙翀王子珊
中南民族大学学报(自然科学版) 2023年4期
雷建云 ,彭佳丽 ,帖军 ,孙翀 *,王子珊
(1 中南民族大学 计算机科学学院,武汉 430074; 2 中南民族大学 湖北省制造企业智能管理工程技术研究中心,武汉 430074; 3 中南民族大学 农业区块链与智能管理湖北省工程研究中心,武汉 430074)
随着区块链[1-3]技术日益兴起,区块链应用不只局限于数据溯源[4-6],在数据防篡改[7-10]方面也提供了强大的保证.区块链本质上是一个去中心化的分布式账本,账本内存储的数据持续性增加,并且不可修改.此种防篡改特性被应用于多个安全领域,给信息共享、物联网、加密数字货币等领域提供更多的可能.从数据库角度看区块链,传统区块链在保证去中心化需求的同时占用大量空间,导致吞吐量降低.而区块链数据管理方向是目前研究的热点,区块链结合数据库的系统有很大的优势,如BigchainDB[11]、FalconDB[12]、BlockchainDB[13]等都致力于将成熟的数据库技术应用于区块链领域.为了更加高效、安全地存储海量数据,本文提出一种区块链结合数据库的架构,增加区块链系统的吞吐量,链下数据库存储全部的数据,链上存储摘要值.这样的结构既提高了数据库数据的安全性,又减小了区块链的存储压力.
区块链适合云存储[14]环境下日志型数据的存储,不适合数据库数据大量更新的应用场景.针对数据库频繁更新的场景,区块链无法对数据库变更的数据进行保护.为克服区块链无法保障变更数据安全性的弊端,本文提出利用事务日志存储数据变更状态的功能,将日志的消息摘要值(为方便说明,本文消息摘要值采用SHA256计算方法)保存至区块链中,以保障数据库的安全性.
本文的主要贡献如下:
(1)提出一种区块链与链下数据库结合的架构.将数据存储在数据库内,数据摘要值存储在区块链上,增加系统吞吐量,减小区块链存储压力.
(2)提出一种数据保障方法以保障数据库变更数据的安全性.针对数据库频繁更新的场景,将事务日志消息摘要值存储到区块链上,验证事务日志是否发生篡改,以此推导数据库数据是正常更新还是被恶意篡改.若是恶意篡改可通过本方法恢复正常数据,提高了系统的安全性.
1 相关工作
区块链在保证去中心化需求的同时使得区块链交易吞吐量低,提高交易吞吐量是提高区块链性能的关键.LI 等[15]提出一种可扩展的分散的Conflux区块链系统,该系统的共识协议可根据Conflux账本结构中的拓扑自适应地为块分配权重,从而实现较高的吞吐量.SATIJA等[16]提出Blockene区块链系统,该系统通过数量级降低成员节点的资源使用,只需智能手机参与块验证和共识,提供高吞吐量和规模.HARI等[17]提出一种高吞吐量、低延迟、确定性的确认机制ACCEL,用于加速比特币的块确认机制.
区块链本身具有防篡改特性,可将该特性运用于其他系统上,保障系统数据的安全性.李瑾等[18]将区块链与IPFS结合以扩展电能量数据区块链的存储容量,并通过链上保存IPFS返回的哈希值及查询属性验证数据是否被篡改,但目前处于实验阶段,能否推广应用仍需进一步测试与验证.隋源等[19]将Hyperledger Fabric与HBase相结合,利用区块链防篡改特点,提出一种可验证查询方法,但该系统只能保障连续存入的数据的安全性,没有探讨数据库持续更新情况的数据安全性.李莹等[14]提出一个提高区块链的三层架构模型TBchain,结合云存储实现区块链的扩展,并运用ETag值验证云存储中的内容是否发生变化,但三层架构的区块链TBChain的安全性不及传统区块链的安全性.
事务日志文件(Transaction Log File)是保证数据库安全性中较重要的一个文件,它记录了数据库数据的更新情况,每一次数据库更新数据都会将变更记录存储在事务日志文件中.若数据库发生异常篡改,则可通过事务日志文件恢复到之前某个安全时刻的状态.近年来,学者们对事务日志数据安全可信性保证进行了大量的研究.陈驰等[20]提出一种新型事务恢复日志模型,采用抽象状态机描述日志生成规则和入侵响应模型,可仅恢复受恶意事务影响的部分而无需回滚所有事务, 从而提高数据库系统的生存性.范晓丹等[21]将事务日志分析应用于医疗信息安全方面,通过对事务日志文件的跟踪与分析,明确事故原因,找回丢失的数据.TALIUS[22]等提出一个可用于用户和应用程序错误时恢复的方案,并使用事务日志及时回退数据库.上述三种方案通过对事务日志的运用来恢复被篡改的数据,但没有提出如何甄别更新的数据库数据是正常更新还是异常篡改的解决方案.因此,本文提出一个运用区块链和事务日志结合的数据保障方法解决此问题,以更加安全的方式存储数据库数据.
2 数据保障方法
事务日志记录数据库数据变更的状态,数据篡改可通过事务日志进行恢复数据,但仅通过事务日志无法得知数据是正常更新还是异常篡改且无法解决越过事务日志的篡改问题.为解决相关问题,本文采用区块链加外源数据库架构,并运用三个算法保障数据库数据从t1到t2时间段的安全性,算法在时间轴上的分布如图1所示.首先,t1到t2时间段,运用数据存储更新算法将数据按需更新至数据库或区块链上;其次,t2到t3时间段,运用事务日志校验算法验证t1到t2时间段数据库数据是否被篡改并是何种篡改;最后,t3到t4时间段,经过链下数据恢复算法将数据库恢复到安全时的状态.

图1 算法时间轴分布Fig.1 Distribution of algorithm time axis
2.1 Hyperledger Fabric+链下数据库架构
Hyperledger Fabric[23]是IBM提出的一种联盟链,具有高度模块化和可扩展性,同时它具有很好的保密性、可伸缩性和灵活性.它在实际应用场景中具有较高的吞吐量,Fabric是第一个应用于分布式应用程序的可扩展区块链系统,也是第一个运用通用编程语言编写的分布式应用程序的区块链系统,不需要依赖于本地加密货币.但其吞吐量仍不能满足当前应用的需求,因此加上外源数据库为区块链提供吞吐量.
区块链+数据库架构如图2所示,链上是Hyperledger Fabric区块链网络,其包含peer节点和order节点.peer节点进行背书、记账,并存储区块链所有交易数据,本文运用peer节点存储事务日志消息摘要值,order节点进行交易排序、打包数据形成区块,保障区块的共识.链下是一个MySQL数据库,保存所有数据,本文运用数据库存储交易数据data、事务日志logs、t1时刻数据副本t1backupFile.

图2 区块链+数据库架构Fig.2 Architecture of blockchain + database
2.2 数据存储更新算法
算法1为将不同类型数据进行存储更新过程的步骤.算法1的1~3行即在t1时刻,将t1时刻数据副本导出保存到数据库中(为方便说明,本文t1时刻数据副本不会被篡改);4~6行即在t1到t2时间段,用户将交易数据运用updata方法更新到数据库;7~9行即在t1到t2时间段,将产生的所有事务日志分别计算出摘要值上链.
相比于单一的存储方法,通过数据存储更新算法可以达到将多种重要数据存储到指定存储空间的效果.
数据存储更新算法如算法1所示.

2.3 事务日志校验算法
算法2为运用事务日志进行验证过程的步骤.输入为t1时刻的数据副本,t1到t2时间段产生的所有事务日志和实际导出的t2时刻的数据副本,输出为验证结果.算法2的1~3行:依次计算链下t1到t2时间段事务日志文件摘要值;通过GetState方法依次获取链上t1到t2时间段事务日志文件摘要值;运用t1时刻的数据副本和t1到t2时间段产生的所有事务日志计算出t2时刻的数据副本.4、5行判断是否有被记录在事务日志文件上的恶意操作;6、7行判断是否有越过事务日志文件对数据库进行篡改的恶意操作;第9行返回数据库数据无篡改.
事务日志校验算法不仅可验证出数据库是否发生篡改,而且可验证出是事务日志篡改还是越过事务日志的篡改.
事务日志校验算法如算法2所示.

在t2时刻,验证t1到t2时间段数据库产生的更新是正常更改还是恶意篡改,算法2的具体验证步骤(图3)如下.

图3 数据验证示意图Fig.3 Diagram of data verification
(1)按产生顺序计算出t1到t2时间段每个事务日志文件的消息摘要值,并依次与链上所存储的事务日志文件的消息摘要值进行对比.若某对事务日志摘要值不等,则数据被恶意篡改,且恶意操作被记录在此事务日志文件上,而这一事务日志文件之前的事务日志文件没被篡改;若摘要值相等,则t1到t2时间段可能没有恶意操作,进入第二个验证步骤;
(2)通过t1时刻的数据副本和t1到t2时刻所有的事务日志文件计算出t2时刻的数据库数据副本,再将计算出的t2时刻的数据副本与t2时刻数据库的实际数据副本进行对比.若两个数据副本所记录的数据库操作不等则t1到t2时刻的数据被篡改,且恶意操作越过事务日志文件对数据库进行篡改;若两个数据副本所记录的操作一样,则在t1到t2的时间段数据库所有数据没被恶意篡改过.
2.4 链下数据恢复算法
在t2时刻已运用算法2检测出数据被异常篡改,此时需要将数据恢复到正常状态.算法3说明了数据恢复过程的步骤.输入为运行算法2所产生的验证结果、t1时刻数据副本和t1到t2时间段产生的事务日志,输出为数据恢复结果.算法3的1~3行表示验证结果为事务日志篡改,则通过t1时刻数据副本和部分事务日志文件进行恢复数据库,并返回成功;4~6行表示验证结果为越过事务日志的篡改,则通过t1时刻数据副本和所有事务日志文件进行恢复,并返回成功.
传统的数据库恢复方法是针对已知的某个事务日志篡改,直接运用事务日志进行回滚从而恢复到数据库正常状态,而本文的链下数据恢复算法不仅针对事务日志篡改进行数据恢复,也可针对越过事务日志的篡改进行数据恢复.
链下数据恢复算法如算法3所示.

t2时刻验证时出现两种数据异常篡改的情况,运用算法3进行恢复的具体步骤(图4)如下.
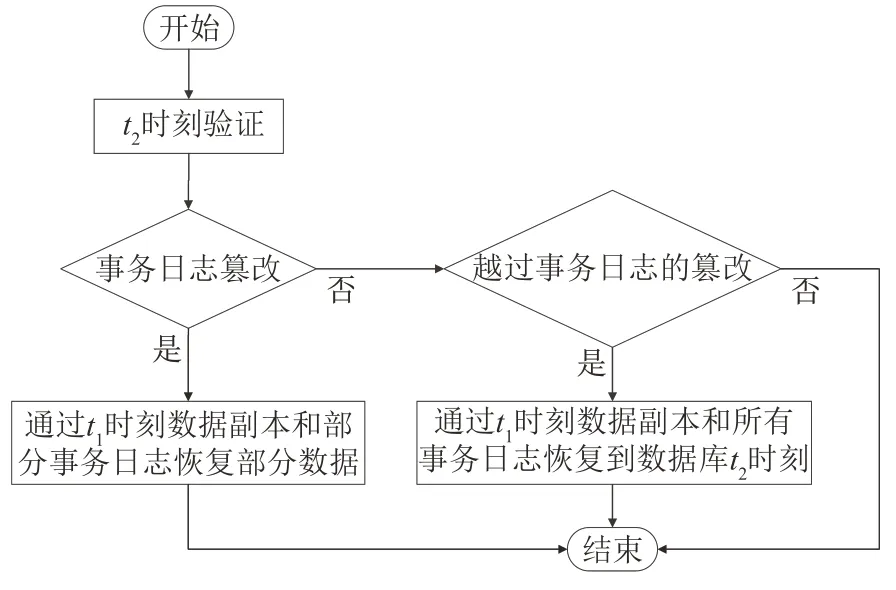
图4 数据恢复示意图Fig.4 Diagram of data recovery
(1)事务日志篡改.t2时刻,已验证得出为事务日志篡改,则可通过t1时刻的数据副本和部分未被篡改的事务日志文件进行数据的恢复.t2时刻,首先通过t1时刻数据副本将数据库恢复到t1时刻的状态,其次找到已篡改的某一事务日志之前的所有未被篡改的事务日志,最后运用事务日志文件通过基于位置的恢复方式将数据库恢复到已篡改事务日志之前的数据库正确状态;
(2)越过事务日志的篡改.t2时刻,已验证得出为越过事务日志的篡改,则可通过t1时刻的数据副本和t1到t2时间段产生的所有事务日志文件恢复到t2时刻的数据库正确状态.t2时刻,首先通过t1时刻数据副本将数据库恢复到t1时刻的状态,其次找到t1至t2时间段的所有事务日志文件,最后运用事务日志文件通过基于位置的恢复方式将数据库恢复到t2时刻的数据库正确状态.
3 实验与分析
3.1 数据集及实验环境
本实验数据集来自于实验室的智慧农业农田小气候项目的数据库的environment表,environment表有三个属性即环境序号environment_id(int)、温度temperature(int)、降雨量rainfall(int),每条数据12字节左右.本实验使用KB级、MB级、GB级的数据集进行测试,分别包含1 KB、2 KB、1 MB、2 MB、1 GB、2 GB的environment表的信息.
本实验底层区块链采用Hyperledger Fabric搭建2个组织和1个order点,每个组织2个peer结点,链下运用MySQL数据库操作数据,完成基于区块链的链下数据库高吞吐量的数据可信保障的模拟实验.链下开发环境为Ubuntu16.04操作系统、内存12 G、硬盘容量50 G、Golang版本为go1.10.3 linux/amd64、Hyperledger Fabric版本为Hyperledger Fabric release-1.4.3.为验证基于区块链的数据可信保障方法的有效性,实验模拟篡改操作被记录到日志文件上和越过日志文件篡改数据这两种实际应用中出现的数据篡改情况,并记录算法消耗时间.
3.2 正常更新实验
实验模拟正常数据更新情况,运用1 KB数据进行实验的具体操作如下.
首先,实验运用数据存储更新算法将数据按分类进行存储.在MySQL数据库内创建environment表并插入多条数据,此时为t1时刻,将此时MySQL数据库备份文件导出并命名为:cpy.sql.再对environment表插入50条数据,此50条正常操作会被记录到事务日志mysql-bin1.000001上,将此日志文件导出并计算消息摘要值为5aa85f27814680fc6a5acd922505178 6d8676a25bf255aec9d97518b75d3a5b5进行上链.随后回滚产生新的日志文件mysql-bin2.000002,再对environment表进行插入50条数据的操作,将此日志文件导出并计算消息摘要值为e5bda9e018f894b1d1 0f91bdb600744f5fa4b68a8f67de1db207701312623afe进行上链,操作完成的时刻为t2时刻.
其次,实验运用事务日志校验算法验证t1到t2时间段数据的安全性.t2时刻,将日志导出并命名为mysql-new1.000001、mysql-new2.000002,计算其摘要值与链上的mysql-bin1.000001、mysql-bin2.000002摘要值一样,则进行计算验证步骤.运用cpy.sql和mysql-bin1.000001、mysql-bin2.000002文件计算出t2时刻数据库备份文件内容,与实际导出的t2时刻数据库备份文件比较,结果一样,则数据库数据被正常更新.
3.3 篡改实验
3.3.1 篡改数据操作被记录在事务日志文件上
实验模拟篡改数据操作被记录在事务日志文件上的情况,分别运用1 KB、2 KB、1 MB、2 MB、1 GB、2 GB的数据进行篡改实验.实验运用1 KB数据进行篡改实验的具体操作如下.
首先,实验运用数据存储更新算法将数据按分类进行存储.在MySQL数据库内创建environment表并插入多条数据,此时为t1时刻,将此时MySQL数据库备份文件导出并命名为:cpy1.sql.再对environment表插入50条数据,此50条正常操作会被记录到事务日志mysql-bin3.000003上,将此日志文件导出并计算消息摘要值为d8e94237ec6cd1fbf611054273b2 9f20cc2797538875893112299885e7acb9ed进行上链.随后模拟篡改操作即篡改一条数据:update environment set temperature =‘26’ where environment_id=1;此操作被记录到日志文件mysqlbin3.000003内.随后回滚产生新的日志文件mysqlbin4.000004,再对environment表插入50条数据,将此时日志文件导出并计算消息摘要值为c201044e7 78b622b8922b44087a08a648bf17427ee93d1d96300b b6a8e59077d进行上链,操作完成的时刻为t2时刻.
其次,实验运用事务日志校验算法验证t1到t2时间段数据的安全性.t2时刻,将模拟的被篡改的日志导出并命名为mysql-tamper3.000003,计算其摘要值为f8f6def654ac84bf058b8e2ddadd9d7ef81277af69f 011dbcdcdc6460ac640ed,此值与链上的mysqlbin3.000003摘要值不一样,则数据库数据被篡改,且该篡改操作被记录在mysql-tamper3.000003上.
最后,实验运用链下数据恢复算法恢复数据.运用t1时刻备份文件cpy1.sql直接恢复数据库到t1时刻的安全状态.
实验运用2 KB、1 MB、2 MB、1 GB、2 GB的数据进行的篡改实验与1 KB数据进行的篡改实验操作大体类似.
图5为KB级、MB级、GB级的数据运用全数据更新算法所消耗的时间折线图.由图5可见:随着数量级的增加,算法消耗的时间越多,这是由于数据存储更新算法需要将大量数据存入数据库,数量级越大,存入数据库耗时越多.
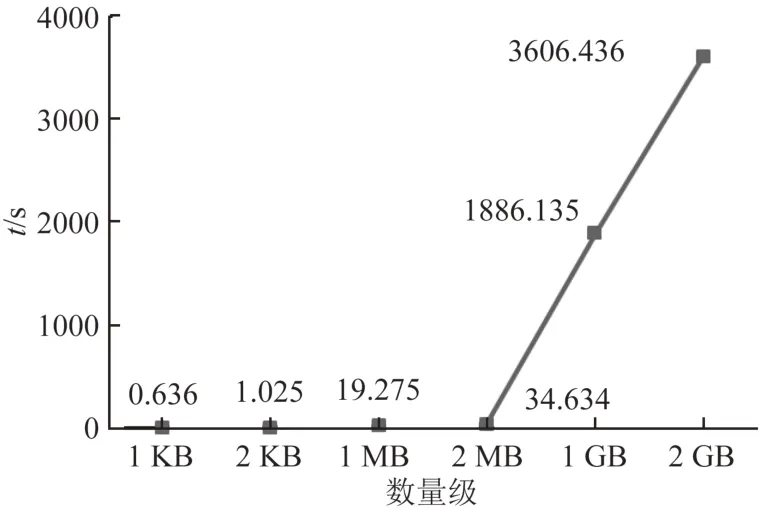
图5 数据存储更新算法时间消耗Fig.5 Time consumption of data store update algorithm
图6为KB级、MB级、GB级的数据运用事务日志校验算法所消耗的时间折线图.由图6可见:随着数量级的增加,算法消耗的时间波动不大,这是由于事务日志校验算法只需获取事务日志的链上摘要值,而时间消耗与数量级大小无关.
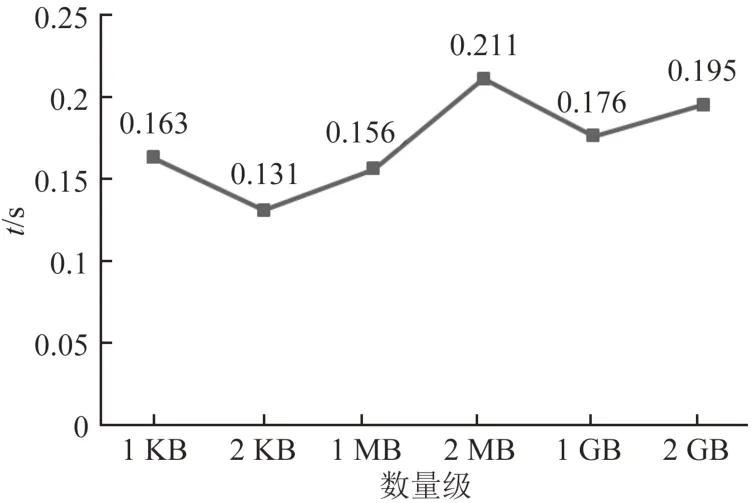
图6 事务日志校验算法时间消耗Fig.6 Time consumption of transaction log validation algorithm
图7为KB级、MB级、GB级的数据运用链下数据恢复算法所消耗的时间折线图.由图7可见:随着数量级的增加,算法消耗的时间越多,这是由于数据量越大,运用备份文件和事务日志文件恢复数据耗时越多.
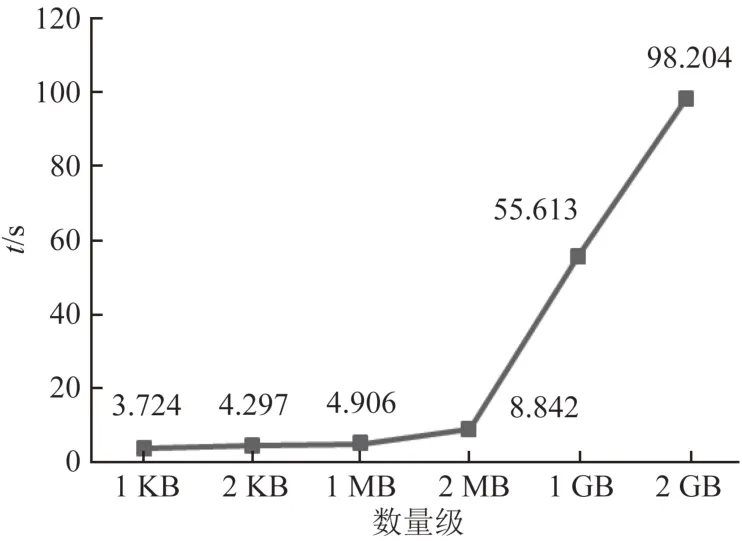
图7 链下数据恢复算法时间消耗Fig.7 Time consumption of off-chain data recovery algorithm
3.3.2 越过事务日志文件篡改数据
实验模拟越过事务日志的篡改,分别运用1 KB、2 KB、1 MB、2 MB、1 GB、2 GB的数据进行篡改实验.实验运用1 KB数据进行篡改实验的具体操作如下.
首先,运用数据存储更新算法在MySQL数据库内创建environment表并插入多条数据,此时为t1时刻,将此时MySQL数据库备份文件导出并命名为:cpy2.sql.再对environment表插入50条数据,此50条正常操作会被记录到事务日志mysql-bin5.000005上,将此日志文件导出并计算消息摘要值为5445a8998bcd2a050b84b5ed538f8cb407daf3857bef18 f40af864eeffbf8653进行上链.随后关闭日志审计功能,对数据库数据模拟进行恶意篡改的操作即篡改一条数据:delete from environment where environment_id=100;此操作不会被记录到日志文件mysqlbin5.000005内.随后开启日志审计功能产生新的日志文件mysql-bin6.000006,再对environment表插入50条数据,将此时mysql-bin6.000006计算摘要值为d519189ab34fdebdf56fcdbbe5b345b1eb4d23e437e4a7 547856b90b2d20e5c0并上链,操作完成的时刻为t2时刻.
其次,实验运用事务日志校验算法验证t1到t2时间段数据的安全性.t2时刻,将日志mysqlbin5.000005、mysql-bin6.000006导出并计算其摘要值,此值与链上的mysql-bin5.000005、mysqlbin6.000006摘要值一样,则进行计算验证步骤.运用cpy2.sql和mysql-bin5.000005、mysql-bin6.000006文件计算出t2时刻数据库备份文件内容,与实际导出的t2时刻数据库备份文件cpy3.sql比较,结果不一样,则数据库被篡改了.
最后,实验运用t1时刻备份文件cpy2.sql和mysql-bin5.000005、mysql-bin6.000006恢复数据库到t2时刻的安全状态.
实验运用2 KB、1 MB、2 MB、1 GB、2 GB的数据进行的篡改实验与 1KB数据进行的篡改实验操作大体类似.
图8为KB级、MB级、GB级的数据运用数据存储更新算法所消耗的时间折线图.由图8可见:随着数量级的增加,算法消耗的时间越多,这是由于数据存储更新算法需要将大量数据存入数据库,数量级越大,存入数据库耗时越多.
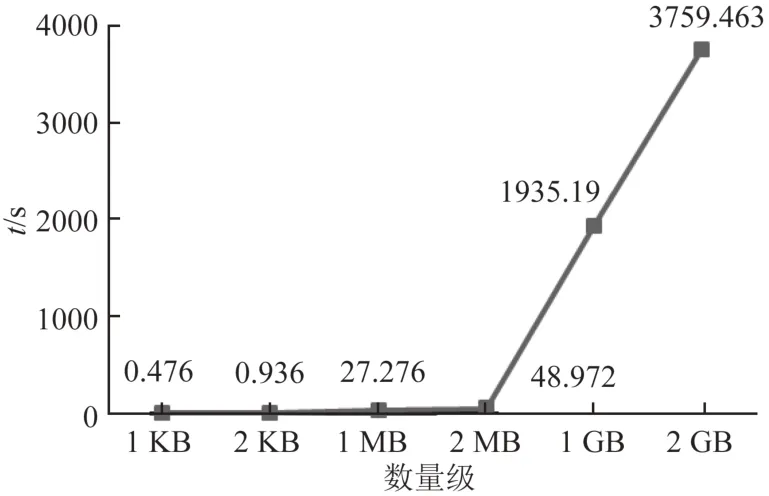
图8 数据存储更新算法时间消耗Fig.8 Time consumption of data store update algorithm
图9为KB级、MB级、GB级的数据运用事务日志校验算法所消耗的时间折线图.由图9可见:随着数量级的增加,算法消耗的时间波动不大,这主要是因为事务日志校验算法只需获取事务日志的链上摘要值,而时间消耗与数量级大小无关.
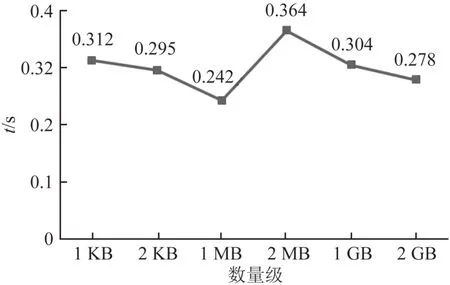
图9 事务日志校验算法时间消耗Fig.9 Time consumption of transaction log validation algorithm
图10为KB级、MB级、GB级的数据运用链下数据恢复算法所消耗的时间折线图.由图10可见:随着数量级的增加,算法消耗的时间越多,这主要是因为数据量越大,运用备份文件和事务日志文件恢复数据耗时越多.
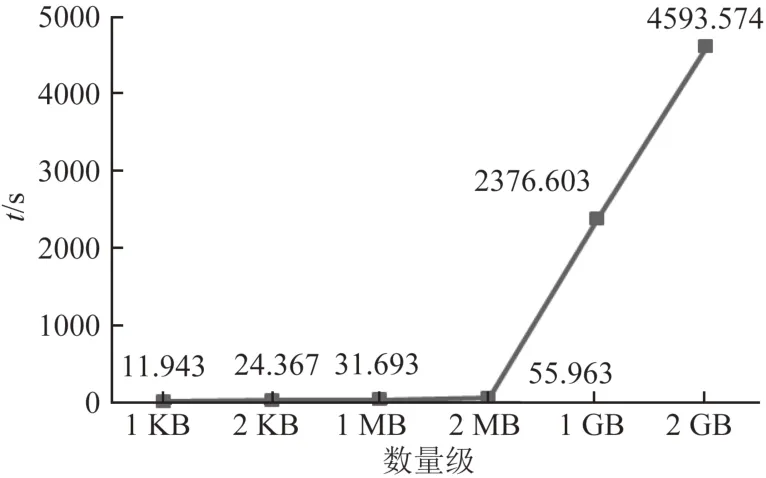
图10 链下数据恢复算法时间消耗Fig.10 Time consumption of off-chain data recovery algorithm
4 结语
本文提出一种区块链结合数据库的架构,该架构将数据存储在数据库内,数据摘要值存储在区块链上,提高了区块链的可扩展性,并使区块链系统具有更强的吞吐能力.在此架构基础上,提出包含三种算法的数据保障方法,将区块链技术和数据库日志技术应用于解决数据库频繁更新所存在的数据被篡改的安全问题中.通过Hyperledger Fabric和MySQL的架构模拟篡改实验,结果表明该方法使频繁更新的数据库具有更高的吞吐量和更强的防篡改能力.本文通过手工的方式利用t1时刻数据副本和日志文件计算出t2时刻的数据副本,一旦数据量过大,这个过程消耗的代价便急剧升高,未来可以尝试简化这个过程以减少代价.
猜你喜欢
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
河南水利年鉴(2020年0期)2020-06-09 05:43:44
计算机系统应用(2019年2期)2019-04-10 05:08:46
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
计算机与生活(2016年11期)2016-11-22 02:07:32
计算机工程与科学(2015年3期)2015-03-27 07:46:15
电子设计工程(2014年19期)2014-02-27 12:00:42
