
融合相似度算法与预训练模型的中文电子病历实体映射方法研究*
2023-06-30 02:27:24冯凤翔任慧玲李晓瑛王巍洁
医学信息学杂志 2023年5期
冯凤翔 任慧玲 李晓瑛 王巍洁 王 勖 张 颖
(中国医学科学院/北京协和医学院医学信息研究所/图书馆 北京 100020)
1 引言
随着计算机技术和生物技术的飞速发展,电子病历(electronic medical record,EMR)、医学报告、医学文献等生物医学文本的数量迅速增长,积累了海量有价值的医学数据[1],如EMR记录患者全部诊疗过程,包括所患疾病、药物、检查和治疗结果等[2]。随着命名实体识别技术成熟,可实现从中抽取疾病、药物、手术操作等特定实体[3],但实体存在表述口语化、多样化等问题,如“狼疮脑炎”可能被表述为“狼疮脑病”,“氯硝柳胺”可能被写作“灭绦灵”等。如果未经处理就加以利用或者储存入库可能导致各医疗信息系统标准不一,难以实现医院间资源互联互通[2]。因而需要根据实体在文中语义表达将其映射到知识库中对应的标准实体上,以解决概念内涵不清、语义表达和逻辑不一致等问题,促进独立医疗信息系统间的互操作,实现医疗信息和数据共享[4]。
目前中文电子病历实体映射研究主要由中国健康信息处理会议(China Health Information Processing Conference,CHIP)中的临床术语标准化评测任务推动,该任务使用来自真实医疗数据中的手术原词,由专业人员依据《ICD 9—2017协和临床版》手术词表进行训练数据标注。目前已有多支队伍完成手术实体映射任务,CHIP 2019任务最佳结果F1值为94.83%,由Dolphin-ICI团队取得[5]。实体映射作为一项重要的生物医学技术,近年来取得较大进步。但由于生物医学领域本身的复杂性以及真实医疗应用场景的高标准、严要求,该领域研究还存在一些提升空间,如现有研究大都以预训练语言模型BERT为基础进行任务构造,相关研究主要围绕CHIP任务中标注的手术实体进行[6],还需增加基于多类型实体的映射方法研究、改进方法模型以提升实体映射效果。
本文依靠专家知识与标准词表,标注涵盖多种类型实体的自标注标准数据集。结合传统文本匹配方法与深度学习的优势,提出融合传统相似度算法与深度学习模型的联合模型改进实体映射效果。并在此基础上提出基于别名间相似性映射标准实体的方法,为提升较短字符类实体映射效果提供思路。本文提出的方法在自标注数据集中F1值达到94.87%,可帮助抽取和规范化医疗数据以扩充中文临床医学术语体系的实体覆盖度,更好地支持临床辅助诊疗系统、精准医学研究和疾病监控等应用。
2 研究内容
2.1 数据来源
从“爱爱医” “众意好医师”“病历网”中抽取20 000余条中文电子病历,采用命名实体识别模型对疾病诊断、解剖部位、临床检查、手术操作和药物5类实体进行识别[7]。每类实体分别抽取约500个样例,邀请3位临床专家根据《国际疾病分类第10次修订本》(International Classification of Disease V 10,ICD 10)和《常用临床医学名词(2019年版)》,人工标注标准实体,数据清洗后,形成共包含2 390对数据的自标注标准数据集,训练集与测试集数据按照7∶3的比例进行分配,见表1。

表1 自标注标准数据集内容统计
2.2 实验设计
实体映射任务可分成候选实体生成(candidate entity generation,CEG)和实体消歧(entity disambiguation,ED)两个阶段,为此设计两个实验。
实验1为候选实体生成实验,即为待标准实体找到标准词表中所有可能与之对应的实体,生成候选标准实体集合,高效简便的相似度算法可以较好地完成这一任务。具体而言,针对每个待标准实体,计算其与标准词表中每个标准实体的文本相似度并排序,选取结果中前15位作为候选标准实体集合。采用目前应用较广泛的中文短文本相似度算法进行实验,对召回率进行比较以选取最佳算法,包括Cosine余弦相似度、BM 25(best match,BM)相关性评分、Jaccard相似系数、编辑距离(minimum edit distance,MED)与Dice系数。
实验2为实体消歧实验,生成候选标准实体集后,需要从中预测最可能与待标准实体相对应的实体作为映射结果,这一过程便是实体消歧。将该任务视为一个二分类任务,采用深度学习模型进行预训练,学习实体间语义关系并输出预测结果。谷歌推出的BERT模型能结合文本上下文信息并从中提取丰富全面的语义特征,出色完成二分类任务,在其基础上还衍生出如RoBERTa、ALBERT、RoBERTa-wwm等在各项自然语言处理任务中取得较好效果的模型。采用以上4种模型进行实体消歧,并比较模型性能,得到表现最好的算法模型组合,见图1。

图1 本文技术路线
2.3 评价指标
采用准确率(accuracy,A)、精确率(precision,P)、召回率(recall,R)和F1值(F1 score)作为评价指标。准确率指所有预测正确的结果所占比例,精确率指预测正确的正例占所有被预测为正例的比例,召回率指所有正例样本中预测正确的样本所占比例。F1值用来衡量二分类模型精确度,可以看作是模型精准率和召回率的调和平均,其最大值是1,最小值是0。预测结果有真阳性(true positive,TP),假阳性(false positive,FP),真阴性(true negative,TN),假阴性(false negative,FN)4种类型。其中,真阳性指预测结果为正,实际亦为正,其他同理。各指标计算方式如下:
(1)
(2)
(3)
(4)
3 相关算法与模型
3.1 相似度算法
3.1.1 Cosine余弦相似度 通过将文本矢量化,计算同个向量空间中两个向量夹角间的余弦值Cos(θ)来衡量相似度大小,夹角越小则相似度越高。在生成每个文本矢量时根据词频-逆向文件频率(term frequency-inverse document frequency,TF-IDF)原理,用词频向量V代替文本矢量每个维度的值[8]:
(5)
3.1.2 BM 25相关性评分 主要原理是先对句子q分词,生成若干特征词qi。Wi为每个qi的权重。之后对要与句子q进行比较的句子D计算每个qi与D的相关性得分,最后将qi相对于D的相关性得分进行加权求和,得到q与D的相关性得分[9]:
(6)
3.1.3 Jaccard相似系数 用于比较两个有限样本集之间的相似性,两个集合A和B交集元素的个数在A、B并集中所占比例称为这两个集合的Jaccard系数,Jaccard系数值越大则相似度越高[10]:
(7)
3.1.4 编辑距离 是对两个字符串差异程度的测量,其原理是计算一个字符串S1经过多少次处理才能变成另一个字符串S2,允许的编辑操作有替换一个字符、插入一个字符、删除一个字符3种[11]:
(8)
其中len代表字符串的字符个数,d(S1,S2)为字符串S1和S2的编辑距离。
3.1.5 Dice系数 是一种集合相似度度量指标,可将字符串理解为集合,因此Dice系数也可用于计算两个字符串的相似度,其范围为0~1,值越大表示相似度越高[12]。对于给定字符串S1和S2,其Dice系数算法如下:
(9)
3.2 深度学习模型
3.2.1 BERT 是一个无监督双向模型,可以使用纯文本语料库进行训练,并预测受左右上下文制约的单词。BERT能够在各种自然语言处理任务中表现出优异的性能[13]。经过调整,BERT可用于进行二分类任务,其模型原理,见图2。其中[CLS]位于开头,用于预测文本类别,[SEP]用于分割两个句子,ClassLabel为模型输出的类别标签。

图2 BERT模型二分类任务原理
3.2.2 RoBERTa 是在BERT预训练模型基础上进行改进的复制研究,其中包括对超参数调整和对训练集大小的影响进行仔细评估。同时该任务使用新数据集CCNEWS,并使用更多数据进行预训练,进一步提高下游任务性能[14]。
3.2.3 ALBERT 采用因子嵌入参数化和跨层参数共享两种参数简化技术解决BERT内存消耗高和训练速度慢的问题。此外,模型还提出句子顺序预测(sentence order prediction,SOP)任务来代替传统的下一句预测(next sentence prediction,NSP)预训练任务,从而获得更好的性能[15]。
3.2.4 RoBERTa-wwm 由哈工大讯飞联合实验室发布,结合中文全词掩码(whole word masking,wwm)技术与RoBERTa模型的优势,在RoBERTa模型基础上采用全词掩码来屏蔽汉语单词进行预训练。由于这些模型将应用于中文文本分类,全词掩码将允许这些模型结合中文场景,以提供更多有关中文语义的信息[16]。
4 实验结果及分析
4.1 候选实体生成实验
为对比分析不同相似度算法对候选实体生成效果的影响,基于5种相似度算法进行候选实体生成,选取相似度概率值前15位作为候选实体,并计算其召回率,见表2。为方便理解,下文待标准实体称为原始词,标准实体称为标准词。从结果中可以看出,基于Jaccard相似度算法匹配的效果优于其他4种算法,因此选择Jaccard算法进行候选实体生成能较好地保证候选标准实体集质量,有利于进行后续实体消歧工作。Cosine余弦相似度算法和BM25算法的生成效果明显低于其他相似度算法,是因为余弦相似度算法依赖高质量的词向量,BM25算法需要精准分词,本文并未人工进行特征构建,因此二者效果较差。

表2 候选实体生成实验召回率统计结果
从本实验中Jaccard算法未召回准确标准词的样例中可以看出,对字数过短或者原始词与标准词之间差异较大的实体,单纯使用相似度算法无法获取词中的语义信息,会导致召回失败,见表3。

表3 Jaccard算法未召回标准词样例
4.2 实体消歧实验
4.2.1 模型训练集构建 基于预训练模型的实体消歧需要构建包含正负例的训练集用于训练模型。根据相似度算法性能对比实验,基于Jaccard相似度算法,计算原词i与标准词词表中的每个标准词的Jaccard相似度系数,取相似度值前15位作为候选词表,将标准词i从候选词表中去除后剩下的候选标准词j用于构建负例[17]。训练集正例为:<原词i,标准词i,1>。负例为:<原词i,标准词j,0>。由于正样本数较少,与负样本数相差较大,为了扩充正样本,构建10*(标准-原始+原始-标准)共33 460条正样本。
4.2.2 实验环境及参数 本实验代码使用Python 3.6和Tensorflow 1.8编写,模型详细训练参数包括学习率(learning_rate)、每个样本处理成的长度(pad_size)、隐藏层中节点个数(hidden_size)、单次训练选取样本数(batch_size)、样本训练轮次(num_epochs),见表4。

表4 预训练模型参数设置
4.2.3 实体消歧实验结果 在基于Jaccard算法生成候选实体集的基础上,选取4种在二分类任务中表现较好的深度学习预训练模型作为基准进行实验,以对比分析不同模型的性能,见表5。从结果可知,采用RoBERTa-wwm模型的准确率最高,ALBERT模型的精确率和F1值最高,BERT模型的召回率最高,RoBERTa模型的各项指标效果都接近理想,因此难以确定最佳模型。同时还注意到,4个模型整体的准确率、精确率和F1值仍不太理想。对输出结果文档进行分析后发现除药物分类之外的其他分类各项指标均已大于86%,但是药物分类的原始词和标准词之间差异性过大,导致召回率较低,还需对此问题进行解决。

表5 实体消歧实验结果指标统计
4.2.4 优化后实体消歧实验结果 针对药物原始词和标准词差异过大问题,提出通过别名间相似性来进行知识补全从而提高实体映射效果的方法。标准词的别名间大多存在字符相似关系,如“甲硝唑”的别名有“灭滴灵”和“灭滴唑”,“布地奈德”的别名有“普米克”和“普米克令舒”。因此,本文针对药物实体采集第2批共9 481条标准实体-别名语料,构建药品别名映射库,增加药品原始词与药品标准词别名的匹配,若匹配到药品别名,将其链接至标准词。从结果可知,方法优化后,4个模型组合的实验结果均有较大提升,召回率均超过98%。采用Jaccard+BERT方法进行实体映射的各项指标均优于其他模型,F1值达到94.87%,见表6。
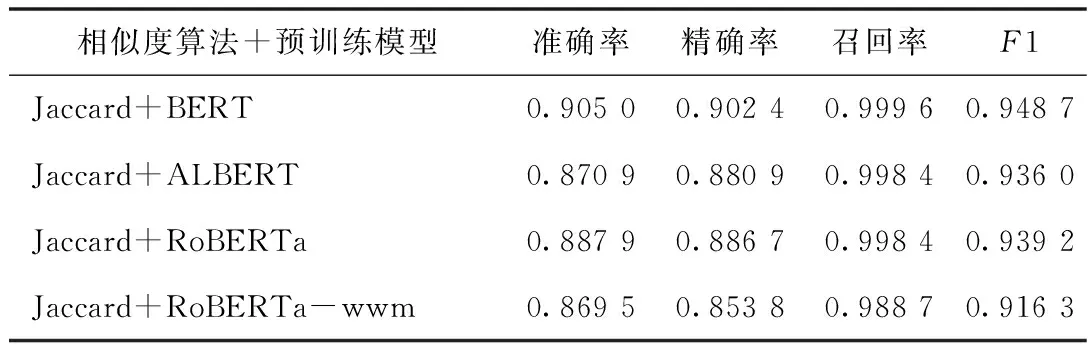
表6 优化后实体消歧实验结果指标统计
5 结语
本文标注了一个中文电子病历实体映射数据集,结合相似度算法与深度学习预训练模型,探究进行海量实体映射的最佳算法与模型组合。采用相似度算法进行候选实体生成,采用预训练模型进行实体消歧,并比较不同算法模型效果。结果显示采用Jaccard相似度算法与BERT模型的组合能够达到最优效果。同时本文提出通过别名间相似性改进实体映射效果的方法,各组合模型较改进前的F1值平均提高15.69%,达到较理想的实体映射效果,为未来相关研究提供思路。但是本文标注样本量较少,缺乏对不同类型实体映射效果的分别比较,未详细探究术语构成特点,未来可增加对不同类型实体的对照研究,针对性探究改进方案,以提升中文电子病历实体映射效果。
猜你喜欢
城市道桥与防洪(2022年4期)2022-07-01 06:04:12
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
中国外汇(2019年18期)2019-11-25 01:41:54
当代陕西(2019年8期)2019-05-09 02:22:48
动漫星空(兴趣百科)(2019年3期)2019-03-07 07:23:10
电脑与电信(2018年12期)2018-03-23 02:37:20
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
