
基于改进YOLOv4的车辆目标检测算法
2023-06-25 08:27:56刘伊智
天津科技大学学报 2023年3期
苏 静,刘伊智
(天津科技大学人工智能学院,天津 300457)
随着城市的不断发展,人口流动更加频繁,堵车等交通拥挤问题也逐渐得到重视,发展智慧交通成为了重中之重.车辆的目标检测是实现城市智慧交通的关键技术.视觉目标检测是计算机视觉的经典任务,旨在定位图像中存在物体的位置并识别物体的具体类别.目标检测是许多计算机视觉任务及相关应用的基础与前提,直接决定相关视觉任务及应用的性能[1].
传统的目标检测算法以手工设计特征为主,这些特征的泛化能力弱,对复杂场景的性能表现较差[2],并且存在速度缓慢和准确率低等问题.现如今基于深度学习的目标检测算法已经成为主流,此类目标检测算法主要分为两类:单阶段(one stage)算法和两阶段(two stage)算法.两阶段算法的主要代表为R-CNN[3]系列算法,单阶段算法最有代表性的是YOLO算法和SSD算法[4],其中YOLO系列算法更是进行了多次迭代更新,后续分别提出了YOLOv2[5]、YOLOv3[6]、YOLOv4等算法.在城市道路交通中,车辆行驶速度一般在30~120km/h之间,在本文的实验部分,对Faster RCNN与YOLOv4进行了帧每秒(FPS)的对比实验,Faster RCNN的平均FPS只有32.4,而YOLOv4原算法FPS为58.1.由实验可知Faser RCNN算法检测速度缓慢,不适用于道路上高速行驶车辆的检测.YOLO系列算法具有检测速度快、准确率高的优点,可以更好地适用于公路上行驶车辆的目标检测.YOLO系列的第四代算法YOLOv4具有良好的检测性能与检测速度,但是对于一些目标也存在识别率不高等问题.
李挺等[7]将MobileNetv2作为YOLOv4的主干网络,加入了Bottom-up连接,并融合了CBAM注意力机制,在分类网络中加入了Inception结构.虽然在行人检测方面的结果有所提高,但是对行驶车辆的检测却会出现漏检等问题.陈洋等[8]在PANet中加入CBAM模块,同时使用加强的k均值聚类(k-means)对目标真实框进行聚类,使算法检测锚框更适合于训练集,提高了船舰图像检测的精度,但是却增大了网络参数,使得模型训练缓慢,不够轻量.王滢暄等[9]提出了多标签检测方法,建立其约束关系,并提出图像拼接检测方法,以提升网络的运行效率.
因此,本文提出改进YOLOv4车辆检测算法:将主干网络改进为轻量型的CSPDarknet53-tiny和GhostModule模块结合的网络结构进行特征提取,形成YOLOv4-Ghost-tiny,提高模型的运行速度,减少网络的规模大小;将SPPNet替换为ASPPNet[10],增大网络感受野并减少模型参数;将注意力机制SENet[11]结构嵌入其残差结构当中,使其能够对不同特征图进行相应处理.
1 相关工作
1.1 YOLOv4算法介绍
Alexey Bochkovskiy继承了YOLO系列的理念,在YOLOv3的基础上进行了改进,发布了YOLOv4[12].在与EfficientDet网络性能相当的情况下,该算法的推理速度是EfficientDet的2倍左右,比上一代YOLOv3算法的平均精度(AP)和FPS分别提高了10%和12%.
该算法由主干特征提取网络CSPDarknet53、特征金字塔SPPNet和检测结构YOLO-Head构成.主干网络CSPDarknet53在YOLOv3主干网络Darknet53基础上,借鉴了CSPNet的思想,在减少参数计算量的同时保证了准确率.YOLOv4算法在特征金字塔模块中采用了SPPNet结构,进一步提高了算法的特征提取能力,而YOLO Head特征层则继续使用YOLOv3的结构.
1.2 GhostModule网络模块
GhostModule[13]网络模块来自GhostNet网络,网络核心是开创了一种全新的Ghost模块,它可以在使用较少参数的同时能保留更多的特征.Ghost模块可以替换任何CNN网络中的卷积操作,其优点是轻量、高效,效果优于轻量级网络MobileNetV3[14].在神经网络中,Ghost模块将一个普通的卷积块分成两部分.首先将输入的特征图先经过卷积,再通过逐层深度可分离卷积生成其对应的冗余特征图,最后将卷积生成的特征图和深度分离卷积生成的特征图进行堆叠操作.与传统卷积神经网络相比,该方法的参数量和计算复杂度均有所降低.
主要核心模块Ghost Module的原理主要是用Ghost Module代替传统卷积.首先采用1×1卷积对输入图片进行通道数的压缩,然后再进行深度可分离卷积[15]得到更多的特征图,最后对不同的特征图进行拼接操作,使其拼接到一起,组合成新的输出图.Ghost Module结构如图1所示.

图1 Ghost Module结构Fig.1 Ghost Module structure
1.3 ASPPNet
DeepLabv3[16]网络的ASPP模块结构包括1次1×1的普通卷积、3次3×3的空洞卷积和1个全局池化分支.该网络模块受到空间金字塔池化的启发,可以对不同特征的特征图进行有效采样以及分类操作.
ASPPNet利用空洞卷积[17],在不改变其他参数的情况下增大其感受野,该模块的组成部分为1次1×1卷积和3次3×3卷积,分别进行这些操作计算,最终将4次卷积结果进行拼接叠加.
1.4 SENet注意力机制
通过引入注意力机制,使众多输入信息能够聚焦于更为关键的信息,降低对其余参数信息的敏感度,过滤掉无关信息,提高任务处理的效率与准确率.SENet是Momenta公司2017年在CVPR中提出,并获得最后一届ImageNet图像识别冠军.
SENet模块结构如图2所示.首先,对给定输入特征图X进行全局平均池化操作,得到一个通道数为C的特征图;然后,对通道数为C的特征图进行两次全连接操作,第一次全连接时的参数量相比第二次全连接时的参数量更少,在两次全连接操作完成后,对其特征层的每一层通道进行Sigmoid操作,得到权重值;最后,将权重值与其原特征层进行参数相乘操作.该模块可以用到其他网络结构中,能够达到即插即用的效果,对大多数网络都有所提升.

图2 SENet模块结构Fig.2 SENet module structure
2 算法改进
2.1 改进主干网络
原始的YOLOv4网络使用了CSPDarknet53作为其算法的主干网络,CSPDarknet53对图片特征有着很强的提取能力.但是,由于其网络结构复杂、参数繁杂,导致其训练缓慢,在轻量性方面有所欠缺.为了提高速度,将网络前驱部分DarknetConv2D的激活函数由Mish改为LeakyReLU.由于模型一般在减少参数后准确率往往会降低,因此对其网络中的Resblock_body模块进行改进,将该模块的残差部分改为GhostModule结构,形成ResGhost_body模块,弥补准确率降低的缺点.ResGhost_body模块结构如图3所示.主干网络最终提取到3个有效特征层(52×52、26×26、13×13).

图3 ResGhost_body模块结构Fig.3 ResGhost_body module structure
2.2 改进特征融合模块
YOLOv4在其主干特征提取网络之后连接了特征融合模块SPPNet,该网络结构由He等[18]提出,起初是为了解决R-CNN速度缓慢的问题.在原YOLOv4网络结构中,SPPNet接在了最后一层特征层的卷积里,并对其主干网络中最后一个特征层进行3次卷积之后,分别利用4个不同大小的池化层对其进行处理,其池化核大小分别为1×1、5×5、9×9、13×13,最后将得到的4个特征模块图进行通道拼接,结构如图4(a)所示.但是,此模块会导致参数量增大,使网络结构训练减慢,运行速度下降.

图4 SPPNet改进图Fig.4 SPPNet improved diagram
因此,将SPPNet模块结构替换为与其相似的ASPPNet,不仅能够减少参数量,还可以增大网络的感受野.该网络结构模块为1个1×1的普通卷积和3个3×3的空洞卷积.首先对输入的特征图进行3次卷积,之后对其进行1次1×1的普通卷积和3次3×3的空洞卷积,最后将得到的4个模块特征图进行叠加,其结构如图4(b)所示.
2.3 嵌入SENet结构
原始特征图在经过了主干网络的特征提取及ASPPNet等结构的一系列卷积操作之后,随着参数量的增大,产生梯度消失等问题,容易失去主要特征,使得最终的准确率下降.因此,在最后的PANet[19]模块中加入注意力机制SENet结构,让网络聚焦更为关键的信息.在原始的YOLOv4网络结构中,主干特征提取网络有2个分支以及在特征融合模块之后有1个分支,这3个分支会进入PANet结构中,因此为了保留原始分支中的信息,在PANet模块中加入注意力机制SENet.改进前模块和改进后模块的结构如图5所示,其中P1、P2、P3代表其3个分支.
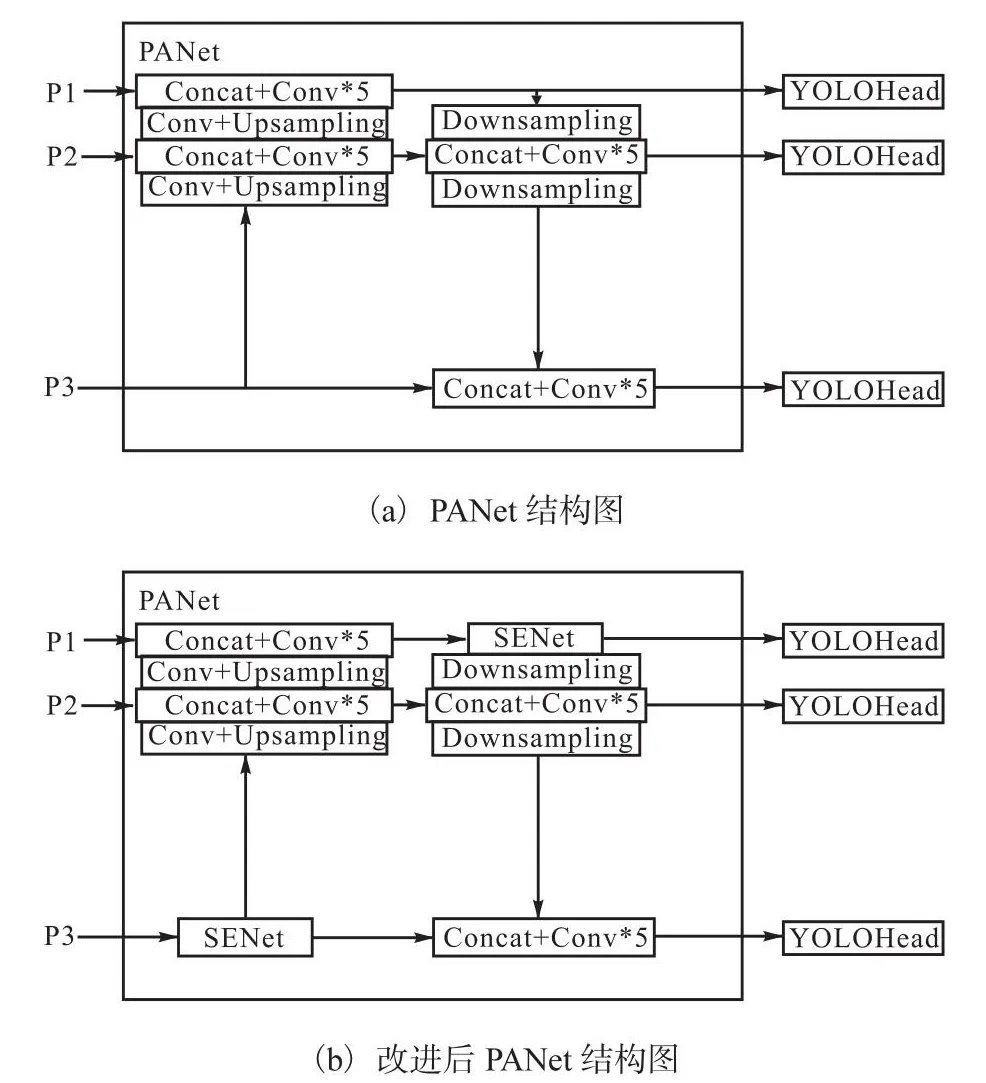
图5 PANet结构对比图Fig.5 Comparison of PANet structures
3 实验设计与结果分析
3.1 实验平台
本实验在Windows10操作系统下完成,使用语言为Python,使用框架为PyTorch1.7.0,处理器为Inter i5-9300H,内存为16GB,GPU采用GTX 1650 4GB显卡.
3.2 实验数据集
对于车辆的目标检测,采用自动驾驶BDD100K数据集,其中训练集50000张,测试集15000张.由于本文主要研究对车辆的目标检测,因此对数据集进行了筛选和清洗,最终训练集36400张,测试集9256张.
3.3 评价指标
用精确率(precision)、召回率(recall)和平均精度(AP)对模型进行评估,公式为
式中:NTP为被模型预测为正类的正样本,NFP为被模型预测为正类的负样本,NFN为被模型预测为负类的正样本,P、R、Pav分别表示精确率、召回率和平均精度.
3.4 实验结果比较
为了验证本文算法的有效性,实验在BDD100K数据集上进行了测试,结果见表1.由表1可知:本文算法通过改进残差模块,在残差分支中加入了GhostModule模块;对原网络结构中的SPP结构进行改进,增大感受野,提高精度;PANet网络结构添加了SENet注意力机制模块,使整个网络结构得到了优化.较原算法YOLOv4结构,AP提升了2.69%,帧每秒(FPS)也有相应提升,使算法具备更好的检测效果,AP、召回率、精确率结果对比如图6所示.

表1 对比实验结果Tab.1 Results of contrast experiment
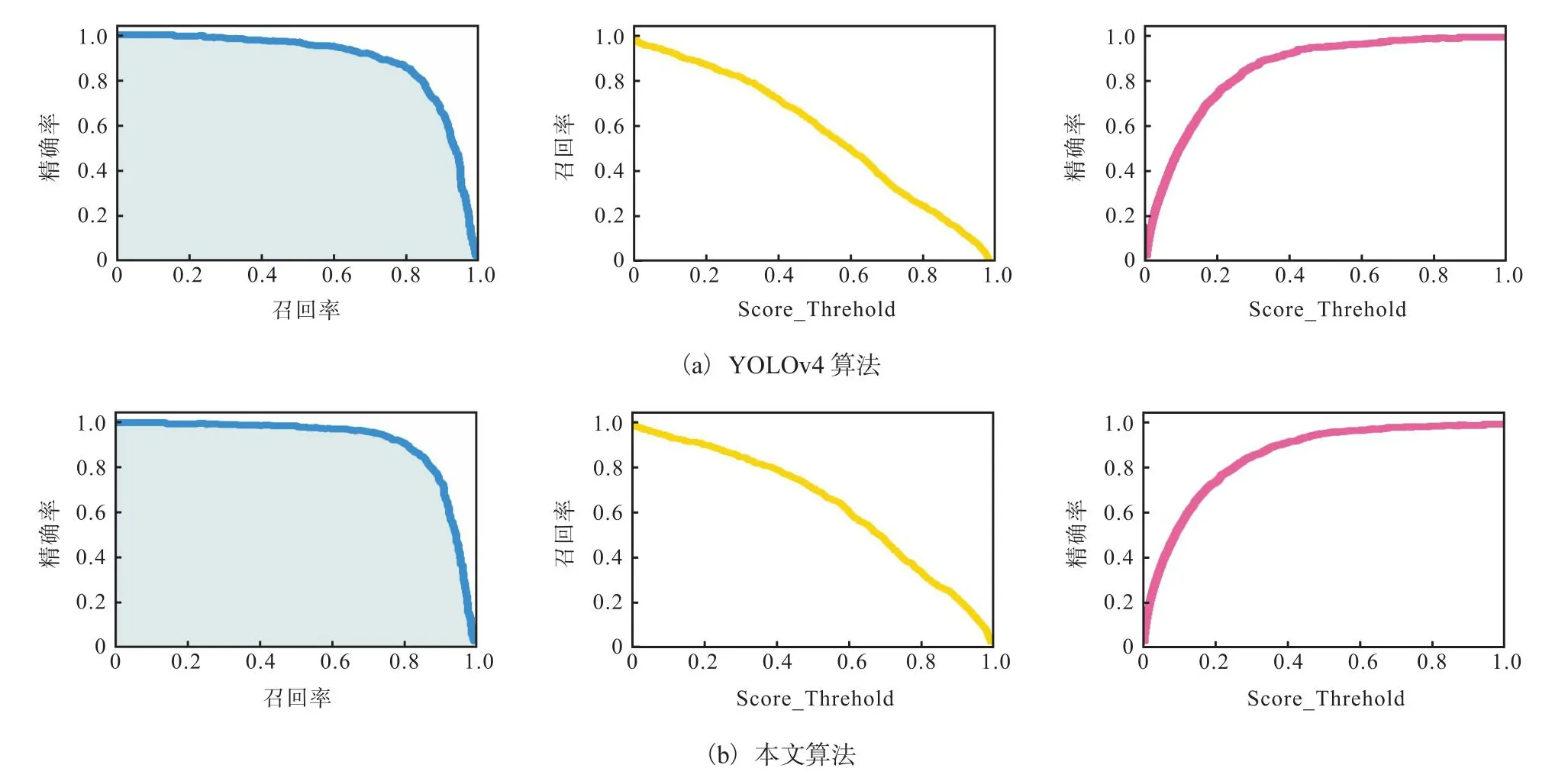
图6 不同算法AP、召回率、精确率结果对比Fig.6 Contrast graph of AP,recall and precision of different algorithm
3.5 实验效果对比
本文模型与原算法YOLOv4在测试集上进行实验,部分检测结果如图7所示.从图7中可以看出,原算法对于部分车辆检测出现了漏检现象,而本文算法有着更好的检测性能.

图7 YOLOv4算法和本文改进算法在测试集上的效果Fig.7 Effects of YOLOv4 algorithm and improved algorithm on the test set
3.6 消融实验
为了验证本文提出的改进YOLOv4算法对于原算法的提升效果,对本算法提出的3个改进点分别进行消融实验,分别为主干网络残差边融合GhostModule、ASPP、SENet.消融实验结果见表2.
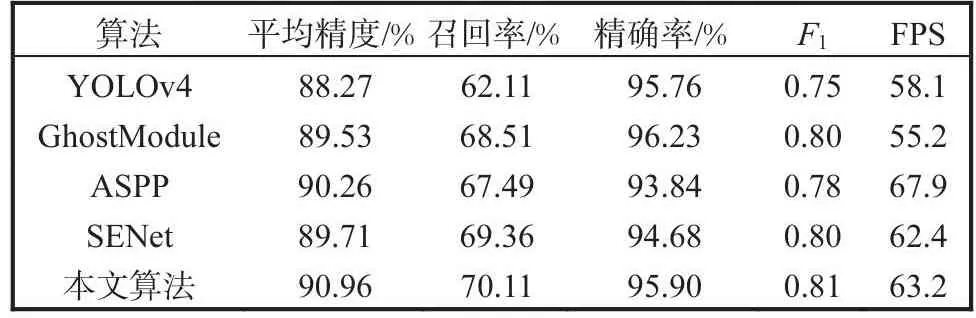
表2 消融实验结果Tab.2 Ablation experimental result
由表2可知:在AP方面,改进后的算法均比原YOLOv4算法有不同程度的提升,加入ASPP后提升效果最好.
加入SENet模块之后召回率的提升效果最为明显,这主要是因为注意力机制可以更加关注重要的特征通道,提升网络的信息提取能力.ASPP和SENet模块的精确率相对于YOLOv4算法并没有提升,而加入了GhostModule之后,精确率有所提升,这是因为在残差边部分加入GhostMoudule模块可以加强其特征提取能力,使得精确率提升.在FPS方面,在将SPP改为ASPP之后,参数量减少,导致模型检测FPS提升最为明显.因此在加入上述3处改进点之后,4个指标都有不同程度的增长.本文中的算法同时融合了3处改进点,相对于GhostModule,牺牲了一部分精确率,但是平均精度和召回率均为上述实验中的最高值,并且精确率和FPS相对于YOLOv4算法也有所提升.
3.7 实际场景中的应用
为了验证本算法在实际场景中的应用能力,自制搜集相关数据集6000张,对其进行标注并将图片转换为voc格式数据集,在实际场景中对数据集进行实验,实验结果见表3.
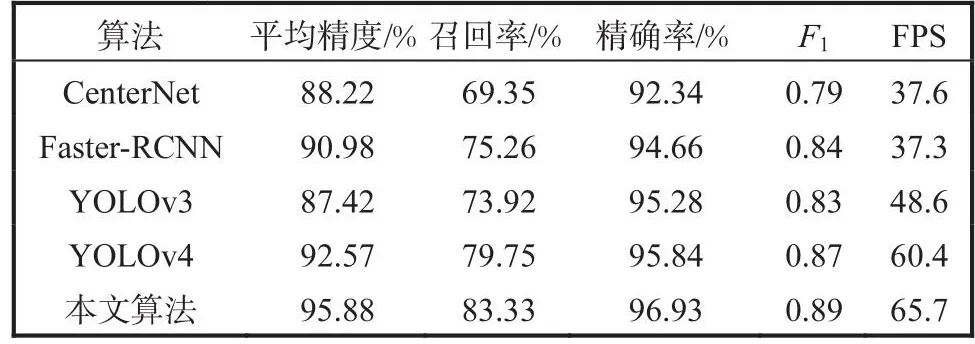
表3 网络模型在实际场景下的实验结果Tab.3 Experimental result of network model in real scene
由表3可知,本文算法在实际场景下比YOLOv4算法表现更为优秀,平均精度提高了3.31%,且其他指标都有不同程度的提高,YOLOv4算法与本文算法在实际场景下检测效果如图8所示.

图8 实际场景下检测效果对比Fig.8 Comparison of detection effects in actual scenarios
4 结 语
(1)本算法在原始算法YOLOv4的主干特征提取网络的残差块中添加GhostModule模块,提高其检测精度;同时将特征金字塔中的SPPNet模块替换为ASPPNet模块,减少参数量的同时增大网络感受野;在PANet模块中的两个分支插入SENet结构,防止其因为网络结构复杂而出现梯度消失的问题,增强网络特征的表现能力.
(2)本文算法通过实验验证,解决了在交通道路中对于车辆的漏检、误检情况,经过改进后的YOLOv4算法已经可以满足道路场景下的实际应用需要.但是,目前图片数据集还是不够全面,之后还需要增加一些处于极端天气下,比如暴雨和沙尘暴天气下的车辆图片,从而让模型能够在任何条件下都拥有良好的检测性能.
猜你喜欢
军事文摘(2024年2期)2024-01-10 01:58:34
广东教育·高中(2022年1期)2022-03-16 23:19:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
心肺血管病杂志(2020年3期)2021-01-14 00:42:12
心肺血管病杂志(2019年6期)2019-07-12 09:04:30
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
