
基于数据治理的脑血管专病数据库建设实践*
2023-06-30 02:12:44连万民段文舟张冬平王博涵
医学信息学杂志 2023年5期
连万民 段文舟 张冬平 王博涵
(广东省第二人民医院 广州 510317) (广州知汇云科技有限公司 广州 510000)
1 引言
近年来以电子病历为核心的医疗机构信息化建设得到大力推动,“互联网 + 医疗健康”应用日渐广泛,医院诊疗数据、检查检验数据、健康人群体检数据、队列随访数据、药物使用数据、病理和影像数据、基因组学等健康大数据快速增长,推动医疗健康领域进入“大数据”时代[1]。基于真实世界的大数据研究分析成为当下研究热点。然而,不少医院院内虽然具有良好的信息化基础,但是数据质量不高、数据开发难度较大,缺乏统一数据开发平台[2],导致医务人员在推动疾病诊断、治疗、预后的研究和发展方面缺乏相应数据及技术支持,医院积累的宝贵经验无法得到高效分享,医疗证据不能得到合理应用。
脑血管病是全球性公共卫生问题。2019年全球疾病负担课题组(Global Burden of Disease 2019,GBD 2019)数据显示,脑血管病是204个国家和地区居民死亡和过早死亡的主要原因之一[3]。根据国家统计局数据,近年来脑血管病死亡人数一直处于高位,2017—2021年城市、农村脑血管病死亡人数占总死亡人数的平均比重高达20.86%和23.92%[4],且有逐年升高趋势;与此同时,随着我国人口老龄化不断加剧,到2022年我国65岁以上人口比例已达14.86%,这一疾病负担将日趋严重[5]。脑血管病以其发病率高、复发率高和致残率高的特点成为严重阻碍我国社会经济发展的重大疾病[6]。脑血管病的治疗需要一体化、全链条干预,一般急性期在神经内科治疗,病情平稳后即可进入康复理疗科治疗。但是,医院信息系统常存在数据资源无法共享以及多系统、多业务存储底层数据结构不统一等问题[7],导致神经内科与其他相关科室之间的临床数据处于信息孤岛状态,无法充分挖掘其价值。
发达国家围绕临床与科研已经广泛开展脑血管病相关数据库建设与应用研究。例如,欧洲建立卒中数据库对急性脑血管病患者的人口统计学特征、危险因素、卒中严重程度和治疗效果进行研究[8],美国建立心房纤颤导管消融术后30天急性脑血管意外发生率和预测因素研究数据库[9],均取得较好效果。因此基于全院数据治理框架,建设脑血管专病科研数据库,利用数据挖掘与人工智能等技术掌握不同病因脑血管病发生、发展和转归特点,最终阐明疾病发病机制进而辅助临床决策,对延缓病程进展、准确预测并发症发生及死亡风险、早期治疗、干预等具有临床和社会意义[10],同时对提高人均预期寿命、降低重大慢性病过早死亡率具有重要现实意义。
2 建设实践
2.1 系统架构
2.1.1 整体架构 提高临床数据可及性和可用性是临床科研数据库平台需要解决的核心问题[11]。数据治理是提升数据质量和可利用性的重要手段。但是针对不同应用场景和数据基础,数据治理的总体框架和核心任务则反映各自专业需求特点,各不相同[12]。因此,广东省第二人民医院以建设高效、灵活、方便、安全、一体化的科研专病数据库系统平台为目标[13],结合现有数据基础,借鉴治理基础层、数据加工层、价值体现层3层治理框架,进行临床科研数据治理,通过算法、逻辑、规则、功能模块,执行标准化、元数据与主数据管理、数据建模、数据采集、数据归集、数据加工、数据挖掘、数据展示、质量控制等核心任务[14],见图1。

图1 系统整体架构
2.1.2 基本工作流程 影像存储与传输系统(picture archiving and communication system,PACS)、医院信息系统(hospital information system,HIS)、电子病历系统(electronic medical record,EMR)、实验室信息管理系统(laboratory information management system,LIS)等业务系统和临床数据库(clinical data repository,CDR)按照电子病历数据集、国际疾病分类法(international classification of diseases,ICD)、观测指标标识符逻辑命名与编码系统(logical observation identifiers names and codes,LOING)、医院信息互联互通成熟度测评标准完成业务数据标准化,通过数据仓库技术(extract-transform-load,ETL),根据实时性要求分别从各业务系统或临床数据库中抽取数据,经清洗、转换、加载等初步加工处理形成原始病历库。然后通过数据映射、自然语言处理(natural language processing,NLP)、正则规则等深度加工后与结构化数据按照主题域构建科研病历库,再根据专病模型对数据进行逻辑归集形成各专病库。基于科研病历库,系统为用户提供知识挖掘、全文检索、复杂统计、质量管理等各种应用输出。
2.2 关键问题
2.2.1 基于标准化的专病模型 专病数据库本质上是对多个分散异构业务系统的诊疗数据通过ETL进行形式和内容上的二次加工,使其符合科研数据库的数据模型。不同专病数据库一般采用自定义的数据模型,在对外数据共享、建立多中心专病库时需要耗费大量资源进行对接改造和数据映射。为解决这些问题,需要引入数据标准,建立标准化的临床数据模型、医学术语、编码系统[15]。广东省第二人民医院脑血管专病库大部分数据来源于CDR。其中数据在进入前已遵循电子病历数据集、ICD、LOINC、医院信息互联互通成熟度测评等标准规范在数据层面进行标准化。专病模型的确立与研究目的、建库工作量和后期扩展性高度相关。健康医疗数据科学与信息学组织(Observational Health DataSciences and Informatics,OHDSI)提出的观察医疗结果合作项目通用数据模型(observational medical outcomes partnership common data model,OMOPCDM)是一个为医学数据标准化而设计的数据模型[16]。借鉴该模型,结合国情与项目目标对数据的需求,进行专病库数据模型设计,就既往科研病历报告表单(case report form,CRF)与研究课题所需数据项进行深度沟通,最终确认模型构成。再根据模型搭建专病数据库,对数据中心以及业务系统的数据进行抽取、清洗并加载至数据库中,对部分数据项实现标准化清洗,对关注的医嘱药品、检验、诊断信息等数据进行归一化处理,对多来源数据项进行关联和逻辑计算。根据专病库实时性要求,通过ETL工具实现数据自动增量,对增量流程进行监控,实现数据量统计、日志记录、报错智能提醒等功能。对数据溯源关系、数据处理脚本进行封装,保证ETL流程透明化。编写数据质量脚本进行专病数据量统计、完整度计算、多来源数据项一致性校验,实现专病库数据质量控制。
2.2.2 后结构化处理 为提高数据质量,专病数据库通常会在临床业务信息系统通过结构化模板等方式进行数据的前结构化,但是临床表达与使用习惯等不同会导致部分数据不能实现结构化。然而临床科研关注的数据往往包括非结构化数据,如转科检查和转科病历等医疗文书,因此需要通过NLP进行后结构化处理。考虑到传统NLP医生标注的工作量和成本,脑血管专病库使用超过5万篇电子病历数据,基于TensorFlow框架,主要采用无监督深度学习方法训练得到垂直领域专病语言模型。模型以改造后的BERT预训练语言表征模型为基础,结合相关指标信息(包括指标名称、同义词、数据来源等特征),自动抽取与指标相关的病历原文,然后结合内部医疗知识库,利用命名实体识别及关系抽取算法自动生成规则,从而完善语义规则引擎及知识库,最终完成指标的自动提取和后结构化,见图2。
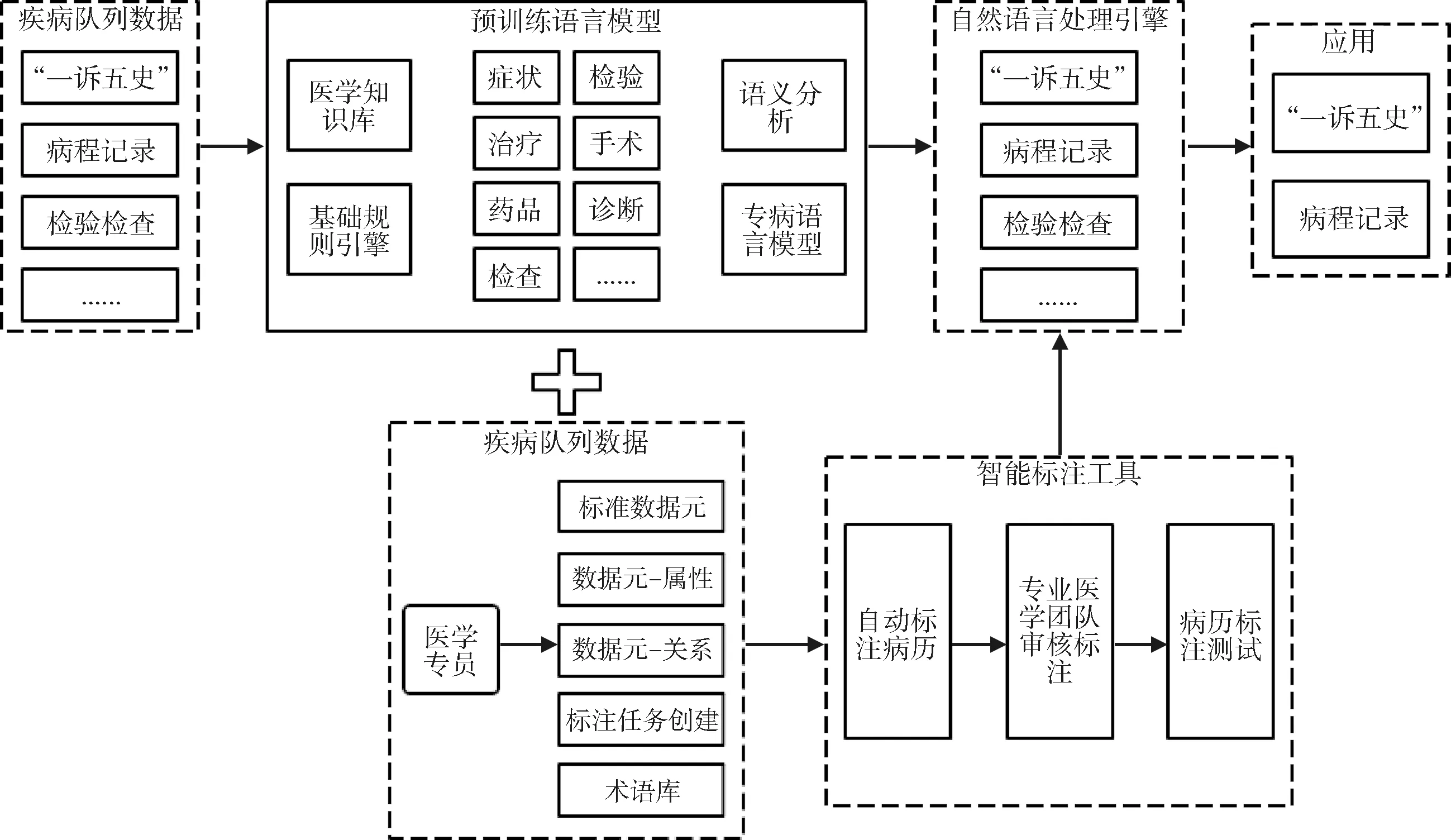
图2 后结构化工作流程
利用该病历后结构化流程,所有枚举型指标都将跳过人工标注,直接通过预训练模型自动后结构化。模型在自动学习过程中不断完善知识库,持续提高效率和精度。此外,结合临床医学特点进行语义化分词,将分词后的结构以临床医生熟悉的专科词汇进行存储,便于在科研、临床辅助过程中快速获取关键病历信息,如症状、特征值、阳性特征等,最大化、最快速地为科研提供临床参考资料。
2.2.3 多维数据关联 最大程度地从原始医疗数据中自动关联和提取病历数据是减轻临床科研人员数据整理工作量的关键[17]。由于历史原因,同一患者在医院可能有多个身份标识,同时医疗数据包括文本、图片、视频、表格等多种数据类型,具有多维特征,在数据抽取时,容易遗漏,造成数据不完整。因此,通过建立患者主索引(enterprise master patient index,EMPI),应用特定算法将不同业务系统所提供的患者标识信息重新组织,生成同一患者的唯一标识编码企业级患者主索引识别码(enterprise master patient index_identity,EMPI_ID),根据此编码能找到分布在各业务系统中的患者所有医疗信息,同时消除重复的患者数据,实现跨系统信息检索与共享[18]。EMPI同时提供患者信息检索服务,提供给其他应用程序访问患者基本信息;考虑到对异构平台的支持,消除系统平台的环境差异性等因素,EMPI通过接口对外提供服务,例如医院随访系统可以传入患者关键信息(姓名、性别、出生日期、身份证号、联系电话等),通过调用EMPI服务接口返回或生成对应的EMPI_ID,各业务系统都可以通过EMPI提供的接口来检索相关患者用户信息[19]。专病库在ETL中使用患者主索引服务,通过患者姓名和身份证进行精确匹配,通过姓名、性别、出生日期、联系方式等属性的权重进行模糊匹配,合并患者标识,生成或获得EMPI_ID,然后以就诊时间串联患者历次就诊记录形成纵向时间轴,横向以每次就诊的流水号关联各类型就诊数据,最终实现患者多维数据关联,并可通过时间轴上的链接调阅病历、影像等数据,见图3。
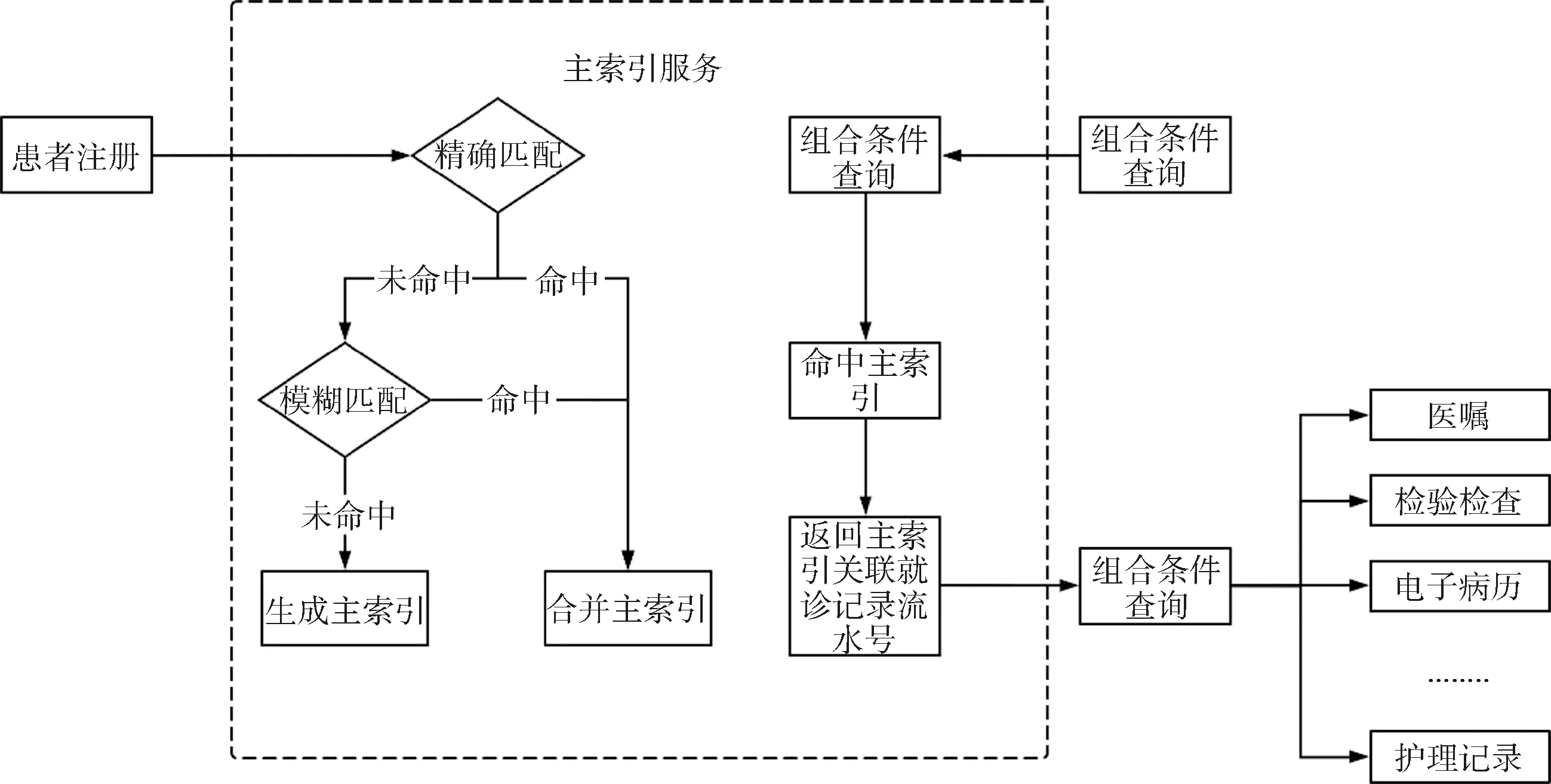
图3 主索引服务
2.2.4 智能检索 对已确定的科研主题,通过特定条件精准筛选病历数据,建立科研队列,对队列数据进行分析,按临床需求设计和生成CRF表单并导出数据,提供数据分析工具,采用统计分析方法对数据的分布状态、数字特征和随机变量之间的关系进行定性或定量估计和描述[20]。医生也可通过指定检索条件快速归集病历,形成临时队列,通过对队列的分析总结产生新的科研课题。因此专病库需要强大的搜索引擎,能高效实现专病库各数据项多重组合条件的检索和病历文书的全文检索。考虑到脑血管专病库数据量和对检索效率的要求,采用广泛应用的Elasticsearch数据分析引擎,通过对底层开源库Apache Lucene的封装,实现对每个数据项的索引和搜索。首先从科研数据库中抽取数据写入搜索引擎Elasticsearch Index;系统建设初期使用全量抽取,之后通过增量方式进行抽数。完成索引后,当系统接收到用户检索条件的请求,自动匹配定义的数据元,并利用系统自身逻辑程序封装成Elasticsearch的DSL语句;而后基于Elasticsearch的底层能力,根据DSL语句从 Elasticsearch Index中检索。如检索到数据,进行相关处理(如脱敏等操作)后,返回给用户。用户可以预览数据和下载CRF,见图4。相关数据结果可在智能统计平台进行分析。
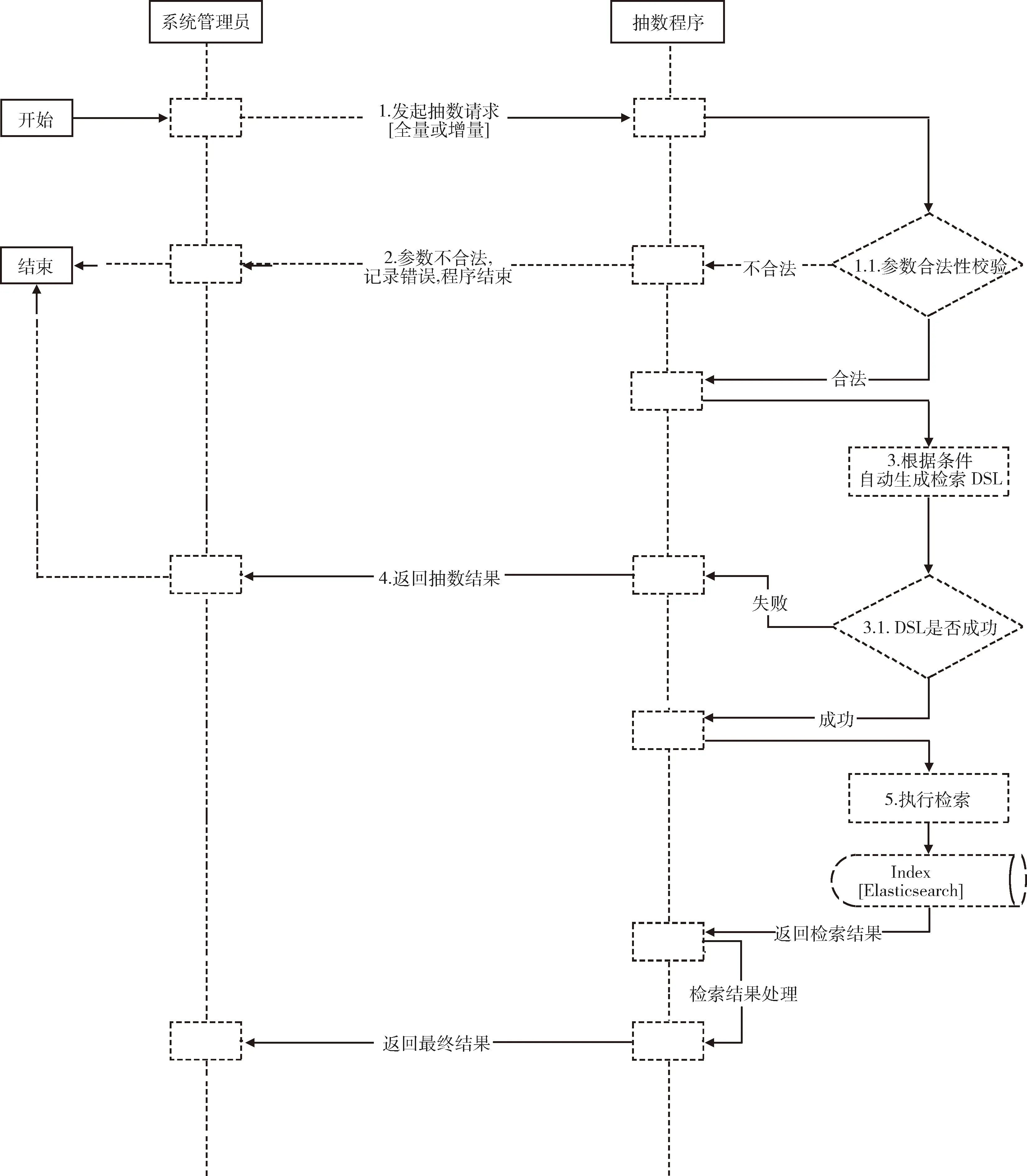
图4 数据检索流程
3 建设成果
该脑血管专病数据库于 2019年12月开始建设,2020年6月上线,其中纳入近8年以脑血管病为主诊断的患者38 391例。通过数据映射,应用同义词归一等数据治理手段,将住院及门诊不规范诊断24 706种归一映射出主诊断为脑血管病、脑梗死、高脂血症、脑梗死后遗症等241种诊断。
专病库采集数据元按业务域分为24类,共计1 188项,见表1。其中包含结构化数据747项,361项通过映射实现值域与数据字典的一致性;非结构化数据441项。
其中,对脑血管病诊疗核心的入院记录、手术记录、脑血管造影、颅脑磁共振等,需要后结构化指标441个,临床专家团队对每类100例报告进行标注,技术团队经过1万份样本训练后,完成以上指标的自动化采集、清洗、治理及可视化。为脑血管病等复杂疾病诊疗数字化提供重要参考依据。
此外,根据脑血管病诊断特点并结合临床研究应用方便快速检索数据的需求,令“诊断条件”按“前后循环”“血管定位”“解剖定位”“定性诊断”平铺陈列,“影像信息”按“检查类型”“解剖部位”“血管部位”“病变性质”“灌注成像”平铺陈列,方便临床科研工作人员快速定位相关患者队列,还可以通过检索频次、常用检索匹配逻辑固定成检索项,快速锁定队列。目前,已建立脑梗-丘脑、脑梗-后循环等多个研究队列,通过指定条件检索入组病历,为科研提供数据支持,也可以通过对队列数据的分析研究挖掘新的科研课题。
4 结语
以数据治理的理论框架为指导,通过临床调研、专病数据模型建立、后结构化、数据抽取、智能检索等技术实践,建立脑血管专病数据库,为脑血管专病科研队列管理、临床回顾性研究、数据建模和相关性分析提供有力数据支撑。
在数据库建设过程中遇到一些问题需要结合具体情况制定相应解决方案。例如卒中绿色通道患者缺失较多院前急救信息,通过对院前急救系统的改造,使用平板快速录入关键信息,使用患者主索引关联就诊记录,直接从院前急救系统提取数据项。再如部分后结构化数据项经过多次标注和算法优化效果仍然不好,通过对病历模板复杂度和医生书写习惯的分析,使用前结构化方式对部分模板进行改造,同时进一步优化NLP算法,在平衡医生病历书写工作量、满足科研需求的前提下提高数据准确性。在后续数据分析建模过程中,存在部分数据项为文字描述型无法进行分析,以及连续型变量中掺杂文字符号无法进行量化等问题,增加异常值处理模块,自动分析数据项类型,将描述型变量按关键词转换为多分类变量,为连续型变量中的非数字类型赋值,满足后续分析建模需求,节省数据准备时间。
未来,专病数据库还将根据临床需求扩充数据项覆盖范围,增加专病科研随访平台,提升NLP算法性能,在数据维度、时效性和准确性方面不断提升。同时,提升数据分析建模能力,借助患者全景、多模态数据,结合传统logistic回归分析、决策树分类、深度神经网络等人工智能分析方法,对各类数据进行相关性分析,建立智能疾病预测模型,辅助指导临床决策。将数据转换为科研成果,最终回归临床,指导实践,提升专科科研水平,完善治疗方案,为患者提供更加优质的服务。
猜你喜欢
基层中医药(2022年2期)2022-07-22 07:40:28
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
中西医结合心脑血管病杂志(2016年20期)2016-03-01 04:20:45
中国卫生标准管理(2015年13期)2016-01-15 02:58:29
中外医疗(2015年16期)2016-01-04 06:51:50
哈尔滨医药(2015年5期)2015-12-01 03:58:09
计算机工程(2015年8期)2015-07-03 12:20:35
中国中医药现代远程教育(2014年21期)2014-03-01 04:32:04
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
