
基于深度学习的医学影像问答模型*
2023-06-30 02:27:26赵晋稷
医学信息学杂志 2023年5期
赵晋稷 刘 旻
(1天津中医药大学第一附属医院 天津 300193 2 国家中医针灸临床医学研究中心 天津 300193)
1 引言
我国卫生资源总体缺乏,优质卫生资源严重不足。医生在临床工作中需要阅读大量医疗检查报告,存在人为错误的可能性,医疗资源不足可能会加剧这一现象。近年来,随着“互联网+医疗”模式的推广,在线问诊平台发展迅速,患者可以通过平台直接与医生沟通[1-2]。中医问诊平台中,大量舌象图像咨询成为急需解决的问题。伴随人工智能赋能医疗行业,医学领域出现了一系列智能分析系统,如医学影像问答系统,能够依托平台辅助解答并分流大量信息,提高工作效率,减轻医务工作者压力[3]。
2 相关工作
医学影像问答(medical visual question answering,Med-VQA)是医学领域的问答任务。在该过程中,输入医学影像和与之相关的临床问题,将自动输出答案[4]。患者可以在提问后及时得到反馈,医生也可以在诊断疾病时将系统反馈的答案作为参考意见。医学影像问答系统可以节省宝贵的医疗资源,辅助医生诊断。已有医学影像问答系统及相关模型[4]直接将自然场景下的图像问答模型迁移到医学场景使用。考虑到自然图像和医学图像中包含的语义有较大差异,有研究者提出注意力堆叠网络(stacked attention networks,SAN)[5]、双线性池化(multimodal compact bilinear,MCB)[6]、增强医学图像中的视觉信息(mixture of enhanced visual features,MEVF)[7]、问题为前提的推理(question-conditioned reasoning,QCR)[8]、双线性注意力网络(bilinear attention networks,BAN)[9]等操作,以缓解数据缺乏问题。已有模型性能较差,主要存在3方面问题:一是面对数据分布不相同的自然图片和医学影像,适用于自然图片问答系统的模型在医学影像问答系统并不一定有效;二是医学影像问答任务相关数据集需要人工标注,因此很多数据集包含训练样本较少,限制模型训练效果;三是医学影像问答任务相对于自然图像问答难度更大,因此在完成该任务时需要模型有更强的语义分析和多模态融合处理能力,见表1。本文在上述工作基础上采用语义图卷积(semantic graph convolution,SGC)进一步获取医学影像和文本之间的关联,从而更好地解决医学影像问答任务。针对问题一,通过元学习和自编码器增强医学影像相关数据,提高模型对噪声的鲁棒性;针对问题二,增加数据可以缓解训练样本较少的问题;针对问题三,通过设计语义图结构,进一步增强提取医学影像和文本之间关联的能力,并通过门控线性单元选择出文本中的重要部分,从而更好地完成医学影像问答任务。

表1 多种医学影像问答方法的基本原理和缺点
3 方法
3.1 医学影像问答任务
首先输入一张待诊断图片,如电子计算机断层扫描(computed tomography,CT)图像、舌象图像等;然后输入一个与该图像相关的问题;模型充当医生角色,根据输入图片回答给定问题,从而进行智能问诊。本文提出基于语义图卷积的医学影像问答模型,见图1。
两口子忙了半下午,瞅瞅,日光已经西斜了。看来觉是不能睡了,也睡不着了。相反,两人的精神头,倒比睡着了更好。
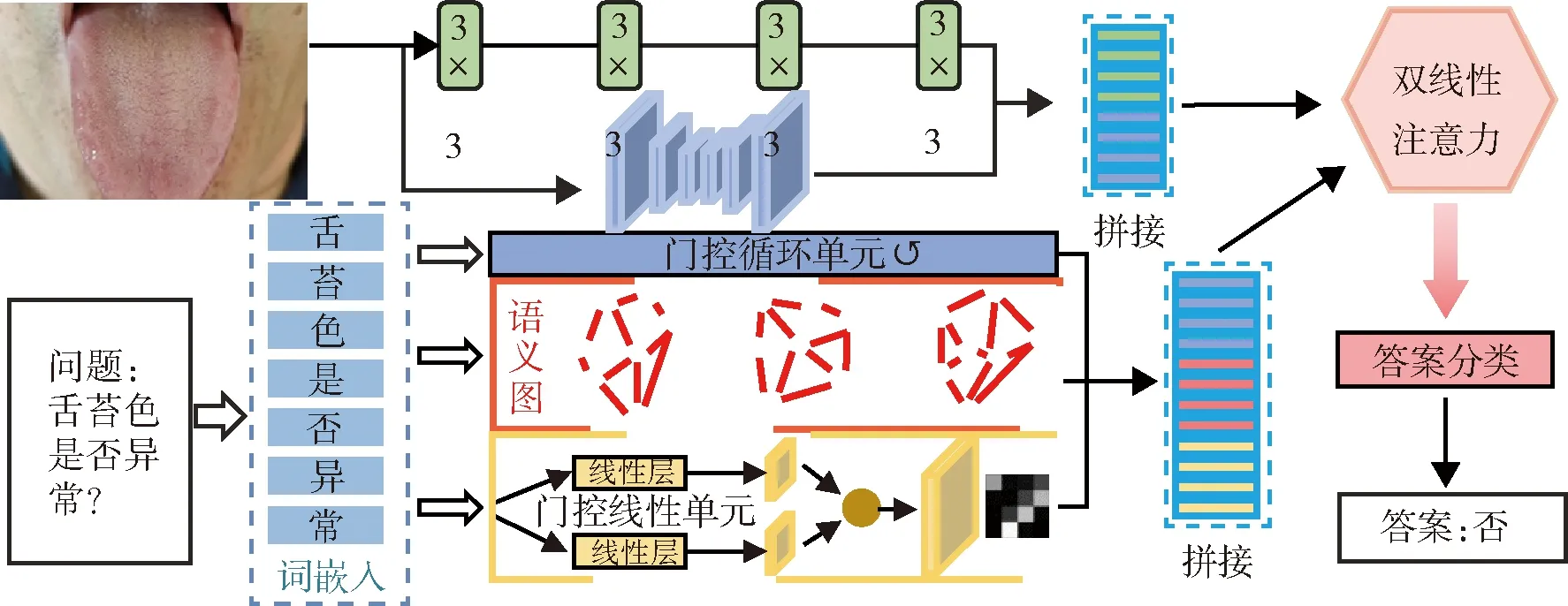
图1 研究框架
3.2 图像信息处理
输入医学图像I之后,对该图像采用如下预处理。一是将图像首先输入4层3×3的卷积网络,然后进行全局平均池化,并采用元学习(model-agnostic meta-learning,MAML)方法初始化网络权重[10],最终该操作得到的特征维度为64。二是采用自编码器对图像进行进一步处理[11]。三是将上述两步操作得到的特征进行拼接,得到图像特征V∈R1×128。
3.3 文本信息处理
本文在医学问答数据集(visual questions and answers about radiology images,VQA-RAD)上进行训练和测试[15],该数据集包含315张医学领域相关待诊断图片和3 515条医生标注的问诊对话。其中,问诊对话包含两种类型:固定式问答和开放式问答。固定式问答的答案为“是”或“否”两种特定选项,例如问题为“该胸部CT图像中是否有异常状况”,答案为“是”;开放式问答的答案没有固定形式,例如问题为“该头颅核磁中的病灶在什么位置”,答案为对应的特定位置。在实验中,采用3 064条问答对话作为训练集,451条对话作为测试集。训练过程中采用自适应动量优化器进行梯度下降优化,学习率为0.000 1,训练轮数为150轮。
可以看到与QCR相比,本文方法在开放式问答数据集准确率方面提升2.8个百分点,达到55.6%;在固定式问答数据集准确率方面提升2.5个百分点,达到79.3%,见图2。其中红色代表正确回答,绿色代表错误回答。为了进一步分析图2中的问答结果,将本文方法(SGC)与已有方法(QCR)模型提取的中间层特征进行可视化,见图3。图3针对图2中的问题1和问题3进行分析,高亮部分分别为本文方法(红色)和已有方法(绿色)重点关注区域,结合问题1(“动脉瘤”)和问题3(“右侧颞叶”)文本部分可知,本文方法可以更好地捕捉与文本相关的医学影像区域,从而更好地回答问题。通过图3所示的可视化结果可以看到,本文方法通过设计语义图结构可以更好地提取医学影像和文本中的关联信息,优于已有方法。
第2步:考虑到语句本身包含上下文序列信息,为了编码整个语句序列特征Qs∈Rn×ds,采用门控循环单元(gate recurrent unit,GRU)[12],该步的输入为上一步得到的词嵌入特征Qe,输出为包含上下文序列信息的语句特征Qs。
第3步:考虑到语句中单个文字之间的关联以及整个语句中的语义结构,将整个语句嵌入到图结构中构成语义图[13],并采用图卷积网络提取特征,语义图本质上是一种特殊的特征结构方式。首先提取语句之间的关联强度作为语义图的邻接矩阵:
(1)
其中We1,We2∈Rde×da,da表示图结构的隐式特征维度,A0∈Rn×n表示该语义图的邻接矩阵。接下来基于邻接矩阵进行图卷积操作:
ΔROA=γ0+γ1cashi+γ2mixi+γ3leveragei+γ4scalei+γ5sizei+γ6tobinQi+εi
Qg=A0QeWe1Wg0
(2)
第4步:为了进一步提取并突出语句中重要的文字特征,采用门控线性单元(gated linear unit,GLU)[14]:
出版类企业核心竞争力提升策略探析 ………………………………………………………………………………… 黄 晓(2/24)
其中Wg0∈Rda×de为可学习的参数,Qg∈Rn×de为经过语义图嵌入后的语句特征,不仅包含语句文字之间的关联信息,而且融合了语句整体信息。在语义图中,每个文字是1个单独的图节点,每个图节点之间边的权重通过关联强度决定,图卷积过程相当于对整个图结构的边不断进行更新,训练完成后得到整个语义图最优结构。
U1=φ1(QeW1)
(3)
U2=φ2(QeW2)
(4)
Ql=φ3(U1⊙U2)Wl
(5)
根据前文表2中的实验结果和上述分析可知本文提出的基于语义图问答模型的有效性,针对开放式问答和固定式问答,通过语义图模块可以加强文本特征之间关联的表达,同时利用门控线性单元筛选文本特征中的重要信息,提升了整个模型的问答准确率。
第5步:在得到上下文序列信息的语句特征Qs、语句的语义图特征Qg、重要性相关语句特征Ql后,将不同层次级别的语句特征进行特征融合,具体实现方式如下:
Qfea=[Qs;Qg;Ql]Wq
(6)
其中Ac表示正确回答的问题数量,Aall表示整个数据集中的问题数量。为了更准确地分析方法效果和性能,实验结果部分对开放式问答和固定式问答分别进行统计。
岩体稀土元素含量∑REE为116.43×10-6,∑Ce/∑Y比值为2.66,δEu为0.61。(La/Sm)N值为3.47,(Gd/Yb)N为0.91;为富轻稀土型。δEu<0.7,表明岩浆为上地壳经不同程度的部分熔融形成的。
3.4 问答系统
采用双线性注意力网络对图像特征V和文本特征Qfea进行融合:
y=BAN(V,Qfea)
(7)
然后通过分类器预测答案的置信分数s,将概率最大的作为最终结果。
4 实验结果与分析
4.1 实验设置
在实际应用中,当患者将待诊断图像上传后,会提出并输入相应问题q∈Rn,其中n为问句长度。对该问句采取如下特征处理过程。
4.2 评价指标
(8)
其中,[;]表示特征拼接操作,Wq∈R(ds+dg+dl)×dq是可学习的参数,Qfea∈Rn×dq表示最终提取得到的文本特征。
4.3 实验结果
本文提出的方法(SGC)与已有方法应用于开放式问答和固定式问答任务的准确率对比结果,见表2。
1)果园深翻。秋季采果后结合秋施基肥进行,只要方法合适,春、夏、秋季都可进行深翻,其中以秋季果实采收后至落叶期进行为好。针对贵州苹果产区中的山区薄土层果园,土壤深翻,能够加厚活土层,促进岩土的风化和熟化,提高土壤蓄水保肥能力。

表2 不同方法准确率对比
第1步:对问句中每个文字进行词嵌入(word embedding,WE),得到语句特征Qe=[w1,w2,…,wn]∈Rn×de。

图2 本文方法与已有方法的问答结果
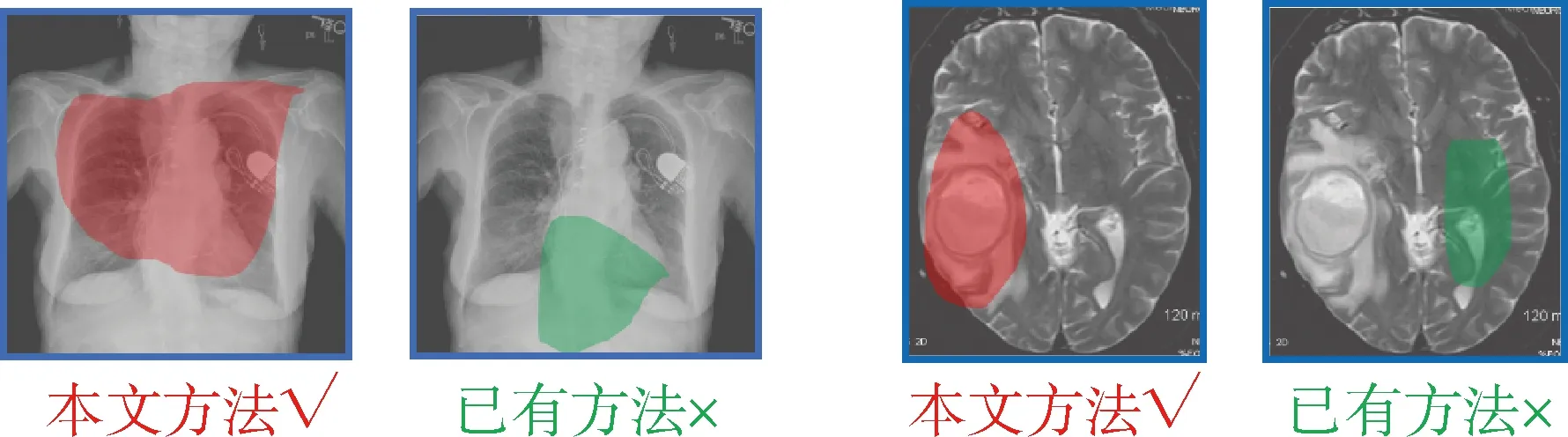
图3 本文方法与已有方法对医学影像的关注区域可视化

4.4 消融分析
为了进一步探讨本文提出模型(SGC)中各模块对于任务的作用和效果,从语义图模块、门控模块以及两模块中包含的激活函数3方面进行消融分析。不同模块消融后的基于问答准确率的实验结果,见表3。

表3 不同模块消融实验
其中“√”表示使用该模块,“-”表示不使用此模块。从表3第1行可以看到门控线性模块对提升问答准确率的重要作用,固定式问答任务性能提升约6%;从第2行可以看到语义图模块能够在较难的开放任务上有效捕捉文本内部关联;从第3行可以看到语义图模块和门控线性模块中的激活函数对任务准确度也有一定影响。
为了分析不同维度对模型性能的影响,实施相关模块对模型维度敏感度分析,见图4、图5。可以看到不同语义图嵌入维度对模型性能影响较小,当维度达到足以表征语义图时,模型性能达到饱和,更高维度的隐式空间是不必要的;门控线性模块对不同维度选择有一定要求,合适的隐藏层维度有利于该模块寻找重要语句文本。
原来这届的社长要改选时,一共有七位大三的学长符合选举资格,但没有一位想当社长,最后只好用猜拳决定,猜输的当社长。

图4 不同语义图维度模型性能

图5 不同门控线性模块维度模型性能
针对语义图维度和门控模块维度,从模型表达能力而言,两者在一定范围内的提高均可以提升相应表达能力,但是更高维度会带来更大的计算复杂度,在神经网络训练过程中有较大开销,延缓整个模型的收敛效率,有一定可能造成性能下降,因而隐藏层维度并不是越大越好,这也与图4和图5的实验现象一致。从模型过拟合而言,虽然双向编码器表征模型[16]的隐藏层维度可达768甚至1 024,却能同时拥有更强表达能力,对比可知,造成本文模型维度受限的另一个主要原因是训练集数据量较少,较深维度容易导致过拟合性能下降,由于医学领域标注的数据集有限,拥有专业医学知识的标注人员稀缺,标注难度较大,这也是医学问答领域乃至“人工智能+医学信息”领域目前的重要挑战。
随着新媒体的快速发展,微信群成为家校沟通的重要渠道。管理班级微信群,与其要求家长在群里不能做什么,还不如与家长商讨能做什么,以及怎么做。开学初,我借助家长会,与各科老师以及家长充分探讨,最终确定了班级微信群每天“群聊”的话题。同时,这也被当作家长的一项“作业”来完成。
5 结语
本文使用深度学习方法解决医学影像问答问题,通过元学习和自编码器模块提取医学影像视觉特征,通过语义图卷积提取问题中的文本特征,并获取视觉特征和文本特征之间的重要关联。实验结果表明本文方法在相关医学影像问答数据集上较已有工作有一定提升,开放式问答准确率提升到55.6%;固定式问答准确率提升到79.3%。本文方法在开放式问答性能提升方面尚有较大空间,开放式问答任务本身需要生成对应答案,因此需要提升模型生成能力。在未来工作中将从以下两个方面进行改进,首先在语言特征提取时采用预训练的大模型[16]提升特征表达能力,其次是收集并标注更多医学领域语料库用于训练,使模型具备更好的文本生成能力。
猜你喜欢
中国药学药品知识仓库(2022年8期)2022-05-09 13:54:24
中国临床医学影像杂志(2021年10期)2021-11-22 07:46:38
中国医学影像学杂志(2021年6期)2021-08-13 08:43:08
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
开放教育研究(2020年2期)2020-03-31 01:54:14
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
语文知识(2014年4期)2014-02-28 21:59:52
卫生职业教育(2014年9期)2014-02-16 07:22:08
